Redis 缓存预热+缓存雪崩+缓存击穿+缓存穿透
面试题:
- 缓存预热、雪萌、穿透、击穿分别是什么?你遇到过那几个情况?
- 缓存预热你是怎么做的?
- 如何造免或者减少缓存雪崩?
- 穿透和击穿有什么区别?他两是一个意思还是载然不同?
- 穿适和击穿你有什么解决方案?如何避免?
- 假如出现了缓存不一致,你有哪些修补方案?
- 。。。。。。
缓存预热
@PostConstruct初始化白名单数据
详情地址可查看代码:Redis BitMap/HyperLogLog/GEO/布隆过滤器案例_Please Sit Down的博客-CSDN博客
缓存雪崩
出现原因
- redis主机挂了,redis全盘崩溃,偏硬件运维
- redis中有大量key同时过期大面积失效,偏软件开发
缓存+解决
1、redis中key设置为永不过期 or 过期时间错开
2、redis缓存集群实现高可用
a、主从+哨兵
b、使用Redis集群
c、开启redis持久化机制aof/rdb,尽快恢复缓存集群
3、多缓存结合预防雪崩
ehcache本地缓存 + redis缓存
4、服务降级
Hystrix或者阿里sentinel限流&降级
缓存穿透
是什么
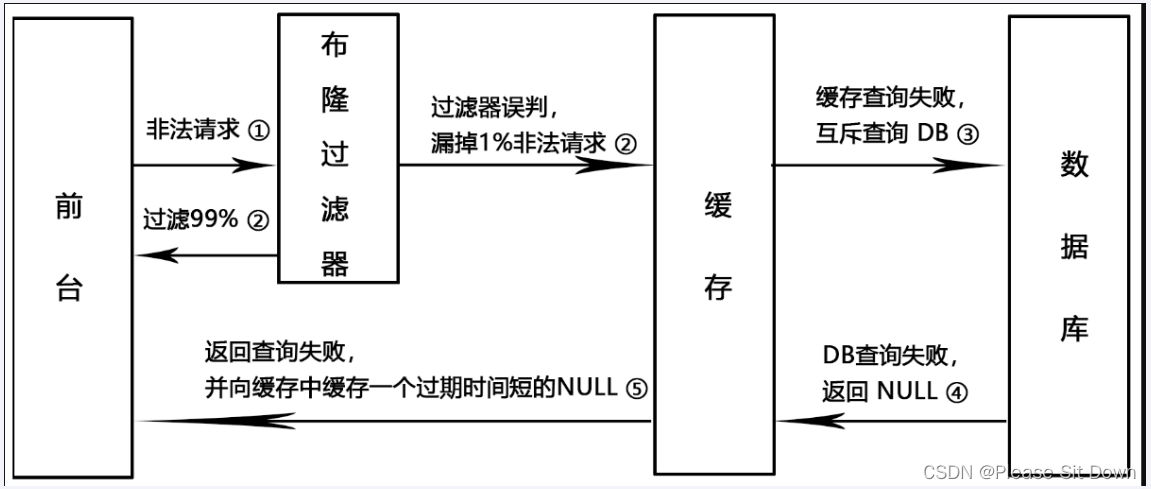
请求去查询一条记录,先查redis无,后查mysq无,都查询不到该条记录,但是清求每次都会打到数据库上面去,导致后台数据库压力暴增。这种现象我们称为缓存穿适,这个redis变成了一个摆设。
简单说就是:本来无物,两库都没有。既不在Redis缓存库,也不在mysql,数据车存在被多次暴击风险。
解决
主要是防止恶意攻击,解决方法:空对象缓存、bloomfilteri过滤器

方案一
空对象缓存或者缺省值。
第一种解决方案,回写增强。如果发生了缓存穿透,我们可以针对要查询的数据,在Redis里存一个和业务部门商量后确定的缺省值(比如,零、负数、defaultNull等)。
比如,键uid:abcdxxx,值defaultNull作为案例的key和value。先去redis查键uid:abcdxxx没有,再去mysql查没有获得 ,这就发生了一次穿透现象。but,可以增强回写机制。mysql也查不到的话也让redis存入刚刚查不到的key并保护mysql。第一次来查询uid:abcdxxx,redis和mysql都没有,返回null给调用者,但是增强回写后第二次来查uid:abcdxxx,此时redis就有值了。可以直接从Redis中读取default缺省值返回给业务应用程序,避免了把大量请求发送给mysql处理,打爆mysql。但是,此方法架不住黑客的恶意攻击,有缺陷......,只能解决key相同的情况。
黑客或者恶意攻击:黑客会对你的系统进行攻击,拿一个不存在的id去查询数据,会产生大量的情求到数据库去查询。可能会导数你的数据库由于压力过大而宕掉。
1、key相同打你系统:第一次打到mysql,空对象缓存后第二次就返回defaultNull缺省值,避免mysql被攻击,不用再到数据车中去走一圈了。
2、key不同打你系统:由于存在空对象缓存和缓存回写(看自己业务不限死),redis中的无关紧要的key也会越写越多(记得设置redisi过期时间)
方案二
使用Google布隆过器Guava解决缓存穿透。
Guava中布隆过滤器的实现算是比较权威的,所以实际项目中我们可以直接使用Guava布隆过滤器。
Guava's BloomFilter源码出处:https://github.com/google/guava/blob/master/guava/src/com/google/common/hash/BloomFilter.java
白名单过滤器案例:

说明:会出现误判问题,但是概率小可以接受,不能从布隆过滤器删除;全部合法的key都需要放入Guava版布隆过滤器+redis里面,不然数据就是返回null。
代码实现:
pom.xml
<!--guava Google 开源的 Guava 中自带的布隆过滤器-->
<dependency><groupId>com.google.guava</groupId><artifactId>guava</artifactId><version>23.0</version>
</dependency>yml
server.port=7777
spring.application.name=redis7# ========================redis单机=====================
spring.redis.database=0
# 修改为自己真实IP
spring.redis.host=192.168.111.185
spring.redis.port=6379
spring.redis.password=111111
spring.redis.lettuce.pool.max-active=8
spring.redis.lettuce.pool.max-wait=-1ms
spring.redis.lettuce.pool.max-idle=8
spring.redis.lettuce.pool.min-idle=0
测试1:
@Test
public void testGuavaWithBloomFilter(){// 创建布隆过滤器对象BloomFilter<Integer> filter = BloomFilter.create(Funnels.integerFunnel(), 100);// 判断指定元素是否存在System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));// 将元素添加进布隆过滤器filter.put(1);filter.put(2);System.out.println(filter.mightContain(1));System.out.println(filter.mightContain(2));
}// 结果
// false false // true true测试2:取样本100W数据,查查不在100W范围内,其它10W数据是否存在
controller
import com.atguigu.redis7.service.GuavaBloomFilterService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;@Api(tags = "google工具Guava处理布隆过滤器")
@RestController
@Slf4j
public class GuavaBloomFilterController{@Resourceprivate GuavaBloomFilterService guavaBloomFilterService;@ApiOperation("guava布隆过滤器插入100万样本数据并额外10W测试是否存在")@RequestMapping(value = "/guavafilter",method = RequestMethod.GET)public void guavaBloomFilter() {guavaBloomFilterService.guavaBloomFilter();}
}service
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;import java.util.ArrayList;
import java.util.List;@Service
@Slf4j
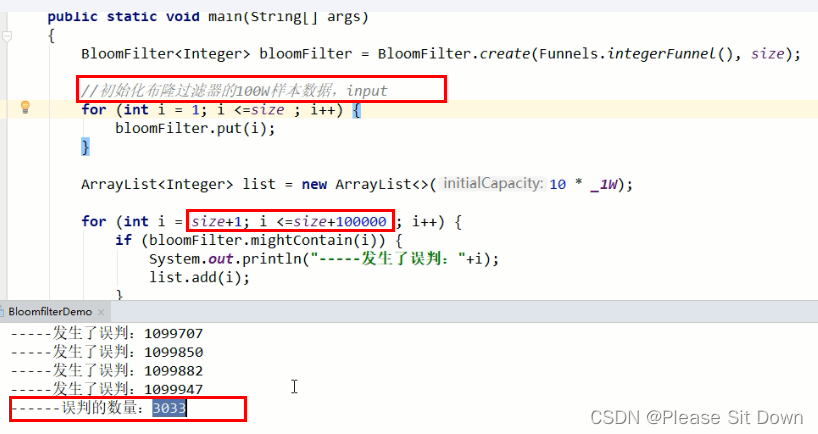
public class GuavaBloomFilterService{public static final int _1W = 10000;//布隆过滤器里预计要插入多少数据public static int size = 100 * _1W;//误判率,它越小误判的个数也就越少(思考,是不是可以设置的无限小,没有误判岂不更好)//fpp the desired false positive probabilitypublic static double fpp = 0.03;// 构建布隆过滤器private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), size,fpp);public void guavaBloomFilter(){//1 先往布隆过滤器里面插入100万的样本数据for (int i = 1; i <=size; i++) {bloomFilter.put(i);}//故意取10万个不在过滤器里的值,看看有多少个会被认为在过滤器里List<Integer> list = new ArrayList<>(10 * _1W);for (int i = size+1; i <= size + (10 *_1W); i++) {if (bloomFilter.mightContain(i)) {log.info("被误判了:{}",i);list.add(i);}}log.info("误判的总数量::{}",list.size());}
}结果:
现在总共有10万数据是不存在的,误判了3033次,原始样本:100W
不存在数据:1000000W---1100000W
误判率:3033 / 100000 = 0.03033
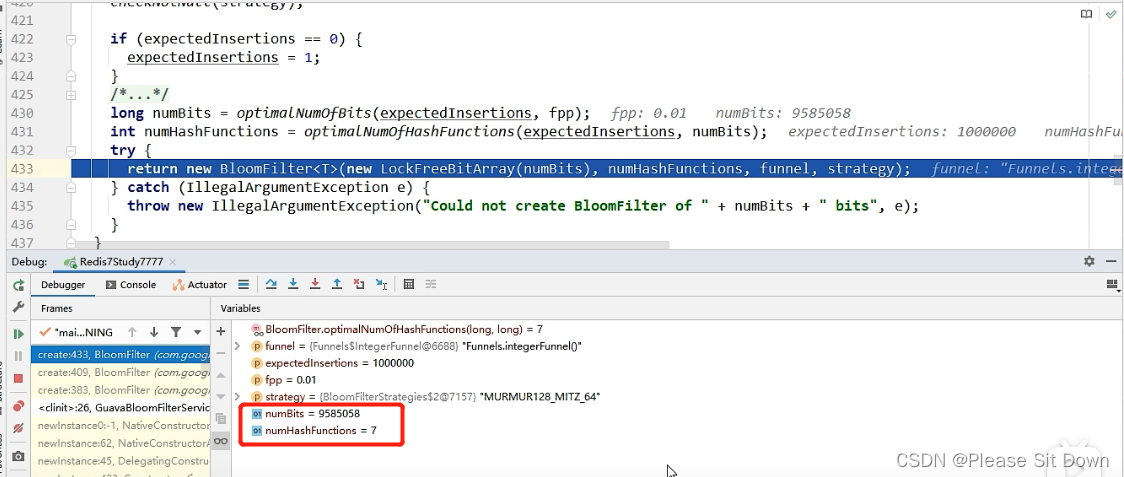
深刻分析代码:核心BloomFilter.create方法
@VisibleForTestingstatic <T> BloomFilter<T> create(Funnel<? super T> funnel, long expectedInsertions, double fpp, Strategy strategy) {。。。。
}这里有四个参数:
-
funnel:数据类型(通常是调用Funnels工具类中的) -
expectedInsertions:指望插入的值的个数 -
fpp:误判率(默认值为0.03) -
strategy:哈希算法
问题:为什么fpp设置成0.03?
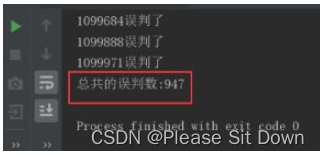
情景一:fpp = 0.01
- 误判个数:947
- 占内存大小:9585058位数
- 解决的hash冲突函数:7个
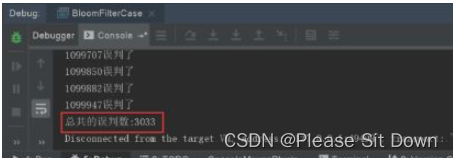
情景二:fpp = 0.03(默认参数)
- 误判个数:3033
- 占内存大小:7298440位数
- 解决的hash冲突函数:5个

