Yarn资源调度器
文章目录
- 一、Yarn资源调度器
- 1、架构
- 2、Yarn工作机制
- 3、HDFS、YARN、MR关系
- 4、作业提交之HDFS&MapReduce
- 二、Yarn调度器和调度算法
- 1、先进先出调度器(FIFO)
- 2、容量调度器(Capacity Scheduler)
- 3、公平调度器(Fair Scheduler)
- 3.1 调度器原理
- 3.22 资源分配方式
- 三、修改Yarn集群
- 1、Yarn配置
- 2、多队列提交
- 3、向集群中提交任务
一、Yarn资源调度器
Yarn是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台,而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
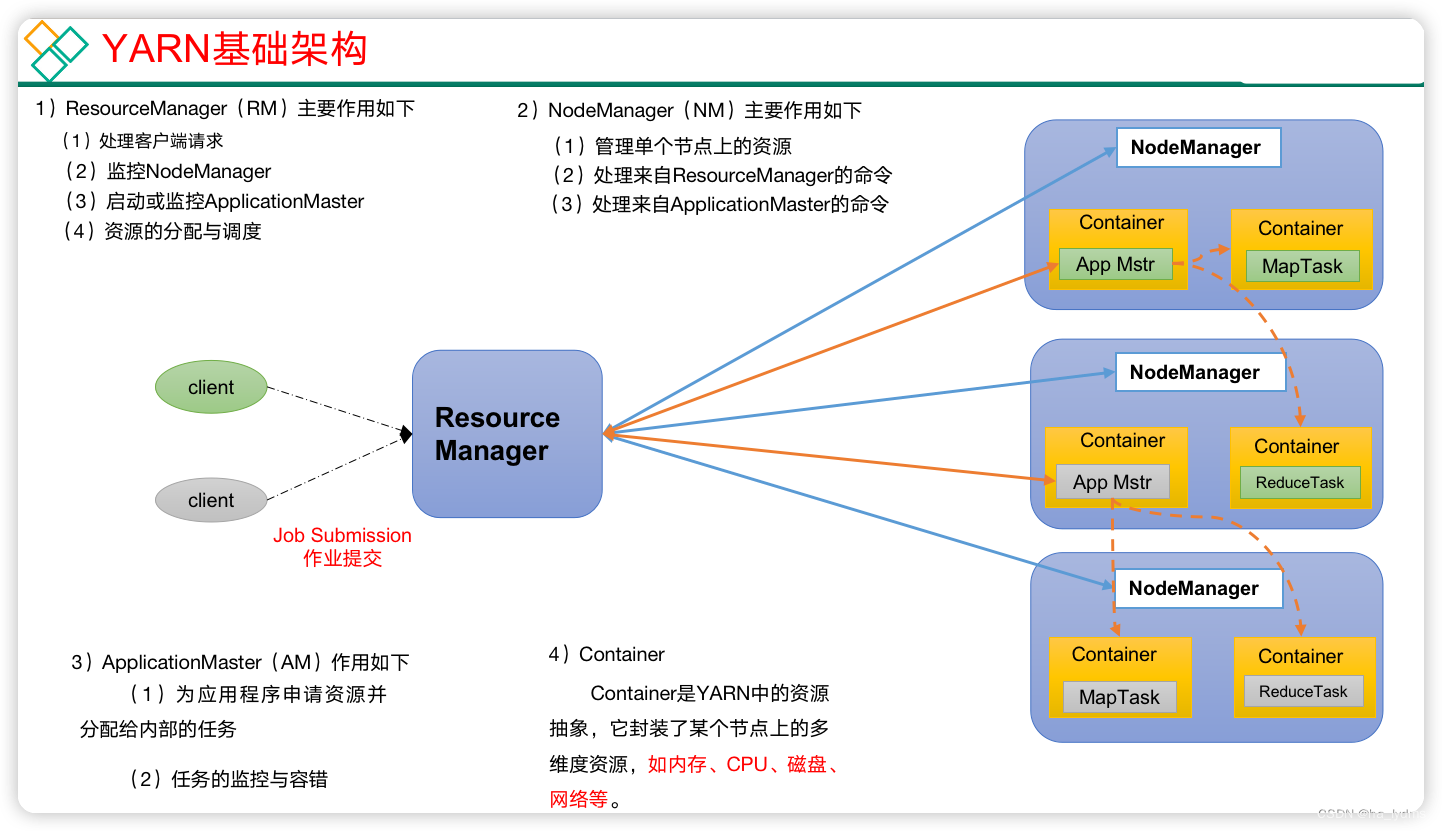
1、架构
YARN主要由ResourceManager、NodeManager、ApplicationMaster和Container等组件构成。
2、Yarn工作机制
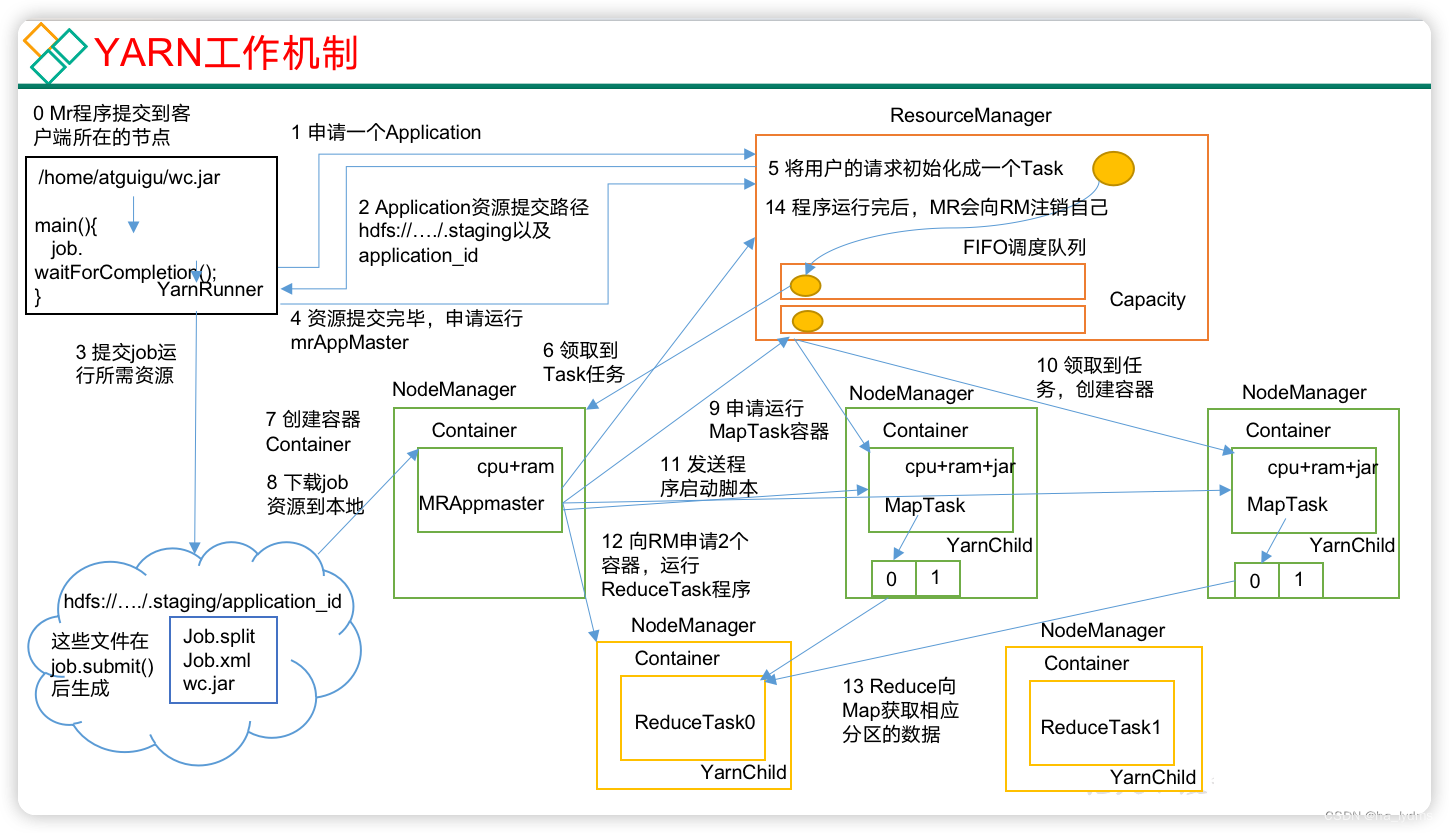
- MR程序提交到客户端所在的节点。
- YarnRunner向ResourceManager申请一个Application。
- RM将该应用程序的资源路径返回给YarnRunner。
- 该程序将运行所需资源提交到HDFS上。
- 程序资源提交完毕后,申请运行mrAppMaster。
- RM将用户的请求初始化成一个Task。
- 其中一个NodeManager领取到Task任务。
- 该NodeManager创建容器Container,并产生MRAppmaster。
- Container从HDFS上拷贝资源到本地。
- MRAppmaster向RM 申请运行MapTask资源。
- RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
- MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
- MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
- ReduceTask向MapTask获取相应分区的数据。程序运行完毕后,MR会向RM申请注销自己。
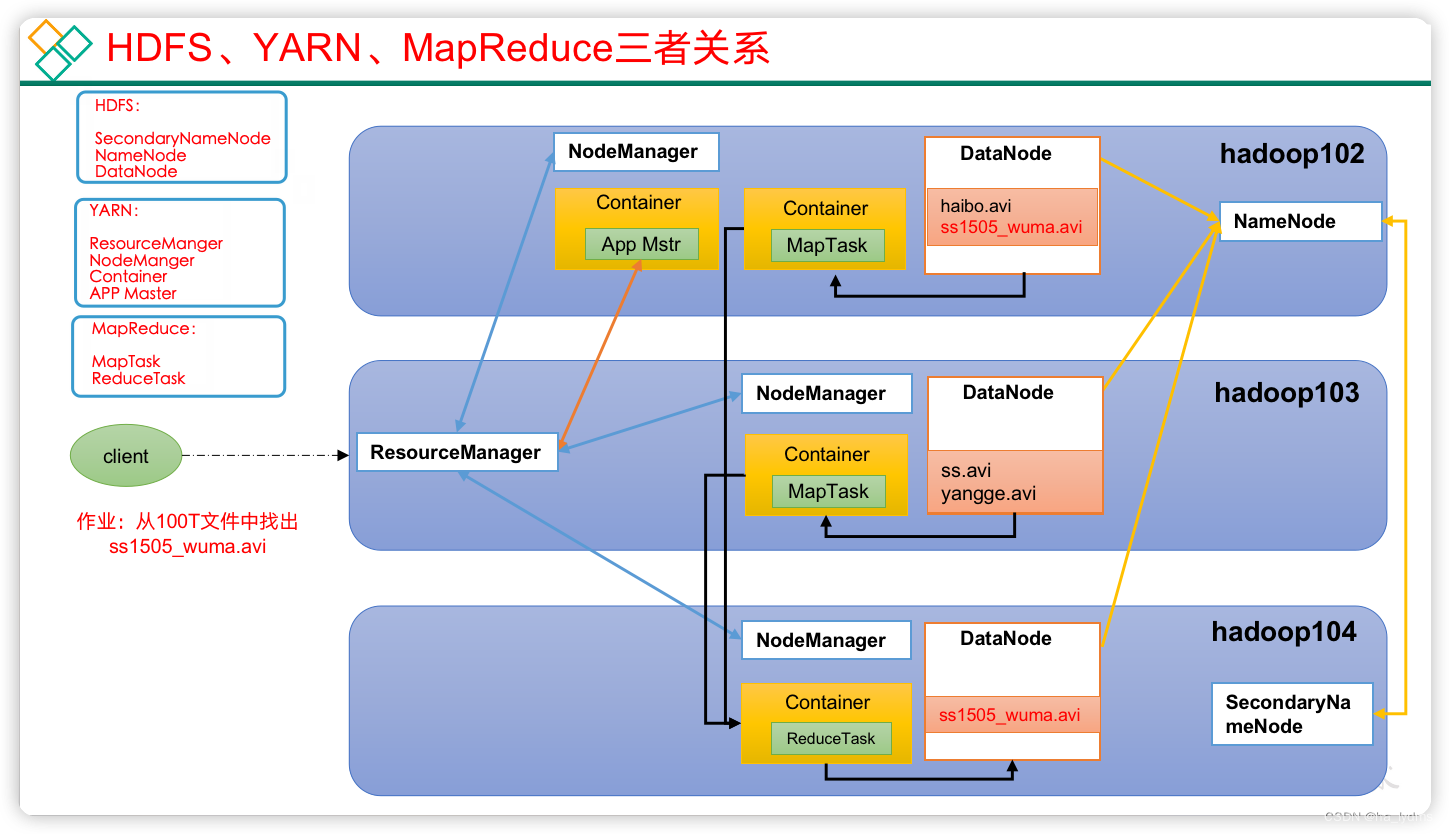
3、HDFS、YARN、MR关系
4、作业提交之HDFS&MapReduce

