zookeeper 理论合集
目录
系统背景
集群结构
多个节点之间的角色
节点的状态
为什么引入 Observer
存储结构
ZNode 节点结构
ZNode 创建类型
内存数据存储
数据持久化
zookeeper 的容量大小
数据同步
消息广播
崩溃恢复
如何保证顺序一致性
核心流程
Leader 选举流程
脑裂问题
session 会话
临时节点的实现
顺序节点的实现
节点 watch 机制
应用场景
数据发布与订阅 / 分布式服务协调
分布式锁
分布式队列
系统背景
zookeeper 为了解决什么问题?
分布式协调服务,用于管理分布式系统,使一个系统中的节点知道其他节点的状态。
实现方式?
通过维护和监控存储的数据变化,达到基于数据的集群一致性管理。
简单说,zookeeper = 文件系统 + 监控通知机制
应用场景?
配置维护、域名维护、分布式同步、服务发现等
zookeeper中的 CAP?
C:保证「最终一致性」,并不保证强一致性,在十几秒可以Sync到各个节点(如果保证强一致,写性能会很差)
-
如果想保证取得是数据一定是最新的,需要手工调用Sync()
A:保证了可用性,数据总是可用的,没有锁
-
但是在集群选主期间,服务不可用
| C 一致性 | A 可用性 | |
|---|---|---|
| zookeeper
|
|
|
| Eureka
|
|
|
| 单机 Redis
|
| |
| 集群 Redis
|
|
|
集群结构
在分布式系统中,zookeeper 作为一个协调组件,更需要保证其可用性,所以一定是多节点部署的。

