【大数据】Flink 详解(六):源码篇 Ⅰ
Flink 详解(六):源码篇 Ⅰ
- 55、Flink 作业的提交流程?
- 56、Flink 作业提交分为几种方式?
- 57、Flink JobGraph 是在什么时候生成的?
- 58、那在 JobGraph 提交集群之前都经历哪些过程?
- 59、看你提到 PipeExecutor,它有哪些实现类?
- 60、Local 提交模式有啥特点,怎么实现的?
- 61、远程提交模式都有哪些?
- 62、Standalone 模式简单介绍一下?
- 63、yarn 集群提交方式介绍一下?
- 64、yarn - session 模式特点?
- 65、yarn - per - job 模式特点?
- 66、yarn - application 模式特点?
- 67、yarn - session 提交流程详细介绍一下?
- 68、yarn - per - job 提交流程详细介绍一下?
55、Flink 作业的提交流程?
Flink 的提交流程:
- 在
Flink Client中,通过反射启动jar中的main函数,生成 Flink StreamGraph 和 JobGraph,将 JobGraph 提交给 Flink 集群。 - Flink 集群收到 JobGraph(
JobManager收到)后,将 JobGraph 翻译成 ExecutionGraph,然后开始调度,启动成功之后开始消费数据。
总结来说:Flink 核心执行流程,对用户 API 的调用可以转为 StreamGraph → JobGraph → ExecutionGraph。
56、Flink 作业提交分为几种方式?
Flink 的作业提交分为两种方式:
- Local 方式:即本地提交模式,直接在 IDEA 运行代码。
- 远程提交方式:分为
standalone方式、yarn方式、K8s方式。其中,yarn方式又分为三种提交模式:yarn-per-job模式、yarn-session模式、yarn-application模式。
57、Flink JobGraph 是在什么时候生成的?
StreamGraph、JobGraph 全部是在 Flink Client 客户端生成的,即提交集群之前生成,原理图如下:

58、那在 JobGraph 提交集群之前都经历哪些过程?
- 用户通过启动 Flink 集群,使用命令行提交作业,运行
flink run -c WordCount xxx.jar。 - 运行命令行后,会通过
run脚本调用CliFrontend入口,CliFrontend会触发用户提交的jar文件中的main方法,然后交给PipelineExecuteor的execute方法,最终根据提交的模式选择触发一个具体的PipelineExecutor执行。 - 根据具体的
PipelineExecutor执行,将对用户的代码进行编译生成 StreamGraph,经过优化后生成 Jobgraph。
具体流程图如下:

59、看你提到 PipeExecutor,它有哪些实现类?
PipeExecutor 在 Flink 中被叫做 流水线执行器,它是一个接口,是 Flink Client 生成 JobGraph 之后,将作业提交给集群的重要环节。前面说过,作业提交到集群有好几种方式,最常用的是 yarn 方式,yarn 方式包含 3 3 3 种提交模式,主要使用 session 模式,per-job 模式。application 模式中 JobGraph 是在集群中生成。
所以 PipeExecutor 的实现类如下图所示:(在代码中按 CTRL+H 就会出来)

除了上述红框的两种模式外,在 IDEA 环境中运行 Flink MiniCluster 进行调试时,使用 LocalExecutor。
60、Local 提交模式有啥特点,怎么实现的?
Local 是在本地 IDEA 环境中运行的提交方式。不上集群。主要用于调试,原理图如下:

-
Flink 程序由
JobClient进行提交。 -
JobClient将作业提交给JobManager。 -
JobManager负责协调资源分配和作业执行。资源分配完成后,任务将提交给相应的TaskManager。 -
TaskManager启动一个线程开始执行,TaskManager会向JobManager报告状态更改,如开始执 行,正在进行或者已完成。 -
作业执行完成后,结果将发送回客户端。
源码分析:通过 Flink 1.12.2 1.12.2 1.12.2 源码进行分析的。
(1)创建获取对应的 StreamExecutionEnvironment 对象:LocalStreamEnvironment。
调用 StreamExecutionEnvironment 对象的 execute 方法。





