Apache Doris 2.0 如何实现导入性能提升 2-8 倍
数据导入吞吐是 OLAP 系统性能的重要衡量标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。随着 Apache Doris 用户规模的不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 Apache Doris 的数据导入能力带来了更大的挑战。
为提供快速的数据写入支持,Apache Doris 存储引擎采用了类似 LSM Tree 结构。在进行数据导入时,数据会先写入 Tablet 对应的 MemTable 中,MemTable 采用 SkipList 的数据结构。当 MemTable 写满之后,会将其中的数据刷写(Flush)到磁盘。数据从 MemTable 刷写到磁盘的过程分为两个阶段,第一阶段是将 MemTable 中的行存结构在内存中转换为列存结构,并为每一列生成对应的索引结构;第二阶段是将转换后的列存结构写入磁盘,生成 Segment 文件。
具体而言,Apache Doris 在导入流程中会把 BE 模块分为上游和下游,其中上游 BE 对数据的处理分为 Scan 和 Sink 两个步骤:首先 Scan 过程对原始数据进行解析,然后 Sink 过程将数据组织并通过 RPC 分发给下游 BE。当下游 BE 接收数据后,首先在内存结构 MemTable 中进行数据攒批,对数据排序、聚合,并最终下刷成数据文件(也称 Segment 文件)到硬盘上来进行持久化存储。
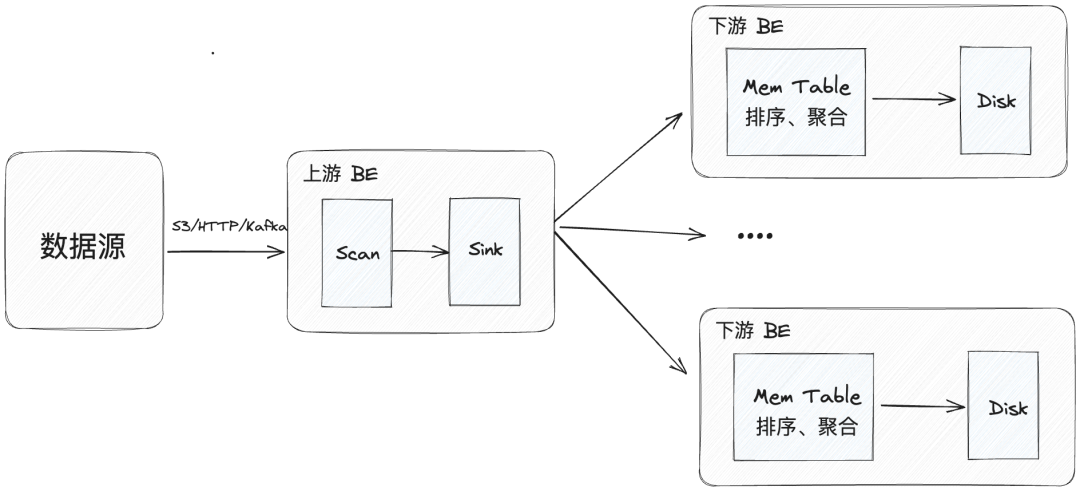
而我们在实际的数据导入过程中,可能会出现以下问题:
- 因上游 BE 跟下游 BE 之间的 RPC 采用 Ping-Pong 的模式,即下游 BE 一个请求处理完成并回复到上游 BE 后,上游 BE 才会发送下一个请求。如果下游 BE 在 MemTable 的处理过程中消耗了较长的时间,那么上游 BE 将会等待 RPC 返回的时间也会变长,这就会影响到数据传输的效率。
- 当对多副本的表导入数据时,需要在每个副本上重复执行 MemTable 的处理过程。然而,这种方式使每个副本所在节点都会消耗一定的内存和 CPU 资源,不仅如此,冗长的处理流程也会影响执行效率。
为解决以上问题,我们在刚刚发布不久 Apache Doris 2.0 版本中(https://github.com/apache/doris/tree/2.0.1-rc04 ),对导入过程中 MemTable 的攒批、排序和落盘等流程进行优化,提高了上下游之间数据传输的效率。此外我们在新版本中还提供 “单副本导入” 的数据分发模式,当面对多副本数据导入时,无需在多个 BE 上重复进行 MemTable 工作,有效提升集群计算和内存资源的利用率,进而提升导入的总吞吐量。
MemTable 优化
01 写入优化
在 Aapche Doris 过去版本中,下游 BE 在写入 MemTable 时,为了维护 Key 的顺序,会实时对 SkipList 进行更新。对于 Unique Key 表或者 Aggregate Key 表来说,遇到已经存在的 Key 时,将会调用聚合函数并进行合并。然而这两个步骤可能会消耗较多的处理时间,从而延迟 RPC 响应时间,影响数据写入的效率。
