Java缓存理解

CPU占用:如果你有某些应用需要消耗大量的cpu去计算,比如正则表达式,如果你使用正则表达式比较频繁,而其又占用了很多CPU的话,那你就应该使用缓存将正则表达式的结果给缓存下来。
数据库IO性能:如果发现有大量数据需要频繁查询使用,或者某些数据不会频繁变更时,为了提高数据库IO性能,可以使用缓存
缓存定义
所谓缓存,就是将程序或系统经常要调用的对象存在内存中,一遍其使用时可以快速调用,不必再去创建新的重复的实例。这样做可以减少系统开销,提高系统效率。
缓存主要可分为二大类:
通过文件缓存,顾名思义文件缓存是指把数据存储在磁盘上,不管你是以XML格式,序列化文件DAT格式还是其它文件格式;
内存缓存,也就是创建一个静态内存区域,将数据存储进去,例如我们B/S架构的将数据存储在Application中或者存储在一个静态Map中。
本地缓存
所谓的本地缓存是相对于网络而言的(包括集群,数据库访问等)
在系统中,有些数据,数据量小,但是访问十分频繁(例如国家标准行政区域数据或者一些数据字典等),针对这种场景,需要将数据搞到应用的本地缓存中,以提升系统的访问效率,减少无谓的数据库访问(数据库访问占用数据库连接,同时网络消耗比较大)
但是有一点需要注意,就是缓存的占用空间以及缓存的失效策略。
分布式/集群缓存定义
传统单机缓存概念的一个延伸,用于表示能跨越多台服务器,同时具有可扩展性的缓存。说白了,就是将本地缓存数据存储到远程可集群的缓存载体上,利用网络进行数据交换的一种缓存方式
常用集群载体:Redis;Memcached
多级缓存
定义:系统中使用多种缓存(本地缓存及分布式缓存)技术对数据进行缓存,应用数据时,按照优先级(先本地,后分布式)对数据进行依次读取,如果所有缓存中都无数据,则对数据库进行数据读写,并将取到的数据依次(先分布式,后本地)进行缓存更新
为什么使用多级缓存技术(以一级缓存L1(Caffeine)和二级缓存L2(Redis)举例)
如果只有L1,那么在系统重新部署后,缓存数据全部消失;
如果只要L2,使用Redis,很多系统都会使用云服务,这时访问Redis会有一定的网络I/O以及序列化反序列化,虽然性能很高但是其终究没有本地内存L1快
多级缓存常用技术
利用Caffeine做一级缓存,Redis作为二级缓存。
首先去Caffeine中查询数据,如果有直接返回。如果没有则进行第2步。
再去Redis中查询,如果查询到了返回数据并在Caffeine中填充此数据。如果没有查到则进行第3步。
最后去Mysql中查询,如果查询到了返回数据并在Redis,Caffeine中依次填充此数据。
对于Caffeine的缓存,如果有数据更新,只能删除更新数据的那台机器上的缓存,其他机器只能通过超时来过期缓存,超时设定可以有两种策略
设置成写入后多少时间后过期
设置成写入后多少时间刷新
缓存更新
先删除缓存,再更新数据库。
这个操作有一个比较大的问题,在对缓存删除完之后,有一个读请求,这个时候由于缓存被删除所以直接会读库,读操作的数据是老的并且会被加载进入缓存当中,后续读请求全部访问的老数据。