(2)获取 StreamGraph。

(3)执行具体的 PipeLineExecutor 得到 localExecutorFactory。

(4) 获取 JobGraph。
根据 localExecutorFactory 的实现类 LocalExecutor 生成 JobGraph。

上面这部分全部是在 Flink Client 生成的。由于是使用 Local 模式提交,所以接下来将创建 MiniCluster 集群,由 miniCluster.submitJob 指定要提交的 jobGraph。
(5)实例化 MiniCluster 集群。

(6)返回 JobClient 客户端。
在上面执行 miniCluster.submitJob 将 JobGraph 提交到本地集群后,会返回一个 JobClient 客户端,该 JobClient 包含了应用的一些详细信息,包括 JobID、应用的状态等等。最后返回到代码执行的上一层,对应类为 StreamExecutionEnvironment。

以上就是 Local 模式的源码执行过程。
61、远程提交模式都有哪些?
远程提交方式:分为 Standalone 方式、Yarn 方式、K8s 方式。
- Standalone:包含
session模式。 - Yarn 方式 分为三种提交模式:
yarn-per-job模式、yarn-Session模式、yarn-application模式。 - K8s 方式:包含
session模式。
62、Standalone 模式简单介绍一下?
Standalone 模式为 Flink 集群的 单机版提交方式,只使用一个节点进行提交,常用 Session 模式。

提交命令如下:
bin/flink run org.apache.flink.WordCount xxx.jar
Client客户端提交任务给JobManager。JobManager负责申请任务运行所需要的资源并管理任务和资源。JobManager分发任务给TaskManager执行。TaskManager定期向JobManager汇报状态。
63、yarn 集群提交方式介绍一下?
通过 yarn 集群提交分为 3 3 3 种提交方式:
session模式per-job模式application模式
64、yarn - session 模式特点?
提交命令如下:
./bin/flink run -t yarn-session \
-Dyarn.application.id=application_XXXX_YY xxx.jar
yarn-session 模式:所有作业共享集群资源,隔离性差,JM 负载瓶颈,main 方法在客户端执行。适合执行时间短,频繁执行的短任务,集群中的所有作业只有一个 JobManager,另外,Job 被随机分配给 TaskManager。
特点:session-cluster 模式需要先启动集群,然后再提交作业,接着会向 Yarn 申请一块空间后,资源永远保持不变。如果资源满了,下一个作业就无法提交,只能等到 Yarn 中的其中一个作业执行完成后,释放了资源,下个作业才会正常提交。所有作业共享 Dispatcher 和 ResourceManager,共享资源,适合规模小执行时间短的作业。

65、yarn - per - job 模式特点?
提交命令:
./bin/flink run -t yarn-per-job --detached xxx.jar
yarn-per-job 模式:每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在客户端执行。在 per-job 模式下,每个 Job 都有一个 JobManager,每个 TaskManager 只有单个 Job。
特点:一个任务会对应一个 Job,每提交一个作业会根据自身的情况,都会单独向 Yarn 申请资源,直到作业执行完成,一个作业的失败与否并不会影响下一个作业的正常提交和运行。独享 Dispatcher 和 ResourceManager,按需接受资源申请。适合规模大长时间运行的作业。

66、yarn - application 模式特点?
提交命令如下:
./bin/flink run-application -t yarn-application xxx.jar
yarn-application 模式:每个作业单独启动集群,隔离性好,JM 负载均衡,main 方法在 JobManager 上执行。
在 yarn-per-job 和 yarn-session 模式下,客户端都需要执行以下三步,即:
- 获取作业所需的依赖项;
- 通过执行环境分析并取得逻辑计划,即
StreamGraph→JobGraph; - 将依赖项和 JobGraph 上传到集群中。

只有在这些都完成之后,才会通过 env.execute() 方法触发 Flink 运行时真正地开始执行作业。如果所有用户都在同一个客户端上提交作业,较大的依赖会消耗更多的带宽,而较复杂的作业逻辑翻译成 JobGraph 也需要吃掉更多的 CPU 和内存,客户端的资源反而会成为瓶颈。
为了解决它,社区在传统部署模式的基础上实现了 Application 模式。原本需要客户端做的三件事被转移到了 JobManager 里,也就是说 main() 方法在集群中执行(入口点位于 ApplicationClusterEntryPoint),客户端只需要负责发起部署请求了。