多个节点之间的角色
-
Leader 领导者:提供读、写服务;负责投票的发起、决议
-
Follower 跟随者:提供读服务;参与事务投票;参与 leader 选举投票;参加 leader 选举
-
Observer 观察者:提供读服务;不参与事务投票;不参与 leader 选举投票;不参加 leader 选举
节点的状态
-
Looking:竞选状态
-
Following:跟随者状态
-
observing:观察者状态
-
leadering:领导者状态
为什么引入 Observer
Observer 是 zk-3.3 之后引入的新角色,其与 follower 的区别就是不参与任何投票;
可以在不影响「写」性能的前提下,提高「读」性能;(写操作在超过半数节点投票之后才成功,参与投票的节点多,投票过程会成为性能瓶颈)
Observer 的数据没有事务化到硬盘,只加载在内存中。
存储结构
简单讲 zookeeper = 文件系统 + 通知机制
ZNode 节点结构
在zk中可以说所有的数据都是由znode组成的,并且以 k/v 的形式存储。类似于 linux中文件目录的 树形结构,根目录以 / 开头。
| cZxid | 创建节点时的事务ID |
| ctime | 创建节点时的时间 |
| mZxid | 最后修改节点时的事务ID |
| mtime | 最后修改节点时的时间 |
| pZxid | 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID(注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid) |
| cversion | 子节点版本号,子节点每次修改版本号加1 |
| dataversion | 数据版本号,数据每次修改该版本号加1 |
| aclversion | 权限版本号,权限每次修改该版本号加1 |
| ephemeralOwner | 创建该临时节点的会话的sessionID。(如果该节点是持久节点,那么这个属性值为0) |
| dataLength | 该节点的数据长度 |
| numChildren | 该节点拥有子节点的数量(只统计直接子节点的数量) |
ZNode 创建类型
-
Persistent 持久化节点
-
Persistent_sequential 顺序自动编号持久化节点(根据当前已存在的节点数+1)
-
Ephemeral 临时节点(客户端session超时此节点自动删除)
-
Ephemeral_sequential 临时自动编号节点
内存数据存储
zookeeper 的数据组织形式为一个类似文件系统的数据结构,这些数据都是存储在内存中的。
但是其存储格式并不是一个真正的数据,而是一个对象:DataTree,代表了内存中的全部数据
public class DataTree {private final ConcurrentHashMap<String, DataNode> nodes =new ConcurrentHashMap<String, DataNode>();private final WatchManager dataWatches = new WatchManager();private final WatchManager childWatches = new WatchManager();
} 其中 DataNode 是数据存储的最小单位
public class DataNode implements Record {byte data[]; // 数据的字节数组Long acl; // 访问权限 public StatPersisted stat; // 持久化统计信息private Set<String> children = null; // 子节点路径的集合
}数据持久化
为了避免宕机或断电情况下的数据丢失,zookeeper 也制定了一些数据持久化方式:
-
事务日志 log
-
事务快照 snapshot
事务日志 log 文件
-
对于客户端的每一次事务(写)操作,zk除了会将数据变更到内存中,还会记录到事务日志中;
-
目录格式:log.{zxid},zxid:创建该文件时的最大 zxid
事务快照 snapshot 文件
-
用于记录某一个时刻 zk 服务器上的全量数据,
-
目录格式:snapshot.{zxid},zxid:创建该文件时的最大 zxid
事务恢复过程
先通过快照数据快速恢复,再通过增量事务日志恢复
-
先从 snapshot 目录中找到 zxid 最大的文件,根据它的内容恢复
-
去 log 目录中找 略小于 zxid、所有比 zxid 大的文件,依次读取并执行请求
zookeeper 的容量大小
每个 znode 中数据的限制为 < 1MB,一般 znode 的数量 < 10w,snapshot 大小 < 800M
zookeeper 应该被作为一个分布式协调服务,而不是存储服务,所以不应该被存储过多的数据。
数据同步
节点间的数据一致性,指的是事务操作改变的数据,即写操作;
在 zookeeper 中,主要通过 ZAB协议(Zookeeper Atomic Broadcast 「zk原子广播协议」) 来实现分布式数据一致性。ZAB 协议分为两部分:
-
消息广播:使用一个单一的leader来处理所有的写请求,并且将请求以事务投票的形式广播到所有的follower中;
-
崩溃恢复:在主机断电、宕机的情况下,集群恢复之后依然正常工作,数据一致;
消息广播
其过程类似于2PC,不同的是主节点不需要等待所有节点的ack,而是过半的 follower 就可以。(Observer 不参与投票)
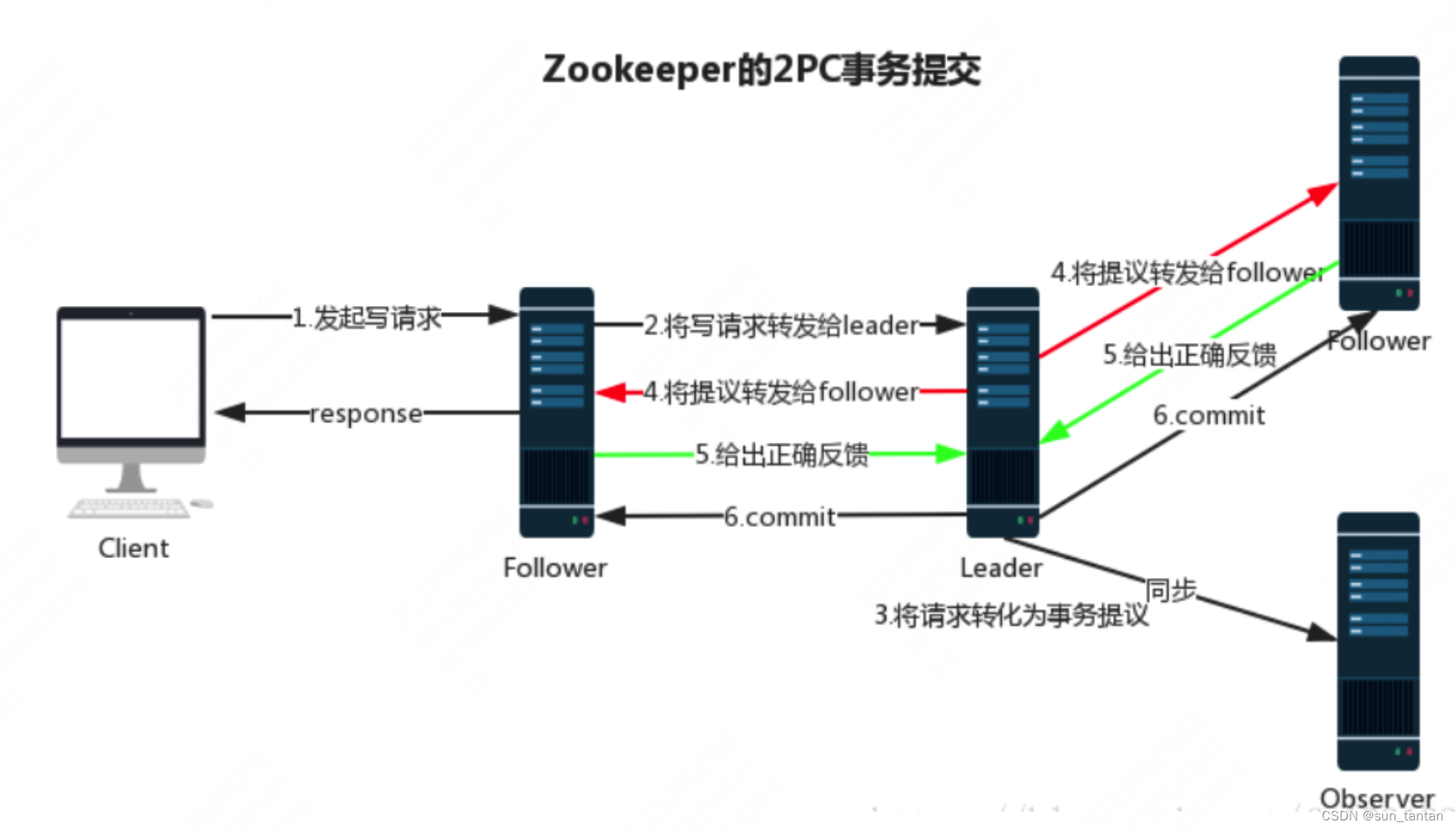
-
leader 收到消息请求后,将会生成一个 zxid,
-
leader 与 follower 之间通过 tcp 协议 + FIFO 队列 通信,将带有 zxid 的消息发送给 follower
zxid
—— zk中的事务id:全局单调递增唯一id
高32位 epoch 纪元 :代表 leader 周期,每进行一次 leader 选举+1,并将 counter 清零
低32位 counter 计数器:针对客户端的每个事务请求都+1
崩溃恢复
什么时候算是崩溃?
leader 服务器出现故障,或者由于网络问题,leader 服务器与过半的 follower 失去通信。
什么叫做恢复?
选举出一个新的 leader
在这个过程中可能出现两种情况:
被丢弃的消息不能再出现
-
原 leader 发出写请求后崩溃,其他服务器并没有收到此消息,选取新 leader后,此消息被跳过;
-
但原 leader 重启后成为 follower,其保留了此消息,需要被删除
新的 leader 会以自己的最后一个事务消息为准,明确其他节点需要丢弃的消息
已经被处理的消息不能被丢弃