先更新数据库,再删除缓存(推荐)
有一个数据此时是没有缓存的,所以查询请求会直接落库,更新操作在查询请求之后,但是更新操作删除数据库操作在查询完之后回填缓存之前,就会导致我们缓存中和数据库出现缓存不一致,但是这个问题几率特别小。
为什么要删除缓存,而不是更新缓存
你可以想想当有多个并发的请求更新数据,你并不能保证更新数据库的顺序和更新缓存的顺序一致,那就会出现数据库中和缓存中数据不一致的情况。所以一般来说考虑删除缓存。
缓存坑货三剑客
缓存穿透
解释:缓存穿透是指查询的数据在数据库是没有的,那么在缓存中自然也没有,所以,在缓存中查不到就会去数据库取查询,这样的请求一多,那么我们的数据库的压力自然会增大
解决方案:
约定:对于返回为NULL的依然缓存,对于抛出异常的返回不进行缓存,注意不要把抛异常的也给缓存了。采用这种手段的会增加我们缓存的维护成本,需要在插入缓存的时候删除这个空缓存,当然我们可以通过设置较短的超时时间来解决这个问题。
制定一些规则过滤一些不可能存在的数据,小数据用BitMap,大数据可以用布隆过滤器,比如你的订单ID 明显是在一个范围1-1000,如果不是1-1000之内的数据那其实可以直接给过滤掉。
缓存击穿
解释:对于某些key设置了过期时间,但是其是热点数据,如果某个key失效,可能大量的请求打过来,缓存未命中,然后去数据库访问,此时数据库访问量会急剧增加。
解决方案:
加分布式锁:加载数据的时候可以利用分布式锁锁住这个数据的Key,在Redis中直接使用setNX操作即可,对于获取到这个锁的线程,查询数据库更新缓存,其他线程采取重试策略,这样数据库不会同时受到很多线程访问同一条数据。
异步加载:由于缓存击穿是热点数据才会出现的问题,可以对这部分热点数据采取到期自动刷新的策略,而不是到期自动淘汰。淘汰其实也是为了数据的时效性,所以采用自动刷新也可以。
缓存雪崩
解释:缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
解决方案:
增加缓存系统可用性,通过监控关注缓存的健康程度,根据业务量适当的扩容缓存。
采用多级缓存,不同级别缓存设置的超时时间不同,及时某个级别缓存都过期,也有其他级别缓存兜底。
缓存的过期时间可以取个随机值,比如以前是设置10分钟的超时时间,那每个Key都可以随机8-13分钟过期,尽量让不同Key的过期时间不同。
缓存监控
很多人对于缓存的监控也比较忽略,基本上线之后如果不报错然后就默认他就生效了。但是存在这个问题,很多人由于经验不足,有可能设置了不恰当的过期时间,或者不恰当的缓存大小导致缓存命中率不高,让缓存就成为了代码中的一个装饰品。所以对于缓存各种指标的监控,也比较重要,通过其不同的指标数据,我们可以对缓存的参数进行优化,从而让缓存达到最优化
相关文章:
Java缓存理解
CPU占用:如果你有某些应用需要消耗大量的cpu去计算,比如正则表达式,如果你使用正则表达式比较频繁,而其又占用了很多CPU的话,那你就应该使用缓存将正则表达式的结果给缓存下来。 数据库IO性能:如果发现有大…...