综上所述,Flink 社区比较推荐使用 yarn-per-job 或者 yarn-application 模式进行提交应用。
67、yarn - session 提交流程详细介绍一下?
提交流程图如下:

1、启动集群
Flink Client向Yarn ResourceManager提交任务信息。Flink Client将应用配置(Flink-conf.yaml、logback.xml、log4j.properties)和相关文件(Flink Jar、配置类文件、用户 Jar 文件、JobGraph 对象等)上传至分布式存储 HDFS 中。Flink Client向Yarn ResourceManager提交任务信息。
- Yarn 启动 Flink 集群,做 2 2 2 步操作:
- 通过
Yarn Client向Yarn ResourceManager提交 Flink 创建集群的申请,Yarn ResourceManager分配 Container 资源,并通知对应的NodeManager上启动一个ApplicationMaster(每提交一个 Flink Job 就会启动一个ApplicationMaster),ApplicationMaster会包含当前要启动的JobManager和 Flink 自己内部要使用的ResourceManager。 - 在
JobManager进程中运行YarnSessionClusterEntryPoint作为集群启动的入口。初始化Dispatcher,Flink 自己内部要使用的ResourceManager,启动相关 RPC 服务,等待Flink Client通过 Rest 接口提交 JobGraph。
- 通过
2、作业提交
-
Flink Client通过 Rest 向Dispatcher提交编译好的 JobGraph。Dispatcher是 Rest 接口,不负责实际的调度、指定工作。 -
Dispatcher收到 JobGraph 后,为作业创建一个JobMaster,将工作交给JobMaster,JobMaster负责作业调度,管理作业和 Task 的生命周期,构建 ExecutionGraph(JobGraph 的并行化版本,调度层最核心的数据结构)。
以上两步执行完后,作业进入调度执行阶段。
3、作业调度执行
-
JobMaster向ResourceManager申请资源,开始调度 ExecutionGraph。 -
ResourceManager将资源请求加入等待队列,通过心跳向YarnResourceManager申请新的 Container 来启动TaskManager进程。 -
YarnResourceManager启动,然后从 HDFS 加载 Jar 文件等所需相关资源,在容器中启动TaskManager,TaskManager启动TaskExecutor。 -
TaskManager启动后,向ResourceManager注册,并把自己的 Slot 资源情况汇报给ResourceManager。 -
ResourceManager从等待队列取出 Slot 请求,向TaskManager确认资源可用情况,并告知TaskManager将 Slot 分配给哪个JobMaster。 -
TaskManager向JobMaster回复自己的一个 Slot 属于你这个任务,JobMaser会将 Slot 缓存到 SlotPool。 -
JobMaster调度 Task 到TaskMnager的 Slot 上执行。
68、yarn - per - job 提交流程详细介绍一下?
提交命令如下:
./bin/flink run -t yarn-per-job --detached xxx.jar
提交流程图如下所示:

1、启动集群
Flink Client向Yarn ResourceManager提交任务信息。Flink Client将应用配置(Flink-conf.yaml、logback.xml、log4j.properties)和相关文件(Flink Jar、配置类文件、用户 Jar 文件、JobGraph 对象等)上传至分布式存储 HDFS 中。Flink Client向Yarn ResourceManager提交任务信息。
- Yarn 启动 Flink 集群,做 2 2 2 步操作。
- 通过
Yarn Client向Yarn ResourceManager提交 Flink 创建集群的申请,Yarn ResourceManager分配 Container 资源,并通知对应的NodeManager上启动一个ApplicationMaster(每提交一个 Flink Job 就会启动一个ApplicationMaster),ApplicationMaster会包含当前要启动的JobManager和 Flink 自己内部要使用的ResourceManager。 - 在
JobManager进程中运行YarnJobClusterEntryPoint作为集群启动的入口。初始化Dispatcher,Flink 自己内部要使用的ResourceManager,启动相关 RPC 服务,等待Flink Client通过 Rest 接口提交 JobGraph。
- 通过
2、作业提交
ApplicationMaster启动Dispatcher,Dispatcher启动ResourceManager和JobMaster(该步和 Session 不同,JobMaster是由Dispatcher拉起,而不是 Client 传过来的)。JobMaster负责作业调度,管理作业和 Task 的生命周期,构建 ExecutionGraph(JobGraph 的并行化版本,调度层最核心的数据结构)。
以上两步执行完后,作业进入调度执行阶段。
3、作业调度执行
-
JobMaster向ResourceManager申请 Slot 资源,开始调度 ExecutionGraph。 -
ResourceManager将资源请求加入等待队列,通过心跳向YarnResourceManager申请新的 Container 来启动TaskManager进程。 -
YarnResourceManager启动,然后从 HDFS 加载 Jar 文件等所需相关资源,在容器中启动TaskManager。 -
TaskManager在内部启动TaskExecutor。 -
TaskManager启动后,向ResourceManager注册,并把自己的 Slot 资源情况汇报给ResourceManager。 -
ResourceManager从等待队列取出 Slot 请求,向TaskManager确认资源可用情况,并告知TaskManager将 Slot 分配给哪个JobMaster。 -
TaskManager向JobMaster回复自己的一个 Slot 属于你这个任务,JobMaser会将 Slot 缓存到 SlotPool。 -
JobMaster调度 Task 到TaskMnager的 Slot 上执行。
相关文章:
【大数据】Flink 详解(六):源码篇 Ⅰ
Flink 详解(六):源码篇 Ⅰ 55、Flink 作业的提交流程?56、Flink 作业提交分为几种方式?57、Flink JobGraph 是在什么时候生成的?58、那在 JobGraph 提交集群之前都经历哪些过程?59、看你提到 Pi…...
ShardingSphere——弹性伸缩原理
摘要 支持自定义分片算法,减少数据伸缩及迁移时的业务影响,提供一站式的通用弹性伸缩解决方案,是 Apache ShardingSphere 弹性伸缩的主要设计目标。对于使用单数据库运行的系统来说,如何安全简单地将数据迁移至水平分片的数据库上…...

Linux项目自动化构建工具-make/Makefile
一、什么是make和makefile make是一条指令 Makefile是当前目录下的一个文件 二、makefile文件编写 依赖关系::前为要目标文件,后为其依赖的文件 依赖方法:用依赖文件生成目标文件的具体指令 简便写法: $:表示目标文件 $^:表示…...

Python爬虫实战:自动化数据采集与分析
在大数据时代,数据采集与分析已经成为了许多行业的核心竞争力。Python作为一门广泛应用的编程语言,拥有丰富的爬虫库,使得我们能够轻松实现自动化数据采集与分析。本文将通过一个简单的示例,带您了解如何使用Python进行爬虫实战。…...
视频智能分析平台EasyCVR安防视频汇聚平台助力森林公园防火安全的应用方案
一、研发背景 随着经济的发展和人们生活水平的提高,越来越多的人喜欢在周末去周边的森林公园旅游,享受大自然的美景,并进行野炊和烧烤等娱乐活动。然而,近年来由于烟蒂和烧烤碳渣等人为因素,森林公园火灾频繁发生。森…...

跨境做独立站,如何低成本引流?
大家都知道,海外的消费习惯与国内不同,独立站一向是海外消费者的最喜欢的购物方式之一,这也吸引了许多跨境商家开设独立站。 独立站不同于其他的第三方平台,其他平台可以靠平台自身流量来获得转化,而独立站本身没有流…...
leetcode55.跳跃游戏 【贪心】
题目: 给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。 示例…...
探秘C语言扫雷游戏实现技巧
本篇博客会讲解,如何使用C语言实现扫雷小游戏。 0.思路及准备工作 使用2个二维数组mine和show,分别来存储雷的位置信息和排查出来的雷的信息,前者隐藏,后者展示给玩家。假设盘面大小是99,这2个二维数组都要开大一圈…...

Leetcode112. 路径总和
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 t…...

生成12位短id,自增且不连续,永不重复,不依赖数据库
基本思路: 设计模式:单例模式 是否加锁:是 synchronized 获取最后一次生成的时间戳值T0 限定初始时间为2023-08-01 00:00:00,获取当前时间时间戳T1,T1与初始时间的毫秒差值T2,转为16进制,转为字符串为r1,获取该字符串的长度L1…...

