使用Python对数据的操作转换
1、列表加值转字典
在Python中,将列表的值转换为字典的键可以使用以下代码:
myList = ["name", "age", "location"]
myDict = {k: None for k in myList}
print(myDict)输出:
{'name': None, 'age': None, 'location': None}在上面的代码中,我们首先定义一个列表 myList,接着,我们使用字典推导式,创建一个新的字典 myDict,其中字典的键是从列表 myList 中获取的每个元素,而对应的值都设置为 None。
如果想让列表中的值对应不同的值,只需在推导式中指定相应的值即可,例如:
myList = ["name", "age", "location"]
myValues = ["John", 22, "Bei Jing"]
myDict = {myList[i]: myValues[i] for i in range(len(myList))}
print(myDict)输出:
{'name': 'John', 'age': 22, 'location': 'Bei Jing'}如果你想学习自动化测试,我这边给你推荐一套视频,这个视频可以说是B站播放全网第一的自动化测试教程,同时在线人数到达1000人,并且还有笔记可以领取及各路大神技术交流:798478386
【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)_哔哩哔哩_bilibili【已更新】B站讲的最详细的Python接口自动化测试实战教程全集(实战最新版)共计200条视频,包括:1、接口自动化之为什么要做接口自动化、2、接口自动化之request全局观、3、接口自动化之接口实战等,UP主更多精彩视频,请关注UP账号。![]() https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click 在上面的代码中,我们创建一个包含键、值的列表,然后使用循环和字典推导式来创建字典,其中列表中的每个值对应于字典中的一个键和一个值。
https://www.bilibili.com/video/BV17p4y1B77x/?spm_id_from=333.337.search-card.all.click 在上面的代码中,我们创建一个包含键、值的列表,然后使用循环和字典推导式来创建字典,其中列表中的每个值对应于字典中的一个键和一个值。
2、字典键新增值数据
根据上面的代码,对每个键又新增了2条数据,该如何操作
如果想要在已经存在的字典中为每个键添加多个值,可以将值存储在列表中,然后将列表作为键对应的值,例如:
myDict = {"name": ["John"], "age": [22], "location": ["Bei Jing"]}# 为 name 增加两个新值
myDict["name"].extend(["Alice", "Bob"])
print(myDict)# 为 age 和 location 增加两个新值
myDict["age"].append(25)
myDict["location"].extend(["Shang Hai", "Guang Zhou"])
print(myDict)输出:
{'name': ['John', 'Alice', 'Bob'], 'age': [22], 'location': ['Bei Jing']}
{'name': ['John', 'Alice', 'Bob'], 'age': [22, 25], 'location': ['Bei Jing', 'Shang Hai', 'Guang Zhou']}在上面的代码中,我们首先在字典中为每个键初始化一个列表,然后可以使用字典键和列表方法来添加由多个值组成的列表。
3、转换新的字典格式
如何将[{'key': 'name', 'value': 'John'}, {'key': 'location', 'value': 'Bei Jing'}]数据更改为{'name': 'John', 'location': 'Bei Jing'}
可以使用一个循环来遍历列表中的字典,然后将每个字典的键和值提取出来,组成一个新的字典。具体如下:
# 原始数据
data = [{'key': 'name', 'value': 'John'}, {'key': 'location', 'value': 'Bei Jing'}]# 新的字典
new_dict = {}
for item in data:key = item['key']value = item['value']new_dict[key] = valueprint(new_dict)输出:
{'name': 'John', 'location': 'Bei Jing'}首先定义一个空字典 new_dict,用于存储新的数据。然后使用 for 循环遍历原始数据中的每个字典。在循环中,使用 item['key'] 和 item['value'] 分别获取当前字典的键和值,并使用 new_dict[key] = value 将其存储到新的字典中,最后输出新的字典即可。
4、两组数据比较筛选
