从零实现深度学习框架:Seq2Seq从理论到实战【实战篇】
来源:投稿 作者:175
编辑:学姐
往期内容:
从零实现深度学习框架1:RNN从理论到实战(理论篇)
从零实现深度学习框架2:RNN从理论到实战(实战篇)
从零实现深度学习框架3:再探多层双向RNN的实现
从零实现深度学习框架:Seq2Seq从理论到实战【理论篇】
从零实现深度学习框架:Seq2Seq从理论到实战【实战篇】(本篇)
引言
本着“凡我不能创造的,我就不能理解”的思想,本系列文章会基于纯Python以及NumPy从零创建自己的深度学习框架,该框架类似PyTorch能实现自动求导。
要深入理解深度学习,从零开始创建的经验非常重要,从自己可以理解的角度出发,尽量不使用外部完备的框架前提下,实现我们想要的模型。本系列文章的宗旨就是通过这样的过程,让大家切实掌握深度学习底层实现,而不是仅做一个调包侠。
在上篇文章中了解seq2seq的理论知识,作为实战,本文为完成机器翻译任务来实现seq2seq模型来。
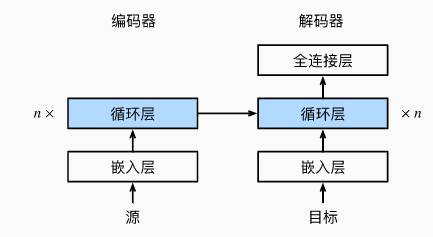
编码器-解码器架构