Zip压缩文件夹php打包函数代码
Zip压缩文件夹php打包函数代码,Zip相关函数是PHP的扩展功能,此函数可以直接复制使用。 以下是代码: <?php # 将文件夹的文件压缩到文件里 class Zip {/*** 将目标文件夹下的内容压缩到zip中(zip包含文件夹目录)* @param $sourcePath *文件夹路径 例: /home/test* @p…...

RISC-V交叉工具链riscv-gnu-toolchain编译
文章目录 1、下载2、编译1. 依赖安装2. 编译 3、运行 1、下载 $ sudo apt-get install git wget build-essential $ git clone https://github.com/riscv-collab/riscv-gnu-toolchain $ git checkout 2023.06.02注意上面 clone 的仓库,我们称其为构建脚本仓库&…...

我能“C“——指针进阶(上)
目录 指针的概念 1. 字符指针 2. 指针数组 3. 数组指针 3.1 数组指针的定义 3.2 &数组名VS数组名 3.3 数组指针的使用 4. 数组参数、指针参数 4.1 一维数组传参 4.2 二维数组传参 4.3 一级指针传参 4.4 二级指针传参 5. 函数指针 阅读两段有趣的代码&…...

SQLServer2008数据库还原失败 恢复失败
源地址:http://www.taodudu.cc/news/show-1609349.html?actiononClick 还原数据库问题解决方案 在还原数据库“Dsideal_school_db”时,有时会遇见上图中的问题“因为数据库正在使用,所以无法获得对数据库的独占访问权”,此时我们…...

【微服务部署】04-ForwardedHeaders
文章目录 1. ForwardedHeaders1.1 场景1.2 关键的HTTP头1.3 核心处理要点 1. ForwardedHeaders 1.1 场景 获取用户IP获取用户请求的原始URL 1.2 关键的HTTP头 X-Forwarded-ForX-Forwarded-ProtoX-Forwarded-Host 1.3 核心处理要点 设置PathBase设置ForwardedHeaders中间件…...
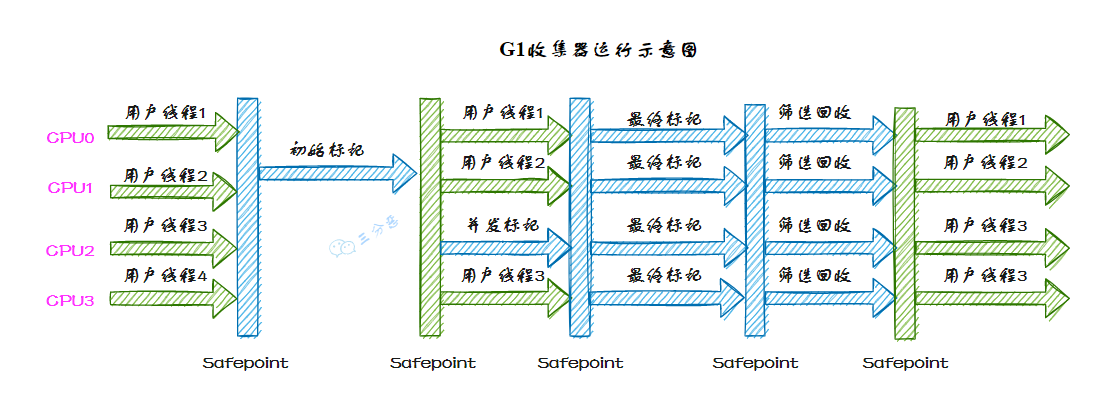
JVM 垃圾收集器
重点:CMS,G1,ZGC 主要垃圾收集器如下,图中标出了它们的工作区域、垃圾收集算法,以及配合关系。 Serial 收集器 Serial 收集器是最基础、历史最悠久的收集器。 如同它的名字(串行),…...

CSS 样式使用link和@import有什么区别
在页面导入样式时,使用link和import有以下区别: 位置:link标签可以放置在HTML文档的head或body中的任何位置,而import规则必须出现在CSS样式表的顶部。 加载方式:当浏览器解析到link标签时,会立即请求并加…...

