【阿旭机器学习实战】【31】股票价格预测案例--线性回归
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
注:本文模型结果不好,仅做学习参考使用,提供思路。了解数据处理思路,训练模型和预测数值的过程。
目录
- 1. 读取数据
- K线图绘制
- 2.构建回归模型
- 3.绘制预测结果
- 在这里插入图片描述
1. 读取数据
import numpy as np # 数学计算
import pandas as pd # 数据处理
import matplotlib.pyplot as plt
from datetime import datetime as dt
关注公众号:阿旭算法与机器学习,回复:“ML31”即可获取本文数据集、源码与项目文档,欢迎共同学习交流
df = pd.read_csv('./000001.csv')
print(np.shape(df))
df.head()
(611, 14)
| date | open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2019-05-30 | 12.32 | 12.38 | 12.22 | 12.11 | 646284.62 | -0.18 | -1.45 | 12.366 | 12.390 | 12.579 | 747470.29 | 739308.42 | 953969.39 |
| 1 | 2019-05-29 | 12.36 | 12.59 | 12.40 | 12.26 | 666411.50 | -0.09 | -0.72 | 12.380 | 12.453 | 12.673 | 751584.45 | 738170.10 | 973189.95 |
| 2 | 2019-05-28 | 12.31 | 12.55 | 12.49 | 12.26 | 880703.12 | 0.12 | 0.97 | 12.380 | 12.505 | 12.742 | 719548.29 | 781927.80 | 990340.43 |
| 3 | 2019-05-27 | 12.21 | 12.42 | 12.37 | 11.93 | 1048426.00 | 0.02 | 0.16 | 12.394 | 12.505 | 12.824 | 689649.77 | 812117.30 | 1001879.10 |
| 4 | 2019-05-24 | 12.35 | 12.45 | 12.35 | 12.31 | 495526.19 | 0.06 | 0.49 | 12.396 | 12.498 | 12.928 | 637251.61 | 781466.47 | 1046943.98 |
股票数据的特征
- date:日期
- open:开盘价
- high:最高价
- close:收盘价
- low:最低价
- volume:成交量
- price_change:价格变动
- p_change:涨跌幅
- ma5:5日均价
- ma10:10日均价
- ma20:20日均价
- v_ma5:5日均量
- v_ma10:10日均量
- v_ma20:20日均量
# 将每一个数据的键值的类型从字符串转为日期
df['date'] = pd.to_datetime(df['date'])
# 将日期变为索引
df = df.set_index('date')
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True)
df.tail()
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||||
| 2019-05-24 | 12.35 | 12.45 | 12.35 | 12.31 | 495526.19 | 0.06 | 0.49 | 12.396 | 12.498 | 12.928 | 637251.61 | 781466.47 | 1046943.98 |
| 2019-05-27 | 12.21 | 12.42 | 12.37 | 11.93 | 1048426.00 | 0.02 | 0.16 | 12.394 | 12.505 | 12.824 | 689649.77 | 812117.30 | 1001879.10 |
| 2019-05-28 | 12.31 | 12.55 | 12.49 | 12.26 | 880703.12 | 0.12 | 0.97 | 12.380 | 12.505 | 12.742 | 719548.29 | 781927.80 | 990340.43 |
| 2019-05-29 | 12.36 | 12.59 | 12.40 | 12.26 | 666411.50 | -0.09 | -0.72 | 12.380 | 12.453 | 12.673 | 751584.45 | 738170.10 | 973189.95 |
| 2019-05-30 | 12.32 | 12.38 | 12.22 | 12.11 | 646284.62 | -0.18 | -1.45 | 12.366 | 12.390 | 12.579 | 747470.29 | 739308.42 | 953969.39 |
# 检测是否有缺失数据 NaNs
df.dropna(axis=0 , inplace=True)
df.isna().sum()
open 0
high 0
close 0
low 0
volume 0
price_change 0
p_change 0
ma5 0
ma10 0
ma20 0
v_ma5 0
v_ma10 0
v_ma20 0
dtype: int64
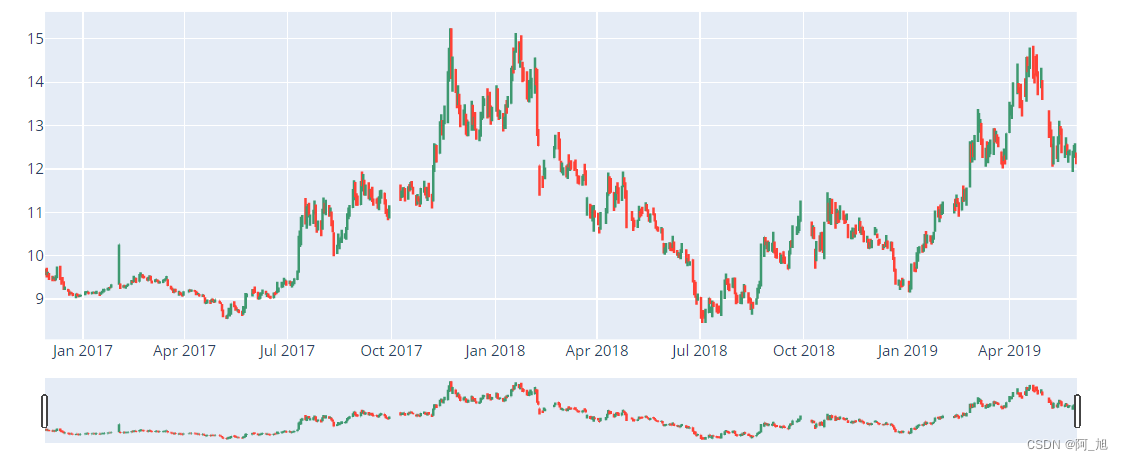
K线图绘制
Min_date = df.index.min()
Max_date = df.index.max()
print ("First date is",Min_date)
