实战:大数据Flink CDC同步Mysql数据到ElasticSearch
文章目录
- 前言
- 知识积累
- CDC简介
- CDC的种类
- 常见的CDC方案比较
- Springboot接入Flink CDC
- 环境准备
- 项目搭建
- 本地运行
- 集群运行
- 将项目打包将包传入集群启动
- 远程将包部署到flink集群
- 写在最后
前言
前面的博文我们分享了大数据分布式流处理计算框架Flink和其基础环境的搭建,相信各位看官都已经搭建好了自己的运行环境。那么,今天就来实战一把使用Flink CDC同步Mysql数据导Elasticsearch。
知识积累
CDC简介
CDC 的全称是 Change Data Capture(变更数据捕获技术) ,在广义的概念上,只要是能捕获数据变更的技术,我们都可以称之为 CDC 。目前通常描述的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
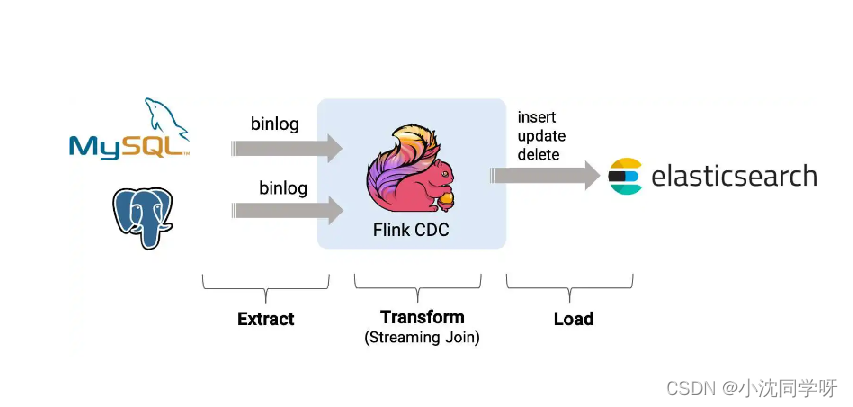
CDC的种类
CDC 的技术方案非常多,目前业界主流的实现机制可以分为两种:
基于查询的 CDC:
◆离线调度查询作业,批处理。把一张表同步到其他系统,每次通过查询去获取表中最新的数据;
◆无法保障数据一致性,查的过程中有可能数据已经发生了多次变更;
◆不保障实时性,基于离线调度存在天然的延迟。
基于日志的 CDC:
◆实时消费日志,流处理,例如 MySQL 的 binlog 日志完整记录了数据库中的变更,可以把 binlog 文件当作流的数据源;
◆保障数据一致性,因为 binlog 文件包含了所有历史变更明细;
◆保障实时性,因为类似 binlog 的日志文件是可以流式消费的,提供的是实时数据。
常见的CDC方案比较

