【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录
- 一. 问题描述
- 二. 问题分析与解决
- 1. container内存监控
- 1.1. 虚拟内存判断
- 1.2. 物理内存判断
- 2. 正确配置mapReduce内存
- 2.1. 配置map和reduce进程的物理内存:
- 2.2. Map 和Reduce 进程的JVM 堆大小
- 3. 小结
一. 问题描述
在hadoop3.0.3集群上执行hive3.1.2的任务,任务提交时报如下错误:
Application application_1409135750325_48141 failed 2 times due to AM Container for
appattempt_1409135750325_48141_000002 exited with exitCode: 143 due to: Container
[pid=4733,containerID=container_1409135750325_48141_02_000001] is running beyond physical memory limits.
Current usage: 2.0 GB of 2 GB physical memory used; 6.0 GB of 4.2 GB virtual memory used. Killing container.
上述日志大致描述了:
任务申请了2.0g的物理内存,6g的虚拟内存,但是yarn只能分配2g的物理内存,4.2g的虚拟内存。因为虚拟内存不够,导致任务无法启动而报错。
二. 问题分析与解决
报错的原因是:申请的物理内存比container中物理内存大,导致任务无法运行。那为什么超预算申请?这是我们需要探索的问题。
1. container内存监控
本节讨论yarn是如何监控container的内存变化。
每一个yarn的节点都会运行一个nodemanager,nodemanager会监控container的运行,其中nodemanager会监控container的内存使用率。具体地,nodemanager会定期(yarn.nodemanager.container-monitor.interval-ms 默认三秒)监控container,它会计算进程树(每一个container所有的子进程),检查每一个进程文件/proc/<PID>/stat(PID:container的pid),并解析物理内存和虚拟内存。
1.1. 虚拟内存判断
如果启用虚拟内存检查(默认为 true,yarn.nodemanager.vmem-check-enabled),则 YARN 会判断container现在所申请的虚拟内存是否小于允许的最大虚拟内存
而最大的虚拟内存由yarn.nodemanager.vmem-pmem-ratio(默认为 2.1)计算得出。
比如,container配置 2 GB 物理内存,则该数字乘以 2.1,得出可以使用 4.2 GB 虚拟内存。
1.2. 物理内存判断
如果启用物理内存检查(默认为 true,yarn.nodemanager.pmem-check-enabled),则 YARN 会判断container现在所申请的物理内存是否小于允许的最大物理内存
综上所述:
如果虚拟或物理高于允许的最大值,YARN 将终止container运行,报错如本文顶部所示。
知道了报错的原因我们就可以针对性的配置mapreduce相关配置,接着往下看。
2. 正确配置mapReduce内存
2.1. 配置map和reduce进程的物理内存:
假如map限制为2GB、reduce限制为4GB,且设置为默认值,则可以在mapred-site.xml中配置:
<property><name>mapreduce.map.memory.mb</name><value>2048</value>
</property>
<property><name>mapreduce.reduce.memory.mb</name><value>4096</value>
</property>
而上述的配置必须在container允许的最小和最大内存范围内(在yarn-site.xml中分别检查yarn.scheduler.maximum-allocation-mb和yarn.scheduler.minimum-allocation-mb属性)。
<property><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>8196</value></property>
2.2. Map 和Reduce 进程的JVM 堆大小
这些大小需要小于您在上一节中配置的物理内存。一般来说,它们应该是 YARN 物理内存设置大小的 80%。采用 2GB 和 4GB 物理内存限制并乘以 0.8 来得出 Java 堆大小。
<property><name>mapreduce.map.java.opts</name><value>-Xmx1638m</value>
</property>
<property><name>mapreduce.reduce.java.opts</name><value>-Xmx3278m</value>
</property>
3. 小结
如果说配置之后还是报开头的错误,说明物理内存配置还是小不足以加载mr程序,接着申请了大于2.1比例的虚拟内存,这样任务还是启动不了。
这时可以调大yarn.nodemanager.vmem-pmem-ratio比例,或者进一步调大物理内存。2.1是yarn推荐的比例(ing),这里建议调整物理内存。
如果是少数任务需要特定调整,则我们可以在任务启动时,根据实际情况配置,动态地传递以下参数,来覆盖不适合此任务的默认配置。
| 配置 | 描述 |
|---|---|
| mapreduce.map.memory.mb | map所用物理内存 |
| mapreduce.reduce.memory.mb | reduce所用物理内存 |
| mapreduce.map.java.opts | map堆内存,一般为mapreduce.map.memory.mb的80% |
| mapreduce.reduce.java.opts | reduce堆内存,一般为mapreduce.reduce.memory.mb的80% |
参考:
http://grepalex.com/2016/12/07/mapreduce-yarn-memory/
相关文章:

