Flink--2、Flink部署(Yarn集群搭建下的会话模式部署、单作业模式部署、应用模式部署)

星光下的赶路人star的个人主页
你必须赢过,才可以说不在乎输赢
文章目录
- 1、Flink部署
- 1.1 集群角色
- 1.2 Flink集群搭建
- 1.2.1 集群启动
- 1.2.2 向集群提交作业
- 1.3 部署模式
- 1.3.1 会话模式(Session Mode)
- 1.3.2 单作业模式(Per-Job Mode)
- 1.3.3 应用模式(Application Mode)
- 1.4 Standalone运行模式
- 1.4.1 会话模式部署
- 1.4.2 单作业模式部署
- 1.4.3 应用模式部署
- 1.5 Yarn运行模式(非常重要)
- 1.5.1 相关准备和配置
- 1.5.2 会话模式部署
- 1.5.3 单作业模式部署
- 1.5.4 应用模式部署
- 1.6 K8S运行模式(了解)
- 1.7 历史服务器
1、Flink部署
1.1 集群角色
Flink提交作业和执行任务,需要几个关键组件:
- 客户端(Client):代码由客户端获取并做转换,之后提交给JobManager
- JobManager就是Flink集群里的“管事人”,对作业进行中央调度管理,而它获取到要执行的作业后,会进一步处理转换,然后分发给众多的TaskManager。
- TaskManager,就是真正的“干活的人”,数据的处理操作都是它们来做的。
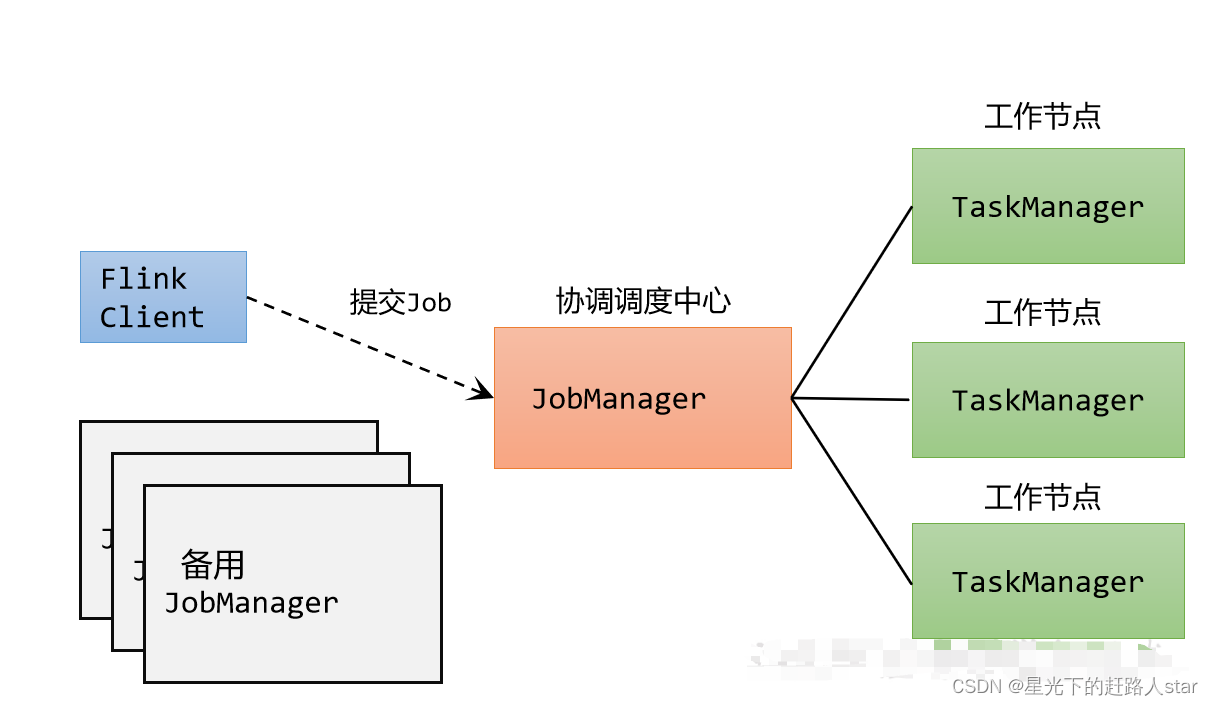
注意:Flink是一个非常灵活的处理框架,它支持多种不同的部署场景,还可以和不同的资源管理平台方便地集成。
1.2 Flink集群搭建
1.2.1 集群启动
0、集群规划
| 节点服务器 | hadoop102 | hadoop103 | hadoop104 |
|---|---|---|---|
| 角色 | JobManager、TaskManager | TaskManager | TaskManager |
具体安装部署步骤如下:
1、下载并解压安装包
(1)下载(直接去官网下)安装包flink-1.17.0-bin-scala_2.12.tgz,将该jar包上传到hadoop102节点服务器的/opt/software路径上。
(2)在/opt/software路径上解压安装包到/opt/module路径上
tar -zxvf flink-1.17.0-bin-scala_2.12.tgz -C /opt/module/
2、修改集群配置
(1)进入conf路径,修改flink-conf.yaml文件,指定hadoop102节点服务器为JobManager
vim flink-conf.yaml
修改如下内容:
# JobManager节点地址.
jobmanager.rpc.address: hadoop102
jobmanager.bind-host: 0.0.0.0
rest.address: hadoop102
rest.bind-address: 0.0.0.0
# TaskManager节点地址.需要配置为当前机器名
taskmanager.bind-host: 0.0.0.0
taskmanager.host: hadoop102
(2)修改workers文件,指定hadoop102、hadoop103和hadoop104为TaskManager
vim workers
修改如下内容:
hadoop102
hadoop103
hadoop104
(3)修改master文件
vim masters
修改内容如下:
hadoop102:8081
(4)另外,在flink-conf.yaml文件中还可以对集群中的JobManager和TaskManager组件进行优化配置,主要配置项如下:
- jobmanager.memory.process.size:对JobManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1600M,可以根据集群规模进行适当调整。
- taskmanager.memory.process.size:对TaskManager进程可使用到的全部内存进行配置,包括JVM元空间和其他开销,默认为1728M,可以根据集群规模进行适当调整。
- taskmanager.numberOfTaskSlots:对每个TaskManager能够分配的Slot数量进行配置,默认为1,可根据TaskManager所在的机器能够提供给Flink的CPU数量决定。所谓Slot就是TaskManager中具体运行一个任务所分配的计算资源。
- parallelism.default:Flink任务执行的并行度,默认为1。优先级低于代码中进行的并行度配置和任务提交时使用参数指定的并行度数量。
3、分发安装目录
(1)配置修改完毕后,将Flink安装目录发给另外两个节点服务器。
xsync flink-1.17.0/
(2)修改hadoop103的 taskmanager.host
修改如下内容:
# TaskManager节点地址.需要配置为当前机器名
taskmanager.host: hadoop103
(3)修改hadoop104的 taskmanager.host(和上面差不多只是改为hadoop104而已)
4、启动集群
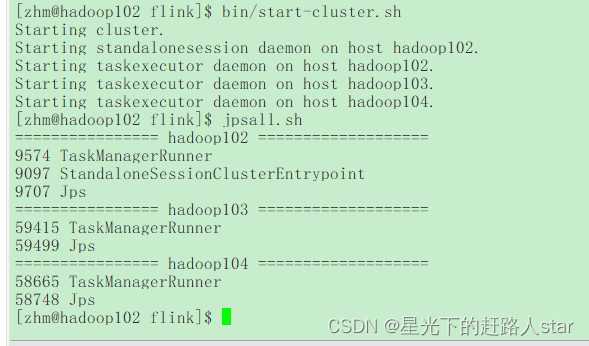
(1)在hadoop102节点服务器上执行start-cluster.sh启动Flink集群:
bin/start-cluster.sh
(2)查看进程情况:
5、访问WebUI
启动成功后,同样可以访问http://hadoop102:8081对Flink集群和任务进行监控管理。
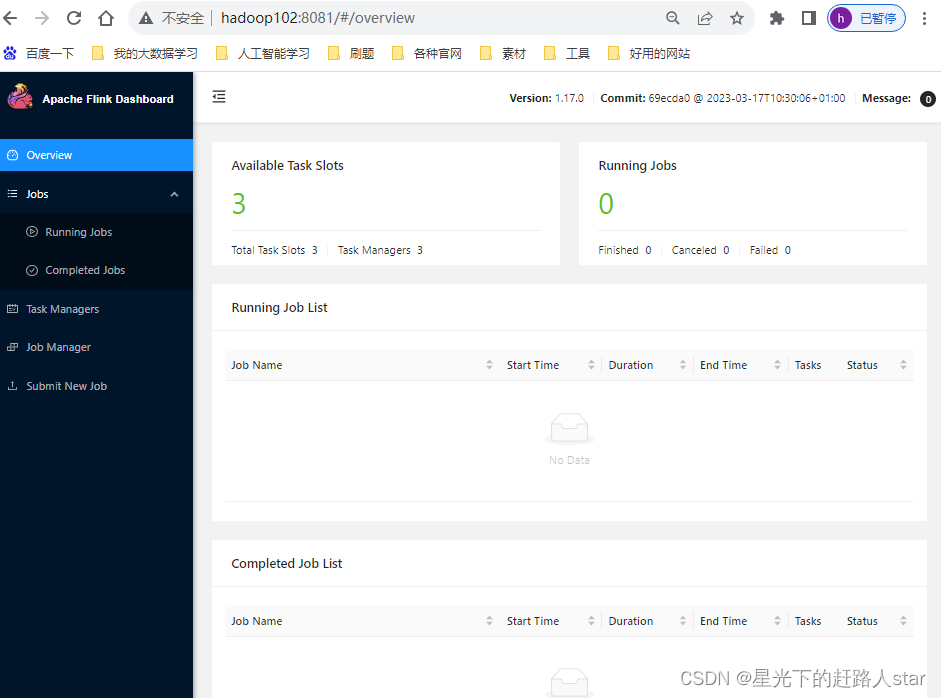
这样可以明显看到,当前集群的TaskManager数量为3;由于默认每个TaskManager的Slot数量为1,所以总Slot数和可用Slot数都为3。
1.2.2 向集群提交作业
在上一章中,我们已经编写读取socket发送的单词并统计单词的个数程序案例。本节我们将以该程序为例,演示如何将任务提交到集群中进行执行。具体步骤如下。
1、环境准备
在hadoop102中执行以下命令启动netcat。
nc -lk hadoop102 7777
2、程序打包
(1)在我们编写的Flink入门程序的pom.xml文件中添加打包插件的配置,具体如下:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><!-- Do not copy the signatures in the META-INF folder.Otherwise, this might cause SecurityExceptions when using the JAR. --><artifact>*:*</artifact><excludes><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers combine.children="append"><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"></transformer></transformers></configuration></execution></executions></plugin></plugins>
</build>
(2)插件配置完毕后,可以使用IDEA的Maven工具执行package命令,出现如下提示即表示打包成功。