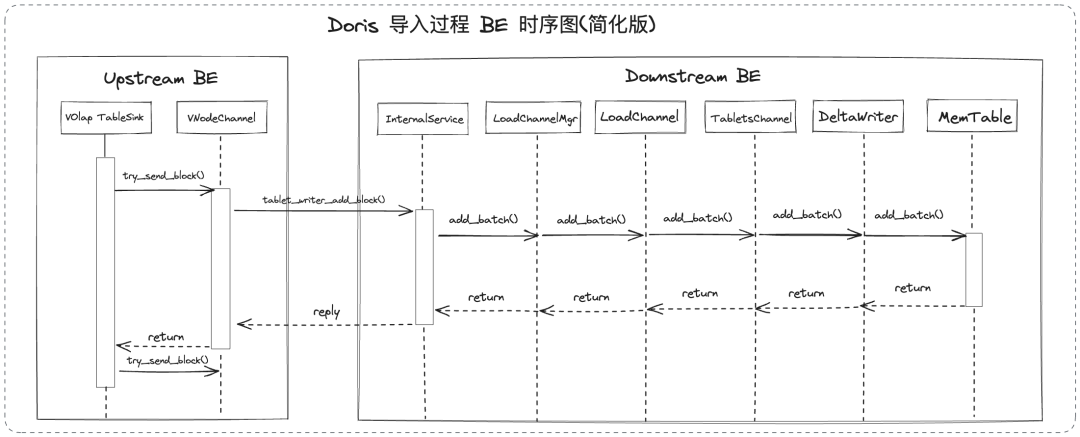
因此我们在 2.0 版本中对这一过程进行了优化。当下游 BE 在写入 MemTable 时,不再实时维护 MemTable 中 Key 的顺序,而是将顺序的保证推迟到 MemTable 即将被下刷成 Segment 之前。此外,我们采用更高效的 pdqsort 来替代 std::sort ,实现了缓存友好的列优先排序方式,并取得了更好的排序性能。通过上述两种手段来保证 RPC 能够被及时响应。
02 并行下刷
在导入过程中,当下游 BE 将一个 MemTable 写入一定大小之后,会把 MemTable 下刷为 Segment 数据文件来持久化存储数据并释放内存。为了保证前文提到的 Ping-Pong RPC 性能不受影响,MemTable 的下刷操作会被提交到一个线程池中进行异步执行。
在 Apache Doris 过去版本中,对于 Unique Key 的表来说,MemTable 下刷任务是串行执行的,原因是不同 Segment 文件之间可能存在重复 Key,串行执行可以保持它们的先后顺序,而 Segment 序号是在下刷任务被调度执行时分配的。同时,在 Tablet 数量较少无法提供足够的并发时,串行下刷可能会导致系统的 IO 资源无法重复被利用。而在 Apache Doris 2.0 版本中,由于我们将 Key 的排序和聚合操作进行了后置,除了原有的 IO 负载以外,下刷任务中还增加了 CPU 负载(即后置的排序和聚合操作)。此时若仍使用串行下刷的方式,当没有足够多 Tablet 来保证并发数时,CPU 和 IO 会交替成为瓶颈,从而导致下刷任务的吞吐量大幅降低。
为解决这个问题,我们在下刷任务提交时就为其分配 Segment 序号,确保并行下刷后生成的 Segment 文件顺序是正确的。同时,我们还对后续 Rowset 构建流程进行了优化,使其可以处理不连续的 Segment 序号。通过以上改进,使得所有类型的表都可以并行下刷 MemTable,从而提高整体资源利用率和导入吞吐量。
03 优化效果
通过对 MemTable 的优化,面对不同的导入场景,Stream Load 的吞吐量均有不同幅度的提升(详细对比数据可见下文)。这项优化不仅适用于Stream Load ,还对 Apache Doris 支持的其他导入方式同样有效,例如 Insert Into、Broker Load、S3 Load 等,均在不同程度提升了导入的效率及性能。
单副本导入
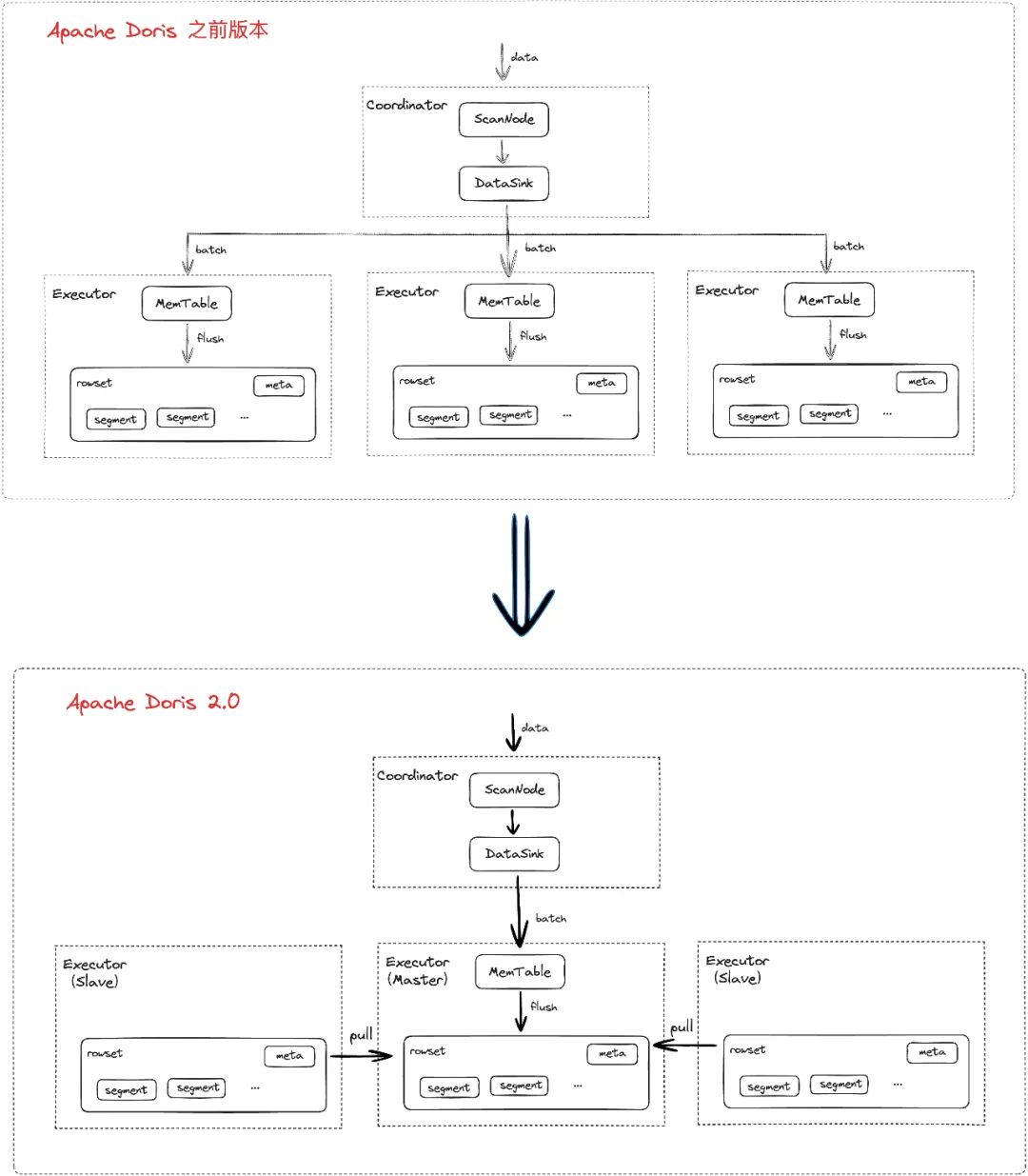
01 原理和实现
在过去版本中,当面对多副本数据写入时,Apache Doris 的每个数据副本均需要在各自节点上进行排序和压缩,这样会造成较大的资源占用。为了节约 CPU 和内存资源,我们在 Apache Doris 在 2.0 版本中提供了单副本导入的能力,该能力会从多个副本中选择一个副本作为主副本(其他副本为从副本),且只对主副本进行计算,当主副本的数据文件都写入成功后,通知从副本所在节点直接接拉取主副本的数据文件,实现副本间的数据同步,当所有从副本节点拉取完后进行返回或超时返回(大多数副本成功即返回成功)。该能力无需一一在节点上进行处理,减少了节点的压力,而节约的算力和内存将会用于其它任务的处理,从而提升整体系统的并发吞吐能力。
