【C++入门】命名空间、缺省参数、函数重载、引用、内联函数

👻内容专栏: C/C++编程
🐨本文概括: C++入门学习必备语法
🐼本文作者: 阿四啊
🐸发布时间:2023.9.3
前言
C++是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式
等。熟悉C语言之后,对C++学习有一定的帮助,本章节主要目标:
- 补充C语言语法的不足,以及C++是如何对C语言设计不合理的地方进行优化的,比如:作用
域方面、IO方面、函数方面、指针方面、宏方面等。- 为后续类和对象学习打基础
C++关键字(C++98)
C++总计63个关键字,C语言32个关键字
ps:这里仅列出C++的关键字,混个眼熟就行,这里不作细致讲解,后面每每用到会做讲解。
| asm | do | if | return | try | continue |
|---|---|---|---|---|---|
| auto | double | inline | short | typedef | for |
| bool | dynamic_cast | int | signed | typeid | public |
| break | else | long | sizeof | typename | throw |
| case | enum | mutable | static | union | wchar_t |
| catch | explicit | namespace | static_cast | unsigned | default |
| char | export | new | struct | using | friend |
| class | extern | operator | switch | virtual | register |
| const | false | private | template | void | true |
| const_cast | float | protected | this | volatile | while |
| delete | goto | reinterpret_cast |
命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
#include <stdio.h>
#include <stdlib.h>int rand;
int main()
{printf("%d", rand);return 0;
}
编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”

