Spring Quartz 持久化解决方案
Quartz是实现了序列化接口的,包括接口,所以可以使用标准方式序列化到数据库。
而Spring2.5.6在集成Quartz时却未能考虑持久化问题。
Spring对JobDetail进行了封装,却未实现序列化接口,所以持久化的时候会产生NotSerializable问题,这也是网上一直在那边叫嚣为什么不能持久化到数据库问题,哥今天看了下Spring源码,发现Spring对Quartz持久化的问题.
1. 不知道Spring未来会不会对持久化的支持,不过我们可以有如下解决方案,比如改写
Spring的代码,实现序列化接口.
2. 不使用Spring的Fatory,自己实现任务的初始化.
既然Spring不支持持久化,那么持久化任务还是自己编写实现吧,否则每次都需要打包发布,麻烦,自己编写的类与Quartz完全兼容.
注意:为什么Spring不支持外配置任务,可能也是考虑到这方面问题所以才不提供这些任务的执行化支持.[配置文件配置与数据库配置重复]
直接使用Quartz是支持序列化功能,比如直接使用页面配置Quartz界面,设置任务执行时间等属性。
通过配置实现的是不应该初始化到数据库,否则直接在数据库中配置了。不过也是可以配置的,通过改写JobDetailBean.代码如下:
-
package org.frame.auth.service; import java.util.Map; import org.quartz.Job; import org.quartz.JobDetail; import org.quartz.Scheduler; import org.springframework.beans.factory.BeanNameAware; import org.springframework.beans.factory.InitializingBean; import org.springframework.scheduling.quartz.DelegatingJob; import org.springframework.scheduling.quartz.SchedulerFactoryBean; public class PersistentJobDetailBean extends JobDetail implements BeanNameAware, InitializingBean { private static final long serialVersionUID = -4389885435844732405L; private Class actualJobClass; private String beanName; /** * Overridden to support any job class, to allow a custom JobFactory * to adapt the given job class to the Quartz Job interface. * @see SchedulerFactoryBean#setJobFactory */ public void setJobClass(Class jobClass) { if (jobClass != null && !Job.class.isAssignableFrom(jobClass)) { super.setJobClass(DelegatingJob.class); this.actualJobClass = jobClass; } else { super.setJobClass(jobClass); } } /** * Overridden to support any job class, to allow a custom JobFactory * to adapt the given job class to the Quartz Job interface. */ public Class getJobClass() { return (this.actualJobClass != null ? this.actualJobClass : super.getJobClass()); } /** * Register objects in the JobDataMap via a given Map. * <p>These objects will be available to this Job only, * in contrast to objects in the SchedulerContext. * <p>Note: When using persistent Jobs whose JobDetail will be kept in the * database, do not put Spring-managed beans or an ApplicationContext * reference into the JobDataMap but rather into the SchedulerContext. * @param jobDataAsMap Map with String keys and any objects as values * (for example Spring-managed beans) * @see SchedulerFactoryBean#setSchedulerContextAsMap */ public void setJobDataAsMap(Map jobDataAsMap) { getJobDataMap().putAll(jobDataAsMap); } /** * Set a list of JobListener names for this job, referring to * non-global JobListeners registered with the Scheduler. * <p>A JobListener name always refers to the name returned * by the JobListener implementation. * @see SchedulerFactoryBean#setJobListeners * @see org.quartz.JobListener#getName */ public void setJobListenerNames(String[] names) { for (int i = 0; i < names.length; i++) { addJobListener(names[i]); } } public void setBeanName(String beanName) { this.beanName = beanName; } public void afterPropertiesSet() { if (getName() == null) { setName(this.beanName); } if (getGroup() == null) { setGroup(Scheduler.DEFAULT_GROUP); } } }