有两组数据,list1['code', 'data.totalPage', 'data.type']和list2['code', 'description', 'errCode', 'error', 'msg', 'message', 'success', 'btSuccess', 'btCode', 'btMsg', 'header.mss'],筛选list1里面的元素不存在list2里,则预期的筛选结果为['data.totalPage', 'data.type']
可以使用列表推导式以及not in语句来实现筛选:
list1 = ['code', 'data.totalPage', 'data.type']
list2 = ['code', 'description', 'errCode', 'error', 'msg', 'message', 'success', 'btSuccess', 'btCode', 'btMsg', 'header.mss']result = [ele for ele in list1 if ele not in list2]
print(result)输出:
['data.totalPage', 'data.type']其中,列表推导式的语法格式为:[返回值 for in 条件语句],它可以将符合条件的元素一次性生成到一个新列表中。而not in语句则表示不在列表中的元素。因此,上述代码中的列表推导式就是遍历list1中的每个元素ele,如果ele不在list2中,则将其添加到结果列表中。
5、将两段独立代码合并
有两段独立的代码,都有for循环
hj = HandleJson(data_dict)
res = hj.find_key_path('request')
print(res)
print(type(res))
# request-循环
for count_i, api_i in enumerate(res):# requestjson_request = eval(str(data_dict) + api_i)# print("json_request " + str(json_request))# namejson_name = eval(str(data_dict) + api_i.replace("request", "name"))print("count_i 第 " + str(count_i + 1) + " 个接口")print("json_name " + str(json_name))hj2 = HandleJson(data_dict)
res2 = hj2.find_key_path('response')
print(res2)
print(type(res2))
# response-循环
for count_i, api_i in enumerate(res2):# responsejson_response = eval(str(data_dict) + api_i)print("json_response " + str(json_response))if json_response:print("json_response 不为空")for count_i_i, api_i_i in enumerate(json_response):# print(api_i_i)# namejson_name = eval(str(api_i_i) + str(["name"]))print("count_i_i 第 " + str(count_i_i + 1) + " 个接口")print("json_name " + str(json_name))如何将这两段代码合并
可以使用zip()函数将两个循环的结果压缩在一起,然后在一个for循环中同时遍历两个列表。具体代码如下所示:
hj = HandleJson(data_dict)
res = hj.find_key_path('request')
res2 = hj.find_key_path('response')
for count_i, (api_i, api_i2) in enumerate(zip(res, res2)):# request-循环的代码内容# response-循环的代码内容相关文章:
使用Python对数据的操作转换
1、列表加值转字典 在Python中,将列表的值转换为字典的键可以使用以下代码: myList ["name", "age", "location"] myDict {k: None for k in myList} print(myDict) 输出: {name: None, age: None, loca…...
MyBatis-Plus —— 初窥门径
前言 在前面的文章中荔枝梳理了MyBatis及相关的操作,作为MyBatis的增强工具,MyBatis-Plus无需再在xml中写sql语句,在这篇文章中荔枝将梳理MyBatis-Plus的基础知识并基于SpringBoot梳理MyBatis-Plus给出的两个接口:BaseMapper和ISe…...
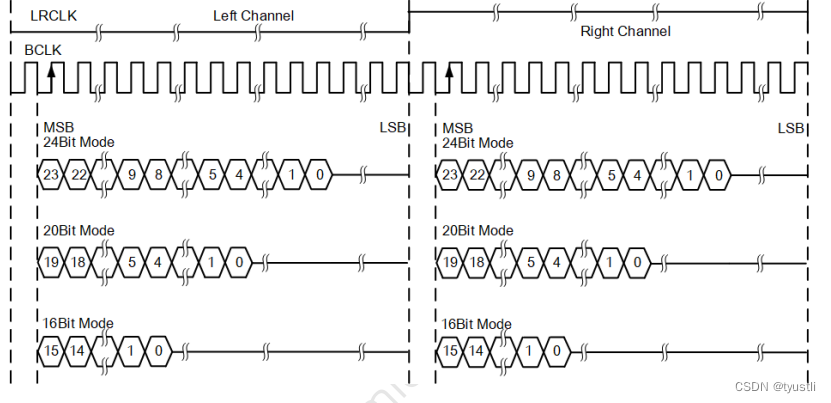
音频——I2S 标准模式(二)
I2S 基本概念飞利浦(I2S)标准模式左(MSB)对齐标准模式右(LSB)对齐标准模式DSP 模式TDM 模式 文章目录 I2S format时序图逻辑分析仪抓包 I2S format 飞利浦 (I2S) 标准模式 数据在跟随 LRCLK 传输的 BCLK 的第二个上升沿时传输 MSB,其他位一直到 LSB 按顺序传传输依…...

