RT-DETR个人整理向理解
一、前言
在开始介绍RT-DETR这个网络之前,我们首先需要先了解DETR这个系列的网络与我们常提及的anchor-base以及anchor-free存在着何种差异。
首先我们先简单讨论一下anchor-base以及anchor-free两者的差异与共性:
1、两者差异:顾名思义,这两者一个显而易见的差别就是有无anchor,anchor-base是需要手工选取不同比例大小的anchor来得到proposals,而anchor-free则不需要。当然两者具体差异肯定不是这么几句话就能说的清的,这里不做详细讨论所以按下不表。
2、两者共性:两者虽然在获取proposals的原理方面存在不同,但是其最终还是存在了一个多对一的问题,也就是会对同一个目标产生多个proposal,也即最后两者最后都是需要通过阈值选取以及nms去过滤掉多余的预测框。此处可参考:Nms-Free时代
但是当问题涉及到了工业或者生活等其他领域落地问题上面的时候,无论是anchor-base还是anchor-free所面临的这中两套阈值问题(要先完成阈值筛选(Confidence threshold)和非极大值抑制(NMS)处理两个关键步骤)总是会对时效性产生很大的影响。
二、DETR系列网络的动机
在引言中,我们提到了无论是anchor-base还是anchor-free其实都存在着一个阈值问题,而这个阈值问题就决定了绕不开nms这个机制,nms这一机制的存在也就导致无法真正意义上去实现一个端到端的简易部署的网络模型,而DETR既不需要proposal也不需要anchor,而是直接利用Transformers这种能全局建模的能力,通过将目标检测视为一个集合预测问题。同时由于这种全局建模能力使得DETR系列网络不会输出那么多冗余的框。在此处个人水平有限害怕个人水平对读者的理解造成扭曲,因此在这就不对DETR做过多解释如果有兴趣的可以移步沐神的精讲视频:李沐DETR论文精读
而DETR系列网络究竟有多简洁,上述一小段文字自然无法很好的解释其简洁性,大家可以通过下面视频截图的50行代码看出DETR的简洁性。

三、RT-DETR网络
首先RT-DETR网络的检测动机其实非常明确,从这个命名也能看出来,其是想打造一个能实际用于工业界的DETR网络。但是对于DETR而言虽然其具备简单易用的特点,然而其实时性较差,在DETR的论文中的实验可以看到其FPS较之于Faster-RCNN更低(如下图所示),因此这是DETR的一个缺点。同时DETR还有另外一个缺点,就是其虽然借助于自注意机制带来的全局信息使得对于大目标检测效果表现较好,但是其对于小目标的检测效果相对而言较弱,当然在RT-DETR中也未解决这个问题,因此此处只提一下按下不表。