02 如何开启
FE 配置:
enable_single_replica_load = true
BE 配置:
enable_single_replica_load = true
环境变量(insert into)
SET experimental_enable_single_replica_insert=true;
03 优化效果
- 对于单并发导入来说,单副本数据导入可以有效降低资源消耗。单副本导入所占的内存仅为三副本导入的 1/3(单副本导入时只需要写一份内存,三副本导入时需要写三份内存)。同时从实际测试可知,单副本导入的 CPU 消耗约为三副本导入的 1/2,可有效节约 CPU 资源。
- 对于多并发导入来说,在相同的资源消耗下,单副本导入可以显著增加任务吞吐。同时在实际测试中,同样的并发导入任务, 三副本导入方式耗时 67 分钟,而单副本导入方式仅耗时 27 分钟,导入效率提升约 2.5 倍。具体数据请参考后文。
性能对比
测试环境及配置:
- 3 个 BE (16C 64G),每个 BE 配置 3 块盘 (单盘读写约 150 MB/s)
- 1 个 FE,共享其中一个 BE 的机器
原始数据使用 TPC-H SF100 生成的 Lineitem 表,存储在 FE 所在机器的一个独立的盘上(读约 150 MB/s)。
01 Stream Load(单并发)
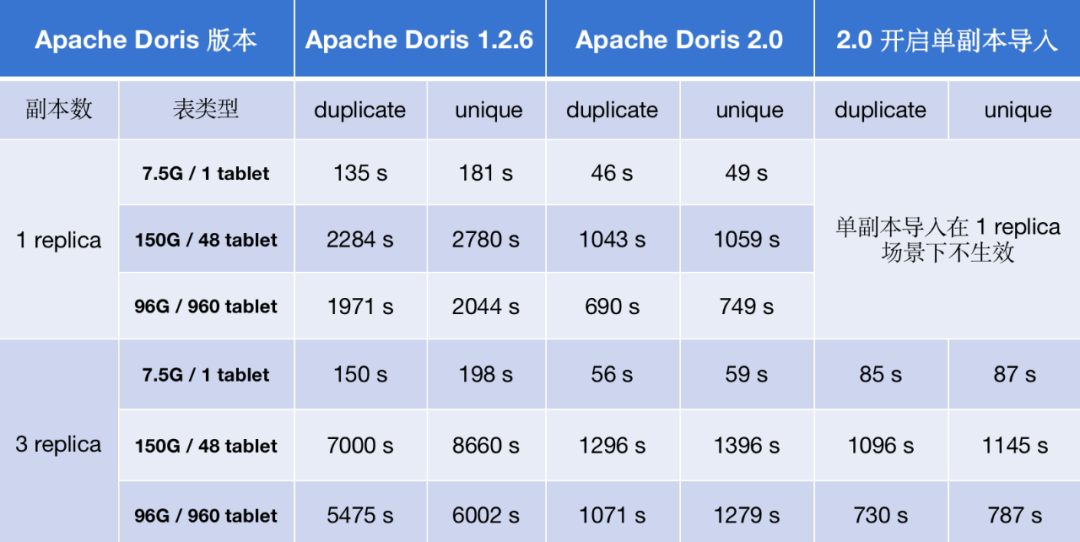
以上述列举的单并发场景来说,Apache Doris 2.0 版本整体的导入性能比 1.2.6 版本提升了 2-7 倍;在多副本前提下,开启新特性单副本导入,导入性能提升了 2-8 倍。
02 INSERT INTO (多并发)
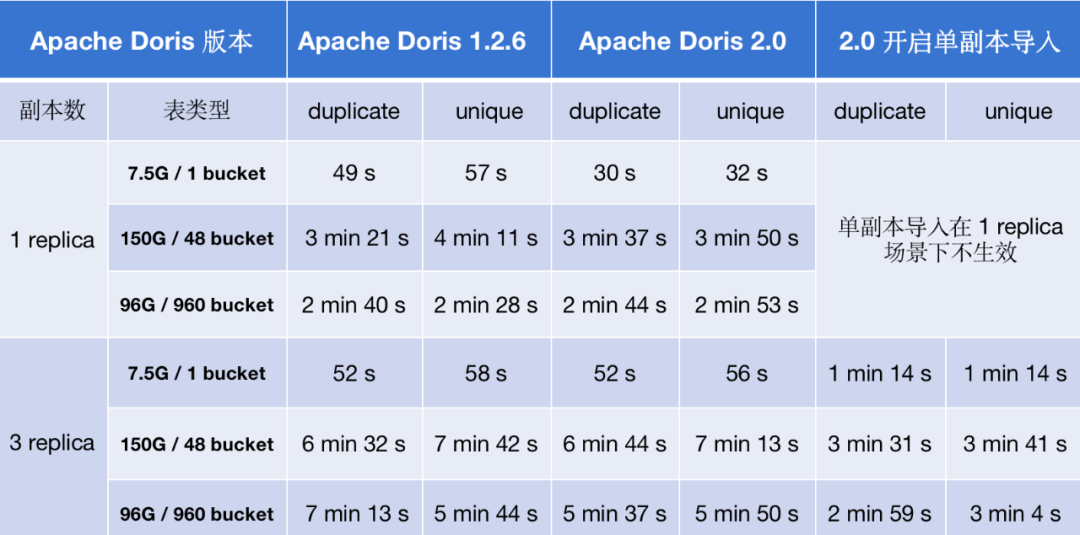
以上述列举的多并发场景来说,Apache Doris 2.0 版本整体比 1.2.6 版本有小幅提升;开启新特性单副本导入后,对在多副本提导入性能提升效果明显,导入速度较 1.2.6 版提升约 50% 。
结束语
社区一直致力于提升 Apache Doris 导入性能这一核心能力,为用户提供更佳的高效分析体验,通过在 2.0 版本对 Memtable、单副本导入等能力进行优化,导入性能相较于之前版本已经呈现数倍提升。未来我们还将在 2.1 版本中持续迭代,结合 MemTable 的优化方法、单副本优化资源能效理念,以及基于 Streaming RPC 优化后的 IO 模型和精简的 IO 路径对导入性能进一步优化,同时减少导入对查询性能的影响,为用户提供更加卓越的数据导入体验。
# 作者介绍:
陈凯杰,SelectDB 高级研发工程师
张正宇,SelectDB 资深研发工程师
相关文章:
Apache Doris 2.0 如何实现导入性能提升 2-8 倍
数据导入吞吐是 OLAP 系统性能的重要衡量标准之一,高效的数据导入能力能够加速数据实时处理和分析的效率。随着 Apache Doris 用户规模的不断扩大, 越来越多用户对数据导入提出更高的要求,这也为 Apache Doris 的数据导入能力带来了更大的挑战…...