Python语音识别处理详解
概要 人们对智能语音助手的需求不断提高,语音识别技术也随之迅速发展。在这篇文章中,我们将介绍如何使用Python的SpeechRecognition和pydub等库来实现语音识别和处理,从而打造属于自己的智能语音助手。 1. 什么是语音识别? 语音…...

【小吉送书—第一期】Kali Linux高级渗透测试
文章目录 🍔前言🛸读者对象🎈本书资源🎄彩蛋 🍔前言 对于企业网络安全建设工作的质量保障,业界普遍遵循PDCA(计划(Plan)、实施(Do)、检查&#x…...

服务器允许ssh登录root
用vim打开/etc/ssh/sshd_config sudo vim /etc/ssh/sshd_config将sshd_config中的PermitRootLogin属性改为yes ... PermitRootLogin yes ...重启sshd服务 sudo service sshd restart...

【微服务部署】三、Jenkins+Maven插件Jib一键打包部署SpringBoot应用Docker镜像步骤详解
前面我们介绍了K8SDockerMaven插件打包部署SpringCloud微服务项目,在实际应用过程中,很多项目没有用到K8S和微服务,但是用到了Docker和SpringBoot,所以,我们这边介绍,如果使用Jenkinsjib-maven-plugin插件打…...
Ansible学习笔记9
yum_repository模块: yum_repository模块用于配置yum仓库的。 测试下: [rootlocalhost ~]# ansible group1 -m yum_repository -a "namelocal descriptionlocalyum baseurlfile:///mnt/ enabledyes gpgcheckno" 192.168.17.106 | CHANGED &g…...
Ubuntu22.04安装Mongodb7.0
Ubuntu安装Mongodb 1.平台支持2.安装MongoDB社区版2.1导入包管理系统使用的公钥2.2为MongoDB创建列表文件2.3重新加载本地包数据库2.4安装MongoDB包1.安装最新版MongoDB2.安装指定版MongoDB 3.运行MongoDB社区版1.目录2.配置文件3.初始化系统4.启动MongoDB5.验证MongoDB是否成功…...
)
Oracle中序列删除的正确语句(oracle删除序列语句)
Oracle中序列删除的正确语句 Oracle 是由世界上最大的软件公司 Oracle Corporation 提供的关系型数据库管理系统,拥有广泛的应用和功能,如存储过程、触发器、视图、序列以及其他的复杂的特性,能够满足丰富的业务需求。本文主要研究Oracle中序…...

ChatGPT AI在线免费体验
🤖 与ChatGPT亲密接触 🤖 ChatGPT!它就是一款强大的聊天型人工智能模型,可以与你进行各种有趣的对话,就像我们在这里一样。不论你想聊天、提问、寻求建议,还是只是想找个伙伴一起闲聊,ChatGPT都…...

CSS中如何实现文字渐变色效果(Text Gradient Color)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 文字渐变色效果(Text Gradient Color)⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这…...
)
尚硅谷SpringMVC (1-4)
一、SpringMVC简介 1、什么是MVC MVC 是一种软件架构的思想,将软件按照模型、视图、控制器来划分 M : Model ,模型层,指工程中的 JavaBean ,作用是处理数据 JavaBean 分为两类: 一类称为实体类Bean&am…...
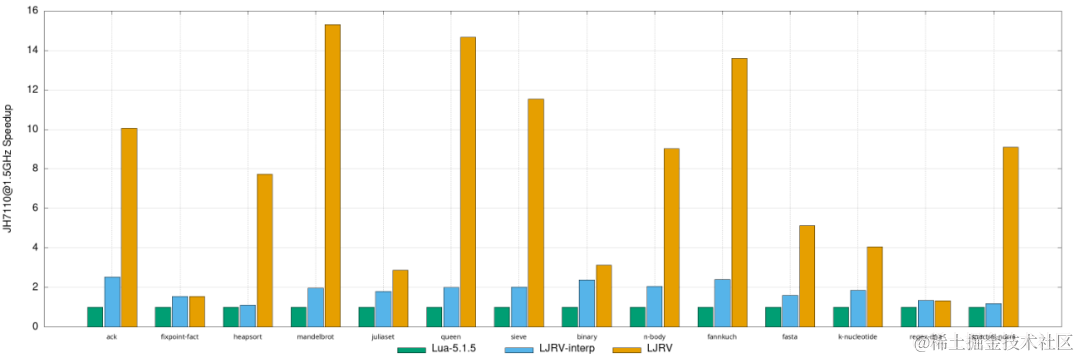
独家首发!openEuler 主线集成 LuaJIT RISC-V JIT 技术
RISC-V SIG 预期随主线发布的 openEuler 23.09 创新版本会集成 LuaJIT RISC-V 支持。本次发版将提供带有完整 LuaJIT 支持的 RISC-V 环境并带有相关软件如 openResty 等软件的支持。 随着 RISC-V SIG 主线推动工作的进展,LuaJIT 和相关软件在 RISC-V 架构下的支持也…...

