OpenCL编程指南-10.2使用C++包装器API的矢量相加示例
选择OpenCL平台并创建一个上下文
建立OpenCL的第一步是选择一个平台。第2章介绍过,OpenCL使用了ICD模型,其中可以有多个OpenCL实现在一个系统上并存。类似于HelloWorld示例,这个矢量相加程序展示了选择OpenCL平台的一种最简单的方法:选择第一个可用的平台。
首先,调用cl::Platform::get()得到平台列表:
std::vector<cl::Platform> platformList;
cl::Platform::get(&platformList);
得到平台列表之后,这个例子会调用cl::Context()创建一个上下文。cl::Context ()调用会尝试由一个GPU设备创建上下文。如果失败,程序会产生一个异常,这个程序使用了OpenCL C++包装器异常特性,以一个错误消息终止。创建上下文的代码如下:
cl_context_properties cprops[] = (CL_CONTEXT_PLATFORM,(cl_context_properties)(platformList[0])(),0);
cl::Context context(CL_DEVICE_TYPE_GPU, cprops);
选择一个设备并创建命令队列
选择一个平台并创建上下文之后,矢量相加应用程序的下一步是选择一个设备,并创建一个命令队列。第一个任务是查询与之前所创建上下文关联的设备集合。可以通过cl::Context::getInfo<CL_CONTEXT_DEVICES >()调用来查询,这会返回与上下文关联的设备std::vector。
在继续学习后面的内容之前,先来了解getInfo()方法,因为它遵循了C++包装器API中通用的一种模式。一般来说,对于一个支持查询接口的CAPl对象(例如,查询接口为clGetXXInfo(),其中xx是所查询C API对象的名),任何表示这样一个CAPI对象的C++包装器API对象都有相应的一个接口,形式如下:
template <cl_int> typename
detail::param_traits<detail::cl_XX_info, name>::param_type
cl::Object::getInfo(void);
乍一看可能会让你有些害怕,因为这里使用了一种称为特征类(traits)的C++模板技术(这里用于关联clGetXXInfo()提供的共享功能),不过,由于使用这些getInfo()函数的程序在实际中从来不需要引用特征类组件,所以对于开发人员编写的代码没有任何影响。需要指出的重要一点是,所有对应一个底层C API对象的C++包装器API对象都有一个模板方法,名为getInfo(),以查询的cl_xx_info枚举值作为其模板参数。其效果是可以静态检查所请求的值是否合法,也就是说,一个特定的getInfo()方法只接受相应cl_xx_info枚举中定义的值。通过使用这种特征类技术,getInfo()函数可以自动推导出结果类型。
再来看矢量相加示例,要为关联的一组设备查询一个上下文,可以用CL_CONTEXT_DEVICES限定相应的cl::Context::getInfo(),返回std::vector<cl::Device>。通过以下代码可以说明:
//Query the set of devices attached to the context
std::vector<cl::Device> device =context.getInfo<CL_CONTEXT_DEVICES>();
注意:利用C++包装器API查询方法,现在不再需要先查询上下文来找出需要多大的空间存储设备列表,然后再提供另一个查询调用得到具体的设备。所有这些都隐藏在C++包装器API的一个简单的通用接口中。
选择设备集合之后,可以用cl::CommandQueue()创建一个命令队列,为简单起见,这里选择第一个设备:
//Create command-queue
cl::CommandQueue queue(context, device[0], 0);
创建和构建程序对象
矢量相加示例中的下一步是使用cl::Program()由OpenCL C内核源代码创建一个程序对象(矢量相加示例的内核源代码在本章最后的代码清单2-1中给出,这里不再重复)。程序对象用内核源代码加载,然后使用cl::Program::build()编译这个代码,以便在与上下文关联的设备上执行。下面给出相应的代码:
cl::Program::Sources sources(1,std::make_pair(kernelSourceCode,0));
cl::Program program(context, sources);
program.build(devices);
与其他C++包装器API调用类似,如果出现错误,则会有一个异常,程序将退出。
创建内核和内存对象