RabbitMQ: topic 结构
生产者 package com.qf.mq2302.topic;import com.qf.mq2302.utils.MQUtils; import com.rabbitmq.client.Channel; import com.rabbitmq.client.Connection;public class Pubisher {public static final String EXCHANGE_NAME"mypubilisher";public static void ma…...
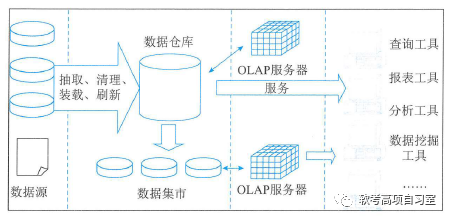
信息系统项目管理教程(第4版):第二章 信息技术及其发展
请点击↑关注、收藏,本博客免费为你获取精彩知识分享!有惊喜哟!! 第二章 信息技术及其发展 2.1信息技术及其发展 信息技术是以微电子学为基础的计算机技术和电信技术的结合而形成的,对声音的、图像的、文字的、数字…...

有哪些适合初学者的编程语言?
C语言 那为什么我还要教你C语言呢?因为我想要让你成为一个更好、更强大的程序员。如果你要变得更好,C语言是一个极佳的选择,其原因有二。首先,C语言缺乏任何现代的安全功能,这意味着你必须更为警惕,时刻了…...

