python-基本数据类型-笔记
数字型digit:int整型 float浮点型 complex复数
布尔型bool:True False
字符串str:用一对引号(单、双、三单、三双等引号)作为定界线
列表list:[ ]
元组tuple:( )
字典dict:{ } 由键值对组成 - - - {‘a’:1, ‘b’:2}
集合set:{ }
1.数据类型
1.1整数类型
1.1.1不同进制整数的转换
int() 十进制 - - - 将其他 的数字转为整数
bin() 二进制 - - - - - 0b开头,二进制整数,开头的0 is 零
oct() 八进制 - - - - - 0o开头,八进制整数,开头的0 is 零
hex() 十六进制 - - - 0x开头,十六进制整数,开头的0 is 零
bin(7) # '0b111'
oct(7) # '0o7'
hex(7) # '0x7'
bin(0x7) # '0b111' # 将十六进制转为二进制
1.1.2整型 int()
int() 参数为整数、实数、分数或合法的数字字符串
int(0b111) # 7 # 将二进制转为十进制
int(bin(7),2) # 7
int(hex(7),16) # 7
int('0b111',2) # 7 # 第二个参数必须要与隐含进制一致,0b隐含的是二进制
int('123',6) # 51 # 第一个参数没有隐含进制,arg2可以是2到36间的数字# 改代码为六进制,转为十进制 = 1*6**2 + 2*6**1 + 3*6**0 = 51
1.2浮点数类型
十进制形式 和 科学计数法(10为基数,用子母e或E作为幂的符号)
float() 将十进制的其他形式的数据转换为实数
float(4) # 4.0
float('3') # 3.0
1.3复数类型
复数有一个基本单位元素j,称为虚数单位,含有虚数单位的数叫做复数
complex(3) # (3+0j) # 3是实部
complex(4,5) # (4+5j) # 4是实部,5是虚部
complex('1+2j') # (1+2j) # 将str转为复数
complex('inf') # (inf+0j) # 无穷大
1.4其他函数
abs() - - - 计算实数的绝对值或者复数的模
divmod() - - - 同时计算两个数字的整数商和余数
pow() - - - 计算幂
round() - - - 对数字进行四舍五入
abs(-5) # 5
abs(-3+4j) # 5.0 # 复数实部和虚部的平方和的平方根
divmod(13,5) # (2, 3) # 12÷5 = 2 余 3
pow(2,3) # 2*2*2
pow(3,3,5) # 2 # 幂运算后再去余数 3*3*3/5 的余数为2
round(3.1234, 2) # 3.12 # 四舍五入
2.运算符
2.1算数运算符
+ 加 - - - 列表、元组、str合并与连接 - - - ‘a’ + ‘1’ = ‘a1’
- 减 - - - 集合差集 - - - {1,2,3,4,5} - {2,3,4} = {1, 5}
* 乘 - - - 序列重复 - - - ‘&’*3 = ‘&&&’
/ 除
// 取整除 - - - 返回商的整数部分
% 取余 - - - 返回余数
** 幂
2.2比较(关系)运算符
比较之后,条件成立返回True,否则False
== 等于
!= 不等于
>
<
>=
<=
2.3赋值运算符
a += 1 - - - a = a + 1
a *= c - - - a = a * c
a *= 2+3 - - - a = a * (2+3)
==操作符(等于)
=操作符(赋值)
2.4逻辑运算符
and 与 or 或 not 非
2.5运算符的优先级
** # 逻辑运算符
* / % // # 乘 除 取余 取整
+ - # 加 减
<= < > >= # 比较运算符
== != # 等于运算符
**= %= *= /= //= -= += = # 赋值运算符
not or and # 逻辑运算符
2.6成员运算符
in - - - 在······里面 - - - 在指定序列中找到找到值返回True
not in - - - 不在······里面
1 in (2,3) # False
1 not in (2,3) # True
2.7身份运算符
is - - - 是 - - - is用来判断两个标识符是不是引用自同一个对象 (id()函数用于获取对象内存地址)
is not - - - 不是
a = 1
b = a
a is b # True # 等价于 a == b
id(a) # 140722281894944
id(b) # 140722281894944
a is not b # False # 等价于 a != b
2.8集合运算符
& 交集 | 并集 -差集 ^ 对称差集
a = {1,2,3}
b = {3,4,5}
a & b # {3}
a | b # {1, 2, 3, 4, 5}
a - b # {1, 2}
a ^ b # {1, 2, 4, 5}
3.字符串
python语言使用Unicode编码表示字符
单行字符串 - - - 单引号 ' ' - - - 双引号 " "
多行字符串 - - - 三单引号 ''' ''' - - - 三双引号 """ """