要执行OpenCL计算内核,需要在OpenCL设备上可访问的内存中分配内核函数的参数,这里就是缓冲区对象。这些缓冲区对象使用cl::Buffer()创建。对于输入缓冲区,我们使用CL_MEM_COPY_FROM_HOST_PTR来避免额外的调用来移动输人数据。对于输出缓冲区(即矢量相加的结果),则使用CL_MEM_USE_HOST_PTR,这要求将结果缓冲区映射到宿主机内存以便访问结果。可以使用以下代码来分配这些缓冲区:
cl::Buffer aBuffer = cl::Buffer(context,CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,BUFFER_SIZE * sizeof(int),(void *) &A[0]);cl::Buffer bBuffer = cl::Buffer(context,CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,BUFFER_SIZE * sizeof(int),(void *) &B[0]);cl::Buffer cBuffer = cl::Buffer(context,CL_MEM_WRITE_ONLY | CL_MEM_USE_HOST_PTR,BUFFER_SIZE * sizeof(int),(void *) &C[0]);
利用cl::Kernel()调用创建内核对象:
cl::Kernel kernel(program, "vadd");
执行矢量相加内核
既然已经创建了内核和内存对象,矢量相加程序终于可以将内核人队等待执行了。内核函数的所有参数都要使用cl::Kernel:setArg()方法来设置。根据C API中的clSetKernelArg(),这个函数的第一个参数是内核函数参数索引。vadd()内核有3个参数(a、b和c),分别对应索引0、1和2。将之前创建的内存对象传入这个内核对象:
kernel.setArg(0, aBuffer);
kernel.setArg(1, bBuffer);
kernel.setArg(2, cBuffer);
与以往一样,设置内核参数之后,矢量相加示例使用命令队列将内核入队等待在设备上执行。这是通过调用cl::CommandQueue::enqueueNDRangeKernel()完成的。全局和局部工作大小使用cl::Range()传递。
对于局部工作大小,使用cl::Range()对象的一个特殊实例cl::NullRange,顾名思义,它对应于C API中传递NULL,允许运行时为设备确定最佳的工作组大小和请求的全局工作大小。
queue.enqueueNDRangeKernel(kernel,cl::NullRange,cl::NDRange(BUFFER_SIZE),cl::NullRange);
将内核入队等待执行并不意味着内核会立即执行。可以使用cl::CommandQueue::flush()或cl::CommandQueue::finish()强制提交到设备立即执行。不过,由于这个矢量相加示例只是要显示结果,所以它使用了一个阻塞的cl::CommandQueue::enqueueMapBuffer(),将输出缓冲区映射到一个宿主机指针:
int * output = (int *)queue.enqueueMapBuffere(cBuffer,CL_TRUE, //blockCL_MAP_READ,0,BUFFER_SIZE * sizeof(int));
宿主机应用程序再处理output 指向的数据,一旦完成,必须用cl::CommandQueue::enqueueUnmapMemObj()调用释放映射的内存:
err = queue.enqueueUnmapMemObject(cBuffer,(void *)output);
代码示例
#define __CL_ENABLE_EXCEPTIONS#include <CL/cl.hpp>#include <cstdio>
#include <cstdlib>
#include <iostream>#define BUFFER_SIZE 20int A[BUFFER_SIZE];
int B[BUFFER_SIZE];
int C[BUFFER_SIZE];static char
kernelSourceCode[] =
"__kernel void \n"
"vadd(__global int * a, __global int * b, __global int * c) \n"
"{ \n"
" size_t i = get_global_id(0); \n"
" \n"
" c[i] = a[i] + b[i]; \n"
"} \n"
;int
main(void)