在C语言中,我们会写出这样的代码,我们想命名一个与stdlib库中函数一样的名字rand, 但是C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决。
命名空间的定义
- 1.定义
定义命名空间,需要使用到
namespace关键字,后面跟命名空间的名字,然后接一对{ }即可,{ }中即为命名空间的成员。
//Asi是命名空间的名字
//命名空间定义
namespace Asi
{// 命名空间中可以定义变量/函数/自定义类型int rand = 10;int Add(int a, int b){return a + b;}struct Node{struct Node* next;int val;};
}
- 2.命名空间的嵌套
namespace Asi
{// 命名空间中可以定义变量/函数/自定义类型int rand = 10;int Add(int a, int b){return a + b;}struct Node{struct Node* next;int val;};namespace _Asi{// 命名空间中可以定义变量/函数/自定义类型int rand = 20;int Add(int a, int b){return a + b;}struct Node{struct Node* next;int val;};}
}int main()
{printf("%d\n", Asi::rand);printf("%d\n", Asi::_Asi::rand);
}
打印结果:
1020
命名空间的使用
- 1.加命名空间名称及作用域限定符
namespace Asi
{// 命名空间中可以定义变量/函数/自定义类型int i, j;int rand = 10;int Add(int a, int b){return a + b;}struct Node{struct Node* next;int val;};
}
int main()
{//错误写法//printf("%d\n",i);//error:“i”:未声明的标识符//printf("%d\n",Add(0, 1));// “Add”: 找不到标识符 编译器默认会到全局作用域中去找//Asi::struct Node node;//正确写法printf("%p\n",Asi::rand); // “::”符号为作用域限定符printf("%d\n",Asi::Add(0, 1));struct Asi::Node node;return 0;
}
🤓:命名空间使用的其他两种写法
- 2.展开命名空间(全部授权)
- 使用
using namespace+命名空间名称 引入
- 使用
//展开命名空间
using namespce Asi;
int main()
{printf("%d\n", N::i);printf("%d\n", j);Add(10, 20);return 0;
}
⚠️注意:展开命名空间是一件非常有风险的做法,观察以下代码,发现再去编译这段代码,编译报错:“rand”:不明确的符号
因为编译器不知道这个rand是命名空间里面的,还是库函数里面的。
//展开命名空间
using namespce Asi;
int main()
{printf("%p\n",rand);printf("%d\n", i);printf("%d\n", j);Add(10, 20);return 0;
}
😜针对这种情况,我们可以使用第三种用法。
- 3.展开某一个变量/函数/自定义类型(部分授权)
- 使用
using+ 命名空间中某个成员 引入
- 使用
using Asi::Add;
using Asi::i;
int main()
{printf("%p\n", rand);printf("%d\n", Add(1, 2));printf("%d\n", i);return 0;
}
C++输入与输出
using namespace std是干嘛的?- 以下我们这一串代码我们会在C++中常用,那么
std是什么?std其实是C++标准库的命名空间,也就是说C++标准库中所有用到的东西都会放到std当中。 - 那么有同学会问那头文件
#include <iostream>有何用处呢?头文件其实被封装到std命名空间里面,引用头文件会将头文件中的内容展开到std命名空间中,注意,这里说的意思是头文件的展开,是将头文件中的内容拷贝到std命名空间。 命名空间的展开就是将#include <iostream>中的所有内容进行授权。使用std和endl,编译器就会到std命名空间当中去找,所以如果没有写using namespace std,编译器就会报出“cout”“endl”:未声明的标识符
- 以下我们这一串代码我们会在C++中常用,那么
#include <iostream>
using namespace std;
int main()
{cout << "hello world" << endl;return 0;
}
ps:
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含
< iostream >头文件以及按命名空间使用方法使用std。- cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含
<iostream >头文件中。- <<是流插入运算符,>>是流提取运算符。
- 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。
- 实际上cout和cin分别是ostream和istream类型的对象,>>和<<也涉及运算符重载等知识,这些知识我们我们后续才会学习,所以我们这里只是简单学习他们的使用。后面我们还有一个章节更深入的学习IO流用法及原理。
⚠️注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持
<iostream.h>格式,后续编译器已不支持,因此推荐使用<iostream> + std的方式。
#include <iostream>
using namespace std;