在Mac 上安装flutter 遇到的问题
准备工作 1、升级Macos系统为最新系统 2、安装最新的Xcode 3、电脑上面需要安装brew https://brew.sh/ 4、安装chrome浏览器(开发web用) 下载Flutter、配置Flutter环境变量、配置Flutter镜像 下载Flutter SDK https://docs.flutter.dev/release/archive?tabmacos 根据自己…...
一个月能做什么?成长感悟分享
一个月做了什么? 八月做了些什么? 单词打卡 第一件事情就是单词打卡 英语很差的我,一样继续打卡,今天是第736天 当你还在纠结扇贝和不背、可可英语哪一个好的时候,别人已经同时使用了 当你还在咨询学编程、敲代码需…...
网络编程
1. 网络编程入门 1.1 网络编程概述 计算机网络 是指将地理位置不同的具有独立功能的多台计算机及其外部设备,通过通信线路连接起来,在网络操作系统,网络管理软件及网络通信协议的管理和协调下,实现资源共享和信息传递的计算机系统…...
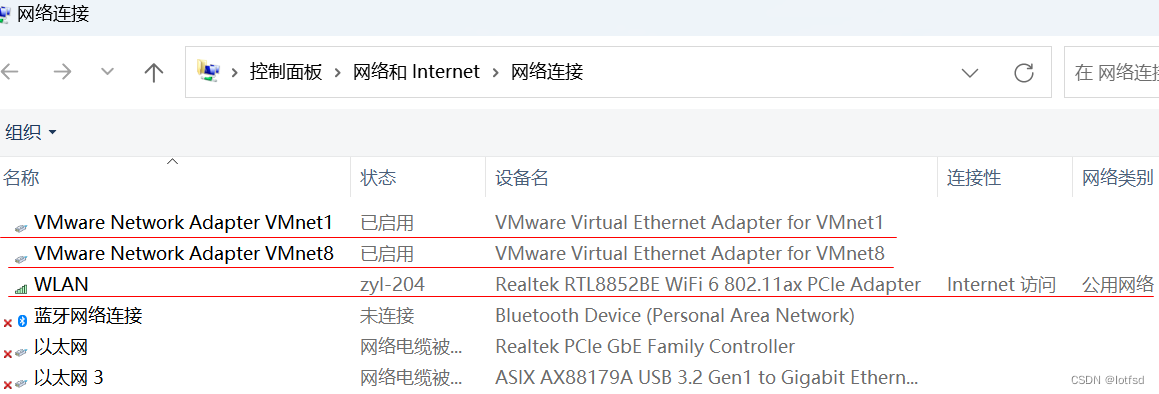
ip route get ip地址 应用案例
应用场景 在做虚拟化实验用的虚拟机和实际的ECS云主机一般都会有多个网卡,网络的联通性是经常碰到的问题。比如在一个VM上有3个网卡,分别为ens160(和寄主机进行桥接的网卡10.0.0.128)、ens224(连接仅主机网络10.0.0.0/24的网卡10.0.0.128&…...

Windows下Redis的安装和配置
文章目录 一,Redis介绍二,Redis下载三,Redis安装-解压四,Redis配置五,Redis启动和关闭(通过terminal操作)六,Redis连接七,Redis使用 一,Redis介绍 远程字典服务,一个开源的,键值对形式的在线服务框架,值支持多数据结构,本文介绍windows下Redis的安装,配置相关,官网默认下载的是…...

【sgTransfer】自定义组件:带有翻页、页码、分页器的穿梭框组件,支持大批量数据的穿梭显示。
特性: 表格宽度可以自定义翻页器显示控件可以自定义列配置项可以设置显示字段列名称、宽度、字段名可以配置搜索框提示文本,支持搜索过滤穿梭框顶部标题可以自定义左右箭头按钮文本可以设置 sgTransfer源码 <template><div :class"$opti…...