-
(1)作业提交
- 第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
- 第2步:Client向RM申请一个作业id。
- 第3步:RM给Client返回该job资源的提交路径和作业id。
- 第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
- 第5步:Client提交完资源后,向RM申请运行MrAppMaster。
-
(2)作业初始化
- 第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
- 第7步:某一个空闲的NM领取到该Job。
- 第8步:该NM创建Container,并产生MRAppmaster。
- 第9步:下载Client提交的资源到本地。
-
(3)任务分配
- 第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
- 第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分别领取任务并创建容器。
-
(4)任务运行
- 第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager分别启动MapTask,MapTask对数据分区排序。
- 第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
- 第14步:ReduceTask向MapTask获取相应分区的数据。
- 第15步:程序运行完毕后,MR会向RM申请注销自己。
-
(5)进度和状态更新
- YARN中的任务将其进度和状态(包括counter)返回给应用管理器, 客户端每秒(通过mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用户。
-
(6)作业完成
- 除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查。
二、Yarn调度器和调度算法
目前,Hadoop作业调度器主要有三种:FIFO、容量(Capacity Scheduler)和公平(Fair Scheduler)。
-
Apache Hadoop3.1.3默认的资源调度器是Capacity Scheduler。
-
CDH框架默认调度器是Fair Scheduler。
详见yarn-default.xml文件
<property><description>The class to use as the resource scheduler.</description><name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
1、先进先出调度器(FIFO)
FIFO调度器(First In First Out):单队列,根据提交作业的先后顺序,先来先服务。
- 优点:简单易懂。
- 缺点:不支持多队列,生产环境很少使用。