正如我们前面所讨论的,编码器-解码器架构可以处理输入和输出都是可变长度的序列。编码器接受变成序列作为输入,并将其转换为定长的编码向量。解码器将定长的编码向量映射成变长的序列。
编码器
class Encoder(nn.Module):def __init__(self, **kwargs):super(Encoder, self).__init__(**kwargs)def forward(self, X) -> Tensor:raise NotImplementedError我们定义一个编码器基类,编码器的具体实现可以是RNN、CNN或Transformer等。
这里我们基于RNN实现编码器。
class RNNEncoder(Encoder):'''用RNN实现编码器'''def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):super(RNNEncoder, self).__init__(**kwargs)# 嵌入层 获取输入序列中每个单词的嵌入向量self.embedding = nn.Embedding(vocab_size, embed_size)# 基于GRU实现self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)def forward(self, X) -> Tensor:'''Args:X: 形状 (batch_size, num_steps)Returns:'''X = self.embedding(X) # X 的形状 (batch_size, num_steps, embed_size)X = X.permute((1, 0, 2)) # (num_steps, batch_size, embed_size)output, state = self.rnn(X)return output, state
下面我们实例化上述编码器进行测试。并给定一个小批量的输入序列,批大小为4,时间步长度为7。
encoder = RNNEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
X = Tensor.zeros((4, 7), dtype=numpy.int32)
output, state = encoder(X)
print(output.shape)
(7, 4, 16)
在完成所有时间步之后,最后一层的隐藏状态输出是一个向量,其形状为(时间步长,批大小,隐藏单元数)。
解码器
在解码器的接口中,增加一个init_state函数,用于从编码器的输出中提取编码后的状态。
class Decoder(nn.Module):def __init__(self, **kwargs):super(Decoder, self).__init__(**kwargs)def init_state(self, enc_outputs):raise NotImplementedErrordef forward(self, X, state) -> Tuple[Tensor, Tensor]:raise NotImplementedError
基于RNN实现的解码器如下:
class RNNDecoder(Decoder):def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=.0, **kwargs):super(RNNDecoder, self).__init__(**kwargs)self.embedding = nn.Embedding(vocab_size, embed_size)# embed_size + num_hiddens 为了处理拼接后的维度,见forward函数中的注释self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, batch_first=False, dropout=dropout)# 将隐状态转换为词典大小维度self.dense = nn.Linear(num_hiddens, vocab_size)def init_state(self, enc_outputs):return enc_outputs[1] # 得到编码器输出中的statedef forward(self, X, state) -> Tuple[Tensor, Tensor]:X = self.embedding(X).permute((1, 0, 2)) # (num_steps, batch_size, embed_size)# 将最顶层的上下文向量广播成与X相同的时间步,其他维度上只复制1次(保持不变)# 形状 (num_layers, batch_size, num_hiddens ) => (num_steps, batch_size, num_hiddens)context = state[-1].repeat((X.shape[0], 1, 1))# 为了每个解码时间步都能看到上下文,拼接context与X# (num_steps, batch_size, embed_size) + (num_steps, batch_size, num_hiddens)# => (num_steps, batch_size, embed_size + num_hiddens)concat_context = F.cat((X, context), 2)output, state = self.rnn(concat_context, state)output = self.dense(output).permute((1, 0, 2)) # (batch_size, num_steps, vocab_size)return output, state
为了在解码器的每个时间步都能看到上下文信息,上下文向量与解码器的输入进行了拼接。
下面,我们用与前面提到的编码器中相同的超参数来实例化解码器。 如我们所见,解码器的输出形状变为(批大小,时间步长,词表大小), 其中最后一个维度存储预测的单词概率分布。
decoder = RNNDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
print(output.shape, state.shape)
(4, 7, 10) (2, 4, 16)
合并编码器和解码器
class EncoderDecoder(nn.Module):'''合并编码器和解码器'''def __init__(self, encoder, decoder, **kwargs):super(EncoderDecoder, self).__init__(**kwargs)self.encoder = encoderself.decoder = decoderdef forward(self, enc_X, dec_X) -> Tensor:enc_outputs = self.encoder(enc_X)dec_state = self.decoder.init_state(enc_outputs)return self.decoder(dec_X, dec_state)
合并编码器和解码器很简单,只要传入实例化好的编码器和解码器即可。在forward中从编码器的输出中抽取上下文向量,与解码器的输入同时传入解码器。
数据集与预处理
本小节介绍一下如何处理机器翻译的数据集。为了能更好的看到效果,这里采用中英翻译数据集。
数据集下载:https://download.csdn.net/download/yjw123456/86247212