情景三:fpp=0.000000000000001
- 占用内存大小:67095408位数
- 解决的hash冲突函数:47个
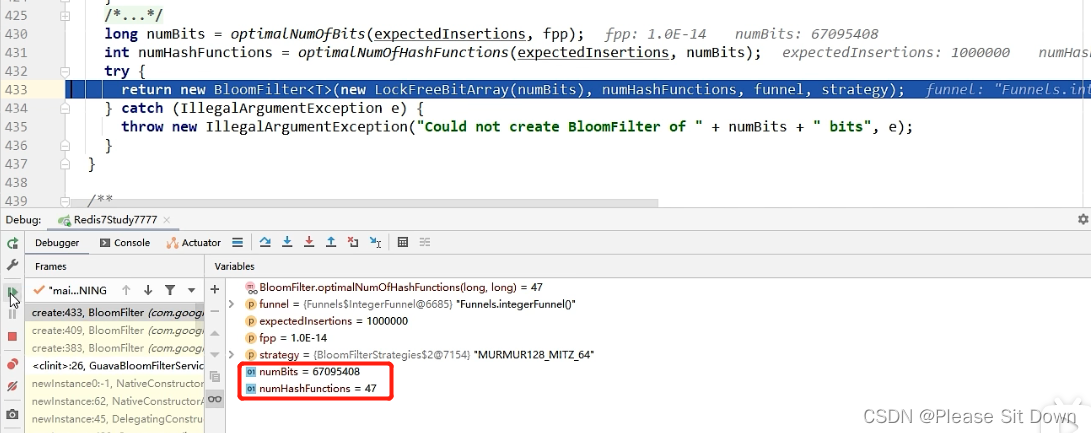
情景总结:
- 误判率能够经过fpp参数进行调节
- fpp越小,须要的内存空间就越大:0.01须要900多万位数,0.03须要700多万位数。
- fpp越小,集合添加数据时,就须要更多的hash函数运算更多的hash值,去存储到对应的数组下标里。(忘了去看上面的布隆过滤存入数据的过程)
上面的numBits,表示存一百万个int类型数字,须要的位数为7298440,700多万位。理论上存一百万个数,一个int是4字节32位,须要481000000=3200万位。若是使用HashMap去存,按HashMap50%的存储效率,须要6400万位。能够看出BloomFilter的存储空间很小,只有HashMap的1/10左右。
上面的numHashFunctions表示须要几个hash函数运算,去映射不一样的下标存这些数字是否存在(0 or 1)。
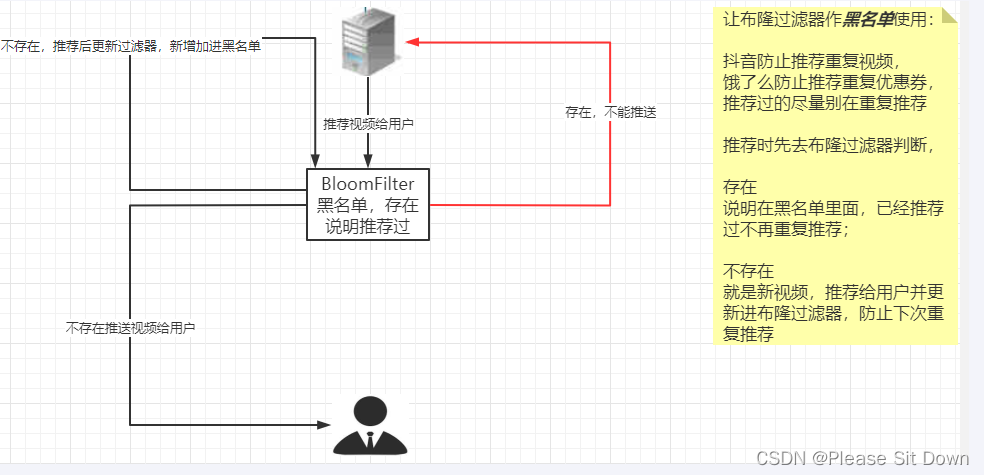
布隆过滤器说明:
黑名单过滤器案例:
缓存击穿
是什么
大量的请求同时查询一个key时,此时这个key正好失效了,就会导致大量的请求都打到数据库上面去。简单说就是热点key突然失效了,暴打mysql
备注:穿透和击穿,截然不同。
危害
会造成某一时刻数据库请求量过大,压力剧增。
一般技术部门需要知道热点key是那些个?做到心里有数防止击穿
解决
互斥更新、随机退避、差异失效时间
热点key失效问题:时间到了自然清除但还波访问到;delete掉的key,刚I巧又被访问
方案1:差异失效时间,对于访问须繁的热点key,干脆就不设置过期时间
方案2:互斥跟新,采用双检加锁策略
多个线程同时去查询数据库的这条数据,那么我们可以在第一个查询数据的请求上使用一个 互斥锁来锁住它。其他的线程走到这一步拿不到锁就等着,等第一个线程查询到了数据,然后做缓存。后面的线程进来发现已经有缓存了,就直接走缓存。
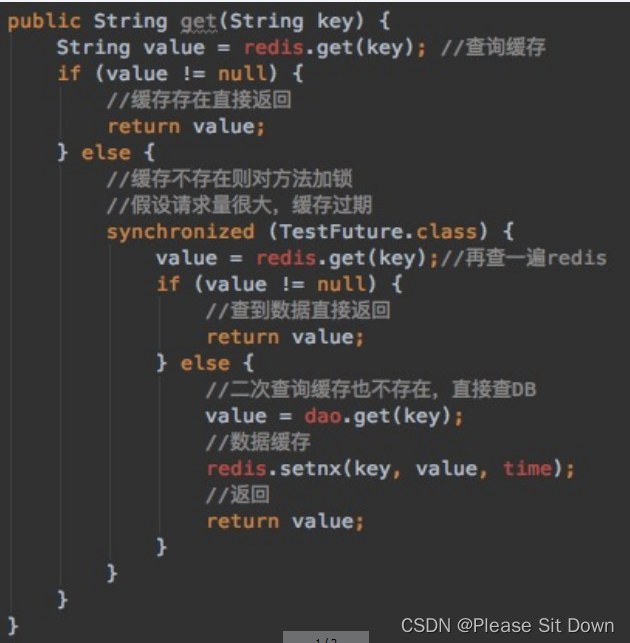
案例
天猫聚划算功能实现+防止缓存击穿(热点key突然失效导致了缓存击穿)
定时任务每次取20条记录,取的过程中,突然失效,大量数据打到mysql