续行符 - - - \
a = 'asdf\asdf'
a # 'asdf asdf'
\ 转义符 \' 表示输出'
\t 制表符 \n 换行符
3.1 索引和切片
3.1.1 索引
索引从0开始,从左到右依次增大 - - > 0,1,2,3,······
索引从-1开始,从右到左依次减小 - - > -1,-2,-3,-4,······
3.1.2 切片
切片slice
使用索引值来限定范围(左闭右开),根据步长从原序列中取出一部分组成新的序列 - - - 适用于str,list,tuple
字符串名[开始索引:结束索引:方向与步长]
从头开始,开始索引可以省略(:不可省) - - - [:3:步长]
到末尾结束,结束索引可以省略(:不可省) - - - [2::步长]
步长为1,步长和第二个冒号:可以省略
-
根据索引查字符串
str1 = 'asdfghjkl' str1[:] # 'asdfghjkl' # 截取完整的字符串,等价于str1[0:] str1[2:-1] # 'dfghjk' # 从第三个元素d开始,到 末尾-1 的字符串 str1[-2:] # 'kl' # 截取字符串末尾的两个字符 str1[::-1] # 'lkjhgfdsa' # 字符串的逆序(步长为1) # str1[-1::-1] -
根据字符查索引
str2 = 'abcdABCD' str2.index('d') # 3 str3 = 'asdfasdf' str3.index('d') # 2 # 查询的是字符串中首次出现该字符串的索引
3.2 操作运算符
| 运算符 | 描述 | 支持的数据类型 |
|---|---|---|
| + | 合并/拼接 | str,list,tuple |
| * | 重复 | str,list,tuple |
| in / not in | 元素是否(不)存在 | str,list,tuple,dict(对字典操作时,判断的是字典的键) |
| 比较运算符 > >= == < <= | 元素比较 | str,list,tuple |
str1 = 'hello'
str2 = 'world'
str1 + str2 # 'helloworld'
str1*3 # 'hellohellohello'
'h' in str1 # True# 字符串的比较的标准:ASCII码,Unicode编码表中的编码值
# 升序排列:数字 < 大写字母(A-Z) < 小写字母 (a-z)
a = 'A' < 'a' # True # 先计算'A' < 'a',再将返回值赋值给a
b = '123' > '1a1' # False # 先比较第一个字符,若相等,再比较第二个字符··· 2<a
chr(num)函数:返回Unicode编码值对应的字符 - - - character
ord(单字符)函数:返回单字符对应的Unicode编码值 - - - ordinal
chr(1),chr(2),chr(49),chr(65),chr(97),chr(21834),chr(38463)
# ('\x01', '\x02', '1', 'A', 'a', '啊', '阿')
chr(64) # '@'
ord('1'),ord('a'),ord('啊') # (49, 97, 21834)
ord('d') # 100
3.3字符串的格式化 format
默认顺序
'hi {}, welcome to my {}.'.format('Tom','boke')
# 'hi Tom, welcome to my boke.'
指定顺序
根据字符串指定参数的索引,在相应的位置填入参数
必须所有的{ }里都有索引,否则会报错
'这是一篇名为{1}的{0}'.format('博客','数据类型')
# '这是一篇名为数据类型的博客'
a = 1
b = 2
'{1} + {0} = {2}'.format(a,b,a+b)
# '2 + 1 = 3'
两个{{可以输出{,两个}}可以输出}
'{{ {} is a number}}'.format(0)
# '{ 0 is a number}'
format 方法的格式控制
,| : | 填充 | 对齐 | 宽度 | , | .精度 | 类型 |
|---|---|---|---|---|---|---|
| 引用符号 | 用于填充的 单个字符串 | <左对齐 >右对齐 ^居中对齐 | 槽的设定 输出宽度 | 数字的千位分隔符, 适用于整数和浮点数 | 浮点数小数部分的精度或字符串的最大输出长度 | 整数类型:b,c,d,o,x,X 浮点数类型:e,E,f,% |
默认左对齐,以空格将左边填充至宽度
整数类型:b 输出整数的二进制方式d 十进制o 八进制octx 小写十六进制hexX 大写十六进制hex浮点数类型:e 输出浮点数对应的小写字母e的指数形式E 输出浮点数对应的大写字母E的指数形式f 输出浮点数的标准浮点形式% 输出浮点数的百分比形式c 输出整数对应的Unicode字符
a = 'asdf'
print('{:*^10}'.format(a))
# ***asdf*** # 用*填充,宽度为10,居中对齐
a = 'abcd'
b = '#'
c = '^'
print('{0:{1}{3}{2}}'.format(a,b,10,c)) # 等价于'{:-^10}'.format(a)