我们先来看一下数据是长什么样的:
anyone can do that. 任何人都可以做到。
How about another piece of cake? 要不要再來一塊蛋糕?
She married him. 她嫁给了他。
I don't like learning irregular verbs. 我不喜欢学习不规则动词。
It's a whole new ball game for me. 這對我來說是個全新的球類遊戲。
He's sleeping like a baby. 他正睡着,像个婴儿一样。
He can play both tennis and baseball. 他既会打网球,又会打棒球。
We should cancel the hike. 我們應該取消這次遠足。
He is good at dealing with children. 他擅長應付小孩子。
观察数据集,我们需要进行预处理。包括分词,这里对中文语句以字为单位进行切分。
加载数据
首先来加载数据:
def read_nmt(file_path='../data/en-cn/train_mini.txt'):with open(file_path, 'r', encoding='utf-8') as f:return f.read()def cht_to_chs(sent):# pip install hanziconv# 繁体转换为简体sent = HanziConv.toSimplified(sent)sent.encode("utf-8")return sent
同时由于中文是繁体,所以这里进行一个简繁转换。
raw_text = cht_to_chs(read_nmt())
print(raw_text[:74])
Anyone can do that. 任何人都可以做到。
How about another piece of cake? 要不要再来一块蛋糕?
预处理
看起来不错,下面我们来实现预处理。 例如,我们用空格代替不间断空格(non-breaking space), 使用小写字母替换大写字母,并在单词和标点符号之间插入空格。
def process_nmt(text):"""预处理“英文-中文”数据集"""def no_space(char, prev_char):return char in set(',.!?') and prev_char != ' '# 使用空格替换不间断空格,并全部转换为小写text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower()# 在单词和标点符号之间插入空格out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else charfor i, char in enumerate(text)]return ''.join(out)
同时也对上面得到的原始数据进行测试:
text = process_nmt(raw_text)
print(text[:76])
anyone can do that . 任何人都可以做到。
how about another piece of cake ? 要不要再来一块蛋糕?
注意到,这里只是对英文中的空白符和符号进行了处理,并没有处理中文的。因为中文可以直接按字拆分,这在Python中也很好实现。
词元化
下面实现分词代码:
def tokenize_nmt(text, num_examples=None):"""词元化“英文-中文”数据数据集"""source, target = [], []for i, line in enumerate(text.split('\n')):if num_examples and i > num_examples:breakparts = line.split('\t')if len(parts) == 2:source.append(parts[0].split(' ')) # 英文按空格切分target.append([char for char in parts[1]]) # 中文按字切分return source, target
在上面代码运行结果的基础上进行分词,为了简单,这里指定样本数为6:
from pprint import pprint
source, target = tokenize_nmt(text, 6)
pprint(source)
pprint(target)
[['anyone', 'can', 'do', 'that', '.'],['how', 'about', 'another', 'piece', 'of', 'cake', '?'],['she', 'married', 'him', '.'],['i', "don't", 'like', 'learning', 'irregular', 'verbs', '.'],["it's", 'a', 'whole', 'new', 'ball', 'game', 'for', 'me', '.'],["he's", 'sleeping', 'like', 'a', 'baby', '.'],['he', 'can', 'play', 'both', 'tennis', 'and', 'baseball', '.']]
[['任', '何', '人', '都', '可', '以', '做', '到', '。'],['要', '不', '要', '再', '来', '一', '块', '蛋', '糕', '?'],['她', '嫁', '给', '了', '他', '。'],['我', '不', '喜', '欢', '学', '习', '不', '规', '则', '动', '词', '。'],['这', '对', '我', '来', '说', '是', '个', '全', '新', '的', '球', '类', '游', '戏', '。'],['他', '正', '睡', '着', ',', '像', '个', '婴', '儿', '一', '样', '。'],['他', '既', '会', '打', '网', '球', ',', '又', '会', '打', '棒', '球', '。']]构建词表
由于机器翻译数据集由语言对组成,因此我们需要分别为源语言和目标语言构建两个词表。
src_vocab = Vocabulary.build(source, min_freq=min_freq, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])
print(len(src_vocab))
print(src_vocab.token(0))
print(src_vocab.token(1))
42
<unk>
<pad>
我们直接调用之前实现好的词表类构建即可。这里分别输出了ID为0和1的单词。
截断与填充
语言模型中的序列样本有一个固定的长度,该固定的长度就是时间步数。而在机器翻译中,每个样本都是由源和目标组成的序列对,其中每个文本序列可能具有不同的长度。
为了提高计算效率,我们需要通过截断(truncation)和填充(padding)方式实现一次只处理一个小批量的文本序列,并且每个小批量中的序列都应该具有相同的长度num_steps。那么当某个文本序列的长度小于num_steps时,我们将在其末尾添加填充符<pad>,直到达到num_steps;反之,如果某个文本序列的长度超过num_steps,我们则需要截断它,只取前num_step个单词。
这样,每个文本序列将具有相同的长度,以便以相同形状的小批量进行加载。
下面定义截断或填充函数:
def truncate_pad(line, max_len, padding_token):"""截断或填充文本序列"""if len(line) > max_len:return line[:max_len] # 截断return line + [padding_token] * (max_len - len(line)) # 填充
print(truncate_pad(src_vocab[source[0]], 10, src_vocab[PAD_TOKEN]))[4, 5, 6, 7, 8, 1, 1, 1, 1, 1]
我们知道该语句为:['anyone', 'can', 'do', 'that', '.'],它的长度为5,后面填充了5个填充符。
批量化
现在我们定义一个函数,可以将文本序列转换成小批量数据集用于训练。 我们将特定的“”单词添加到所有序列的末尾, 用于表示序列的结束。 当模型通过一个单词接一个单词地生成序列进行预测时, 生成的“”单词说明完成了序列输出工作。
def build_array_nmt(lines, vocab, max_len=None):if not max_len:max_len = max(len(x) for x in lines)"""将机器翻译的文本序列转换成小批量"""lines = [vocab[l] for l in lines]lines = [l + [vocab[EOS_TOKEN]] for l in lines]return np.array([truncate_pad(l, max_len, vocab[PAD_TOKEN]) for l in lines])
然后我们设定序列最大长度为10,构建这6个序列样本批量化的结果:
src_array = build_array_nmt(source, src_vocab, 10)
print(src_array)
[[ 4 5 6 7 8 3 1 1 1 1][ 9 10 11 12 13 14 15 3 1 1][16 17 18 8 3 1 1 1 1 1][19 20 21 22 23 24 8 3 1 1][25 26 27 28 29 30 31 32 8 3][33 34 21 26 35 8 3 1 1 1][36 5 37 38 39 40 41 8 3 1]]
定义机器翻译数据集
class NMTDataset(Dataset):def __init__(self, data):self.data = np.array(data)def __len__(self):return len(self.data)def __getitem__(self, i):return self.data[i]@staticmethoddef collate_fn(examples):src = [Tensor(ex[0]) for ex in examples]tgt = [Tensor(ex[1]) for ex in examples]# 这里只是转换为Tensor向量src = pad_sequence(src)tgt = pad_sequence(tgt)return src, tgt
该数据集同时保存了源于目标样本数据。
加载数据集
下面定义一个函数来返回数据加载器和源语言以及目标语言词表。
def load_dataset_nmt(data_path, batch_size=32, min_freq=1, max_len=20):# 读取原始文本raw_text = read_nmt(data_path)# 处理英文符号text = process_nmt(raw_text)# 中英文分词source, target = tokenize_nmt(text)# 构建源和目标词表src_vocab = Vocabulary.build(source, min_freq=min_freq, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])tgt_vocab = Vocabulary.build(target, min_freq=min_freq, reserved_tokens=[PAD_TOKEN, BOS_TOKEN, EOS_TOKEN])print(f'Source vocabulary size:{len(src_vocab)}, Target vocabulary size: {len(tgt_vocab)}')# 转换成批数据src_array = build_array_nmt(source, src_vocab, max_len)tgt_array = build_array_nmt(target, tgt_vocab, max_len)# 构建数据集dataset = NMTDataset([(src, tgt) for src, tgt in zip(src_array, tgt_array)])# 数据加载器data_loader = DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.collate_fn, shuffle=True)# 返回加载器和两个词表return data_loader, src_vocab, tgt_vocab
train_dataset, src_vocab, tgt_vocab = load_dataset_nmt('../data/en-cn/train_mini.txt')
for X, Y in train_dataset:print('X:', X.shape)print('Y:', Y.shape)break
Source vocabulary size: 1476, Target vocabulary size: 1445
X: (32, 20)
Y: (32, 20)
至此,数据集处理好了,我们可以喂给模型进行训练了。但在此之前,还需要先定义训练用的损失函数。
损失函数
编码器和解码器架构已经实现好了,接下来可以开始训练。但在训练之前需要先定义好损失函数。在每个时间步,解码器预测了输出单词的概率分布。类似于语言模型,可以用softmax来获得分布,并通过交叉熵损失函数来进行优化。
但由于批次内不同样本的长度不同,我们添加了填充单词到短序列中,这样不同长度的序列可以通过相同形状的小批量加载。但是我们应该将填充单词的预测排除到损失函数的计算之外。
class MaskedSoftmaxCELoss(CrossEntropyLoss):"""带遮蔽的softmax交叉熵损失函数"""# pred的形状:(batch_size,num_steps,vocab_size)# label的形状:(batch_size,num_steps)# valid_len的形状:(batch_size,)def forward(self, pred, label, padding_value):self.reduction = 'none'unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(pred, label)label_valid = label != padding_value# with no_grad():# num_tokens = label_valid.sum().item()# weighted_loss = (unweighted_loss * label_valid).sum() / float(num_tokens)weighted_loss = (unweighted_loss * label_valid).sum()return weighted_loss
训练