uni-app动态tabBar,根据不同用户展示不同的tabBar
1.uni框架的api实现 因为我们用的是uni-app框架开发,所以在创建项目的时候直接创建uni-ui的项目即可,这个项目模板中自带了uni的一些好用的组件和api。 起初我想着这个效果不难实现,因为官方也有api可以直接使用,所以我最开始尝试…...

手写Spring:第6章-资源加载器解析文件注册对象
文章目录 一、目标:资源加载器解析文件注册对象二、设计:资源加载器解析文件注册对象三、实现:资源加载器解析文件注册对象3.1 工程结构3.2 资源加载器解析文件注册对象类图3.3 类工具类3.4 资源加载接口定义和实现3.4.1 定义资源加载接口3.4…...

Redis 7 第八讲 集群模式(cluster)架构篇
集群架构 Redis 集群架构图 集群定义 Redis 集群是一个提供在多个Redis节点间共享数据的程序集;Redis集群可以支持多个master 应用场景 Redis集群支持多个master,每个master又可以挂载多个slave读写分离支持数据的高可用支持海量数据的读写存储操作集群自带Sentinel的故障…...

【PowerQuery】导入与加载XML
在标准数据格式类型里面,有一类比较特殊的数据类型,就是层次结构数据。层次结构数据和标准的结构型数据方式完全不同,在实际应用过程中使用最为频繁的几种数据类型如下。 XML数据格式Json 数据格式Yaml 数据格式我们将在本节和大家一起分享下XML格式数据集成,下一节和大家分…...

vue 预览视频
1.预览本地文件 1.1 直接给video或者embed的src赋值本地路径 <video :src"videoUrl"></video> // 或者 使用embed标签<embed :src"videoUrl" /> 1.2 读取文件流形式 <input type"file" ref"file" /> <vi…...

4个维度讲透ChatGPT技术原理,揭开ChatGPT神秘技术黑盒!(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

【无标题】@Scheduled 的cron
, :指定多个值。 -:表示一个区间。 / :指定一个值的增加幅度。n/m表示从n开始,每次增加m。 L:是last的缩写,表示最后一天,用在日表示一个月中的最后一天,用在周表示每周最后一天&…...