这里把Spring的ApplicationContext去掉了,因为这个属性没有实现序列化接口。其他配置与原告一致:
-
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE beans PUBLIC "-//SPRING//DTD BEAN//EN" " http://www.springframework.org/dtd/spring-beans.dtd "> <beans default-autowire="byName"> <bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource" destroy-method="close"> <property name="driverClassName" value="com.mysql.jdbc.Driver"/> <property name="url" > <value><![CDATA[jdbc:mysql://localhost:3306/txl?connectTimeout=1000&useUnicode=true&characterEncoding=utf-8]]></value> </property> <property name="username" value="root"/> <property name="password" value=""/> </bean> <bean id="jobDetail" class = "org.frame.auth.service.PersistentJobDetailBean"> <property name="jobClass" value="org.frame.auth.service.PersistentJob"></property> </bean> <!-- <bean id="trigger" class="org.springframework.scheduling.quartz.SimpleTriggerBean" >--> <!-- <property name="jobDetail" ref="jobDetail"></property>--> <!-- <property name="startDelay" value="1000"></property>--> <!-- <property name="repeatInterval" value="3000"></property>--> <!-- <property name="jobDataAsMap">--> <!-- <map>--> <!-- <entry key="message" value="this is trigger"></entry>--> <!-- </map>--> <!-- </property>--> <!-- </bean>--> <bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean" > <property name="jobDetail" ref="jobDetail"/> <property name="cronExpression"> <value>0/10 * * * * ?</value> </property> </bean> <bean id="schedulerFactory" class="org.springframework.scheduling.quartz.SchedulerFactoryBean"> <property name="dataSource" ref="dataSource"></property> <property name="applicationContextSchedulerContextKey" value="applicationContextKey" /> <property name="configLocation" value="classpath:quartz.properties"/> </bean> </beans>
org.frame.auth.service.PersistentJob这个类很简单,如下:
-
package org.frame.auth.service; import org.quartz.Job; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; public class PersistentJob implements Job { @Override public void execute(JobExecutionContext context) throws JobExecutionException { System.out.println("spring quartz!"); } }
有人可能会说,你这种任务调度持久化就没有意义了,是的,一般持久化到数据库的代码如下:
-
package org.frame.auth.service; import java.util.Map; import org.quartz.JobExecutionContext; import org.quartz.JobExecutionException; import org.quartz.StatefulJob; public class PersistentJob implements StatefulJob { @Override public void execute(JobExecutionContext context) throws JobExecutionException { // TODO Auto-generated method stub Map map = context.getJobDetail().getJobDataMap(); System.out.println("["+context.getJobDetail().getName()+"]"+map.get("message")); map.put("message", "updated Message"); } }
这样的话,信息message就会持久化到数据库中了.可以建立系统的连锁调度,这根据你的业务需求了.
在Spring中配置的任务通过我这种修改是可以运行,不过每次运行都需要把原先的任务删除,否则会提示任务已经存在,Quartz的优势是就算服务器停止,下次重启能够恢复原先的任务并继续执行.
相关文章:

Spring Quartz 持久化解决方案
Quartz是实现了序列化接口的,包括接口,所以可以使用标准方式序列化到数据库。 而Spring2.5.6在集成Quartz时却未能考虑持久化问题。 Spring对JobDetail进行了封装,却未实现序列化接口,所以持久化的时候会产生NotSerializable问题&…...
基于Java+SpringBoot+Vue前后端分离火锅店管理系统设计和实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...
Unity——导航系统补充说明
一、导航系统补充说明 1、导航与动画 我们可以通过设置动画状态机的变量,让动画匹配由玩家直接控制的角色的移动。那么自动导航的角色如何与动画系统结合呢? 有两个常用的属性可以获得导航代理当前的状态: 一是agent.velocity,…...

nginx实现负载均衡load balance
目录 nginx实现负载均衡load balance相关算法负载均衡https的访问后端的real server是否知道真正访问的用户的IP地址健康检查提升负载均衡的并发数量七层负载均衡和四层负载均衡七层负载均衡四层负载均衡四层和七层的区别502错误 nginx实现负载均衡load balance 准备ÿ…...

淘宝订单接口:连接消费者与商家的桥梁
当我们谈论淘宝订单接口时,我们谈论的是淘宝网为卖家和买家提供的一个用于处理订单的核心系统。通过这个接口,卖家可以接收订单、处理订单状态,并更新买家和平台的状态信息;买家则可以实时追踪自己的订单状态,更好地掌…...

数据结构-第一期——数组(Python)
目录 00、前言: 01、一维数组 一维数组的定义和初始化 一维变长数组 一维正向遍历 一维反向遍历 一维数组的区间操作 竞赛小技巧:不用从a[0]开始,从a[1]开始 蓝桥杯真题练习1 读入一维数组 例题一 例题二 例题三 实战训…...
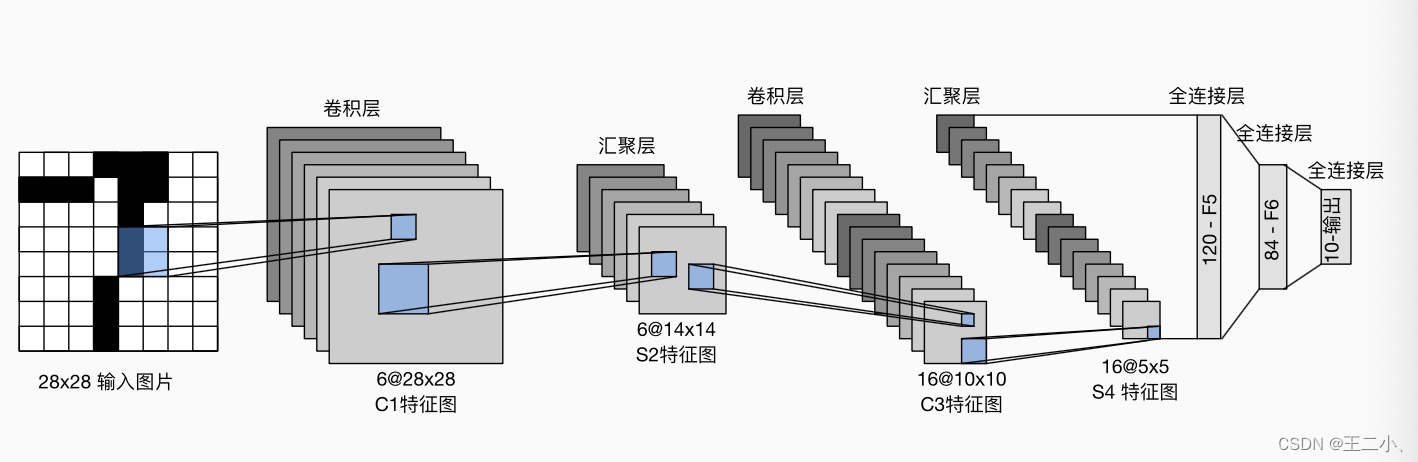
八 动手学深度学习v2 ——卷积神经网络之卷积+填充步幅+池化+LeNet
目录 1. 图像卷积总结2. 填充和步幅 padding和stride3. 多输入多输出通道4. 池化层5. LeNet 1. 图像卷积总结 二维卷积层的核心计算是二维互相关运算。最简单的形式是,对二维输入数据和卷积核执行互相关操作,然后添加一个偏置。核矩阵和偏移是可学习的参…...

SparkCore
第1章 RDD概述 1.1 什么是RDD RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。 RDD类比工厂生产。 …...

配置 Windows 系统环境变量
直接按键盘上面的 WINS 打开 Windows 搜索 搜索“编辑系统环境变量” 也可以右键此电脑->属性->高级系统设置打开相同的界面 点击环境变量 一般添加就是添加在框出的 Path 里面,双击可以看到现有的环境变量并进行编辑 例如我在博客中写把 Java 的 jdk 解压好…...