在训练阶段,如上图所示, 特定的序列开始单词(<bos>)和 原始的输出序列(不包括序列结束单词<eos>) 拼接在一起作为解码器的输入。 这被称为强制教学(teacher forcing), 因为原始的输出序列(单词的标签)被送入解码器。 而在推理阶段,通常将来自上一个时间步的预测得到的单词作为解码器的当前输入。
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):"""训练序列到序列模型"""net.to(device)optimizer = SGD(net.parameters(), lr=lr)loss = MaskedSoftmaxCELoss()net.train()animator = Animator(xlabel='epoch', ylabel='loss', xlim=[10, num_epochs])for epoch in tqdm(range(num_epochs)):timer = Timer()metric = Accumulator(2) # 训练损失总和,单词数量for batch in data_iter:optimizer.zero_grad()X, Y = [x.to(device) for x in batch]bos = Tensor([tgt_vocab[BOS_TOKEN]] * Y.shape[0], device=device).reshape((-1, 1))dec_input = F.cat([bos, Y[:, :-1]], 1) # 强制教学Y_hat, _ = net(X, dec_input)Y = Y.view(-1)output_dim = Y_hat.shape[-1]Y_hat = Y_hat.view(-1, output_dim)l = loss(Y_hat, Y, tgt_vocab[PAD_TOKEN])l.sum().backward()num_tokens = (Y != 0).sum()optimizer.step()with no_grad():metric.add(l.sum().item(), num_tokens.item())if (epoch + 1) % 10 == 0:animator.add(epoch + 1, (metric[0] / metric[1],))print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} 'f'tokens/sec on {str(device)}')print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} 'f'tokens/sec on {str(device)}')
下面,就可以执行训练操作了:
# 参数定义
embed_size = 64
num_hiddens = 128
num_layers = 2
dropout = 0.1batch_size = 128
num_steps = 20lr = 0.0005
num_epochs = 1000
min_freq = 1
device = cuda.get_device("cuda:0" if cuda.is_available() else "cpu")# 加载数据集
train_iter, src_vocab, tgt_vocab = load_dataset_nmt('../data/en-cn/train_mini.txt', batch_size=batch_size,min_freq=min_freq, max_len=num_steps)
# 构建编码器
encoder = RNNEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
# 构建解码器
decoder = RNNDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
# 编码器-解码器
net = EncoderDecoder(encoder, decoder)
# 训练
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
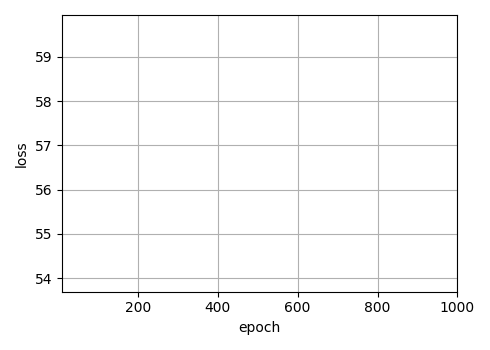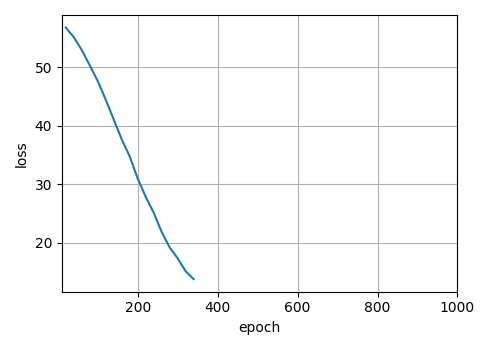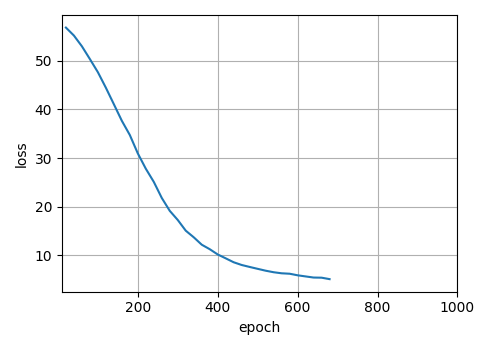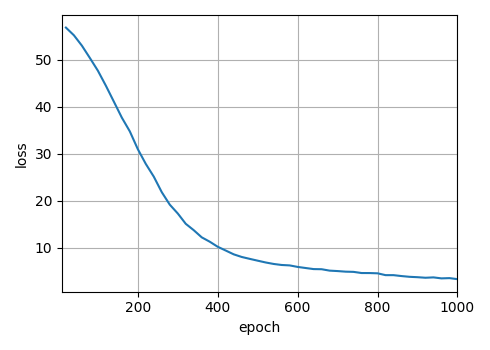
经过漫长的训练,最终损失降到了个位数,但是损失看不出来模型的好坏。在机器翻译中,常用的评价指标是BLEU得分。下篇文章就来学习下这个评价指标。
完整代码
https://github.com/nlp-greyfoss/metagrad
参考
Dive Into Deep Learning Speech and Language Processing
关注下方卡片《学姐带你玩AI》🚀🚀🚀
后台回复“500”
180+条AI必读论文讲解视频&代码数据集免费领
码字不易,欢迎大家点赞评论收藏!
相关文章:
从零实现深度学习框架:Seq2Seq从理论到实战【实战篇】
来源:投稿 作者:175 编辑:学姐 往期内容: 从零实现深度学习框架1:RNN从理论到实战(理论篇) 从零实现深度学习框架2:RNN从理论到实战(实战篇) 从零实现深度…...