【hadoop运维】running beyond physical memory limits:正确配置yarn中的mapreduce内存
文章目录 一. 问题描述二. 问题分析与解决1. container内存监控1.1. 虚拟内存判断1.2. 物理内存判断 2. 正确配置mapReduce内存2.1. 配置map和reduce进程的物理内存:2.2. Map 和Reduce 进程的JVM 堆大小 3. 小结 一. 问题描述 在hadoop3.0.3集群上执行hive3.1.2的任…...
)
数据结构--6.5二叉排序树(插入,查找和删除)
目录 一、创建 二、插入 三、删除 二叉排序树(Binary Sort Tree)又称为二叉查找树,它或者是一棵空树,或者是具有下列性质的二叉树: ——若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值…...
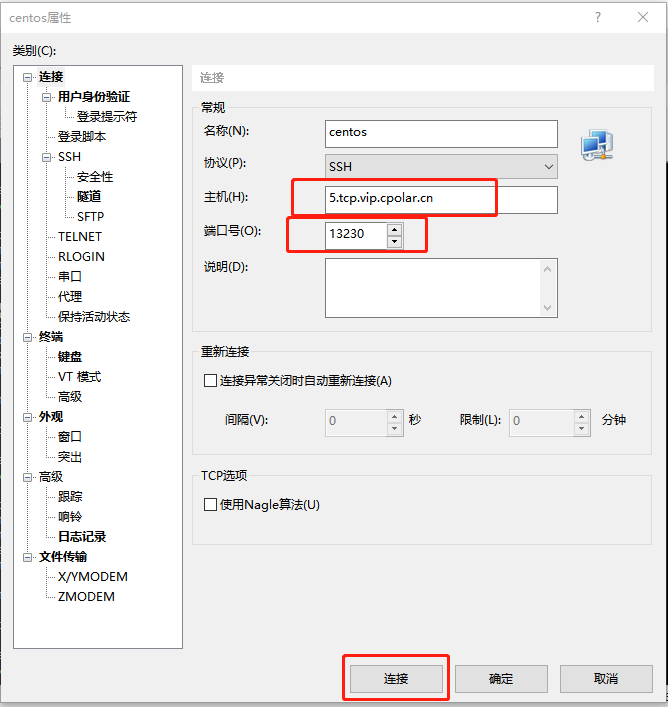
无需公网IP,在家SSH远程连接公司内网服务器「cpolar内网穿透」
文章目录 1. Linux CentOS安装cpolar2. 创建TCP隧道3. 随机地址公网远程连接4. 固定TCP地址5. 使用固定公网TCP地址SSH远程 本次教程我们来实现如何在外公网环境下,SSH远程连接家里/公司的Linux CentOS服务器,无需公网IP,也不需要设置路由器。…...

Java工具类
一、org.apache.commons.io.IOUtils closeQuietly() toString() copy() toByteArray() write() toInputStream() readLines() copyLarge() lineIterator() readFully() 二、org.apache.commons.io.FileUtils deleteDirectory() readFileToString() de…...

makefile之使用函数wildcard和patsubst
Makefile之调用函数 调用makefile机制实现的一些函数 $(function arguments) : function是函数名,arguments是该函数的参数 参数和函数名用空格或Tab分隔,如果有多个参数,之间用逗号隔开. wildcard函数:让通配符在makefile文件中使用有效果 $(wildcard pattern) 输入只有一个参…...