【计算机视觉】图片文件格式的讲解
文章目录 一、图片的压缩二、计算机表示颜色三、JPG和PNG3.1 JPG3.2 PNG 一、图片的压缩 图片文件格式有可能会对图片的文件大小进行不同程度的压缩,图片的压缩分为有损压缩和无损压缩两种。 有损压缩。指在压缩文件大小的过程中,损失了一部分图片的信…...

2023最全的性能测试种类介绍,这6个种类特别重要!
系统的性能是一个很大的概念,覆盖面非常广泛,包括执行效率、资源占用、系统稳定性、安全性、兼容性、可靠性、可扩展性等,性能测试就是描述测试对象与性能相关的特征并对其进行评价而实施的一类测试。 性能测试是一个统称,它其实包…...

代码随想录算法训练营19期第43天
1049. 最后一块石头的重量 II 视频讲解:动态规划之背包问题,这个背包最多能装多少?LeetCode:1049.最后一块石头的重量II_哔哩哔哩_bilibili 代码随想录 初步思路:动态规划。 总结:套用01背包 dp[j…...

微信小程序wx.previewImage实现图片预览
在微信小程序中,wx.previewImage函数用于预览图片,可以将一组图片以轮播的方式展示给用户,并支持用户手势操作进行切换。 使用wx.previewImage函数需要传入一个参数对象,该对象包含以下属性: current: String&#x…...
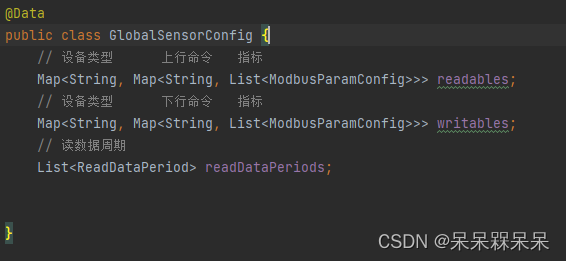
Java实现Modbus读写数据
背景 由于当时项目周期赶,引入了一个PLC4X组件,上手快。接下来就是使用这个组件遇到的一些问题: 关闭连接NioEventLoop没有释放导致oom设计思想是一个设备一个连接,而不是一个网关一个连接连接断开后客户端无从感知 前两个问题解…...
C++11新特性⑤ | 仿函数与lambda表达式
目录 1、引言 2、仿函数 3、lambda表达式 3.1、lambda表达式的一般形式 3.2、返回类型说明 3.3、捕获列表的规则 3.4、可以捕获哪些变量 3.5、lambda表达式给编程带来的便利 VC常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...&a…...

解决websocket不定时出现1005错误
后台抛出异常如下: Operator called default onErrorDropped reactor.core.Exceptions$ErrorCallbackNotImplemented: java.lang.IllegalArgumentException: WebSocket close status code does NOT comply with RFC-6455: 1005 Caused by: java.lang.IllegalArgume…...

文章内容生成随机图像,并将这些图像上链
一、需求背景 在当前的互联网时代,信息越来越快速地传播,一篇好的文章不仅需要有吸引人的文字内容,还需要有精美的配图。但是,对于某些只有文字,而没有图片的文章,我们可以使用程序去生成随机的图片来作为文章的配图。 本文将详细介绍如何使用Java语言实现文章内容生成…...

l8-d9 UDP通信实现
一、函数接口扩展与UDP通信实现流程 1.write/read到send/recv 函数原型: ssize_t send(int sockfd, const void *buf, size_t len, int flags); ssize_t recv(int sockfd, void *buf, size_t len, int flags); 前三个参数同read/write一样; ssize_t rea…...

MongoDB复杂聚合查询与java中MongoTemplate的api对应
MongoDB聚合json脚本 db.getCollection("202303_refund").aggregate([{"$match": {"courseType": "常规班课","teacherRefundReasonCheck": true,"teacherId": {"$in": [7544]},"createTime"…...
WireShark抓包工具的安装
1.下载安装包 在官网或者电脑应用商城都可以下载 2.安装 打开安装包,点击next 点击next 选择UI界面,两种都装上 根据习惯选择 选择安装位置点击安装 开始安装安装成功...