打包完成后,在target目录下即可找到所需JAR包,JAR包会有两个,FlinkDemo-1.0-SNAPSHOT.jar和original-FlinkDemo-1.0-SNAPSHOT.jar,因为集群中已经具备任务运行所需的所有依赖,所以建议使用FlinkDemo-1.0-SNAPSHOT.jar。
3、在WebUI上提交作业
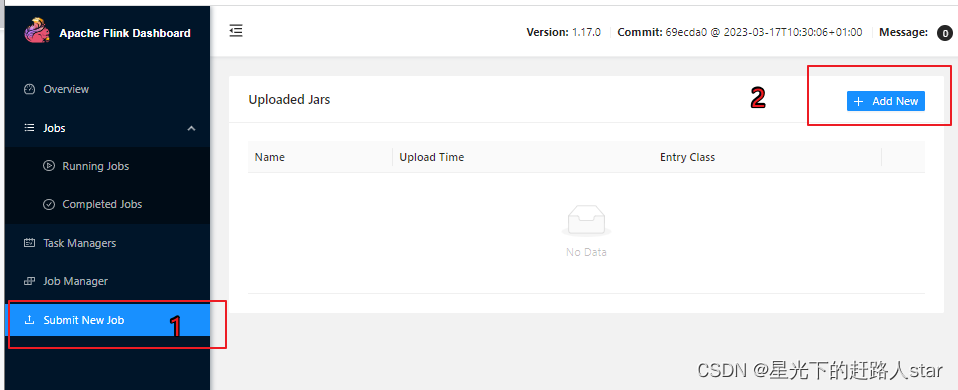
(1)任务打包完成后,我们打开Flink的WEB UI页面,在右侧导航栏点击“Submit New Job”,然后点击按钮“+ Add New”,选择要上传运行的JAR包,如下图所示。
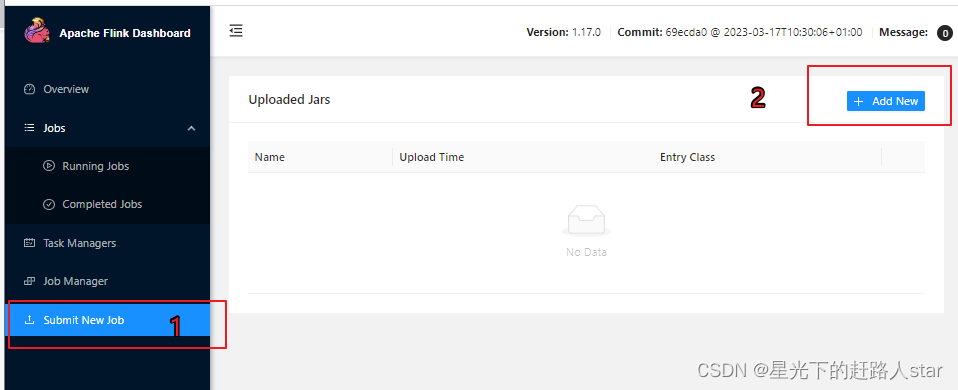
jar包上传完成,如下图所示
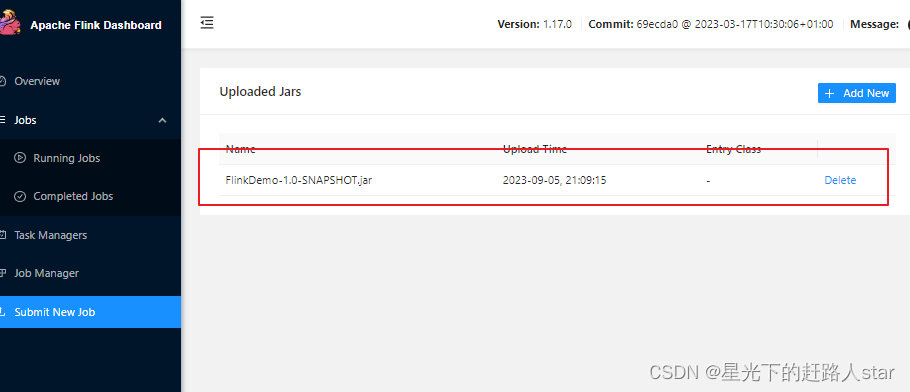
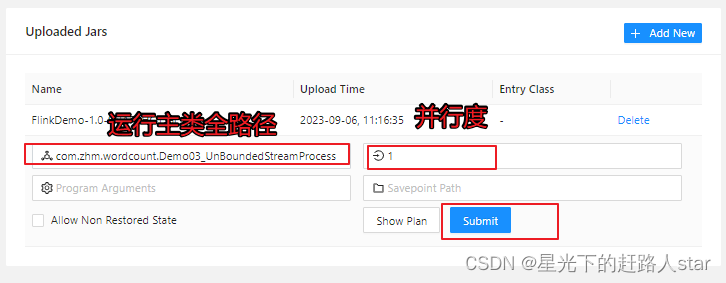
(2)点击该jar包,出现任务配置页面,进行相应的配置
主要配置程序入口主类的全类名,任务运行的并行度,任务运行所需的配置参数和保存点路径等,如下图所示,配置完成后,即可点击按钮“Submit”,将任务提交到集群运行。
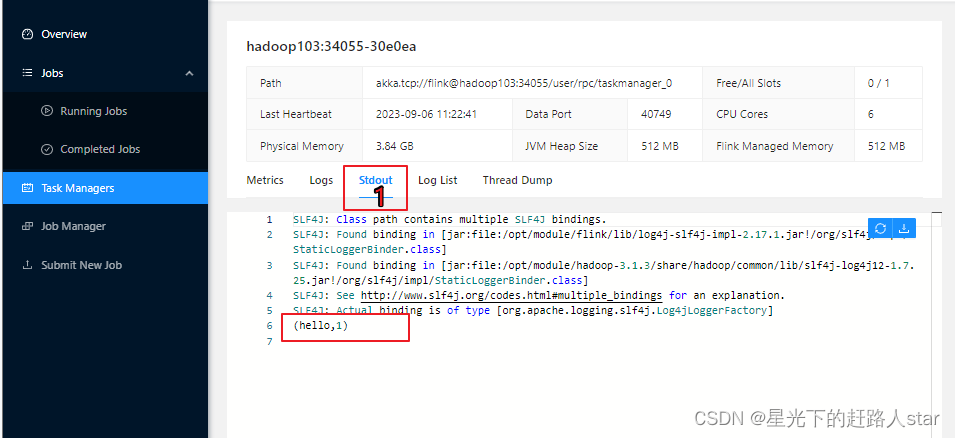
(3)任务提交成功之后,可点击左侧导航栏的“Running Jobs”查看程序运行列表情况。

