ES-索引管理
前言
数据类型
搜索引擎是对数据的检索,所以我们先从生活中的数据说起。我们生活中的数据总体分为两种:
- 结构化数据
- 非结构化数据
结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据: 又可称为全文数据,不定长或无固定格式,不适于由数据库二维表来表现,包括所有格式的办公文档、XML、HTML、Word 文档,邮件,各类报表、图片和咅频、视频信息等。
如果要更细致的区分的话,XML、HTML 可划分为半结构化数据。因为它们也具有自己特定的标签格式,所以既可以根据需要按结构化数据来处理,也可抽取出纯文本按非结构化数据来处理
数据搜索
根据两种数据分类,搜索也相应的分为两种:
- 结构化数据搜索
- 非结构化数据搜索
对于结构化数据,因为它们具有特定的结构,所以我们一般都是可以通过关系型数据库(MySQL,Oracle 等)的二维表(Table)的方式存储和搜索,也可以建立索引。
对于非结构化数据,也即对全文数据的搜索主要有两种方法:
- 顺序扫描
- 全文检索
顺序扫描: 通过文字名称也可了解到它的大概搜索方式,即按照顺序扫描的方式查询特定的关键字。
全文搜索: 将非结构化数据中的一部分信息提取出来,重新组织,使其变得有一定结构,然后对此有一定结构的数据进行搜索,从而达到搜索相对较快的目的。这种方式就构成了全文检索的基本思路。**这部分从非结构化数据中提取出的然后重新组织的信息,我们称之为索引。**这种方式的主要工作量在前期索引的创建,但是对于后期搜索却是快速高效的。
Lucene
对于这种非结构化数据的处理需要依赖全文搜索,而目前市场上开放源代码的最好全文检索引擎工具包就属于 Apache 的 Lucene了。但是 Lucene 只是一个工具包,它不是一个完整的全文检索引擎。Lucene 的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
目前以 Lucene 为基础建立的开源可用全文搜索引擎主要是 Solr 和 Elasticsearch。Solr 和 Elasticsearch 都是比较成熟的全文搜索引擎,能完成的功能和性能也基本一样。但是 ES 本身就具有分布式的特性和易安装使用的特点,而 Solr 的分布式需要借助第三方来实现,例如通过使用 ZooKeeper 来达到分布式协调管理。
倒排索引
不管是 Solr 还是 Elasticsearch 底层都是依赖于 Lucene,而 Lucene 能实现全文搜索主要是因为它实现了倒排索引的查询结构。
如何理解倒排索引呢? 假如现有三份数据文档,文档的内容如下分别是:
- Java is the best programming language.
- PHP is the best programming language.
- Javascript is the best programming language.
为了创建倒排索引,需要通过分词器将每个文档的内容域拆分成单独的词(我们称它为词条或 Term),创建一个包含所有不重复词条的排序列表,然后列出每个词条出现在哪个文档。
这种结构由文档中所有不重复词的列表构成,对于其中每个词都有一个文档列表与之关联。这种由属性值来确定记录的位置的结构就是倒排索引。带有倒排索引的文件我们称为倒排文件。
名词解释
- 词条(Term): 索引里面最小的存储和查询单元,对于英文来说是一个单词,对于中文来说一般指分词后的一个词。
- 词典(Term Dictionary): 或字典,是词条 Term 的集合。搜索引擎的通常索引单位是单词,单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向“倒排列表”的指针。
- 倒排表(Post list): 一个文档通常由多个词组成,倒排表记录的是某个词在哪些文档里出现过以及出现的位置。每条记录称为一个倒排项(Posting),倒排表记录的不单是文档编号,还存储了词频等信息。
- 倒排文件(Inverted File): 所有单词的倒排列表往往顺序地存储在磁盘的某个文件里,这个文件被称之为倒排文件,倒排文件是存储倒排索引的物理文件。
**由此可知,倒排索引主要由词典和倒排文件组成。**词典和倒排表是 Lucene 中很重要的两种数据结构,是实现快速检索的重要基石。词典和倒排文件是分两部分存储的,词典在内存中而倒排文件存储在磁盘上。
索引管理的引入
一般在增加文档时,会动态创建一个customer的index,而这个index实际上以及自动创建了它里面的字段(name)的类型。可以分析一下自动创建的mapping:
{"mappings": {"_doc": {"properties": {"name": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}}}}}
} 如果需要对这个建立索引的过程做更多的控制:比如想要确保这个索引有数量适中的主分片,并且在我们索引任何数据之前,分析器和映射已经被建立好。那么就会引入两点:第一个禁止自动创建索引,第二个是手动创建索引。
#禁止自动创建索引
#可以通过在 config/elasticsearch.yml 的每个节点下添加下面的配置:
action.auto_create_index: false
索引的格式
请求体里面传入设置或类型映射,如下所示:
PUT /my_index
{"settings": { ... any settings ... },"mappings": {"properties": { ... any properties ... }}
}
- settings: 用来设置分片,副本等配置信息
- mappings: 字段映射,类型等
- properties: 由于type在后续版本中会被Deprecated, 所以无需被type嵌套
索引管理操作
手工创建索引
创建一个user 索引test-index-users,其中包含三个属性:name,age, remarks; 存储在一个分片一个副本上。
PUT /test-index-users
{"settings": {"number_of_shards": 1,"number_of_replicas": 1},"mappings": {"properties": {"name": {"type": "text","fields": {"keyword": {"type": "keyword","ignore_above": 256}}},"age": {"type": "long"},"remarks": {"type": "text"}}}
}# 插入数据
POST /test-index-users/_doc
{
"name":"zhangsan",
"age":"18",
"remarks":"hello world"
} 如果输入类型不匹配,就会看到对应的不匹配的错误。
修改索引
# 修改副本数量为0
PUT /test-index-users/_settings
{"settings": {"number_of_replicas": 0}
}
打开/关闭索引
关闭索引
一旦索引被关闭,那么这个索引只能显示元数据信息,不能够进行读写操作。
关闭索引命令为:POST /test-index-users/_close