redis数据类型选型:list
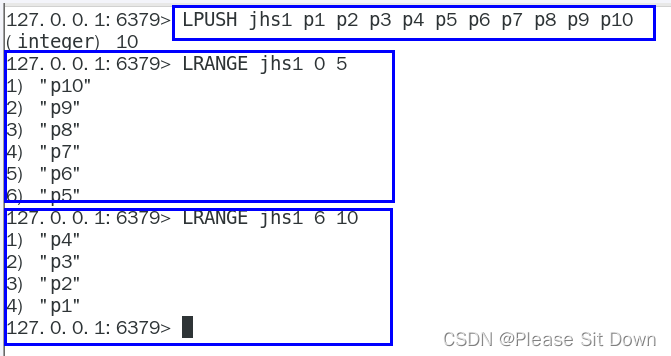
常规代码
entity
import io.swagger.annotations.ApiModel;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;@Data
@AllArgsConstructor
@NoArgsConstructor
@ApiModel(value = "聚划算活动producet信息")
public class Product {//产品IDprivate Long id;//产品名称private String name;//产品价格private Integer price;//产品详情private String detail;
}service:采用定时器将参与聚划算活动的特价商品新增进入redis中
import cn.hutool.core.date.DateUtil;
import com.atguigu.redis7.entities.Product;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;@Service
@Slf4j
public class JHSTaskService {public static final String JHS_KEY="jhs";public static final String JHS_KEY_A="jhs:a";public static final String JHS_KEY_B="jhs:b";@Autowiredprivate RedisTemplate redisTemplate;/*** 偷个懒不加mybatis了,模拟从数据库读取100件特价商品,用于加载到聚划算的页面中* @return*/private List<Product> getProductsFromMysql() {List<Product> list=new ArrayList<>();for (int i = 1; i <=20; i++) {Random rand = new Random();int id= rand.nextInt(10000);Product obj=new Product((long) id,"product"+i,i,"detail");list.add(obj);}return list;}@PostConstructpublic void initJHS(){log.info("启动定时器淘宝聚划算功能模拟.........."+ DateUtil.now());new Thread(() -> {//模拟定时器一个后台任务,定时把数据库的特价商品,刷新到redis中while (true){//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中List<Product> list=this.getProductsFromMysql();//采用redis list数据结构的lpush来实现存储this.redisTemplate.delete(JHS_KEY);//lpush命令this.redisTemplate.opsForList().leftPushAll(JHS_KEY,list);//间隔一分钟 执行一遍,模拟聚划算每3天刷新一批次参加活动try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }log.info("runJhs定时刷新..............");}},"t1").start();}
}
controller
import com.atguigu.redis7.entities.Product;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;@RestController
@Slf4j
@Api(tags = "聚划算商品列表接口")
public class JHSProductController {public static final String JHS_KEY="jhs";@Autowiredprivate RedisTemplate redisTemplate;/*** 分页查询:在高并发的情况下,只能走redis查询,走db的话必定会把db打垮* @param page* @param size* @return*/@RequestMapping(value = "/pruduct/find",method = RequestMethod.GET)@ApiOperation("按照分页和每页显示容量,点击查看")public List<Product> find(int page, int size) {List<Product> list=null;long start = (page - 1) * size;long end = start + size - 1;try {//采用redis list数据结构的lrange命令实现分页查询list = this.redisTemplate.opsForList().range(JHS_KEY, start, end);if (CollectionUtils.isEmpty(list)) {//TODO 走DB查询}log.info("查询结果:{}", list);} catch (Exception ex) {//这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}
}至此步骤,上述聚划算的功能算是完成,请思考在高并发下有什么经典生产问题?
答案:热点k突然失效导致可怕的缓存击穿,delete命令执行的一瞬间有空隙,其它请求线程继续找Redis为null,打到了mysql,暴击…
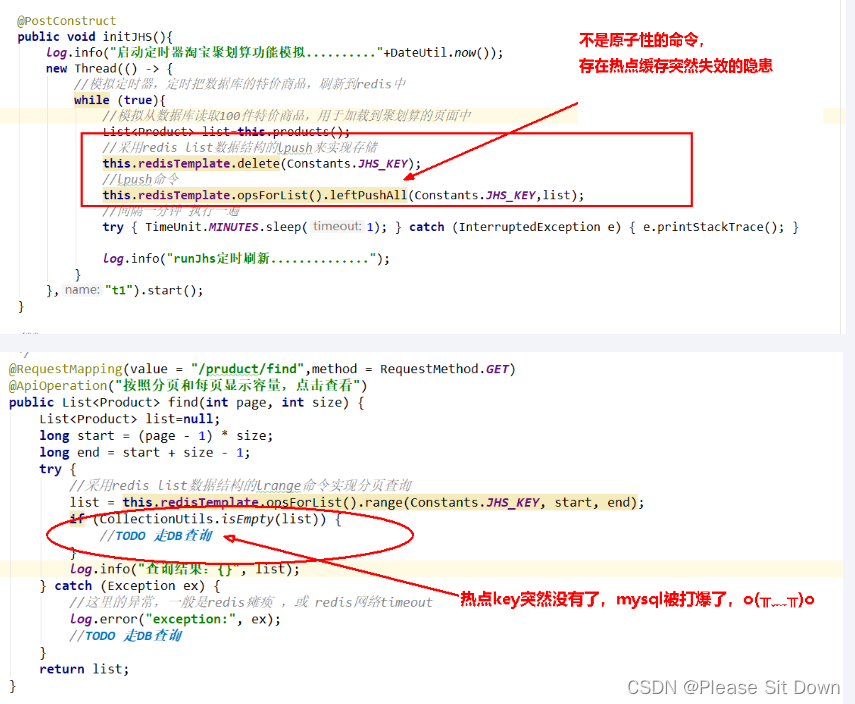
最终目的:2条命令原子性还是其次,主要是防止热key突然失效暴击mysq打爆系统
加固代码
采用差异失效时间
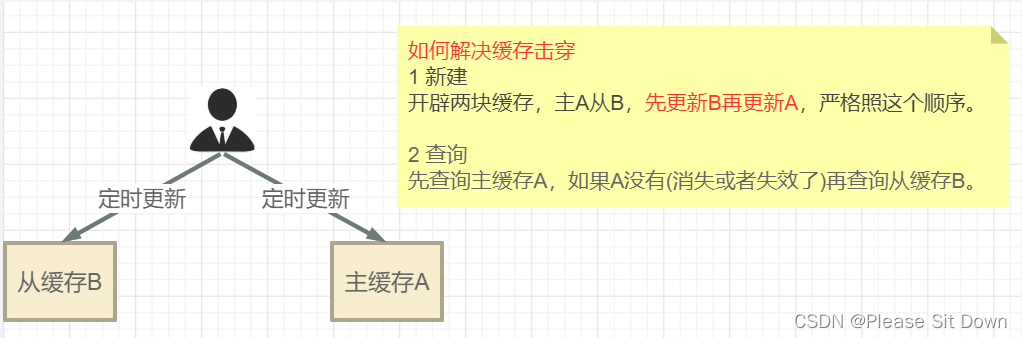
sevice