print ("Last date is",Max_date)
print (Max_date - Min_date)
First date is 2016-11-29 00:00:00
Last date is 2019-05-30 00:00:00
912 days 00:00:00
from plotly import tools
from plotly.graph_objs import *
from plotly.offline import init_notebook_mode, iplot, iplot_mpl
init_notebook_mode()
import chart_studio.plotly as py
import plotly.graph_objs as gotrace = go.Ohlc(x=df.index, open=df['open'], high=df['high'], low=df['low'], close=df['close'])
data = [trace]
iplot(data, filename='simple_ohlc')
2.构建回归模型
from sklearn.linear_model import LinearRegression
from sklearn import preprocessing
# 创建标签数据:即预测值, 根据当前的数据预测5天以后的收盘价
num = 5 # 预测5天后的情况
df['label'] = df['close'].shift(-num) # 预测值,将5天后的收盘价当作当前样本的标签print(df.shape)
(611, 14)
# 丢弃 'label', 'price_change', 'p_change', 不需要它们做预测
Data = df.drop(['label', 'price_change', 'p_change'],axis=1)
Data.tail()
| open | high | close | low | volume | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| date | |||||||||||
| 2019-05-24 | 12.35 | 12.45 | 12.35 | 12.31 | 495526.19 | 12.396 | 12.498 | 12.928 | 637251.61 | 781466.47 | 1046943.98 |
| 2019-05-27 | 12.21 | 12.42 | 12.37 | 11.93 | 1048426.00 | 12.394 | 12.505 | 12.824 | 689649.77 | 812117.30 | 1001879.10 |
| 2019-05-28 | 12.31 | 12.55 | 12.49 | 12.26 | 880703.12 | 12.380 | 12.505 | 12.742 | 719548.29 | 781927.80 | 990340.43 |
| 2019-05-29 | 12.36 | 12.59 | 12.40 | 12.26 | 666411.50 | 12.380 | 12.453 | 12.673 | 751584.45 | 738170.10 | 973189.95 |
| 2019-05-30 | 12.32 | 12.38 | 12.22 | 12.11 | 646284.62 | 12.366 | 12.390 | 12.579 | 747470.29 | 739308.42 | 953969.39 |
X = Data.values
# 去掉最后5行,因为没有Y的值
X = X[:-num]
# 将特征进行归一化
X = preprocessing.scale(X)
# 去掉标签为null的最后5行
df.dropna(inplace=True)
Target = df.label
y = Target.valuesprint(np.shape(X), np.shape(y))
(606, 11) (606,)
# 将数据分为训练数据和测试数据
X_train, y_train = X[0:550, :], y[0:550]
X_test, y_test = X[550:, -51:], y[550:606]
print(X_train.shape)
print(y_train.shape)
print(X_test.shape)
print(y_test.shape)
(550, 11)
(550,)
(56, 11)
(56,)
lr = LinearRegression()
lr.fit(X_train, y_train)
lr.score(X_test, y_test) # 使用绝对系数 R^2 评估模型
0.04930040648385525
# 做预测 :取最后5行数据,预测5天后的股票价格
X_Predict = X[-num:]
Forecast = lr.predict(X_Predict)
print(Forecast)
print(y[-num:])
[12.5019651 12.45069629 12.56248765 12.3172638 12.27070154]
[12.35 12.37 12.49 12.4 12.22]
# 查看模型的各个特征参数的系数值
for idx, col_name in enumerate(['open', 'high', 'close', 'low', 'volume', 'ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20']):print("The coefficient for {} is {}".format(col_name, lr.coef_[idx]))
The coefficient for open is -0.7623399996475224
The coefficient for high is 0.8321435171405448