IP和MAC的作用区别
在 IP 地址的上一行是 link/ether fa:16:3e:c7:79:75 brd ff:ff:ff:ff:ff:ff,这个被称为 MAC 地址,是一个网卡的物理地址,用十六进制,6 个 byte 表示。 一个网络包要从一个地方传到另一个地方,除了要有确定的地址&…...

python趣味编程-数独游戏
数独游戏是一个用Python编程语言编写的应用程序。该项目包含可以显示实际应用程序的基本功能。该项目可以让修读 IT 相关课程并希望开发简单应用程序的学生受益。这个Python 数独游戏是一个简单的项目,可用于学习tkinter库的实践。这个数独游戏可以提供Python编程的基本编码技…...

MySQL/MariaDB 查询某个 / 多个字段重复数据
创建测试表和数据 # 创建表 create table if not exists t_duplicate (name varchar(255) not null,age int not null );# 插入测试数据 insert into t_duplicate(name, age) values(a, 1); insert into t_duplicate(name, age) values(a, 2);查询单个字段重复 使用 count() …...
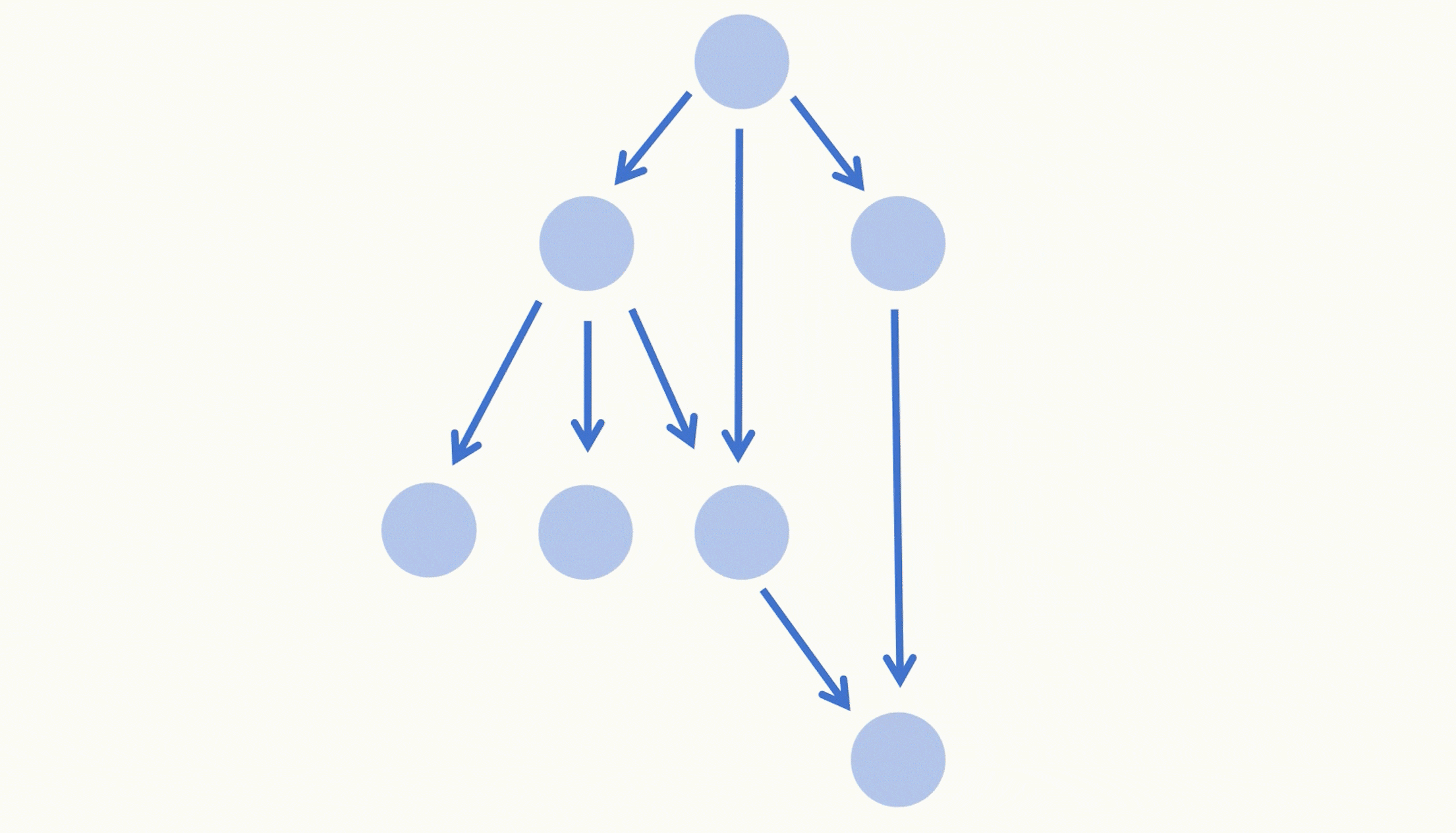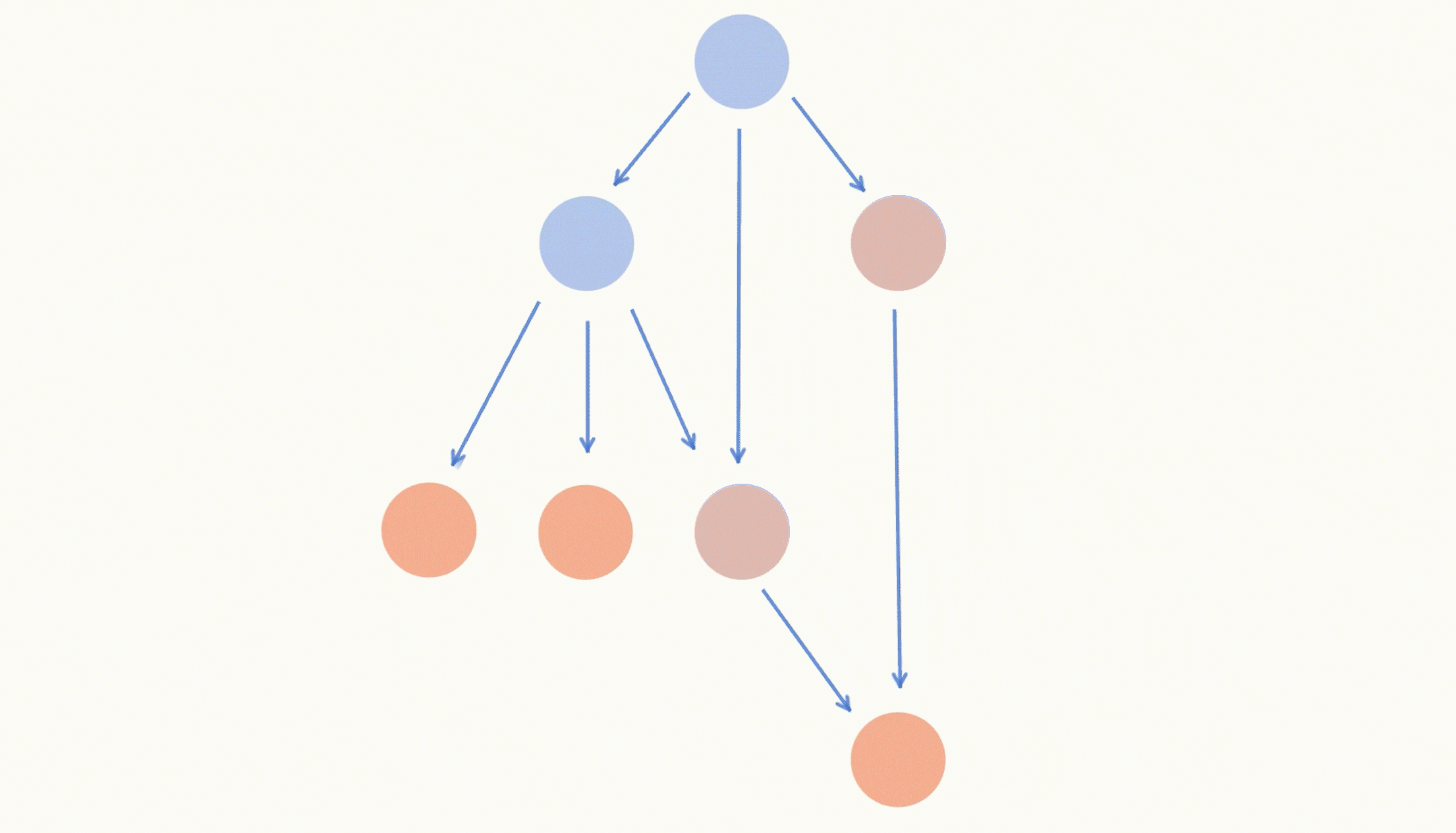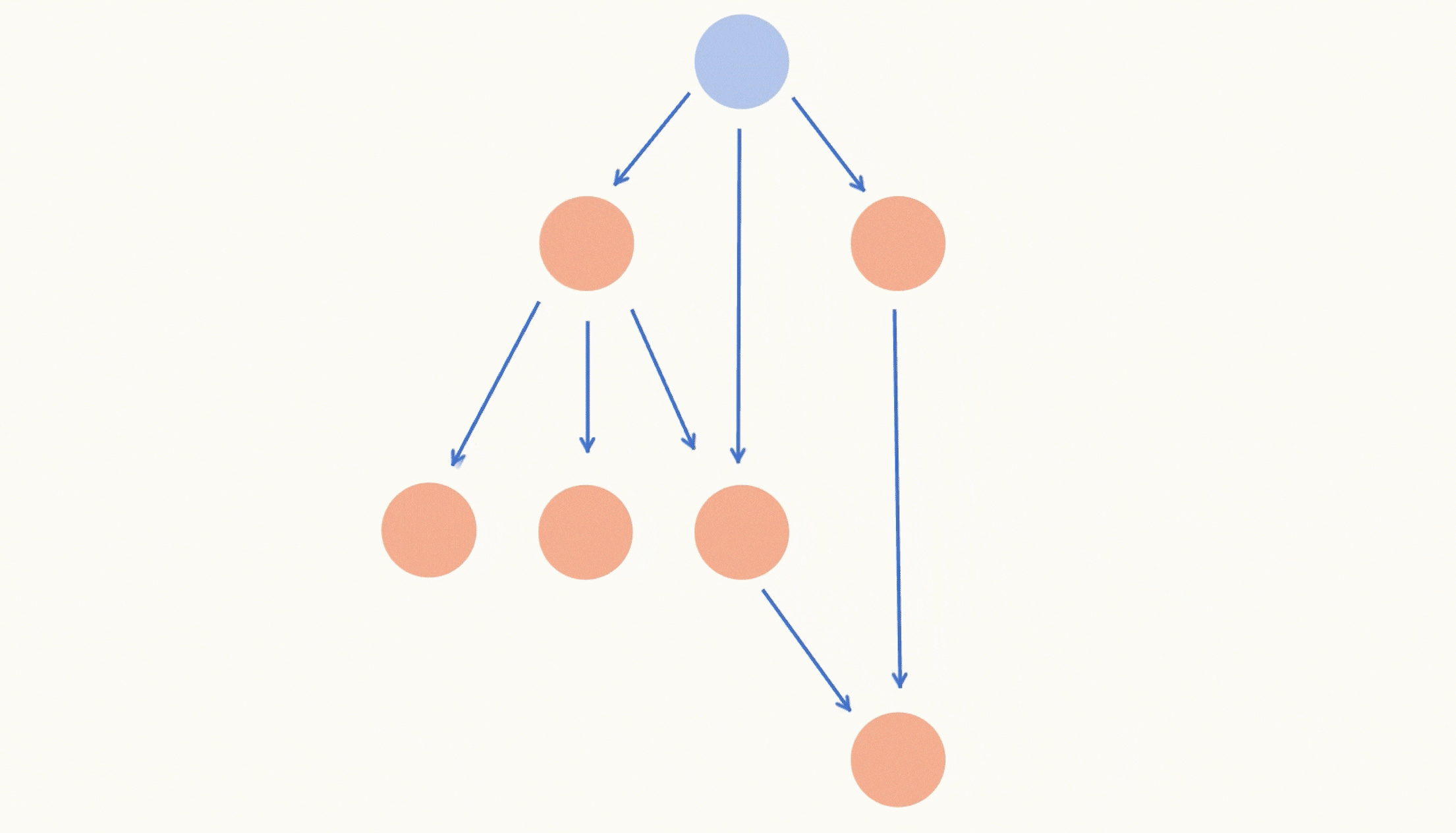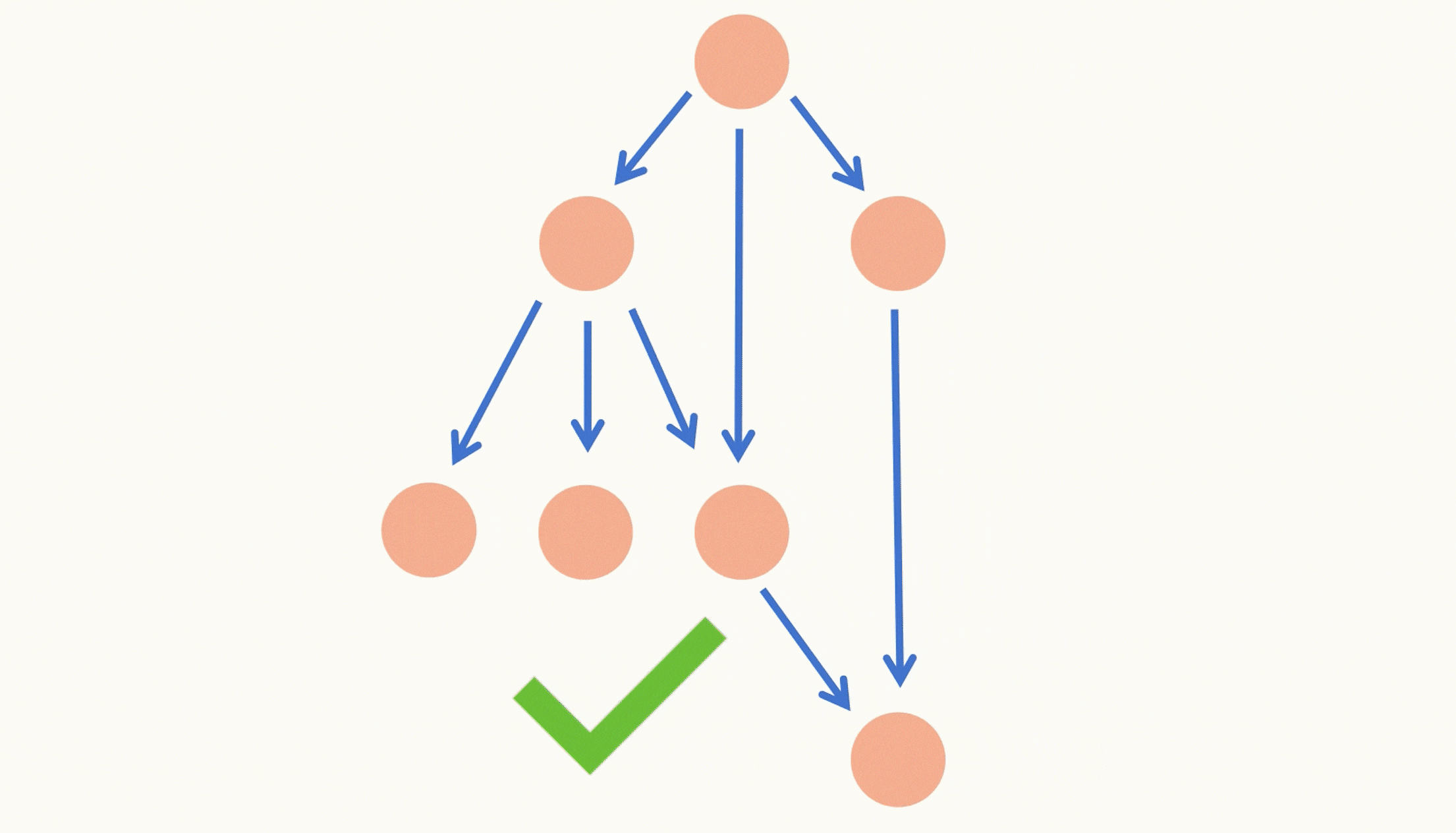
【力扣每日一题】2023.9.10 课程表Ⅱ
目录 题目: 示例: 分析: 代码: 题目: 示例: 分析: 今天的题目和昨天类似,不过今天要我们求出学习所有课程的先后顺序。 昨天只需要我们求出能否学习完所有课程,因此…...