# ###abcd###
a = 123456789
print('{:=>20,}'.format(a))
# =========123,456,789
'{:-^20.2f}'.format(12345.12345)
# '------12345.12------'
'{:.4}'.format('我是一个粉刷匠')
# '我是一个'
'{0:b},{0:d},{0:o},{0:x},{0:X}'.format(123)
# '1111011,123,173,7b,7B' # {0:b} 0 is 槽里索引为0的数,这里123的二进制是1111011
'{1:b}'.format(1,2)
# '10'
'{0:e}, {0:E}, {0:f}, {0:.2f}, {0:.2%}'.format(1.23)
# '1.230000e+00, 1.230000E+00, 1.230000, 1.23, 123.00%'
'{0:c}, {1:c}'.format(65,425)
# 'A, Ʃ'
3.4字符串内建函数
len(x)
str(x)
chr(x) - - - 返回Unicode编码值x对应的单字符
ord(x) - - - 返回单字符x表示的Unicode编码值
hex(x)
oct(x)
max(x) - - - 返回字符串x中对应的Unicode编码值最大的单字符
min(x) - - - 返回字符串x中对应的Unicode编码值最小的单字符
str(0x2A) # 42 # 十六进制0x2A的十进制字符串42
max('hello') # 'o'
chr(65) # 'A'
ord('1') # 49
3.5字符串的处理方法
str.count(字符或字符串) - - - 计算某字符或字符串或标点出现的次数
str.index(某字符) - - - 某字符第一次出现的索引
str.capitalize() - - - 字符串的第一个字符大写,其余小写
str.title() - - - 把字符串每个单词的首字母大写
str.lower() - - - 转换string中所有大写字母为小写
str.upper() - - - 将所有小写转换为大写
str.swapcase() - - - 翻转string中的大小写
a = 'hello world!'
a.count('l') # 3 # l出现3次
a.index('w') # 6 # w在第7个位置,索引为6
a.capitalize() # 'Hello world!'
a.title() # 'Hello World!'
a.upper() # 'HELLO WORLD!'
b = 'aBc'
b.swapcase() # 'AbC'
-
str.split(sep)- - - 根据sep分割str - - - sep默认为空格
分割后的内容以列表形式返回'python is a language'.split('a') # ['python is ', ' l', 'ngu', 'ge'] -
str.replace(old,new)- - - 将old字符串换位new字符串'python is a language'.replace('python','java') # 'java is a language' -
str.center(width,fillchar)- - - 返回长度为width的字符串,字符串处于居中位置,两侧使用fillchar填充'python'.center(20,'=') # '=======python=======' -
str.strip(chars)- - - 删除str字符串头尾中参数char指定字符(默认为空格或换行符)
不会改变原来的字符串a = ' python is our friend' a.strip() # 'python is our friend' a.strip('f.ned') # 包含字符串a头或尾部的字符,可以不按顺序填入 # ' python is our fri' # 开头没有f,所有没有删除,尾部有end并删除 a.strip(' pf.nyedi') # 'thon is our fr' # 将头 pf删除了,还将尾部的iend删除了 a.strip('fny') # ' python is our friend' # 头和尾都没有fny,所以不删除 -
str.join(iter)- - - 将str、tuple、list中的元素以指定的字符(分隔符)连接生成一个新的字符串iter是一个具备迭代性质的变量
'=hi='.join('ABC') # 'A=hi=B=hi=C' # 使用=hi=将ABC连接为新的字符串 ','.join('asdf') # 'a,s,d,f'
3.6类型判断 type
type(x) - - - 对变量x进行类型查看与判断
print(type(10),type('a'),type(10.12),type([1,2,3]),type({a,b,c}),type({a:1,b:2}))
# <class 'int'> <class 'str'> <class 'float'> <class 'list'> <class 'set'> <class 'dict'>
相关文章:

python-基本数据类型-笔记
数字型digit:int整型 float浮点型 complex复数 布尔型bool:True False 字符串str:用一对引号(单、双、三单、三双等引号)作为定界线 列表list:[ ] 元组tuple:( ) 字典dict:{ } 由键值…...

如何使用API数据接口给自己创造收益
使用API数据接口创造收益的方法有很多,以下是一些常见的方法,并附有代码示例: 一、数据分析与预测 通过获取API数据接口中的大量数据,我们可以进行深入的数据分析,并利用这些数据来预测未来的趋势和行为。例如&#…...
第三方软件信息安全测评服务范围
安全测试 第三方软件信息安全cnas资质测评服务范围: 1、信息安全风险评估 依据《GB/T 20984-2007 信息安全技术信息安全风险评估规范》,通过风险评估项目的实施,对信息系统的重要资产、资产所面临的威胁、资产存在的脆弱性、已采取的防护措…...

测试开发 | Java 接口自动化测试首选方案:REST Assured 实践
1 . 初识 REST Assured 在 REST Assured 的官方 GitHub 上有这样一句简短的描述: Java DSL for easy testing of REST services 简约的 REST 服务测试 Java DSL 1.1 优点: REST Assured 官方的 README 第一句话对进行了一个优点的概述,总的…...
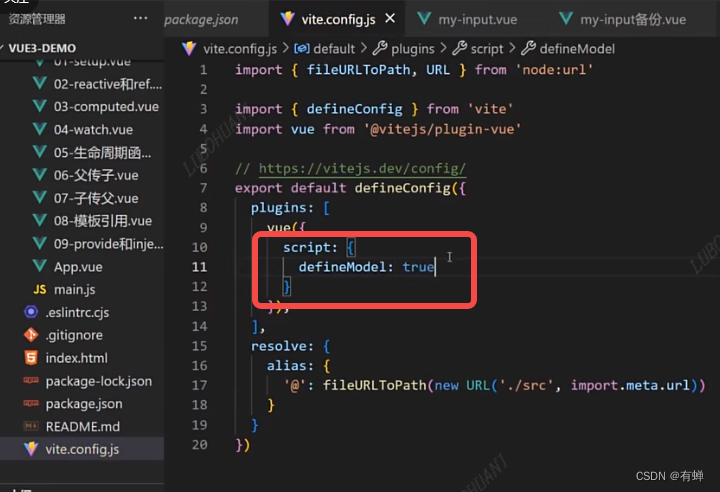
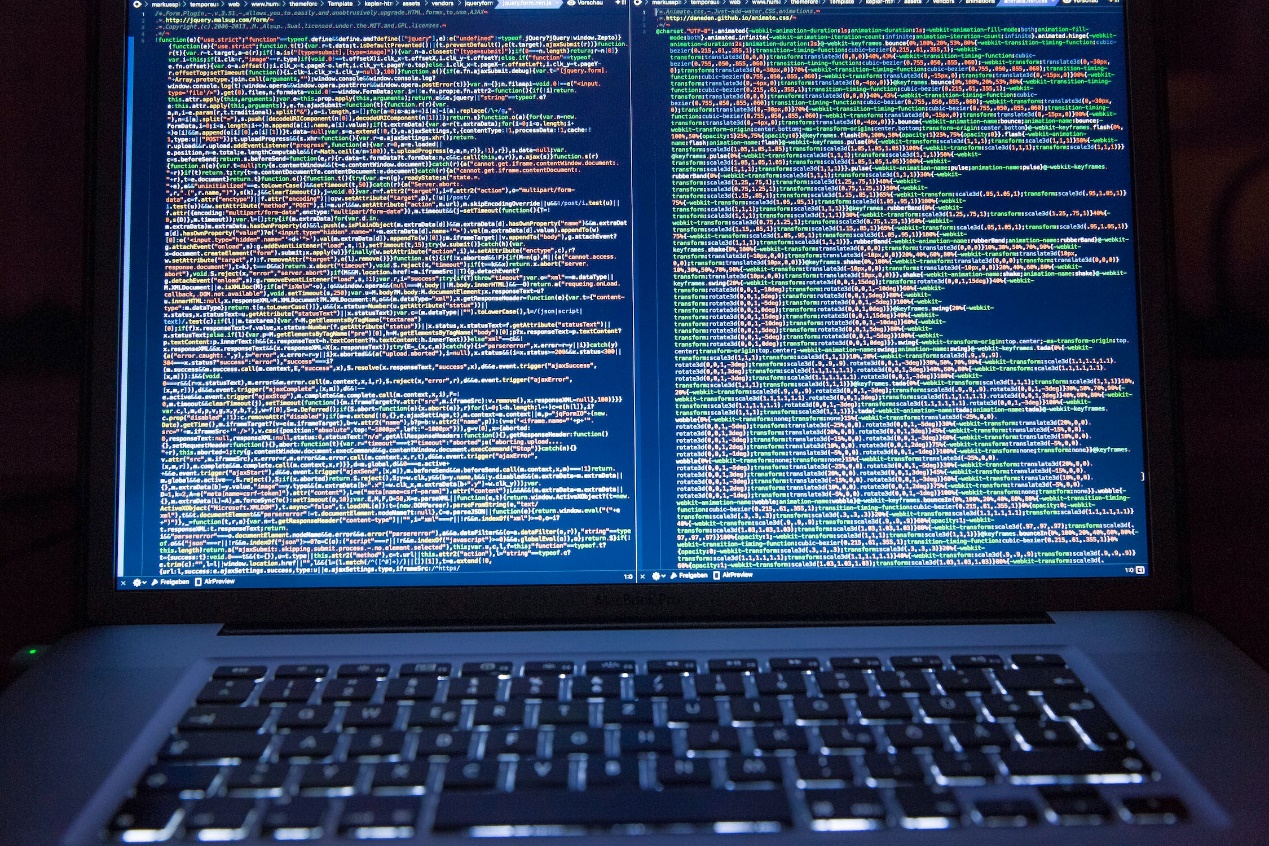
vue3:13、Vue3.3新特性-defineModel
旧版本的语法 新版本语法...