DreamScene2动态桌面软件:为Windows桌面注入活力的终极解决方案
DreamScene2动态桌面软件:为Windows桌面注入活力的终极解决方案 【免费下载链接】DreamScene2 一个小而快并且功能强大的 Windows 动态桌面软件 项目地址: https://gitcode.com/gh_mirrors/dr/DreamScene2 厌倦了千篇一律的静态桌面背景吗?DreamS…...

在Windows 11上用VirtualBox搞定WRF-Hydro 5.2.0:一个水文模型小白的Ubuntu 22.04虚拟机避坑实录
在Windows 11上用VirtualBox搞定WRF-Hydro 5.2.0:一个水文模型小白的Ubuntu 22.04虚拟机避坑实录 第一次接触WRF-Hydro时,我盯着满屏的命令行代码和复杂的依赖关系,感觉像在破解某种外星密码。作为一名水文专业的研究生,我的Linux…...

Docker Desktop部署Weaviate向量数据库:从配置到生产环境全流程
在Docker Desktop上部署Weaviate向量数据库的全流程。通过Docker Compose实现容器化,涵盖持久化存储、安全认证配置及text2vec-openai集成。提供Python/Java客户端连接示例,并针对端口冲突、数据持久化等常见问题给出实用解决方案,助力快速搭…...

DLSS Swapper终极指南:如何快速管理游戏DLSS版本提升性能?
DLSS Swapper终极指南:如何快速管理游戏DLSS版本提升性能? 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为NVIDIA显卡用户设计的智能管理工具,能够无缝管理游…...
)
Java医疗系统通过等保三级测评前,这8个高危漏洞必须在72小时内闭环(附OWASP Top 10映射清单)
第一章:医疗Java系统等保三级合规性基线与高危漏洞判定标准在医疗行业,Java系统承载着电子病历、HIS、LIS、PACS等核心业务,其安全合规性直接关系患者隐私与公共健康。等保三级要求系统具备完善的身份鉴别、访问控制、安全审计、入侵防范及可…...

构建语音驱动的智能Agent:集成SenseVoice-Small与AI决策框架
构建语音驱动的智能Agent:集成SenseVoice-Small与AI决策框架 你有没有想过,对着电脑说句话,它就能帮你写代码、查资料、甚至控制智能家居?这听起来像是科幻电影里的场景,但现在,通过将强大的语音识别模型与…...
)
QGIS属性表关联Excel实战:5步搞定空间数据分析(附避坑指南)
QGIS属性表与Excel高效关联:从数据匹配到空间分析的完整指南 1. 为什么需要关联Excel与QGIS属性表? 在日常空间分析工作中,我们经常遇到这样的场景:拥有完整的空间数据(如行政区划边界),但关键分…...

OpenClaw安全防护全攻略:Qwen3-32B-Chat操作权限精细控制
OpenClaw安全防护全攻略:Qwen3-32B-Chat操作权限精细控制 1. 为什么需要安全防护? 当我第一次把OpenClaw接入本地部署的Qwen3-32B-Chat模型时,那种兴奋感至今记忆犹新——我的电脑突然有了一个24小时待命的AI助手。但很快,一个细…...

轻量级OpenClaw方案对比:nanobot与标准部署性能测试
轻量级OpenClaw方案对比:nanobot与标准部署性能测试 1. 测试背景与动机 最近在为一台闲置的2核4G云主机寻找合适的自动化方案时,我遇到了一个典型的技术选型问题:标准OpenClaw部署对资源要求较高,而新出现的nanobot方案号称是&q…...

Gauge常见问题解决:10个典型错误及修复方法
Gauge常见问题解决:10个典型错误及修复方法 【免费下载链接】gauge Light weight cross-platform test automation 项目地址: https://gitcode.com/gh_mirrors/ga/gauge Gauge作为一款轻量级跨平台测试自动化工具,在使用过程中可能会遇到各种错误…...