(4)测试
①在socket端口中输入hello

②按图顺序

③点击Stdout,就可以看到hello单词的统计
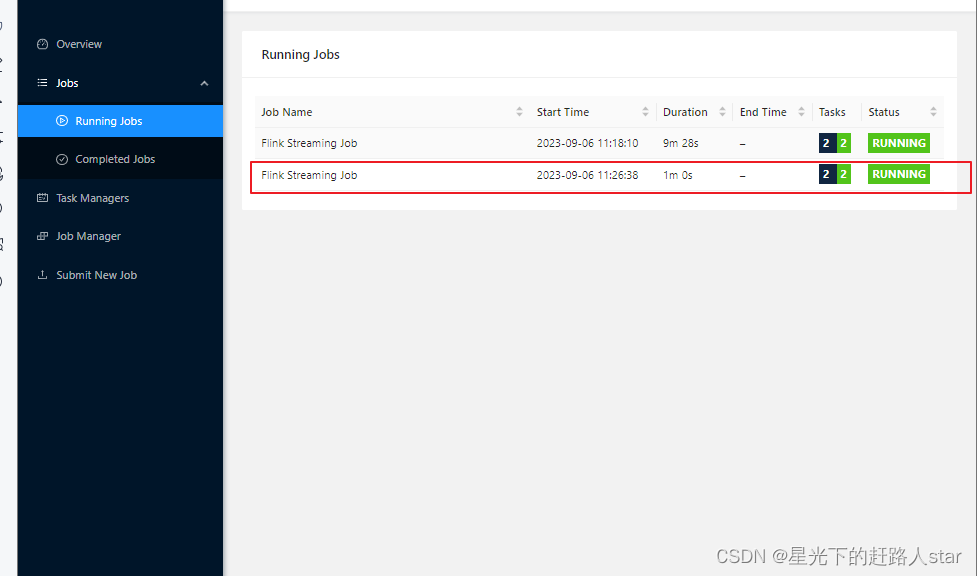
(4)点击该任务,可以查看任务运行的具体情况,也可以通过点击“Cancel Job”结束任务运行。