算法通关村第十八关——排列问题
LeetCode46.给定一个没有重复数字的序列,返回其所有可能的全排列。例如: 输入:[1,2,3] 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]] 元素1在[1,2]中已经使…...

基于STM32设计的生理监测装置
一、项目功能要求 设计并制作一个生理监测装置,能够实时监测人体的心电图、呼吸和温度,并在LCD液晶显示屏上显示相关数据。 随着现代生活节奏的加快和环境的变化,人们对身体健康的关注程度越来越高。为了及时掌握自身的生理状况,…...

Go-Python-Java-C-LeetCode高分解法-第五周合集
前言 本题解Go语言部分基于 LeetCode-Go 其他部分基于本人实践学习 个人题解GitHub连接:LeetCode-Go-Python-Java-C Go-Python-Java-C-LeetCode高分解法-第一周合集 Go-Python-Java-C-LeetCode高分解法-第二周合集 Go-Python-Java-C-LeetCode高分解法-第三周合集 G…...
)
【前端知识】前端加密算法(base64、md5、sha1、escape/unescape、AES/DES)
前端加密算法 一、base64加解密算法 简介:Base64算法使用64个字符(A-Z、a-z、0-9、、/)来表示二进制数据的64种可能性,将每3个字节的数据编码为4个可打印字符。如果字节数不是3的倍数,将会进行填充。 优点࿱…...
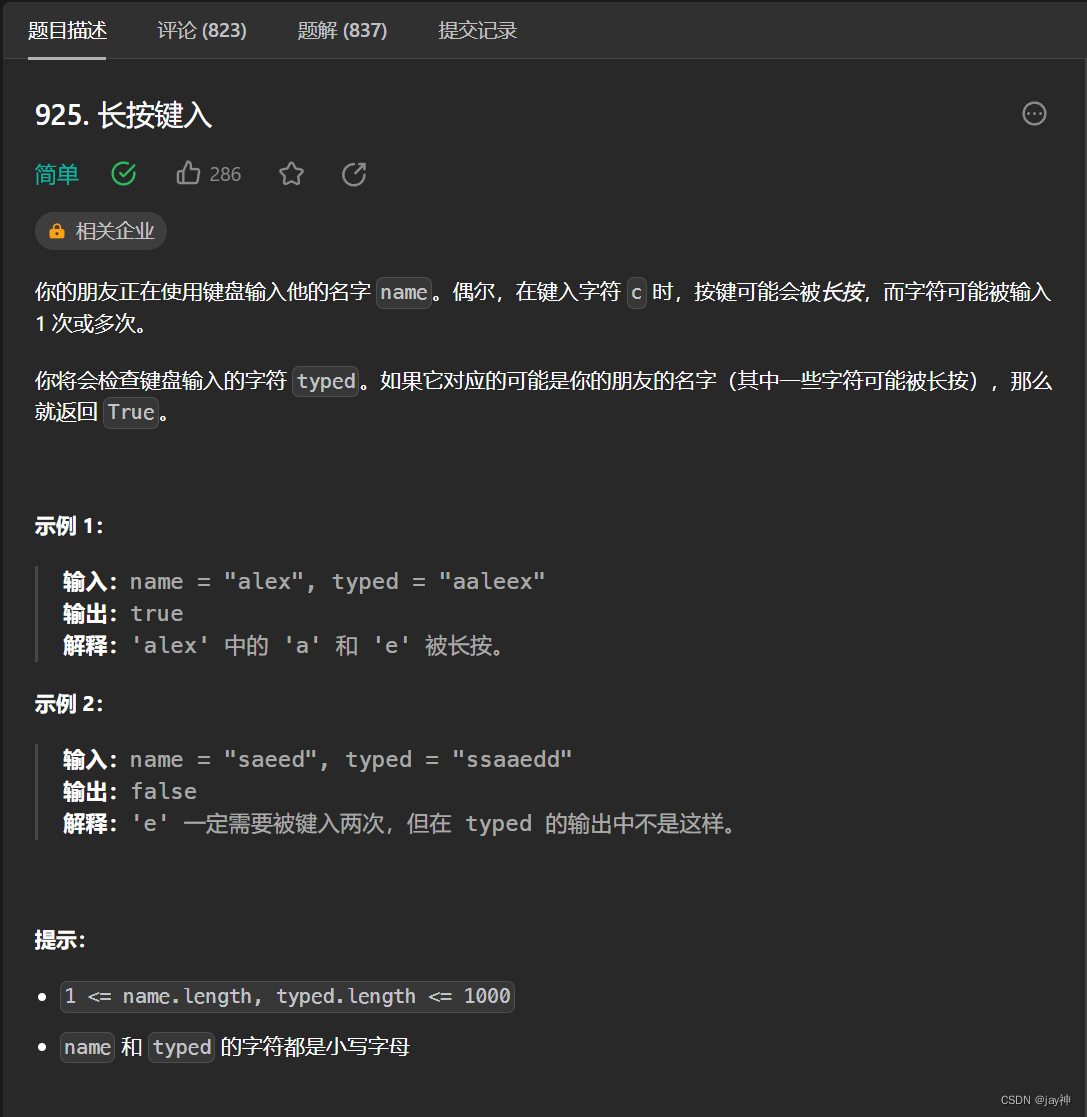
leetcode 925. 长按键入
2023.9.7 我的基本思路是两数组字符逐一对比,遇到不同的字符,判断一下typed与上一字符是否相同,不相同返回false,相同则继续对比。 最后要分别判断name和typed分别先遍历完时的情况。直接看代码: class Solution { p…...