{cl_int err;// Initialize A, B, Cfor (int i = 0; i < BUFFER_SIZE; i++) {A[i] = i;B[i] = i * 2;C[i] = 0;}try {std::vector<cl::Platform> platformList;// Pick platformcl::Platform::get(&platformList);// Pick first platformcl_context_properties cprops[] = {CL_CONTEXT_PLATFORM, (cl_context_properties)(platformList[0])(), 0 };cl::Context context(CL_DEVICE_TYPE_GPU, cprops);// Query the set of devices attched to the contextstd::vector<cl::Device> devices = context.getInfo<CL_CONTEXT_DEVICES>();// Create and program from sourcecl::Program::Sources sources(1, std::make_pair(kernelSourceCode, 0));cl::Program program(context, sources);// Build programprogram.build(devices);// Create buffer for A and copy host contentscl::Buffer aBuffer = cl::Buffer(context,CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,BUFFER_SIZE * sizeof(int),(void*)&A[0]);// Create buffer for B and copy host contentscl::Buffer bBuffer = cl::Buffer(context,CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR,BUFFER_SIZE * sizeof(int),(void*)&B[0]);// Create buffer for that uses the host ptr Ccl::Buffer cBuffer = cl::Buffer(context,CL_MEM_WRITE_ONLY | CL_MEM_USE_HOST_PTR,BUFFER_SIZE * sizeof(int),(void*)&C[0]);// Create kernel objectcl::Kernel kernel(program, "vadd");// Set kernel argskernel.setArg(0, aBuffer);kernel.setArg(1, bBuffer);kernel.setArg(2, cBuffer);// Create command queuecl::CommandQueue queue(context, devices[0], 0);// Do the workqueue.enqueueNDRangeKernel(kernel,cl::NullRange,cl::NDRange(BUFFER_SIZE),cl::NullRange);// Map cBuffer to host pointer. This enforces a sync with // the host backing space, remember we choose GPU device.int* output = (int*)queue.enqueueMapBuffer(cBuffer,CL_TRUE, // block CL_MAP_READ,0,BUFFER_SIZE * sizeof(int));for (int i = 0; i < BUFFER_SIZE; i++) {std::cout << C[i] << " ";}std::cout << std::endl;// Finally release our hold on accessing the memoryerr = queue.enqueueUnmapMemObject(cBuffer,(void*)output);// There is no need to perform a finish on the final unmap// or release any objects as this all happens implicitly with// the C++ Wrapper API.}catch (cl::Error err) {std::cerr<< "ERROR: "<< err.what()<< "("<< err.err()<< ")"<< std::endl;return EXIT_FAILURE;}return EXIT_SUCCESS;
}