好了,既然目前已经知道DETR有一个实时性较差的缺点,那么接下来就应该对造成推理耗时高的原因进行一下分析,在RT-DETR中作者认为在Encoder部分作用在 S 5 S_5 S5(最顶层特征,即 C 5 C_5 C5只是换个表达方式),这样就可以大幅度减小计算量、提高计算速度,同时不会损伤模型性能,这样做的的原因是作者是基于一下两点考虑:
- 以往的DETR,如Deformable DETR是将多尺度的特征都拉平成拼接在其中,构成一个序列很长的向量,尽管这可以使得多尺度之间的特征进行充分的交互,但也会造成极大的计算量和计算耗时。RT-DETR认为这是当前的DETR计算速度慢的主要原因之一;
- RT-DETR认为相较于较浅 S 3 S_3 S3特征和 S 4 S_4 S4特征, S 5 S_5 S5特征拥有更深、更高级、更丰富的语义特征,这些语义特征是Transformer更加感兴趣的和需要的,对于区分不同物体的特征是更加有用的,而浅层特征因缺少较好的语义特征而起不到什么作用。
于个人而言感觉这个观点很类似YOLOF的观点,在YOLOF中也是直接使用顶层的特征层,有感兴趣的可以去看看YOLOF这篇文章。
而为了验证这个观点,作者的团队设计了若干对照组实验,实验如下图所示:
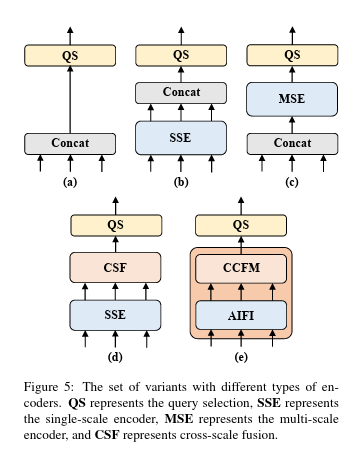
对于对照组(a),其结构就是DINO-R50,但移除了DINO-R50中的多尺度encoder,直接将 S 3 S_3 S3、 S 4 S_4 S4和 S 5 S_5 S5拼接在一起,交给后续的网络去处理,得到最终的输出。注意,这里的拼接是先将二维的 H × W H×W H×W拉平成 H W HW HW然后再去拼接: H 1 W 1 + H 2 W 2 + H 3 W 3 H_1W_1+H_2W_2+H_3W_3 H1W1+H2W2+H3W3。
对于对照组(b),作者团队在(a)基础上,加入了单尺度的Transformer Encoder(SSE),仅包含一层Encoder层,分别处理三个尺度的输出,注意,三个尺度共享一个SSE,而不是为每一个尺度都设计一个独立的SSE。通过这一共享的操作,三个尺度的信息是可以实现一定程度的信息交互。最后将处理结果拼接在一起,交给后续的网络去处理,得到最终的输出。
对于对照组©,作者团队使用多尺度的Transformer Encoder(MSE),大概是Deformable DETR所采用的那一类MSE结构。将三个尺度的特征拼接在一起后,交由MSE来做处理,使得三个尺度的特征同时完成“尺度内”和“跨尺度”的信息交互和融合,最后将处理结果,交给后续的网络去处理,得到最终的输出。
对于对照组(d),作者团队则先用共享的SSE分别处理每个尺度的特征,然后再使用PAN-like的特征金字塔网络去融合三个尺度的特征,最后将融合后的多尺度特征拼接在一起,交给后续的网络去处理,得到最终的输出。
对于对照组(e),作者团队则使用一个SSE只处理 S 5 S_5 S5特征,即所谓的AIFI模块,随后再使用CCFM模块去完成跨尺度的特征融合,最后将融合后的多尺度特征拼接在一起,交给后续的网络去处理,得到最终的输出。
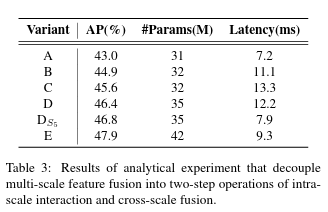
最终,对比结果如上方的图所示,我们简单地来分析一下这组对比试验说明了什么样的结论。
- 首先,A即对照组(a)取得到了43.0 AP的结果,注意,A的设置是不包含Encoder的,即没有自注意力机制,在Backbone之后直接接Decoder去做处理,从而获得输出结果,可想而知,A的性能应该是最差的,这也是后续实验的Baseline;
- 随后,在A的基础上,B引入了共享的SSE去处理每个尺度的特征,使得性能从43.0提升至44.9,表明使用共享的SSE是可以提升性能的。从研究的角度来说,对于B,应该再做一个额外的实验,即使用三个独立的SSE分别去处理每个尺度的特征,以此来论证“共享SSE”的必要性。当然,我们可以感性地认识到共享SSE会更好,但从理性的严谨层面来讲,补上这一对比试验还是有必要的。简而言之,B证明了加入Encoder会更好;
- 相较于B,C则是使用MSE,即使用MSE来同步完成“尺度内”和“跨尺度”的特征融合(应该和Deformable DETR的多尺度Encoder做法相似),这一做法可以让不同尺度的特征之间得到更好的交互和融合,可预见地会提升了AP指标,其实验结果也意料内地证明了这一点:AP指标从43.0提升至45.6,要高于B的44.9,这表明MSE的做法是有效的,即“尺度内”和“跨尺度”的特征融合是必要的。但是,从速度的角度来看,MSE拖慢了推理速度,Latency从7.2增加值13.3 ms,要高于B组的11.1 ms;
- 随后是对照组D,不同于C,D是相当于解耦了C中的MSE:先使用共享的SSE分别去处理每个尺度的特征,完成“尺度内”的信息交互,然后再用一个PAN风格的跨尺度融合网络去融合不同尺度之间的特征,完成“跨尺度”的信息融合。这种做法可以有效地避免MSE中因输入的序列过长而导致的计算量增加的问题。相较于C,D的这种解耦的做法不仅仅使得Latency从13.3 ms降低至12.2 ms,性能也从45.6 AP提升至46.4 AP,这表明MSE的做法并不是最优的,先处理“尺度内”,再完成“跨尺度”,性能会更好;
- 随后是对照组D,不同于C,D是相当于解耦了C中的MSE:先使用共享的SSE分别去处理每个尺度的特征,完成“尺度内”的信息交互,然后再用一个PAN风格的跨尺度融合网络去融合不同尺度之间的特征,完成“跨尺度”的信息融合。这种做法可以有效地避免MSE中因输入的序列过长而导致的计算量增加的问题。相较于C,D的这种解耦的做法不仅仅使得Latency从13.3 ms降低至12.2 ms,性能也从45.6 AP提升至46.4 AP,这表明MSE的做法并不是最优的,先处理“尺度内”,再完成“跨尺度”,性能会更好;
- 最后就是对照组E,在DS5的基础上,E重构了跨尺度特征融合模块,构建了新的CCFM模块,由于论文里没给出CSF模块的细节,所以CCFM模块究竟调整了哪里也是无法获知的,但就CCFM本身来看,大体上也是一个PAN-like的结构。在换上了CCFM后,性能从46.8进一步地提升至47.9。
综上,这组对比试验证明了两件事:1) Transformer的Encoder部分只需要处理high-level特征,既能大幅度削减计算量、提升计算速度,同时也不会损伤到性能,甚至还有所提升;2) 对于多尺度特征的交互和融合,我们仍可以采用CNN架构常用的PAN网络来搭建,只需要一些细节上的调整即可。
另外,我们仔细来看一下这个对照组(e),注意,根据论文给出的结果和源代码,所谓的CCFM其实还是PaFPN,如下方的图10所示,其中的Fusion模块就是一个CSPBlock风格的模块。