【数据结构入门】-链表之单链表(1)
个人主页:平行线也会相交 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 平行线也会相交 原创 收录于专栏【数据结构初阶(C实现)】 文章标题回顾链表链表的概念及结构各种节点打印链表尾插创建节点尾删头插头删查找在pos…...
Docker竟如此简单!
文章目录什么是容器?容器隔离何为“边界”?容器和虚拟机一样吗?基于 Linux Namespace 隔离机制的弊端容器限制何为“限制”?Cgroups 对资源的限制能力缺陷单进程模型容器镜像容器的诞生容器的一致性何为“层(layer&…...
在外包干了几年,感觉自己都快费了
先说一下自己的情况。大专生,18年通过校招进入湖南某软件公司,干了接近2年的点点点,今年年上旬,感觉自己不能够在这样下去了,长时间呆在一个舒适的环境会让一个人堕落!而我已经在一个企业干了五年的功能测试…...
Java实现多线程有几种方式(满分回答)
目录JDK8 创建的线程的两种方式orcle文档解释方式一:继承Thread类方式二:实现Runnable接口同时用两种的情况其他间接创建方式Callable接口线程池JDK8 创建的线程的两种方式 orcle文档解释 orcle文档:https://docs.oracle.com/javase/8/docs…...

实例4:树莓派GPIO控制舵机转动
实例4:树莓派GPIO控制舵机转动 实验目的 通过背景知识学习,了解舵机的外观及基本运动方式。了解四足机器人mini pupper腿部单个舵机的组成结构。通过GPIO对舵机进行转动控制,熟悉PWM。了解mini pupper舵机组的整体调零。 实验要求 使用Py…...