Springboot接入Flink CDC
由于Flink官方提供了Java、Scala、Python语言接口用以开发Flink应用程序,故我们可以直接用Maven引入Flink依赖进行功能实现。
环境准备
1、SpringBoot 2.4.3
2、Flink 1.13.6
3、Scala 2.11
4、Maven 3.6.3
5、Java 8
6、mysql 8
7、es 7
Springboot、Flink、Scala版本一定要相匹配,也可以严格按照本博客进行配置。
注意:
如果只是本机测试玩玩,Maven依赖已经整合计算环境,不用额外搭建Flink环境;如果需要部署到Flink集群则需要额外搭建Flink集群。另外Scala 版本只是用于依赖选择,不用关心Scala环境。
项目搭建
1、引入Flink CDC Maven依赖
pom.xml
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.4.3</version><relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>flink-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>flink-demo</name>
<description>Demo project for Spring Boot</description>
<properties><java.version>8</java.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding><flink.version>1.13.6</flink.version>
</properties>
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.23</version></dependency><!-- Flink CDC connector for MySQL --><dependency><groupId>com.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>2.1.0</version><exclusions><exclusion><groupId>org.apache.flink</groupId><artifactId>flink-shaded-guava</artifactId></exclusion></exclusions></dependency><!-- Flink CDC connector for ES https://mvnrepository.com/artifact/org.apache.flink/flink-connector-elasticsearch7_2.11--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-elasticsearch7_2.11</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-json --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-api-java-bridge_2.11 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner_2.11 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients_2.11 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java_2.11 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency>
</dependencies>
2、创建测试数据库表users
users表结构
CREATE TABLE `users` (`id` bigint NOT NULL AUTO_INCREMENT COMMENT 'ID',`name` varchar(50) NOT NULL COMMENT '名称',`birthday` timestamp NULL DEFAULT NULL COMMENT '生日',`ts` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='用户';
3、es索引操作
es操作命令
es索引会自动创建
#设置es分片与副本
curl -X PUT "10.10.22.174:9200/users" -u elastic:VaHcSC3mOFfovLWTqW6E -H 'Content-Type: application/json' -d'
{"settings" : {"number_of_shards" : 3,"number_of_replicas" : 2}
}'#查询index下全部数据
curl -X GET "http://10.10.22.174:9200/users/_search" -u elastic:VaHcSC3mOFfovLWTqW6E -H 'Content-Type: application/json' #删除index
curl -X DELETE "10.10.22.174:9200/users" -u elastic:VaHcSC3mOFfovLWTqW6E
本地运行
@SpringBootTest
class FlinkDemoApplicationTests {/*** flinkCDC* mysql to es* @author senfel* @date 2023/8/22 14:37 * @return void*/@Testvoid flinkCDC() throws Exception{EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()//.useBlinkPlanner().inStreamingMode().build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env,fsSettings);tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);// 数据源表String sourceDDL ="CREATE TABLE users (\n" +" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +" name STRING,\n" +" birthday TIMESTAMP(3),\n" +" ts TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'mysql-cdc',\n" +" 'hostname' = '10.10.10.202',\n" +" 'port' = '6456',\n" +" 'username' = 'root',\n" +" 'password' = 'MyNewPass2021',\n" +" 'server-time-zone' = 'Asia/Shanghai',\n" +" 'database-name' = 'cdc',\n" +" 'table-name' = 'users'\n" +" )";// 输出目标表String sinkDDL ="CREATE TABLE users_sink_es\n" +"(\n" +" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +" name STRING,\n" +" birthday TIMESTAMP(3),\n" +" ts TIMESTAMP(3)\n" +") \n" +"WITH (\n" +" 'connector' = 'elasticsearch-7',\n" +" 'hosts' = 'http://10.10.22.174:9200',\n" +" 'index' = 'users',\n" +" 'username' = 'elastic',\n" +" 'password' = 'VaHcSC3mOFfovLWTqW6E'\n" +")";// 简单的聚合处理String transformSQL = "INSERT INTO users_sink_es SELECT * FROM users";tableEnv.executeSql(sourceDDL);tableEnv.executeSql(sinkDDL);TableResult result = tableEnv.executeSql(transformSQL);result.print();env.execute("mysql-to-es");}