打开索引
打开索引命令:POST /test-index-users/_open
打开之后就看可以写入正常。
删除索引
将创建的test-index-users删除。命令:DELETE /test-index-users
删除索引之后,再看mapping的索引的信息,就会发现之前新建索引所附加的字段信息没有了。
ES中的mapping有点类似与RDB中“表结构”的概念,在MySQL中,表结构里包含了字段名称,字段的类型还有索引信息等。在Mapping里也包含了一些属性,比如字段名称、类型、字段使用的分词器、是否评分、是否创建索引等属性,并且在ES中一个字段可以有对个类型。
1)先获取基础配置信息
GET /bank/_settings
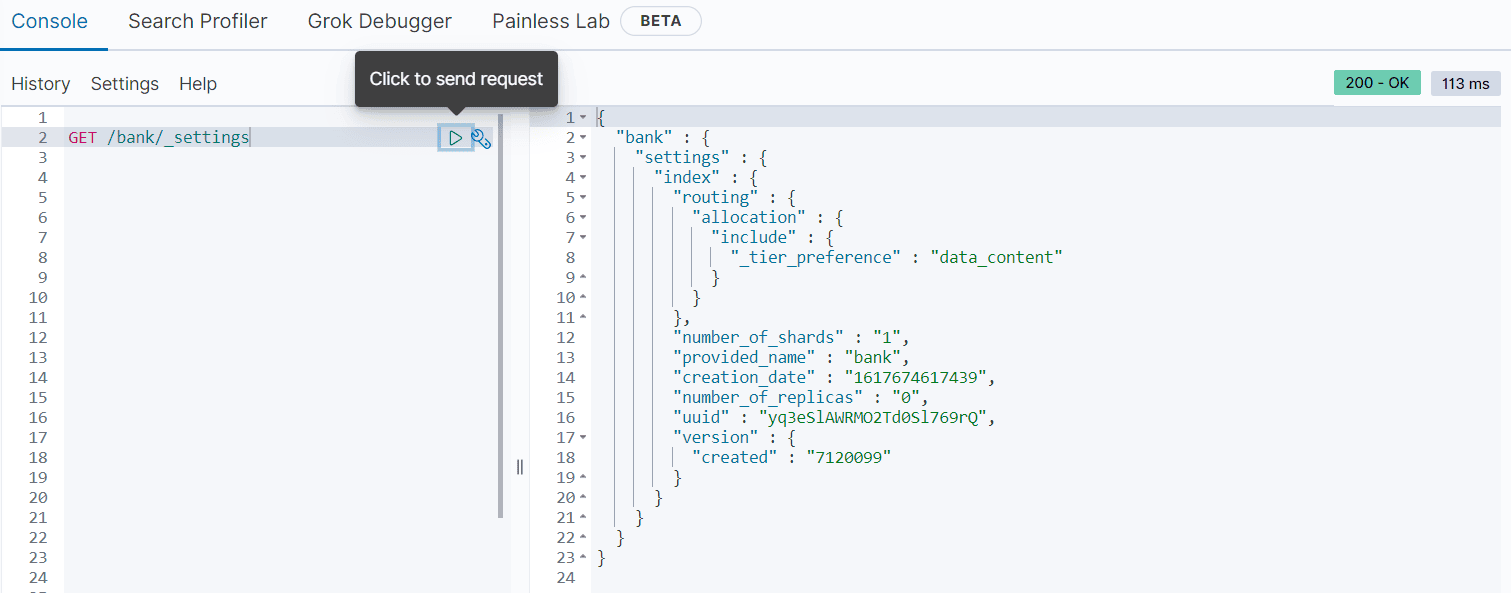
2)获取映射mapping信息
GET /bank/_mapping