-
原 leader 在本地执行 commmit,并且发出 commit 后崩溃,则剩下的服务器并没有提交此事务
选举出的新 leader 是zxid最大的节点,必然包括此事务;
新的 leader 会将自己事务日志中已 proposal 但没有 commit 的事务提交掉,然后给其他的 follower 发消息。
被丢弃的消息不能再出现
-
原 leader 发出写请求后崩溃,其他服务器并没有收到此消息,选取新 leader后,此消息被跳过;
-
但原 leader 重启后成为 follower,其保留了此消息,需要被删除
新的 leader 会以自己的最后一个事务消息为准,明确其他节点需要丢弃的消息
已经被处理的消息不能被丢弃
-
原 leader 在本地执行 commmit,并且发出 commit 后崩溃,则剩下的服务器并没有提交此事务
选举出的新 leader 是zxid最大的节点,必然包括此事务;
新的 leader 会将自己事务日志中已 proposal 但没有 commit 的事务提交掉,然后给其他的 follower 发消息。
如何保证顺序一致性
从客户端的角度来看
zookeeper 保证了同一个客户端请求的有序性;但是不同的客户端之间的事务请求不保证。
因为 zk 中通过一个 Map 去保存每一个客户端的请求,每个客户端的key 不同,而value 为一个 FIFO 先进先出队列。
从服务端(Leader 节点)的角度来看
-
一致性
对于ZooKeeper来讲,ZooKeeper的写请求由Leader处理,Leader能够保证并发写入的有序性,即同一时刻,只有一个写操作被批准,然后对该写操作进行全局编号,最后进行原子广播写入,所以ZooKeeper的并发写请求是顺序处理的,而底层又是用了ConcurrentHashMap,理所当然写请求是线程安全的。
-
有序性
zookeeper 的 leader 节点需要保证事务按照 zxid 的顺序来生效;
但是 leader 节点在执行一个事务时,需要发起提议、收到超半数的 follower 的投票后才生效,这两个步骤的时间并不是完全按照发起的顺序。
Leader 为了保证提案按 ZXID 顺序生效,使用了一个 ConcurrentHashMap, 记录所有未提交的提案 ,命名为 outstandingProposals
每发起一个提案,将提案的 zxid 与内容记录到 outstandingProposals ,即:待提交提案
收到 follower 的 ack 后,根据 ack 中的 zxid 从 outstandingProposals 中找到对应的提案,对 ack 计数
尝试将提案提交:
判断提案是否收到了超过半数的 ack,达到半数,可以提交
判断当前 zxid 之前是否还有提案未提交,如果有,当前提案暂时不能被提交
—— 判断 outstandingProposals 里,当前 zxid 的前一个 zxid (zxid-1)是否还在
核心流程
Leader 选举流程
发生 leader 选举的时机有两个:集群启动时、或是原 leader 节点宕机。
几个选举时非常重要的参数:
-
myid:服务器id,集群中节点的编号,1/2/3...,编号越大权重越高;
-
zxid:事务id,值越大说明此节点上的数据越新;
-
ephoch(与zxid中的ephoch不同):投票选举轮数,同一轮投票所有的 ephoch是相同的;
服务器启动时leader选举
-
集群启动时每个节点都是 looking 竞选状态
-
每个节点将自己的(ephoch、zxid、myid)作为投票发送给其他节点
-
节点处理投票,优先级为:ephoch、zxid、myid;
-
对方节点 > 自己,更新投票为对方节点的信息;
-
自己 > 对方节点,投票信息不变;
-
-
进入下一轮投票,ephoch+1;
其中每一轮投票都进行一次统计:是否有超过半数的节点投给了某个节点,如果超过一半,则已选出leader;
此节点更新自身状态为 leadering,进入数据同步、消息广播阶段。
运行过程中leader选举
与启动时类似
脑裂问题
什么是脑裂?在什么场景下会发生?
在分布式系统中,如 zookeeper 集群会有一个统一的“大脑”,也就是 leader 节点。但由于网络问题等,集群中一部分节点不能与 leader 通信,此时集群将分裂成不同小集群,各自选出自己的 leader。
zookeeper 如何避免?
zookeeper 在选举 leader 时采用「投票过半」机制:只有获得超过半数节点的投票,才能选举成功。因此要么选举出唯一 leader,要么选举失败。
如果其余节点选举出新 leader,旧的 leader 又复活了呢?
zookeeper 维护了一个 ephoch 纪元变量,每个 leader 产生,ephoch+1,follower 会拒绝所有 ephoch < 现任 leader ephoch 的所有请求
zookeeper 之外所有脑裂问题的解决方式
超半数投票;添加心跳线(采用多种通信方式);磁盘锁(集群中只有一个 leader 可以获取锁)
session 会话
所谓 session,就是在客户端与服务器之间创建的一个「TCP长链接」。有了链接之后,后续的请求发送、回应、心跳等都是基于会话实现的。
-
zk 中一个客户端只会与一个服务器建立 tcp 长链接,除非与当前服务器连接失败
session 的管理机制——分桶
session 的数据结构:
-
SessionId:会话的唯一id,由zk管理分配(由时间戳+机器id生成)
-
TimeOut:超时时间(相对时间)
-
ExpirationTime:绝对过期时间,是 ExpirationInterval(zk定时检查session过期频率,默认 2000ms) 的倍数。所以 expiration time 是一个近似值。
zookeeper 服务端会把各个 session 分配到不同的「桶」里面进行管理,区分的维度即:Expiration Time。
然后 zk 会以 ExpirationInterval 为频率定期扫描下一个过期的桶,将其内的 session 置为过期。
session 续约
客户端与服务器建立连接之后,expiration time 并不是永远不变的,客户端会发生读写请求或者心跳来保持会话的有效性。
过期时间的更新,也意味着 session 需要在 桶 之间进行迁移。
-
客户端发送 读、写 请求,都会触发一次激活
-
客户端没有请求,在 timeout 的1/3 时间会发送一次 ping 来续约
-
客户端断开,则 timeout 过期之后 zk 扫描到此 session 过期并清理
临时节点的实现
临时节点的过期时间?
客户端建立连接时的 session 过期后,其创建的所有临时节点将被删除。
zookeeper 怎么知道哪些节点由此客户端创建的?
znode 中的 ephemeralOwner 字段,保存了客户端 session Id