如何理解C++中的void*
1.什么是void* 首先void*中的void代表一个任意的数据类型,"星号"代表一个指针,所以其就是一个任意数据类型的指针。 其实就是一个未指定跳跃力的指针。 那void*的跳跃力又什么时候指定?在需要使用的时候指定就可以了,…...
MVC,MVP,MVVM的理解和区别
MVC MVC ,早期的开发架构,在安卓里,用res代表V,activity代表Controller层,Model层完成数据请求,更新操作,activity完成view的绑定,以及业务逻辑的编写,更新view…...
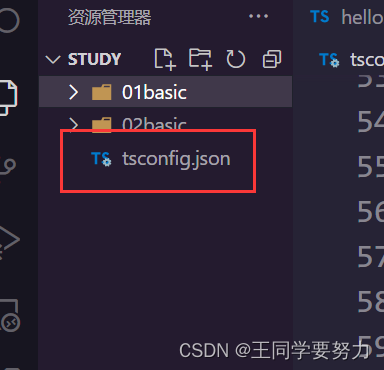
【TypeScript】一直提示 :无法重新声明块范围变量
【TypeScript】一直提示 :无法重新声明块范围变量 问题描述:在VSCode中编写ts代码时,编写保存完之后,通过tsc 文件名.ts编译就会看到变量名下面出现了红色的波浪线,提示的内容是无法重新声明块范围变量。 解决方法&am…...

【python自动化】七月PytestAutoApi开源框架学习笔记(一)
前言 本篇内容为学习七月大佬开源框架PytestAutoApi记录的相关知识点,供大家学习探讨 项目地址:https://gitee.com/yu_xiao_qi/pytest-auto-api2 阅读本文前,请先对该框架有一个整体学习,请认真阅读作者的README.md文件。 本文…...

Python学习 -- logging模块
logging 模块是 Python 中用于记录日志的标准库,它提供了丰富的功能,可以帮助开发者进行日志记录和管理。以下是关于logging模块的详细使用方式,包括日志级别、处理流程、Logger 类、Handler 类、Filter 类、Formatter 类以及模块中常用函数等…...