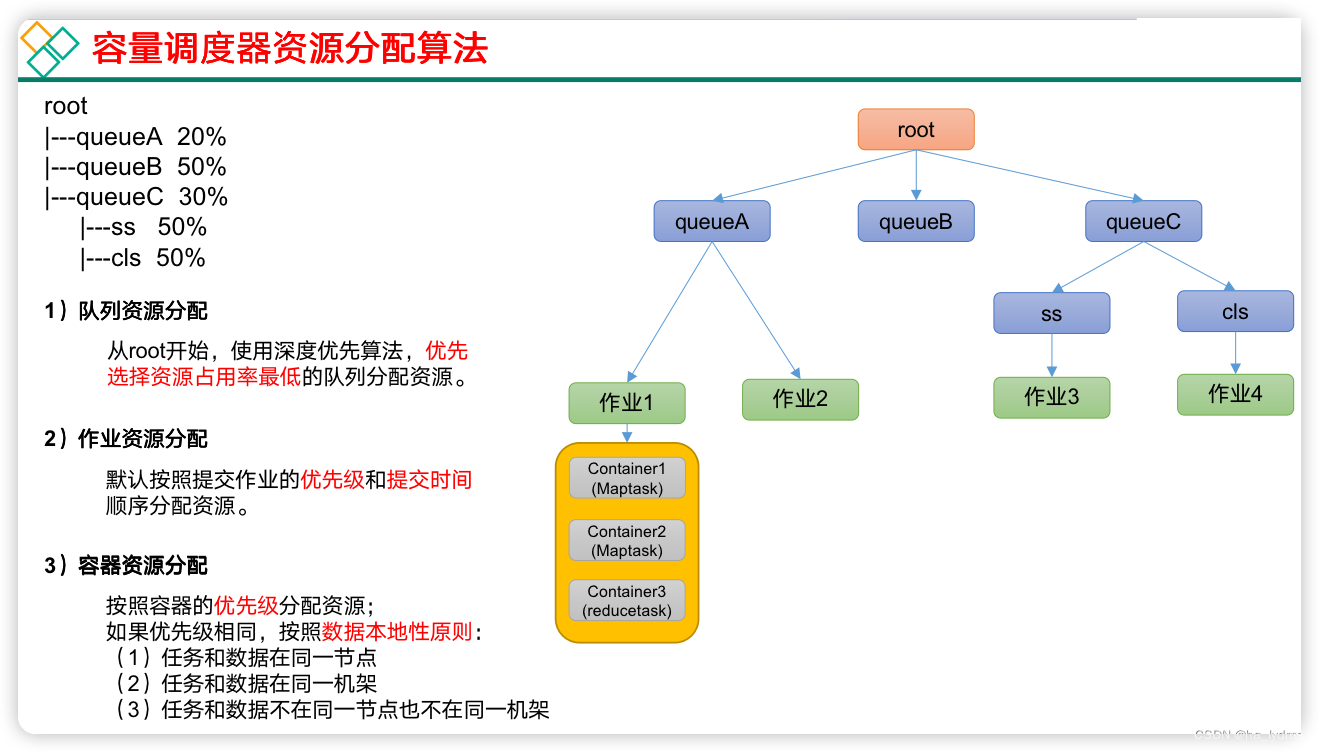
2、容量调度器(Capacity Scheduler)
Capacity Scheduler是Yahoo开发的多用户调度器。