int main()
{int a;double b;char c;// 可以自动识别变量的类型cin>>a;cin>>b>>c;cout<<a<<endl;cout<<b<<" "<<c<<endl;return 0;
}
// ps:关于cout和cin还有很多更复杂的用法,比如控制浮点数输出精度,控制整形输出进制格式等等。
//因为C++兼容C语言的用法,指定输出格式时可以暂时用scanf和printf的用法。
缺省参数
缺省参数概念
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
void func(int a = 10)
{cout << a << endl;
}
int main()
{func();//没有传参,使用缺省参数func(20);//给定参数,使用指定的参数return 0;
}
打印:
10
20
缺省参数分类
- 全缺省参数
void Func(int a = 10, int b = 20, int c = 30)
{cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;
}
- 半缺省参数
void Func(int a, int b = 10, int c = 20)
{cout<<"a = "<<a<<endl;cout<<"b = "<<b<<endl;cout<<"c = "<<c<<endl;
}
⚠️注意:
1. 半缺省参数必须从右往左依次来给定,不能间隔给定;
2. 缺省参数不能在函数声明和定义中同时出现,只用在声明当中给定,定义不给定。
3. 缺省值必须是常量或者全局变量
4. C语言不支持(编译器不支持)
函数重载
我们当时在学C语言的时候,对于
int类型,我们需要写一个Swapi函数,对于double类型,我们需要写一个Swapd函数,但是在C++中,有一个同名函数的概念,对于所有类型的交换函数,我们可以只用写一个Swap重载函数就行。
函数重载概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 参数类型 或 参数类型的顺序)不同,常用来处理实现功能类似数据类型不同的问题。
#include<iostream>
using namespace std;
// 1、参数类型不同
int Add(int left, int right)
{cout << "int Add(int left, int right)" << endl;return left + right;
}
double Add(double left, double right)
{cout << "double Add(double left, double right)" << endl;return left + right;
}
// 2、参数个数不同
void fun()
{cout << "fun()" << endl;
}
void fun(int a)
{cout << "fun(int a)" << endl;
}
// 3、参数类型顺序不同
void fun(int a, char b)
{cout << "fun(int a,char b)" << endl;
}
void fun(char b, int a)
{cout << "fun(char b, int a)" << endl;
}
int main()
{Add(10, 20);Add(10.1, 20.2);fun();fun(10);fun(10, 'a');fun('a', 10);return 0;
}
那么函数重载是怎么实现的呢?
C++支持函数重载的原理——名字修饰(name Mangling)
🤔为什么C++支持重载,而C语言不支持重载?
这其实与编译器的编译有关,让我们回顾一下C语言时期学习的编译链接相关知识(对这个概念熟悉的同学,可以直接跳到符号表):
预处理->编译->汇编->链接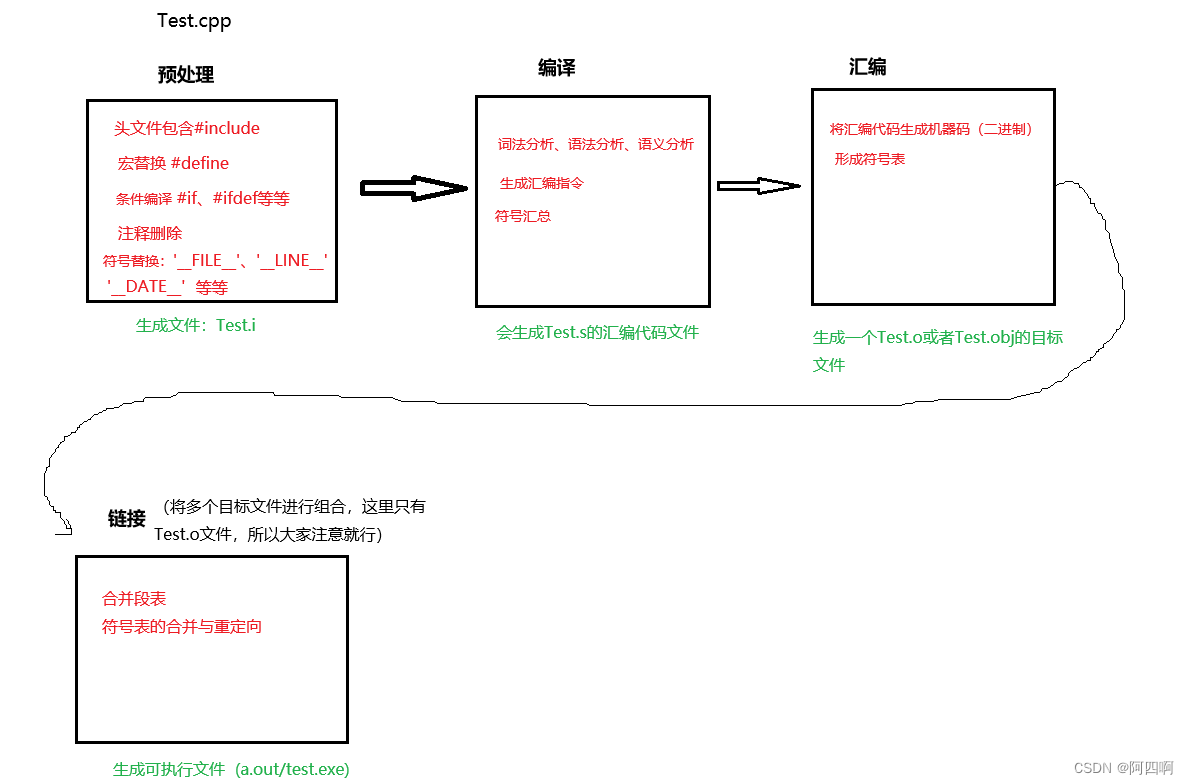
下面,我们可以在gcc平台,用几条命令回顾一下程序编译的几个阶段,我们在gcc环境下简单写一份.c文件:
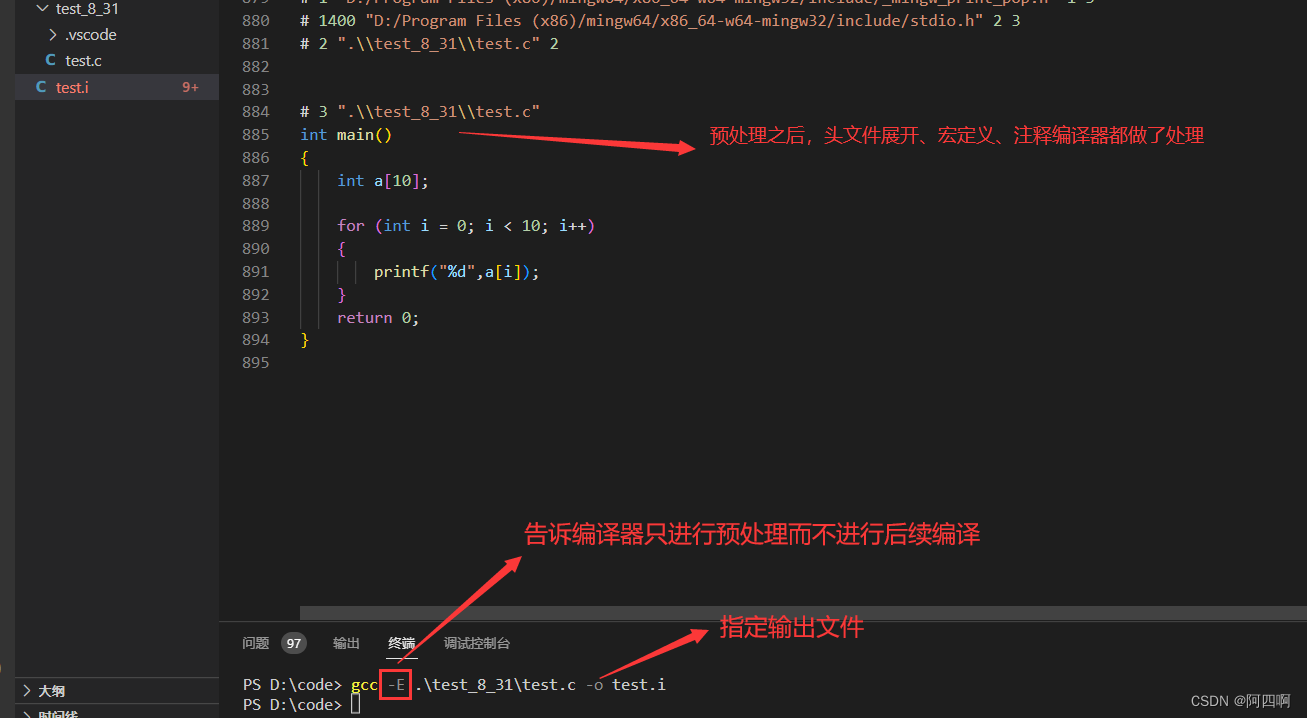
1.预处理 选项: gcc -E test.c -o test.i
预处理完成之后就停下来,预处理之后产生的结果都放在test.i文件中。
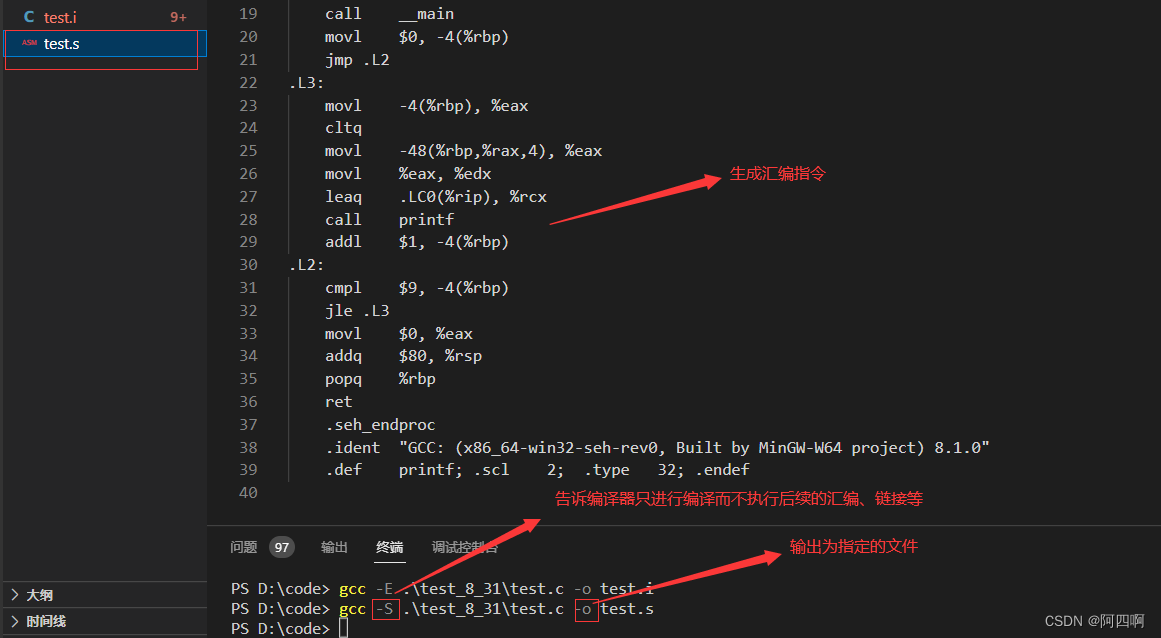
2.编译 选项: gcc -S test.c
编译完成之后就停下来,结果保存在test.s中
3.汇编 选项:gcc -c test.c
汇编完成之后就停下来,结果保存在test.o中
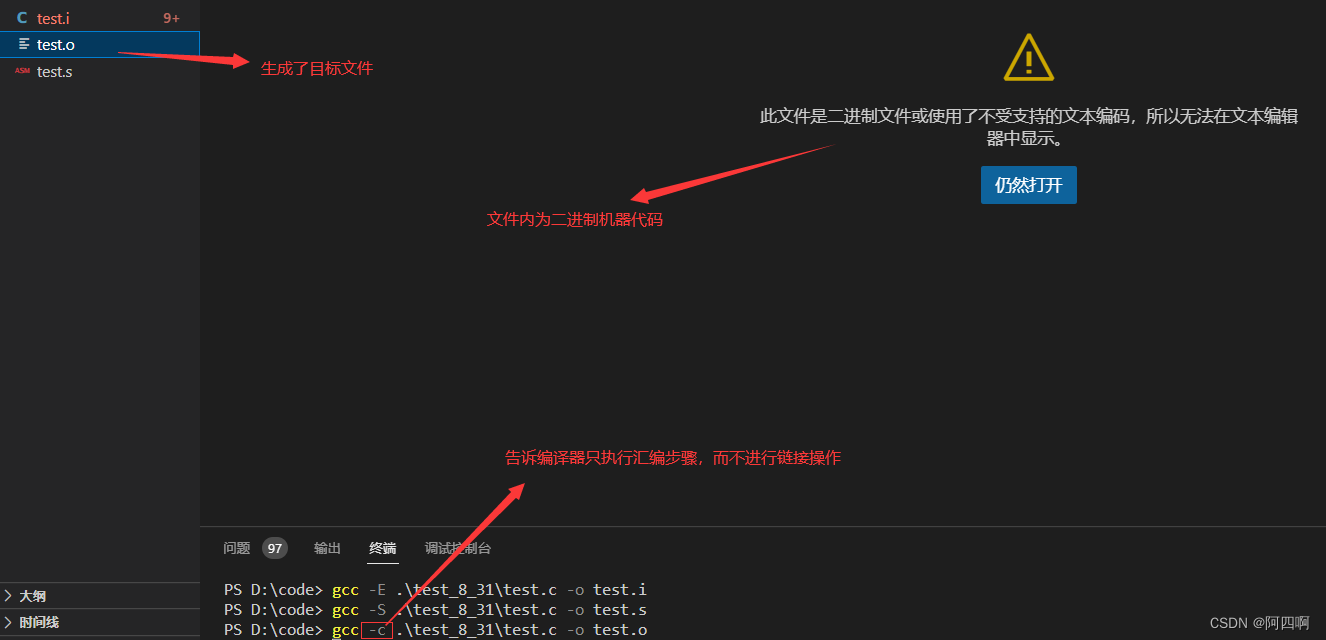
符号表
好了,程序编译大概分为这么几个阶段,下面着重理解一下符号表的概念,什么是符号表?
符号表内包含了变量、函数、类、结构体等等标识符,记录了各种变量、函数的名字与其地址一一映射的关系!
在C语言中,编译器其实就是直接以你自己写的函数名本身充当符号表中的函数名,所以在C语言中不支持函数重载
那么C++是如何支持函数重载的呢? 这里每个编译器都有自己的函数名修饰规则
函数名修饰规则
由于Windows下vs的修饰规则过于复杂,而Linux下g++的修饰规则简单易懂,下面我们先在Linux环境下进行演示。
- Linux环境下函数名修饰规则
- 通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成:
_Z + 函数长度 + 函数名 + 类型首字母 objdump -S 文件名会对给定的目标文件或可执行文件进行反汇编,并显示汇编代码以及与源代码对应的内容。- 采用C语言编译器编译后的结果:
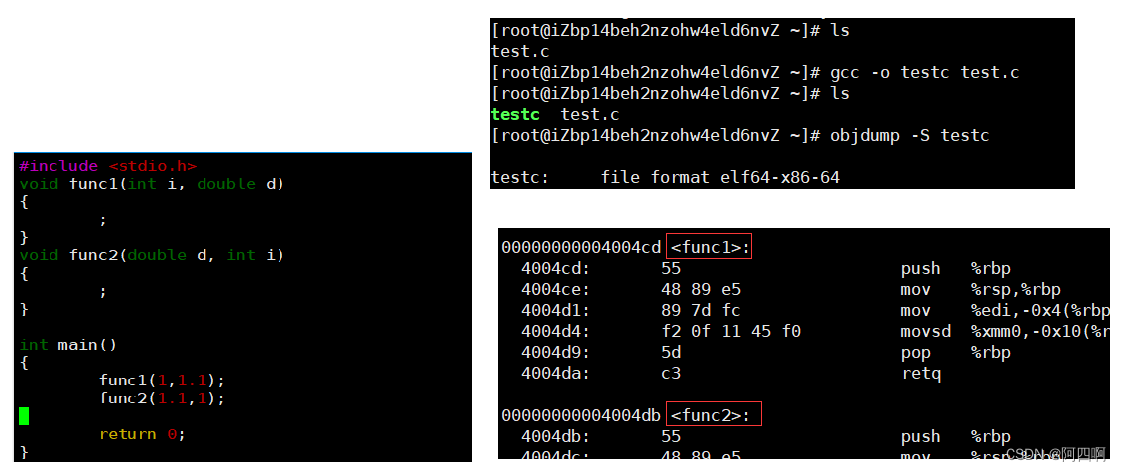
结论:在linux下,采用gcc编译完成后,函数名字的修饰没有发生改变。 - 采用C++编译器编译后结果
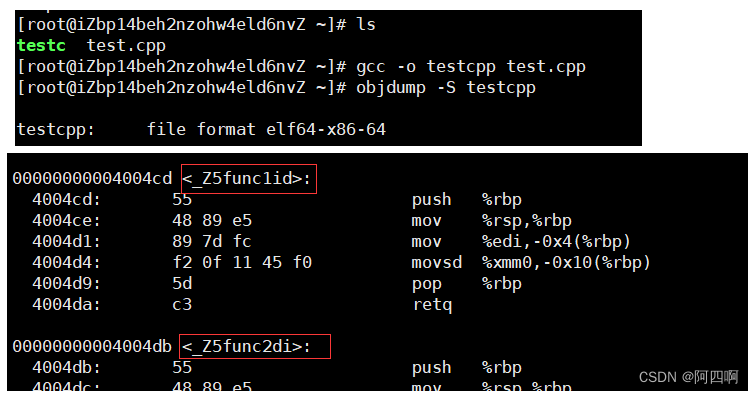

