刷新你对Redis持久化的认知
认识持久化
redis是一个内存数据库,数据存储到内存中。而内存的数据是不持久的,要想做到持久化,就需要让redis把数据存储到硬盘上。
因此redis既要在内存上存储一份数据,还要在硬盘上存储一份数据。这样这两份数据在理论上是完全相同的(实际上可能存在一点差异,这取决于咱们怎么进行持久化)。当要插入一个数据的时候,需要同时写入内存和硬盘(实际上怎么写入硬盘有不同的策略);当查询某个数据的时候,直接从内存读取;硬盘的数据只是在redis重启的时候,用来恢复内存中的数据。
redis实现持久化的两种方式
- RDB:定期备份
- AOF:实时备份
RDB
RDB定期的把redis内存中所有数据,给拍个”照片“,生成快照文件写入硬盘中。一旦redis重启,就可以根据刚才的”快照“把内存的数据给恢复回来。
定期的两种方式
手动触发
程序员通过redis客服端,执行特定命令,触发快照的生成
save命令,执行save时,redis会全力投入到生成“快照”中,阻塞redis其他客服端的命令。因此一般不建议使用save命令bgsave命令,并不会影响redis服务器处理其他客服端的请求和命令,通过多进程实现,如下图所示:
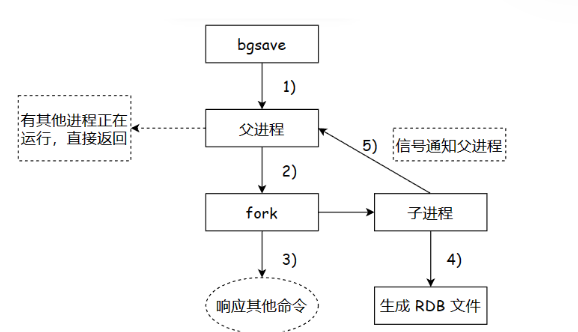
- 执行
bgsave命令,父进程会判断是否存在其他正在执行的子进程,例如RDB/AOF子进程,如果存在,bgsave命令会直接返回 - 父进程执行
fork创建子进程,fork过程中父进程会阻塞,可以通过info status命令查看 latest_fork_usec选项,获取最近一次fork操作耗时,单位ms.
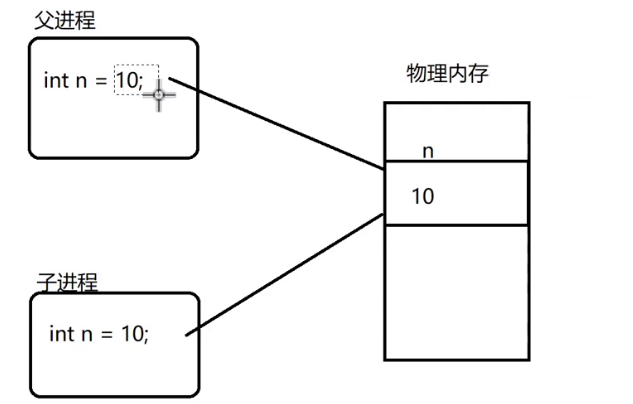
fork是linux提供创建子进程的api,直接把父进程复制一份(pcb,文件描述符表,虚拟地址空间(内存中的数据)),作为子进程。在redis服务器中有若干变量,保存了一些键值对数据,随着fork的进行,子进程内存中也会存在和刚才父进程一样的变量。因此子进程进行“持久化”操作,相当于把父进程的内存数据给持久化了。(父进程打开一个文件,fork之后,子进程也同样使用这个文件;这就导致子进程进行持久化写入的那个文件和父进程本来要写的文件是同一个)
:::tips
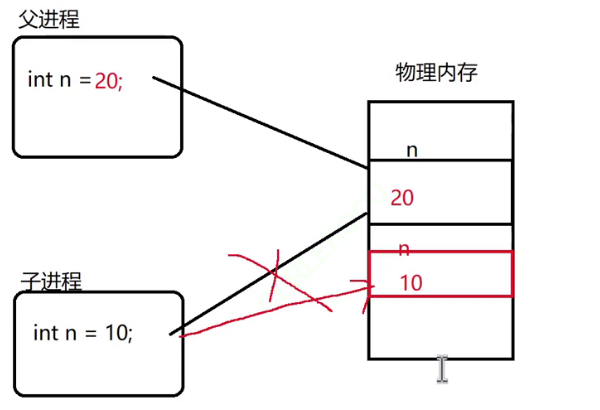
fork的“写时拷贝”机制
:::
父进程进行一些修改
在bgsave这个场景中,绝大部分内存数据是不需要改变的,因此子进程的“写时拷贝”并不会触发很多次,也就保证了整体的“拷贝时间”是可控的
- 父进程fork完成后,
bgsave命令返回"Background saving started"信息,不再阻塞父进程,可以继续响应其他命令 - 子进程创建RDB文件,根据父进程内存生成临时快照文件,完成后对原有文件进行原子替换。执行
lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。 - 进程发送信号给父进程表示完成,父进程更新统计信息
自动触发
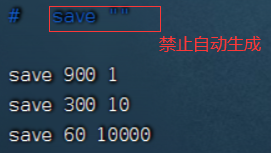
在redis的配置文件redis.conf进行设置,让redis每隔多长时间,每生产多少次修改就触发.