3、公平调度器(Fair Scheduler)
3.1 调度器原理
Fair Schedulere是Facebook开发的多用户调度器。

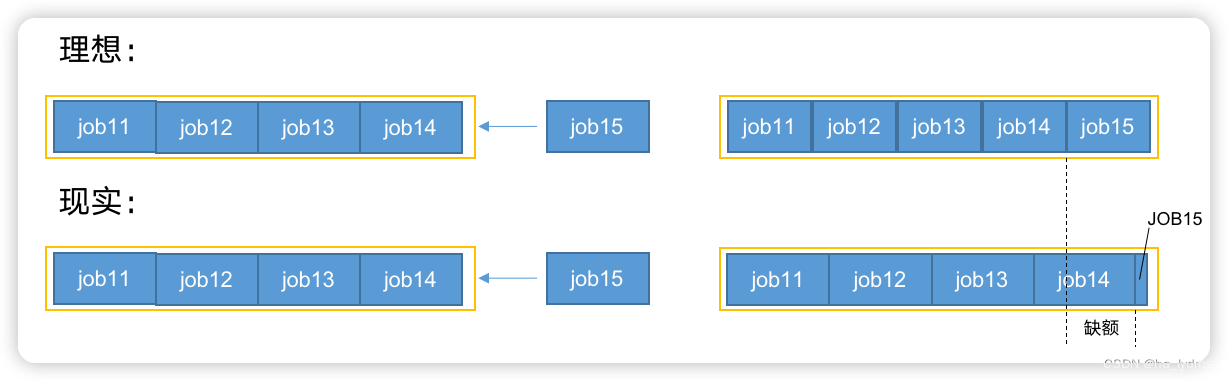
公平调度器—缺额
- 公平调度器设计目标是:在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫“缺额”。
- 调度器会优先为缺额大的作业分配资源
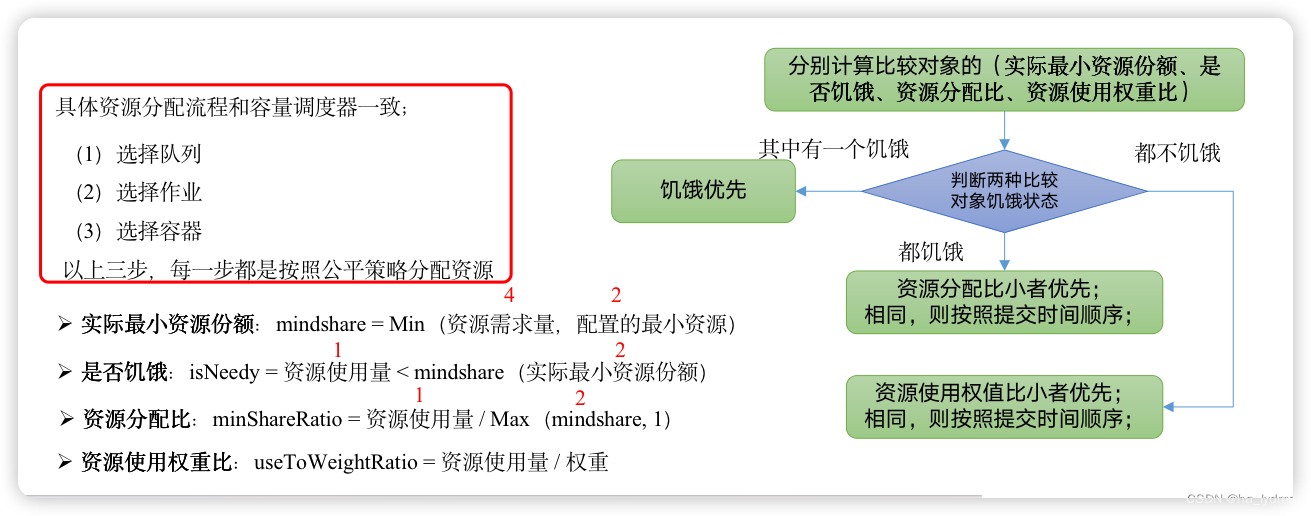
3.22 资源分配方式
有3种资源分配方式:FIFO策略、 Fair 策略、 DRF策略。
(1)、FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,此时公平调度器相当于上面讲过的容量调度器。
(2)、Fair 策略
Fair 策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
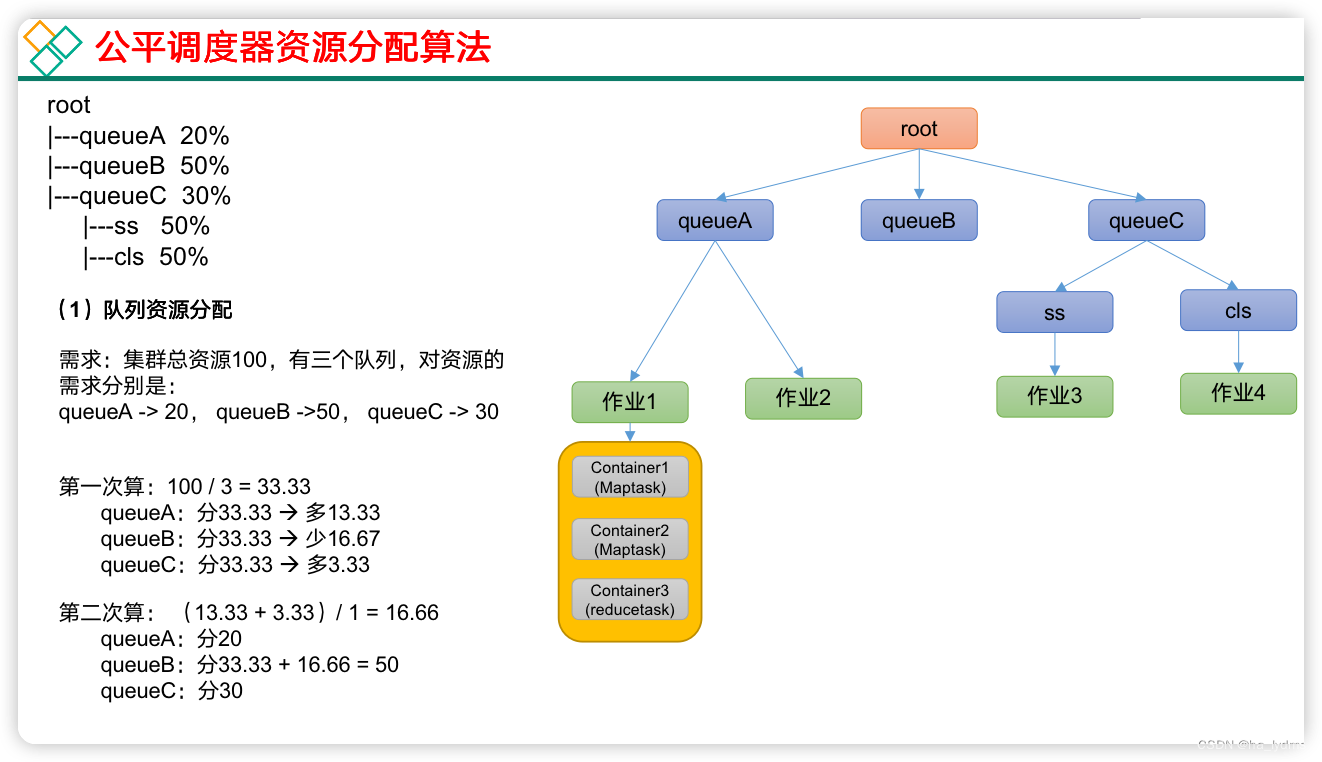
(2)作业资源分配
- 不加权(关注点是Job的个数):
需求:有一条队列总资源12个, 有4个job,对资源的需求分别是:
job1->1, job2->2 , job3->6, job4->5第一次算: 12 / 4 = 3 job1: 分3 --> 多2个 job2: 分3 --> 多1个job3: 分3 --> 差3个job4: 分3 --> 差2个第二次算: 3 / 2 = 1.5 job1: 分1job2: 分2job3: 分3 --> 差3个 --> 分1.5 --> 最终: 4.5 job4: 分3 --> 差2个 --> 分1.5 --> 最终: 4.5第n次算: 一直算到没有空闲资源
- 加权(关注点是Job的权重):
需求:有一条队列总资源16,有4个job
对资源的需求分别是:
job1->4 job2->2 job3->10 job4->4
每个job的权重为:
job1->5 job2->8 job3->1 job4->2第一次算: 16 / (5+8+1+2) = 1job1: 分5 --> 多1job2: 分8 --> 多6job3: 分1 --> 少9job4: 分2 --> 少2 第二次算: 7 / (1+2) = 7/3job1: 分4job2: 分2job3: 分1 --> 分7/3(2.33) -->少6.67job4: 分2 --> 分14/3(4.66) -->多2.66第三次算:2.66/1=2.66 job1: 分4job2: 分2job3: 分3.33 --> 分2.66/1 --> 分6job4: 分4
第n次算: 一直算到没有空闲资源
(3)、DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是Yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU,100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
三、修改Yarn集群
1、Yarn配置
资源配置:
-
从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程。
-
1G / 128m = 8个MapTask;1个ReduceTask;1个mrAppMaster。
-
平均每个节点运行10个 / 3台 ≈ 3个任务(4 3 3)
修改yarn-site.xml配置参数如下
<!-- 选择调度器,默认容量 -->
<property><description>The class to use as the resource scheduler.</description><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property><!-- ResourceManager处理调度器请求的线程数量,默认50;如果提交的任务数大于50,可以增加该值,但是不能超过3台 * 4线程 = 12线程(去除其他应用程序实际不能超过8) -->
<property><description>Number of threads to handle scheduler interface.</description><name>yarn.resourcemanager.scheduler.client.thread-count</name><value>8</value>
</property><!--
是否将虚拟核数当作CPU核数,默认是false,采用物理CPU核数
-->
<property><description>Flag to determine if logical processors(such ashyperthreads) should be counted as cores. Only applicable on Linuxwhen yarn.nodemanager.resource.cpu-vcores is set to -1 andyarn.nodemanager.resource.detect-hardware-capabilities is true.</description><name>yarn.nodemanager.resource.count-logical-processors-as-cores</name><value>false</value>
</property><!-- 是否让yarn自动检测硬件进行配置,默认是false,如果该节点有很多其他应用程序,建议手动配置。如果该节点没有其他应用程序,可以采用自动 -->
<property><description>Enable auto-detection of node capabilities such asmemory and CPU.</description><name>yarn.nodemanager.resource.detect-hardware-capabilities</name><value>false</value>
</property><!--
Core转成Vcore的个数(虚拟核数和物理核数乘数,默认是1.0)
hadoop中的vcore不是真正的core,通常vcore的个数设置为逻辑cpu个数的1~5倍。
-->
<property><description>Multiplier to determine how to convert phyiscal cores to vcores. This value is used if
yarn.nodemanager.resource.cpu-vcores is set to -1(which implies auto-calculate vcores) and
yarn.nodemanager.resource.detect-hardware-capabilities is set to true. The number of vcores will be calculated as number of CPUs * multiplier.</description><name>yarn.nodemanager.resource.pcores-vcores-multiplier</name><value>1.0</value>
</property><!-- NodeManager使用内存数,默认8G,修改为4G内存 -->