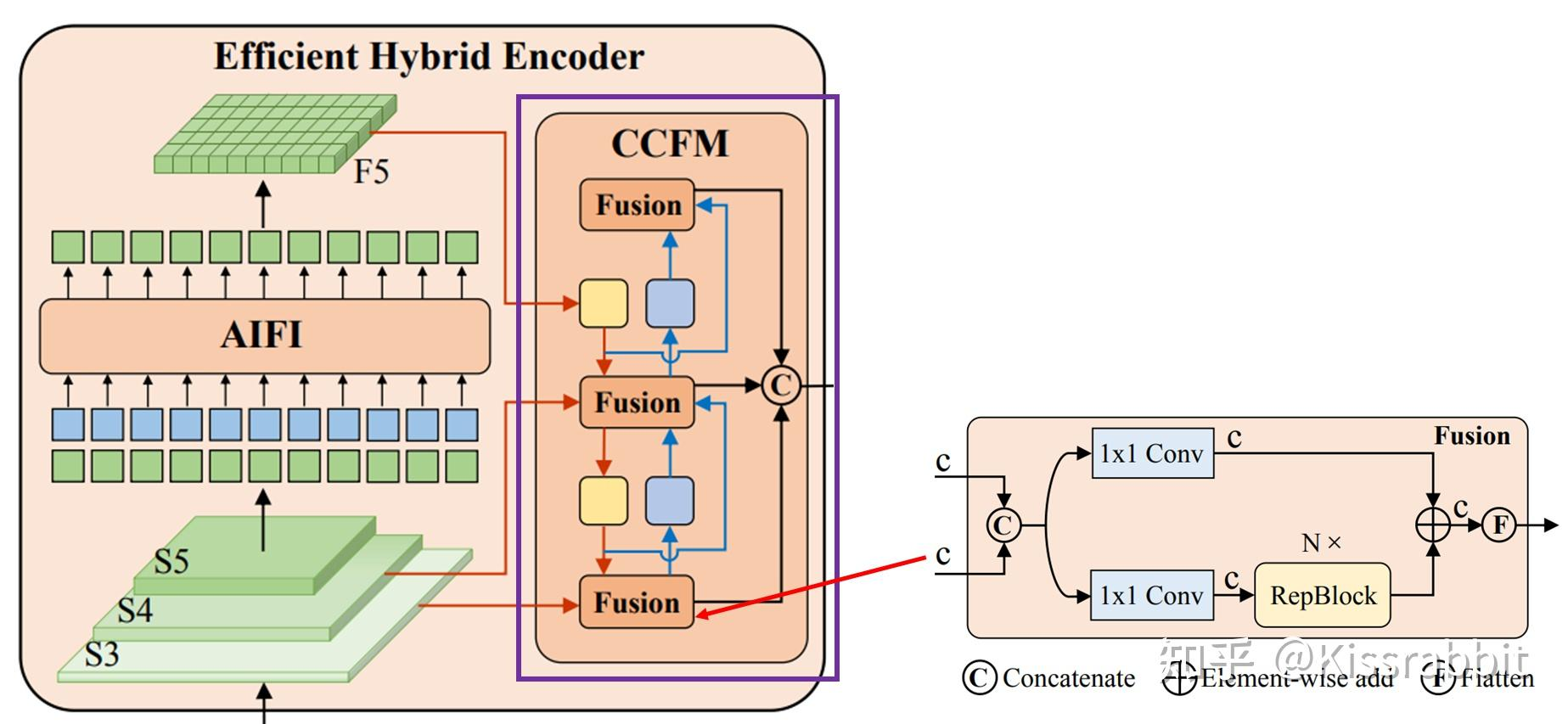
为了看得更仔细一些,我们来看一下官方源码,如下方的Python代码所示。依据论文的设定,HybridEncoder包含AIFI和CCFM两大模块,其中AIFI就是Transformer的Encoder部分,而CCFM其实就是常见的PaFPN结构:首先用若干层1x1卷积将所有的特征的通道数都映射至同一数目,如256,随后再进行top-down和bottom-up两部分的特征融合。
# https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/transformers/hybrid_encoder.pyclass HybridEncoder(nn.Layer):__shared__ = ['depth_mult', 'act', 'trt', 'eval_size']__inject__ = ['encoder_layer']def __init__(self,in_channels=[512, 1024, 2048],feat_strides=[8, 16, 32],hidden_dim=256,use_encoder_idx=[2],num_encoder_layers=1,encoder_layer='TransformerLayer',pe_temperature=10000,expansion=1.0,depth_mult=1.0,act='silu',trt=False,eval_size=None):super(HybridEncoder, self).__init__()self.in_channels = in_channelsself.feat_strides = feat_stridesself.hidden_dim = hidden_dimself.use_encoder_idx = use_encoder_idxself.num_encoder_layers = num_encoder_layersself.pe_temperature = pe_temperatureself.eval_size = eval_size# channel projectionself.input_proj = nn.LayerList()for in_channel in in_channels:self.input_proj.append(nn.Sequential(nn.Conv2D(in_channel, hidden_dim, kernel_size=1, bias_attr=False),nn.BatchNorm2D(hidden_dim,weight_attr=ParamAttr(regularizer=L2Decay(0.0)),bias_attr=ParamAttr(regularizer=L2Decay(0.0)))))# encoder transformerself.encoder = nn.LayerList([TransformerEncoder(encoder_layer, num_encoder_layers)for _ in range(len(use_encoder_idx))])act = get_act_fn(act, trt=trt) if act is None or isinstance(act, str, dict)) else act# top-down fpnself.lateral_convs = nn.LayerList()self.fpn_blocks = nn.LayerList()for idx in range(len(in_channels) - 1, 0, -1):self.lateral_convs.append(BaseConv(hidden_dim, hidden_dim, 1, 1, act=act))self.fpn_blocks.append(CSPRepLayer(hidden_dim * 2,hidden_dim,round(3 * depth_mult),act=act,expansion=expansion))# bottom-up panself.downsample_convs = nn.LayerList()self.pan_blocks = nn.LayerList()for idx in range(len(in_channels) - 1):self.downsample_convs.append(BaseConv(hidden_dim, hidden_dim, 3, stride=2, act=act))self.pan_blocks.append(CSPRepLayer(hidden_dim * 2,hidden_dim,round(3 * depth_mult),act=act,expansion=expansion))def forward(self, feats, for_mot=False):assert len(feats) == len(self.in_channels)# get projection featuresproj_feats = [self.input_proj[i](feat) for i, feat in enumerate(feats)]# encoderif self.num_encoder_layers > 0:for i, enc_ind in enumerate(self.use_encoder_idx):h, w = proj_feats[enc_ind].shape[2:]# flatten [B, C, H, W] to [B, HxW, C]src_flatten = proj_feats[enc_ind].flatten(2).transpose([0, 2, 1])if self.training or self.eval_size is None:pos_embed = self.build_2d_sincos_position_embedding(w, h, self.hidden_dim, self.pe_temperature)else:pos_embed = getattr(self, f'pos_embed{enc_ind}', None)memory = self.encoder[i](src_flatten, pos_embed=pos_embed)proj_feats[enc_ind] = memory.transpose([0, 2, 