顺序节点的实现
sequence 自增原理?
由父节点的 cVersion 控制,在此父节点下创建 顺序子节点,子节点的 path = cVersion,然后 cVersion 自增
如何进行并发控制?
由于创建节点属于 事务操作,因此 follower 节点会转发给 leader 节点进行操作;在 leader 节点中 create Sequence node 之前,会给其父节点加 synchronized
节点 watch 机制
watcher 的特性:
-
一次性:watcher 是一次性的,一旦被触发就会移除,再次使用时需要重新注册
-
需要监听一个节点的更新事件,需要不断注册?
是的。zookeeper curator 框架对此做了封装,实现了自动注册。
-
-
顺序性:watcher 回调是顺序串行化执行的,一个 watcher 回调逻辑不应该太多,以免影响其他 watcher 的执行
-
watch 的通知事件是从服务器异步发送给客户端,不同的客户端收到的 watch 的时间可能不同。但是 zooKeeper 有保证:客户端先收到 watch 事件再看到结点数据的变化的。例如:A=3,此时在上面设置了一次 watch,如果 A 突然变成 4 了,那么客户端会先收到 watch 事件的通知,然后才会看到 A=4。
-
不同的客户端监听的事件可能在不同时刻,但是 同一个客户端是保证顺序 的,客户端 watcher1 监听的事件优先于 watcher2 监听的事件发生,可以保证在客户端 watcher1 先于 watcher2 被触发。
-
-
轻量级:watchEvent 是最小通信单元,结构上包括事件类型、节点路径,但不包括内容的前后变化
-
时效性:watcher 在当前 session 完全失效时才失效,如果客户端在 session 有效时间内重连成功,watcher 依然有效
watchEvent 内容:
| KeeperState | EventType | 触发条件 |
|---|---|---|
| SyncConnected | None | 客户端与服务器成功建立连接 |
| NodeCreated | 监听节点被创建 | |
| NodeDeleted | 监听节点被删除 | |
| NodeDataChanged | 监听节点内容变更 | |
| NodeChildrenChanged | 监听节点的子节点列表发生变更 | |
| DisConnected | None | 客户端与服务断开连接 |
| Expired | None | 会话超时 |
| AuthFails | None | 权限错误 |
zookeeper 的 watcher 机制,与「观察者模式」类似,一共分为四个步骤:
-
客户端注册 watcher
客户端可以在任意的 读命令 上注册 watcher,如 getData、exists、getChildren 接口
-
服务端处理 watcher
-
服务端触发 watcher 事件
-
客户端回调 watcher
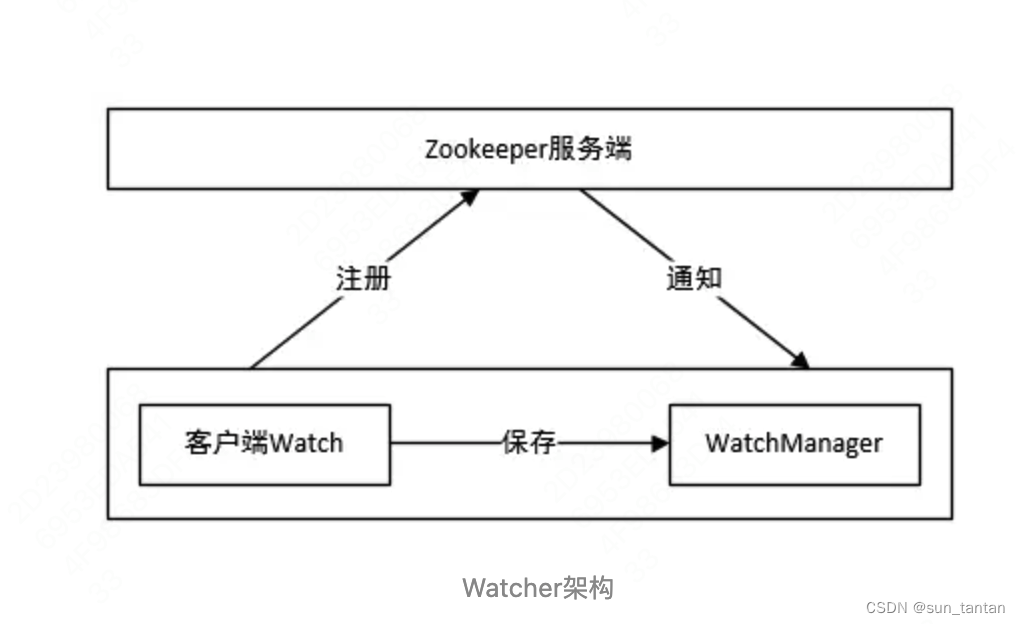
客户端首先将 watcher 注册到服务端,同时将 watcher 对象保存到客户端的 watch 管理器中。当 ZooKeeper 服务端监听的数据状态发生变化时,服务端会主动通知客户端,接着客户端的 watch 管理器会触发相关 watcher 来回调相应处理逻辑,从而完成整体的数据发布/订阅流程。
watcher管理器 数据结构
客户端 —— ZKWatchManager
-
key:数据节点路径
-
value:注册在当前节点的 watcher 集合
// 代表节点上内容数据、状态信息变更相关监听
private final Map<String, Set<Watcher>> dataWatches =new HashMap<String, Set<Watcher>>();// 代表节点变更相关监听
private final Map<String, Set<Watcher>> existWatches =new HashMap<String, Set<Watcher>>();// 代表节点子列表变更相关监听
private final Map<String, Set<Watcher>> childWatches =new HashMap<String, Set<Watcher>>();服务端 —— WatchManager
// key代表数据节点路径,value代表客户端连接的集合,
// 该map作用为:通过一个指定znode路径可找到其映射的所有客户端,当znode发生变更时
// 可快速通知所有注册了当前Watcher的客户端
private final HashMap<String, HashSet<Watcher>> watchTable =new HashMap<String, HashSet<Watcher>>();//key代表一个客户端与服务端的连接,value代表当前客户端监听的所有数据节点路径
//该map作用为:当一个连接彻底断开时,可快速找到当前连接对应的所有
//注册了监听的节点,以便移除当前客户端对节点的Watcher
private final HashMap<Watcher, HashSet<String>> watch2Paths =new HashMap<Watcher, HashSet<String>>(); 
应用场景
数据发布与订阅 / 分布式服务协调
多个订阅者同时监听同一个主题对象,主题对象状态变化时通知所有订阅者;此方式可以让发布方与订阅方独立封装,互相解耦
在分布式系统中的应用有:
-
配置中心
-
服务发现
-
集群机器存活监控:检测系统和被检测系统不直接联系,通过 zk 上的节点关联,解耦
-
通过客户端注册 EPHEMERAL 节点,监控端进行监听,一旦会话结束或过期,该节点就会消失。
(在此方式之前,一般是监控者通过某种手段比如 ping,定时监控每台机器;或者是客户端定时向监控者汇报我还活着)
-
-
系统调度:管理者在控制台进行一些操作,实际是修改了某些 zk 的节点,对应的客户端将会收到节点变化通知,作出相应任务
分布式锁
排它锁
定义锁:
/exclusive_lock/lock-
所有的客户端通过调用 create() 接口,在 /exclusive_lock 节点下创建 临时子节点 /exclusive_lock/lock,最终只有一个客户端能创建成功,调用成功的客户端代表成功获取锁;
-
其余的客户端在 /exclusive_lock 节点上注册一个 子节点变更的 watcher 监听事件,以便重新争取获得锁
羊群效应
所有的客户端均监控 /exclusive_lock 一个节点,如果当前锁释放,所有客户端均收到通知,但是只能有一个客户端会重新获取锁,这对资源是一种浪费。