<property><description>Amount of physical memory, in MB, that can be allocated for containers. If set to -1 andyarn.nodemanager.resource.detect-hardware-capabilities is true, it isautomatically calculated(in case of Windows and Linux).In other cases, the default is 8192MB.</description><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value>
</property><!-- nodemanager的CPU核数,不按照硬件环境自动设定时默认是8个,修改为4个 -->
<property><description>Number of vcores that can be allocatedfor containers. This is used by the RM scheduler when allocatingresources for containers. This is not used to limit the number ofCPUs used by YARN containers. If it is set to -1 andyarn.nodemanager.resource.detect-hardware-capabilities is true, it isautomatically determined from the hardware in case of Windows and Linux.In other cases, number of vcores is 8 by default.</description><name>yarn.nodemanager.resource.cpu-vcores</name><value>4</value>
</property><!-- 容器最小内存,默认1G -->
<property><description>The minimum allocation for every container request at the RM in MBs. Memory requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have less memory than this value will be shut down by the resource manager.</description><name>yarn.scheduler.minimum-allocation-mb</name><value>1024</value>
</property><!-- 容器最大内存,默认8G,修改为2G -->
<property><description>The maximum allocation for every container request at the RM in MBs. Memory requests higher than this will throw an InvalidResourceRequestException.</description><name>yarn.scheduler.maximum-allocation-mb</name><value>2048</value>
</property><!-- 容器最小CPU核数,默认1个 -->
<property><description>The minimum allocation for every container request at the RM in terms of virtual CPU cores. Requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have fewer virtual cores than this value will be shut down by the resource manager.</description><name>yarn.scheduler.minimum-allocation-vcores</name><value>1</value>
</property><!-- 容器最大CPU核数,默认4个,修改为2个 -->
<property><description>The maximum allocation for every container request at the RM in terms of virtual CPU cores. Requests higher than this will throw anInvalidResourceRequestException.</description><name>yarn.scheduler.maximum-allocation-vcores</name><value>2</value>
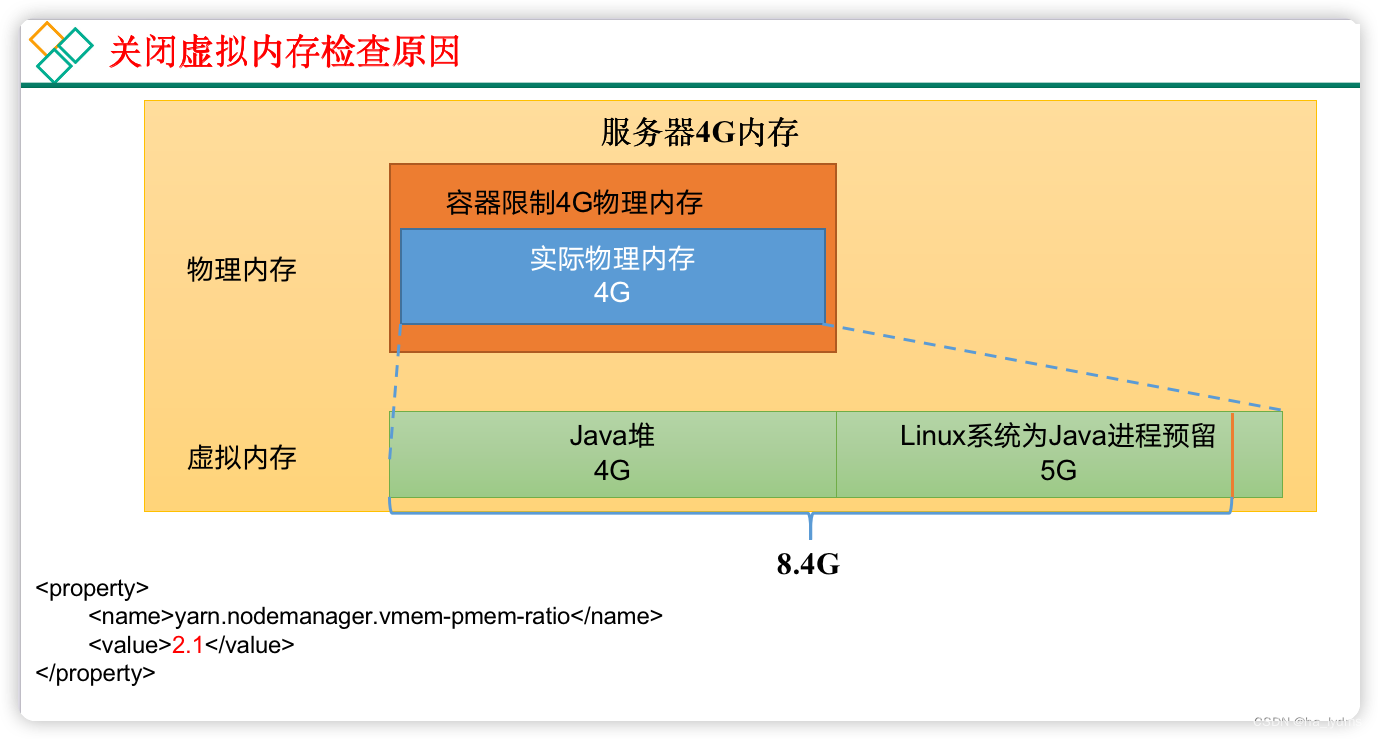
</property><!-- 虚拟内存检查,默认打开,修改为关闭 -->
<property><description>Whether virtual memory limits will be enforced forcontainers.</description><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property><!-- 虚拟内存和物理内存设置比例,默认2.1 -->
<property><description>Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio.</description><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value>
</property>
重启Yarn集群
./sbin/stop-yarn.sh
./sbin/start-yarn.sh
登录页面查看资源修改:http://hadoop102:8088/cluster
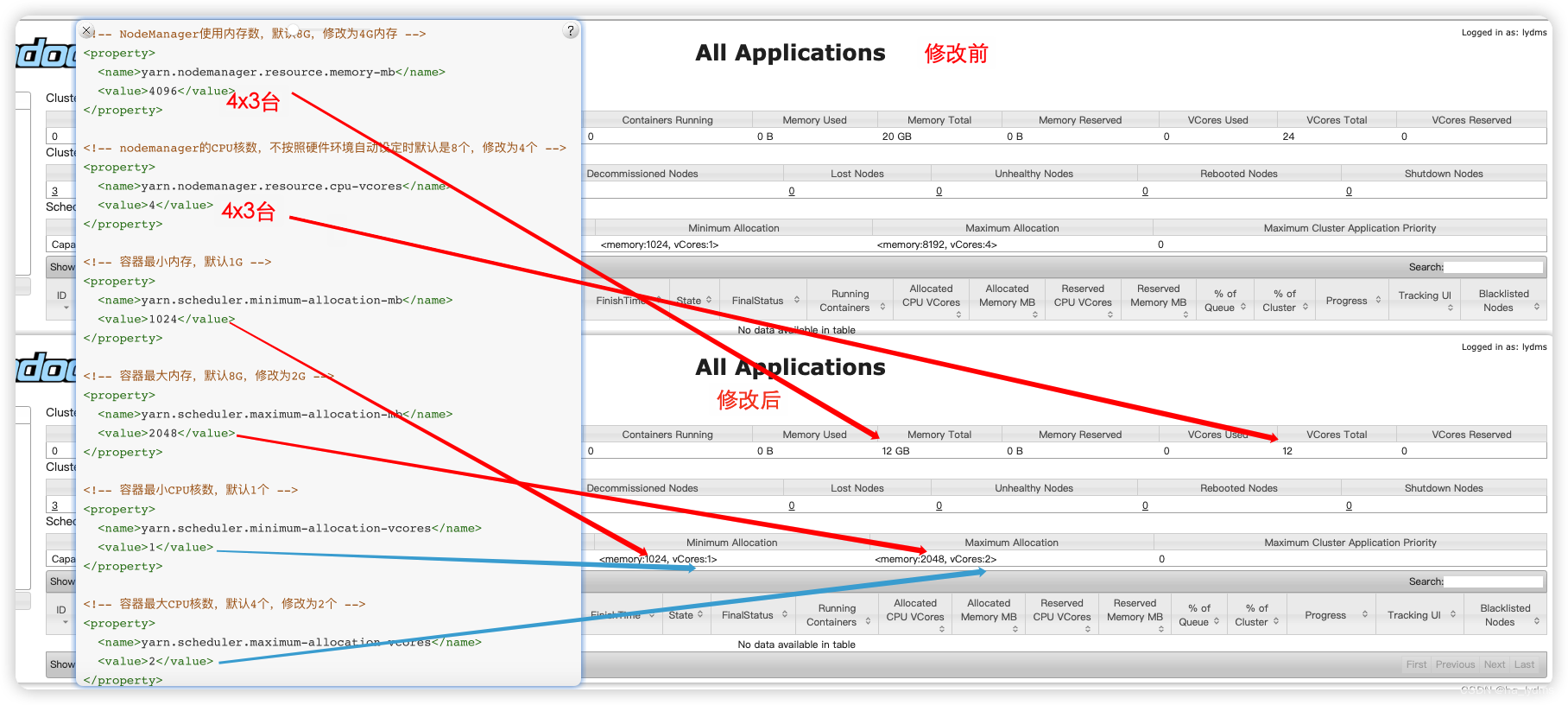
关闭虚拟内存检查
2、多队列提交
配置参数:
default队列:占总内存的40%,最大资源容量占总资源60%。
hive队列:占总内存的60%,最大资源容量占总资源80%。
修改capacity-scheduler.xml配置
<!-- 指定多队列,增加hive队列 -->
<property><name>yarn.scheduler.capacity.root.queues</name><value>default,hive</value><description>The queues at the this level (root is the root queue).</description>
</property><!-- 降低default队列资源额定容量为40%,默认100% -->
<property><name>yarn.scheduler.capacity.root.default.capacity</name><value>40</value>