1]).reshape([-1, self.hidden_dim, h, w])# top-down fpninner_outs = [proj_feats[-1]]for idx in range(len(self.in_channels) - 1, 0, -1):feat_heigh = inner_outs[0]feat_low = proj_feats[idx - 1]feat_heigh = self.lateral_convs[len(self.in_channels) - 1 - idx](feat_heigh)inner_outs[0] = feat_heighupsample_feat = F.interpolate(feat_heigh, scale_factor=2., mode="nearest")inner_out = self.fpn_blocks[len(self.in_channels) - 1 - idx](paddle.concat([upsample_feat, feat_low], axis=1))inner_outs.insert(0, inner_out)# bottom-up panouts = [inner_outs[0]]for idx in range(len(self.in_channels) - 1):feat_low = outs[-1]feat_height = inner_outs[idx + 1]downsample_feat = self.downsample_convs[idx](feat_low)out = self.pan_blocks[idx](paddle.concat([downsample_feat, feat_height], axis=1))outs.append(out)return outs
而对于其中解码器的decoder部分使用的是"DINO Head"的decoder部分,也即使用了DINO的一个“去噪思想”(具体我未了解过,有感兴趣的可以自行了解)。但是看官方源码可知在推理阶段的时候,RT-DETR的decoder部分与DETR并无区别,由于我只关注推理阶段因此关于"去噪思想"这部分各位可以详细看看DINO以及官方源码自行了解。
class RTDETRTransformer(nn.Layer):__shared__ = ['num_classes', 'hidden_dim', 'eval_size']def __init__(self,num_classes=80,hidden_dim=256,num_queries=300,position_embed_type='sine',backbone_feat_channels=[512, 1024, 2048],feat_strides=[8, 16, 32],num_levels=3,num_decoder_points=4,nhead=8,num_decoder_layers=6,dim_feedforward=1024,dropout=0.,activation="relu",num_denoising=100,label_noise_ratio=0.5,box_noise_scale=1.0,learnt_init_query=True,query_pos_head_inv_sig=False,eval_size=None,eval_idx=-1,eps=1e-2):super(RTDETRTransformer, self).__init__()assert position_embed_type in ['sine', 'learned'], \f'ValueError: position_embed_type not supported {position_embed_type}!'assert len(backbone_feat_channels) <= num_levelsassert len(feat_strides) == len(backbone_feat_channels)for _ in range(num_levels - len(feat_strides)):feat_strides.append(feat_strides[-1] * 2)self.hidden_dim = hidden_dimself.nhead = nheadself.feat_strides = feat_stridesself.num_levels = num_levelsself.num_classes = num_classesself.num_queries = num_queriesself.eps = epsself.num_decoder_layers = num_decoder_layersself.eval_size = eval_size# backbone feature projectionself._build_input_proj_layer(backbone_feat_channels)# Transformer moduledecoder_layer = TransformerDecoderLayer(hidden_dim, nhead, dim_feedforward, dropout, activation, num_levels,num_decoder_points)self.decoder = TransformerDecoder(hidden_dim, decoder_layer,num_decoder_layers, eval_idx)# denoising partself.denoising_class_embed = nn.Embedding(num_classes,hidden_dim,weight_attr=ParamAttr(initializer=nn.initializer.Normal()))self.num_denoising = num_denoisingself.label_noise_ratio = label_noise_ratioself.box_noise_scale = box_noise_scale# decoder embeddingself.learnt_init_query = learnt_init_queryif learnt_init_query:self.tgt_embed = nn.Embedding(num_queries, hidden_dim)self.query_pos_head = MLP(4, 2 * hidden_dim, hidden_dim, num_layers=2)self.query_pos_head_inv_sig = query_pos_head_inv_sig# encoder