相关文章:
OpenCL编程指南-10.2使用C++包装器API的矢量相加示例
选择OpenCL平台并创建一个上下文 建立OpenCL的第一步是选择一个平台。第2章介绍过,OpenCL使用了ICD模型,其中可以有多个OpenCL实现在一个系统上并存。类似于HelloWorld示例,这个矢量相加程序展示了选择OpenCL平台的一种最简单的方法…...
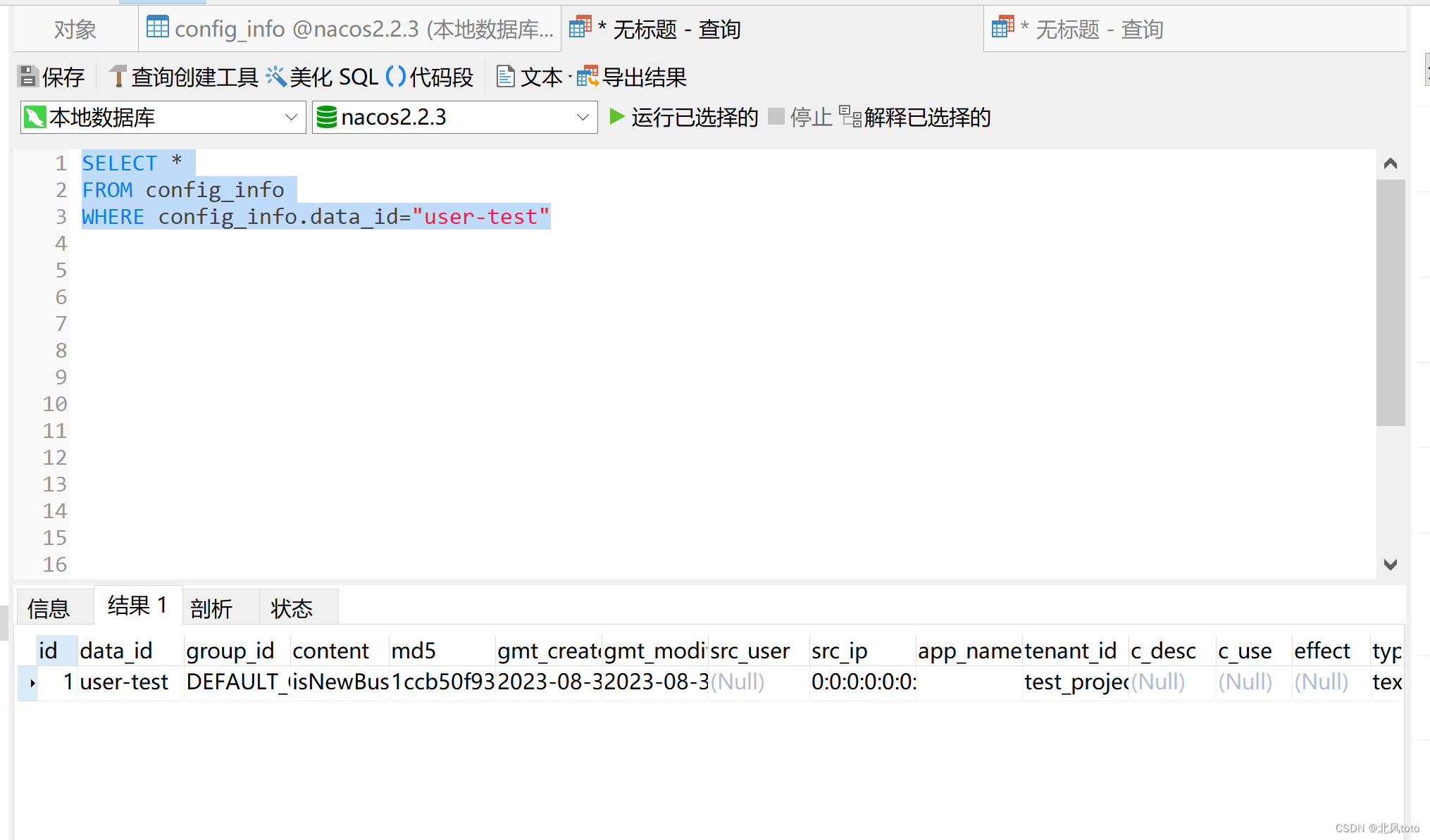
mysql数据库,字符串使用双引号““导致报错,使用单引号‘‘不报错,Unknown column ‘user-test‘ in ‘where clause‘
文章目录 一、完整报错二、报错数据三、报错原因四、解决方式1、更改执行sql2、更改sql数据校验模式(改为默认校验) 一、完整报错 > 1054 - Unknown column user-test in where clause二、报错数据 SELECT * FROM config_info WHERE config_info.da…...