Kibana管理索引
Kibana管理索引,可以通过Management->Stack Management->Data->Index Management ->选择对应索引->点击Mappings 可查看索引结构
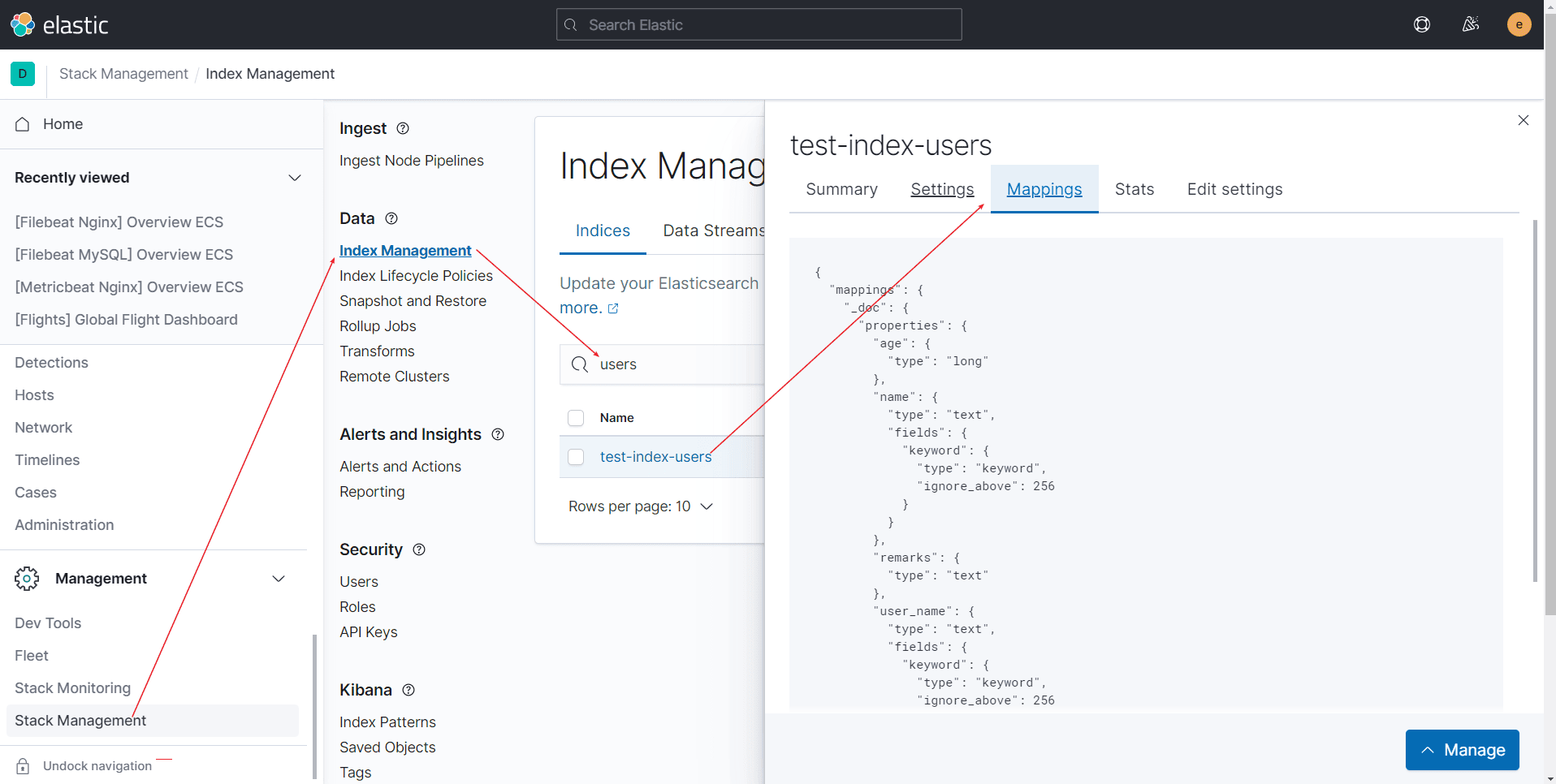
索引模版
前言
上面介绍了索引的一些操作,特别是手动创建索引,但是批量和脚本化必然需要提供一种模板方式快速构建和管理索引,也就是索引模板(Index Template),它是一种告诉Elasticsearch在创建索引时如何配置索引的方法。
索引模版
在创建索引之前可以先配置模板,这样在创建索引(手动创建索引或通过对文档建立索引)时,模板设置将用作创建索引的基础。
模板类型
模板有两种类型:索引模板和组件模板。
- 组件模板是可重用的构建块,用于配置映射,设置和别名;它们不会直接应用于一组索引。
- 索引模板是可以包含组件模板的集合,也可以直接指定设置,映射和别名。
索引模板中的优先级
- 可组合模板优先于旧模板。如果没有可组合模板匹配给定索引,则旧版模板可能仍匹配并被应用。
- 如果使用显式设置创建索引并且该索引也与索引模板匹配,则创建索引请求中的设置将优先于索引模板及其组件模板中指定的设置。
- 如果新数据流或索引与多个索引模板匹配,则使用优先级最高的索引模板。
内置索引模板
Elasticsearch具有内置索引模板,每个索引模板的优先级为100,适用于以下索引模式:
logs-*-*metrics-*-*synthetics-*-*
所以在涉及内建索引模板时,要避免索引模式冲突。
案例
创建索引模版
PUT _component_template/component_template1
{"template": {"mappings": {"properties": {"@timestamp": {"type": "date"}}}}
}PUT _component_template/runtime_component_template
{"template": {"mappings": {"runtime": { "day_of_week": {"type": "keyword","script": {"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"}}}}}
}- 创建使用组件模板的索引模板
PUT _index_template/template_1
{"index_patterns": ["bar*"],"template": {"settings": {"number_of_shards": 1},"mappings": {"_source": {"enabled": true},"properties": {"host_name": {"type": "keyword"},"created_at": {"type": "date","format": "EEE MMM dd HH:mm:ss Z yyyy"}}},"aliases": {"mydata": { }}},"priority": 500,"composed_of": ["component_template1", "runtime_component_template"], "version": 3,"_meta": {"description": "my custom"}
}
- 创建一个匹配
bar*的索引bar-test
PUT /bar-test
相关文章:
ES-索引管理
前言 数据类型 搜索引擎是对数据的检索,所以我们先从生活中的数据说起。我们生活中的数据总体分为两种: 结构化数据非结构化数据 结构化数据: 也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数…...

