数据分析面试题(2023.09.08)
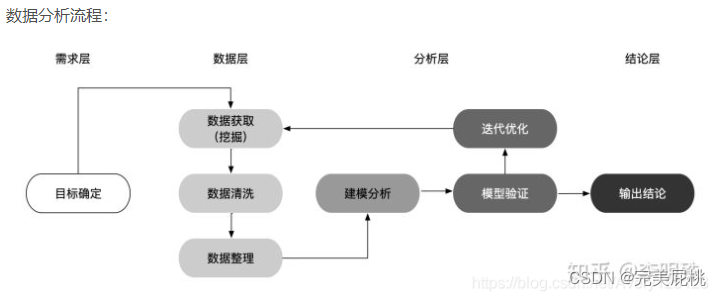
数据分析流程
总体分为四层:需求层、数据层、分析层和结论层
一、统计学问题
1、贝叶斯公式复述并解释应用场景
- 公式:P(A|B)= P(B|A)*P(A) / P(B)
- 应用场景:如搜索query纠错,设A为正确的词,B为输入的词,那么:
a. P(A|B)表示输入词B实际为A的概率
b. P(B|A)表示词A错输为B的概率,可以根据AB的相似度计算(如编辑距离)
c. P(A)是词A出现的频率,统计获得
d. P(B)对于所有候选的A都一样,所以可以省去
-
朴素贝叶斯是在已知一些先验概率的情况下,由果索因的一种方法。朴素的意思是假设了事件相互独立。
2、参数估计
参数估计是指根据从总体中抽取的样本估计总体分布中包含的未知参数的方法。它是统计推断的一种基本形式,是数理统计学的一个重要分支,分为点估计和区间估计两部分。

- 点估计:依据样本估计总体分布中所含的未知参数或未知参数的函数。

- 区间估计(置信区间估计):依据抽取的样本,根据一定的正确度与精确度要求,构造出适当的区间,作为总体分布的未知参数或参数的函数的真值所在范围的估计。例如人们常说的由百分之多少的把握保证某值在某个范围内,即用区间估计的最简单的应用。

3、极大似然估计
极大似然估计是利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
4、假设检验
参数估计和假设检验是统计推断的两个组成部分,它们都是利用样本对总体进行某种推断,但推断的角度不同。
- 参数估计讨论的是用样本估计总体参数的方法,总体参数μ在估计前是未知的。
- 假设检验,是先对μ的值提出一个假设额,然后利用样本信息去检验这个假设是否成立。
5、P值是什么?
P值是用来判定假设检验结果的一个参数,也可以根据不同的分布使用分布的拒绝域进行比较。
P值就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。如果P值很小,说明原假设情况的发生的概率很凶啊,而如果出现了,根据小概率原理,我们就有理由拒绝原假设。P值越小,我们拒绝原假设的理由越充分。总之,P值越小,表明结果越显著。但是检验的结果究竟时“显著的”“中度显著的”还是“高度显著的”需要我们自己根据P值的大小和实际问题来解决。
6、置信度和置信区间
- 置信区间:我们所计算出的变量存在范围
- 置信度:就是我们对于这个数值存在于我们计算出的这个范围的可信程度。
- 举例:①有95%的把握,真正的数值在我们所计算的范围里。95%是置信水平,而计算出的范围,就是置信区间。②如果置信度为95%,则抽取100个样本来估计总体的均值,由100个样本所构造的100个区间中,约有95个区间包含总体均值。
7、协方差和相关系数的区别和联系
- 协方差:协方差表示的是两个变量的总体误差,这与只表示一个变量误差的方差不同。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值,如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
- 相关系数:研究变量之间线性相关程度的量,取值范围是[-1,1],相关系数也可以看成协方差--一种剔除了两个变量量纲影响、标准化后的特殊协方差。
8、中心极限定理
- 定义:①任何一个样本的平均值将会约等于其所在总体的平均值;②不管总体是什么分布,任意一个总体的样本平均值都会围绕在总体的平均值周围,并且呈正态分布。
- 作用:①在没有办法得到总体全部数据的情况下,我们可以用样本来估计总体;②根据总体的平均值和标准差,判断某个样本是否属于总体。
二、概率问题
1、54张扑克牌,分成2份,求着2份都有2张A的概率。
M表示这两个牌堆各有2个A的情况:M=4(25!25!)