查看redis.conf文件
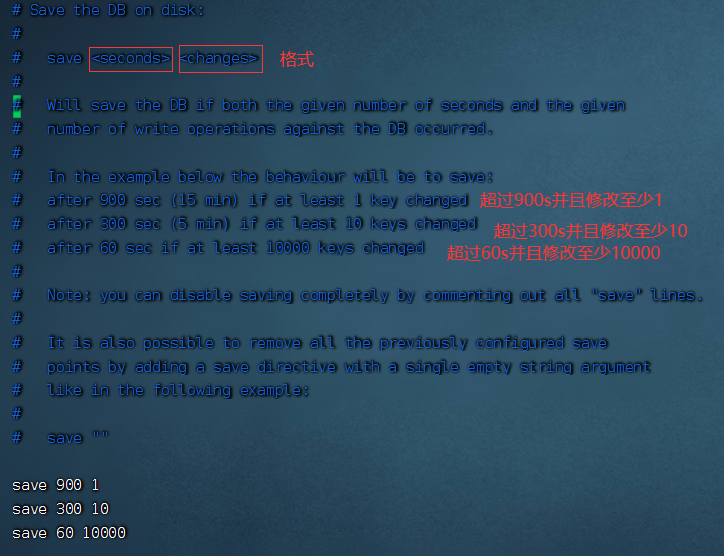
上述数值可以修改配置,但是不能让rdb操作过于频繁,因为生成一次rdb快照是一个成本比较高的成本。
RDB生成的文件
redis生成的rdb文件,存放在redis的工作目录中,可以在redis.conf中查看该工作目录。
:::tips
cd /etc/
vim redis.conf
:::

切换到该工作目录
:::tips
cd /var/lib/redis/
ll
:::
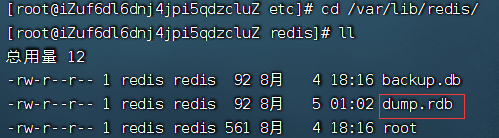
其中dump.rdb即rdb机制生成的镜像文件,redis服务器默认是开启rdb的。dump.rdb是一个二进制文件,redis将内存中的数据,以压缩的形式,保存到这个二进制文件中。
redis默认采用LZF算法对生成的RDB文件做压缩处理,默认开启,可以在redis.conf文件中修改配置

后续redis服务器重新启动,就会加载dump.rdb文件,在加载时会进行校验,redis提供了rdb文件的检查工具redis-check-rdb。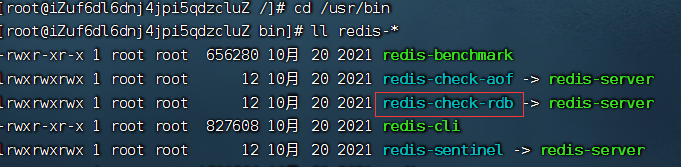
由上图我们发现检查工具和redis服务器在5.0版本是同一个可执行程序,可以在运行的时候加入不同的选项,从而实现不同的功能。例如,运行的时候,加入rdb文件作为命令行参数,此时就是以检查工具的方式运行,不会真的启动redis服务器。
生成RDB文件的方式
- 手动执行
bgsave触发一次生成快照
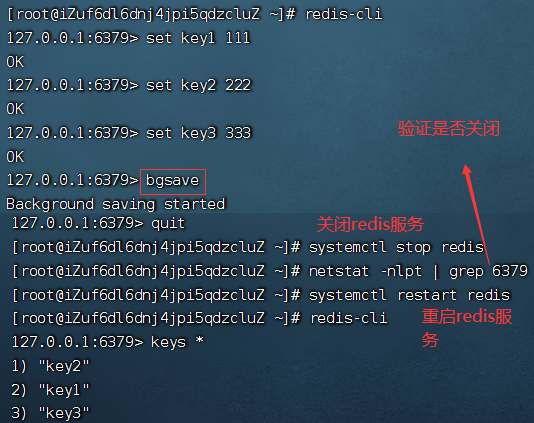
redis服务器重新启动之后,会加载rdb文件的内容,恢复内存中的数据。dump.rdb文件如下,虽然我们看不懂二进制文件,但是能看到key1,key2,key3。
- 插入新的key,不手动执行
bgsave
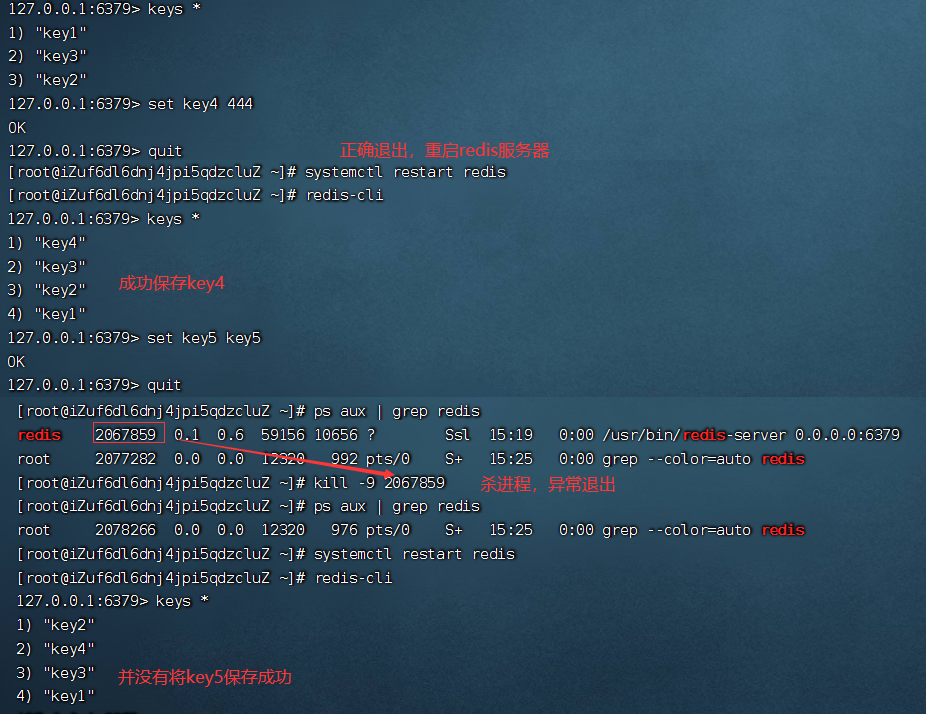
由上图可知,如果是通过正常流程重启redis服务器,此时redis服务器在退出的时候,会自动触发rdb操作;如果是异常重启(kill -9/服务器掉电)此时redis服务器来不及生成rdb,内存中尚未保存到快照中的数据,就会随着重启而丢失。
:::info
redis生成快照,不通过手动执行命令,而是自动触发有如下情况
- 满足配置文件中超过M秒,修改了N次,触发save操作
- 通过
shutdown命令(redis正确关闭服务器的命令)也会触发 - redis进行主从复制的时候,主节点会自动生成rdb快照,然后把rdb快照文件内容传输给从节点
:::
观察生成rdb的过程