MHA高可用及故障切换
一、什么是 MHA MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过程中最大…...

1000元订金?华为折叠屏手机MateX5今日开始预订,售价尚未公布
华为最新款折叠屏手机Mate X5今日在华为商城开始预订,吸引了众多消费者的关注。预订时需交纳1000元的订金,而具体售价尚未公布。据华为商城配置表显示,Mate X5预计将搭载Mate 60系列同款麒麟9000S处理器,或可能搭载麒麟9100处理器…...
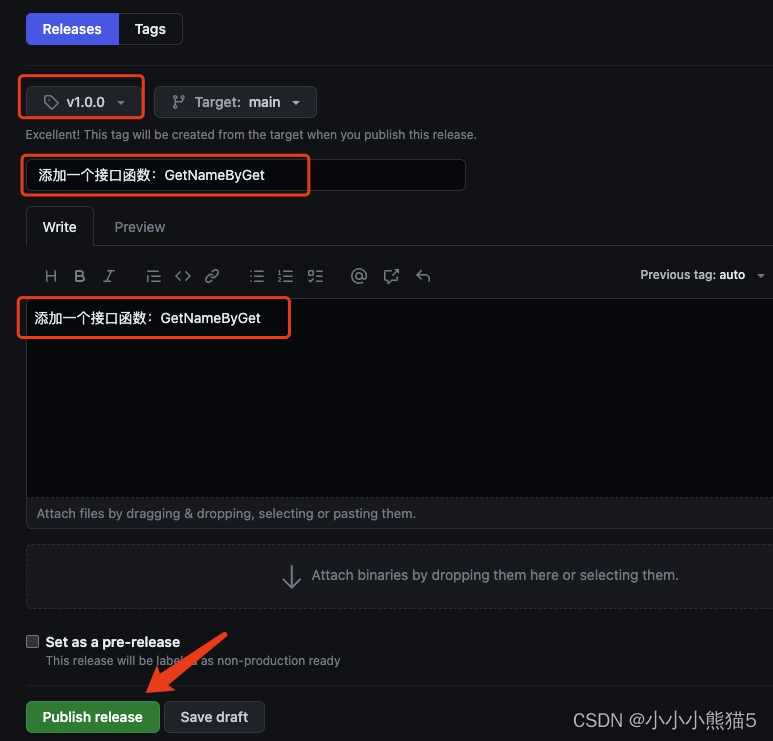
Golang编写客户端SDK,并开源发布包到GitHub,供其他项目import使用
目录 编写客户端SDK,并开源发布包到GitHub1. 创建 GitHub 仓库2. 构建项目,编写代码Go 代码示例:项目目录结构展示: 3. 提交代码到 GitHub仓库4. 发布版本5. 现在其他人可以引用使用你的模块包了 编写客户端SDK,并开源…...

手写Mybatis:第10章-使用策略模式,调用参数处理器
文章目录 一、目标:参数处理器二、设计:参数处理器三、实现:参数处理器3.1 工程结构3.2 参数处理器关系图3.3 入参数校准3.4 参数策略处理器3.4.1 JDBC枚举类型修改3.4.2 类型处理器接口3.4.3 模板模式:类型处理器抽象基类3.4.4 类…...

pair 是 C++ 标准库中的一个模板类,用于存储两个对象的组合
pair 是 C 标准库中的一个模板类,用于存储两个对象的组合。它位于 <utility> 头文件中。 pair 类的定义如下: template <class T1, class T2> struct pair {T1 first;T2 second;pair();pair(const T1& x, const T2& y);template&l…...
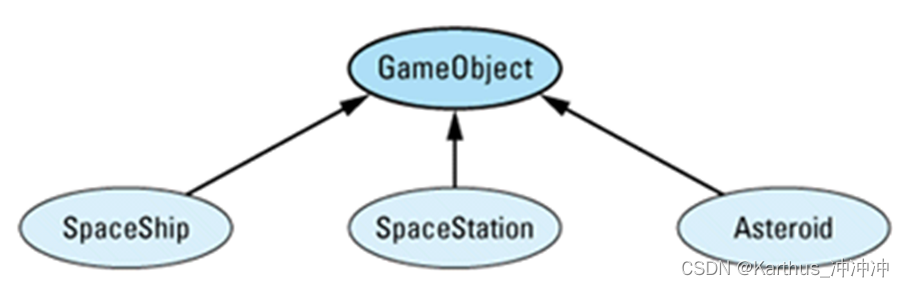
More Effective C++学习笔记(5)
目录 条款25:将构造函数和非成员函数虚化条款26:限制某个类所能产生的对象数量条款27:要求(或禁止)对象产生于heap(堆)之中条款28:智能指针条款29:引用计数条款30&#x…...
SpringMVC之CRUD(直接让你迅速完成部署)
一、项目创建 首先创建一个基于maven的项目部署,如果有些插件没有的话可以参考mybatis入门Idea搭建 二、配置依赖导入 依赖导入 1、pom.xml 需要根据自己的文件来进行导入,并不是原本照着导入 <project xmlns"http://maven.apache.org/POM/4.0.0…...