LeetCode-2511-最多可以摧毁的敌人城堡数目
题目链接 代码实现: class Solution {/** 找 1 -> -1 的时候,经过0的最大个数* 解题思路:双指针*/public int captureForts(int[] forts) {int len forts.length;if(len1){return 0;}int max Integer.MIN_VALUE;boolean flag false;boo…...
iOS开发Swift-2-图片视图、App图标-赏月App
1.创建新项目 点击File - New - Project。 选择Single View App,点击Next。 填写文件信息,点击Next。 选择文件位置,点击Create。 修改App显示名称为 “赏月”。 2.设置背景色 选择Main,点击View界面,选择右边属性&…...

node18 vue2启动报错 error:0308010C:digital envelope routines::unsupported
出现原因 貌似是因为是因为 node 17版本开始发布的OpenSSL3.0, 而OpenSSL3.0对允许算法和密钥大小增加了严格的限制,可能会对生态系统造成一些影响。 解决方法 第一种方法降低node版本 降低到17以下即可 ,如项目不能降低版本 看后面的解决方式 第二…...

MulimgViewer:高效多图像浏览与对比工具
MulimgViewer:高效多图像浏览与对比工具 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. 项目地址: https://gitcode.com…...

X光安检目标识别分割数据集lableme格式2000张5类别
数据集格式:labelme格式(不包含mask文件,仅仅包含jpg图片和对应的json文件)图片数量(jpg文件个数):2000标注数量(json文件个数):2000标注类别数:5标注类别名称:["Electronic Items","Laptop",&quo…...

3分钟搞定百度网盘提取码:新手也能快速上手的终极解决方案
3分钟搞定百度网盘提取码:新手也能快速上手的终极解决方案 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 你是否经常遇到这样的烦恼:朋友分享的百度网盘链接明明就在眼前,却因为缺少那个关…...

安捷伦E8257D/E8267D信号源不开机、输出不正常故障排查
安捷伦E8257D/E8267D信号源作为射频微波测试领域的常用设备,广泛应用于通信、半导体等行业,长期高负荷运行后,不开机、输出不正常等故障十分常见,给测试工作带来诸多困扰。常见故障一:安捷伦E8257D/E8267D不开机不开机…...

3步魔法公式:用novideo_srgb为NVIDIA显卡开启色彩真实之门
3步魔法公式:用novideo_srgb为NVIDIA显卡开启色彩真实之门 【免费下载链接】novideo_srgb Calibrate monitors to sRGB or other color spaces on NVIDIA GPUs, based on EDID data or ICC profiles 项目地址: https://gitcode.com/gh_mirrors/no/novideo_srgb …...

Hitboxer SOCD Cleaner:键盘输入仲裁系统的底层实现与技术架构分析
Hitboxer SOCD Cleaner:键盘输入仲裁系统的底层实现与技术架构分析 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在竞技游戏领域,键盘输入精度直接影响玩家操作表现。传统键盘在处理同…...

5分钟快速上手Mermaid Live Editor:免费在线图表编辑器完全指南
5分钟快速上手Mermaid Live Editor:免费在线图表编辑器完全指南 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-li…...

传奇3手游网站下载 元素搭配攻略 新手快速上手复古服
官方出版资质:传奇3光通版手游由传奇3G原班人马打造,出版单位华东师范大学电子音像出版社有限公司,审批文号新广出审〔2016〕2183号,出版物号ISBN978-7-7979-0843-6,运营主体安徽游昕网络科技有限公司,官网…...

RX65N嵌入式开发实战:从硬件设计到外设驱动与调试
1. 项目概述:为什么选择RX65N作为嵌入式开发的起点?在嵌入式开发领域,选择一个合适的微控制器(MCU)作为学习和项目实践的起点至关重要。它既要功能足够强大以覆盖主流应用场景,又要有完善的生态支持&#x…...

强化学习回报归一化:ARN方法原理与SFC分区实践
1. 强化学习中的回报归一化:理论与实现在深度强化学习(DRL)的实际应用中,训练稳定性一直是困扰研究者的核心难题。特别是在处理服务功能链(SFC)分区等复杂网络编排任务时,由于任务周期长、状态空…...