N表示两个牌堆完全随机的情况:N=27!27!
概率为:M/N=926/53*17
2、男生点击率增加,女生点击率增加,总体为何减少?
因为男女的点击率可能有较大的差异,同时低点击率的群体的占比增大。
如原来男性20人,点击1人;女性100人,点击99人,总点击率100/120
现在男性100人,点击6人;女性20人,点击20人,总点击率26/120
三、数据库
1、什么是数据库,数据库管理系统,数据库系统,数据库管理员?
- 数据库:数据库DataBase就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
- 数据库管理系统:数据库管理系统是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
- 数据库系统:数据库系统通常由软件、数据库和数据库管理员组成。
- 数据库管理员:数据库管理员负责全面管理和控制数据库系统。
2、什么是元组、码、候选码、主码、外码、主属性、非主属性
- 元组:元组是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列是一个属性,在二维表中,元组也称为行。
- 码:码就是能唯一识别实体的属性,对应表中的列。
- 候选码:若关系中的某一属性或属性组的值能唯一识别一个元组,而其任何子集都不能再表示,则称该属性组为候选码。在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
- 主码:主码也叫主键,主码是从候选码中选出来的,一个实体集中只能有一个主码,但可以有多个候选码。
- 外码:外码也叫外键,如果关系中的一个属性是另外一个关系的主码,则这个属性是外码。
- 主属性:候选码中出现过的属性称为主属性,比如工人(工号,身份证号,姓名,性别,部门)。显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
- 非主属性:不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
3、主键和外键有什么区别?
- 主键:主键用于唯一表示一个元组,不能有重复,不允许有空,一个表只能有一个主键。
- 外键:外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值,一个表可以有多个外键。
4、数据库的范式
- 第一范式(1NF):属性(回应表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再被分为多个其他字段了(原子性)。1NF是所有关系型数据库的最基本要求,也就是说关系型数据库中创建的表一定满足第一范式。
- 第二范式(2NF):2NF在1NF的基础之上,消除了非主属性对码的部分函数依赖。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
- 第三范式(3NF):3NF在2NF的基础之上,消除了非主属性对码的传递依赖。解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系R(学号 ,姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合3NF的要求。
- 总结:1NF:属性不可再分。2NF:1NF的基础之上,消除了非主属性对于码的部分函数依赖。3NF:3NF在2NF的基础之上,消除了非主属性对于码的传递函数依赖 。
5、什么是函数依赖?部分函数依赖?完全函数依赖?传递函数依赖?
- 函数依赖(functional dependency): 若在一张表中,在属性(属性组)X的值确定的情况下,必定能确定属性Y的值,那么就可以说Y函数依赖于X,写作X → Y。
- 部分函数依赖:如果X → Y,并且存在X的一个真子集X0,使得X0→ Y,则称Y对X部分函数依赖。比如学生基本信息表R中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号)。
- 完全函数依赖(Full functional dependency) :在一个关系中,若某个非主属性数据依赖于全部关键字称之为完全函数依赖。比如学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖于(学号,班级)。
- 传递函数依赖(transitive functional dependency) :在关系模式R(U)中,设X,Y,Z是U的不同的属性子集,如果X确定Y、Y确定Z,且有X不包含Y,Y不确定X,(X∪Y)∩Z=空集合,则称Z传递函数依赖于X。传递函数依赖会导致数据冗余和异常。传递函数依赖的Y和Z子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系R(学号 ,姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。
6、什么是存储过程?
我们可以把存储过程看成是一些SQL语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候非常实用,比如很多时候我们完成一个操作可能需要写一大串SQL语句,这时候我们可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程单纯比SQL语句执行要快,因为存储过程是预编译过的。
但部分公司存储过程应用不多,因为存储过程难以调试和扩展,而且没有移植性,还会消耗数据库资源。
7、drop 、delete和truncate区别?