Github Copilot连接不上服务器
现象 报错:[ERROR] [default] [2023-09-08T15:47:01.542Z] GitHub Copilot could not connect to server. Extension activation failed: “connect ETIMEDOUT 20.205.243.168:443” 原因 DNS解析api.github.com的地址到20.205.243.168,但实际上这个地…...
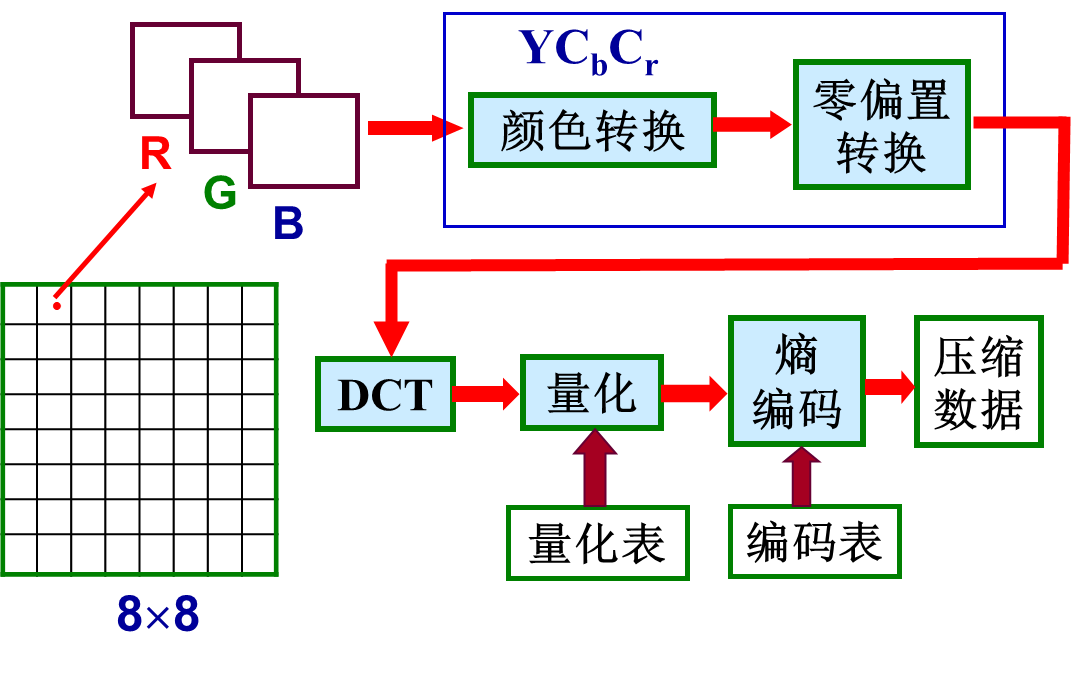
(数字图像处理MATLAB+Python)第十二章图像编码-第三、四节:有损编码和JPEG
文章目录 一:有损编码(1)预测编码A:概述B:DM编码C:最优预测器 (2)变换编码A:概述B:实现变换编码的主要问题 二:JPEG 一:有损编码 &am…...

基于SpringBoot + Vue的项目整合WebSocket的入门教程
1、WebSocket简介 WebSocket是一种网络通信协议,可以在单个TCP连接上进行全双工通信。它于2011年被IETF定为标准RFC 6455,并由RFC7936进行补充规范。在WebSocket API中,浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性…...