解决:客户端创建 临时顺序节点,每个客户端监控其前一个序号的节点。
优点:每次锁释放,只有一个客户端被通知;另外还实现了公平锁,先到先得。
共享锁(读写锁)
定义锁:
/shared_lock/[hostname]-请求类型W/R-序号 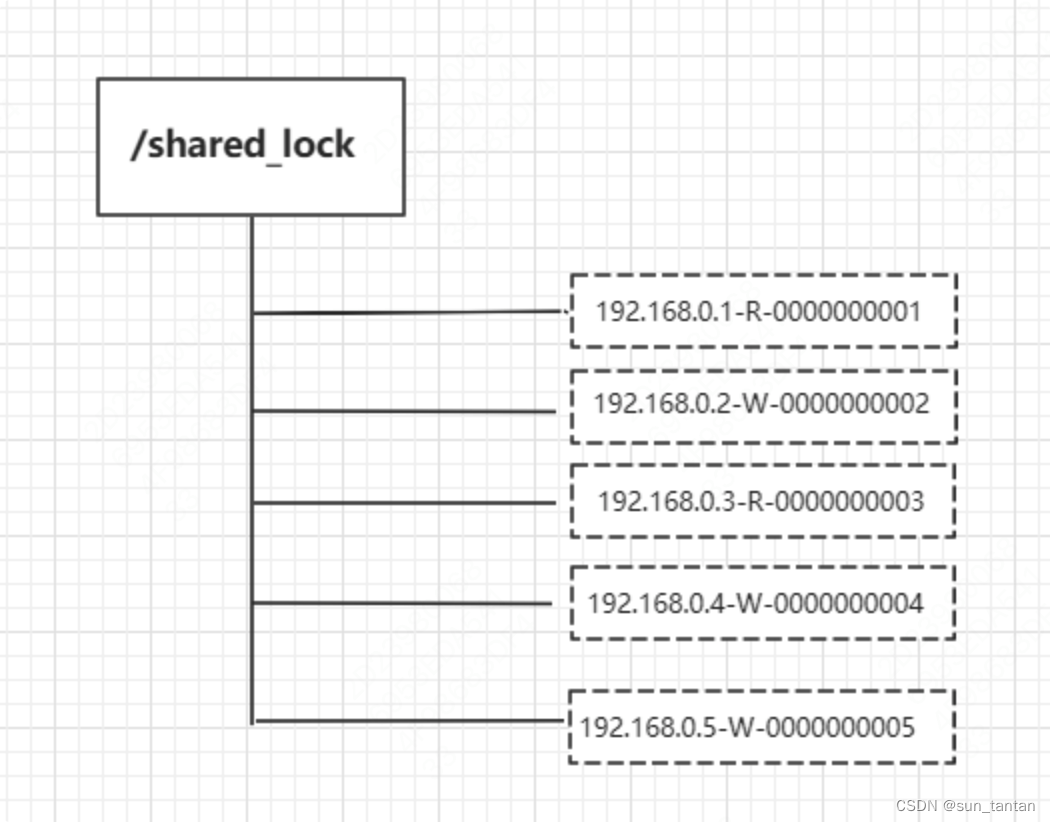
-
客户端调用 create 方法创建类似定义锁方式的 临时顺序节点
-
客户端调用 getChildren 接口来获取所有已创建的子节点列表,判断是否获得锁:
-
对于读请求:如果自己是序号最小的节点、或者所有比自己小的子节点都是读请求,表明已经成功获取共享锁;否则,监听比自己序号小的最后一个写请求节点
-
对于写请求,如果自己不是序号最小的子节点,那么就进入等待;否则,监听序号比自己序号小的节点
-
应用场景
ZooKeeper分布式锁(如InterProcessMutex),能有效的解决分布式锁问题,但是性能并不高。
因为每次在创建锁和释放锁的过程中,都要动态创建、销毁瞬时节点来实现锁功能。大家知道,ZK中创建和删除节点只能通过Leader服务器来执行,然后Leader服务器还需要将数据同不到所有的Follower机器上,这样频繁的网络通信,性能的短板是非常突出的。
在高性能,高并发的场景下,不建议使用ZooKeeper的分布式锁,可以使用Redis的分布式锁。而由于ZooKeeper的高可用特性,所以在并发量不是太高的场景,推荐使用ZooKeeper的分布式锁。
分布式队列
实现方式
定义队列节点:
/queue_fifo生产者:写入消息,即在队列节点下创建 持久性顺序节点
消费者:调用 getChildren 获取 /queue_fifo 下所有子节点
- 为空,调用 getChildren 进行子节点监控,消费者进入等待状态
- 不为空,则消费、删除节点
应用场景
不推荐使用。因为 ZooKeeper 有 1MB 的传输限制,实践中 ZNode 必须相对较小,而队列包含成千上万的消息,可能非常的大;
当某个 ZNode 很大的时候会很难清理,同时调用这个节点的 getChildren() 方法会失败;
当出现大量的包含成千上万的子节点的 ZNode 时,ZooKeeper 的性能会急剧下降;
ZooKeeper 的数据完全存放在内存中,如果有大量的队列消息会占用很多的内存空间。
相关文章:
zookeeper 理论合集
目录 系统背景 集群结构 多个节点之间的角色 节点的状态 为什么引入 Observer 存储结构 ZNode 节点结构 ZNode 创建类型 内存数据存储 数据持久化 zookeeper 的容量大小 数据同步 消息广播 崩溃恢复 如何保证顺序一致性 核心流程 Leader 选举流程 脑裂问题 …...
【pyinstaller 怎么打包python,打包后程序闪退 不打日志 找不到自建模块等问题的踩坑解决】
程序打包踩坑解决的所有问题 问题1 多个目录怎么打包 不管你包含多个层目录,引用多么复杂,只需要打包主程序所在文件即可,pyinstaller会自动寻找依赖包,如果报错自建模块找不到,参照问题3 pyinstaller main.py问题2…...
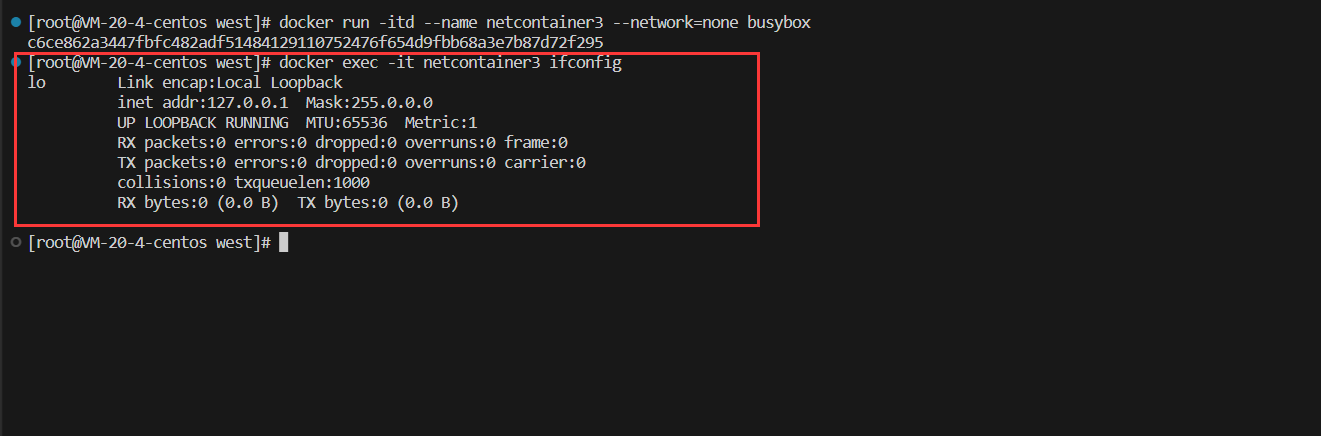
【Docker】网络
文章目录 Docker 网络基础Docker网络管理Docker网络架构CNMLibnetwork驱动 常见的网络类型 Docker 网络管理命令docker network createdocker network inspectdocker network connectdocker network disconnectdocker network prunedocker network rmdocker network ls docker …...