bgsave通过创建子进程,让子进程完成持久化操作。持久化会把数据写入新的文件中,然后使用新的文件替换旧的文件。由于持久化速度太快(数据量小),难以观察;而新文件替换旧文件是容易观察的。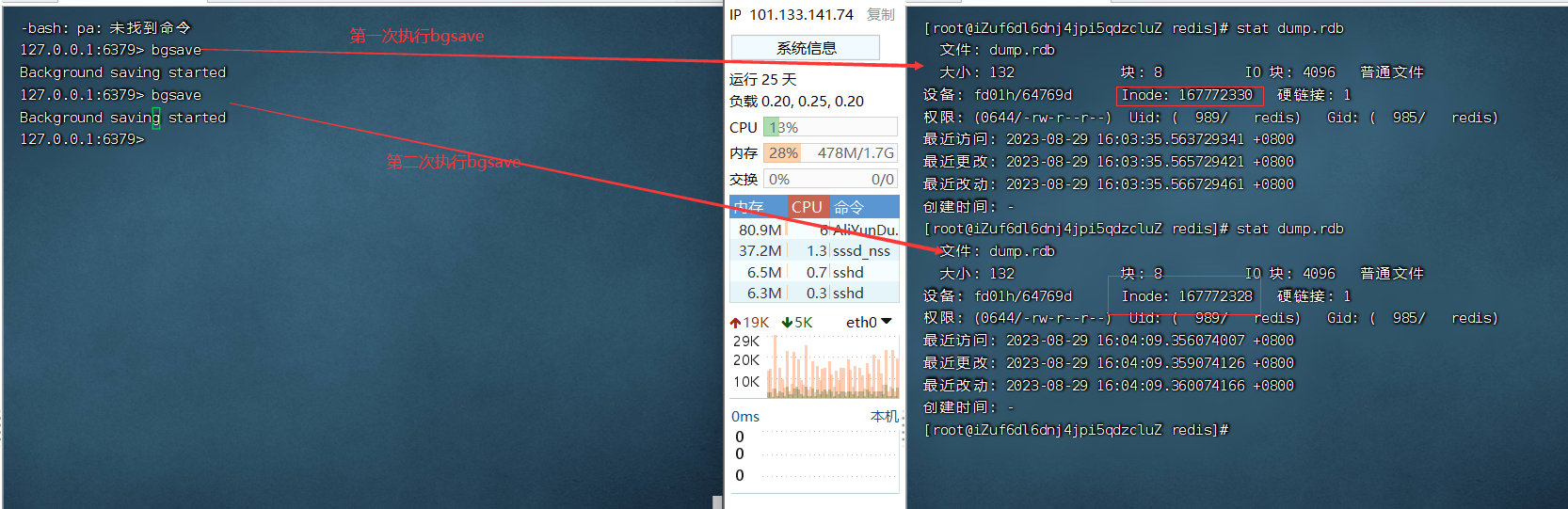
inode编号是文件的身份标识,两次inode编号不同,说明文件并不是同一个文件,只是内容相同。
linux文件系统的组织方式是ext4,主要将整个文件系统分成3个部分
- 超级块,存放一些管理信息
- inode区,存放inode节点,每个文件都会分配一个inode数据结构,包含了文件的各种元数据
- block区,存放文件的数据内容
RDB的优缺点
- RDB是一个压缩的二进制文件,代表redis在某个时间点上的数据快照。非常适合用来备份,全量复制等场景。比如每6个小时执行
bgsave备份,并把rdb文件复制到远程机器或者文件系统中用于备灾 - redis加载rdb恢复数据远快于aof方式。因为rdb使用二进制的方式组织数据,直接把数据读到内存中,按照字节的格式取,放到结构体/对象中即可。而aof是使用文本的方式组织数据,则需要进行一系列的字符串切分操作
- rdb文件使用特定二进制格式保存,当redis版本升级以后,兼容性可能存在风险。
可以遍历旧版本的redis中所有的key,把数据取出来,插入到新的redis服务器中
- rdb最大的问题就是不能实时持久化保存数据,在两次快照之间,实时的数据可能随着重启而丢失
AOF
aof以独立日志的方式记录每次写的命令,重启时在重新执行aof文件中的命令达到恢复数据的目的。aof主要作用是解决数据持久化的实时性问题,是目前redis持久化的主流方式。
使用AOF
开启aof功能需要在配置文件中设置:appendonly yes默认不开启。当开启aof后,rdb就不生效;启动以后不再读取rdb内容。aof文件名通过appendfilename配置文件中设置。aof文件所在位置和rdb文件所在的目录一样,默认/var/lib/redis(可配置)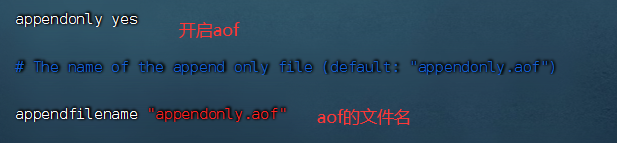
向redis中添加key1,key2,key3
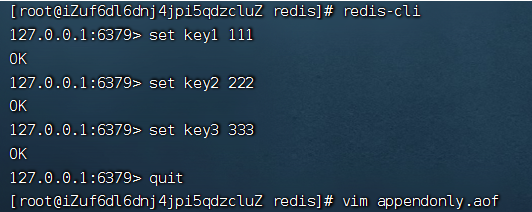
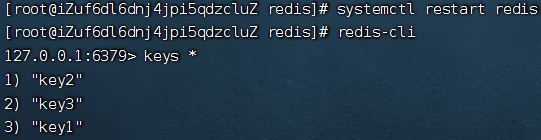
查看appendonly.aof文件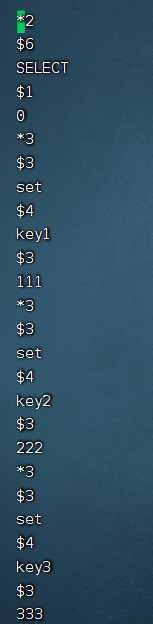
appendonly.aof文件记录了你的每一个操作命令,通过一些特殊符号作为分割符,来对命令的细节做出区分。aof文件的格式是文本格式,因为文本协议具备更好的兼容性,事先简单,具备可读性。
AOF的工作流程
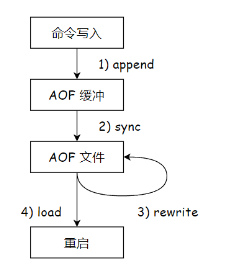
aof-buf缓冲区
引入aof机制,既写内存,有写硬盘,速度还会很快吗?