所以在C++中,类型不同,因参数个数、参数类型的顺序、参数类型本身的不同就会构成函数自身的函数名字,所以汇编指令call (调用)函数时,调用函数其实根据函数名在符号表中去寻找对应的地址!所以容易误认为的函数返回值,并不属于函数重载的特性。
结论: 在linux下,采用g++编译完成后,函数名字的修饰发生改变,编译器将函数参数类型信息添加到修改后的名字中。
- 采用C语言编译器编译后的结果:
- Windows下函数名修饰规则
#include <iostream>
using namespace std;void func1(int i, double d);
//{
// cout << "void func(int a, double b)" << endl;
//}
void func2(double d, int i);
//{
// cout << "void func(double a, int b)" << endl;
//}//函数名修饰规则
int main()
{func1(1, 1.1); // call _Z5func11idfunc2(1.1, 1); // call _Z5func2di
}
将代码编译:
修饰后名字由 “?”开头,接着是函数名由“@”符号结尾的函数名;后面跟着由“@”结尾的类名“C”和名称空间“N”,再一个“@”表示函数的名称空间结束;第一个“A”表示函数调用类型为“__cdecl”,接着是函数的参数类型及返回值,由“@”结束,最后由“Z”结尾。

对比Linux会发现,windowws下vs编译器对函数名字修饰规则相对复杂难懂,但道理都是类似的,我们就不做细致研究了。
通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办法区分。
引用
引用概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
类型& 引用变量名(对象名) = 引用实体
void TestRef()
{int a = 10;int& b = a;//<====定义引用类型//取地址cout << &a << endl;cout << &b << endl;
}
注意:1. 引用类型必须和引用实体是同种类型的;
2.&在C语言阶段我们都知道是取地址操作符,但与这里的引用并不冲突,取决于他们各自的使用方式。
引用特性
- 一个变量可以有多个引用
- 引用在定义时必须初始化
- 引用一旦引用一个实体,再不能引用其他实体

void TestRef()
{int a = 10;// int& ra; // 该条语句编译时会出错,因为没有初始化引用int& ra = a;int& rra = a;printf("%p %p %p\n", &a, &ra, &rra);
}
使用场景
- 1、引用做函数参数
在学数据结构时,我们对链表的PushBack()函数进行传参,需要传入结构体一级指针,用二级指针来接收。
typedef struct ListNode
{int val;struct ListNode* next;
}ListNode;//C语言一级指针传参,二级指针用来接收
void PushBack(ListNode** pphead,int x)
{ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (*pphead == NULL){*pphead = newnode;}else{;}
}
int main()
{ListNode* plist = NULL;PushBack(&plist, 1);PushBack(&plist, 2);PushBack(&plist, 3);
}
而使用C++的引用传递参数,在这里方便了许多,也变得容易理解。
typedef struct ListNode
{int val;struct ListNode* next;
}ListNode,* PListNode;//用C++引用参数接收
//void PushBack(PListNode& pphead, int x)
void PushBack(ListNode*& pphead, int x)
{ListNode* newnode = (ListNode*)malloc(sizeof(ListNode));if (pphead == NULL){pphead = newnode;}else{;}
}
int main()
{ListNode* plist = NULL;PushBack(plist, 1);PushBack(plist, 2);PushBack(plist, 3);
}
- 2.引用做返回值
在C语言中,我们学过函数传值返回的概念,编译器在给Count()函数返回值做返回的时候,为了确保出了作用域n变量会被销毁,会生成一个临时变量(寄存器或者一块栈帧空间),然后再返回给ret
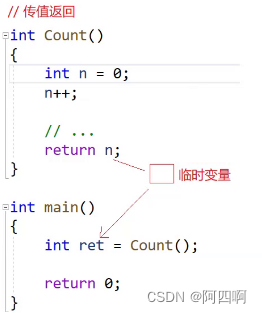
👇而在C++中,可以用引用返回,观察下面的代码,Count()函数返回的是n的别名,那么大家可能会想,n出了作用域不就被销毁了吗,ret再去拿到别名不也就没了吗?这里想说的是空间地址还在,只是数据资源被清理了。那么存放到ret的结果可能是1,也可能是随机值,这就取决于编译器环境、Count函数栈帧空间是否会立马释放,置为随机值。