请求es用户索引发现并无数据:
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:0,“timed_out”:false,“_shards”:{“total”:3,“successful”:3,“skipped”:0,“failed”:0},“hits”:{“total”:{“value”:0,“relation”:“eq”},“max_score”:null,“hits”:[]}}
操作mysql数据库新增多条数据
5 senfel 2023-08-30 15:02:28 2023-08-30 15:02:36
6 sebfel2 2023-08-30 15:02:43 2023-08-30 15:02:47
再次获取es用户索引查看数据
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:67,“timed_out”:false,“_shards”:{“total”:3,“successful”:3,“skipped”:0,“failed”:0},“hits”:{“total”:{“value”:2,“relation”:“eq”},“max_score”:1.0,“hits”:[{“_index”:“users”,“_type”:“_doc”,“_id”:“5”,“_score”:1.0,“_source”:{“id”:5,“name”:“senfel”,“birthday”:“2023-08-30 15:02:28”,“ts”:“2023-08-30 15:02:36”}},{“_index”:“users”,“_type”:“_doc”,“_id”:“6”,“_score”:1.0,“_source”:{“id”:6,“name”:“sebfel2”,“birthday”:“2023-08-30 15:02:43”,“ts”:“2023-08-30 15:02:47”}}]}}
由上测试结果可知本地运行无异常。
集群运行
项目树:
1、创建集群运行代码逻辑
/*** FlinkMysqlToEs* @author senfel* @version 1.0* @date 2023/8/22 14:56*/
public class FlinkMysqlToEs {public static void main(String[] args) throws Exception {EnvironmentSettings fsSettings = EnvironmentSettings.newInstance()//.useBlinkPlanner().inStreamingMode().build();StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env,fsSettings);tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);// 数据源表String sourceDDL ="CREATE TABLE users (\n" +" id BIGINT PRIMARY KEY NOT ENFORCED ,\n" +" name STRING,\n" +" birthday TIMESTAMP(3),\n" +" ts TIMESTAMP(3)\n" +") WITH (\n" +" 'connector' = 'mysql-cdc',\n" +" 'hostname' = '10.10.10.202',\n" +" 'port' = '6456',\n" +" 'username' = 'root',\n" +" 'password' = 'MyNewPass2021',\n" +" 'server-time-zone' = 'Asia/Shanghai',\n" +" 'database-name' = 'cdc',\n" +" 'table-name' = 'users'\n" +" )";// 输出目标表String sinkDDL ="CREATE TABLE users_sink_es\n" +"(\n" +" id BIGINT PRIMARY KEY NOT ENFORCED,\n" +" name STRING,\n" +" birthday TIMESTAMP(3),\n" +" ts TIMESTAMP(3)\n" +") \n" +"WITH (\n" +" 'connector' = 'elasticsearch-7',\n" +" 'hosts' = 'http://10.10.22.174:9200',\n" +" 'index' = 'users',\n" +" 'username' = 'elastic',\n" +" 'password' = 'VaHcSC3mOFfovLWTqW6E'\n" +")";// 简单的聚合处理String transformSQL = "INSERT INTO users_sink_es SELECT * FROM users";tableEnv.executeSql(sourceDDL);tableEnv.executeSql(sinkDDL);TableResult result = tableEnv.executeSql(transformSQL);result.print();env.execute("mysql-to-es");}
}
2、集群运行需要将Flink程序打包,不同于普通的jar包,这里必须采用shade
<build><finalName>flink-demo</finalName><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>3.2.4</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><createDependencyReducedPom>false</createDependencyReducedPom><artifactSet><excludes><exclude>com.google.code.findbugs:jsr305</exclude><exclude>org.slf4j:*</exclude><exclude>log4j:*</exclude></excludes></artifactSet><filters><filter><artifact>*:*</artifact><excludes><exclude>module-info.class</exclude><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformerimplementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"><resource>META-INF/spring.handlers</resource><resource>reference.conf</resource></transformer><transformerimplementation="org.springframework.boot.maven.PropertiesMergingResourceTransformer"><resource>META-INF/spring.factories</resource></transformer><transformerimplementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"><resource>META-INF/spring.schemas</resource></transformer><transformerimplementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer" /><transformerimplementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.example.flinkdemo.FlinkMysqlToEs</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins>