[CMake教程] 循环
目录 一、foreach()二、while()三、break() 与 continue() 作为一个编程语言,CMake也少不了循环流程控制,他提供两种循环foreach() 和 while()。 一、foreach() 基本语法: foreach(<loop_var> <items>)<commands> endfo…...
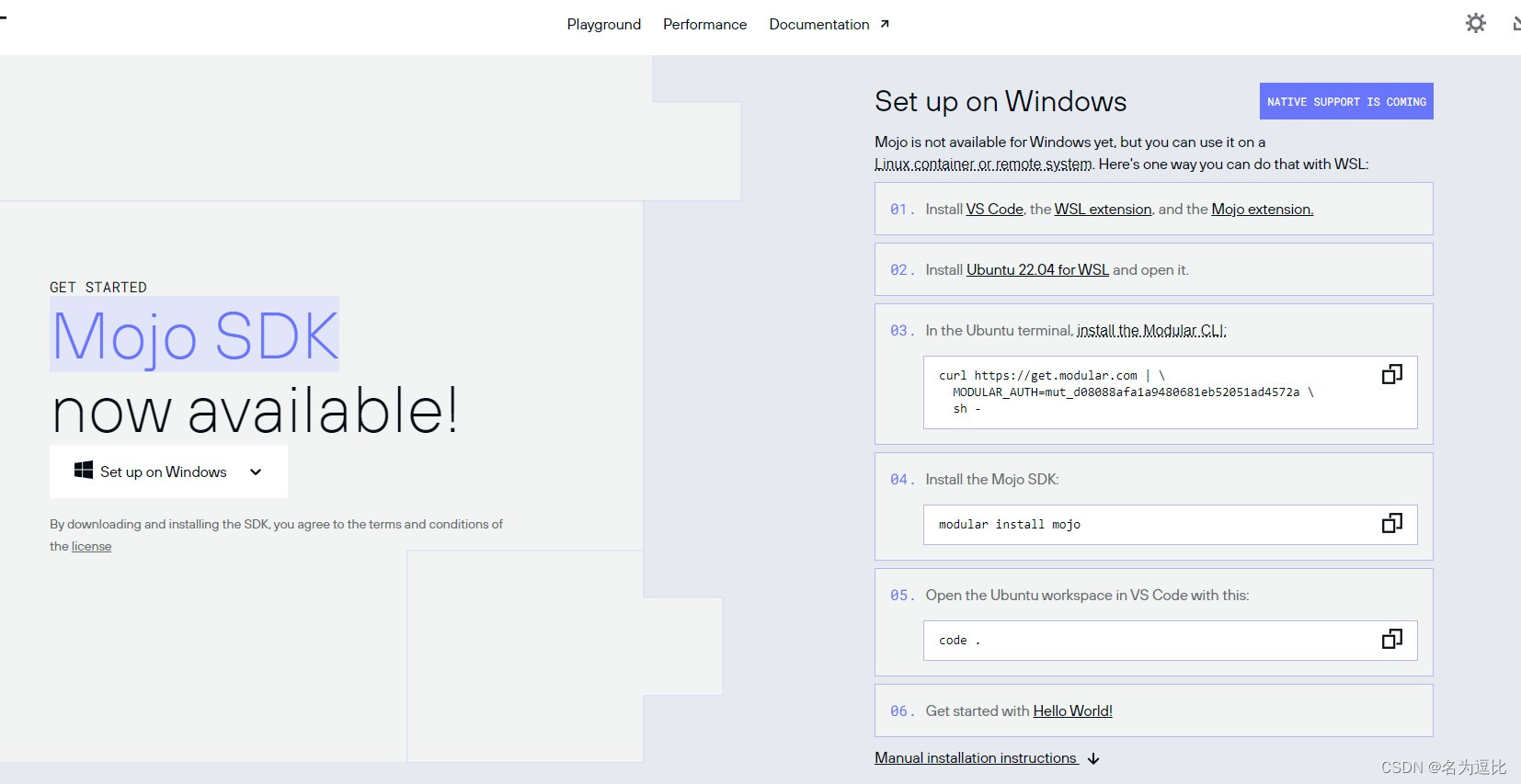
Mojo安装使用初体验
一个声称比python块68000倍的语言 蹭个热度,安装试试 系统配置要求: 不支持Windows系统 配置要求: 系统:Ubuntu 20.04/22.04 LTSCPU:x86-64 CPU (with SSE4.2 or newer)内存:8 GiB memoryPython 3.8 - 3.10g or cla…...