[华为云云服务器评测] 华为云耀云服务器 Java、node环境配置
系列文章目录 第一章 [linux实战] 华为云耀云服务器L实例 Java、node环境配置 文章目录 系列文章目录前言一、任务拆解二、修改密码三、配置安全规则四、远程登录并更新apt五、安装、配置JDK环境5.1、安装openjdk,选择8版本5.2、检查jdk配置 六、安装、配置git6.1、安装git6.2…...

中企绕道突破封锁,防不胜防 | 百能云芯
韩国的财经媒体Business Korea最新报道指出,尽管美方在《通胀削减法案》(IRA)的补贴中排除了中国,但中国企业正通过多种方式积极应对美国在半导体和电动汽车电池领域的封锁,这包括建立合资企业、设立生产基地以及开展技…...

动手实践:从栈帧看字节码是如何在 JVM 中进行流转的
Java全能学习面试指南:https://www.javaxiaobear.cn/ 前面我们提到,类的初始化发生在类加载阶段,那对象都有哪些创建方式呢?除了我们常用的 new,还有下面这些方式: 使用 Class 的 newInstance 方法。使用…...
PEX装机
目录 一、PXE是什么? 二、PXE的组件: vsftpd/httpd/nfs tftp dhcp 三、配置vsftpd 四、配置tftp 1.安装tftp-server 2.启动tftp 五、准备pxelinx.0文件、引导文件、内核文件 1.准备pxelinux.0文件 2.准备引导文件、内核文件 六、配置dhcp …...

异地远程访问内网BUG管理系统【Cpolar内网穿透】
文章目录 前言1. 本地安装配置BUG管理系统2. 内网穿透2.1 安装cpolar内网穿透2.2 创建隧道映射本地服务3. 测试公网远程访问4. 配置固定二级子域名4.1 保留一个二级子域名5.1 配置二级子域名6. 使用固定二级子域名远程 前言 BUG管理软件,作为软件测试工程师的必备工具之一。在…...
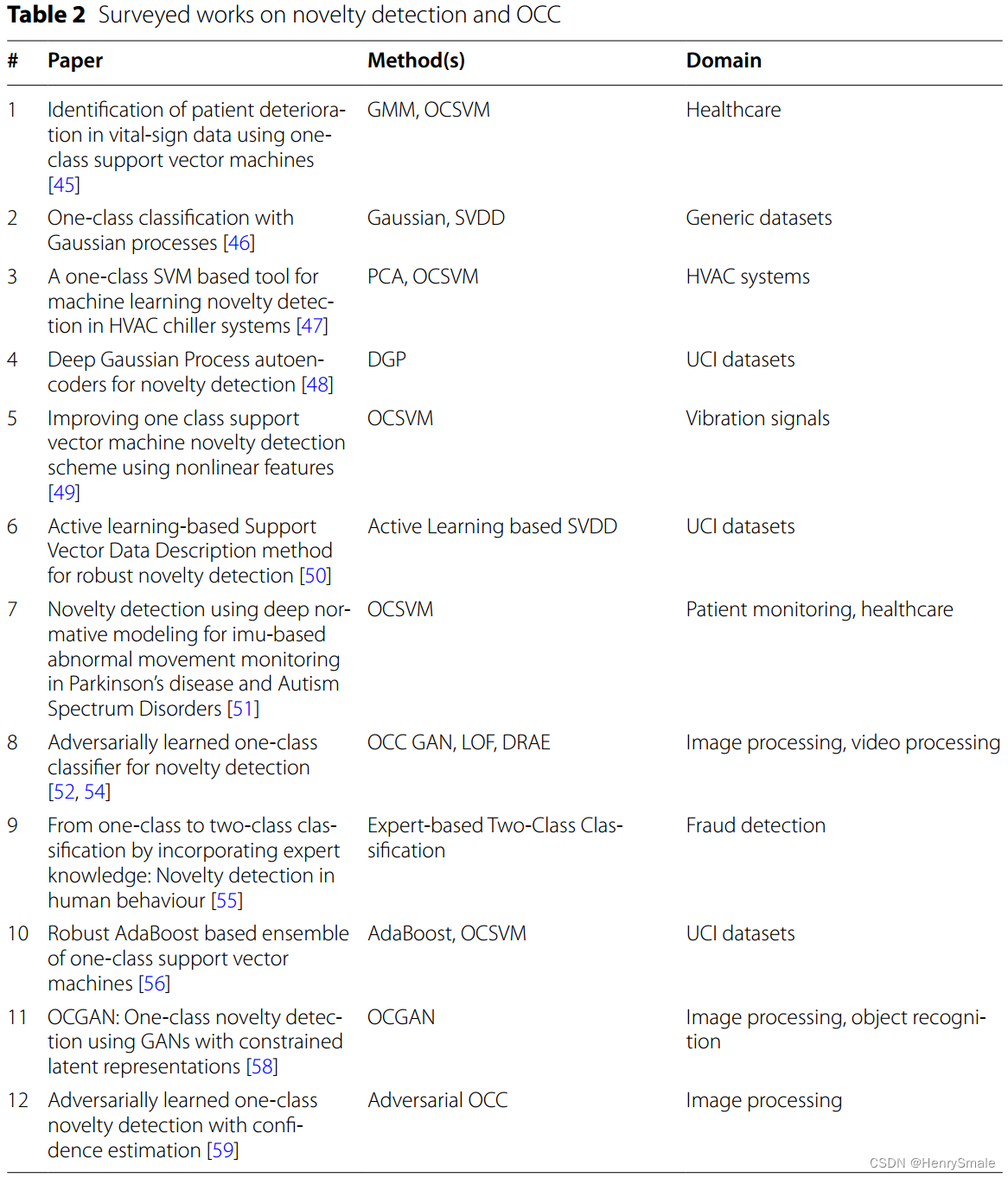
论文笔记:一分类及其在大数据中的潜在应用综述
0 概述 论文:A literature review on one‑class classification and its potential applications in big data 发表:Journal of Big Data 在严重不平衡的数据集中,使用传统的二分类或多分类通常会导致对具有大量实例的类的偏见。在这种情况…...