</build>
将项目打包将包传入集群启动
1、项目打包
mvn package -Dmaven.test.skip=true
2、手动上传到服务器拷贝如集群内部运行:
/opt/flink/bin# ./flink run …/flink-demo.jar
3、测试操作mysql数据库
删除id =6只剩下id=5的用户
5 senfel000 2023-08-30 15:02:28 2023-08-30 15:02:36
4、查询es用户索引
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:931,“timed_out”:false,“_shards”:{“total”:3,“successful”:3,“skipped”:0,“failed”:0},“hits”:{“total”:{“value”:1,“relation”:“eq”},“max_score”:1.0,“hits”:[{“_index”:“users”,“_type”:“_doc”,“_id”:“5”,“_score”:1.0,“_source”:{“id”:5,“name”:“senfel”,“birthday”:“2023-08-30 15:02:28”,“ts”:“2023-08-30 15:02:36”}}]}}[
如上所示es中只剩下了id==5的数据;
经测试手动部署到集群环境成功。
远程将包部署到flink集群
1、新增controller触发接口
/*** remote runTask* @author senfel* @date 2023/8/30 16:57 * @return org.apache.flink.api.common.JobID*/
@GetMapping("/runTask")
public JobID runTask() {try {// 集群信息Configuration configuration = new Configuration();configuration.setString(JobManagerOptions.ADDRESS, "10.10.22.91");configuration.setInteger(JobManagerOptions.PORT, 6123);configuration.setInteger(RestOptions.PORT, 8081);RestClusterClient<StandaloneClusterId> client = new RestClusterClient<>(configuration, StandaloneClusterId.getInstance());//jar包存放路径,也可以直接调用hdfs中的jarFile jarFile = new File("input/flink-demo.jar");SavepointRestoreSettings savepointRestoreSettings = SavepointRestoreSettings.none();//构建提交任务参数PackagedProgram program = PackagedProgram.newBuilder().setConfiguration(configuration).setEntryPointClassName("com.example.flinkdemo.FlinkMysqlToEs").setJarFile(jarFile).setSavepointRestoreSettings(savepointRestoreSettings).build();//创建任务JobGraph jobGraph = PackagedProgramUtils.createJobGraph(program, configuration, 1, false);//提交任务CompletableFuture<JobID> result = client.submitJob(jobGraph);return result.get();} catch (Exception e) {e.printStackTrace();return null;}
}
2、启动Springboot项目
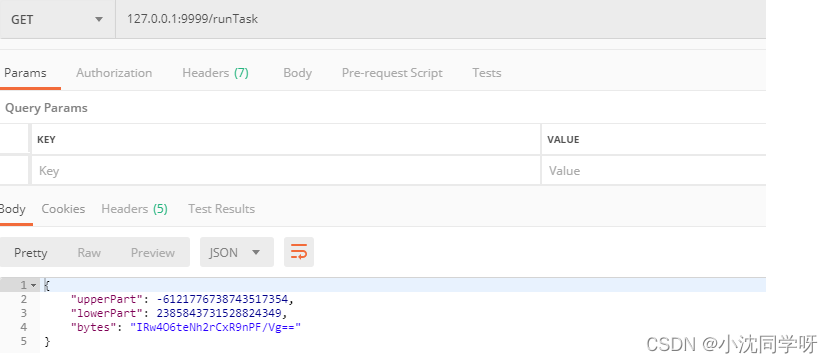
3、postman请求
4、查看Fink集群控制台
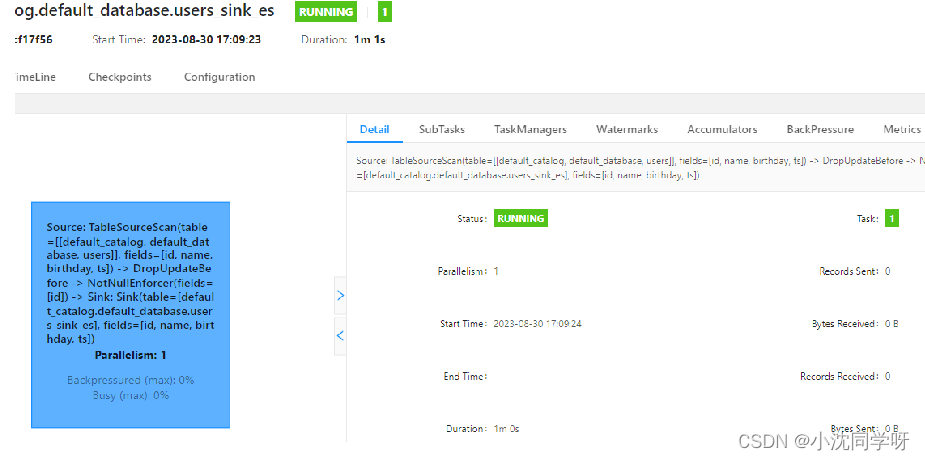
由上图所示已将远程部署完成。
5、测试操作mysql数据库
5 senfel000 2023-08-30 15:02:28 2023-08-30 15:02:36
7 eeeee 2023-08-30 17:12:00 2023-08-30 17:12:04
8 33333 2023-08-30 17:12:08 2023-08-30 17:12:11
6、查询es用户索引
[root@bluejingyu-1 ~]# curl -X GET “http://10.10.22.174:9200/users/_search” -u elastic:VaHcSC3mOFfovLWTqW6E -H ‘Content-Type: application/json’
{“took”:766,“timed_out”:false,“_shards”:{“total”:3,“successful”:3,“skipped”:0,“failed”:0},“hits”:{“total”:{“value”:3,“relation”:“eq”},“max_score”:1.0,“hits”:[{“_index”:“users”,“_type”:“_doc”,“_id”:“5”,“_score”:1.0,“_source”:{“id”:5,“name”:“senfel000”,“birthday”:“2023-08-30 15:02:28”,“ts”:“2023-08-30 15:02:36”}},{“_index”:“users”,“_type”:“_doc”,“_id”:“7”,“_score”:1.0,“_source”:{“id”:7,“name”:“eeeee”,“birthday”:“2023-08-30 17:12:00”,“ts”:“2023-08-30 17:12:04”}},{“_index”:“users”,“_type”:“_doc”,“_id”:“8”,“_score”:1.0,“_source”:{“id”:8,“name”:“33333”,“birthday”:“2023-08-30 17:12:08”,“ts”:“2023-08-30 17:12:11”}}]}}
如上所以es中新增了两条数据;
经测试远程发布Flink Task完成。
写在最后
大数据Flink CDC同步Mysql数据到ElasticSearch搭建与测试运行较为简单,对于基础的学习测试环境独立集群目前只支持单个任务部署,如果需要多个任务或者运用于生产可以采用Yarn与Job分离模式进行部署。
相关文章:
实战:大数据Flink CDC同步Mysql数据到ElasticSearch
文章目录 前言知识积累CDC简介CDC的种类常见的CDC方案比较 Springboot接入Flink CDC环境准备项目搭建 本地运行集群运行将项目打包将包传入集群启动远程将包部署到flink集群 写在最后 前言 前面的博文我们分享了大数据分布式流处理计算框架Flink和其基础环境的搭建,…...