4、命令行提交作业
除了通过WebUI界面提交任务之外,也可以直接通过命令来提交任务。这里为方便起见,我们可以先把jar包直接上传到目录flink-1.17.0下。
(1)首先要启动集群
bin/start-cluster.sh
(2)在hadoop102中执行以下命令启动netcat。
nc -lk 9999
(3)将flink程序运行jar包上传到/opt/module/flink-1.17.0路径
(4)进入到flink的安装路径下,在命令行使用flink run命令提交作业。
bin/flink run -m hadoop102:8081 -c com.zhm.wordcount.Demo03_UnBoundedStreamProcess ./FlinkDemo-1.0-SNAPSHOT.jar
这里的参数 -m指定了提交到的JobManager,-c指定了入口类。
(5)在浏览器中打开Web UI,http://hadoop102:8081查看应用执行情况。用netcat输入数据,可以在TaskManager的标准输出(Stdout)看到对应的统计结果。
(6)数据模拟和实现和WebUI提交是一样的!!!
1.3 部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种模式:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式以及应用的main方法到底在哪里执行—客户端(Client)还是JobManager。
1.3.1 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
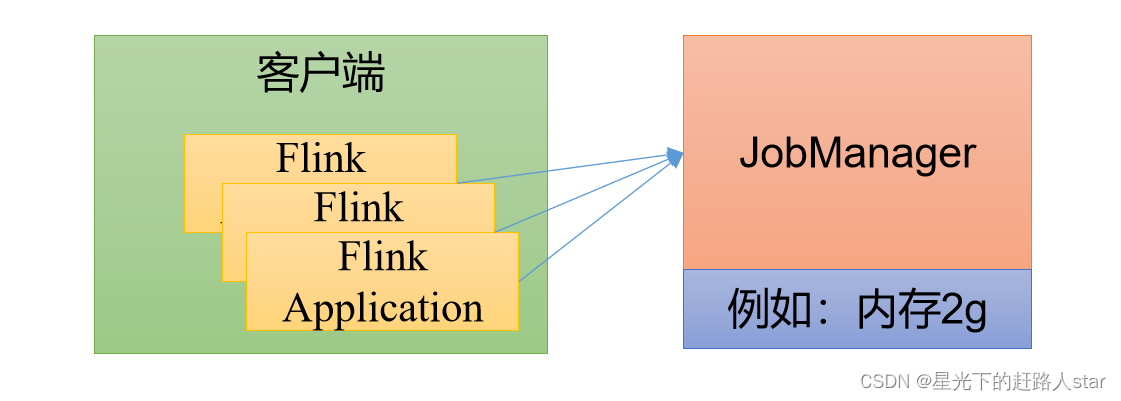
会话模式比较适合于单个规模小、执行时间短的大量作业。
1.3.2 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好的隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。
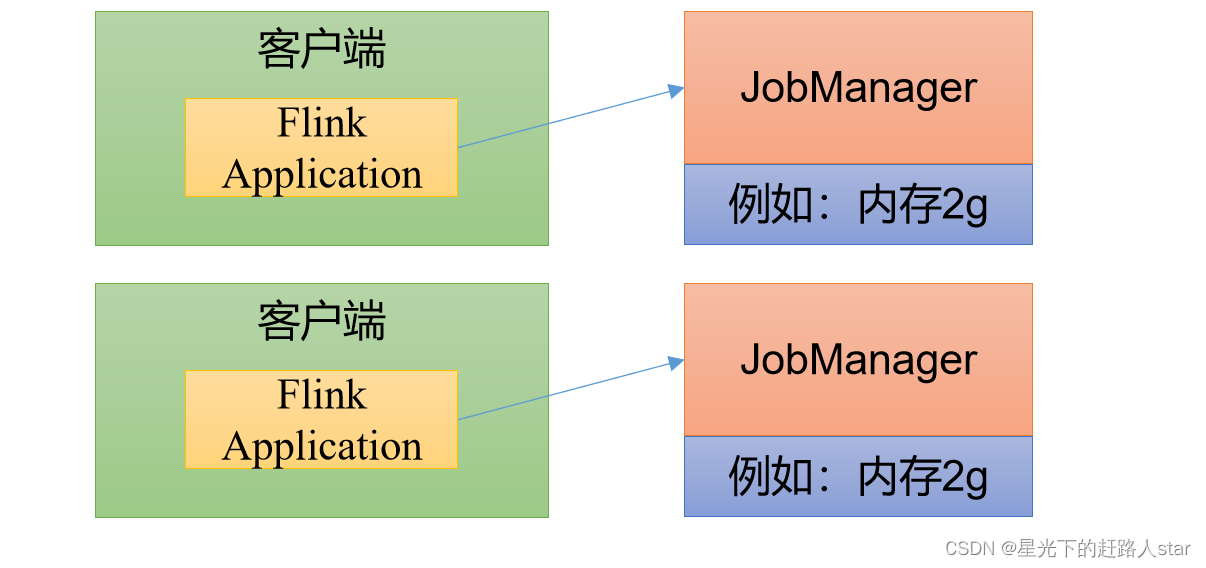
作业完成后,集群就会关闭,所有资源也会释放。
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
需要注意的是:Flink本身无法直接这样运行,所有单作业模式一般需要借助一些资源管理框架爱来启动集群,比如Yarn、Kubernets(K8S)。
1.3.3 应用模式(Application Mode)
前面两个模式下,应用代码都是在客户端上执行的,然后由于客户端提交给JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到JobManager上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。
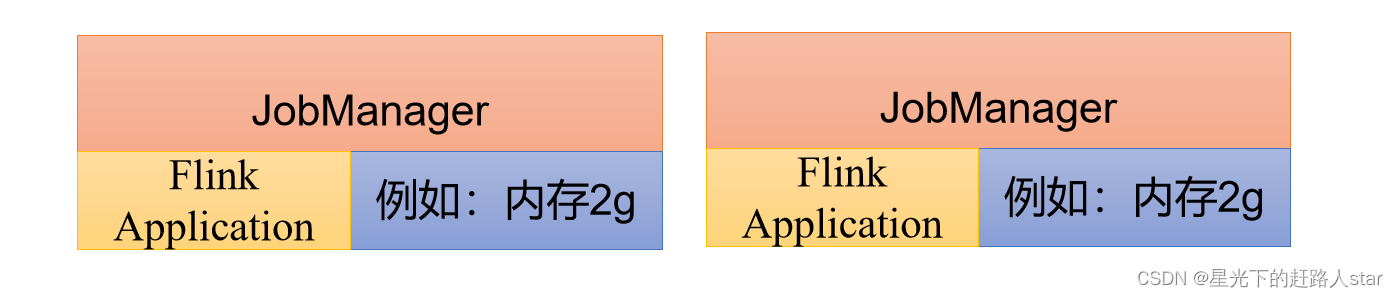
应用模式和单作业模式都是提交作业之后才创建集群的;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由JobManager执行应用程序的。
这里说的部署模式是比较抽象的概念。实际应用的时候,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者的场景。
1.4 Standalone运行模式
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
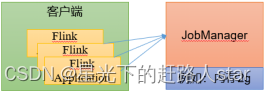
1.4.1 会话模式部署
在1.3.2 节就是用的Standalone集群的会话模式部署。
提前启动集群,并通过Web页面客户端提交任务(可以多个任务,但是集群资源固定)
1.4.2 单作业模式部署
Flink的Standalone集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
1.4.3 应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。