下单时如何保证数据一致性?
原创 哪吒 哪吒编程 2023-09-07 08:03 发表于辽宁 收录于合集#Redis11个 (给哪吒编程加星标,提高Java技能) 大家好,我是哪吒。 在前几篇文章中,提到了Redis实现排行榜、Redis数据缓存策略,让我们对Redis…...

【C++ Core Guidelines解析】深入理解现代C++的特性和原理
文章目录 👨⚖️《C Core Guidelines解析》的主要观点👨🏫《C Core Guidelines解析》的主要内容👨💻作者介绍 🌸🌸🌸🌷🌷🌷💐&a…...

Go语言高阶:Reflection反射与Files操作 详细示例教程
目录标题 一、Reflection反射1. What is reflection? 什么是反射2. Inspect a variable and find its type 检查变量并找到它的类型3. Reflect.Type and reflect.Value 反射类型和值4. Reflect.Kind 查看底层种类5. NumField() and Field() methods 字段数量和索引值方法6. In…...

谷歌seo技术流
很多外贸企业和独立站都想从Google获得免费的流量,也就是SEO流量,但是在做SEO的过程中,总会面临这样或那样的问题。米贸搜谷歌推广将这些问题总结如下: 既然SEO看起来似乎很难,但还是有很多电商公司愿意投资SEO&#x…...
-Collections)
ReactiveUI MVVM框架(1)-Collections
ReactiveUI MVVM框架(1)-Collections ReactiveUI使用动态数据(DynamicData)用于集合的操作。 当对动态数据集合进行更改时,会产生更改通知,通知表示为ChangeSet,里面包含了更改信息࿰…...
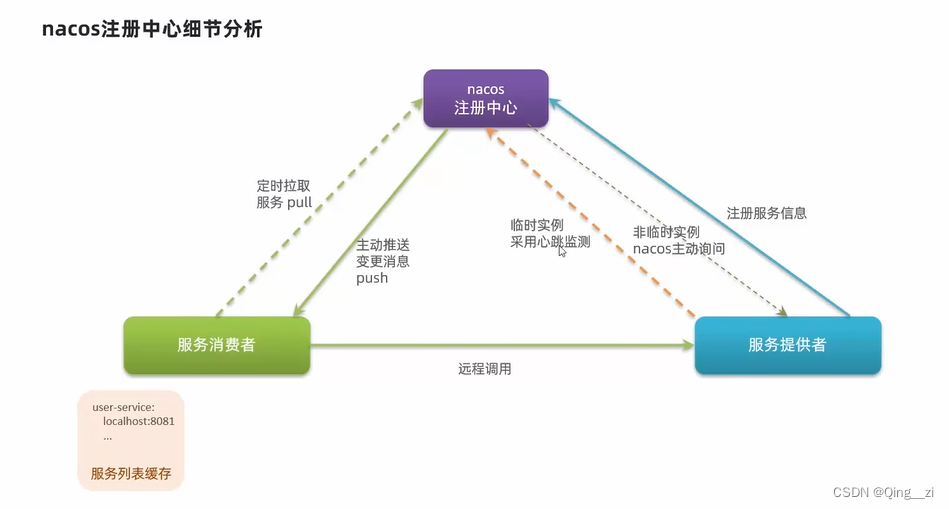
【微服务】五. Nacos服务注册