The coefficient for close is 0.24463705375238926
The coefficient for low is 1.091415550493547
The coefficient for volume is 0.0043807937569128675
The coefficient for ma5 is -0.30717535019465575
The coefficient for ma10 is 0.1935431079947582
The coefficient for ma20 is 0.24902077484698157
The coefficient for v_ma5 is 0.17472336466033722
The coefficient for v_ma10 is 0.08873934447969857
The coefficient for v_ma20 is -0.27910702694420775
3.绘制预测结果
# 预测 2019-05-13 到 2019-05-17 , 一共 5 天的收盘价
trange = pd.date_range('2019-05-13', periods=num, freq='d')
trange
DatetimeIndex(['2019-05-13', '2019-05-14', '2019-05-15', '2019-05-16','2019-05-17'],dtype='datetime64[ns]', freq='D')
# 产生预测值dataframe
Predict_df = pd.DataFrame(Forecast, index=trange)
Predict_df.columns = ['forecast']
Predict_df
| forecast | |
|---|---|
| 2019-05-13 | 12.501965 |
| 2019-05-14 | 12.450696 |
| 2019-05-15 | 12.562488 |
| 2019-05-16 | 12.317264 |
| 2019-05-17 | 12.270702 |
# 将预测值添加到原始dataframe
df = pd.read_csv('./000001.csv')
df['date'] = pd.to_datetime(df['date'])
df = df.set_index('date')
# 按照时间升序排列
df.sort_values(by=['date'], inplace=True, ascending=True)
df_concat = pd.concat([df, Predict_df], axis=1)df_concat = df_concat[df_concat.index.isin(Predict_df.index)]
df_concat.tail(num)
| open | high | close | low | volume | price_change | p_change | ma5 | ma10 | ma20 | v_ma5 | v_ma10 | v_ma20 | forecast | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019-05-13 | 12.33 | 12.54 | 12.30 | 12.23 | 741917.75 | -0.38 | -3.00 | 12.538 | 13.143 | 13.637 | 1107915.51 | 1191640.89 | 1211461.61 | 12.501965 |
| 2019-05-14 | 12.20 | 12.75 | 12.49 | 12.16 | 1182598.12 | 0.19 | 1.54 | 12.446 | 12.979 | 13.585 | 1129903.46 | 1198753.07 | 1237823.69 | 12.450696 |
| 2019-05-15 | 12.58 | 13.11 | 12.92 | 12.57 | 1103988.50 | 0.43 | 3.44 | 12.510 | 12.892 | 13.560 | 1155611.00 | 1208209.79 | 1254306.88 | 12.562488 |
| 2019-05-16 | 12.93 | 12.99 | 12.85 | 12.78 | 634901.44 | -0.07 | -0.54 | 12.648 | 12.767 | 13.518 | 971160.96 | 1168630.36 | 1209357.42 | 12.317264 |
| 2019-05-17 | 12.92 | 12.93 | 12.44 | 12.36 | 965000.88 | -0.41 | -3.19 | 12.600 | 12.626 | 13.411 | 925681.34 | 1153473.43 | 1138638.70 | 12.270702 |
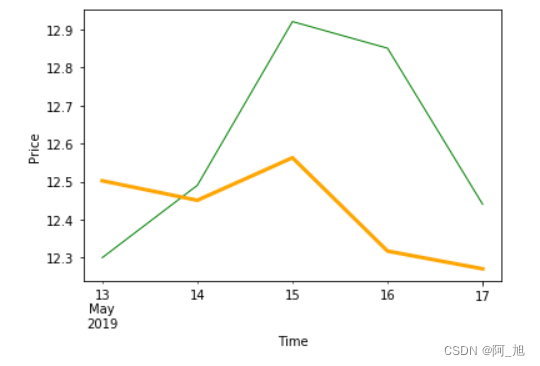
# 画预测值和实际值
df_concat['close'].plot(color='green', linewidth=1)
df_concat['forecast'].plot(color='orange', linewidth=3)
plt.xlabel('Time')
plt.ylabel('Price')
plt.show()
如果文章对你有帮助,感谢点赞+关注!
关注下方GZH:阿旭算法与机器学习,回复:“ML31”即可获取本文数据集、源码与项目文档,欢迎共同学习交流
相关文章:
【阿旭机器学习实战】【31】股票价格预测案例--线性回归
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。 注:本文模型结果不好,仅做学习参考使用,提供思路。了解数据处理思路,训练模型和预测数值的过程。 目录1. 读取数据K线图绘…...