- drop(丢弃数据):drop table(表名),直接删除表。
- truncate(清空数据):truncate table(表名),只删除表中的数据,再插入数据的时候自增长id又从1开始,在清空表中数据的时候使用。
- delete(删除数据):delete from 表名 where 列名=值,删除某一列的数据,如果不加where子句和truncate table表名作用类似。
- 总结:truncate和不带where子句的delete、以及drop都会删除表内的数据,但是truncate和delete只删除数据不删除表的结构(定义),执行drop语句,此表的结构也会删除,也就是执行drop以后对应的表不复存在。
- truncate和drop属于DDL(数据定义语言)语句,操作立即生效,原数据不放在rollback segment中,不能回滚,操作不触发trigger。而delete语句是DML(数据库操作语言)语句,这和操作会放到rollback segment中,事务提交之后才生效。
- 执行速度:drop>truncate>delete
8、DML语句和DDL语句的区别。
- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括插入(insert)、更新(update)、删除(delete)和查询(select),是开发人员日常使用最频繁的操作。
- DDL(Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语句。它和DML语言的最大区别是DML只是对表内部数据的操作,而不涉及表的定义、结构的修改,更不会涉及到其他对象。DDL语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
9、数据库设计通常分为哪几步?
- 需求分析:分析用户的需求,包括数据、功能和性能需求。
- 概念结构设计:主要采用E-R模型进行设计,包括画E-R图。
- 逻辑结构设计:通过将E-R图转换为表,实现从E-R模型到关系模型的转换。
- 物理结构设计:主要是为所设计的数据库选择合适的存储结构和存取路径。
- 数据库实施:包括编程、测试和试运行。
- 数据库运行和维护:系统的运行与数据库的日常维护。
10、事务的ACID特性是什么?★
- 原子性:事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成、要么完全不起作用。
- 一致性:执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的。
- 隔离性:并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的。
- 持久性:一个事务被提交之后。它对数据库的数据的改变是持久的。即使数据库发生故障也不应该对其有任何影响。
11、并发事务带来哪些问题?
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对统一数据进行操作)并发虽然是必须的,但可能会导致以下的问题:
- 脏读(Dirty read):当一个事务正在访问数据并且对这个数据进行了修改,而这种修改还没有提及到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据脏数据所作的操作可能是不正确的。(其他事务读取了修改以前的数据,涉及操作为修改-查询)
- 丢失修改(Lost to modify):指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。(两个事务同时修改,后一个事务修改结果覆盖了之前修改的结果,涉及的操作为修改-修改)
- 不可重复读(Unrepeatableread):指在一个事务内多次读同一个数据,在这个事务还没结束的时候,另一个事务也访问了该数据并修改,导致第一个事务两次读取的数据不一样,称为不可重复读。(第一个事务多次读的间隙,第二个事务修改,导致第一个事务不可重复读,涉及的操作有查询-修改-查询)
- 幻读(Phantom read):幻读和不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务就会发现多了一些原本不存在的记录,就好像存在了幻觉一样,所以称为幻读。(第一个事务读取过程中,第二个事务增加或删除,导致第一个事务读取结果不一致,涉及的操作有查询-增加/删除-查询)
12、不可重复读和幻读有什么区别?
不可重复读的重点是修改,幻读的重点在于新增或者删除。
13、事务的隔离级别有哪些?MySQL的默认隔离级别是?