👇但是将ret改为引用类型接收,打印两个ret的值,第一个为1,第二个为随机值,为什么呢?这里首先需要说明,cout << ret << endl利用了运算符重载函数(具体后面章节会细讲)。 第一个cout << ret << endl,首先ret会传参给运算符重载函数,那么打印的ret就是正常值1,然后开辟了运算符重载函数栈帧,于是就将原来的Count()函数栈帧空间给覆盖了,那么此时,再去取ret也就是n的别名,n已经被置为随机值了,那么打印的ret也就是一个随机值。

这里如果理解了的话,大家可以看看下面这个代码的结果是什么?
#include <iostream>
using namespace std;
//注:该代码仅用于理解引用底层的逻辑,不建议学习此代码。
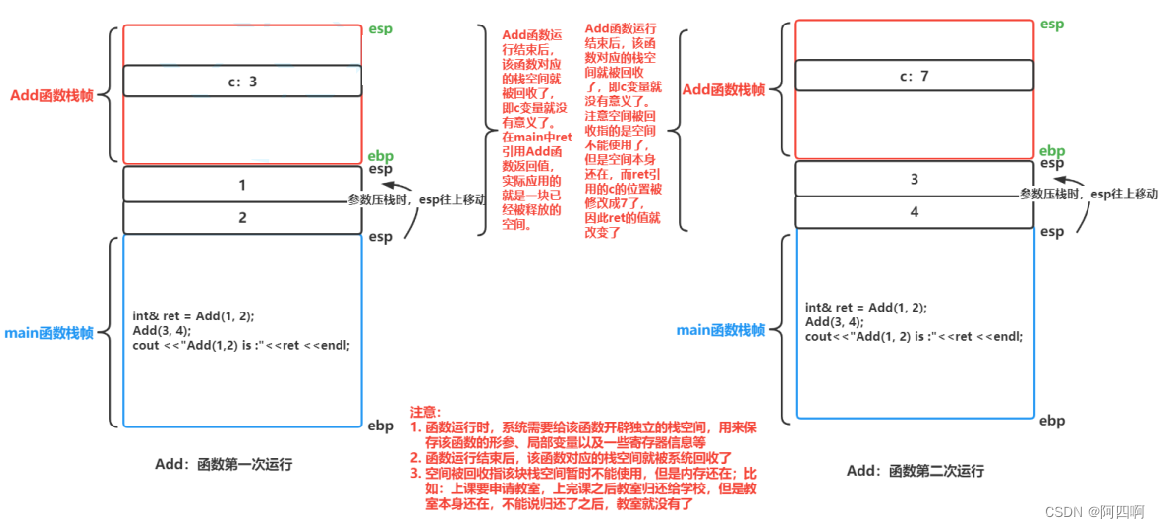
int& Add(int a, int b)
{int c = a + b;return c;
}
int main()
{int& ret = Add(1, 2);Add(3, 4);cout << "ret = " << ret <<endl;return 0;
}
打印上述代码结果:
ret = 7
💡解释:
那么引用作为返回值,到底怎么使用呢?
⚠️注意:如果函数返回时,出了函数作用域,如果返回对象还在(还没还给系统),则可以使用引用返回,如果已经还给系统了,则必须使用传值返回。
值和引用作为返回值类型的性能比较
#include <time.h>
struct A{ int a[10000]; };
A a;
// 值返回
A TestFunc1() { return a;}
// 引用返回
A& TestFunc2(){ return a;}
void TestReturnByRefOrValue()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
打印上述代码结果:
TestFunc1 time:162
TestFunc2 time:2
通过比较,发现传值和指针在作为传参以及返回值类型上效率相差很大。
传引用传参和传引用返回的作用
- 传引用传参(任何时候都可以使用)
- 提高效率
- 输出型参数(形参的修改,影响实参)
- 传引用返回(出了作用域对象还在才能使用)
- 提高效率
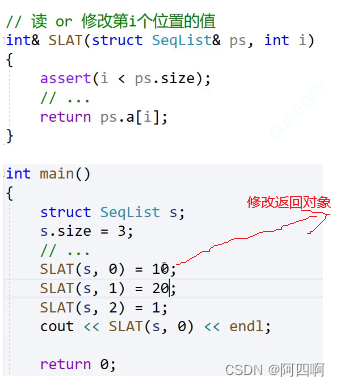
- 修改返回对象(比如说C语言实现的顺序表,需要写
SLFind()和SLModify()两个接口函数,而CPP利用传引用返回,只需要写一个SLAt()接口,可以调用函数后进行修改。)
常引用
在引用的过程中,权限可以平移,可以缩小,但是不能放大。
void TestConstRef()
{const int a = 10;//权限的放大//int& b = a; //注意:int b = a;是可以的,这里是赋值拷贝,因为b的 修改不影响a//权限的平移const int& c = a;//权限的缩小int x = 20;const int& y = x;//error:这里并不是类型不匹配,整型传递给double类型中间会发生隐式类型转换,//产生一个临时变量,而临时变量具有常属性。int i = 30;//double& d = i; const double& d = i; }
引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
int main()
{int a = 10;int& ra = a;cout<<"&a = "<<&a<<endl;cout<<"&ra = "<<&ra<<endl;return 0;
}
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
int main()
{int a = 0;int* p1 = &a;int& ref = a;return 0;
}
转到反汇编代码,引用和指针都有
lea指令操作,表示取地址的意思。