B-Tree 索引和 Hash 索引的对比
分析&回答 B-Tree 索引的特点 B-tree 索引可以用于使用 , >, >, <, < 或者 BETWEEN 运算符的列比较。如果 LIKE 的参数是一个没有以通配符起始的常量字符串的话也可以使用这种索引。 有时,即使有索引可以使用,MySQL 也不使用任何索引。…...

入门Python编程:了解计算机语言、Python介绍和开发环境搭建
文章目录 Python入门什么是计算机语言1. 机器语言2. 符号语言(汇编)3. 高级语言 编译型语言和解释型语言1. 编译型语言2. 解释型语言 Python的介绍Python开发环境搭建Python的交互界面 python学习专栏python基础知识(0基础入门)py…...

深度解析Redisson框架的分布式锁运行原理与高级知识点
推荐阅读 项目实战:AI文本 OCR识别最佳实践 AI Gamma一键生成PPT工具直达链接 玩转cloud Studio 在线编码神器 玩转 GPU AI绘画、AI讲话、翻译,GPU点亮AI想象空间 资源分享 史上最全文档AI绘画stablediffusion资料分享 AI绘画关于SD,MJ,GPT,SDXL百科全书 AI绘画 stable…...

C#扩展方法
参数列表中this的这种用法是在.NET 3.0之后新增的一种特性---扩展方法。通过这个属性可以让程序员在现有的类型上添加扩展方法(无需创建新的派生类型、重新编译或者以其他方式修改原始类型)。 扩展方法是一种特殊的静态方法,虽然是静态方法&a…...

uniapp 高度铺满全屏
问题:在有uni-tabbar的情况下,页面铺满剩下的部分 <template><view :style"{height:screenHeightpx}" class"page"></view> </template> <script>export default {data() {return {screenHeight: &q…...

UG\NX二次开发 判断向量在指定的公差内是否为零,判断是否是零向量 UF_VEC3_is_zero
文章作者:里海 来源网站:王牌飞行员_里海_里海NX二次开发3000例,里海BlockUI专栏,C\C++-CSDN博客 简介: UG\NX二次开发 判断向量在指定的公差内是否为零,判断是否是零向量 UF_VEC3_is_zero 效果: 代码: #include "me.hpp"void ufusr(char* param, int* retco…...

2023年MySQL实战核心技术第一篇
目录 四 . 基础架构:一条SQl查询语句是如何执行的? 4.1 MySQL逻辑架构图: 4.2 MySQL的Server层和存储引擎层 4.2.1 连接器 4.2.1.1 解释 4.2.1.2 MySQL 异常重启 解决方案: 4.2.1.2.1. 定期断开长连接: 4.2.1.2.2. 初始…...

hivesql执行过程
语法解析 SemanticAnalyzer SemanticAnalyzer是Hive中的语义分析器,负责检查Hive SQL程序的语义是否正确。SemanticAnalyzer会对Hive SQL程序进行以下检查: 检查过程 语法检查 SemanticAnalyzer会检查Hive SQL程序的语法是否正确,包括关…...