- aof机制并不是直接让工作线程把数据写入硬盘,而是先写入内存的缓冲区aof_buf,积累一波后,再统一写入硬盘,降低了写硬盘的次数。写硬盘的时候,一次写入硬盘数据的多少,对于性能影响不是很大,但是写入硬盘的次数影响很大。
- 硬盘上读写数据,顺序读写的速度比较快,随机访问的速度比较慢。而aof每次把新的操作写入到原有文件的末尾,属于顺序写入。
把数据写入缓冲区,本质还是在内存中,当进程挂了或者主机掉电,缓冲区的数据会不会丢失?
会,缓冲区中没来得及写入硬盘的数据会丢。
缓冲区的刷新策略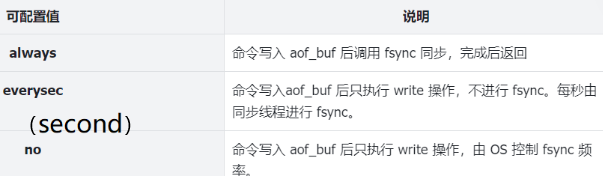
- always:每一步操作立刻同步到aof文件中,频率最高,数据可靠性最高,性能最低
- everysec:每秒将缓冲区的数据写入aof文件,频率低一些,数据可靠性降低一些,性能提高一些,默认采用everysec策略
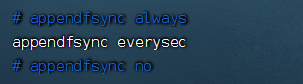
- no:由操作系统来控制什么时候写入aof文件,频率最低,数据可靠性最低,性能最高
重写机制(rewrite)
随着操作的增多,aof文件体积越来越大。redis启动的时候需要读取aof文件内容,这就会影响到redis启动时间。实际上redis启动的时候,只关注最终结果,并不关心aof文件中记录的中间过程,所以aof文件中有一些内容存在冗余。如下所示:
因此redis就引入了“重写机制”,对aof文件进行整理操作,剔除其中的冗余操作,并且合并一些操作,达到给aof文件瘦身的效果。
触发重写机制
- 手动触发:执行
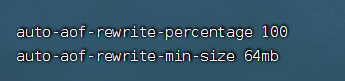
bgrewriteaof命令 - 自动触发:根据
auto-aof-rewrite-min-size和auto-aof-rewirte-percentage参数确定自动触发时机- auto-aof-rewrite-min-size:表示触发重写时aof的最小文件大小,默认是64Mb
- auto-aof-rewrite-percentage:表示当前aof占用大小相比上次重写时增加的比例
AOF重写流程
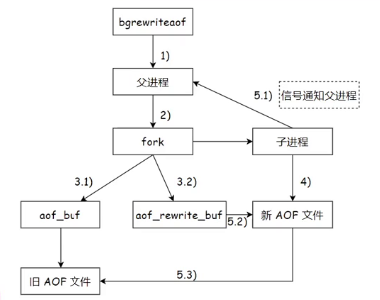
序号2和4的过程
aof重写和rdb生成快照文件一样,都是通过多进程的方式。通过fork创建子进程,父进程负责接收请求,子进程负责针对aof文件进行重写。子进程只需要把当前内存中的数据,获取出来,以aof的格式写入到一个新的aof文件中。因为内存中的数据状态,就相当于把aof文件整理后的结果。此处子进程写数据的过程,类似于rdb生成一个镜像快照。只不过rdb是按照二进制的方式生成的,aof重写则是按照aof要求的文本格式生成的,都是把当前内存的所有数据状态给记录到文件中。
序号3.1的过程
子进程写新aof文件的同时,父进程仍然在不停的接收客服端新的请求,父进程会把这些请求先写入aof_buf缓冲区中,再刷新到原有的aof文件中。
序号3.2,5.1, 5.2, 5.3过程
在创建子进程的一瞬间,子进程继承了当前父进程的内存状态。因此子进程中的内存数据是父进程fork之前的状态,fork之后,新的请求,对内存造成的修改,是子进程不知道的。此时,父进程准备了一个aof_rewrite_buf缓冲区,专门放fork之后的数据。子进程把aof数据写完以后,会通过信号通知一下父进程,父进程再把aof_rewrite_buf缓冲区的内容也写到新的aof文件中,到这就可以用新的aof文件替换旧的aof文件。
什么是信号?
信号是linux的神经系统,是进程间通信的一种手段。信号能表达的信息有限,并不像socket可以传输任意数据,图中子进程向父进程发送一个信号,表示“我已经干完了”。
信号包含3部分
- 信号源:哪个进程发送的
- 信号类型:例如kill -9 表示给指定进程发送9号信号
- 信号的处理函数:接收方接到这个信号触发的行为
如果在执行
bgrewriteaof时,当前redis已经正在进行aof重写,会咋样?
此时,不会再次执行aof重写,直接返回。
如果在执行
bgrewriteaof时,当前redis在生成rdb文件快照,会咋样?
此时aof重写操作会等待,等待rdb快照生成完毕之后,再执行aof重写
父进程fork完成后,子进程开始写入新的aof文件,随着时间推移,子进程写完新的文件后,让新的aof文件替换旧的aof文件。此时父进程仍然继续写入旧的aof文件是否有意义?