具体步骤如下:
(1)环境准备,在hadoop102中执行以下命令启动netcat。
nc -lk hadoop102 9999
(2)进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
(3)执行以下命令,启动JobManager。
bin/standalone-job.sh start --job-classname com.zhm.wordcount.Demo03_UnBoundedStreamProcess
这里我们直接指定作业入口类,脚本会到lib目录下扫描所有的jar包。
(4)同样是使用bin目录下的脚本,启动TaskManager。
bin/taskmanager.sh start
(5)在hadoop102上模拟发送单词数据。
(6)在hadoop102:8081地址中观察输出数据
(7)如果希望停掉集群,同样可以使用脚本,命令如下
bin/taskmanager.sh stopbin/standalone-job.sh stop
1.5 Yarn运行模式(非常重要)
Yarn上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器(Container)。这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManager·上的作业所需要的槽数动态分配TaskManager资源。
1.5.1 相关准备和配置
在Flink任务不是至Yarn集群之前,需要确认集群是否按照有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。
(1)配置环境变量,增加环境变量配置如下:
sudo vim /etc/profile.d/my_env.sh#添加内容
HADOOP_HOME=/opt/module/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
(2)启动Hadoop集群,包括HDFS和Yarn
start-dfs.sh
start-yarn.sh
(3)在hadoop102执行以下命令启动netcat
nc -lk hadoop102 9999
1.5.2 会话模式部署
Yarn的会话模式与独立集群不一样,需要首先申请一个Yarn会话(Yarn Session)来启动Flink集群,具体步骤如下:
1、启动集群
(1)启动Hadoop集群(HDFS、YARN)。
(2)执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群。
bin/yarn-session.sh -nm test
可用参数解读:
- -d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
- -jm(–jobManagerMemory):配置JobManager所需内存,默认单位MB。
- -nm(–name):配置在YARN UI界面上显示的任务名。
- -qu(–queue):指定YARN队列名。
- -tm(–taskManager):配置每个TaskManager所使用内存。
注意:Flink1.11.0版本不再使用-n参数和-s参数分别指定TaskManager数量和slot数量,Yarn会按照需求动态分配TaskManager和Slot数量。所以从这个意义上来说,Yarn的会话模式也不会把集群资源固定,同样是动态分布的。
Yarn Session启动之后会给出一个WebUI地址以及一个Yarn ApplicationId,如下所示,用户可以通过Web UI或者命令行两种方式提交作业。
2、提交作业
(1)通过Web UI提交作业
这种方式比较简单,与上文述Standalone部署模式基本一样。
(2)通过命令行提交作业
① 将FlinkTutorial-1.0-SNAPSHOT.jar任务上传至集群。
② 执行以下命令将该任务提交到已经开启的Yarn-Session中运行。
bin/flink run -c com.zhm.wordcount.Demo03_UnBoundedStreamProcess FlinkDemo-1.0-SNAPSHOT.jar
客户端可以自行确定JobManager的地址,也可以通过-m或者-jobmanager参数指定JobManager的地址,JobManager的地址在Yarn Session的启动页面可以找到
③ 任务提交成功后,可在YARN的Web UI界面查看运行情况。hadoop103:8088。
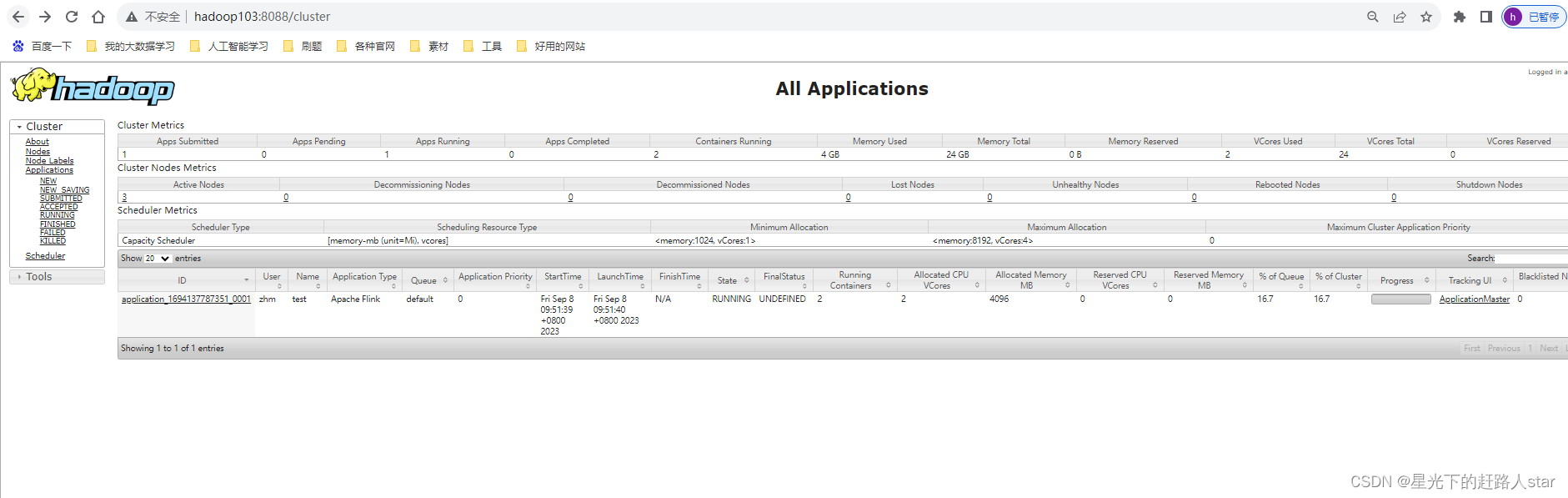
从上图中可以看到我们创建的Yarn-Session实际上是一个Yarn的Application,并且有唯一的Application ID。
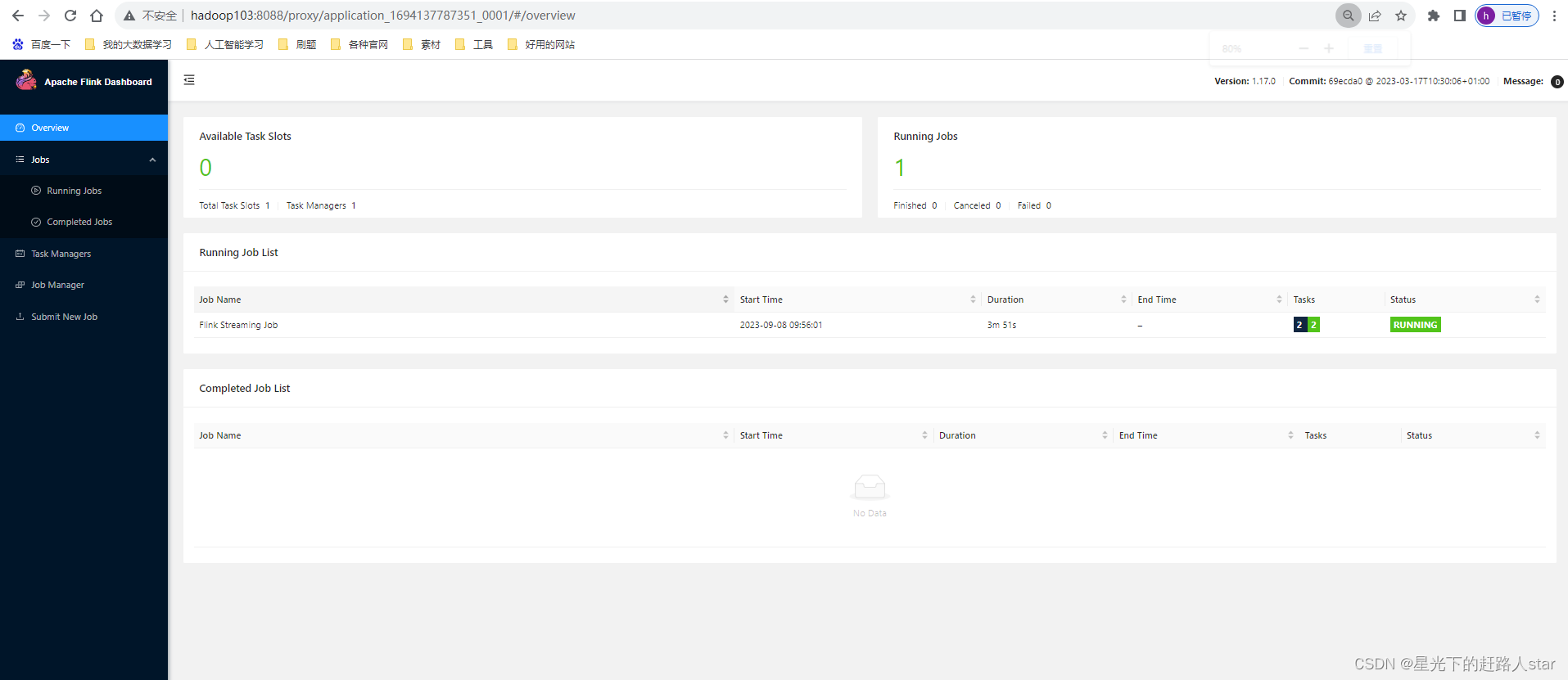
④也可以通过Flink的Web UI页面查看提交任务的运行情况,如下图所示。