艺术与AI:科技与艺术的完美融合
文章目录 艺术创作的新工具生成艺术艺术与数据 AI与互动艺术虚拟现实(VR)与增强现实(AR)机器学习与互动性 艺术与AI的伦理问题结语 🎉欢迎来到AIGC人工智能专栏~艺术与AI:科技与艺术的完美融合 ☆* o(≧▽≦…...
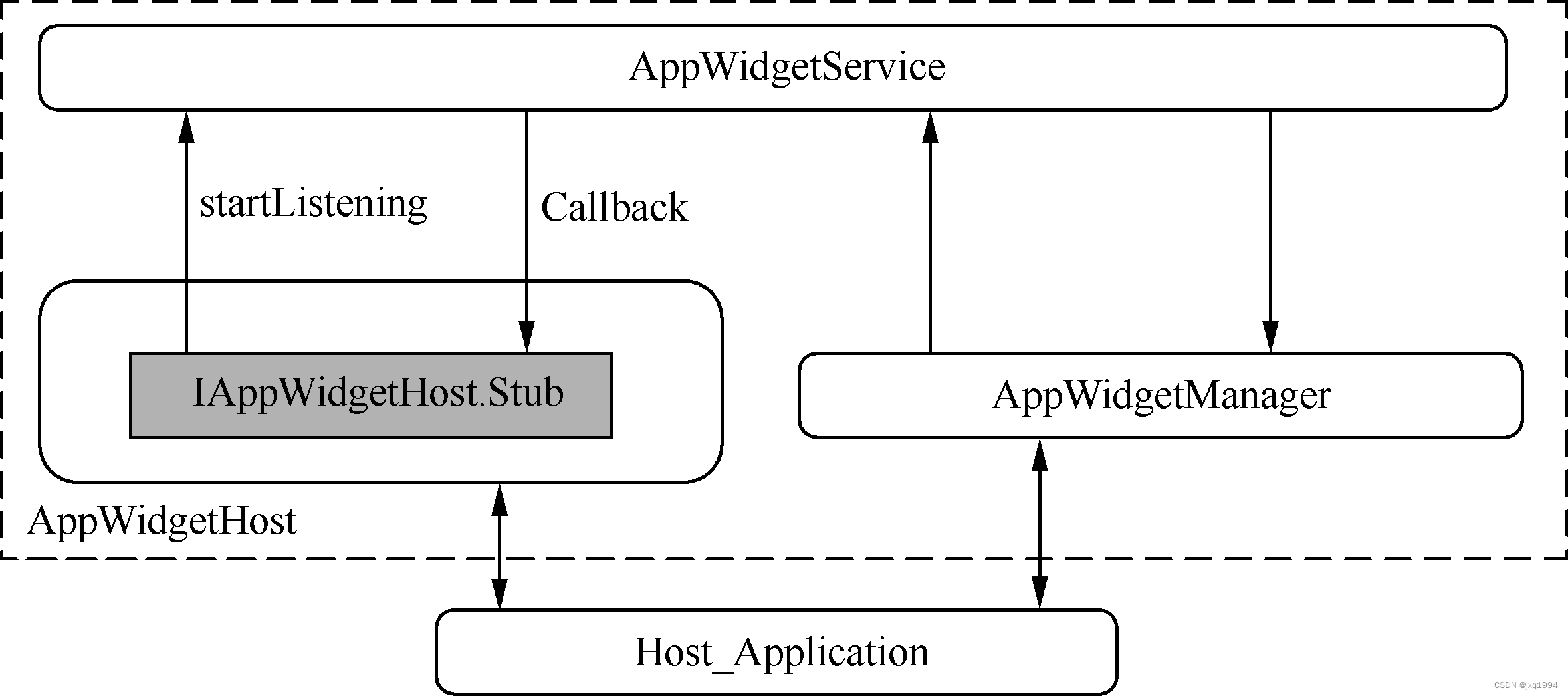
Android常用的工具“小插件”——Widget机制
Widget俗称“小插件”,是Android系统中一个很常用的工具。比如我们可以在Launcher中添加一个音乐播放器的Widget。 在Launcher上可以添加插件,那么是不是说只有Launcher才具备这个功能呢? Android系统并没有具体规定谁才能充当“Widget容器…...