headself.enc_output = nn.Sequential(nn.Linear(hidden_dim, hidden_dim),nn.LayerNorm(hidden_dim,weight_attr=ParamAttr(regularizer=L2Decay(0.0)),bias_attr=ParamAttr(regularizer=L2Decay(0.0))))self.enc_score_head = nn.Linear(hidden_dim, num_classes)self.enc_bbox_head = MLP(hidden_dim, hidden_dim, 4, num_layers=3)# decoder headself.dec_score_head = nn.LayerList([nn.Linear(hidden_dim, num_classes)for _ in range(num_decoder_layers)])self.dec_bbox_head = nn.LayerList([MLP(hidden_dim, hidden_dim, 4, num_layers=3)for _ in range(num_decoder_layers)])self._reset_parameters()def forward(self, feats, pad_mask=None, gt_meta=None, is_teacher=False):# input projection and embedding(memory, spatial_shapes,level_start_index) = self._get_encoder_input(feats)# prepare denoising trainingif self.training:denoising_class, denoising_bbox_unact, attn_mask, dn_meta = \get_contrastive_denoising_training_group(gt_meta,self.num_classes,self.num_queries,self.denoising_class_embed.weight,self.num_denoising,self.label_noise_ratio,self.box_noise_scale)else:denoising_class, denoising_bbox_unact, attn_mask, dn_meta = None, None, None, Nonetarget, init_ref_points_unact, enc_topk_bboxes, enc_topk_logits = \self._get_decoder_input(memory, spatial_shapes, denoising_class, denoising_bbox_unact,is_teacher)# decoderout_bboxes, out_logits = self.decoder(target,init_ref_points_unact,memory,spatial_shapes,level_start_index,self.dec_bbox_head,self.dec_score_head,self.query_pos_head,attn_mask=attn_mask,memory_mask=None,query_pos_head_inv_sig=self.query_pos_head_inv_sig)return (out_bboxes, out_logits, enc_topk_bboxes, enc_topk_logits,dn_meta)
同样在RT-DETR中提及的IoU-aware Query Selection其实在推理阶段也不存在,其是在训练期间约束检测器对高 IoU 的特征产生高分类分数,对低 IoU 的特征产生低分类分数。因此若只关注推理阶段的读者,这部分也可无需关注,而关于IoU-aware Query Selection此部分其实是在assignment阶段和计算loss的阶段,classification的标签都换成了 “IoU软标签” :
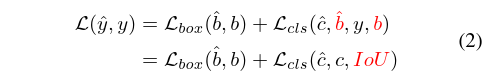
所谓的“IoU软标签”,就是指将预测框与GT之间的IoU作为类别预测的标签。熟悉YOLO工作的读者一定对此不会陌生,其本质就是已经被广泛验证了的IoU-aware。在最近的诸多工作里,比如RTMDet、DAMO-YOLO等工作中,都有引入这一理念,去对齐类别和回归的差异。之所以这么做,是因为按照以往的one-hot方式,完全有可能出现“当定位还不够准确的时候,类别就已经先学好了”的“未对齐”的情况,毕竟类别的标签非0即1。但如果将IoU作为类别的标签,那么类别的学习就要受到回归的调制,只有当回归学得也足够好的时候,类别才会学得足够好,否则,类别不会过快地先学得比回归好,因此后者显式地制约着前者。
四、总结
最后先看一下论文在实验部分给出的对比表格,如下方的图所示:
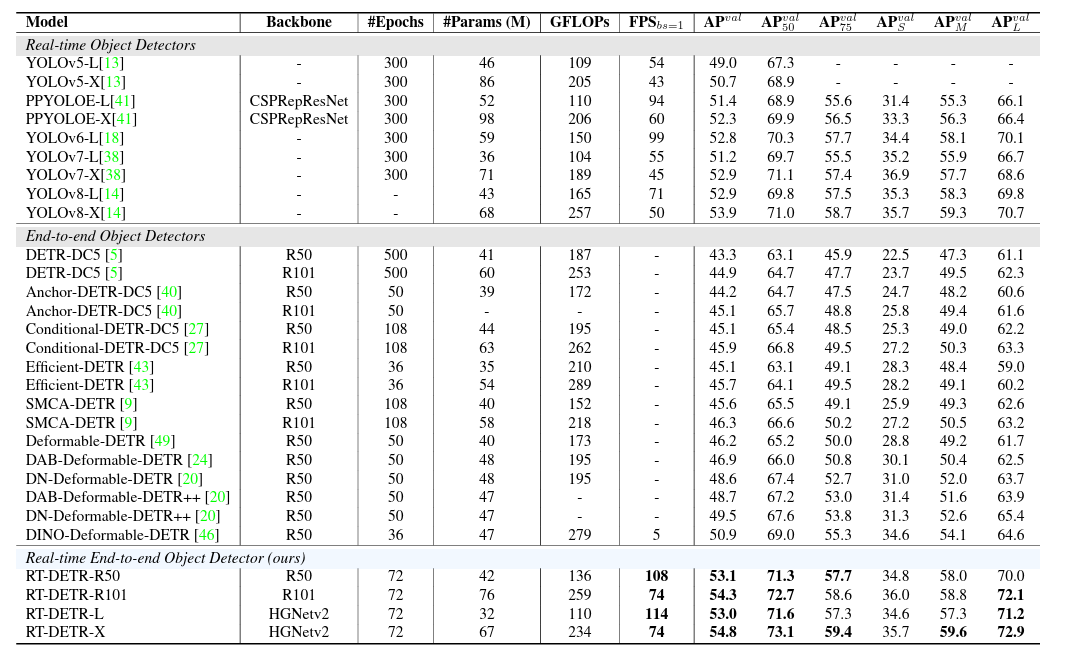
由于在这里我考虑的是RT-DETR的实时性、GFLOPS以及相应的检测性能,因此我只关注其与YOLO系列的对比,而在YOLO系列中目前使用较多的是YOLOV5以及PPYOLOE网络。而RT-DETR与这两个网络对应的L与X对比能看到其FPS是V5的一倍,同样也比PP高出十来FPS,而算力开销也是与两者接近,检测性能同样高出了这两者几个点。同时RT-DETR这个网络也继承了DETR网络只要支持CNN与Transformer就能使用以及其推理阶段简洁性的特点。不难看出在未来DETR系列的网络应能全面铺开,而且其网络的简洁性对于实际部署工作也是有利的。
总而言之,在未来完完全全可以在实时的DETR网络方面好好期待一把。因此于此处记录一下阅读这篇文章以及DETR的读后感。受限于个人能力其中纰漏肯定还有不少,欢迎各位大力指出,共同成长。
参考链接:
《目标检测》-第33章-浅析RT-DETR
超越YOLOv8,飞桨推出精度最高的实时检测器RT-DETR!
PaddlePaddle
DETR 论文精读
Nms-Free时代
相关文章:
RT-DETR个人整理向理解
一、前言 在开始介绍RT-DETR这个网络之前,我们首先需要先了解DETR这个系列的网络与我们常提及的anchor-base以及anchor-free存在着何种差异。 首先我们先简单讨论一下anchor-base以及anchor-free两者的差异与共性: 1、两者差异:顾名思义&…...