Phi-4-mini-reasoning企业级落地:金融风控规则推理引擎构建案例
Phi-4-mini-reasoning企业级落地:金融风控规则推理引擎构建案例 1. 项目背景与模型介绍 在金融风控领域,规则推理引擎是核心决策系统的重要组成部分。传统规则引擎往往面临维护成本高、灵活性差、难以应对复杂场景等问题。Phi-4-mini-reasoning作为一款…...

终极指南:如何用智能工具轻松突破内容访问限制
终极指南:如何用智能工具轻松突破内容访问限制 【免费下载链接】bypass-paywalls-chrome-clean 项目地址: https://gitcode.com/GitHub_Trending/by/bypass-paywalls-chrome-clean 内容访问突破工具是现代数字工作者的必备利器,它能帮助研究人员…...

Ubuntu安装中文输入法后无法输入中文----问题分析及解决方法
问题:之前在Ubuntu系统上安装过搜狗输入法,且能正常输入中文。但重启之后无法调出,Shift切换也不管用,依旧是英文原因分析:后台进程(Fcitx)卡死或崩溃了解决方法:重启Fcitx输入法框架…...
)
告别底噪和电流声:DIY蓝牙音箱的音频电路避坑指南(从TPA2019布线到电源滤波)
蓝牙音箱DIY进阶指南:从电路设计到音质优化的全流程解析 在电子DIY领域,蓝牙音箱制作看似简单,但要实现专业级的音质表现却需要跨越诸多技术门槛。许多爱好者完成基础组装后,常会遇到底噪明显、高频失真或低频浑浊等问题——这往往…...

快速体验WAN2.2文生视频:ComfyUI预置工作流,2分钟生成测试视频
快速体验WAN2.2文生视频:ComfyUI预置工作流,2分钟生成测试视频 1. 为什么选择WAN2.2文生视频工作流 如果你正在寻找一个简单易用、效果出色的文生视频工具,WAN2.2文生视频工作流绝对值得一试。这个预置在ComfyUI中的工作流,让视…...

通义千问3-VL-Reranker-8B保姆级部署教程:5分钟搞定Nginx反向代理与HTTPS配置
通义千问3-VL-Reranker-8B保姆级部署教程:5分钟搞定Nginx反向代理与HTTPS配置 1. 为什么需要反向代理与HTTPS 当你成功在本地运行通义千问3-VL-Reranker-8B服务后,默认只能通过 http://localhost:7860 访问。这种配置存在三个明显问题: 安…...

OffscreenCanvas黑科技:让你的网页动画性能提升300%的配置指南
OffscreenCanvas黑科技:让你的网页动画性能提升300%的配置指南 当网页动画开始卡顿,用户的体验就会直线下降。传统Canvas渲染在主线程执行,复杂的图形运算很容易阻塞UI响应。OffscreenCanvas的出现彻底改变了这一局面——它允许你将绘制逻辑转…...

MDXEditor指令系统详解:如何扩展Markdown语法
MDXEditor指令系统详解:如何扩展Markdown语法 【免费下载链接】editor A rich text editor React component for markdown 项目地址: https://gitcode.com/gh_mirrors/editor/editor MDXEditor是一个功能丰富的React组件,专为Markdown编辑设计&am…...
)
HuggingFace大语言模型实战:如何用Python脚本批量翻译YouTube字幕(含环境配置避坑指南)
HuggingFace大语言模型实战:Python脚本批量翻译YouTube字幕全攻略 当你在YouTube上发现一段精彩的英文技术讲座,或是需要研究某个外语行业报告时,自动翻译工具能大幅提升信息获取效率。本文将带你用HuggingFace生态构建一个本地化翻译工作流&…...
领域的关键模型与实战数据集)
从LaMa到BrushNet:盘点图像修复(Inpainting)领域的关键模型与实战数据集
1. 图像修复技术的前世今生 第一次接触图像修复技术是在2015年,当时我正参与一个老照片修复项目。那些泛黄的老照片上布满了裂痕和污渍,传统Photoshop修复需要耗费数小时。直到发现深度学习可以自动完成这项任务,我才意识到这项技术将彻底改变…...