linux中常用shell脚本整理
linux常见shell脚本整理 备份日志 #!/bin/bash # 每日创建新的备份日志-根据日期备份 tar -czf log-date %Y%m%d.tar.gz /var/log # 通过crontab 每日定时启动 00 03 * * 5 /root/logbak.sh 监控内存和磁盘容量,小于给定值时报警 #!/bin/bash # 实…...

介绍PHP
PHP是一种流行的服务器端编程语言,用于开发Web应用程序。它是一种开源的编程语言,具有易学易用的语法和强大的功能。PHP支持在服务器上运行的动态网页和Web应用程序的快速开发。 PHP可以与HTML标记语言结合使用,从而能够生成动态的Web页面&a…...
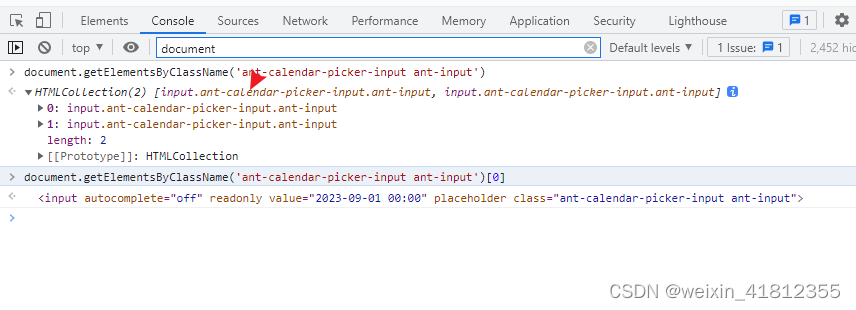
selenium+find_elements用法
1、假如我们遇到多个标签的class一样,比如像下面这样的 我们可以采用js语法去定位,比如: document.getElementsByClassName("ant-calendar-picker-input ant-input")[0]...
1DM+下载器_11.2.1魔改增强版下载
1DM「原:IDM」下载器是一款安卓端的下载工具,多语言解锁版直安装版本,号称是目前 Android 平台最快、最先进的下载管理器应用「支持通过Torrent下载」,而这个版本是改线程的最新idm版本,可用来下载视频、音乐、电影、T…...
vue3:3、项目目录和关键文件
关于vsvode的更改 <!-- 加上setup允许在script中直接编写组合式api --> <script setup> // 组件引入后直接用 import HelloWorld from ./components/HelloWorld.vue import TheWelcome from ./components/TheWelcome.vue</script><!-- 1、js放在最上面&am…...
ChatGPT实战与私有化大模型落地
文章目录 大模型现状baseline底座选择数据构造迁移方法评价思考 领域大模型训练技巧Tokenizer分布式深度学习数据并行管道并行向量并行分布式框架——Megatron-LM分布式深度学习框架——Colossal-AI分布式深度学习框架——DeepSpeedP-tuning 微调 资源消耗模型推理加速模型推理…...
10分钟从实现和使用场景聊聊并发包下的阻塞队列
上篇文章12分钟从Executor自顶向下彻底搞懂线程池中我们聊到线程池,而线程池中包含阻塞队列 这篇文章我们主要聊聊并发包下的阻塞队列 阻塞队列 什么是队列? 队列的实现可以是数组、也可以是链表,可以实现先进先出的顺序队列,…...

Python入门学习13(面向对象)
一、类的定义和使用 类的使用语法: 创建类对象的语法: class Student:name None #学生的名字age None #学生的年龄def say_hi(self):print(f"Hi大家好,我是{self.name}")stu Student() stu.name &q…...

哈工大计算机网络课程网络安全基本原理之:身份认证
哈工大计算机网络课程网络安全基本原理之:身份认证 在日常生活中,在很多场景下我们都需要对当前身份做认证,比如使用密码、人脸识别、指纹识别等,这些都是身份认证的常用方式。本节介绍的身份认证,是在计算机网络安全…...

