spark底层为什么选择使用scala语言开发
Spark 底层使用 Scala 开发有以下几个原因:
基于Scala的语言特性
-
集成性:Scala 是一种运行在 Java 虚拟机(JVM)上的静态类型编程语言,可以与 Java 代码无缝集成。由于 Spark 涉及到与大量 Java 生态系统的交互,例如 Hadoop、Hive 等,使用 Scala 可以方便地与这些组件进行集成和交互。
-
函数式编程支持:Scala 是一种面向函数式编程的语言,提供了丰富的函数式编程特性,如高阶函数、闭包等。这些特性使得编写复杂的数据处理逻辑变得更加简洁和灵活,而大规模数据处理正是 Spark 的核心任务之一。因此,Scala 为 Spark 提供了一种非常适合处理数据流的语言基础。
-
强类型系统:Scala 是一种静态类型语言,拥有强大的类型系统。通过静态类型检查,可以在编译期间捕获一些潜在的错误,提高代码的可靠性和稳定性。这对于 Spark 这样大规模数据处理的框架至关重要,因为它可以帮助开发人员尽早发现潜在的问题。
-
可扩展性:Scala 具有良好的可扩展性,可以轻松地扩展现有的代码库,以适应 Spark 框架不断增长的需求。同时,Scala 还提供了丰富的函数式编程特性,如类型推断、模式匹配等,使得代码的组织和重用更加方便。
-
并发性:Scala 提供了强大的并发编程特性,例如
Future、Actor等。这些特性使得在 Spark 中处理并发任务更加高效和简洁,从而提高了系统的性能和可伸缩性。
Scala 提供了强大的并发编程特性
Scala 提供了强大的并发编程特性,这主要基于以下几个方面:
-
Future和Promise:Scala 标准库提供了scala.concurrent.Future和scala.concurrent.Promise类,用于处理异步计算和并发操作。Future表示一个可能还未完成的计算结果,而Promise则是对Future的简单抽象,可以用来设置Future的结果。通过Future和Promise,可以方便地进行并行计算、异步操作和任务组合,提高代码的效率和性能。 -
Actor模型:Scala 通过Akka库提供了Actor模型的支持。Actor是并发和分布式计算中的基本单位,它是一种轻量级的并发原语,用于实现消息传递和并发任务的处理。Scala 中的Actor可以通过消息传递进行通信,每个Actor都有自己的状态和行为,并且可以相互之间进行消息的发送和接收。使用Actor模型,可以通过消息传递实现并发任务的解耦和灵活性,避免共享状态带来的并发问题。 -
并发集合(Concurrent Collections):Scala 提供了一系列并发集合类,如
ConcurrentHashMap、ConcurrentLinkedQueue等,它们是线程安全的,并且提供了并发访问和更新的方法。在多线程环境下,使用这些并发集合可以简化对共享数据的访问和管理,避免线程安全的问题,提高并发性能。 -
样本(Pattern)和不可变性:Scala 支持函数式编程风格,并鼓励使用不可变数据结构。不可变数据结构天然地支持并发,因为多个线程可以并发地读取不可变数据,而无需担心数据的修改。此外,Scala 的样本匹配机制(Pattern Matching)可以帮助开发者处理并发场景中的不同情况和消息,使得代码更加清晰和易于理解。
scala的Future与java多线程中的Future接口,他们之间有什么关系?
Scala 的 Future 类是基于 Java 的 Future 接口进行扩展和增强的,它们之间存在一定的关系。
在 Scala 中,scala.concurrent.Future 是一个非阻塞的、并发编程的核心类,它提供了以异步方式处理任务的功能。Future 类定义了一组操作符和组合方法,使得异步计算的编写和组合更加方便和灵活。
与此同时,Java 的 java.util.concurrent.Future 接口也用于表示可能还未完成的计算结果。它可以用于提交任务并获取最终结果,但相对于 Scala 的 Future,Java 的 Future 功能较为简单。Java 8 引入的 CompletableFuture 类提供了类似于 Scala Future 的操作符和组合功能,但仍然不如 Scala Future 强大。
Scala 的 Future 类库使用了 Java 的 ExecutorService 和 ScheduledExecutorService 类来执行异步任务,底层仍然是基于 Java 的线程池实现。
需要注意的是,Scala 的 Future 类和 Java 的 Future 接口之间并没有直接的继承关系,虽然它们都用于处理可能还未完成的计算结果。Scala 的 Future 更像是对 Java 的 Future 进行了扩展和增强,提供了更丰富的功能和操作符。
因此,尽管 Scala 的 Future 类与 Java 的 Future 接口有一定的关系,但它们是独立的并发编程模型,各自具有不同的特性和功能。
虽然它们的名称相似,但在功能和用法上有一些区别。下面是它们之间的主要区别:
-
Scala 的
Future是一个只读的、不可变的抽象类,它表示一个可能还未完成的计算结果。你可以将任务提交给Future,并在任务完成后获取到结果。它通常用于处理异步计算和并发操作。Java 的