</property><!-- 降低default队列资源最大容量为60%,默认100% -->
<property><name>yarn.scheduler.capacity.root.default.maximum-capacity</name><value>60</value>
</property>
添加capacity-scheduler.xml配置
<!-- 指定hive队列的资源额定容量 -->
<property><name>yarn.scheduler.capacity.root.hive.capacity</name><value>60</value>
</property><!-- 用户最多可以使用队列多少资源,1表示所有 -->
<property><name>yarn.scheduler.capacity.root.hive.user-limit-factor</name><value>1</value>
</property><!-- 指定hive队列的资源最大容量 -->
<property><name>yarn.scheduler.capacity.root.hive.maximum-capacity</name><value>80</value>
</property><!-- 启动hive队列 -->
<property><name>yarn.scheduler.capacity.root.hive.state</name><value>RUNNING</value>
</property><!-- 哪些用户有权向队列提交作业 -->
<property><name>yarn.scheduler.capacity.root.hive.acl_submit_applications</name><value>*</value>
</property><!-- 哪些用户有权操作队列,管理员权限(查看/杀死) -->
<property><name>yarn.scheduler.capacity.root.hive.acl_administer_queue</name><value>*</value>
</property><!-- 哪些用户有权配置提交任务优先级 -->
<property><name>yarn.scheduler.capacity.root.hive.acl_application_max_priority</name><value>*</value>
</property><!-- 任务的超时时间设置:yarn application -appId appId -updateLifetime Timeout
参考资料:https://blog.cloudera.com/enforcing-application-lifetime-slas-yarn/ --><!-- 如果application指定了超时时间,则提交到该队列的application能够指定的最大超时时间不能超过该值。
-->
<property><name>yarn.scheduler.capacity.root.hive.maximum-application-lifetime</name><value>-1</value>
</property><!-- 如果application没指定超时时间,则用default-application-lifetime作为默认值 -->
<property><name>yarn.scheduler.capacity.root.hive.default-application-lifetime</name><value>-1</value>
</property>
分发修改后配置文件,或者修改ResourceManger所在节点配置
重启Yarn集群或者刷新配置
yarn rmadmin -refreshQueues
登录页面查看队列更新:http://hadoop102:8088/cluster/scheduler
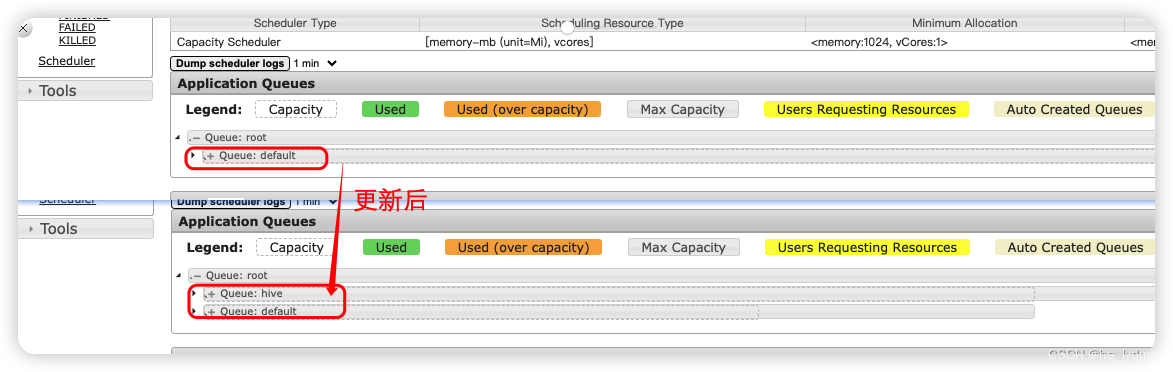
3、向集群中提交任务
package com.example.demo.wordcount;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;public class WCDriver2 {public static void main(String[] args) throws Exception {System.out.println(args[0]);System.out.println(args[1]);//1.创建Job实例Configuration conf = new Configuration();//可以设置参数conf.set("mapreduce.job.queuename", "hive");Job job = Job.getInstance(conf);//2.给Job赋值//2.1关联本程序的jar---如果是本地运行不用设置。如果是在集群上运行(打jar包放在集群上)一定要设置job.setJarByClass(WCDriver2.class);//2.2设置Mapper和Reducer类job.setMapperClass(WCMapper.class);job.setReducerClass(WCReducer.class);//2.3设置Mapper输出的Key,value的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);//2.4设置最终输出的key,value的类型(在这是Reducer输出的key,value的类型)job.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);//2.5设置输入和输出路径FileInputFormat.setInputPaths(job, new Path(args[0]));//注意:输出的目录必须不存在FileOutputFormat.setOutputPath(job, new Path(args[1]));//3.提交Jobboolean b = job.waitForCompletion(true);System.out.println("=======" + b);}
}
pom文件打包方式
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.example</groupId><artifactId>demo</artifactId><version>0.0.1-SNAPSHOT</version><name>demo</name><description>demo</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.12</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>
</project>
登录服务器执行脚本
demo-0.0.1.jar:运行的jar包,服务器所在全路径com.example.demo.wordcount.WCDriver2:全类名运行jar包中的哪个类/input:数据的输入路径(HDFS)/output:数据的输出路径(HDFS)
hadoop jar demo-0.0.1.jar com.example.demo.wordcount.WCDriver2 /input /output