AI智能机器人的语音识别是如何实现的 ?
什么是智能语音识别系统?语音识别实际就是将人类说话的内容和意思转化为计算机可读的输入,例如按键、二进制编码或者字符序列等。与说话人的识别不同,后者主要是识别和确认发出语音的人并非其中所包含的内容。语音识别的目的就是让机器人听懂…...
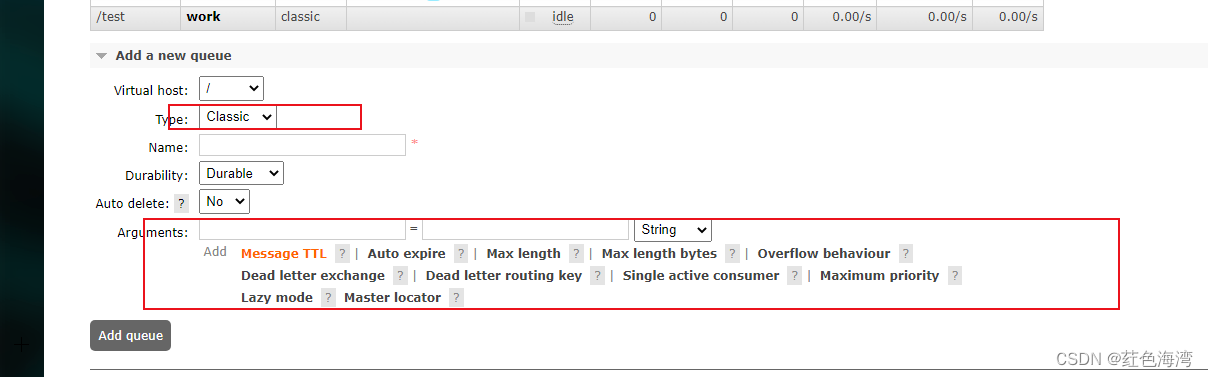
RabbitMQ: 死信队列
一、在客户端创建方式 1.创建死信交换机 2.创建类生产者队列 3.创建死信队列 其实就是一个普通的队列,绑定号私信交换机,不给ttl,给上匹配的路由,等待交换机发送消息。 二、springboot实现创建类生产者队列 1.在消费者里的…...
)
232 - Crossword Answers (UVA)
这道题因为我把puzzle打成了Puzzle,卡了我很久…………真的太无语了。 题目链接如下: Online Judge 我的代码如下: #include <cstdio> #include <cctype> #include <set> const int maxx 10;int r, c, kase, cnt, tem…...