Future接口也用于表示可能未来完成的计算结果,但它是一个可写的接口。通过调用cancel()方法可以取消任务的执行,而且还提供了一些其他方法如isDone()和get()来查询任务的状态和获取最终结果。 -
Scala 的
Future提供了更加丰富的操作符和组合功能,例如map、flatMap、filter等,可以对多个Future进行转换、组合和过滤,从而构建复杂的异步计算流程。Java 的
Future接口相对较为简单,没有提供类似的操作符和组合功能。虽然 Java 8 中引入了CompletableFuture类来提供类似的功能,但与 Scala 的Future相比,仍然较为有限。
总的来说,Scala 的 Future 更加强大和灵活,提供了更多的操作符和组合功能,使得异步编程更加方便和高效。在 Scala 中,你可以使用 Future 来处理并发任务、异步操作和任务的组合。
如何理解Scala中的Promise类?它的底层是怎么实现的?
在 Scala 中,Promise 是一个用于表示异步计算结果的类。它是对 Future 的一种补充,可以将值设置到 Promise 中,并且可以通过 Promise 来获取最终的结果。
Promise 的底层源码基于 Future 和 synchronization 实现。底层的原理如下:
Promise类包含了一个Future对象,用于保存最终的结果。- 当你创建一个
Promise实例时,它会同时创建一个关联的Future对象。 - 你可以使用
Promise的success、failure或complete方法来设置Future的结果。success(value: T): Promise.this.type:将Future的结果标记为成功,并设置结果值为value。failure(cause: Throwable): Promise.this.type:将Future的结果标记为失败,并设置失败原因为cause。complete(result: Try[T]): Promise.this.type:根据Try对象的结果设置Future的结果。
- 在调用
success、failure或complete之后,关联的Future将会收到相应的通知并得到最终结果。 - 如果你需要获取
Promise关联的Future,可以使用future属性进行访问。
底层实现使用了同步机制来确保在多线程环境下的正确性。当调用 success、failure 或 complete 方法时,Promise 会检查当前的状态,如果状态尚未改变,则设置 Future 的结果,并通知正在等待的线程。
在使用 Promise 和 Future 时,你可以将异步计算任务提交给 Promise,并在其他地方通过关联的 Future 来获取最终的结果。这种方式可以更加灵活地进行异步计算和处理,并提供了更多的控制能力。
总的来说,Promise 是 Scala 中用于设置异步计算结果的类,它的底层源码利用了 Future 和同步机制来实现异步计算的处理。
如何理解Spark中的RDD抽象数据模型
RDD 是 Spark 中最基本的数据抽象和计算模型,它的实现涉及以下几个核心概念和原理:
-
数据分片(Partitioning):RDD 将数据集合切分为多个逻辑分片,每个分片代表了数据的一部分。分片的大小通常会根据数据的大小和集群的规模进行自动调整。
-
弹性分布式数据集(Resilient Distributed Dataset):RDD 将数据分布在集群中的多个节点上,每个节点上可以保存一个或多个数据分片。RDD 具有容错性,即在节点故障时可以恢复丢失的数据分片。
-
转换和动作(Transformations and Actions):RDD 提供了一组转换和动作操作,用于对数据集合进行处理和操作。转换操作(Transformations)是惰性计算的,只记录了要对 RDD 进行的转换操作,并不真正执行计算。动作操作(Actions)则触发实际的计算,并返回结果或副作用。
-
依赖关系(Dependency):RDD 之间的转换操作会构成依赖关系。每个 RDD 都记录了自己的父 RDD 的依赖关系,这样在执行计算时可以通过链式调用进行血缘追踪,以便在需要时重新计算丢失的数据分片。
-
宽依赖和窄依赖(Wide and Narrow Dependencies):依赖关系可以分为宽依赖和窄依赖。窄依赖表示每个父分区最多只被一个子分区使用,这种依赖关系允许并行计算。而宽依赖表示同一个父分区可能被多个子分区使用,这种依赖关系会导致数据的 shuffle 操作,降低了并行度和性能。
-
数据分片的计算和调度:Spark 使用任务调度器将 RDD 的转换操作划分为多个任务,并将这些任务分发到集群中的不同节点上进行计算。计算节点上的任务会根据 RDD 的依赖关系和分片信息进行数据的加载、转换和保存。
-
内存缓存(In-Memory Caching):RDD 可以选择将数据分片缓存在内存中,以便在后续迭代计算中更快地访问。缓存 RDD 可以避免重复计算和磁盘 I/O,提高计算性能。
这些原理使得 RDD 具备了弹性、容错、并行计算和优化的特性,从而能够支持 Spark 的分布式计算和数据处理。通过对 RDD 的转换和动作操作的灵活组合,可以实现复杂的数据处理任务,并通过合理的调度和缓存策略提高计算性能。
相关文章:

spark底层为什么选择使用scala语言开发
Spark 底层使用 Scala 开发有以下几个原因: 基于Scala的语言特性 集成性:Scala 是一种运行在 Java 虚拟机(JVM)上的静态类型编程语言,可以与 Java 代码无缝集成。由于 Spark 涉及到与大量 Java 生态系统的交互&#x…...

基于RabbitMQ的模拟消息队列之三——硬盘数据管理
文章目录 一、数据库管理1.设计数据库2.添加sqlite依赖3.配置application.properties文件4.创建接口MetaMapper5.创建MetaMapper.xml文件6.数据库操作7.封装数据库操作 二、文件管理1.消息持久化2.消息文件格式3.序列化/反序列化4.创建文件管理类MessageFileManager5.垃圾回收 …...

DHorse v1.3.2 发布,基于 k8s 的发布平台
版本说明 新增特性 构建版本、部署应用时的线程池可配置化; 优化特性 构建版本跳过单元测试; 解决问题 解决Vue应用详情页面报错的问题;解决Linux环境下脚本运行失败的问题;解决下载Maven安装文件失败的问题; 升…...
在vue.config.js中配置文件路径代理名
今天在公司项目中看到一个非常有趣的导入路径 crud 先是一蒙 这是个啥 突然想起一个被自己遗漏的知识点 在vue.config.js中配置路径指向 这里 我们随便找一个vue项目 在src下找到 components 目录 如果没有就创建一个 下面找到HelloWorld.vue 如果没有也是自己创建一个就好 然…...

深度学习优化算法相关文章
综述性文章 一个框架看懂优化算法之异同 SGD/AdaGrad/Adam 从 SGD 到 Adam —— 深度学习优化算法概览(一)...

echarts自定义Y轴刻度及其颜色
yAxis: [{min:0,max:5,axisLabel: {color: "#999",textStyle: {fontSize: 14,fontWeight: 400,// 设置分段颜色color: function (value) {console.log("试试", value);if (value 1) {return "rgba(140,198,63,1)";} else if (value 2) {return…...

【云原生进阶之PaaS中间件】第一章Redis-1.3Redis配置
1 Redis配置概述 Redis支持采用其内置默认配置的方式来进行启动,而不需要提前配置任何文件,但是这种启动方式只推荐在测试和开发环境中使用,但更好的方式是通过提供一个Redis的配置文件来对Redis进行配置, 这个配置文件一般命名为…...