Linux :realpath 命令
以后可以直接用于查找相关文件 例: 输入:realpath .repo/manifests/rv1126_rv1109_linux_release.xml 输出:/home/sdk/work/rk/rv1126_rv1109/.repo/manifests/rv1126_rv1109_linux/rv1126_rv1109_linux_v3.0.2_20230406.xml根据输入的文件找到对应复制过来的型号,这个命令不…...

react17:生命周期函数
挂载时更新时 setState触发更新、父组件重新渲染时触发更新forceUpdate触发更新卸载时 react(v17.0.2)的生命周期图谱如下。 相较于16版本,17版本生命周期函数有如下变化: componentWillMount() componentWillUpdate() compone…...

腾讯内部单边拥塞算法BBR-TCPA一键脚本安装
TCPA简介 腾讯内部使用的TCPA,由腾讯TEG操作系统组研发,基于RHEL7.4源码,定制化的TCPA。团队介绍:腾讯TEG操作系统组, 2010年成立,专业的内核团队,维护研发腾讯内部linux操作系统tlinux, 保证百万级server高效稳定运行…...
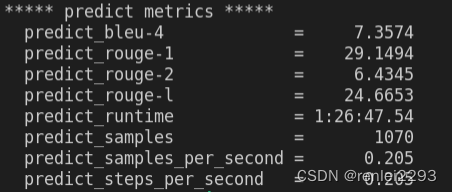
【LLM】chatglm-6B模型训练和推理
本篇文章记录下 chatglm-6B 训练和推理过程 环境:Ubuntu 20.04 1.13.0cu116 chatglm-6B 源代码仓库:链接 chatglm-6B 模型权重:链接 源代码及模型 clone 到本地 这里使用的是 THUDM 在 hugging face 开源的模型。 因为模型比较大ÿ…...