【socket】getaddrinfo、getsockname、getpeername对比
这三个函数都是在网络编程中用来获取地址信息的,但是它们的使用场景和功能有所不同。getaddrinfo(): 这个函数主要用于将一个主机名(或者 IP 地址)和端口号转换成适用于 socket() 函数的一个或多个套接字地址结构。它能够处理 IPv4 和 IPv6 地…...
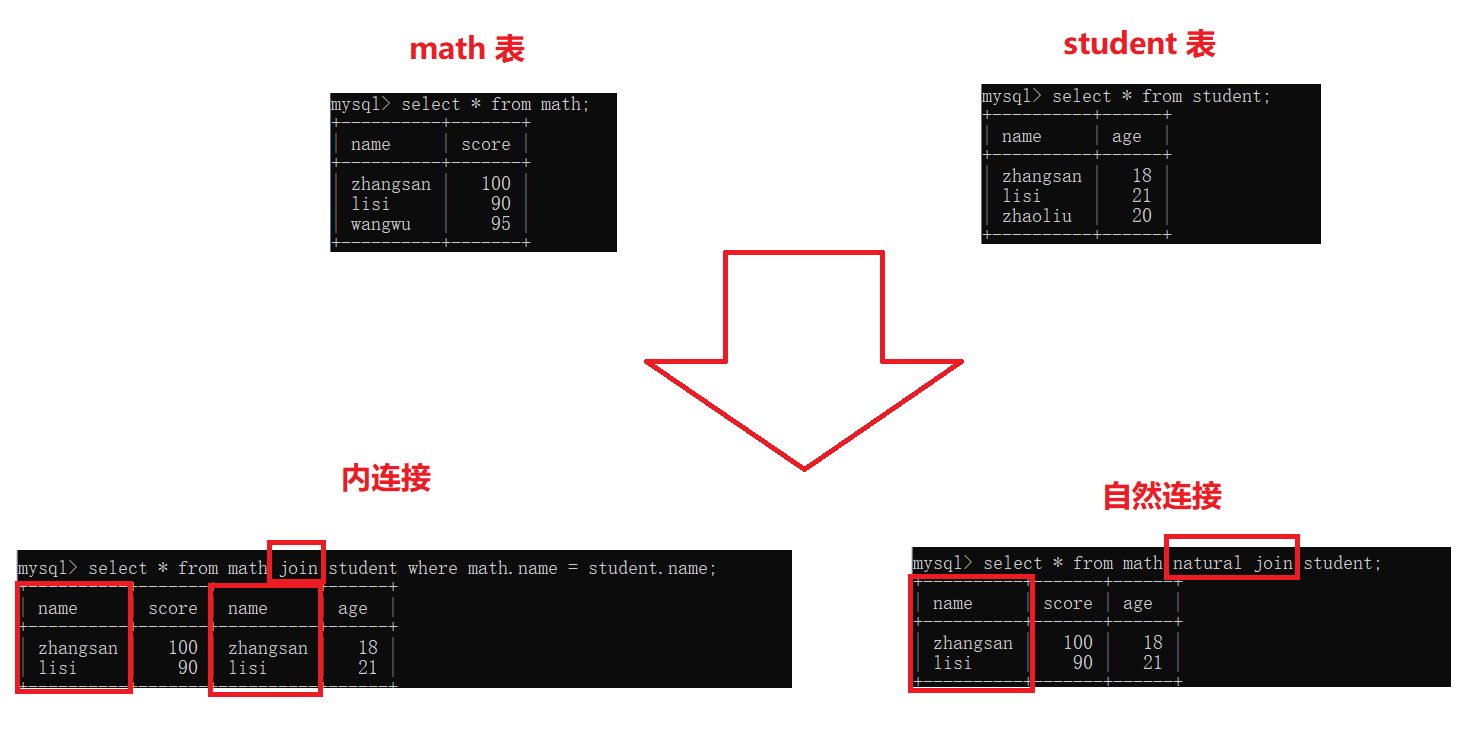
【MySQL】表的增删改查(进阶)
表的增删改查(进阶) 一. 数据库约束1. 约束类型2. NULL约束3. UNIQUE:唯一约束4. DEFAULT:默认值约束5. PRIMARY KEY:主键约束6. FOREIGN KEY:外键约束7. CHECK约束 二. 表的设计1. 一对一2. 一对多3. 多对…...