浅谈毫米波技术与应用
浅谈毫米波之技术篇2020年10月GSMA发布的《5G毫米波技术白皮书》预计,在2022年北京冬奥会上,5G毫米波有望大放异彩,为观众、媒体转播者、赛事组织和参与者等提供优质的观赛体验、完备的服务保障,将可提供全景VR、新型信息交互、智…...

给安全平台编写插件模块的思路分享
一、背景 最近在GitHub看到一个新的开源安全工具,可以把工具都集成到一个平台里,觉得挺有意思,但是平台现有的工具不是太全,我想把自己的工具也集成进去,所以研究了一番 蜻蜓安全工作台是一个安全工具集成平台&#x…...

4123版驱动最新支持《霍格沃茨之遗》,英特尔锐炫显卡带你畅游魔法世界
2023年开年最火的3A大作,那一定是近期上架steam平台的《霍格沃茨之遗》,这款游戏在2020年9月份曝光,游戏根据《哈利波特》系列书籍内容改编,作为一款开放式的3A大作,《霍格沃兹之遗》目前在steam上的实时在线人数已经突…...
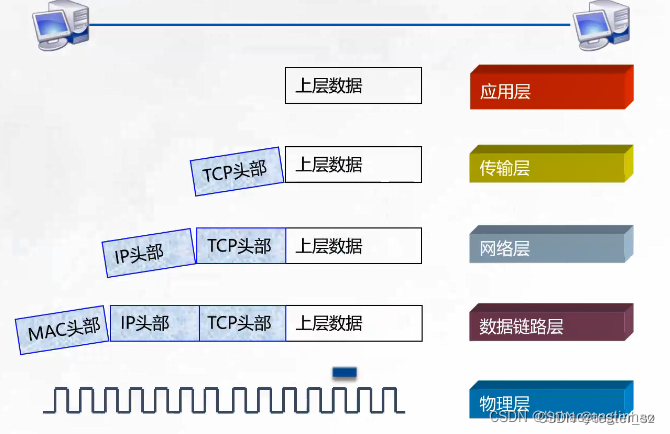
OSI模型和网络协议简介
文章目录一、OSI七层模型1.1什么是OSI七层模型?1.2这个网络模型究竟是干什么呢?二、TCP/IP协议三、常见协议四、物联网通信协议以及MQTT4.1 物联网七大通信协议4.2 MQTT特性一、OSI七层模型 1.1什么是OSI七层模型? 我们需要了解互联网的本质…...

传感器原理及应用期末复习汇总(附某高校期末真题试卷)
文章目录一、选择题二、填空题三、简答题四、计算题五、期末真题一、选择题 1.下列哪一项是金属式应变计的主要缺点(A) A、非线性明显 B、灵敏度低 C、准确度低 D、响应时间慢 2.属于传感器动态特性指标的是(D) A、重复性 B、线…...

【亲测2022年】网络工程师被问最多的面试笔试题
嗨罗~大家好久不见,主要是薄荷呢主业还是比较繁忙的啦,之前发了一个面试题大家都很喜欢,非常感谢各位大佬对薄荷的喜爱,嘻嘻然后呢~薄荷调研了身边的朋友和同事,发现我们之前去面试,写的面试题有很多共同的…...

Web前端:全栈开发人员的责任
多年来,关于全栈开发人员有很多说法,全栈开发人员是一位精通应用程序全栈开发过程的专业人士。这包括数据库、API、前端技术、后端开发语言和控制系统版本。你一定遇到过前端和后端开发人员。前端开发人员将构建接口,而后端开发人员将开发、更…...