SQL标准定义了四个隔离级别:
- Read-uncommitted(读取未提交):最低的隔离级别,允许读取尚未提交的数据变更,可能导致脏读、不可重复读和幻读)
- Read-committed(读取已提交):允许读取并发事务已经提交的数据,可以阻止脏读。但不可重复读和幻读仍有可能发生。
- Repeatable-read(可重复读):对同一字段的多次读取结果都是一致的,除非数据是被本身事务所修改,可以阻止脏读和不可重复读,幻读仍有可能发生。
- Serializable(可串行化):最高的隔离级别,完全服从ACID的隔离级别,所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,可以阻止脏读、不可重复读以及幻读。
- mySQL的默认隔离级别是可重复读。
14、乐观锁和悲观锁的区别
- 悲观锁:总是假设最坏的情况,每次去拿数据都认为别人会修改,所以每次在拿数据时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其他线程阻塞,用完后再把资源转让给其他线程)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁;读锁,写锁等,都是在操作之前先上锁。Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
- 乐观锁:总是假设最好的情况,每次去拿数据时都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。乐观锁使用多读的应用类型,这样可以提高吞吐量。想数据中提供的类似write_condition机制,其实都是提供的乐观锁。在Java中java.util.concurrent.atomic包下面的原子变量类就是使用了乐观锁的一种实现方式CAS实现的
- 两种锁的使用场景:乐观锁适用于多读场景;悲观锁适用于多写场景。
15、乐观锁的两种实现方式。
- 版本号机制:一般在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值加一,当线程A要更新数据时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中version值相等时才更新,否则重试更新操作,直到更新成功。(提交版本必须大于记录版本才能执行更新)
举一个简单的例子: 假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 (50(100-$50 )。在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 (20(100-$20 )。操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
-
CAS算法:compare和swap(比较与交换),是一种有名的无锁算法。无锁编程,即不使用锁的情况下实现多线程之间的变量同步。也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization),CAS算法涉及三个操作数①需要读写的内存值V,②进行比较的值A,③拟写入的新值B。④当且仅当V的值等于A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作),一般情况下是一个自旋操作,即不断重试。
16、乐观锁的缺点。
- ABA问题:如果一个变量V初次读取时是A值,并且在准备赋值时候检查到它仍然为A,那我们就能说明它的值没有被其他线程修改过吗?很明显不能,因为这段时间,它的值有可能被改为其他值,然后又改回A,那CAS操作就误以为它从来没有被修改过。这个问题被称为CAS操作的 "ABA"问题。JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力,其中的 compareAndSet 方法就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
- 循环时间开销大:自旋CAS(也就是不成功就一直循环执行直到成功),如果长时间不成功,会给CPU带来非常大的执行开销,如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
- 只能保证一个共享变量的原子操作:CAS只对单个共享变量有效,当擦欧总涉及跨多个共享变量时CAS无效。但是从 JDK 1.5开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作。
17、什么是数据库索引?
- 数据库索引:是数据库管理系统中的一个排序的数据结构,以协助快速查询、更新数据库表中数据。
- 实现:索引的实现通常使用B树和B+树,加速了数据访问,因为存储引擎不会再去扫描整张表得到需要的数据;相反,它从根节点开始,根节点保存了子节点的指针,存储引擎会根据指针快速寻找数据。
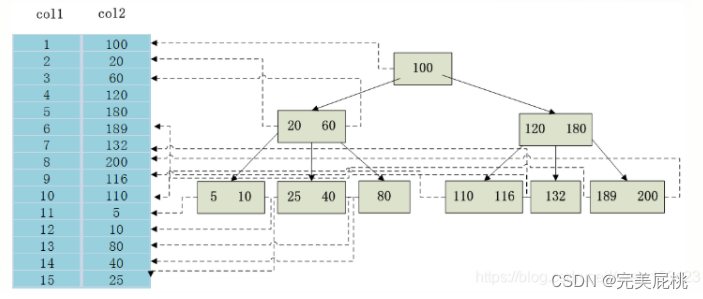
上图显示了一种索引方式。左边是数据库中的数据表,有col1和col2两个字段,一共有15条记录;右边是以col2列为索引列的B_TREE索引,每个结点包含索引的建值和对应数据表地址的指针,这样就可以通过B_TREE在O(logn)的时间复杂度内获取相应的数据,这样明显加快了检索速度。为表设置索引要付出代价,一是增加了数据库的存储过程,二是在插入和修改数据时要花费较多的时间(因为索引也要随之变动)。
18、索引的优缺点?