VSCODE CMAKE C++ 工程调试, C++不以科学计数法输出并控制小数位数
1. VSCODE调试CMAKE工程配置1.1 修改CMakeLists.txt文件1.2. 程序中1.3. launch.json配置1.4 开始调试1.5 注意 2. C设置输出浮点数且保留位数固定 1. VSCODE调试CMAKE工程配置 1.1 修改CMakeLists.txt文件 加这一句 set(CMAKE_BUILD_TYPE "Debug")1.2. 程序中 在…...

Drools规则引擎入门学习记录
业务开发过程中,对于某些判断性的通用规则是基于if-else封装,还是基于策略模式封装?无论以上那种封装出来的方法,只能在单体软件包中共用,且不能无感部署,然而对于业务而言,可能规则改变的比较频…...
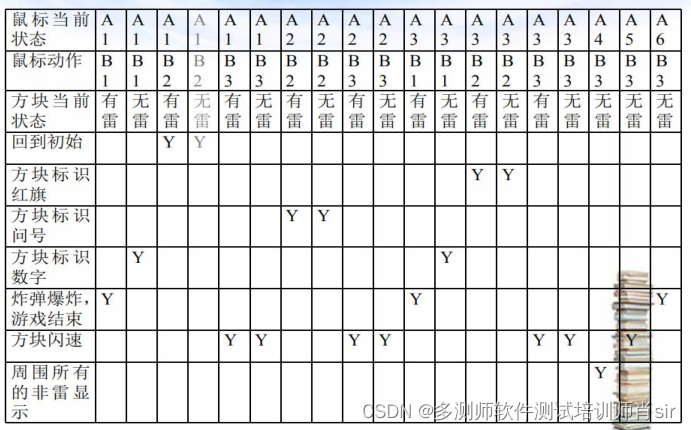
肖sir__设计测试用例方法之判定表06_(黑盒测试)
设计测试用例方法之判定表 1、判定表:是一种表达逻辑判断的工具。 2、判定表:包含四部分 1)条件桩(condition stub):列出问题的 所有条件(通常条件次序无关紧要)。 2)条件项&#x…...

<图像处理> 空间滤波基础
空间滤波基础 图像滤波是一种常见的图像处理技术,用于平滑图像、去除噪音和边缘检测等任务。图像滤波的基本原理是在进行卷积操作时,通过把每个像素的值替换为该像素及其邻域的设定的函数值来修改图像。 预备知识:可分离滤波核、边缘填充。…...

如何在Django中使用django-crontab启动定时任务、关闭任务以及关闭指定任务
安装django-crontab包: pip install django-crontab 在Django项目的settings.py文件中,找到INSTALLED_APPS配置,并添加django_crontab到列表中: INSTALLED_APPS [ ... django_crontab,... ] 在settings.py文件的末尾,添加以下配置以设…...
)
别再只会显示字符了!用51单片机和OLED做个简易电子时钟(IIC协议详解)
从零构建51单片机OLED电子时钟:IIC协议深度解析与项目实战 在嵌入式开发领域,51单片机因其稳定性和易用性始终占据一席之地。当基础的点亮OLED屏幕、显示静态文字已经无法满足你的求知欲时,一个融合硬件协议、实时时钟和UI设计的电子时钟项目…...

自行车轮POV显示:基于视觉暂留与微控制器的DIY空中光绘
1. 项目概述:在车轮上“画”出光之画卷几年前,我第一次在夜间的公园里看到一辆飞驰而过的自行车,它的轮辐间竟然清晰地显示着一行发光的文字和图案,那种瞬间的震撼感至今难忘。那不是魔法,而是视觉暂留原理与微控制器精…...

USB Type-C接口技术解析与工程实践
1. USB接口技术演进与Type-C核心优势USB Type-C接口自2014年发布以来,凭借其革命性的设计理念迅速成为移动设备的主流接口标准。作为从业十余年的硬件工程师,我见证了从USB 2.0 OTG到Type-C的完整迁移过程。与传统micro-A/B接口相比,Type-C最…...

快速上手Redis
一、认识Redis Redis 是一个内存数据库,常用于缓存和高性能数据存储。特点: 数据存储在内存,读写速度快(毫秒级甚至微秒级)支持多种数据结构:String、Hash、List、Set、Sorted Set(ZSet&#…...

别再格式化U盘了!Ubuntu 22.04 LTS下永久解决exFAT支持问题的完整配置指南
永久解决Ubuntu 22.04 LTS的exFAT兼容性问题:从原理到实践 当你在Ubuntu系统中插入一个exFAT格式的U盘或移动硬盘时,那个令人沮丧的错误提示可能已经出现过多次:"unknown filesystem type exfat"。这不是偶然现象,而是源…...

大模型低显存优化实战:量化、KV Cache与动态加载技术解析
1. 项目概述:低显存环境下的OpenClaw模型优化实战最近在GitHub上看到一个挺有意思的项目,标题是“openclaw-lowmem-optimization”。光看名字,就能猜到这大概是在做一件什么事:针对OpenClaw这个模型,进行低显存&#x…...

5个颠覆性文本处理技巧:让notepad--成为你的跨平台效率倍增器
5个颠覆性文本处理技巧:让notepad--成为你的跨平台效率倍增器 【免费下载链接】notepad-- 一个支持windows/linux/mac的文本编辑器,目标是做中国人自己的编辑器,来自中国。 项目地址: https://gitcode.com/GitHub_Trending/no/notepad-- …...

为什么92%的AIGC剪辑师仍在用手动导出?揭秘Sora 2直连Premiere的7大底层优化与3个避坑红线
更多请点击: https://intelliparadigm.com 第一章:Sora 2与Premiere直连整合的行业悖论与破局起点 当OpenAI正式释放Sora 2的API文档并开放有限开发者预览时,Adobe Premiere Pro团队内部立即启动了“Project Lumen”——一项旨在实现双向帧级…...

为防数据泄露!教你拆除2024款RAV4混动汽车调制解调器和GPS
拆除2024款RAV4混动汽车调制解调器和GPS,从源头上阻止数据传输!现代汽车就像装在轮子上的电脑,配备众多传感器,会回传位置、速度等遥测数据。其车内和车外摄像头、麦克风及调制解调器默认开启,且难关闭,数据…...

基于MCP协议与Graph API实现AI助手无缝集成Outlook邮箱
1. 项目概述与核心价值 最近在折腾AI工作流,发现一个挺有意思的项目: ajaya/outlook-app-mcp 。简单来说,这是一个能让你的AI助手(比如Claude Desktop、Cursor等支持MCP协议的客户端)直接读取和操作你Outlook邮箱的…...