C语言之通讯录的实现
通讯录实现所需头文件和源文件 Contact.h的功能 声明函数和创建结构体变量 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h> #include <string.h> #include <stdlib.h> #include <assert.h> #define MAX 1000 #define MAX_NAME 20 #define MAX…...

手把手教大家在 gRPC 中使用 JWT 完成身份校验
文章目录1. JWT 介绍1.1 无状态登录1.1.1 什么是有状态1.1.2 什么是无状态1.2 如何实现无状态1.3 JWT1.3.1 简介1.3.2 JWT数据格式1.3.3 JWT 交互流程1.3.4 JWT 存在的问题2. 实践2.1 项目创建2.2 grpc_api2.3 grpc_server2.4 grpc_client3. 小结上篇文章松哥和小伙伴们聊了在 …...
VSCode远程连接服务器
工作使用服务器的jupyter,直到有一天服务器挂了,然而,代码还没有来得及备份。o(╥﹏╥)o VScode远程连接服务器,使用服务器的资源,代码可以存在本地,可以解决上述困境。 1.官网下载VSCode.网址https://cod…...
【C++】-- 异常
目录 C语言传统的处理错误的方式 C异常概念 异常的使用 异常的抛出和捕获 自定义异常体系 异常的重新抛出 异常安全 异常规范(C期望) C标准库的异常体系 异常的优缺点 C异常的优点 C异常的缺点 总结 C语言传统的处理错误的方式 传统的错误…...
Java中的Stack与Queue
文章目录一、栈的概念及使用1.1 概念1.2 栈的使用1.3 栈的模拟实现二、队列的概念及使用2.1 概念2.2 队列的使用2.3 双端队列(Deque)三、相关OJ题3.1 用队列实现栈。3.2 用栈实现队列。总结一、栈的概念及使用 1.1 概念 栈:一种特殊的线性表,其只允许在…...

xilinx FPGA在线调试方法总结(vivado+ila+vio)
本文主要介绍xilinx FPGA开发过程中常用的调试方法,包括ILA、VIO和TCL命令等等,详细介绍了如何使用。一、FPGA调试基本原则根据实际的输出结果表现,来推测可能的原因,再在模块中加ILA信号,设置抓信号条件,逐…...

自动化测试——css元素定位
文章目录一、css定位场景二、css相对定位的优点三、css的调试方法1、表达式中含有字符串:表达式中的引号一定和外面字符串的引号相反四、css基础语法1、标签定位2、class定位特别注意:当class类型的属性值包含多个分割值,$(.s_tab s_tab_1z9n…...

ChatGPT可能马上取代你,这是它能做的十个工作
ChatGPT 的横空出世,在业界掀起了惊涛骇浪。专家表示,ChatGPT 和相关人工智能技术可能会威胁到一些工作岗位,尤其是白领工作。 自去年11月发布以来,新型聊天机器人模型 ChatGPT 已经被用于各种各样的工作:撰写求职信、编写儿童读物,甚至帮助学生在论文中作弊。谷歌公司发…...
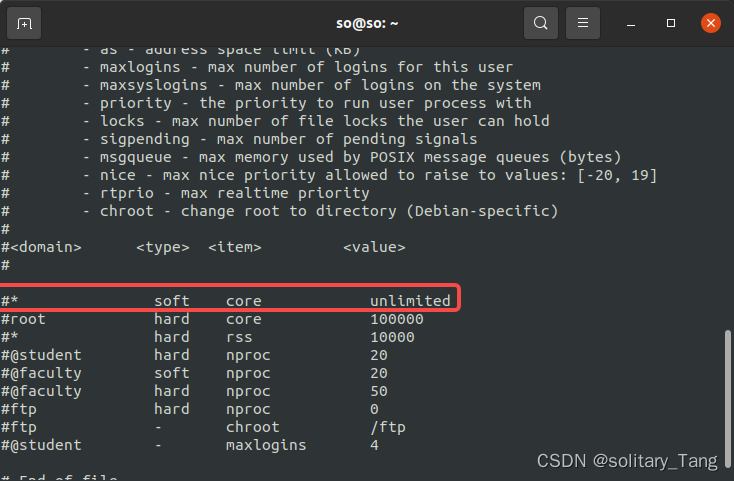
ubuntu转储coredump
方法一: 输入以下命令即可,其中${USER}为自己电脑的用户名: ulimit -c unlimited echo "/home/${USER}/core.%p" > /proc/sys/kernel/core_pattern 方法二: Disable apport : sudo systemctl stop apport.servicesudo system…...