引用和指针的不同点:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求。
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体。
- 没有NULL引用,但有NULL指针。
- 在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)。
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
- 有多级指针,但是没有多级引用。
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理。
- 引用比指针使用起来相对更安全。
内联函数
下面是C语言中的一个Add宏函数
#define Add(x, y) ((x) + (y))
我们在C语言时期学习的宏函数,没有类型的严格限制,以及针对频繁调用较小的函数,不需要再建立栈帧,提升了效率。但是同样具有很多缺点, 比如代码可读性差、可维护性差、语法坑很多,不能对类型进行检查、不能调试。
C++有哪些技术替代宏?
- 常量定义 换用const enum
- 短小函数定义 换用
inline内联函数
inline概念
在C++中,以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
在add函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。
inline int add(int x, int y)
{return x + y;
}
int main()
{int ret = add(1, 2);cout << ret << endl;return 0;
}
需要对一些参数做修改后方便查看:
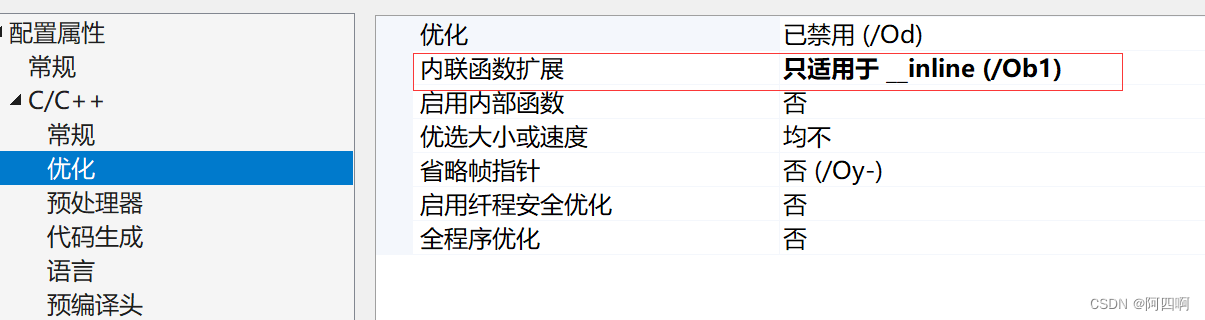
- 在release模式下,查看编译器生成的汇编代码中是否存在
call Add - 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化,以下给出vs2013的设置方式

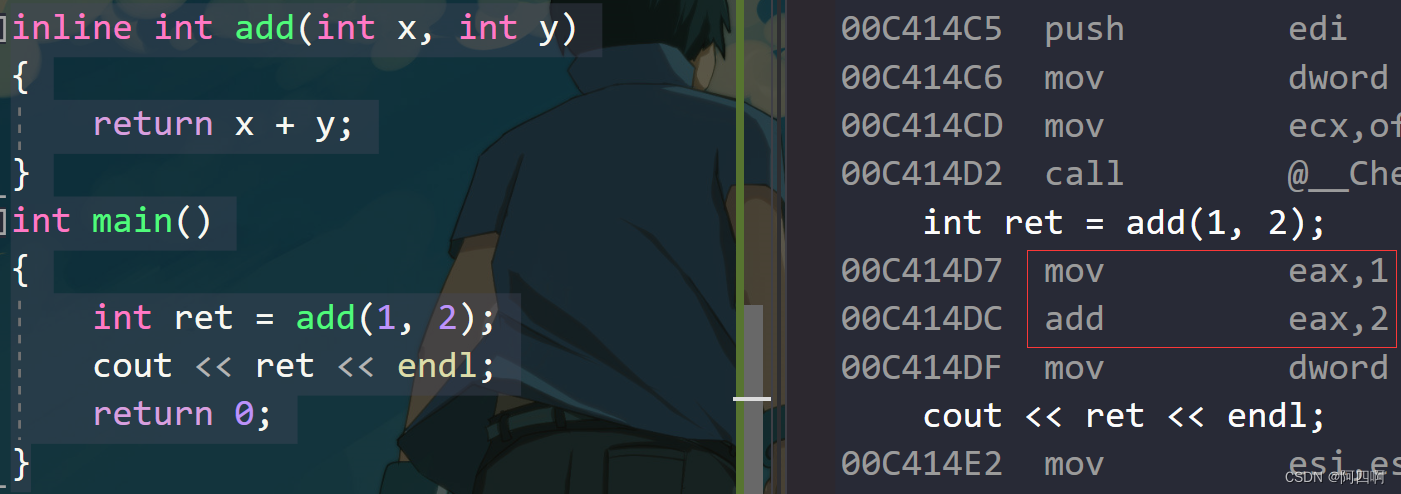
特性
inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。下图为《C++primer》第五版关于inline的建议:

inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。解决方法:我们直接定义就行。
// F.h
#include <iostream>
using namespace std;inline void f(int i);// F.cpp
#include "F.h"
void f(int i)
{cout << i << endl;
}// main.cpp
#include "F.h"
int main()
{f(10);return 0;
}
// 链接错误:main.obj : error LNK2019: 无法解析的外部符号 "void __cdecl
//f(int)" (?f@@YAXH@Z),该符号在函数 _main 中被引用
auto关键字(C++11)
类型别名思考
随着程序越来越复杂,程序中用到的类型也越来越复杂,经常体现在:
- 类型难于拼写
- 含义不明确导致容易出错
#include <string>
#include <map>
int main()
{std::map<std::string, std::string> m{ { "apple", "苹果" }, { "orange",
"橙子" },{"pear","梨"} };std::map<std::string, std::string>::iterator it = m.begin();while (it != m.end()){//....}return 0;
}
std::map<std::string, std::string>::iterator 是一个类型,但是该类型太长了,特别容易写错。聪明的同学可能已经想到:可以通过typedef给类型取别名,比如:
typedef std::map<std::string, std::string> Map;
使用typedef给类型取别名确实可以简化代码,但是typedef有会遇到新的难题:
typedef char* pstring;
int main()
{const pstring p1; // 编译成功还是失败?const pstring* p2; // 编译成功还是失败?、return 0;
}
在编程时,常常需要把表达式的值赋值给变量,这就要求在声明变量的时候清楚地知道表达式的类型。然而有时候要做到这点并非那么容易,因此C++11给auto赋予了新的含义。
auto简介
在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?
C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
int TestAuto()
{return 10;
}
int main()
{int a = 10;auto b = a;auto c = 'a';auto d = TestAuto();cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;cout << typeid(d).name() << endl;//auto e; 无法通过编译,使用auto定义变量时必须对其进行初始化return 0;
}
注意⚠️:使用auto定义变量时必须对其进行初始化,在编译阶段编译器需要根据初始化表达式来推导auto的实际类型。因此auto并非是一种“类型”的声明,而是一个类型声明时的“占位符”,编译器在编译期会将auto替换为变量实际的类型。
auto的使用规则
- auto与指针和引用结合起来使用
用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
int main()
{int x = 10;auto a = &x;auto* b = &x;auto& c = x;cout << typeid(a).name() << endl;cout << typeid(b).name() << endl;cout << typeid(c).name() << endl;*a = 20;*b = 30;c = 40;return 0;
}
- 在同一行定义多个变量
当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
void TestAuto()
{auto a = 1, b = 2;auto c = 3, d = 4.0; // 该行代码会编译失败,因为c和d的初始化表达式类型不同
}
auto不能推导的场景
- auto不能作为函数的参数
// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导
void TestAuto(auto a)
{}
- auto不能直接用来声明数组
void TestAuto()
{int a[] = {1,2,3};auto b[] = {4,5,6};
}
- 为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法。
- auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用。
基于范围的for循环(C++11)
范围for的语法
在C++98中如果要遍历一个数组,可以按照以下方式进行:
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i)array[i] *= 2;for (int* p = array; p < array + sizeof(array)/ sizeof(array[0]); ++p)cout << *p << endl;
}
对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
void TestFor()
{int array[] = { 1, 2, 3, 4, 5 };//依次取数组中的数据进行赋值//auto + & 数组中数据的别名,修改e,等同于可以修改数组元素本身//自动判断结束,自动迭代for(auto& e : array)e *= 2;for(auto e : array)cout << e << " ";return 0;
}
⚠️注意:
- 与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
- for循环迭代的范围必须是确定的,对于数组而言,就是数组中第一个元素和最后一个元素的范围。
空指针nullptr(C++11)
C++98 中的指针空值
在良好的C/C++编程习惯中,声明一个变量时最好给该变量一个合适的初始值,否则可能会出现不可预料的错误,比如未初始化的指针。如果一个指针没有合法的指向,我们基本都是按照如下方式对其进行初始化:
void TestPtr()
{int* p1 = NULL;int* p2 = 0;// ……
}
NULL实际是一个宏,在传统的C头文件(stddef.h)中,可以看到如下代码:
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
可以看到,NULL可能被定义为字面常量0,或者被定义为无类型指针(void*)的常量。不论采取何种定义,在使用空值的指针时,都不可避免的会遇到一些麻烦,比如:
void f(int)
{cout<<"f(int)"<<endl;
}
void f(int*)
{cout<<"f(int*)"<<endl;
}
int main()
{f(0);f(NULL);f((int*)NULL);return 0;
}
程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。
在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void*)0。
⚠️注意:
- 在使用nullptr表示指针空值时,不需要包含头文件,因为
nullptr是C++11作为新关键字引入
的。 - 在C++11中,
sizeof(nullptr)与sizeof((void*)0)所占的字节数相同。 - 为了提高代码的健壮性,在后续表示指针空值时建议最好使用
nullptr
相关文章:
【C++入门】命名空间、缺省参数、函数重载、引用、内联函数
👻内容专栏: C/C编程 🐨本文概括: C入门学习必备语法 🐼本文作者: 阿四啊 🐸发布时间:2023.9.3 前言 C是在C的基础之上,容纳进去了面向对象编程思想,并增加…...

c++ 学习之 构造函数的使用规则
上规则 // 默认情况下,c 编译器至少给一个类添加三个函数 //1.默认构造函数(无参,函数体为空) //2.默认析构函数 (无参 ,函数体为空) //3.默认拷贝函数,对其属性进行值拷贝 //构…...

C++操作符重载的注意事项
关于C操作符重载,可以用类内的成员运算符重载或友元函数。但是注意两个不能同时出现,不然编译出错。 #include<iostream> using namespace std; class Complex{public:Complex(int r0,int i0){real r;imag i;}//#if 0Complex operator(Complex …...

10 | Spark 查找每个单词的最大行号
假设你有一个包含文本行号和文本内容的RDD,现在你想找出每个单词出现在哪些行,并计算它们出现的最大行号。 需求是从包含文本行号和文本内容的RDD中找出每个单词出现在哪些行,并计算它们出现的最大行号。 具体需求如下: 数据输入: 代码从一个包含文本行号和文本内容的RD…...

CRE66365
CRE66365是一款高度集成的电流模式PWM控制IC,为高性能、低待机功耗和低成本的隔离型反激转换器。在正常负载条件下,AC输入高电压下工作在QR模式。为了最大限度地减少开关损耗,QR 模式下的最大开关频率被内部限制为 77kHz。当负载较低时&#…...

React hook 10种常见 Hook
React Hook是什么? React官网是这么介绍的: Hook 是 React 16.8 的新增特性。它可以让你在不编写 class 的情况下使用 state 以及其他的 React 特性。 完全可选的 你无需重写任何已有代码就可以在一些组件中尝试 Hook。但是如果你不想,你不…...
图文详解PhPStudy安装教程
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 官方下载 请在PhPStudy官方网站下载安装文件,官方链接如下:https://m.xp.cn/linux.html;图示如下: 请下载PhPStudy安装文件…...

stable diffusion实践操作-hypernetworks
系列文章目录 本文专门开一节写hypernetworks的内容,在看之前,可以同步关注: stable diffusion实践操作 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 系列文章目录前言一、h…...

Win10搭建VisualSvn Server
Win10搭建VisualSvn Server 目录 Win10搭建VisualSvn Server一、下载VisualSvn Server安装包二、安装VisualSvn Server三、配置和使用VisualSVN Server四、添加用户及权限设定方法五、创建目录及配置权限 1、服务端:有集成了Subversion和Apache、安装使用非常简单且…...

Golang网络编程
Golang网络编程 网络编程简介网络编程协议网络分层模型TCP/IP协议什么是DNS套接字(Socket)客户端服务器模型TCP/UDP的区别HTTP协议会话sessionCookiehttpsHTTP请求格式HTTP响应格式http头信息http请求头信息http响应头信息HTTP状态码http内容类型和内容…...

详解vue3中ref和reactive用法和区别
vue3中ref和reactive区别 1、前言2、基本用法2.1 ref2.2 reactive 3、ref和reactive定义数组对比3.1 ref定义数组3.1 reactive定义数组 4、ref 和reactive的区别 1、前言 ref和reactive是Vue3中用来实现数据响应式的API,一般情况下,ref定义基本数据类型…...

QML与C++的交互操作
QML旨在通过C 代码轻松扩展。Qt QML模块中的类使QML对象能够从C 加载和操作,QML引擎与Qt元对象系统集成的本质使得C 功能可以直接从QML调用。这允许开发混合应用程序,这些应用程序是通过混合使用QML,JavaScript和C 代码实现的。除了从QML访问…...
Java_理解方法调用
理解方法调用 首先什么是隐式参数 --->隐式参数是调用该方法的对象本身。 接下来方法的名称和参数列表被称为方法的签名(signature)。在Java中,方法的签名由方法的名称和参数列表组成,用于唯一标识一个方法。返回类型不是签名的…...