预防极端情况,例如服务器挂了,子进程的内存数据都会丢失,新的aof文件内容不完整,所以如果父进程不坚持写入旧的aof文件,重启旧无法保证数据的完整性。
启动时恢复数据
当redis启动时,会根据rdb和aof文件的内容,进行数据恢复,如下图所示: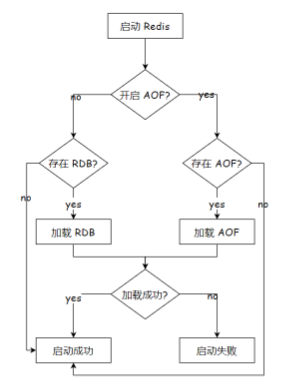
如果开启aof,以aof为主,忽略rdb文件。因为aof中包含的数据比rdb更全。
混合持久化
aof是按照文本的方式写入文件的,导致后续加载的成本较高。因此redis引入“混合持久化”结合了rdb和aof特点,按照aof的方式,把每个请求/操作都记录到文件中,在触发aof重写之后,就会把当前内存的状态按照rdb的二进制格式写入到新的aof文件中,后续再进行的操作,仍然按照aof文本的方式追加到文件后头。
在redis.conf配置文件中开启混合持久化
示例: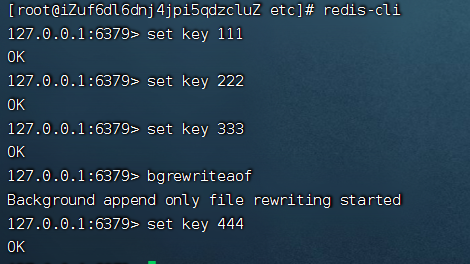
打开appendonly.aof文件
相关文章:
刷新你对Redis持久化的认知
认识持久化 redis是一个内存数据库,数据存储到内存中。而内存的数据是不持久的,要想做到持久化,就需要让redis把数据存储到硬盘上。因此redis既要在内存上存储一份数据,还要在硬盘上存储一份数据。这样这两份数据在理论上是完全相…...

Greenplum-最佳实践小结
注:本文翻译自https://docs.vmware.com/en/VMware-Greenplum/7/greenplum-database/best_practices-logfiles.html 数据模型 Greenplum数据库是一个分析型MPP无共享数据库。该模型与高度规范化/事务性的SMP数据库明显不同。Greenplum数据库使用适合MPP分析处理的非…...
从Gamma空间改为Linear空间会导致性能下降吗
1)从Gamma空间改为Linear空间会导致性能下降吗 2)如何处理没有使用Unity Ads却收到了GooglePlay平台的警告 3)C#端如何处理xLua在执行DoString时候死循环 4)Texture2DArray相关 这是第350篇UWA技术知识分享的推送,精选…...

双轨制的发展,弊端和前景
双轨制是一种经济体制,指两种不同的规则或机制并行运行,以适应不同的市场或客户需求。双轨制最早出现在中国的改革开放中,是从计划经济向市场经济过渡的一种渐进式改革方式。 双轨制的发展可以分为三个阶段: 第一阶段(…...

生成对抗网络(GAN):在图像生成和修复中的应用
文章目录 什么是生成对抗网络(GAN)?GAN在图像生成中的应用图像生成风格迁移 GAN在图像修复中的应用图像修复 拓展应用领域总结 🎉欢迎来到AIGC人工智能专栏~生成对抗网络(GAN):在图像生成和修复…...
扬杰科技携手企企通,召开SRM采购供应链协同系统项目启动会
近日,中国功率半导体领先企业扬州扬杰电子科技股份有限公司(以下简称“扬杰科技”)与企企通召开SRM采购供应链协同系统项目启动会,双方项目团队成员一同出席本次会议。 会上,双方就扬杰科技采购供应链管理平台项目的目…...
AtCoder Beginner Contest 318
目录 A - Full Moon B - Overlapping sheets C - Blue Spring D - General Weighted Max Matching E - Sandwiches F - Octopus A - Full Moon #include<bits/stdc.h> using namespace std; const int N1e65; typedef long long ll ; const int maxv4e65; typedef …...

《Python魔法大冒险》003 两个神奇的魔法工具
魔法师:小鱼,要开始编写魔法般的Python程序,我们首先需要两个神奇的工具:Python解释器和代码编辑器。 小鱼:这两个工具是做什么的? 魔法师:你可以把Python解释器看作是一个魔法棒,只要你向它说出正确的咒语,它就会为你施展魔法。 小鱼:那这个解释器和我之前用的电…...
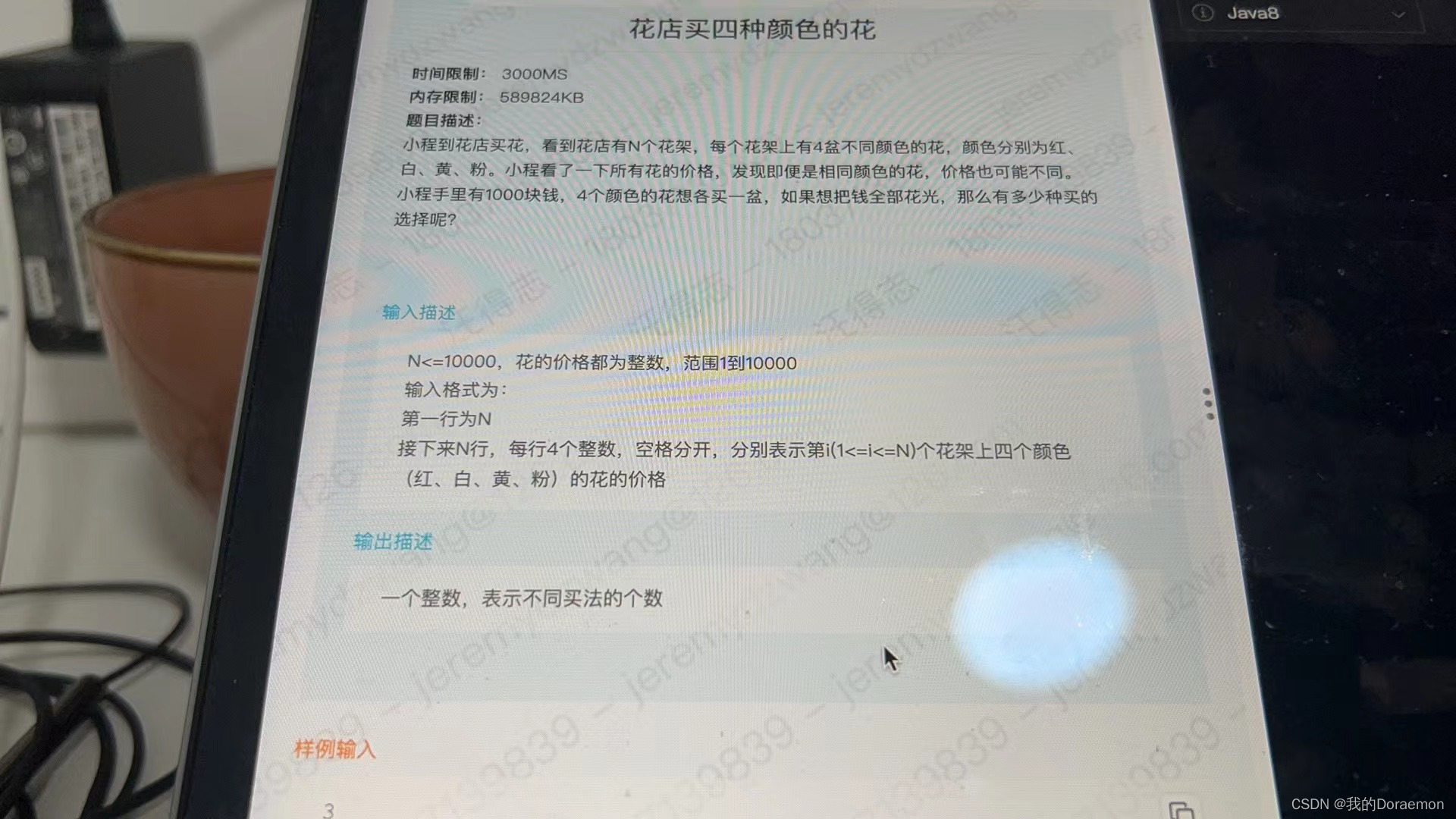
每日一题-动态规划(从不同类型的物品中各挑选一个,使得最后花费总和等于1000)
四种类型的物品,每一种类型物品数量都是n,先要从每种类型的物品中挑选一件,使得最后花费总和等于1000 暴力做法10000^4 看到花费总和是1000,很小且固定的数字,肯定有玄机,从这里想应该是用dp,不…...