Nacos服务注册 5.1 Nacos服务分级存储模型Nacos服务分级存储模型:服务集群属性:总结: 5.2 根据集群负载均衡总结 5.3 Nacos服务实例的权重设置总结: 5.6 环境隔离namespace总结 5.7 Nacos和Eureka的对比总结 5.1 Nacos服务分级存储…...
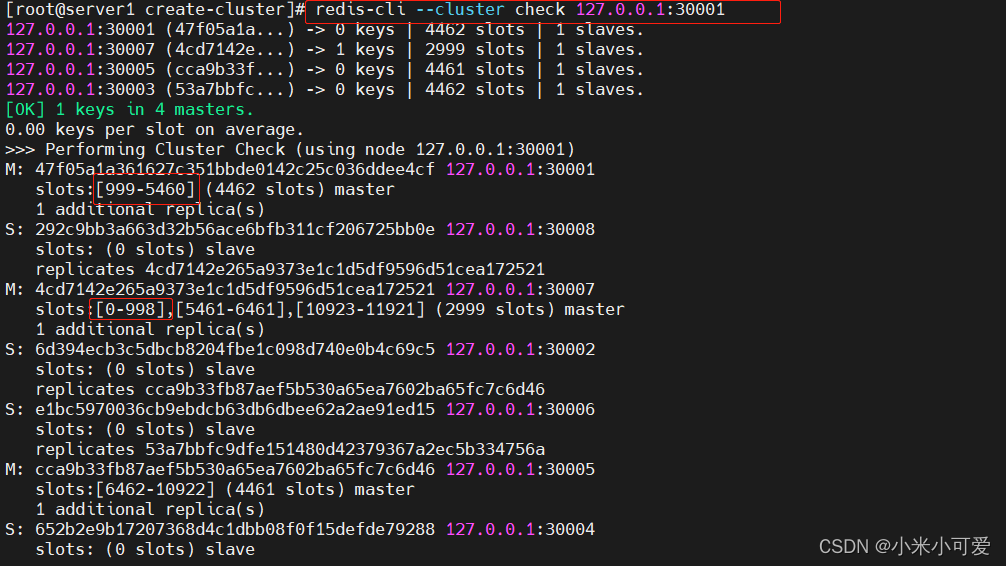
Lnmp架构-Redis
网站:www.redis.cn redis 部署 make的时候需要gcc和make 如果在纯净的环境下需要执行此命令 [rootserver3 redis-6.2.4]# yum install make gcc -y 注释一下这几行 vim /etc/redis/6739.conf 2.Redis主从复制 设置 11 是master 12 13 是slave 在12 上 其他节…...

Python 二进制数据处理与转换
不得不说,Python能火是有原因的,物联网开发中常用的数据处理方式,Python都有内置的函数或方法,相当方便,官方文档见二进制序列类型,下面是一些示例代码 string Hello World! # 字符串转二进制数据 data …...
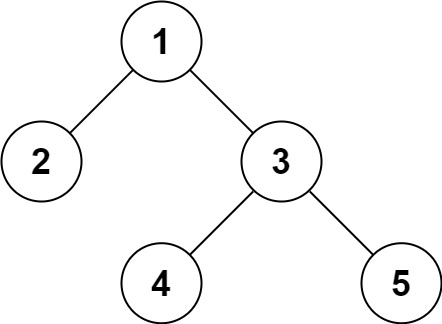
【LeetCode】297.二叉树的序列化与反序列化
题目 序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。 请设计一个算法来实现二叉树的序列化与反序列化…...

Java HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。 HashSet 允许有 null 值。 HashSet 是无序的,即不会记录插入的顺序。 HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必…...