import cn.hutool.core.date.DateUtil;
import com.atguigu.redis7.entities.Product;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import javax.annotation.PostConstruct;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.TimeUnit;@Service
@Slf4j
public class JHSTaskService {public static final String JHS_KEY_A="jhs:a";public static final String JHS_KEY_B="jhs:b";@Autowiredprivate RedisTemplate redisTemplate;/*** 偷个懒不加mybatis了,模拟从数据库读取100件特价商品,用于加载到聚划算的页面中* @return*/private List<Product> getProductsFromMysql() {List<Product> list=new ArrayList<>();for (int i = 1; i <=20; i++) {Random rand = new Random();int id= rand.nextInt(10000);Product obj=new Product((long) id,"product"+i,i,"detail");list.add(obj);}return list;}@PostConstructpublic void initJHSAB(){log.info("启动AB定时器计划任务淘宝聚划算功能模拟.........."+DateUtil.now());new Thread(() -> {//模拟定时器,定时把数据库的特价商品,刷新到redis中while (true){//模拟从数据库读取100件特价商品,用于加载到聚划算的页面中List<Product> list=this.getProductsFromMysql();//先更新B缓存this.redisTemplate.delete(JHS_KEY_B);this.redisTemplate.opsForList().leftPushAll(JHS_KEY_B,list);this.redisTemplate.expire(JHS_KEY_B,20L,TimeUnit.DAYS);//再更新A缓存this.redisTemplate.delete(JHS_KEY_A);this.redisTemplate.opsForList().leftPushAll(JHS_KEY_A,list);this.redisTemplate.expire(JHS_KEY_A,15L,TimeUnit.DAYS);//间隔一分钟 执行一遍try { TimeUnit.MINUTES.sleep(1); } catch (InterruptedException e) { e.printStackTrace(); }log.info("runJhs定时刷新双缓存AB两层..............");}},"t1").start();}
}
controller
import com.atguigu.redis7.entities.Product;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.util.CollectionUtils;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;@RestController
@Slf4j
@Api(tags = "聚划算商品列表接口")
public class JHSProductController {public static final String JHS_KEY_A="jhs:a";public static final String JHS_KEY_B="jhs:b";@Autowiredprivate RedisTemplate redisTemplate;@RequestMapping(value = "/pruduct/findab",method = RequestMethod.GET)@ApiOperation("防止热点key突然失效,AB双缓存架构")public List<Product> findAB(int page, int size) {List<Product> list=null;long start = (page - 1) * size;long end = start + size - 1;try {//采用redis list数据结构的lrange命令实现分页查询list = this.redisTemplate.opsForList().range(JHS_KEY_A, start, end);if (CollectionUtils.isEmpty(list)) {log.info("=========A缓存已经失效了,记得人工修补,B缓存自动延续5天");//用户先查询缓存A(上面的代码),如果缓存A查询不到(例如,更新缓存的时候删除了),再查询缓存Bthis.redisTemplate.opsForList().range(JHS_KEY_B, start, end);//TODO 走DB查询}log.info("查询结果:{}", list);} catch (Exception ex) {//这里的异常,一般是redis瘫痪 ,或 redis网络timeoutlog.error("exception:", ex);//TODO 走DB查询}return list;}
}总结
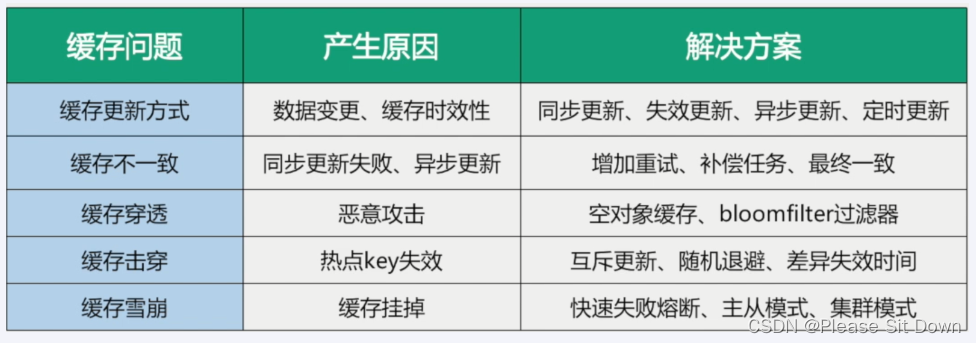
相关文章:
Redis 缓存预热+缓存雪崩+缓存击穿+缓存穿透
面试题: 缓存预热、雪萌、穿透、击穿分别是什么?你遇到过那几个情况?缓存预热你是怎么做的?如何造免或者减少缓存雪崩?穿透和击穿有什么区别?他两是一个意思还是载然不同?穿适和击穿你有什么解…...