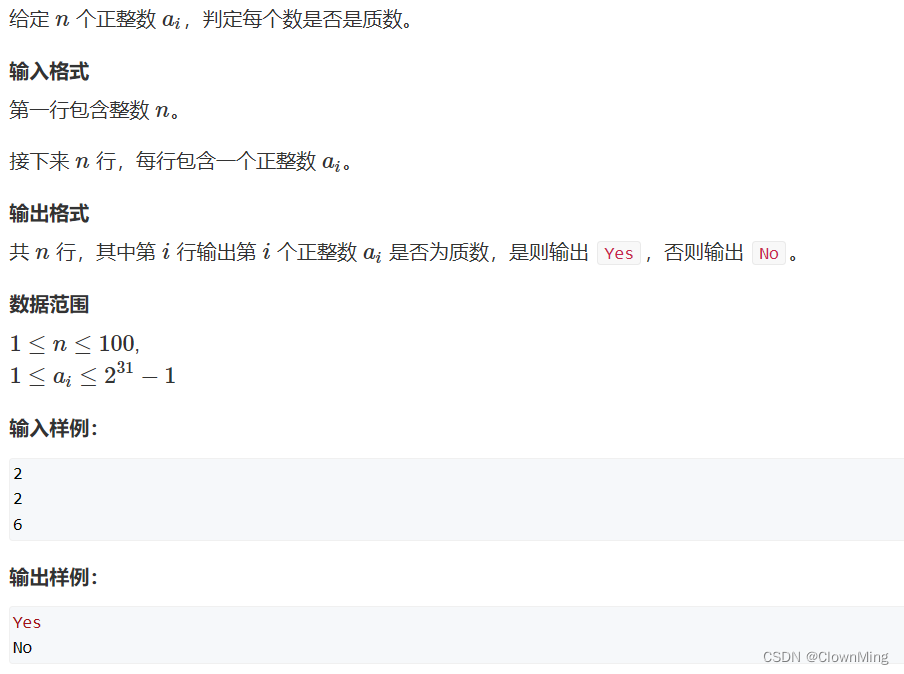
2023-9-3 试除法判定质数
题目链接:试除法判定质数 #include <iostream>using namespace std;bool is_prime(int n) {if(n < 2) return false;for(int i 2; i < n / i; i){if(n % i 0) return false;}return true; }int main() {int n;cin >> n;while(n--){int x;cin &g…...

【Apollo学习笔记】——规划模块TASK之RULE_BASED_STOP_DECIDER
文章目录 前言RULE_BASED_STOP_DECIDER相关配置RULE_BASED_STOP_DECIDER总体流程StopOnSidePassCheckClearDoneCheckSidePassStopIsPerceptionBlockedIsClearToChangeLaneCheckSidePassStopBuildStopDecisionELSE:涉及到的一些其他函数NormalizeAngleSelfRotate CheckLaneChang…...
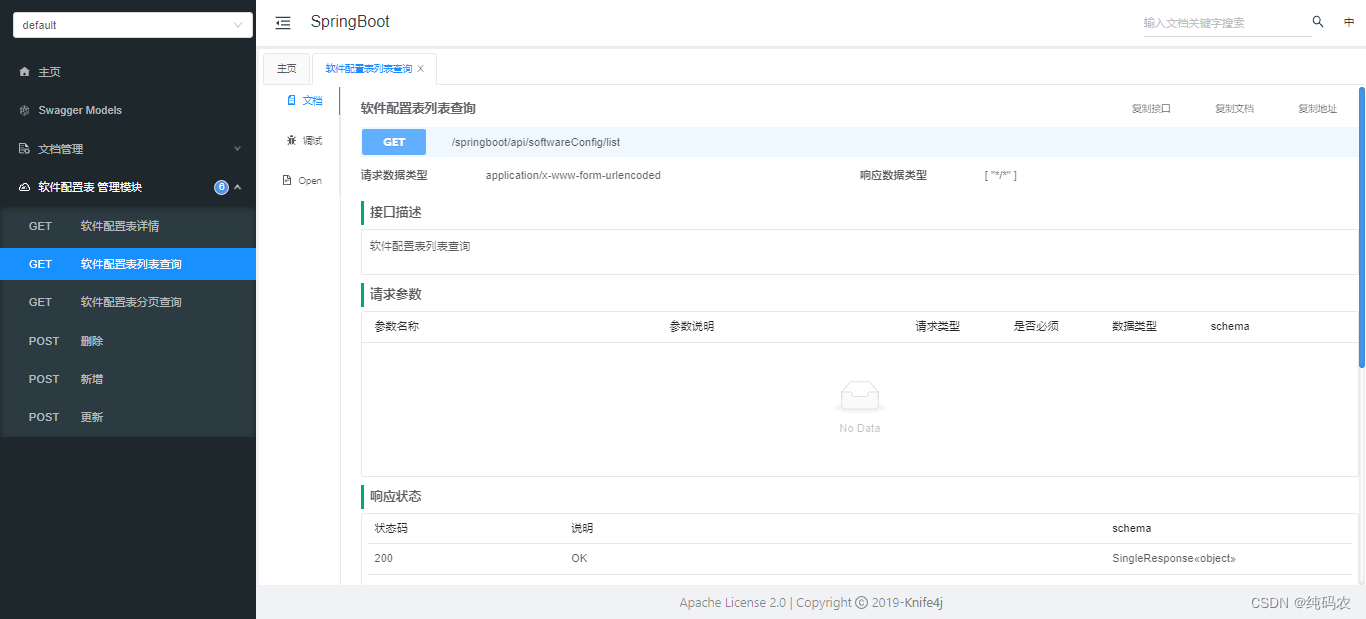
【SpringBoot】最基础的项目架构(SpringBoot+Mybatis-plus+lombok+knife4j+hutool)
汝之观览,吾之幸也! 从本文开始讲下项目中用到的一些框架和技术,最基本的框架使用的是SpringBoot(2.5.10)Mybatis-plus(3.5.3.2)lombok(1.18.28)knife4j(3.0.3)hutool(5.8.21),可以做到代码自动生成,满足最基本的增删查改。 一、新…...