在iPhone上构建自定义数据采集完整指南
在iPhone上构建自定义数据采集工具可以帮助我们更好地满足特定需求,提高数据采集的灵活性和准确性。本文将为您提供一份完整的指南和示例代码,教您如何在iPhone上构建自定义数据采集工具。 自定义数据采集工具的核心组件 a、数据模型 数据模型是数据采…...

Android MediaRecorder录音
1. 简介 在android中录制音频有两种方式,MediaRecorder和AudioRecord。两者的区别如下: MediaRecorder 简单方便,不需要理会中间录制过程,结束录制后可以直接得到音频文件进行播放;录制的音频文件是经过压缩的&#…...

PHP生成随机数字与字母组合及纯数字的方法
、生成随机数字字母组合方法1:使用rand()和chr()函数结合1234567891011function generateRandomString($length 10) {$characters 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ;$randomString ;for ($i 0; $i < $length; $i) {$randomSt…...

Open UI5 源代码解析之854:MenuItem.js
源代码仓库: https://github.com/SAP/openui5 源代码位置:src\sap.m\src\sap\m\MenuItem.js MenuItem.js 深度解析:在 OpenUI5 菜单体系中的定位、机制与实践价值 一、文件定位与总体结论 MenuItem.js 是 sap.m 库里菜单体系的关键节点文件,它实现了 sap.m.MenuItem 控…...

Webpacker终极集成指南:如何与React、Vue、TypeScript完美协作
Webpacker终极集成指南:如何与React、Vue、TypeScript完美协作 【免费下载链接】webpacker Use Webpack to manage app-like JavaScript modules in Rails 项目地址: https://gitcode.com/gh_mirrors/we/webpacker Webpacker是Rails生态系统中一个革命性的工…...

5大场景全覆盖:BilibiliDown视频下载工具的全方位应用指南
5大场景全覆盖:BilibiliDown视频下载工具的全方位应用指南 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirro…...

Unity网格变形系统深度解析:从基础架构到高级应用实践
Unity网格变形系统深度解析:从基础架构到高级应用实践 【免费下载链接】Deform A fully-featured deformer system for Unity that lets you stack effects to animate models in real-time 项目地址: https://gitcode.com/gh_mirrors/de/Deform Deform是一个…...

小米平板5变身Windows工作站:开源驱动如何重塑移动生产力边界?
小米平板5变身Windows工作站:开源驱动如何重塑移动生产力边界? 【免费下载链接】MiPad5-Drivers https://github.com/Project-Aloha/windows_oem_xiaomi_nabu 项目地址: https://gitcode.com/gh_mirrors/mi/MiPad5-Drivers 当一款Android平板遇上…...

利用快马平台快速生成基于jdk17的spring boot应用原型
最近在尝试用JDK17搭建一个Spring Boot项目原型时,发现从环境配置到基础代码编写要花不少时间。正好试用了InsCode(快马)平台,发现它能快速生成可运行的项目骨架,特别适合需要快速验证想法的场景。这里记录下具体操作和体验: 项目…...

告别漫长ps软件下载等待,用快马ai即刻生成你的高效修图工作台
作为一个经常需要处理图片的创作者,我深知传统PS软件下载安装的痛点:动辄几个G的安装包、漫长的等待时间、复杂的配置过程。直到发现了InsCode(快马)平台,才真正体会到什么叫"即开即用"的高效修图体验。 批量处理革命 以前要给几十…...

通义千问3-Reranker-0.6B开箱即用:国产信创服务器上的语义裁判快速搭建
通义千问3-Reranker-0.6B开箱即用:国产信创服务器上的语义裁判快速搭建 1. 为什么需要专业的语义重排序模型? 在信息爆炸的时代,我们每天都要面对海量的文本数据。无论是企业知识库、电商搜索还是智能客服,传统的关键词匹配就像…...

城通网盘下载速度慢?试试ctfileGet,让你畅享本地高速解析体验
城通网盘下载速度慢?试试ctfileGet,让你畅享本地高速解析体验 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 在数字化办公与学习中,网盘已成为文件传输的重要工具。…...