海外代购系统/代购网站怎么搭建
搭建海外代购系统/代购网站的详细步骤涉及到的内容非常多,本文将分为以下几个部分进行详细介绍:前端开发、后端管理系统的开发、数据库设计和代购流程的设计与实现。 一、前端开发 前端开发是整个代购网站的门面,它直接面向用户,…...

go-micro
go-micro Go Micro简介go-micro体系结构gin-go-micro使用consul实现服务注册与发现实现服务发现批量启动多个服务测试服务发现服务调用在微服务中使用ProtocolBuffergo-micro配置文件...
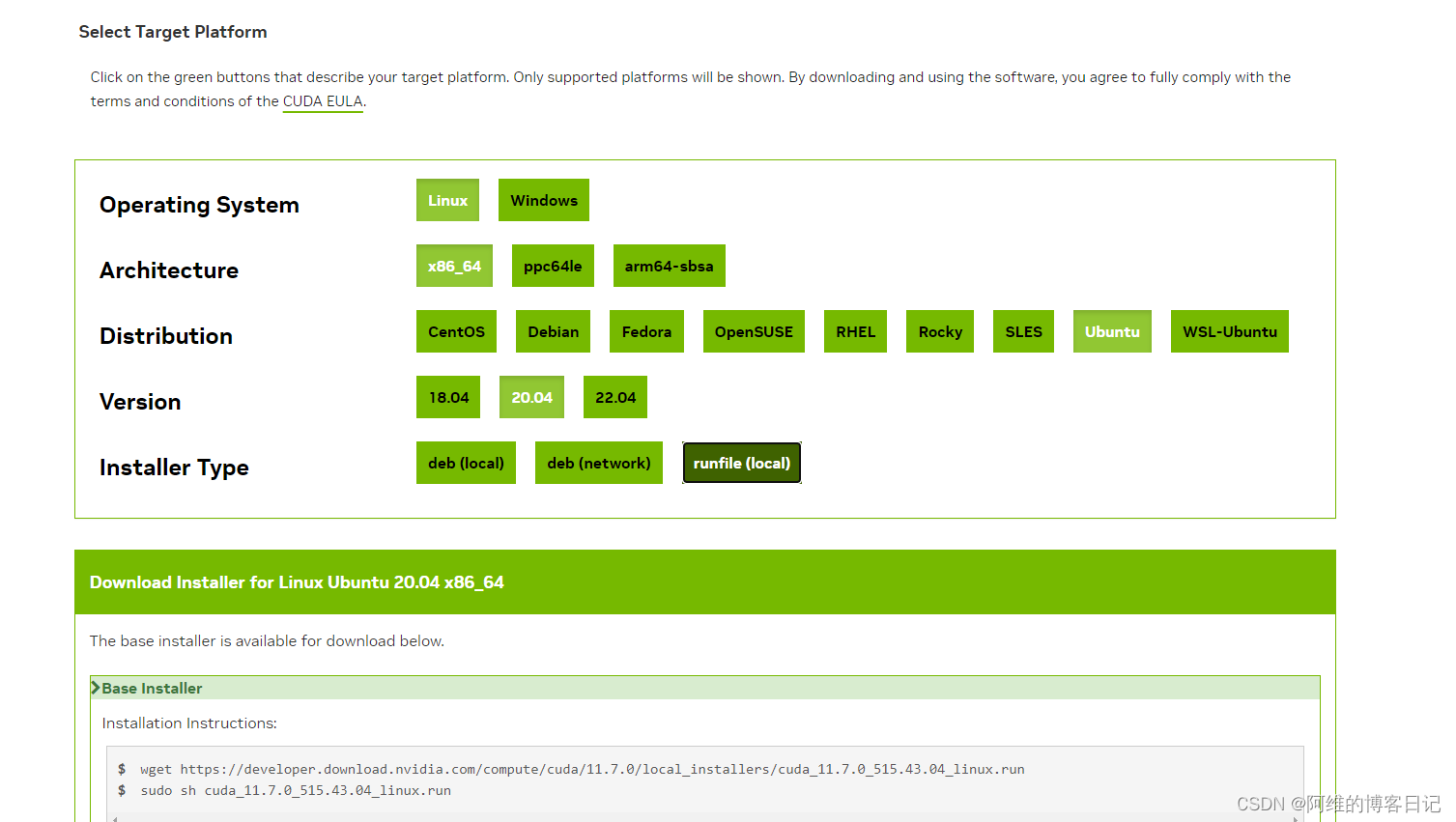
安装GPU驱动,CUDA Toolkit和配置与CUDA对应的Pytorch
如果有帮助,记得回来点个赞 目录 1.安装指定GPU驱动如果安装的GPU CUDA Version和CUDA Toolkit版本已经冲突怎么办? 2.安装指定版本的CUDA Toolkit如果我安装了CUDA Toolkit之后nvcc -V仍然显示旧的CUDA Toolkit版本怎么办? 3.安装与CUDA对应的Pytorch 1.安装指定GPU驱动 &…...