【音视频处理】为什么MP3不是无损音乐?音频参数详解,码率、采样率、音频帧、位深度、声道、编码格式的关系
大家好,欢迎来到停止重构的频道。上期我们讨论了视频的相关概念,本期我们讨论音频的相关概念。包括采样率、码率、单双声道、音频帧、编码格式等概念。这里先抛出一个关于无损音频的问题。为什么48KHz采样率的.mp3不是无损音乐 ,而48KHz采样率…...

Linux 环境变量
Linux 环境变量能帮你提升 Linux shell 体验。很多程序和脚本都通过环境变量来获取系统信息、存储临时数据和配置信息。在 Linux 系统上有很多地方可以设置环境变量,了解去哪里设置相应的环境变量很重要。 认识环境变量 bash shell 用环境变量(environme…...

从功能测试(点点点)到进阶自动化测试,实现薪资翻倍我只用了3个月时间
前言 从事测试工作已3年有余了,今天想聊一下自己刚入门时和现在的今昔对比,虽然现在也没什么成就,只能说笑谈一下自己的测试生涯,各位看官就当是茶余饭后的吐槽吧,另外也想写一写自己的职场感想,希望对刚开…...

aspnetcore 原生 DI 实现基于 key 的服务获取
你可能想通过一个字符串或者其他的类型来获取一个具体的服务实现,那么在 aspnetcore 原生的 MSDI 中,如何实现呢?本文将介绍如何通过自定义工厂来实现。我们现在恰好有基于 Json 和 MessagePack 的两种序列化器有一个接口是这样的publicinter…...
 | 机试题+算法思路+考点+代码解析 【2023】)
华为OD机试 -最大子矩阵和(Python) | 机试题+算法思路+考点+代码解析 【2023】
最大子矩阵和 题目 给定一个二维整数矩阵 要在这个矩阵中 选出一个子矩阵 使得这个子矩阵内所有的数字和尽量大 我们把这个子矩阵成为“和最大子矩阵” 子矩阵的选取原则,是原矩阵中一段相互连续的矩形区域 输入 输入的第一行包含两个整数N,M (1 <= N,M <= 10) 表示…...
)
C2驾照科一学习资料(1)
目录 记1分 记3分 记6分 记9分 记12分 你有不伤别人的教养 却缺少一种不被人伤的气场 若没人护你周全 就请善良中带点锋芒为自己保驾护航 这个世界你若好到毫无保留 对方就会坏到肆无忌惮 记1分 《道路交通安全违法行为记分管理办法》规定,机动车驾驶人有下列…...

4576: 移动数组元素
描述给定一个n个元素的一维数组,将下标从0到p的元素全部平移到数组尾部。输入第一行有两个正整数n和p(2<n<100,0<p<n)。第二行有n个整数,表示数组的各个元素。输出在一行中按顺序输出移动后的各个数组元素…...

字符串中<br>处理
需求: 后端返回的字符串中带有br换行符,前端需要处理行内及行尾的换行符。具体需求可分为以下两个: 若是字符串末尾有换行符,需要去掉。若是字符串内有换行符,有两种需求:①将换行符转换成逗号或其它符号&…...

大数据技术原理与应用介绍
大数据技术原理与应用 概述 大数据不仅仅是数据的“大量化”,而是包含“快速化”、“多样化”和“价值化”等多重属性。 两大核心技术:分布式存储和分布式处理 大数据计算模式 批处理计算流计算图计算查询分析计算 大数据具有数据量大、数据类型繁…...

【Python】序列与列表(列表元素的增删改查,求之,列表推导式、列表的拷贝)
一、序列序列的概念:按照某种顺序排列的数据类型就叫做序列,比如字符串,列表,元组,集合序列的共同点是都有下标,支持index()方法和count(),也支持切片处理(等同于字符串序列的切片处理)l1 [0, …...

update导致死锁
update delete 操作,如果走的索引,对索引和主键索引加行锁 如果没有走索引,锁整张表。 不开启事务,mysql本身也会加锁 一般MYSQL在执行CREATE,ALTER,INSERT等命令时会自动加锁 在对数据进行更新操作时 如果update没用到索引&…...
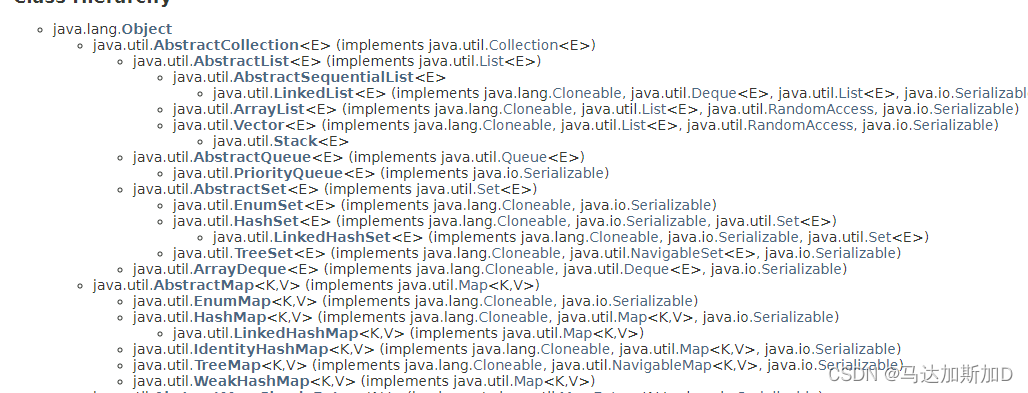
Java 集合 --- 如何遍历Map
Java 集合 --- 如何遍历MapMap的基本操作如何遍历MapType of HashMapMap没有继承Collection接口AbstractMap和AbstractCollection是平级关系 Map的基本操作 package map; import java.util.*; /*** This program demonstrates the use of a map with key type String and val…...
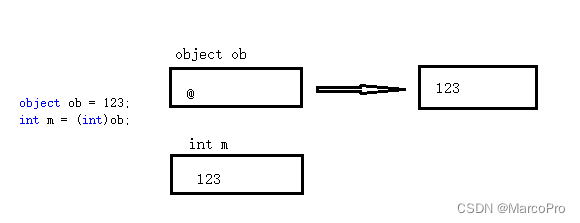
C#从值类型、引用类型到装箱和拆箱
上一篇文章讲了C#的值类型和引用类型,这里再来看看值类型和引用类型最直接的使用场景:装箱和拆箱。 一、基本概念 装箱:值类型转化为引用类型的过程。从托管堆中为新生成的引用类型对象分配内存,再把值类型的实例字段拷贝到托管堆上新对象的…...