探索在云原生环境中构建的大数据驱动的智能应用程序的成功案例,并分析它们的关键要素。
文章目录 1. Netflix - 个性化推荐引擎2. Uber - 实时数据分析和决策支持3. Airbnb - 价格预测和优化5. Google - 自然语言处理和搜索优化 🎈个人主页:程序员 小侯 🎐CSDN新晋作者 🎉欢迎 👍点赞✍评论⭐收藏 ✨收录专…...

jupyter 添加中文选项
文章目录 jupyter 添加中文选项1. 下载中文包2. 选择中文重新加载一下,页面就变成中文了 jupyter 添加中文选项 1. 下载中文包 pip install jupyterlab-language-pack-zh-CN2. 选择中文 重新加载一下,页面就变成中文了 这才是设置中文的正解ÿ…...

系列十、Java操作RocketMQ之批量消息
一、概述 RocketMQ可以一次性发送一组消息,那么这一组消息会被当做一个消息进行消费。 二、案例代码 2.1、pom 同系列五 2.2、RocketMQConstant 同系列五 2.3、BatchConsumer package org.star.batch.consumer;import cn.hutool.core.util.StrUtil; import lom…...

leetcode1两数之和
题目: 给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。 你可以假设每种输入只会对应一个答案。但是,数组中同一个元素在答案里不能重复出现。 你…...

近年GDC服务器分享合集(四): 《火箭联盟》:为免费游玩而进行的扩展
如今,网络游戏采用免费游玩(Free to Play)加内购的比例要远大于买断制,这是因为前者能带来更低的用户门槛。甚至有游戏为了获取更多的用户,选择把原来的买断制改为免费游玩,一个典型的例子就是最近的网易的…...

android反射详解
1,反射的定义 一般情况下,我们使用某个类时必定知道它是什么类,是用来做什么的,并且能够获得此类的引用。于是我们直接对这个类进行实例化,之后使用这个类对象进行操作。 反射则是一开始并不知道我要初始化的类对象是…...