1.5.3 单作业模式部署
在Yarn环境中,由于有了外部平台做资源调度,所以我们也可以直接向Yarn提交一个单独的作业,从而启动一个Flink集群。
(1)执行命令提交作业
bin/flink run -d -t yarn-per-job -c com.zhm.wordcount.Demo03_UnBoundedStreamProcess FlinkDemo-1.0-SNAPSHOT.jar
(2)在YARN的ResourceManager界面查看执行情况。
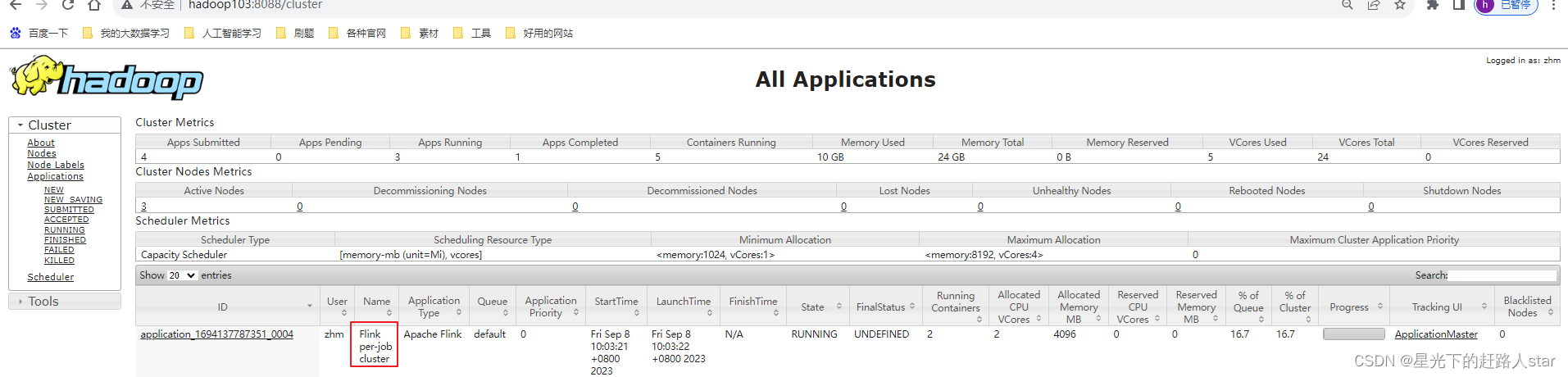
点击(ApplicationMaster)可以打开Flink Web UI页面进行监控,如下图所示:
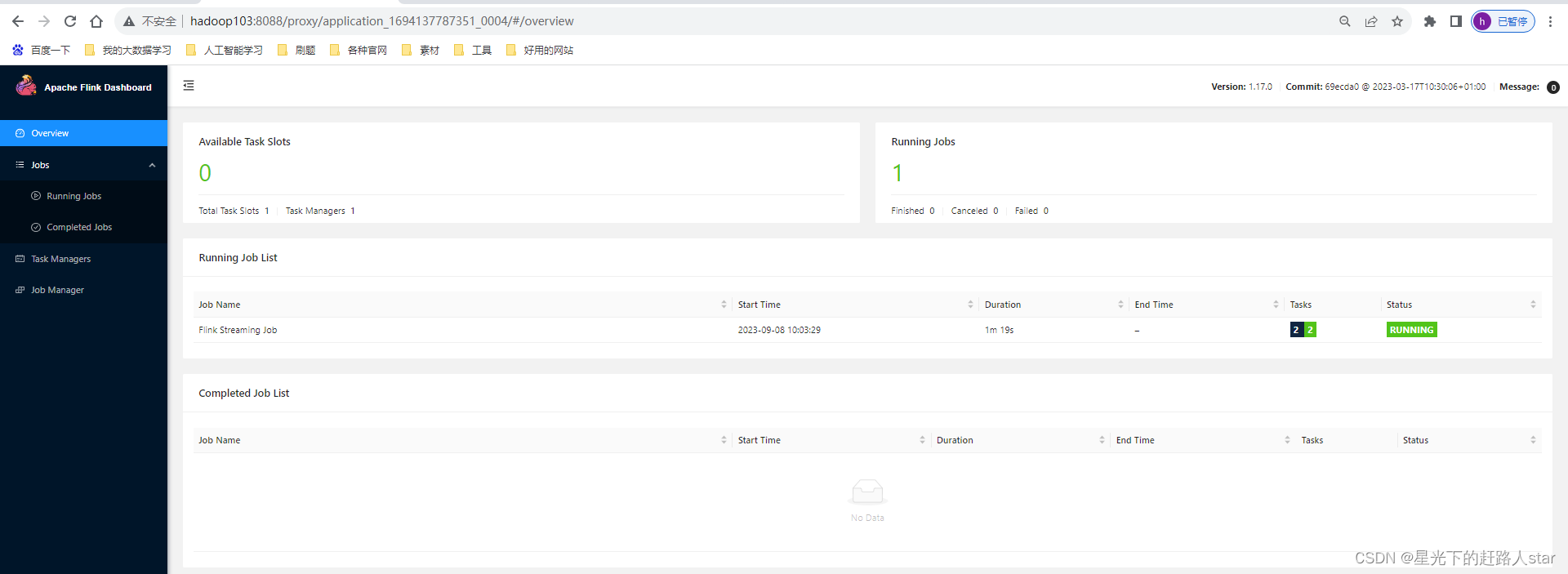
(3)可以使用命令行查看或取消作业,命令如下。
##查看当前job的idbin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY## 取消jobbin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>这里的application_XXXX_YY是当前应用的ID,是作业的ID。注意如果取消作业,整个Flink集群也会停掉。
1.5.4 应用模式部署
应用模式同样非常简单,与单作业模式类似,直接执行flink run-application命令即可。
1、命令行提交
(1)执行命令提交作业。
bin/flink run-application -t yarn-application -c com.zhm.wordcount.Demo03_UnBoundedStreamProcess FlinkDemo-1.0-SNAPSHOT.jar
(2)在命令行中查看或取消作业。(和单作业部署是一样的)
2、上传HDFS提交
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。
(1)上传flink的lib和plugins到HDFS上
## 创建HDFS目录
fs -mkdir /flink-dist
fs -put lib/ /flink-dist##上传文件到HDFS目录
hadoop fs -put plugins/ /flink-dist
(2)上传自己的jar包到HDFS
hadoop fs -mkdir /flink-jars
hadoop fs -put FlinkDemo-1.0-SNAPSHOT.jar /flink-jars(3)提交作业
bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink-dist" -c com.zhm.wordcount.Demo03_UnBoundedStreamProcess hdfs://hadoop102:8020/flink-jars/FlinkDemo-1.0-SNAPSHOT.jar
这种方式上,Flink本身的依赖和用户jar可以预先上传到HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。
1.6 K8S运行模式(了解)
容器化部署是如今业界流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的Kubernetes(K8S),而Flink也在最近的版本中支持了K8S部署模式。基本原理与Yarn是类似的。
1.7 历史服务器
运行 Flink job 的集群一旦停止,只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有 Metrics 监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的 Web UI,我们可以通过 UI 发现和定位一些问题。
Flink提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的WebUI统计信息。通过 History Server 我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
1、创建储存目录
hadoop fs -mkdir -p /logs/flink-job
2、在flink-config.yaml中添加如下配置
jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 5000
3、启动历史服务器
bin/historyserver.sh start
4、停止历史服务器
bin/historyserver.sh stop
5、在浏览器地址栏输入:http://hadoop102:8082 查看已经停止的 job 的统计信息
![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美
相关文章:

Flink--2、Flink部署(Yarn集群搭建下的会话模式部署、单作业模式部署、应用模式部署)
星光下的赶路人star的个人主页 你必须赢过,才可以说不在乎输赢 文章目录 1、Flink部署1.1 集群角色1.2 Flink集群搭建1.2.1 集群启动1.2.2 向集群提交作业 1.3 部署模式1.3.1 会话模式(Session Mode)1.3.2 单作业模式(Per-Job Mod…...

执行Django 的迁移命令报错[1193, Unknown system variable default_storage_engine]
在学习“”编写你的第一个 Django 应用程序,第2部分”时候,遇到一个问题。 执行迁移命令 python manage.py makemigrations polls 后,报错: migrations.py:109: RuntimeWarning: Got an error checking a consistent migration …...

Himall商城-公共方法
目录 1 Himall商城-公共方法 1.1 /// 根据订单id获取订单项 1.2 /// 根据订单项id获取售后记录 1.3 /// 判断订单是否正在申请售后 Himall商城-公共方法 #region 公共方法 public static List<InvoiceTitleInfo> GetInvoiceTitles(long userid) {...

海域可视化监管:浅析海域动态远程视频智能监管平台的构建方案
一、方案背景 随着科技的不断进步,智慧海域管理平台已经成为海洋领域监管的一种重要工具。相比传统的视频监控方式,智慧海域管理平台通过建设近岸海域视频监控网、海洋环境监测网和海上目标探测网络等,可实现海洋管理的数字化转型。 传统的…...

使用Spring Boot + MyBatis实现多数据源
一、引言 在开发中,我们经常会遇到需要连接多个数据库的情况。使用Spring Boot和MyBatis框架可以很方便地实现多数据源的配置和使用。本文将详细介绍如何在Spring Boot项目中使用多数据源。 二、实操 1、添加所需的依赖: <!-- Spring Boot Starte…...

C++中的无限循环
C中的无限循环 while、 do…while 和 for 循环都包含一个条件表达式,在它为 false 时循环结束。如果您指定的条件总是为 true,循环就不会结束。 无限 while 循环类似于下面这样: while(true) // while expression fixed to true {DoSomethi…...
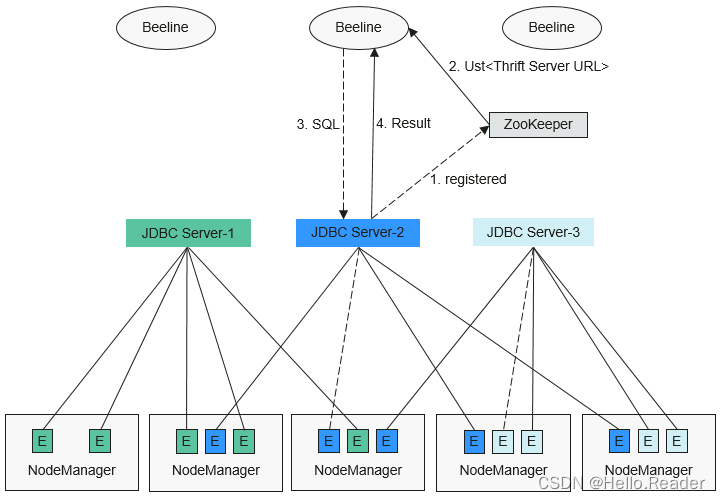
Spark2x原理剖析(二)
一、概述 基于社区已有的JDBCServer基础上,采用多主实例模式实现了其高可用性方案。集群中支持同时共存多个JDBCServer服务,通过客户端可以随机连接其中的任意一个服务进行业务操作。即使集群中一个或多个JDBCServer服务停止工作,也不影响用…...
tomcat安装、部署JSPGOU项目、Tomcat多实例
安装 官网找包 Apache Tomcat - Welcome! tomcat 8 准备运行环境 安装tomcat catalina.sh 服务脚本管理文件 server.xml 主配置文件 修改8009(删除注释) 启动tomcat 访问 为了避免每次进入绝对路径启动tomcat 法二: 三:部署…...

257. 二叉树的所有路径
题目链接: 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台 我的想法: 层次遍历不好解,可用找到叶子节点,但是他有一个回溯过程,他要一直保留路径节点,层次迭代不好加回溯。 递归…...
windows10使用wheel安装tensorflow2.13.0/2.10.0
安装过程 安装虚拟环境安装virtualenv安装满足要求的python版本使用virtualenv创建指定python版本的虚拟环境 安装tensorflow安装tensorflow-docs直接下载使用wheel下载 在VSCode编辑器中使用虚拟环境下的包 注意: tensorflow 2.10.0是最后一个支持GPU的版本 安装虚…...

sql-gen:点击生成SQL、RO、VO的工具
sql-gen仓库地址:码云 Github 1. 概述 sql-gen是一个用于提高后端接口开发效率的小工具,主要有如下功能: 生成连表SQL语句根据WHERE条件来生成封装查询条件的实体类(RO)根据SELECT列来生成封装查询结果的实体类&…...

pytorch从0开始安装
文章目录 一. 安装anaconda1.安装pytorch前需要先安装anaonda,首先进入官网(Anaconda | The Worlds Most Popular Data Science Platform)进行安装相应的版本。2.接着按如图所示安装,遇到下面这个选项时,选择all users.3.选择自己…...
)
Java 语言实现最小生成树算法(如Prim算法、Kruskal算法)
引言: 在图论中,最小生成树是指一个无向图的生成树,其所有边的权值之和最小。解决最小生成树问题的两种主要算法是Prim算法和Kruskal算法。本文将深入探讨这两种算法并比较它们的优缺点,以帮助读者更好地理解最小生成树算法的原理…...