C++ 动态内存
C 程序中的内存分为栈和堆两个部分: 栈:在函数内部声明的所有变量都将占用栈内存;堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存。 堆与栈的详细请参考:一文读懂堆与栈的区别_堆和栈的区别_恋…...

swagger 接口测试,用 python 写自动化时该如何处理?
在使用Python进行Swagger接口测试时,可以使用requests库来发送HTTP请求,并使用json库和yaml库来处理响应数据。以下是一个简单的示例代码: import requests import json import yaml# Swagger API文档地址和需要测试的接口路径 swagger_url …...

QT使用QXlsx实现Excel图片与图表操作 QT基础入门【Excel的操作】
构建图表数据 /// 构建图表数据for (int i = 1; i < 10; ++i) {mxlsx.write(i, 1, i * i * i); // A1:A9mxlsx.write(i, 2, i * i); // B1:B9mxlsx.write(i, 3, i * i - 1); // C1:C9} 需要包含头文件 #include "xlsxchart.h" 1. 饼状图 Chart *pieChart = mxlsx.…...

【Python常用函数】一文让你彻底掌握Python中的numpy.clip函数
大数据时代的到来,使得很多工作都需要进行数据挖掘,从而发现更多有利的规律,或规避风险,或发现商业价值。而大数据分析的基础是学好编程语言。本文和你一起来探索Python中的clip函数,让你以最短的时间明白这个函数的原理。也可以利用碎片化的时间巩固这个函数,让你在处理…...
Matlab(GUI程式设计)
目录 1.MatlabGUI 1.1 坐标区普通按钮 1.1.1 对齐组件 1.1.2 按钮属性 1.1.3 脚本说明 1.1.4 选择呈现 1.3 编译GUI程序 在以前的时候,我们的电脑还是这样的 随着科技的不断进步,我们的电脑也发生着翻天覆地的改变1990s: 在未来,…...
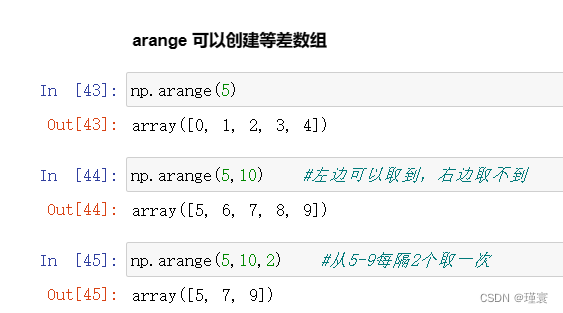
Numpy数组(随时更新)
一、Numpy数组对象的重要属性 #导入库 import numpy as npdata np.arange(12).reshape(4,3)data2 np.arange(24).reshape(3,4,2) #ndim维度个数data.ndimdata2.ndim #shape形状几行几列 数组的维度data.shapedata2.shape#size数组的总个数data.sizedata2.size #dtype数组元素的…...
Spring Cloud--从零开始搭建微服务基础环境【三】
😀前言 本篇博文是关于Spring Cloud–从零开始搭建微服务基础环境【三】,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,…...