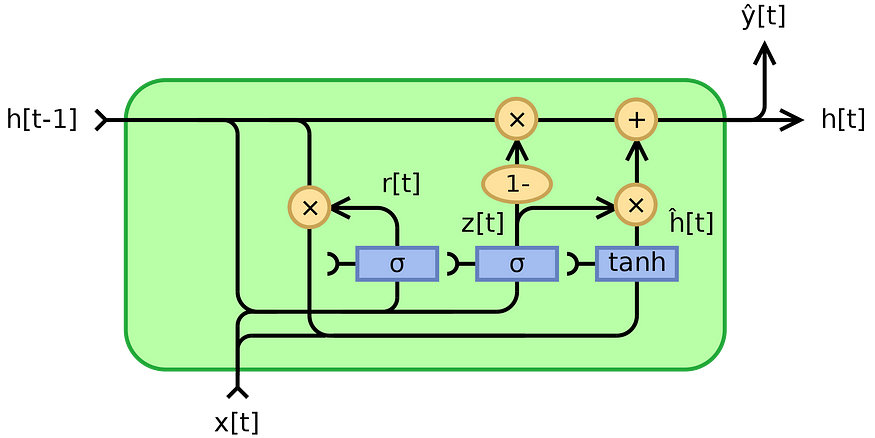
RNN 单元:分析 GRU 方程与 LSTM,以及何时选择 RNN 而不是变压器
一、说明 深度学习往往感觉像是在雪山上找到自己的道路。拥有坚实的原则会让你对做出决定更有信心。我们都去过那里 在上一篇文章中,我们彻底介绍并检查了 LSTM 单元的各个方面。有人可能会争辩说,RNN方法已经过时了,研究它们是没有意义的。的…...
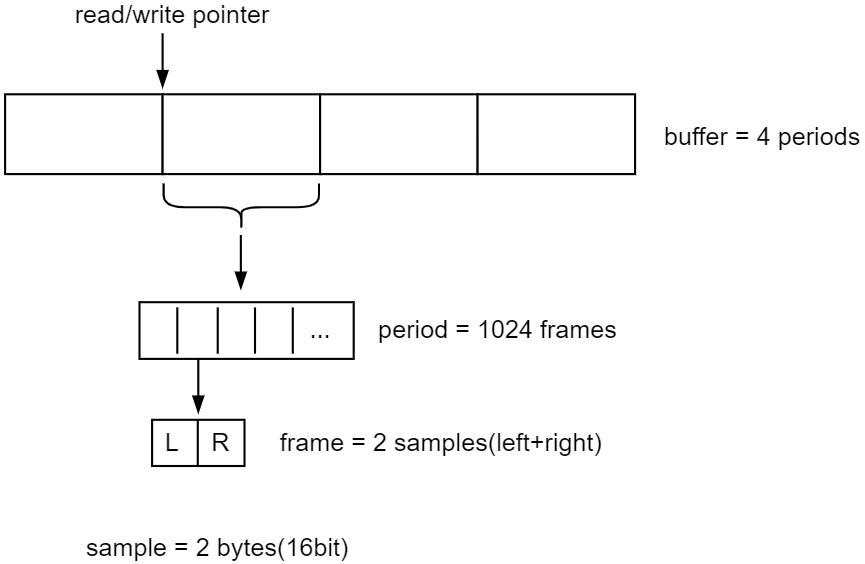
Linux音频了解
ALPHA I.MX6U 开发板支持音频,板上搭载了音频编解码芯片 WM8960,支持播放以及录音功能! 本章将会讨论如下主题内容。 ⚫ Linux 下 ALSA 框架概述; ⚫ alsa-lib 库介绍; ⚫ alsa-lib 库移植; ⚫ alsa-l…...
精心整理了优秀的GitHub开源项目,包含前端、后端、AI人工智能、游戏、黑客工具、网络工具、AI医疗等等,空闲的时候方便看看提高自己的视野
精心整理了优秀的GitHub开源项目,包含前端、后端、AI人工智能、游戏、黑客工具、网络工具、AI医疗等等,空闲的时候方便看看提高自己的视野。 刚开源就变成新星的 igl,不仅获得了 2k star,也能提高你开发游戏的效率,摆…...