- 优点:①创建索引可以大大提高系统的性能;②通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。③可以大大提升数据库的检索速度,这是创建索引最主要的原因;③可以加速表和表之间的连接,特别是在实现数据的参考完整性方面有特别有意义;④在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间;⑤通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。
- 缺点:①创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。②索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么所需的空间就会更大。③当对表中的数据进行增加,删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
19、一般来说,需要在哪些列上创建索引?
- 在经常需要搜索的列上,可以加快搜索的速度。
- 在作为主键的列上,强制该列的唯一性和组织表中数据的排列结构。
- 在经常用在连接的列上,这些列主要是一些外键,可以加快连接的速度。
- 在经常需要根据范围检索的列上创建索引,因为索引已经排序,其指定的范围是连续的。
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序的查询时间。
- 在经常使用where子句中的列上面创建索引,加快条件判断的速度。
20、一般来说,那些列上不应该创建索引?
- 在查询中很少使用或者参考的列不应该创建索引。
- 对于很少数据值的列也不应该增加索引。
- 对于定义text,image,和bit数据类型的列不应该增加索引,因为这些列数据量要么相当大,要么取值很小。
- 当修改性能远远小于检索性能时,不应该创建索引。修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能。因此,当修改性能远远大于检索性能时,不应该创建索引。
21、数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。
- 唯一索引:不允许其中任何两行具有相同索引值的索引。当现有的数据中存在重复的键值,大多数数据库不允许将新创建的唯一索引与表一起保存。数据库还可能防止添加将在表中创建重复键值的新数据。例如,如果在 employee 表中职员的姓(lname)上创建了唯一索引,则任何两个员工都不能同姓。
- 主键索引:数据库表中经常有一列或几列组合,其值唯一标识表中的每一行。该列称为表的主键。在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
- 聚集索引:在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同,一个表只能包含一个聚集索引。如果某索引不是聚集索引,则表中行的物理顺序与键值的逻辑顺序不匹配。与非聚集索引相比,聚集索引通常提供更快的数据访问速度。(跟男朋友吃烤鱼去咯,晚点接着写~
相关文章:
数据分析面试题(2023.09.08)
数据分析流程 总体分为四层:需求层、数据层、分析层和结论层 一、统计学问题 1、贝叶斯公式复述并解释应用场景 公式:P(A|B) P(B|A)*P(A) / P(B)应用场景:如搜索query纠错,设A为正确的词,B为输入的词,那…...

jenkins 报错fatal:could not read Username for ‘XXX‘:No such device or address
#原因:机器做迁移,或者断电,遇到突发情况 #解决: 一.排查HOME和USER环境变量 可以在项目执行shell脚本的时候echo $HOME和USER 也可以在构建记录位置点击compare environment 对比两次构建的环境变量 二.查看指定节点的git凭证 查…...
LRU算法之我见
文章目录 一、LRU算法是什么?二、使用原理三、代码实现总结 一、LRU算法是什么? LRU算法又称最近最少使用算法,它是是大部分操作系统为最大化页面命中率而广泛采用的一种页面置换算法。是一种缓存淘汰策略,根据使用频率来淘汰无用…...
)
【第20例】华为 IPD 体系 | IPD 的底层思考逻辑(限制版)
目录 简介 更新情况 IPD体系 CSDN学院 专栏目录 作者简介 简介 最近随着华为 Mate 60 系列的爆火发布。 这家差不多沉寂了 4 年的企业再次映入大众的眼帘。 其实,华为手机业务发展的元年最早可以追溯...
spaCy库的实体链接踩坑,以及spaCy-entity-linker的knowledge_base下载问题
问题1. spacy Can’t find factory for ‘entityLinker’ 1)问题 写了一个实体链接类,代码如下: nlp spacy.load("en_core_web_md")class entieyLink:def __init__(self, doc, nlp):self.nlp nlpself.doc self.nlp(doc)# Che…...