JavaScript单例模式
JavaScript单例模式 1 什么是单例模式2 实现一个基础的单例模式3 透明的单例模式4 用代理实现单例模式5 JavaScript 中的单例模式6 惰性单例 1 什么是单例模式 保证一个类只有一个实例,并提供一个访问它的全局访问点,这就是单例模式。 单例模式是一种常…...

centos下安装jenkins.war
https://get.jenkins.io/war-stable/ 下载jenkins.war包,(2.164.1 版本支持1.8,其他的都是jdk11),可以安装完成后更新jenkins.war的安装包启动jenkins命令 java -jar jenkins.war --httpPort8010访问http://IP:8010/jenkins (密码在/root/.jenkins/secre…...

App线上网络问题优化策略
在我们App开发过程中,网络是必不可少的,几乎很难想到有哪些app是不需要网络传输的,所以网络问题一般都是线下难以复现,一旦到了用户手里就会碰到很多疑难杂症,所以对于网络的监控是必不可少的,针对用户常见…...
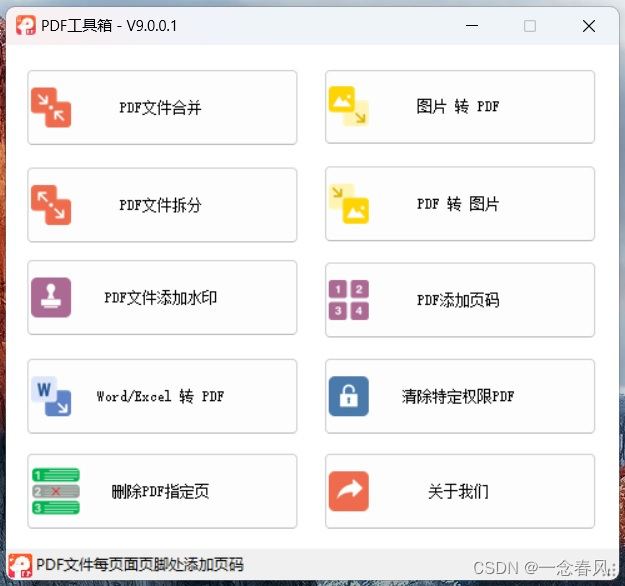
PDF 工具箱
PDF 工具箱 V9.0.0.1 程序:VB.net 运行库:NET Framework 4.5 功能简介: 1、PDF文件多文件合并,可调整顺序。 2、PDF文件拆分,将每页拆分成独立的PDF文件。 3、PDF文件添加水印,文字或图片水印&…...

大数据组件系列-Hadoop每日小问
1、谈谈对HDFS的理解?HDFS这种存储适合哪些场景? HDFS即Hadoop Distributed File System,Hadoop 分布式文件系统。它为的是解决海量数据的存储与分析的问题,它本身是源于Google在大数据方面的论文,GFS-->HDFS; HD…...
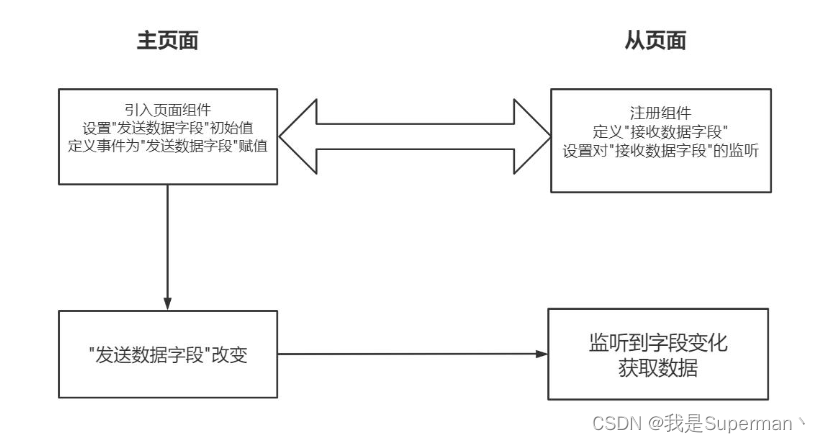
【前端】在Vue页面中引入其它vue页面 数据传输 相互调用方法等
主页面 home 从页面 headView 需求 在 home.vue 中引用 headView.Vue 方案: home.vue 代码: 只需要在home.vue 想要的地方添加 <headView></headView> <script>//聊天页面 import headView /view/headView.vueexport default {components: {headView},…...
网络通信深入解析:探索TCP/IP模型
http协议访问web 你知道在我们的网页浏览器的地址当中输入url,未必是如何呈现的吗? web浏览器根据地址栏中指定的url,从web服务器获取文件资源(resource)等信息,从而显示出web页面。web使用HTTP(…...