易点易动库存管理系统与ERP系统打通,帮助企业实现低值易耗品管理
现今,企业管理日趋复杂,无论是核心经营还是辅助环节,都需要依靠信息化手段来提升效率。而低值易耗品作为企业日常运营中的必需品,其管理也面临诸多挑战。传统做法效率低下,容易出错。如何通过信息化手段实现低值易耗品的高效管理,成为许多企业必顾及的一个课题。 易点易动作为…...

【笔试强训选择题】Day34.习题(错题)解析
作者简介:大家好,我是未央; 博客首页:未央.303 系列专栏:笔试强训选择题 每日一句:人的一生,可以有所作为的时机只有一次,那就是现在!!!ÿ…...

“现代”“修饰”卷积神经网络,何谓现代
一、“现代” vs “传统” 现代卷积神经网络(CNNs)与传统卷积神经网络之间存在一些关键区别。这些区别主要涉及网络的深度、结构、训练技巧和应用领域等方面。以下是现代CNNs与传统CNNs之间的一些区别: 深度: 传统CNNs࿱…...

XHTML基础知识了解
XHTML是一种严格符合XML规范的标记语言,它的基本语法和HTML类似,但是更加严谨和规范。XHTML的代码结构非常清晰,方便浏览器和搜索引擎解析。下面是一些XHTML的基础知识和代码示例: 声明文档类型(DTD) 在X…...
USB Server集中管控加密狗,浙江省电力设计院正在用
近日,软件加密狗的分散管理和易丢失性,给拥有大量加密狗的浙江省电力设计院带来了一系列的问题。好在浙江省电力设计院带及时使用了朝天椒USB Server方案,实现了加密狗的集中安全管控,避免了加密狗因为管理不善和遗失可能带来的巨…...

rust换源
在$HOME/.cargo/目录下建一个config文件。windows默认是C:\Users\user_name\.cargo。 config文件输入: [source.crates-io] registry "https://github.com/rust-lang/crates.io-index" # 使用 replace-with指明默认源更换为ustc源 replace-with ustc#…...

常见关系型数据库SQL增删改查语句
常见关系型数据库SQL增删改查语句: 创建表(Create Table): CREATE TABLE employees (id INT PRIMARY KEY,name VARCHAR(50),age INT,department VARCHAR(50) ); 插入数据(Insert Into): INSERT …...

OpenCV(二十七):图像距离变换
1.像素间距离 2.距离变换函数distanceTransform() void cv::distanceTransform ( InputArray src, OutputArray dst, int distanceType, int maskSize, int dstType CV_32F ) src:输入图像,数据类型为CV8U的单通道图像dst:输出图像,与输入图像…...