C语言学习:8、深入数据类型
数据超过类型规定的大小怎么办 C语言中,如果需要用的整数大于int类型的最大值了怎么办? 我们知道int能表示的最大数是2147483647,最小的数是-2147483648,为什么? 因为字32位系统中,寄存器是32位的&#…...
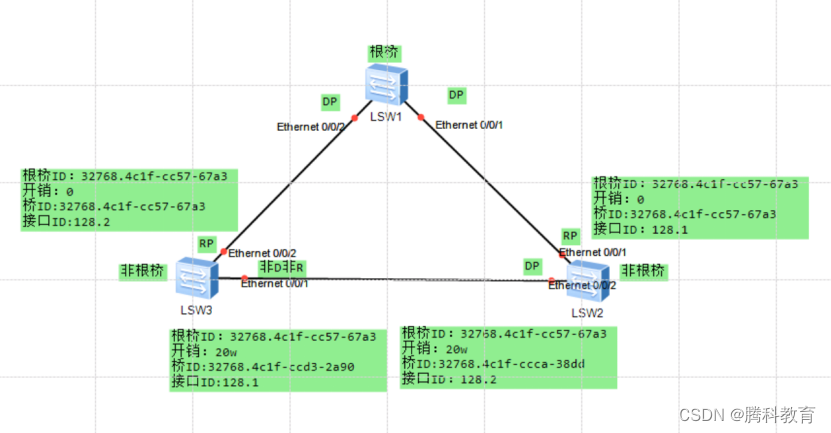
生成树协议 STP(spanning-tree protocol)
一、STP作用 1、消除环路:通过阻断冗余链路来消除网络中可能存在的环路。 2、链路备份:当活动路径发生故障时,激活备份链路,及时恢复网络连通性。 二、STP选举机制 1、目的:找到阻塞的端口 2、STP交换机的角色&am…...

【LeetCode】312.戳气球
题目 有 n 个气球,编号为0 到 n - 1,每个气球上都标有一个数字,这些数字存在数组 nums 中。 现在要求你戳破所有的气球。戳破第 i 个气球,你可以获得 nums[i - 1] * nums[i] * nums[i 1] 枚硬币。 这里的 i - 1 和 i 1 代表和…...

商业数据分析概论
🐳 我正在和鲸社区参加“商业数据分析训练营活动” https://www.heywhale.com/home/competition/6487de6649463ee38dbaf58b ,以下是我的学习笔记: 学习主题:波士顿房价数据快速查看 日期:2023.9.4 关键概念/知识点&…...

Golang GUI框架
Golang GUI框架fyne fyne简介第一个fyne应用fyne应用程序和运行循环fyne更新GUI内容fyne窗口处理fyne解决中文乱码问题fyne应用打包fyne画布和画布对象fyne容器和布局fyne绘制和动画fyne盒子布局fyne网格grid布局fyne网格包裹布局fyne边框布局fyne表单布局fyne中心布局fyne ma…...

LeetCode刷题笔记【24】:贪心算法专题-2(买卖股票的最佳时机II、跳跃游戏、跳跃游戏II)
文章目录 前置知识122.买卖股票的最佳时机II题目描述贪心-直观写法贪心-优化代码更简洁 55. 跳跃游戏题目描述贪心-借助ability数组贪心-只用int far记录最远距离 45.跳跃游戏II题目描述回溯算法贪心算法 总结 前置知识 参考前文 参考文章: LeetCode刷题笔记【23】…...

游戏出现卡顿有哪些因素
一、服务器CPU内存占用过大会导致卡顿,升级CPU内存或者优化自身程序占用都可以解决。 二、带宽跑满导致卡,可以升级带宽解决。 二、平常不卡,有大型的活动的时候会卡,这方面主要是服务器性能方面不够导致的,性能常说…...

学习Bootstrap 5的第八天
目录 加载器 彩色加载器 实例 闪烁加载器 实例 加载器大小 实例 加载器按钮 实例 分页 分页的基本结构 实例 活动状态 实例 禁用状态 实例 分页大小 实例 分页对齐 实例 面包屑(Breadcrumbs) 实例 加载器 彩色加载器 在 Bootstr…...

vue中自定义指令
什么是指令 在Vue.js中,指令是一种特殊的 token,用于在模板中以声明式方式将响应式数据绑定到 DOM 元素上,从而实现与 DOM 元素的交互和操作。指令以 “v-” 前缀开始,后跟指令的名称,例如 v-model、v-bind 和 v-on。…...
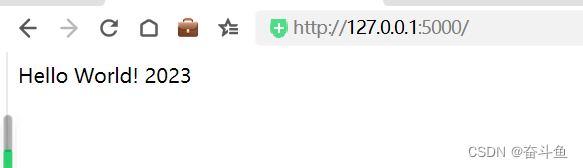
Python:安装Flask web框架hello world
安装easy_install pip install distribute 安装pip easy_install pip 安装 virtualenv pip install virtualenv 激活Flask pip install Flask 创建web页面demo.py from flask import Flask app Flask(__name__)app.route(/) def hello_world():return Hello World! 2023if _…...