Mysql 性能分析(慢日志、profiling、explain)、读写分离(主从架构)、分库分表(垂直分库、垂直分表、水平分表)
查看系统性能参数 一条sql查询语句在执行前,需要确定查询执行计划,如果存在多种执行计划的话,mysql会计算每个执行计划所需要的成本,从中选择 成本最小的一个作为最终执行的执行计划 想要查看某条sql语句的查询成本,可…...

获取Linux内核源码
在嵌入式平台上做Linux开发的时候,我们用的kernel都是芯片厂家移植到自家平台上的,但是最初的原生Linux内核的源码是从哪里来的呢?下面我们介绍一下怎么获取原生的Linux源码。 从Linux社区获取内核kernel源码 Linux社区的官方网站是 https:…...

【Maven教程】(四)坐标与依赖:坐标概念,依赖配置、范围、传递性和最佳实践 ~
Maven 坐标与依赖 1️⃣ 什么是Maven 坐标2️⃣ 坐标详解3️⃣ 依赖的配置4️⃣ 依赖范围5️⃣ 传递性依赖6️⃣ 依赖调解7️⃣ 可选依赖8️⃣ 最佳实践8.1 排除依赖8.2 归类依赖8.3 优化依赖 🌾 总结 正如前面文章所述,Maven 的一大功能是管理项目依赖…...

Java“牵手”京东店铺所有商品API接口数据,通过店铺ID获取整店商品详情数据,京东店铺所有商品API申请指南
京东平台店铺所有商品数据接口是开放平台提供的一种API接口,通过调用API接口,开发者可以获取京东整店的商品的标题、价格、库存、月销量、总销量、库存、详情描述、图片、价格信息等详细信息 。 获取店铺所有商品接口API是一种用于获取电商平台上商品详…...

TuyaOS开发学习笔记(1)——NB-IoT开发搭建环境、编译烧写(MT2625)
一、搭建环境 1.1 官方资料 TuyaOS 1.2 安装VMware 官网下载:https://customerconnect.vmware.com/en/downloads/info/slug/desktop_end_user_computing/vmware_workstation_pro/16_0 百度网盘:https://pan.baidu.com/s/1oN7H81GV0g6cD9zsydg6vg 提取…...

Css 将div设置透明度,并向上移50px,盖住上面的元素一部分
可以使用CSS中的opacity和position属性来实现。 首先,将div的opacity属性设置为小于1的值,比如0.5,这样就可以设置透明度了。其次,将div的position设置为relative,然后再将它向上移动50px,即可盖住上面的元…...
HTTPS安全通信和SSL Pinning
随着互联网的迅速发展,网络通信安全问题日益凸显。在这一背景下,HTTPS作为一种加密通信协议得到了广泛应用,以保障用户的数据隐私和信息安全。本文将介绍HTTPS的基本原理、发展历程,以及与之相关的中间人攻击和防护方法。 1. HTT…...

王二明古方草解毒茶商城模式解析
王二明古方草解毒茶商城模式解析:架构、争议与合规思考在社交电商与大健康产业的交叉赛道中,“王二明古方草解毒茶”凭借其独特的草本茶饮定位与多级分销模式,曾一度引发市场关注。该模式以产品为核心,通过数字化商城系统构建了一…...

Sqitch 实战教程:如何在 PostgreSQL 中管理数据库变更
Sqitch 实战教程:如何在 PostgreSQL 中管理数据库变更 【免费下载链接】sqitch Sensible database change management 项目地址: https://gitcode.com/gh_mirrors/sq/sqitch Sqitch 是一款功能强大的数据库变更管理工具,专为 PostgreSQL 等数据库…...

PHPBrew终极性能优化指南:10个技巧加速PHP编译安装
PHPBrew终极性能优化指南:10个技巧加速PHP编译安装 【免费下载链接】phpbrew Brew & manage PHP versions in pure PHP at HOME 项目地址: https://gitcode.com/gh_mirrors/ph/phpbrew PHPBrew是一款纯PHP编写的PHP版本管理工具,能够帮助开发…...

Mergo入门指南:10分钟学会Go结构体与映射合并技巧
Mergo入门指南:10分钟学会Go结构体与映射合并技巧 【免费下载链接】mergo Mergo: merging Go structs and maps since 2013 项目地址: https://gitcode.com/gh_mirrors/me/mergo Mergo是一个强大的Go语言库,专门用于合并结构体(struct…...

GPEN快速上手教程:手机自拍模糊修复,30秒获取高清证件照
GPEN快速上手教程:手机自拍模糊修复,30秒获取高清证件照 你是不是也遇到过这种情况:急着要用证件照,翻遍手机相册却发现每张自拍都模糊不清?要么是光线太暗,要么是手抖拍糊了,要么就是像素太低…...

Tecplot三维可视化保姆教程:从MATLAB数据到专业云图只需5步
Tecplot三维可视化实战指南:从MATLAB数据到科研级云图全解析 在工程仿真与科学计算领域,数据可视化是研究成果呈现的关键环节。当二维图表无法满足复杂空间数据的展示需求时,Tecplot作为专业的三维可视化工具便展现出独特优势。本文将手把手带…...

SpringBoot整合poi-tl实战:如何优雅导出带动态表格和图片的Word并自动压缩成zip
SpringBoot与poi-tl深度整合:企业级Word动态导出与智能压缩方案 在企业级应用开发中,批量生成结构化的Word文档(如报告、合同等)并打包分发的需求日益普遍。传统方案往往面临动态内容渲染复杂、性能瓶颈明显、文件管理混乱等痛点。…...

硬件工程师成长指南:从理论到实战的完整路径
1. 硬件工程师的成长路线:从理论到实践的完整规划作为一名从业十年的硬件工程师,我见过太多新人一上来就埋头焊板子、调电路,结果浪费大量时间在低水平重复。硬件设计就像下围棋,没有全局思维的人永远只能当个业余爱好者。今天我想…...

HarmonyOS6 半年磨一剑 - RcCheckbox 实战下篇:问卷调查表单与参数使用指南
文章目录前言一、场景:问卷调查表单1.1 需求分析1.2 数据结构设计1.3 表单校验联动1.4 第三题:计数器与数量限制的配合1.5 结果页与状态重置1.6 三道题的样式差异化对比1.7 完整代码二、参数使用频率参考2.1 高频参数(必须掌握)2.…...

颠覆式突破限制:五大核心技术实现网盘下载加速革命
颠覆式突破限制:五大核心技术实现网盘下载加速革命 【免费下载链接】Online-disk-direct-link-download-assistant 可以获取网盘文件真实下载地址。基于【网盘直链下载助手】修改(改自6.1.4版本) ,自用,去推广…...