收藏!AI时代程序员转型指南:从纯编码到人机协同高手
本文揭示了AI对程序员行业的深刻变革:初级编码岗需求锐减,而AI协作、架构师等高端岗位需求激增。文章提出两个阶段提升竞争力:第一阶段掌握AI工具栈(编码助手、调试工具等)并遵循人机协同法则;第二阶段构建…...

从网易招聘看技术人择校与城市选择:一线城市VS武汉,哪里机会更多?
技术人择校与城市选择指南:数据驱动的职业发展决策 站在高考志愿填报或考研择校的十字路口,每个怀揣技术梦想的年轻人都面临着一个关键抉择:是追逐一线城市的产业聚集效应,还是选择武汉这类高校密集但名企较少的城市?这…...

软件开发加速安全审查滞后:“查找 - 修复”与“防御 - 推迟”难敌新风险!
ZDNET的关键要点持续部署让旧安全模型过时,漏洞积压令开发团队不堪重负,应用程序安全需向代码创建阶段转移。锻炼时在跑步机上反复踏步,付出努力却原地不动,毫无成就感,第二天再重复就更觉沮丧。应用程序安全也类似&am…...

终极WebPShop插件:解锁Photoshop专业级WebP处理能力
终极WebPShop插件:解锁Photoshop专业级WebP处理能力 【免费下载链接】WebPShop Photoshop plug-in for opening and saving WebP images 项目地址: https://gitcode.com/gh_mirrors/we/WebPShop WebPShop是一款专为Adobe Photoshop设计的开源插件,…...

Degrees of Lewdity中文本地化技术解析:从安装到优化的实践指南
Degrees of Lewdity中文本地化技术解析:从安装到优化的实践指南 Degrees of Lewdity作为一款备受欢迎的游戏,其英文界面一直是中文用户体验的主要障碍。本文提供的Degrees of Lewdity中文本地化技术解析,将系统指导您完成游戏汉化的全过程&a…...
)
用ChatGPT批量生成高互动Instagram内容:5步工作流+4类避坑红线(数据实测CTR提升217%)
更多请点击: https://intelliparadigm.com 第一章:用ChatGPT批量生成高互动Instagram内容:5步工作流4类避坑红线(数据实测CTR提升217%) 借助ChatGPT API 与 Instagram Graph API 的协同调度,可构建轻量级自…...

Factool开源框架:构建可信AI的事实核查自动化流水线
1. 项目概述:从“事实核查”到“可信AI”的基石工具在信息爆炸的时代,我们每天都被海量的文本内容包围——新闻稿、分析报告、产品介绍、学术论文,甚至是AI模型自己生成的回答。一个核心的挑战随之而来:如何快速、准确地判断一段文…...

Jeandle:基于LLVM的Java JIT编译器架构解析与实战
1. 项目概述与核心价值最近在Java性能优化这个老生常谈的话题里,我又看到了一个新面孔——Jeandle。简单来说,这是一个基于OpenJDK和LLVM构建的Java即时编译器。如果你对JVM的JIT(Just-in-Time Compilation)机制有所了解ÿ…...

RAGday13-day15
Day13:RAG 常见问题 & 调优实战检索不到内容原因:分块太小、关键词太偏、没做混合检索解决:换递归 / 父子分块、加上 ES 混合检索、做 Query 改写搜到内容多但答不对原因:检索杂、没重排、没上下文压缩解决:加 Rer…...

FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程
FPGA仿真库配置避坑指南:Xilinx 7系、Altera Cyclone V、Lattice ECP5在ModelSim 10.6d下的完整流程 第一次在ModelSim 10.6d环境下配置FPGA仿真库时,我花了整整三天时间排查各种路径错误和权限问题。直到现在,我还清楚地记得那个深夜——当仿…...