小程序点击复制功能制作
在wxml文件中添加一个按钮或需要点击的元素,并绑定点击事件监听器2 <button bindtap"copyText">点击复制</button> 2 在对应的js文件中定义点击事件处理函数,并在函数中调用小程序的API进行复制操作, copyText(e){co…...

从‘尺子刻度’到‘信号保真’:用Python仿真带你直观理解ADC的INL、DNL和SNDR到底在说什么
从‘尺子刻度’到‘信号保真’:用Python仿真带你直观理解ADC的INL、DNL和SNDR到底在说什么 在数字信号处理的世界里,模数转换器(ADC)扮演着将连续模拟信号转换为离散数字信号的关键角色。但对于许多软件开发者或跨领域学习者来说,ADC的性能参…...
)
保姆级教程:为Ultralytics YOLOv8 v8.0+ 添加mAP75和mAP90输出(附完整代码与验证方法)
深度优化YOLOv8评估体系:实战添加mAP75与mAP90指标全指南 当目标检测模型的mAP50达到80%以上时,研究者常陷入性能提升的瓶颈期。此时,引入mAP75和mAP90等更严格的评估指标,能有效区分"优秀"与"卓越"模型的边界…...

Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程
Smithbox终极指南:如何免费创建魂系游戏MOD的完整教程 【免费下载链接】Smithbox Smithbox is a modding tool for Elden Ring, Armored Core VI, Sekiro, Dark Souls 3, Dark Souls 2, Dark Souls, Bloodborne and Demons Souls. 项目地址: https://gitcode.com/…...

终极指南:如何安全高效地使用APKMirror下载安卓应用
终极指南:如何安全高效地使用APKMirror下载安卓应用 【免费下载链接】APKMirror 项目地址: https://gitcode.com/gh_mirrors/ap/APKMirror APKMirror是一款专注于安卓应用安全下载与管理的开源工具,为你提供官方应用商店之外的可靠替代方案。通过…...

TPS65131模块实战:单电源生成正负双电压的工程指南
1. 项目概述与核心需求解析在模拟电路、音频设备乃至一些复古的数字逻辑电路里,正负双电源轨是一个绕不开的话题。无论是给运算放大器供电,为LCD屏幕提供偏置电压,还是驱动某些老式合成器模块,你常常需要同时拥有一个正电压和一个…...

完全掌握Adobe软件激活:5个实用技巧深度解析
完全掌握Adobe软件激活:5个实用技巧深度解析 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP 你是否曾经为Adobe Creative Cloud的订阅费用感到困扰&…...

macOS微信防撤回终极指南:3步安装WeChatIntercept插件
macOS微信防撤回终极指南:3步安装WeChatIntercept插件 【免费下载链接】WeChatIntercept 微信防撤回插件,一键安装,仅MAC可用,支持v3.7.0微信 项目地址: https://gitcode.com/gh_mirrors/we/WeChatIntercept 还在为微信消息…...

Hello Robot 发布 Stretch 4 移动操作机器人,推动具身智能迈向家庭实用化
近日,机器人公司 Hello Robot 正式推出了其新一代产品——Stretch 4 移动操作机器人。作为 Stretch 3 的全面升级迭代,全新的 Hello Robot 具身智能平台 在移动灵活性、环境感知、运行性能与续航能力上实现了显著突破,并将设计重心明确转向…...

MA730/MT6835/MT6825/MT6709磁编码器SPI通信实战:从寄存器配置到角度解析
1. 磁编码器SPI通信基础与选型指南 磁编码器作为现代电机控制和机器人系统中的核心传感器,其精度和响应速度直接影响整个系统的性能。MA730、MT6835、MT6825和MT6709这几款磁编码器在工业界应用广泛,它们都采用SPI接口进行通信,但在具体实现上…...

构建智能工单协同系统:Agent技术驱动研发效能提升
1. 项目概述:一个面向开发者的智能工单与任务协同系统最近在梳理团队内部的工作流时,我一直在思考一个问题:如何让代码仓库(比如 GitHub、GitLab)里的 Issues、Pull Requests 这些“待办事项”,不再只是静态…...