java 面试题汇总整理
java有哪四种引用类型 在Java中,有四种引用类型,用于控制对象的生命周期和垃圾回收行为。这些引用类型包括: 强引用(Strong Reference): 强引用是最常见的引用类型,它们是默认的引用类型。当一…...

淘宝开放平台免审核接入 获取淘宝卖家订单列表订单详情API
taobao.open.trades.sold.get 搜索当前会话用户作为卖家已卖出的交易数据(只能获取到三个月以内的交易信息) 1. 返回的数据结果是以订单的创建时间倒序排列的。 注意:type字段的说明,如果该字段不传,接口默认只查4种类…...

Mybatis中的关系映射
1.一对一的映射关系 一对一关系(One-to-One)表示两个实体对象之间存在唯一的关联关系。例如,一个学生只能拥有一个身份证。在 MyBatis 中,我们可以使用结果嵌套或一对一映射来处理一对一关系。 1.1 创建模型类和Vo类 package com…...
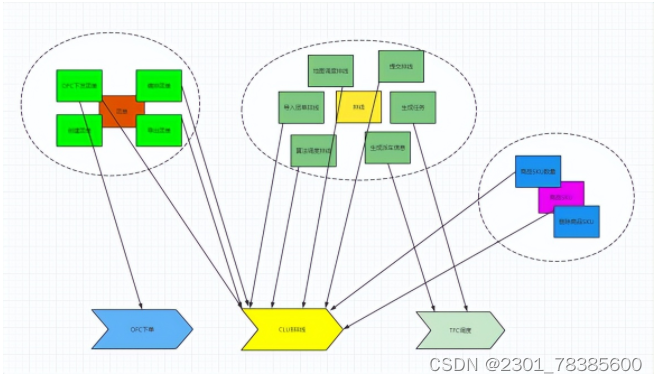
领域建模之数据模型设计方法论
本文通过实际业务需求场景建模案例,为读者提供一种业务模型向数据模型设计的方法论,用于指导实际开发中如何进行业务模型向数据模型转化抽象,并对设计的数据模型可用性、扩展性提供了建议性思考。通过文章,读者可以收获到业务模型…...

springboot毕业生信息招聘平台设计与实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 毕业生信息招聘平台,主要的模块包括查看管理员;首页、个人中心、企业管理、空中宣讲会管理、招聘岗位管理、毕业生管理…...
开发前期准备工作
开发前期准备工作 文章目录 开发前期准备工作0 代码规范0.1 强制0.2 推荐0.3 参考dao:跟数据库打交道service:业务层,人类思维解决controller:抽象化 0.4 注释规范0.5 日志规范0.6 专有名词0.7 控制层统一异常统一结构体控制层提示…...

k8s deployment服务回滚,设置节点为不可调度
服务回滚 通过滚动升级的策略可以平滑的升级Deployment,若升级出现问题,需要最快且最好的方式回退到上一次能够提供正常工作的版本。为此K8S提供了回滚机制。 revision:更新应用时,K8S都会记录当前的版本号,即为revi…...

信息系统安全运维和管理指南
声明 本文是学习 信息系统安全运维管理指南. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 安全运维支撑系统 信息系统安全服务台 目的 对信息系统安全事件进行统一监控与处理。 要求 建立一个集中的信息系统运行状态收集、处理、显示及报警的系…...

现货黄金代理好吗?
做黄金代理这个职业好吗?从目前的市场现状来看,其实做黄金代理很不错的。在股票市场中,投资者只能通过买涨进盈利,所以当市场行情不好的时候,股票经纪人的业务将很难展开,而现货黄金投资者不一样࿰…...
BCSP-玄子Share-Java框基础_双系统Redis安装与基础语法
四、Redis 4.1 Redis 简介 Redis 是开源、高性能的key-value数据库,属于 NoSQL 数据库 NoSQL 数据库与关系型数据库 关系型数据库:采用关系模型来组织数据,主要用于存储格式化的数据结构NoSQL 数据库:泛指非关系型数据库&…...