性能可靠it监控系统,性能监控软件的获得来源有哪些
性能可靠的IT监控系统是企业IT运维的重要保障之一。以下是一个性能可靠的IT监控系统应该具备的特点: 高可用性 高可用性是IT监控系统的一个重要特点,它可以保证系统在24小时不间断监控的同时,保证系统服务的可用性和稳定性。为了实现高可用性…...
 理解网络编程和套接字)
TCP/IP网络编程(一) 理解网络编程和套接字
文章目录 理解网络编程和套接字网络编程和套接字概要构建套接字编写 Hello World 服务器端构建请求连接套接字在Linux平台下运行 基于Linux的文件操作打开文件关闭文件将数据写入文件读取文件中的数据 理解网络编程和套接字 网络编程和套接字概要 网络编程就是编写程序使两台…...

Python 潮流周刊#18:Flask、Streamlit、Polars 的学习教程
你好,我是猫哥。这里每周分享优质的 Python、AI 及通用技术内容,大部分为英文。标题取自其中三则分享,不代表全部内容都是该主题,特此声明。 本周刊由 Python猫 出品,精心筛选国内外的 250 信息源,为你挑选…...

装备一台ubuntu
配置远程连接: ubuntu的root用户无法远程登入问题: openssh安装命令: sudo apt-get install openssh-server 安装完成通过以下命令查看SSH是否启动 ps -e | grep ssh 如果只有ssh-agent表示还没启动,需要: /etc/i…...
为了更好和大家交流,欢迎大家加我的微信账户
因为一些懂的都懂的原因,如果我的账户显示为 此时我无法通过站内信、留言或者任何方式和大家联系。 如果看到这样的内容,可以在此评论区留下你的微信账户,我看到后会添加你。为防止其他人冒充我,我的微信号以2206结尾。...

MS1826A HDMI 多功能视频处理器 HDMI4进1出画面分割芯片
基本介绍 MS1826A 是一款多功能视频处理器,包含 4 路独立 HDMI 音视频输入通道、1 路 HDMI 音视 频输出通道以及 1 路独立可配置为输入或者输出的 SPDIF、I2S 音频信号。支持 4 个独立的字库定 制型 OSD;可处理隔行和逐行视频或者图形输入信号࿱…...

最新文献怎么找|学术最新前沿文献哪里找
查找下载最新文献最好、最快、最省事的方法就是去收录该文献的官方数据库中下载。举例说明: 有位同学求助下载一篇2023年新文献,只有DOI号10.1038/s41586-023-06281-4,遇到这种情况可以在DOI号前加上http://doi.org/输入地址栏查询该文献的篇…...

ctfshow 红包题
前言: 最近一直在搞java很少刷题,看见ctfshow的活动赶紧来复现一波~ ctfshow 红包挑战7 <?php highlight_file(__FILE__); error_reporting(2); extract($_GET); ini_set($name,$value); system("ls ".filter($_GET[1])."" )…...
SpringBoot项目(jar)部署,启动脚本
需求 SpringBoot项目(jar)部署,需要先关闭原来启动的项目,再启动新的项目。直接输入命令,费时费力,还容易出错。所以,使用脚本启动。 脚本 脚本名:start.sh 此脚本需要放置在jar包…...

大数据(四)主流大数据技术
大数据(四)主流大数据技术 一、写在前面的话 To 那些被折磨打击的好女孩(好男孩): 有些事情我们无法选择,也无法逃避伤害。 但请你在任何时候都记住: 你可能在一些人面前,一文不值&a…...