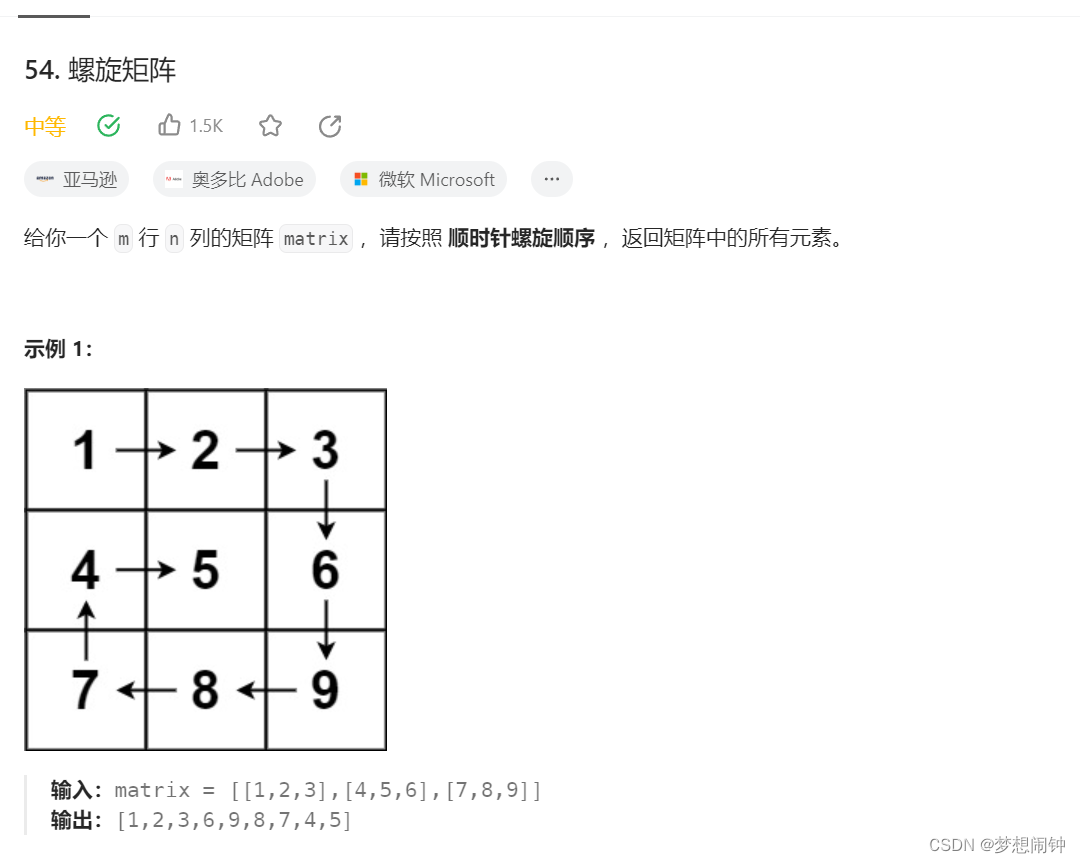
Leetcode54螺旋矩阵
思路:用set记录走过的地方,记下走的方向,根据方向碰壁变换 class Solution:def spiralOrder(self, matrix: list[list[int]]) -> list[int]:max_rows len(matrix)max_cols len(matrix[0])block_nums max_cols * max_rowscount 1i 0j…...

element-plus 表格-方法、事件、属性的使用
记录element-plus 表格的使用。方法、事件、属性的使用。因为是vue3的方式用到了const install getCurrentInstance();才能获取表格的相关信息 没解决怎么获取选中的行的行号,采用自己记的方式实习的。 利用row-class-name"setRowClass"实现样式的简单…...
NVME Linux的查询命令-继续更新
NVME Linux的查询命令 查看NVMe设备 # nvme list 查看nvme controller 支持的一些特性 # nvme id-ctrl /dev/nvme0 查看设备smart log信息 # nvme smart-log /dev/nvme0 查看设备error 信息 # nvme error-log /dev/nvme0 设备的所有命名空间 # nvme list-ns /dev/nvmeX 检…...

pyqt5-自定义文本域1
快捷键支持: CTRL鼠标滚轮实现字体大小调整 支持复制当前行 剪切当前行 # 多行文本框 class TextEdit(QTextEdit):def __init__(self, parentNone):super().__init__(parent)self.setStyleSheet("background-color: #262626;color: #d0d0d0;")self.setFon…...
Go实现LogCollect:海量日志收集系统【上篇——LogAgent实现】
Go实现LogCollect:海量日志收集系统【上篇——LogAgent实现】 下篇:Go实现LogCollect:海量日志收集系统【下篇——开发LogTransfer】 项目架构图: 0 项目背景与方案选择 背景 当公司发展的越来越大,业务越来越复杂…...
)
从一次生产事故复盘:我们如何优雅地处理用户上传的‘异常’Excel文件(附Apache POI配置详解)
从生产事故到防御体系:构建Excel文件处理的工程化解决方案那天凌晨2点,我被一阵急促的告警声惊醒。监控系统显示,核心文件处理服务的错误率在10分钟内飙升到35%,大量用户上传的Excel文件无法正常解析。更糟糕的是,部分…...

AX-MES生产制造管理系统-总览
前言说起 MES 就不得不说 ERP,但是 ERP 大家基本上都知道,MES 就不一定了,常见的 ERP 系统包括 SAP、金蝶、用友等,ERP的流程相对来说也比较统一;MES就不同了,基本上熟悉业务流程的软件公司都可以开发并实施…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...
)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)
从零到上机:我的第一个Quest 3空间锚点应用是如何跑起来的(附完整Unity工程)第一次戴上Meta Quest 3时,那种虚拟与现实交织的震撼感至今难忘。但作为开发者,更让我着迷的是如何让虚拟物体在真实空间中"记住"…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...

为什么你的霓虹总像“塑料灯带”?Midjourney光子散射模拟缺陷曝光:3个被官方隐瞒的--sref调参禁区
更多请点击: https://kaifayun.com 第一章:为什么你的霓虹总像“塑料灯带”? 霓虹效果在现代 UI 设计中无处不在——按钮悬停、加载指示器、焦点高亮……但多数实现却流于表面:生硬的 box-shadow、固定色值的渐变边框、缺乏物理感…...

3步精通WaveTools:鸣潮全场景性能优化终极指南
3步精通WaveTools:鸣潮全场景性能优化终极指南 【免费下载链接】WaveTools 🧰鸣潮工具箱 项目地址: https://gitcode.com/gh_mirrors/wa/WaveTools 开源优化工具WaveTools作为《鸣潮》玩家必备的性能调校助手,通过深度配置优化实现画质…...