MySQL表结构设计规范
一、表设计 1. 命名规范 表名由小写英文字母和下划线组成表必须填写描述信息表名中的英文单词应该使用单数形式临时表以 tmp 为前缀,以日期为后缀备份表以 bak 为前缀,以日期为后缀使用hash、md5 进行散表,表名后缀使用16进制 2. 设计规范…...
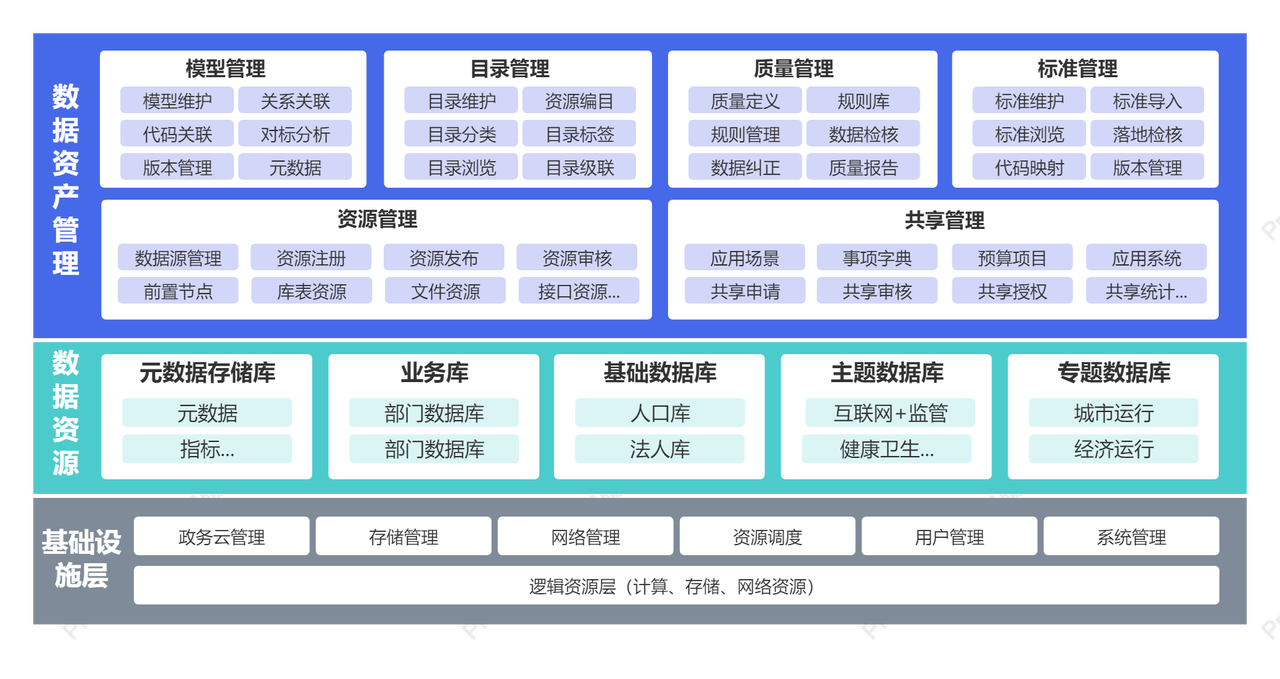
如何利用ProcessOn 做资产管理流程图
资产管理 是一家公司最重要的管理活动。好的资产管理可以让资源最优化利用,实现资产价值的最大化。可以帮助组织管理和降低风险。同时当需要决策的时候,对资产数据进行分析和评估,也可以帮助做出更明智的决策,如优化资产配置、更新…...
geopandas 笔记:geometry上的操作汇总
如无特殊说明,数据主要来自:GeoDataFrame 应用:公园分布映射至subzone_UQI-LIUWJ的博客-CSDN博客 0 读入数据 subzone gpd.read_file(ura-mp19-subzone-no-sea-pl.geojson) subzone subzone_tstsubzone[0:5] subzone_tst subzone_tst.plot…...