android system_server WatchDog简介
简介 android系统中SystemServer WatchDog的主要作用是监控SystemServer进程的运行状态,防止其卡住或者死锁。 具体来说,watchDog线程会定期去检查SystemServer线程的运行情况。如果发现SystemServer线程超过一定时间未有响应,watchDog会认为SystemServer进程发生了问题,这时…...
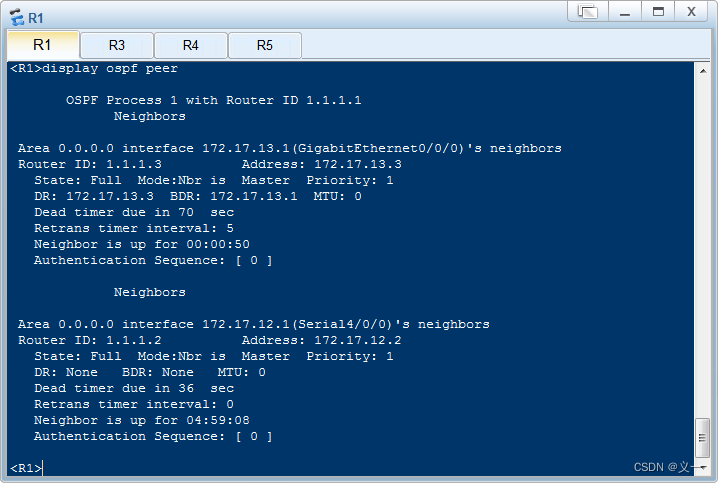
华为---OSPF协议优先级、开销(cost)、定时器简介及示例配置
OSPF协议优先级、开销、定时器简介及示例配置 路由协议优先级:由于路由器上可能同时运行多种动态路由协议,就存在各个路由协议之间路由信息共享和选择的问题。系统为每一种路由协议设置了不同的默认优先级,当在不同协议中发现同一条路由时&am…...

MEMORY-VQ: Compression for Tractable Internet-Scale Memory
本文是深度学习相关文章,针对《MEMORY-VQ: Compression for Tractable Internet-Scale Memory》的翻译。 MEMORY-VQ:可追溯互联网规模存储器的压缩 摘要1 引言2 背景3 MEMORY-VQ4 实验5 相关工作6 结论 摘要 检索增强是一种强大但昂贵的方法࿰…...
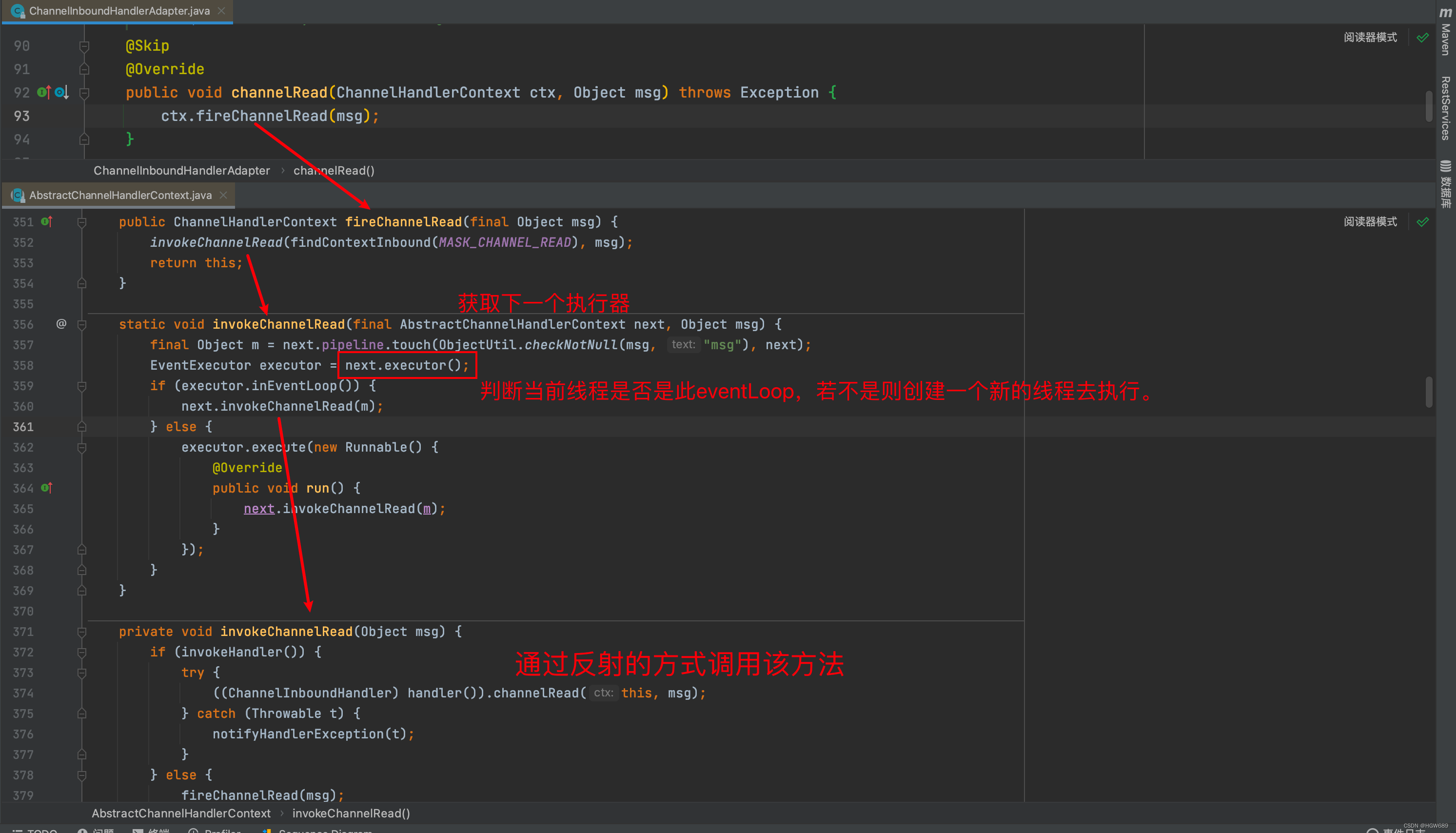
Netty—ChannelHandler
文章目录 一、Channel、ChannelPipeline 以及ChannelHandler 三者的关系❓二、ChannelHandler 是什么?🤔️三、ChannelInboundHandler四、ChannelOutboundHandler 一、Channel、ChannelPipeline 以及ChannelHandler 三者的关系❓ 通过以上对Channel和Ch…...