关于安卓13中Android/data目录下的文件夹只能查看无法进行删改的问题
前言 因为升级了安卓13,然后有个app需要恢复数据,打算和以前一样直接删除Android/data下对应目录再添加,结果不行,以下是结合网上以及自己手机情况来做的一种解决方案。 解决 准备: 待恢复app(包名com.…...
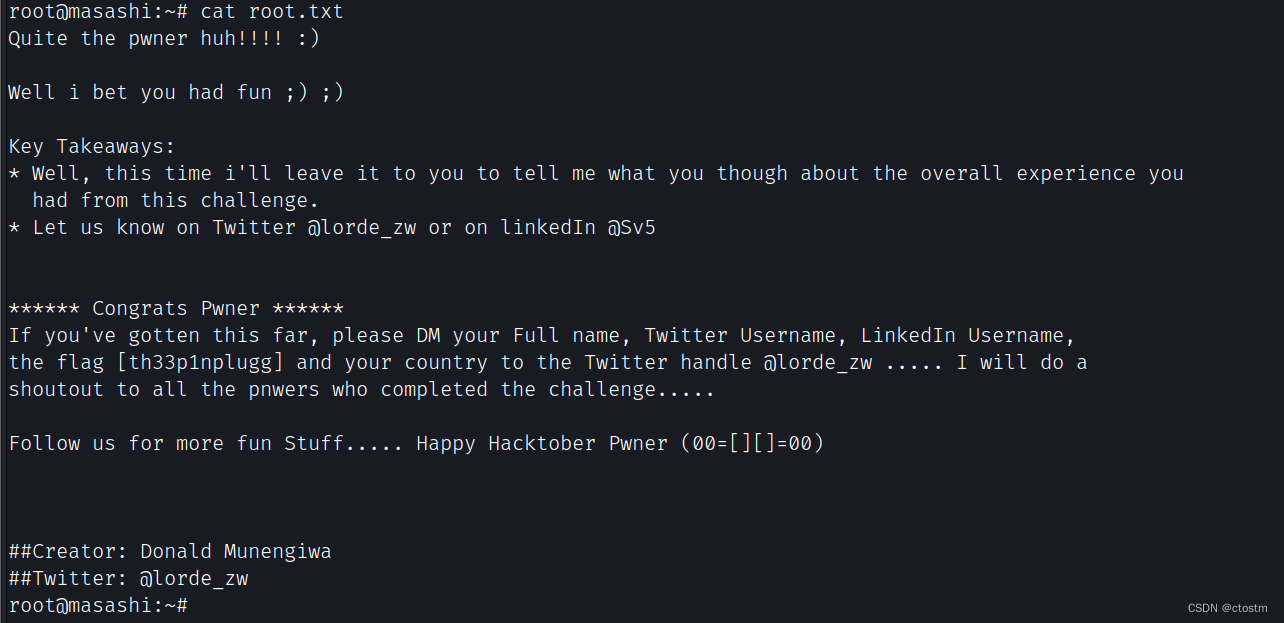
Vulnhub: Masashi: 1靶机
kali:192.168.111.111 靶机:192.168.111.236 信息收集 端口扫描 nmap -A -sC -v -sV -T5 -p- --scripthttp-enum 192.168.111.236查看80端口的robots.txt提示三个文件 snmpwalk.txt内容,tftp服务在1337端口 sshfolder.txt内容,…...
校园二手物品交易系统微信小程序设计
系统简介 本网最大的特点就功能全面,结构简单,角色功能明确。其不同角色实现以下基本功能。 服务端 后台首页:可以直接跳转到后台首页。 用户信息管理:管理所有申请通过的用户。 商品信息管理:管理校园二手物品中…...
Pixillion Pro for Mac:将您的图像转换为艺术佳作
Pixillion for Mac有着非常强大的图像转换功能和简单的使用方法,帮助你快速完成大批量图像转换的工作,支持一键转换jpeg、jpg、bmp、png、gif、raf、heic等各种格式的图像文件,同时pixillion mac激活版还提供了图像旋转、添加水印、调整图像大…...

【上海迪士尼度假区】技术解决方案
开源平台地址Giteehttps://gitee.com/issavior/disney 技术解决方案 1. 背景2. 技术架构3. 业务架构3.1 架构图3.2 说明 4. 技术能力4.1 自研中间件4.2 定制化中间件 5. 领域模型6. 数据模型7. 交易链路8. 状态机8. 接口文档 1. 背景 上海迪士尼度假区已运营近10年,…...
每日刷题-2
目录 一、选择题 二、编程题 1、倒置字符串 2、排序子序列 3、字符串中找出连续最长的数字串 4、数组中出现次数超过一半的数字 一、选择题 1、 题目解析: 二维数组初始化的一般形式是: 数据类型 数组名[常量表达式1][常量表达式2] {初始化数据}; 其…...