相关文章:
Yarn资源调度器
文章目录 一、Yarn资源调度器1、架构2、Yarn工作机制3、HDFS、YARN、MR关系4、作业提交之HDFS&MapReduce 二、Yarn调度器和调度算法1、先进先出调度器(FIFO)2、容量调度器(Capacity Scheduler)3、公平调度器(Fair …...
android上架备案公钥和md5获取工具
最近很多公司上架遇到了一个问题,就是要提供app的备案证明,现在android上架都需要备案了,但是我们的证书都是通过工具生成的,哪里知道公钥和md5那些东西呢?无论安卓备案还是ios备案都需要提供公钥和md5。 包括ios的备案…...
SpringBoot系列(12):SpringBoot集成log4j2日志配置
最近项目上有使用到log4j2日志模板配置,本文简单总结一下之前的学习笔记,如有纰漏之处,请批评指正。 1. log4j2日志依赖 使用log4j2日志模板时,需要引入相关依赖,下边的两种依赖方式均可。 1.1 使用sl4j依赖时 <…...

HTML事件列表
鼠标事件 属性描述DOMonclick当用户点击某个对象时调用的事件句柄。2oncontextmenu在用户点击鼠标右键打开上下文菜单时触发ondblclick当用户双击某个对象时调用的事件句柄。2onmousedown鼠标按钮被按下。2onmouseenter当鼠标指针移动到元素上时触发。2onmouseleave当鼠标指针…...
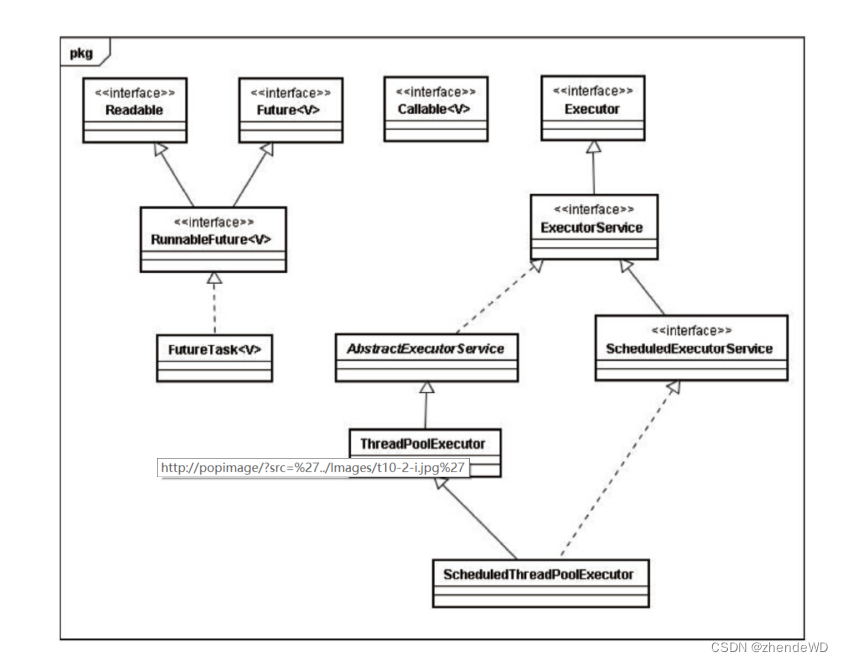
并发-Executor框架笔记
Executor框架 jdk5开始,把工作单元与执行机制分离开来,工作单元包括Runable和Callable,执行机制由Executor框架来提供。 Executor框架简介 Executor框架的两级调度模型 Java线程被一对一映射为本地操作系统线程 java线程启动会创建一个本…...
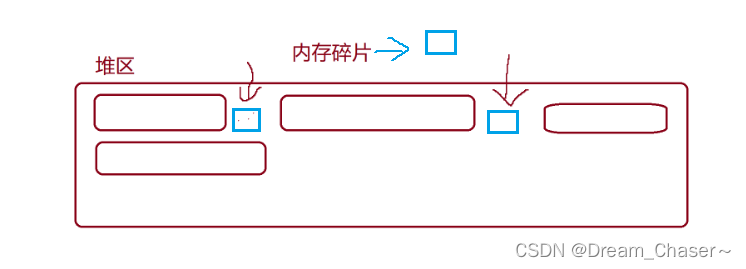
【C进阶】分析 C/C++程序的内存开辟与柔性数组(内有干货)
前言: 本文是对于动态内存管理知识后续的补充,以及加深对其的理解。对于动态内存管理涉及的大部分知识在这篇文章中 ---- 【C进阶】 动态内存管理_Dream_Chaser~的博客-CSDN博客 本文涉及的知识内容主要在两方面: 简单解析C/C程序…...
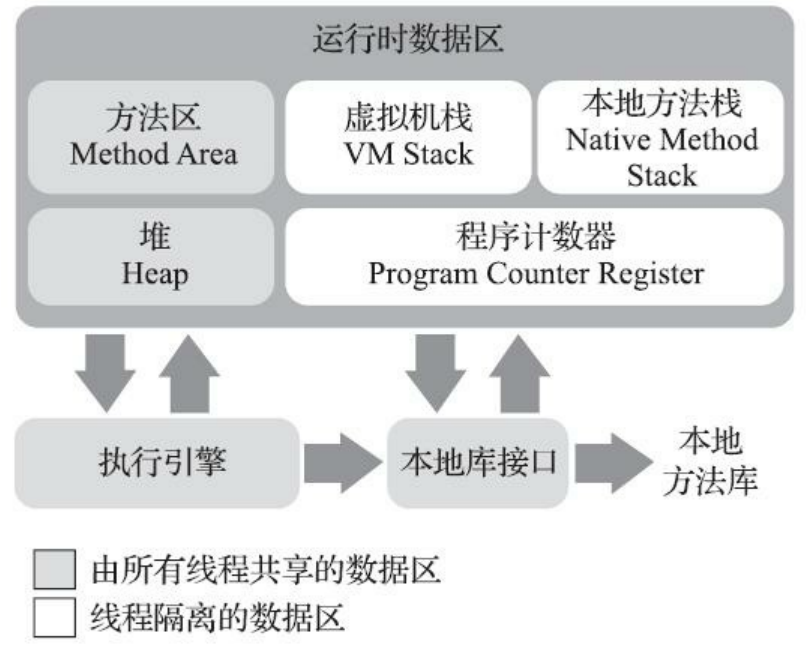
深入理解 JVM 之——字节码指令与执行引擎
更好的阅读体验 \huge{\color{red}{更好的阅读体验}} 更好的阅读体验 类文件结构 Write Once,Run Anywhere 对于 C 语言从程序到运行需要经过编译的过程,只有经历了编译后,我们所编写的代码才能够翻译为机器可以直接运行的二进制代码&#x…...
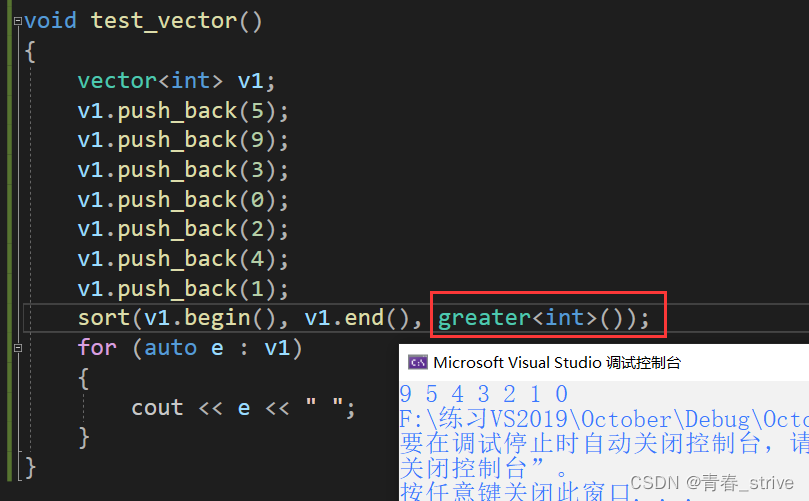
C++:vector
目录 一、关于vector 二、vector的相关函数 三、相关函数的使用 ①构造函数 ②size ③[] 编辑 ④push_back ⑤迭代器iterator ⑥reserve ⑦resize ⑧find ⑨insert ⑩erase ⑪sort 一、关于vector vector比较像数组 观察可知,vector有两个模板参数…...

Android Automotive编译
系统准备 安装系统 准备一台安装Ubuntu系统的机器(windows系统的机器可以通过WSL安装ubuntu系统) 安装docker 本文使用docker进行编译,因此提前安装docker。参考网络链接安装docker并设置为不使用sudo进行docker操作。 参考链接ÿ…...

什么是50ETF期权开户条件,怎么开期权交易权限?
50ETF期权是指上证50ETF期权,标的物是上证50ETF,代码是(510500),期权是一种在上证50ETF基础上进行衍生品交易的金融工具,下文科普什么是50ETF期权开户条件,怎么开期权交易权限?本文来…...