服务器就是一台电脑吗?服务器的功能和作用
服务器不仅仅是一台普通的电脑,它在功能和作用上有着显著的区别。下面是关于服务器的功能和作用的简要说明: 存储和共享数据:服务器可以用作数据存储和共享的中心。它们通常配备大容量的硬盘或固态硬盘,用于存储文件、数据库和其他…...

vue3实现塔罗牌翻牌
vue3实现塔罗牌翻牌 前言一、操作步骤1.布局2.操作3.样式 总结 前言 最近重刷诡秘之主,感觉里面的塔罗牌挺有意思,于是做了一个简单的塔罗牌翻牌动画(vue3vitets) 一、操作步骤 1.布局 首先我们定义一个整体的塔罗牌盒子&…...
分布式搜索引擎
1 DSL查询文档 elasticsearch的查询依然是基于JSON风格的DSL来实现的。 1.1.DSL查询分类 Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括: 查询所有:查询出所有数据,一…...
【2023最新版】腾讯云CODING平台使用教程(Pycharm/命令:本地项目推送到CODING)
目录 一、CODING简介 网址 二、CODING使用 1. 创建项目 2. 创建代码仓库 三、PyCharm:本地项目推送到CODING 1. 管理远程 2. 提交 3. 推送 4. 结果 四、使用命令推送 1. 打开终端 2. 初始化 Git 仓库 3. 添加远程仓库 4. 添加文件到暂存区 5. 提交更…...
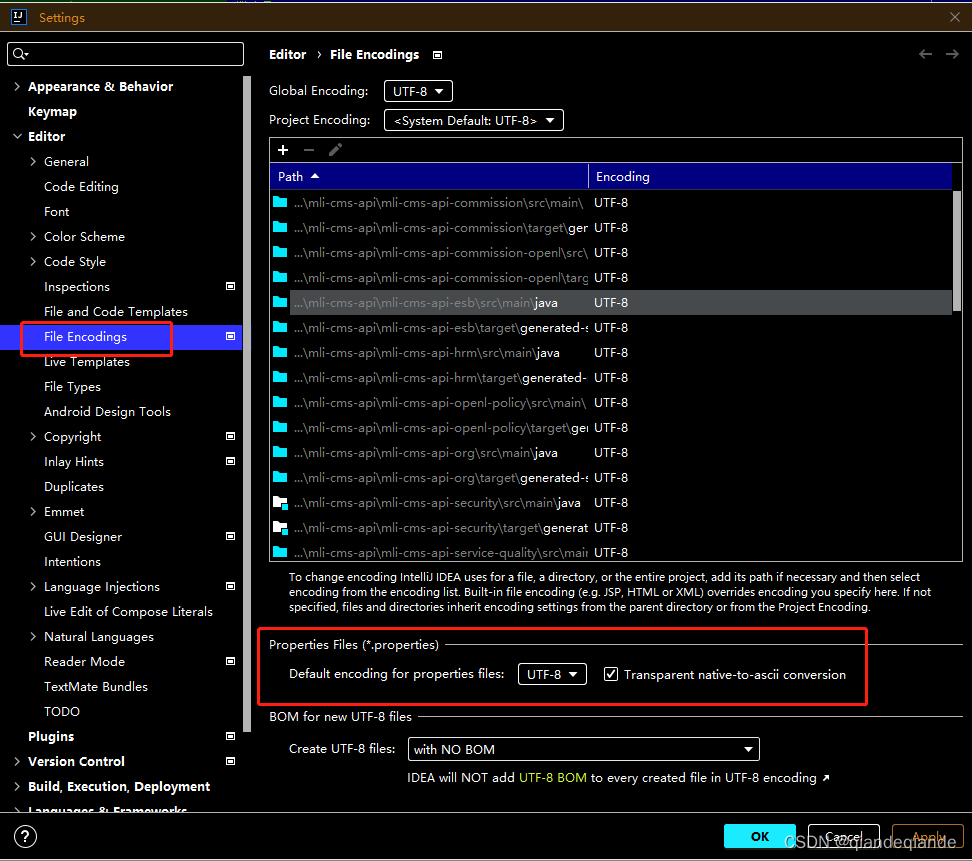
IDEA Properties 文件亂碼怎麼解決
1.FIle->Setting->Editor->File Encodings 修改Properties FIles 編碼顯示格式:UTF-8...

uniapp微信小程序用户隐私保护
使用wx.requirePrivacyAuthorize实现微信小程序用户隐私保护。 一、前言 微信小程序官方出了一个公告《关于小程序隐私保护指引设置的公告》。不处理的话,会导致很多授权无法使用,比如头像昵称、获取手机号、位置、访问相册、上传图片视频、访问剪切板…...

虚幻引擎4中关于设置关于体坐标系下的物体速度的相关问题
虚幻引擎4中关于设置关于体坐标系下的物体速度的相关问题 文章目录 虚幻引擎4中关于设置关于体坐标系下的物体速度的相关问题前言全局坐标系转体坐标系速度设置X轴方向的体坐标系速度设置Y轴方向的体坐标系速度XY轴体坐标系速度整合 Z轴速度的进一步设置解决办法 小结 前言 利…...
)
16 | Spark SQL 的 UDF(用户自定义函数)
UDF(用户自定义函数):Spark SQL 允许用户定义自定义函数,以便在 SQL 查询或 DataFrame 操作中使用。这些 UDF 可以扩展 Spark SQL 的功能,使用户能够执行更复杂的数据操作。 示例: // 注册UDF spark.udf.register("calculateDiscount", (price: Double, disc…...
蓝桥杯官网填空题(土地测量)
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 造成高房价的原因有许多,比如土地出让价格。既然地价高,土地的面积必须仔细计算。遗憾的是,有些地块的形状不规则,比…...