HDFS文件的读写流程
Hadoop HDFS的读写文件流程 HDFS写文件流程 客户端通过Distributed FileSystem模块向NameNode请求上传文件(hadoop fs -put 文件名 文件路径 ) 判断该客户端是否有写入权限NameNode检查目标文件是否已存在,父目录是否存在。 NameNode返回是…...
SpringCloudGateway集成SpringDoc
SpringCloudGateway集成SpringDoc 最近在搞Spring版本升级,按客户要求升级Spring版本,原来用着SpringBoot 2.2.X版本,只需要升级SpringBoot 2.X最新版本也就可以满足客户Spring版本安全要求,可是好像最新的SpringBoot 2.X貌似也不…...
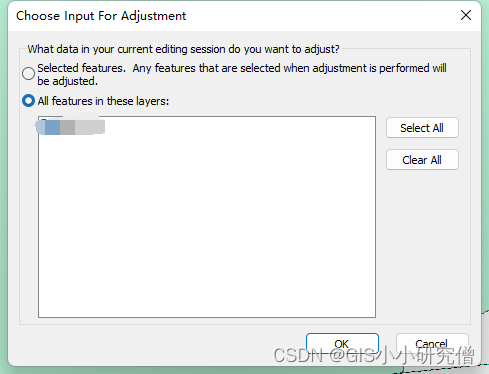
ArcGIS将两个相同范围但不同比例或位置的矢量数据移动到相同位置
有两个市图层,一个是正确经纬度的市行政范围图层,另一个是其他软件导出获取的不正确经纬度信息或缺失信息。 如果单纯的依靠移动图层,使不正确的移动到正确位置需要很久。尝试定义投影等也不能解决。 使用ArcMap 的空间校正工具条ÿ…...

MySQL编写建表语句,如何优雅处理创建时间与更新时间
在 MySQL 中,可以使用 TIMESTAMP 或者 DATETIME 数据类型来存储日期和时间信息,并结合默认值和触发器来实现自动更新 createTime 和 updateTime 字段。 以下是一个示例建表语句,演示如何设置自动更新的 createTime 和 updateTime 字段&#…...
NetSuite as OIDC Provider 演示
书接上回。上次谈了借助第三方身份认证服务SSO登录NetSuite。 NetSuite OIDC、SAML SSO 演示_NetSuite知识会的博客-CSDN博客NetSuite的SSO的策略:第三方的身份认证服务商NetSuite as OIDC Provider。本文演示前者。https://blog.csdn.net/remottshanghai/article/…...

webrtc sdp各字段含义
WebRTC使用Session Description Protocol(SDP)实现传输协议的协商和描述。以下是SDP中常见的字段及其含义: v:协议版本号o:会话创建者的标识符、会话ID、和会话版本号s:会话名称t:会话时间描述…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...
实战选型指南)
别再乱用分支了!Flowable四种网关(排他/并行/包容/事件)实战选型指南
Flowable四大网关实战选型:从混乱到精准的决策艺术当你在设计一个请假审批流程时,是否遇到过这样的困惑:部门经理审批后需要同时通知HR和财务,但某些特殊情况下又需要跳过财务直接归档?这种看似简单的业务需求…...

用STM32CubeMX和HAL库快速上手WS2812B:告别手动计算延时,一键生成驱动框架
基于STM32CubeMX的WS2812B智能灯光控制:从零构建现代化驱动方案在智能硬件和物联网设备快速发展的今天,WS2812B可编程LED灯带因其丰富的色彩表现和简单的单线控制方式,成为创客和工程师们最喜爱的显示组件之一。然而,传统的寄存器…...

Wechat2RSS:微信公众号转RSS订阅工具
文章目录Wechat2RSS:微信公众号转RSS订阅工具Wechat2RSS:微信公众号转RSS订阅工具 ttttmr开源的Wechat2RSS项目,目前在GitHub上获得1409颗Star,项目地址为https://github.com/ttttmr/Wechat2RSS。该工具的核心作用是将微信公众号…...

Unity主题系统设计:状态驱动的主题抽象与自动注入方案
1. 这不是换个颜色那么简单:为什么Unity项目里“换肤”总在发布前夜崩盘?你有没有经历过这样的场景:美术同学凌晨两点发来一套新主题资源包,UI设计师说“这次配色更符合品牌调性”,产品说“上线前必须支持深色模式”&a…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理
碧蓝航线自动化脚本终极指南:3小时学会全自动游戏管理 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝…...

基于随机森林的低成本传感器机器学习校准实践指南
1. 项目概述:当低成本传感器遇上机器学习校准在物联网和智能感知系统铺天盖地的今天,低成本传感器几乎无处不在。从监测办公室的空气质量,到追踪城市街道的噪音污染,再到农业大棚里的温湿度控制,这些价格亲民的“小眼睛…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...