AOSP内置搜狗输入并设置默认输入法
前期准备 AOSP分支:aosp13_r7 系统版本:Ubuntu 22.04.1 LTS 工具:手,vscode,winscp(因为我是用的服务器编译) 下载搜狗输入法 思路: 1.集成搜狗输入法到aosp 2.删除系统输入法 3.设置搜狗输入法为默…...

ICCV 2023|通过慢学习和分类器对齐在预训练模型上进行持续学习
点击蓝字 关注我们 AI TIME欢迎每一位AI爱好者的加入! 作者介绍 张耕维 悉尼科技大学在读博士生,研究方向为持续学习 报告题目 通过慢学习和分类器对齐在预训练模型上进行持续学习 内容简介 持续学习研究的目标在于提高模型利用顺序到达的数据进行学习的…...

Wren AI:数据民主化的技术赋能者
Wren AI:数据民主化的技术赋能者 【免费下载链接】WrenAI Turn any AI Agents into world-class data analysts through the open context layer that gives AI agents grounded, governed memory, context, SQL across 20 data sources, that helps you build GenB…...

抖音内容批量下载终极指南:免费保存视频、图集、音乐和直播回放
抖音内容批量下载终极指南:免费保存视频、图集、音乐和直播回放 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallb…...

Sub-Zero性能优化:7个技巧让你的Plex字幕运行如飞
Sub-Zero性能优化:7个技巧让你的Plex字幕运行如飞 【免费下载链接】Sub-Zero.bundle Subtitles for Plex, as good you would expect them to be. 项目地址: https://gitcode.com/gh_mirrors/su/Sub-Zero.bundle Sub-Zero是Plex媒体服务器最强大的字幕插件之…...

边缘AI闭环数控系统:基于IIoT的轻量级CNC智能改造实践
1. 项目概述:这不是在改装一台机床,而是在给金属切削装上“神经系统”“AI-Driven Machining: Building a Closed-Loop CNC System with IIoT Feedback (Building the CNC)”——这个标题里没有一个词是虚的。它不是讲怎么用AI生成G代码,也不…...

还有人记得这种古老的语言吗?知道的没几个
前两天偶然看到一个熟悉又陌生的词汇, cobol,瞬间又勾起了我多年前的记忆,不知道还有多少人记得这种古老的语言,用过它的应该更是寥寥无几吧!今天来回忆杀。 COBOL(Common Business-Oriented Language&…...

iOS自动化测试环境搭建:Xcode签名与WebDriverAgent配置全指南
1. 为什么iOS自动化测试环境比Android更让人头疼——从Xcode签名到WebDriverAgent的硬门槛AppiumPython实现iOS自动化测试~环境搭建,这短短十几个字背后,藏着绝大多数刚接触iOS自动化的新手在前三天反复重装系统、重启Mac、怀疑人生的真实写照。我带过六…...

数据安全合规实战:等保2.0和GDPR要求下的文件加密配置清单
从“过等保”到“过审计”,一份可直接照抄的配置模板又到了每年合规审计季。去年我们公司同时面临等保2.0三级复测和欧盟客户要求的GDPR合规审查,其中文件加密是两者共同的重点项。我们以天锐绿盾为基础,整理了一套加密合规配置清单ÿ…...

本地 AI 编码助手从 0 配起来:先选模型,再接 Ollama、VS Code、Claude Code 和 Codex
配本地 AI 编码助手,我现在最不建议的做法,就是打开 Ollama 以后直接搜一个最大模型下载。 这条路我踩过。 模型能跑起来,不代表能写代码。能写一个函数,不代表能进项目改文件。能在终端里回一句话,也不代表 Claude …...

课堂教学PPT模板平台深度测评与选用指南
一、引言:PPT—— 课堂教学的重要辅助工具在当今的课堂教学中,PPT 已经成为了教师们不可或缺的 “魔法道具”。一份精心设计的 PPT,就像一位无声的助教,能够将抽象的知识变得直观形象,将枯燥的内容变得生动有趣。它不仅…...

HTTPS一文通
https 的出现,为解决网络加密通信提供了完美的解决方案。现在得到了非常普遍的运用。但 https 的原理和部署方式还存在一些较迷惑的点。 一、基础数学知识 在普通的http通讯过程中,前端浏览器和服务器之间传递的都是明文,这样敏感信息就容易被…...