【Java项目实战】牛客网论坛项目1 - Spring入门与初识SpringMVC
目录 Spring 入门SpringInitializrApplicationContextAwareControllerDAODAO 名称索引ServiceConfig自动装配 初识 SpringMVCHttp 请求GETPOSTHTML 渲染响应 JSON 数据 Spring 入门 SpringInitializr IDEA 专业版自带的功能,也可以直接搜索对应网站,通…...
——操作指南(转自知乎))
Gurobi使用(一)——操作指南(转自知乎)
好像还是要学一下Gurobi如何使用的,不然这代码着实有点抽象了 一、入门操作 一般来说,求解一个数学规划模型的时候,通常会按照如下步骤解决问题: 设置变量---addVar()。 更新变量空间---update()。 设定目标函数---setObjective()。 设定约…...

嵌入式核心板选型实战:从AI加速到工业控制的设计权衡与趋势
1. 展会现场与行业风向初探上周,我作为飞凌嵌入式的一名老员工,亲身参与了2024上海国际嵌入式展。这不仅仅是一次公司产品的展示,更像是一场行业技术趋势的集中检阅。从人头攒动的展台到同行间热烈的技术交流,你能清晰地感受到&am…...

构建全志Tina Linux Docker编译镜像:从环境配置到CI/CD实践
1. 项目概述:为什么我们需要一个专属的Docker编译镜像?如果你和我一样,长期在嵌入式Linux开发领域摸爬滚打,那么“环境搭建”这四个字,大概率是你开发周期里最耗时、也最令人头疼的环节之一。尤其是当我们面对像全志Ti…...

NXP LPC2000中断向量校验和机制与Keil实现
1. NXP LPC2000设备向量校验和机制解析在嵌入式开发领域,NXP LPC2000系列微控制器以其ARM7内核和丰富的外设资源广受欢迎。这类设备有一个独特的启动要求——中断向量表的校验和验证机制。具体来说,地址0x00000014处(ARM保留的中断向量位置&a…...

Linux驱动开发:proc接口原理、实现与调试实战
1. 项目概述:为什么需要了解proc接口?在Linux驱动开发这条路上,很多开发者朋友都曾有过这样的困惑:我的驱动模块加载成功了,设备也识别了,但怎么才能直观地看到它内部的工作状态、配置参数,或者…...

OAuthlib错误排查实战:从invalid_grant到server_error的根因定位
1. 为什么OAuthlib的错误信息总让你一头雾水?刚接手一个老项目,登录流程突然崩了,控制台只甩出一行红字:invalid_grant。我下意识去翻OAuthlib文档,结果发现它压根不解释这个错误到底意味着什么——它只告诉你“授权无…...

神经网络概念解耦:手绘推演前向反向传播与梯度流建模
1. 这不是又一本“手把手教你写反向传播”的书——它专治神经网络学习中的“假懂症”你有没有过这种经历:看完了三遍吴恩达的神经网络课程,能默写出sigmoid导数公式,也能在Jupyter里跑通MNIST分类,但一被问到“为什么ReLU比tanh更…...

避开BLE开发第一个坑:搞懂广播帧里的TxAdd、ChSel字段,让你的智能硬件不再‘隐身’
避开BLE开发第一个坑:广播帧关键字段解析与实战排查指南 当你第一次将精心编写的固件烧录进蓝牙芯片,满心期待地用手机扫描设备时,却发现屏幕上空空如也——这种"设备隐身"的挫败感,几乎每个BLE开发者都经历过。问题的根…...

基于瑞萨R8C MCU的180度电角度无感FOC BLDC电机控制方案详解
1. 项目概述与核心需求解析大家好,我是老王,一个在电机控制和嵌入式系统开发领域摸爬滚打了十几年的工程师。今天想和大家深入聊聊一个非常具体且有意思的项目:如何基于瑞萨电子的R8C系列MCU,来实现一套180度电角度控制的无刷直流…...

基于RK3568嵌入式主板的智能炒菜机方案:从硬件选型到系统集成实战
1. 项目概述:当嵌入式主板“掌勺”智能厨房最近几年,智能厨电赛道卷得厉害,从智能电饭煲到自动炒菜机,大家都在琢磨怎么让做饭这件事变得更“傻瓜”。我接触过不少这类项目,发现一个核心痛点:很多所谓的“智…...

第36天:关系型数据库和MySQL概述
Python学习100天(从入门到精通系列文章) 文章目录 Python学习100天(从入门到精通系列文章) 前言 一、关系型数据库概述 1.1 数据持久化 1.2 数据库发展史 1.3 关系数据库特点 1.4 ER模型(实体关系模型) 1.5 主流关系数据库产品 二、MySQL 简介 三、安装 MySQL 3.1 Window…...