【已解决】激活虚拟环境报错:此时不应有Anaconda3\envs\[envs]\Library\ssl\cacert.pem。
新建虚拟环境后,进入虚拟环境的时候出现这样的报错: 此时不应有Anaconda3 envs yolov5 Library ssl cacert.pem。 但是之前装的虚拟环境也还能再次激活,base环境也无任何问题,仅新装的虚拟环境无法激活。 查遍了百度谷歌ÿ…...
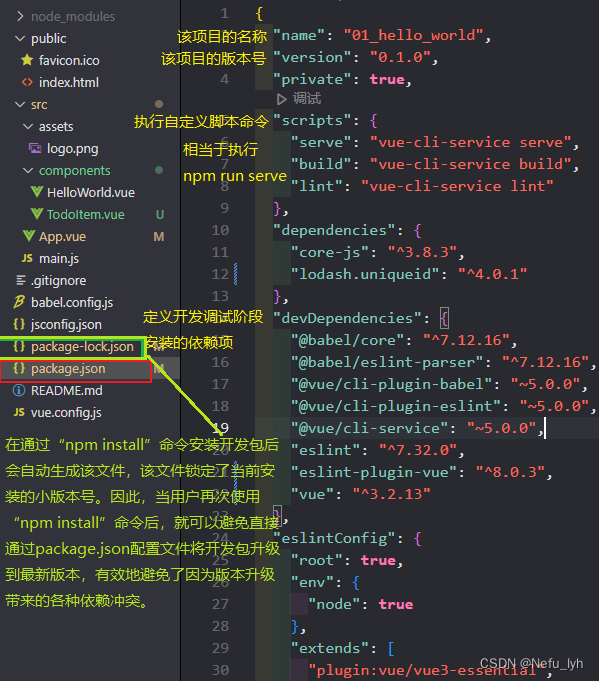
Vue安装过程的困惑解答——nodejs和vue关系、webpack、vue-cli、vue的项目结构
文章目录 1、为什么在使用vue前要下载nodejs?2、为什么安装nodejs后就能使用NPM包管理工具?3、为什么是V8引擎并且使用C实现?4、为什么会安装淘宝镜像?5、什么是webpack模板?6、什么是脚手架 vue-cli?6.1 安…...

PWA ~
vite 安装: pnpm i vite-plugin-pwa -Dvite.config import { VitePWA } from vite-plugin-pwa export default defineConfig({plugins: [VitePWA()] })env.d.ts /// <reference types"vite-plugin-pwa/client" />打包构建:registerSW…...

C++SFINAE技术详解
CSFINAE技术详解SFINAE(Substitution Failure Is Not An Error)是C模板元编程的核心技术,允许在模板实例化失败时不产生编译错误,而是尝试其他重载。SFINAE的基本原理是模板替换失败不是错误。#include #includetemplate typename…...
)
从零实现一个高性能 FTP 服务器(C++ / Linux)
目录一、搭建 TCP 服务器骨架服务器代码测试二、支持多客户端并发三、线程模型核心思路为什么使用 detach输出为什么会错乱四、函数重构重构后的结构五、FTP 协议基础控制连接数据连接六、命令解析行缓冲区命令解析为什么要转大写七、PASV 被动模式为什么需要数据连接ÿ…...

机器学习论文有效阅读:三层穿透法定位技术杠杆点
1. 这不是“读论文”,而是“拆解模型生长的土壤”你有没有过这种体验:打开一篇顶会论文,标题写着《Neural Architecture Search with Reinforcement Learning》,摘要读得热血沸腾,结果翻到Methodology部分,…...

白帽工程师的四大核心工具链:从资产测绘到修复验证
1. 这不是“黑客速成班”,而是真实白帽工程师的日常工具箱很多人看到“挖漏洞”三个字,第一反应是黑进系统、炫技式提权、深夜敲代码改数据库——这其实是影视作品和自媒体标题党联手塑造的幻觉。真实的网络安全一线工作中,90%以上的漏洞发现…...

免费图片去水印工具在线网站有哪些?2026年图片水印去除APP和软件推荐
在日常工作和生活中,我们经常会遇到需要去除图片水印的情况。无论是为了社交媒体分享、内容创作还是素材整理,找到一款高效的免费去水印工具都能节省不少时间。本文将为你详细介绍2026年最实用的免费图片去水印工具,包括在线网站、手机APP和电…...

详细讲解 Spring MVC 的 HandlerInterceptor 接口
目录 一、核心定位 二、接口完整定义 三、三个核心方法详解(执行顺序 作用) 1. preHandle () —— 【请求前置处理】 2. postHandle () —— 【请求后置处理】 3. afterCompletion () —— 【请求完成清理】 四、执行流程(生命周期&a…...

AI Agent与RPA的融合:智能自动化新范式
AI Agent与RPA的融合:智能自动化新范式 关键词:AI Agent、RPA、智能自动化、融合技术、自主决策、业务流程优化、人机协作 摘要:本文深入探讨了AI Agent与RPA(机器人流程自动化)的融合,揭示了这一技术组合如何开创智能自动化的新范式。我们将通过生动的类比和详细的技术解…...

Midjourney中画幅风格不生效?5个致命配置错误正在 silently 毁掉你的成片率
更多请点击: https://kaifayun.com 第一章:Midjourney中画幅风格失效的真相与底层机制 Midjourney 中的中画幅(Medium Format)风格常被用户以 --style medium-format 或关键词 medium format film 调用,但大量实测表…...

ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署
更多请点击: https://kaifayun.com 第一章:ElevenLabs陕西话语音落地实录:从零配置API到高保真秦腔语调还原,7步搞定方言TTS部署 环境准备与API密钥获取 首先注册ElevenLabs账号并进入 Profile → API Keys页面,生成…...

UVa 255 Correct Move
题目分析 这是一道关于国际象棋棋盘上王和后移动规则的模拟问题。题目描述了一个 888 \times 888 的棋盘,格子编号从 000 到 636363,编号方式为逐行排列(第 000 行:0∼70 \sim 70∼7,第 111 行:8∼158 \sim…...