基于单片机的毕业设计推荐
** 2023基于单片机的毕业设计推荐: ** 1、基于51单片机的多功能门禁系统(低端、功能限制较大)。 2、基于单片机的多功能实时时钟。 3、基于单片机的音乐播放器。 4、基于STM32单片机的多功能门禁系统(高端、没有限制)…...
APP测试中ios和androis的区别,有哪些注意点
目录 一、运行机制不同 二、对app内存消耗处理方式不同 三、后台制度不同 四、最高权限指令不同 五、推送机制不同 六、抓取方式不同 七、灰度发版机制不同 八、审核机制不同 总结感谢每一个认真阅读我文章的人!!! 重点:…...
使用 Xcode 创建第一个 Objective-C 命令行程序 HelloWorld
总目录 iOS开发笔记目录 从一无所知到入门 文章目录创建项目运行项目,查看日志输出同一项目下新增子目录,切换要运行的 Target创建项目 打开 Xcode ,Create a new Xcode project 接下来的默认界面: 切换到 macOS 下ÿ…...
:从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界)
DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型选型终极指南(附完整Benchmark Excel模板):从MMLU到GPQA、从AIME到LiveCodeBench,一表看透真实能力边界 选择适配业务场景的DeepSeek模型&am…...

YOLO训练前数据检查必备:一个脚本批量转换LabelImg的txt标签并可视化核对
YOLO训练前数据检查实战:批量转换与可视化核验脚本开发指南 在计算机视觉项目的实际落地过程中,数据质量往往比模型架构更能决定最终效果的上限。许多团队花费大量时间调整超参数和网络结构,却忽略了最基础的标注数据验证环节。当使用LabelIm…...

Python之encode-cli包语法、参数和实际应用案例
Python encode-cli包完整使用指南 encode-cli 是Python生态中轻量、高效的命令行编码/解码工具包,专注于提供主流编码格式的快速转换,支持命令行直接调用,无需编写复杂Python代码,适用于数据加密、文本转码、URL处理、Base64转换等…...

当“画笔”变成“画笔”,世界便不再扁平:上海科技大学师玉娇团队 BevSplat 论文深度解读
用高斯画笔为地面图像“补上高度”,让卫星图片与街景的配对不再尴尬 想象一下这幅情境:一辆自动驾驶汽车在密集的城市楼群中行驶。GPS 信号被摩天大楼遮挡得断断续续,车辆根本无法准确知道自己的位置。于是,它需要一种备用方案&am…...

猫抓浏览器扩展技术深度解析:构建高效流媒体资源捕获工作流
猫抓浏览器扩展技术深度解析:构建高效流媒体资源捕获工作流 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓浏览器扩展是一个基于C…...

Windows安卓子系统终极优化指南:如何通过WSABuilds实现完美Android体验
Windows安卓子系统终极优化指南:如何通过WSABuilds实现完美Android体验 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or Ke…...
详解 + 实例代码)
IDE 重构(Refactoring)详解 + 实例代码
IDE 重构(Refactoring)详解 实例代码 重构是指在不改变代码外部行为的前提下,对代码内部结构进行调整、优化,使代码更易读、易维护、易扩展的过程。IDE(集成开发环境)是重构的最强助手,它能自动…...

STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南
STM32F407 ADC采样值跳得厉害?HAL库时钟配置与软件滤波避坑指南 在嵌入式系统开发中,ADC(模数转换器)的稳定性直接关系到整个系统的测量精度。特别是对于STM32F407这类高性能MCU,当应用于电源监控、医疗设备或工业传感…...
从PointNet到Transformer:聊聊‘参数共享’这个省内存又提性能的炼丹技巧
从PointNet到Transformer:参数共享如何重塑深度学习效率 在深度学习模型日益复杂的今天,算法工程师们不断面临一个核心矛盾:如何在保持模型性能的同时,有效控制参数规模?当我们处理点云、序列或图结构这类不规则数据时…...
)
旧安卓手机别扔!用Termux+LXC把它变成一台Ubuntu Docker服务器(保姆级避坑指南)
旧安卓设备重生指南:打造低功耗Ubuntu容器服务器的完整方案 你是否曾为抽屉里那台退役的安卓手机感到惋惜?当旗舰机型沦为电子垃圾时,其实它们潜藏的算力足以支撑个人开发环境、轻量级服务甚至家庭自动化中枢。本文将揭示如何通过Termux与LXC…...