React 从入门到精通——本文来自AI创作助手
React是一个流行的JavaScript库,用于构建用户界面。以下是React入门到精通的步骤: 入门 安装React 你可以在npm上下载React包,也可以使用其他包管理器。首先需要安装node.js,然后使用以下命令安装React: npm insta…...
 模块功能封装汇总(持续更新))
【51单片机实验笔记】前篇(三) 模块功能封装汇总(持续更新)
文章目录 通用函数public.hpublic.c 延时函数delay.hdelay.c LED模块数码管模块smg.hsmg.c LED点阵模块独立按键模块矩阵按键模块外部中断模块定时器模块串口通讯模块ADC模块PWM模块 通用函数 包含常用头文件,宏定义,自定义类型,函数工具等。…...
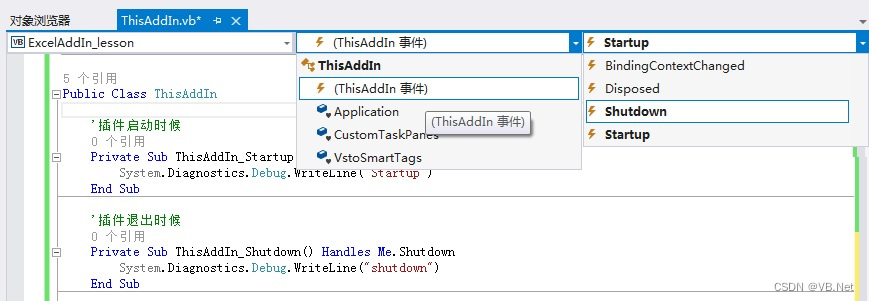
Excel VSTO开发4 -其他事件
版权声明:本文为博主原创文章,转载请在显著位置标明本文出处以及作者网名,未经作者允许不得用于商业目的。 4 其他事件 针对插件的事件主要有Startup、Shutdown这两个事件,在第2节中已经讲解。在开发窗口中,选择对象…...

语音识别数据的采集方法:基本流程数据类型
“人工智能是一种模仿人类功能的产品。数据采集的方法需要针对特定的场景需求。”—–Mark Brayan (澳鹏CEO) 我们一直说,对于一个高质量的人工智能产品离不开高质量的训练数据。对于不同的人工智能我们需要不同的数据对其训练。要采集正确的数据去训练特定的模型才…...

oracle数据库给用户授权DBA权限Oracle查看哪些用户具有DBA权限
oracle数据库给用户授权DBA权限 步骤一:以sysdba身份登录到Oracle数据库 在授予DBA权限之前,我们首先要以sysdba身份登录到Oracle数据库。使用以下命令登录: sqlplus / as sysdba步骤二:创建用户(如有用户跳过&#…...
)
024-从零搭建微服务-系统服务(六)
写在最前 如果这个项目让你有所收获,记得 Star 关注哦,这对我是非常不错的鼓励与支持。 源码地址(后端):https://gitee.com/csps/mingyue 源码地址(前端):https://gitee.com/csps…...
)
Arduino驱动TCS3200传感器(颜色传感器篇)
目录 1、传感器特性 2、硬件原理图 3、控制器和传感器连线图 4、驱动程序 TCS3200颜色传感器是一款全彩的颜色检测器,包括了一块TAOS TCS3200RGB感应芯片和4个白色LED灯,TCS3200能在一定的范围内检测和测量几乎所有的可见光。TCS3200有大量的光检测器,每个都有红绿蓝和清…...
)
基于Matlab实现多个数字水印案例(附上源码+数据集)
数字水印是一种在数字图像或视频中嵌入特定信息的技术,以保护知识产权和防止盗版。在本文中,我们将介绍如何使用Matlab实现数字水印。 文章目录 实现步骤源码数据集下载 实现步骤 首先,我们需要选择一个用于嵌入水印的图像。这可以是原始图像…...
C语言之指针进阶篇(2)
目录 函数指针 函数名和&函数名 函数指针的定义 函数指针的使用 函数指针陷阱 代码1 代码2 注意 函数指针数组定义 函数指针数组的使用 指向函数指针数组的指针 书写 终于军训圆满结束了,首先回顾一下指针进阶篇(1)主要是…...

C++ 进制转化入门知识(1)
一、什么是进制 进制是一种用来表示数值的系统或方法,它是基于一个特定的基数来工作的。在我们常见的几种进制中,有: 1. **二进制(基数 2)**: 二进制只用两个数字:0和1。这是计算机内部使用…...

普遍认为赠送福利越多客户留存越高,编程统计福利投入,客户留存数据过度福利,会造成客户贪婪流失率上升。
“福利投入强度与客户留存的非线性关系分析” 为主题。一、实际应用场景描述(Business Context)在 SaaS、电商、会员制平台、在线教育等商业场景中,赠送福利(优惠券、积分、试用权益、赠品等)被广泛用于:- …...

微信消息自动转发:5分钟实现跨群智能消息同步
微信消息自动转发:5分钟实现跨群智能消息同步 【免费下载链接】wechat-forwarding 在微信群之间转发消息 项目地址: https://gitcode.com/gh_mirrors/we/wechat-forwarding 在微信群管理和团队协作中,你是否经常需要将重要消息手动转发到多个群聊…...

白起、项羽、黄巢杀降时的第三选择
白起、项羽、黄巢,他们都曾站在“杀降”这个决策悬崖上。与其说这是他们个人的暴虐,不如说他们当时都陷入了一个由战争逻辑、资源短缺和恐惧心理共同构筑的绝境。在那个系统里,他们几乎无法做出别的选择。🎲 那场被逼到墙角的困兽…...

在多模型AI客服场景下利用Taotoken实现成本与效果的平衡
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在多模型AI客服场景下利用Taotoken实现成本与效果的平衡 应用场景类,设想一个在线客服系统需要集成对话AI的场景&#…...

基于Ollama与OpenClaw框架,在Ubuntu VPS上部署私有AI助手
1. 项目概述与核心价值最近在折腾一个挺有意思的东西,叫OpenClaw。简单来说,它是一个开源的AI智能体(Agent)框架,能让你自己部署一个功能丰富的AI助手。这玩意儿最吸引我的地方在于,它能和本地的Ollama大语…...

CANdela Studio配置避坑指南:从10服务到Data Type,这些细节别踩雷
CANdela Studio配置避坑指南:从10服务到Data Type,这些细节别踩雷 在汽车电子诊断功能开发中,CANdela Studio作为诊断数据库(CDD)的核心编辑工具,其配置精度直接影响着诊断协议栈的生成质量。许多工程师能够完成基础配置ÿ…...

EDA验证与调试:从学术理论到工业落地的核心挑战与自动化未来
1. 从互联网先驱到EDA专家:Andreas Veneris的跨界之路在半导体设计这个高度专业化的领域,Andreas Veneris的经历显得格外独特。他既是多伦多大学电气与计算机工程及计算机科学系的教授,又是EDA(电子设计自动化)公司Ven…...

芯片设计演进:从摩尔定律到软件驱动与异构集成的工程实践
1. 项目概述:一位芯片老兵的CMOS缩放宣言在半导体这个日新月异的行业里,每隔几年就会听到“摩尔定律已死”的论调。这几乎成了一个周期性出现的“行业寓言”。但如果你在2014年,有机会和吉姆凯勒(Jim Keller)——这位先…...

Cyberpunk 2077存档编辑器:终极免费工具完整使用指南
Cyberpunk 2077存档编辑器:终极免费工具完整使用指南 【免费下载链接】CyberpunkSaveEditor A tool to edit Cyberpunk 2077 sav.dat files 项目地址: https://gitcode.com/gh_mirrors/cy/CyberpunkSaveEditor 你是否想要在《赛博朋克2077》中拥有无限可能&a…...

AI智能体构建实战:从架构设计到工程落地的关键挑战与解决方案
1. 项目概述:揭开AI智能体构建的隐秘面纱 “构建AI智能体”,这听起来像是当下最酷、最前沿的技术话题。无论是科技新闻还是行业论坛,你都能看到无数关于智能体如何自动化工作流、理解复杂指令、甚至自主决策的激动人心的讨论。然而࿰…...