【MongoDB】Ubuntu22.04 下安装 MongoDB | 用户权限认证 | skynet.db.mongo 模块使用
文章目录 Ubuntu 22.04 安装 MongoDB后台启动 MongoDBshell 连入 MongoDB 服务 MongoDB 用户权限认证创建 root 用户开启认证重启 MongoDB 服务创建其他用户查看用户信息验证用户权限删除用户 skynet.db.mongo 模块使用authensureIndexfind、findOneinsert、safe_insertdelete、…...
Python对象序列化
迷途小书童的 Note 读完需要 7分钟 速读仅需 3 分钟 大家好,我是迷途小书童! 在 Python 开发中,我们经常需要将对象数据保存到磁盘,或者通过网络传输对象信息。这时就需要序列化,Pickle 库为我们提供了极为方便的对象序…...
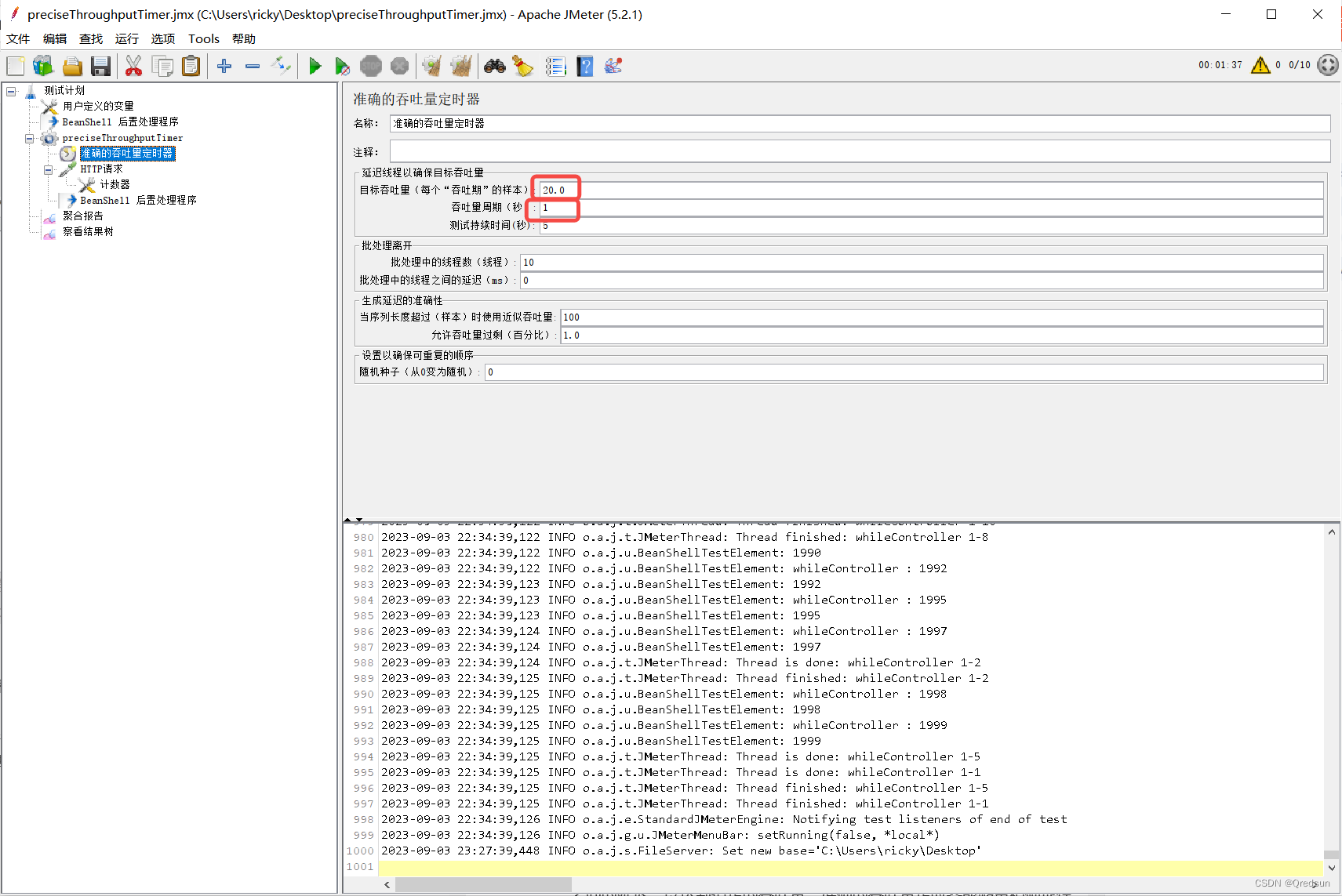
jmeter 准确的吞吐量定时器 Precise Throughput Timer
准确的吞吐量定时器使用实例 提取码:gpex: 说明:配置10个线程,每个线程请求200次,通过准确地的定时器模拟QPS为20的场景 配置测试接口参考链接 配置jmeter测试脚本,主要关注准确的吞吐量定时器参数配置 目…...

落地生产级推理引擎!高性能GPU算子生成系统Kernel-Smith发布
在当今的大模型时代,高性能 GPU 算子(Kernel)是将硬件算力转化为实际吞吐量的核心引擎。无论是支撑 Megatron、vLLM、LMDeploy 等底层系统,还是驱动 AI for Science (AI4S) 的复杂科学计算,高效的算子实现都是释放硬件…...