收藏 | 程序员小白也能掌握大模型开发,AI时代大有可为!
收藏 | 程序员小白也能掌握大模型开发,AI时代大有可为! 本文针对非AI专业背景的程序员,介绍了如何参与大模型应用开发。内容涵盖大模型基础、提示词编写与提示工程技巧,以及使用OpenAI API和LangChain框架进行应用开发的关键步骤。…...

如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧
如何快速解包Godot游戏资源:3分钟掌握PCK文件提取技巧 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否曾经遇到过想要查看Godot游戏内部资源却无从下手的困境?那些神秘…...

Python ORM实战:SQLAlchemy深度解析
Python ORM实战:SQLAlchemy深度解析 引言 在Python后端开发中,ORM(对象关系映射)是连接应用程序和数据库的重要桥梁。作为一名从Rust转向Python的后端开发者,我深刻体会到SQLAlchemy在处理数据库操作方面的强大能力。S…...

Standard计划突然限速?揭秘MJ v6.1后台配额算法变更,3步绕过队列延迟,今日生效
更多请点击: https://intelliparadigm.com 第一章:Standard计划限速事件的全貌还原 2024年Q2,Standard计划在多个云原生生产环境中突发性触发API速率限制(Rate Limiting),导致下游服务批量超时与重试风暴。…...

泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南
泰拉瑞亚地图编辑器TEdit:5步打造专业级游戏世界的终极指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets y…...

为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升
为什么我们的浏览器操作效率低下?如何用Shortkeys扩展实现3倍效率提升 【免费下载链接】shortkeys A browser extension for custom keyboard shortcuts 项目地址: https://gitcode.com/gh_mirrors/sh/shortkeys 每天在浏览器上,我们花费大量时间…...

从理论到实践:LQR在二自由度云台控制系统中的参数整定与仿真验证
1. LQR控制器的工程实践意义 二自由度云台在工业自动化、智能监控等领域应用广泛,但传统PID控制往往难以兼顾快速响应和稳定性的双重需求。LQR(线性二次型调节器)作为现代控制理论中的经典方法,通过优化目标函数实现对系统的精确控…...

同样遍历 Mat,为什么你的代码慢 10 倍?
文章目录前言一、什么是不连续Mat?1.产生不连续内存的常见场景2.连续与不连续内存本质区别二、常见错误遍历方式&踩坑分析1.错误一:at<>()逐像素访问(速度慢)2.错误二:强行使用一维 data 指针(高危崩溃&…...

Claude Code / Cursor 写的代码,你敢直接上线吗?我踩过一次坑,再也不敢
👉 这是一个或许对你有用的社群🐱 一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料: 《项目实战(视频)》:从书中学,往事上…...

模块二-数据选择与索引——06. 列选择与操作
06. 列选择与操作 1. 概述 数据选择是 Pandas 最常用的操作之一。掌握列选择与操作,可以高效地提取、添加、修改和删除数据列。 import pandas as pd import numpy as np# 创建示例数据 df pd.DataFrame({姓名: [张三, 李四, 王五, 赵六, 钱七],年龄: [25, 30, 28,…...