Android 集成onenet物联网平台
一,在Android应用程序中集成OneNet物联网平台,您可以按照以下步骤进行操作: 注册OneNet账户:首先,您需要在OneNet官方网站上注册一个账户。访问OneNet网站(https://open.iot.10086.cn/ ↗)&…...
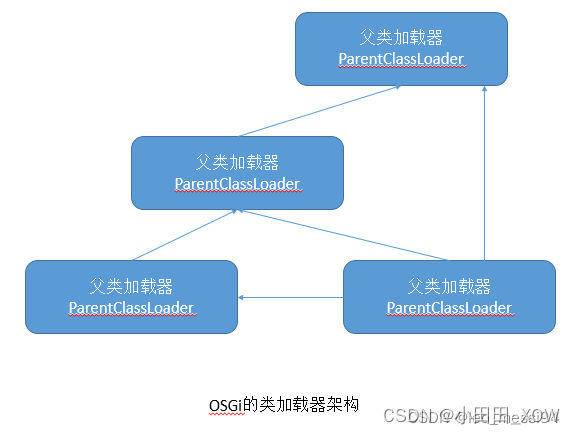
java八股文面试[JVM]——如何打破双亲委派模型
双亲委派模型的第一次“被破坏”是重写自定义加载器的loadClass(),jdk不推荐。一般都只是重写findClass(),这样可以保持双亲委派机制.而loadClass方法加载规则由自己定义,就可以随心所欲的加载类,典型的打破双亲委派模型的框架和中间件有tomc…...
一加11/Ace2/10Pro手机如何实现全局120HZ高刷-游戏超级流畅效果
已经成功root啦。安卓13目前也一样支持LSPosed框架,如果你对LSP框架有需求,也可以使 自测120HZ刷新率诞生以后,很多小伙伴用上了就很难回来啦,一加11/Ace2/10Pro/9pro手 机厂商也对新机做了很多的适配,让我们日常使用起…...

微服务主流框架概览
微服务主流框架概览 目录概述需求: 设计思路实现思路分析1.HSF2.Dubbo 3.Spring Cloud5.gRPC Service mesh 参考资料和推荐阅读 Survive by day and develop by night. talk for import biz , show your perfect code,full busy,skip hardness,make a be…...

Python Flask Web开发二:数据库创建和使用
前言 数据库在 Web 开发中起着至关重要的作用。它不仅提供了数据的持久化存储和管理功能,还支持数据的关联和连接,保证数据的一致性和安全性。通过合理地设计和使用数据库,开发人员可以构建强大、可靠的 Web 应用程序,满足用户的…...
)
告别激光雷达?手把手复现ST-P3:一个纯视觉的端到端自动驾驶模型(附避坑指南)
纯视觉自动驾驶实战:从零复现ST-P3模型的完整指南 当特斯拉在2021年宣布取消所有车型的雷达传感器时,整个行业都在质疑纯视觉方案的可靠性。然而ST-P3论文的发表,为这一技术路线提供了新的理论支撑。本文将带你深入这个前沿模型的实现细节&am…...

实战应用开发:基于快马平台构建带监控和定时任务的c盘管理大师
今天想和大家分享一个非常实用的项目开发经验——如何用Python快速打造一个功能完备的C盘管理工具。作为一个经常被C盘爆满困扰的程序员,我决定把这个痛点转化为一个完整的桌面应用解决方案。 项目需求分析 首先明确核心需求:我们需要一个能实时监控C盘空…...
)
Python实战:用PyWavelets实现小波降噪(附软硬阈值函数对比代码)
Python实战:用PyWavelets实现小波降噪(附软硬阈值函数对比代码) 在信号处理领域,噪声就像不请自来的客人,总是干扰着我们想要获取的真实信息。想象一下医生试图从嘈杂的心电图中诊断病情,或是摄影师处理夜间…...
Janus-Pro-7B多模态效果展示:基于Transformer架构的图像描述与问答
Janus-Pro-7B多模态效果展示:基于Transformer架构的图像描述与问答 最近在体验各种多模态大模型,发现了一个挺有意思的选手——Janus-Pro-7B。它主打一个能力:不仅能看懂图片,还能用文字把看到的东西描述出来,甚至能跟…...

如何将Smart AM60电视盒子变身高性能Armbian服务器:完整实战指南
如何将Smart AM60电视盒子变身高性能Armbian服务器:完整实战指南 【免费下载链接】amlogic-s9xxx-armbian Supports running Armbian on Amlogic, Allwinner, and Rockchip devices. Support a311d, s922x, s905x3, s905x2, s912, s905d, s905x, s905w, s905, s905l…...

unrpa架构深度解析:RPA文件格式逆向工程与高性能解包技术实现
unrpa架构深度解析:RPA文件格式逆向工程与高性能解包技术实现 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 在游戏开发与逆向工程领域,RPA(R…...

XUnity.AutoTranslator实战指南:Unity游戏实时翻译解决方案与开发者实践指南
XUnity.AutoTranslator实战指南:Unity游戏实时翻译解决方案与开发者实践指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 1. 游戏翻译的核心痛点与技术破局 游戏玩家和开发者常常面临三大…...

OFA-Image-Caption模型解析:从卷积神经网络到跨模态理解的架构揭秘
OFA-Image-Caption模型解析:从卷积神经网络到跨模态理解的架构揭秘 最近几年,AI在“看图说话”这件事上进步飞快。你可能见过一些工具,上传一张照片,它就能自动生成一段描述。这背后,图像描述生成技术是关键。今天咱们…...

Node.js 结合 LangChainJS 实现智能对话系统的实战探索
1. 为什么选择Node.js和LangChainJS构建智能对话系统 最近几年,智能对话系统已经成为开发者工具箱里的标配。作为一个在AI领域摸爬滚打多年的老手,我发现Node.js和LangChainJS的组合特别适合快速搭建这类系统。Node.js的异步非阻塞特性让它天生适合处理对…...

交换机接口全解析:从RJ-45到光纤,一文掌握所有连接技巧
1. 交换机接口基础:认识常见的物理接口类型 第一次拆开交换机包装时,面对密密麻麻的接口面板,新手常会感到无从下手。其实这些接口按照传输介质可分为两大阵营:电口和光口。电口就是我们熟悉的RJ-45接口,而光口则包含…...