什么是Linux的Overcommit和OOM
overcommit_memory参数说明: 设置内存分配策略(可选,根据服务器的实际情况进行设置) /proc/sys/vm/overcommit_memory 可选值:0、1、2。 0, 表示内核将检查是否有足够的可用内存供应用进程使用…...
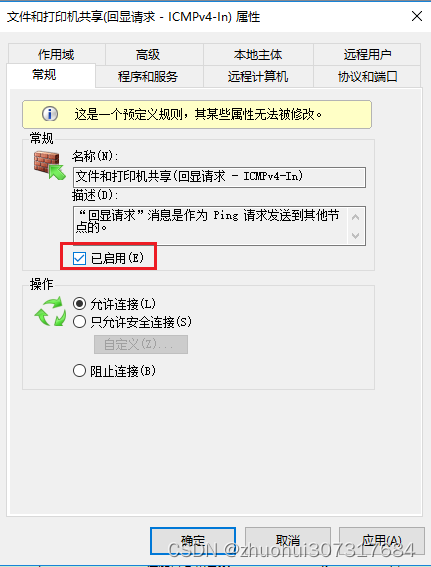
解决防火墙导致虚拟机不能ping通宿主机的问题
今天,无缘无故的,虚拟机突然用不了,网络连上不了,一番折腾翻找,最后才发现,是因为虚拟机ping不同宿主主机了,连网关都ping不通了,但是,宿主主机却可以ping通虚拟机 。 最…...
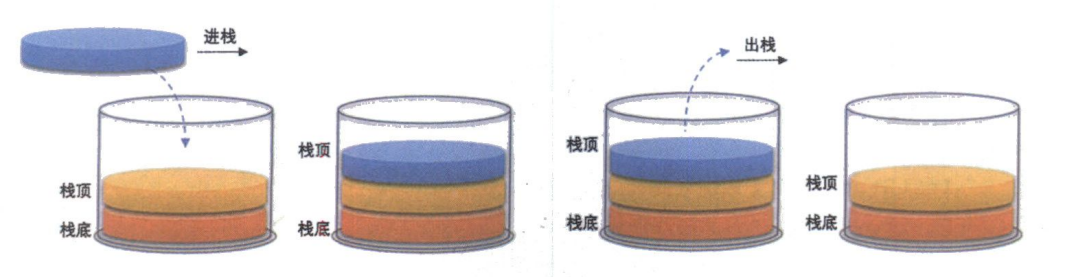
数据结构:线性表(栈的实现)
文章目录 1. 栈(Stack)1.1 栈的概念1.2 栈的结构链表栈数组栈 2. 栈的定义3. 栈的实现3.1 初始化栈 (StackInit)3.2 入栈 (StackPush)3.3 出栈 (StackPop)3.4 检测栈是否为空 (StackEmpty)3.5 获取栈顶元素 (StackTop)3.6 获取栈中有效元素个数 (StackSize)3.7 销毁栈 (StackDe…...

python如何将一个dataframe快速写入clickhouse
目录 前言思路与核心代码优缺点分析 前言 dataframe是用python做数据分析最场景的数据结构了,如何将dataframe数据快速写入到clickhouse数据库呢?这里介绍几种方法,各有优劣势,可以结合自己的使用场景挑用。 思路与核心代码 假…...
Tiny Player Mac:小而美,音乐播放的极致体验
对于追求音质和操作简便的Mac用户来说,Tiny Player Mac是一款不可多得的音乐播放器。它以简洁的界面、强大的功能和优异的性能,吸引了无数用户的目光。接下来,让我们一起了解这款小而美的音乐播放器。 Tiny Player Mac支持多种音频格式&#…...

2022年12月 C/C++(五级)真题解析#中国电子学会#全国青少年软件编程等级考试
C/C++编程(1~8级)全部真题・点这里 第1题:漫漫回国路 2020年5月,国际航班机票难求。一位在美国华盛顿的中国留学生,因为一些原因必须在本周内回到北京。现在已知各个机场之间的航班情况,求问他回不回得来(不考虑转机次数和机票价格)。 时间限制:1000 内存限制:65536 …...

C语言学习:7、break与continue的用法
前面讲到的循环体,貌似能解决生活中的很多问题,毕竟生活中很多事情是在重复的。但有时候也会有些小插曲,比如你在日复一日的上班,但某一天又特殊的事情你失业了,不就没班上了吗,那就得跳出那个上班的循环了…...

YOLOv8.yaml文件配置详解:从参数解析到模型结构优化实战
YOLOv8.yaml文件配置详解:从参数解析到模型结构优化实战 在计算机视觉领域,目标检测一直是核心任务之一。YOLO(You Only Look Once)系列算法因其出色的实时性和准确性广受欢迎,而YOLOv8作为该系列的最新版本,在模型结构和参数配置…...

新手入门指南:在快马平台用AI生成代码理解云桌面基础概念
今天想和大家分享一个特别适合新手理解云桌面基础概念的实践方法。作为一个刚接触云计算的小白,我最初对"一台主机创建多个云桌面"这个概念也是一头雾水,直到在InsCode(快马)平台上尝试用AI生成代码来模拟这个过程,才真正搞明白其中…...

避坑指南:OpenBMI运动想象实验中的‘跨被试’与‘不跨被试’到底怎么选?
避坑指南:OpenBMI运动想象实验中的‘跨被试’与‘不跨被试’到底怎么选? 当你第一次接触OpenBMI工具箱进行运动想象(Motor Imagery, MI)实验时,最令人困惑的决策之一就是如何选择数据划分策略。是采用**跨被试…...

深度解析JiYuTrainer:极域电子教室反控制技术实现与架构设计
深度解析JiYuTrainer:极域电子教室反控制技术实现与架构设计 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer JiYuTrainer是一款专业的极域电子教室反控制软件…...

音频合并避坑指南:为什么你的MP3拼接总有杂音?附FFmpeg解决方案
音频合并避坑指南:为什么你的MP3拼接总有杂音?附FFmpeg解决方案 当你尝试将多个MP3文件拼接成一个时,是否经常遇到以下问题:拼接处出现刺耳的杂音、音频卡顿或时间戳错乱?这并非你的操作失误,而是MP3格式本…...
)
WSL2下USB串口设备‘失踪’?手把手教你找回/dev/ttyUSB0(以Quectel模块为例)
WSL2下USB串口设备消失的终极解决方案:从原理到实战 最近在WSL2环境下调试Quectel模块时,发现一个奇怪现象:lsusb明明能识别设备,但/dev/ttyUSB0却神秘失踪。这让我想起去年调试树莓派时遇到的类似问题,但WSL2的环境特…...

3个步骤,让猫抓帮你轻松捕获网页视频资源
3个步骤,让猫抓帮你轻松捕获网页视频资源 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过这样的情况?在网…...

SPIRAN ART SUMMONER图像生成前端展示效果优化技巧
SPIRAN ART SUMMONER图像生成前端展示效果优化技巧 1. 引言 你有没有遇到过这种情况:用SPIRAN ART SUMMONER生成了超棒的图片,但在网站上展示时却加载缓慢,用户还没看到效果就流失了?或者图片显示不完整,影响了整体的…...

Phi-4-mini-reasoning效果展示:同参数量级中推理准确率超Llama3-8B实测对比
Phi-4-mini-reasoning效果展示:同参数量级中推理准确率超Llama3-8B实测对比 1. 开篇亮点:小模型的大智慧 Phi-4-mini-reasoning这款仅有3.8B参数的轻量级开源模型,正在重新定义我们对小模型能力的认知。作为专为数学推理、逻辑推导和多步解…...
快速上手教程)
Qwen3.5-2B镜像免配置部署:开箱即用WebUI(7860端口)快速上手教程
Qwen3.5-2B镜像免配置部署:开箱即用WebUI(7860端口)快速上手教程 1. 模型简介 Qwen3.5-2B是通义千问系列中的轻量化多模态基础模型,仅有20亿参数规模,专为低功耗、低门槛部署场景设计。这个版本特别适合在端侧设备和…...