探索GetQzonehistory:永久保存QQ空间记忆的数字时光机
探索GetQzonehistory:永久保存QQ空间记忆的数字时光机 【免费下载链接】GetQzonehistory 获取QQ空间发布的历史说说 项目地址: https://gitcode.com/GitHub_Trending/ge/GetQzonehistory 在数字时代,我们的记忆分散在各个社交平台,而Q…...

问道1.6夏日清风单机虚拟机版|200+礼包加持·最强方官1.6完整体验
温馨提示:文末有联系方式【全新封装|问道1.6夏日清风单机虚拟机版】 本版本基于稳定虚拟机环境深度优化,完美集成‘夏日清风’主内容与当前最成熟的‘最强方官1.6’核心框架,运行零冲突、免配置,开箱即玩。【超值&…...

电力系统输电线路距离保护建模与仿真:方向阻抗继电器探秘
1.电力系统输电线路距离保护的建模与仿真matlab/simulink仿真模型 2.方向阻抗继电器 (1)“0度接线”方向阻抗继电器的构造 (2)“相电压和具有K3I0补偿的相电流接线”的方向阻抗继电器模块的构造在电力系统中,输电线路距…...

保姆级教程:在PX4 SITL仿真中为Iris无人机挂载Kinect、RPLidar和FPV摄像头
PX4仿真环境多传感器集成实战:从零搭建SLAM无人机开发平台 无人机仿真开发中最令人头疼的,莫过于将各类传感器完美集成到飞行平台上。我曾花了整整两周时间调试Kinect和RPLidar在Gazebo中的兼容性问题,直到找到这套经过验证的解决方案。本文将…...

ESXI系统安装全流程详解:从U盘启动到网络配置
1. 制作ESXI系统U盘启动盘 准备一个容量至少8GB的U盘,建议使用USB3.0接口的高速U盘,这样写入速度会快很多。我实测过,用USB2.0的U盘写入一个ESXI镜像可能需要20分钟,而USB3.0通常5分钟就能搞定。 首先需要下载两个关键文件&#x…...

汽车电子选型:RF430F5144CIRKVRQ1为什么适合发动机舱附近的应用
RF430F5144CIRKVRQ1:这颗77mm的QFN芯片,如何把13.56MHz NFC和MSP430 MCU塞进一颗汽车级SoCRF430F5144CIRKVRQ1来自德州仪器,是一颗高度集成的NFC传感器收发器SoC。它的核心价值很直接:把13.56MHz HF射频前端、16位MSP430超低功耗M…...

Qwen3-14B部署后效果追踪:30天使用数据与关键指标增长分析
Qwen3-14B部署后效果追踪:30天使用数据与关键指标增长分析 1. 部署效果概览 在RTX 4090D 24GB显存环境下部署Qwen3-14B镜像后,我们对系统进行了为期30天的持续监测。数据显示,这套优化配置展现出令人印象深刻的稳定性和性能表现:…...

DBShadow横空出世,Dapper.net的天花板盖不住了
一、DBShadow是什么DBShadow是.net开源的高性能ORMDBShadow使用开源项目ShadowSql高效拼接sqlDBShadow使用开源项目PocoEmit.Mapper高效映射查询参数和查询结果也就是说SqlBuilder(ShadowSql)OOM(PocoEmit.Mapper)ORM(DBShadow)二、DBShadow和Dapper对比一下1. Dapper代码await…...

Redis 单线程真的是单线程吗?源码角度全面解析
Redis 是单线程的——这句话流传太广了,以至于很多人真的以为 Redis 就一个线程在跑。但实际上,如果你 ps -ef 或者 top 看一眼正在运行的 Redis 进程,会发现线程数不止一个。 到底怎么回事?这篇文章从源码角度把这个问题彻底说清…...