Java中的逻辑运算符/移位运算符简单总结
前段时间刷到了力扣关于位运算的题,这里浅浅记录一下! 1. 逻辑位运算 1.1 与 & &:按位与进行二进制计算,规则是同为1则为1,不同为0,具体如下: 0&00, 0&10, 1&00, 1&…...

qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用
qobuz-dl终极实战指南:专业无损音乐下载工具架构解析与高效应用 【免费下载链接】qobuz-dl A complete Lossless and Hi-Res music downloader for Qobuz 项目地址: https://gitcode.com/gh_mirrors/qo/qobuz-dl 在数字音乐时代,追求极致音质的音…...

告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南
告别Windows卡顿!在VMware里给Kubuntu 22.04 LTS分区和安装的保姆级避坑指南你是否已经厌倦了Windows系统越来越慢的启动速度、频繁的后台更新和资源占用?当你的电脑开始频繁卡顿,或许该考虑给系统来一次"减负"了。Kubuntu 22.04 L…...
)
【C++】零基础入门 · 第 4 节:循环结构(while、for、do-while)
上一节我们学习了条件判断,这一节来学习循环结构。循环让程序能够重复执行某段代码,直到满足特定条件为止。C 提供了三种循环语句:while、for 和 do-while。 1. while 循环:先判断后执行 while 循环在每次执行前先检查条件&#x…...

终极AMD Ryzen调试指南:为什么你需要SMUDebugTool这个免费神器?
终极AMD Ryzen调试指南:为什么你需要SMUDebugTool这个免费神器? 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. …...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...

终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧
终极指南:5步掌握Cursor AI Pro完整功能免费解锁技巧 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tria…...

如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南
如何高效使用开源电路仿真工具:CircuitJS1桌面版新手快速入门指南 【免费下载链接】circuitjs1 Standalone (offline) version of the Circuit Simulator with small modifications based on modified NW.js. 项目地址: https://gitcode.com/gh_mirrors/circ/circ…...

VMnet8 的8到底是什么意思?
它的本质是:8 仅仅是一个 内部标识符 (Internal Identifier) 或 数组索引 (Array Index),用于在 VMware 的虚拟化网络栈中唯一标识 NAT 模式 对应的虚拟交换机实例。它没有任何数学、物理或协议层面的特殊含义(如端口号、版本号或二进制位&am…...
)
BGP选路原则--本地优先级(LocPrf)
如果BGP收到相同的路由,首选值PrefVal如果也相同的话,那么就会继续比较下一条原则:本地优先级Local_Pref 一、拓扑图 二、配置BGP路由协议: R1 bgp 100 peer 12.1.1.2 as-number 200 peer 13.1.1.3 as-number 200 R2 bgp 200 peer 4.4.4.4 as-number 200 peer 4.4.4…...

如何快速构建个人数字图书馆:番茄小说下载器终极指南
如何快速构建个人数字图书馆:番茄小说下载器终极指南 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 想要随时随地畅读番茄小说,却受限于网络连接&…...