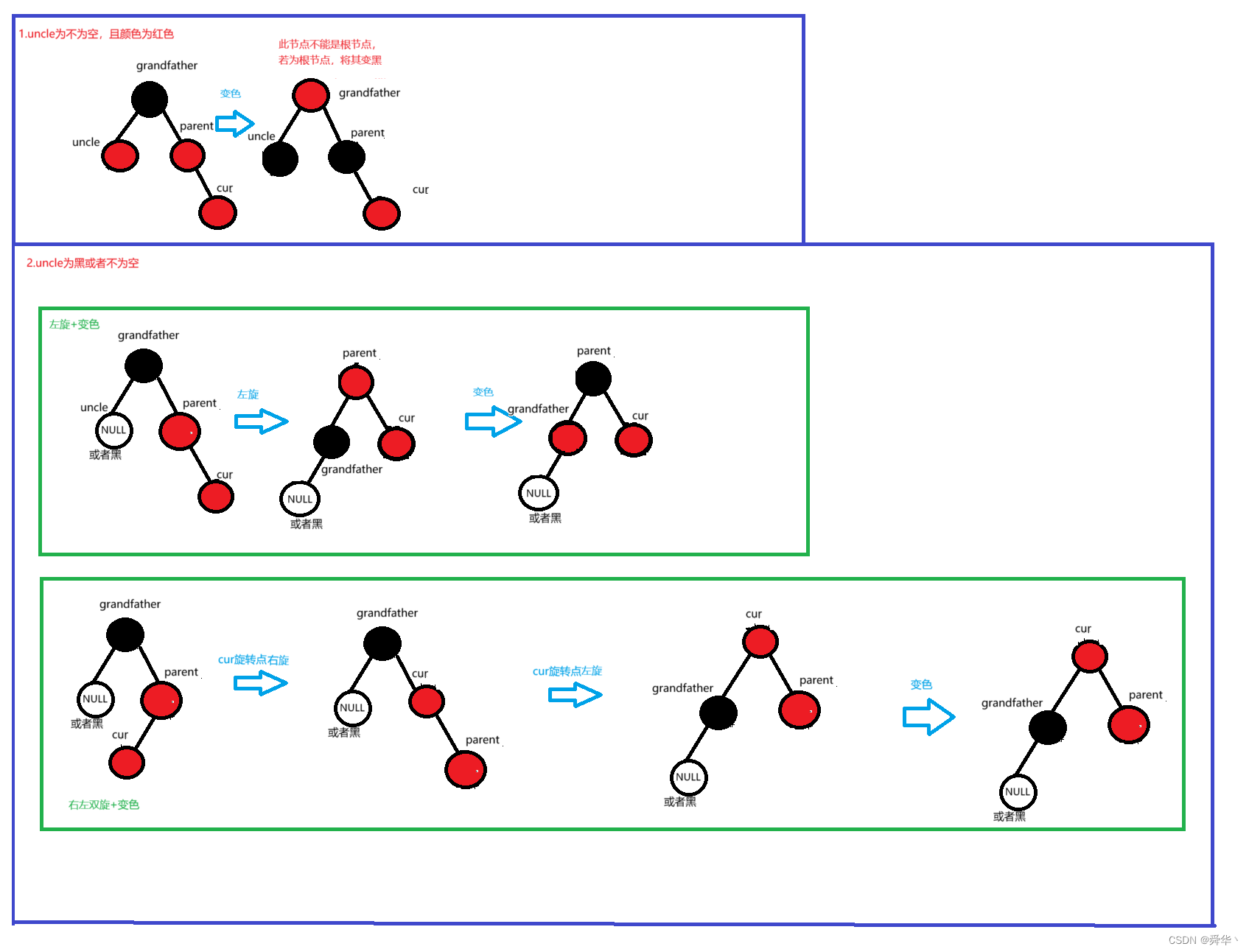
【数据结构】红黑树的插入与验证
文章目录 一、基本概念1.时代背景2. 基本概念3.基本性质 二、实现原理1. 插入1.1变色1.2旋转变色①左旋②右旋③右左双旋④左右双旋 2.验证 源码总结 一、基本概念 1.时代背景 1972年鲁道夫拜尔(Rudolf Bayer)发明了一种数据结构,这是一种特殊的B树4阶情况。这些树…...
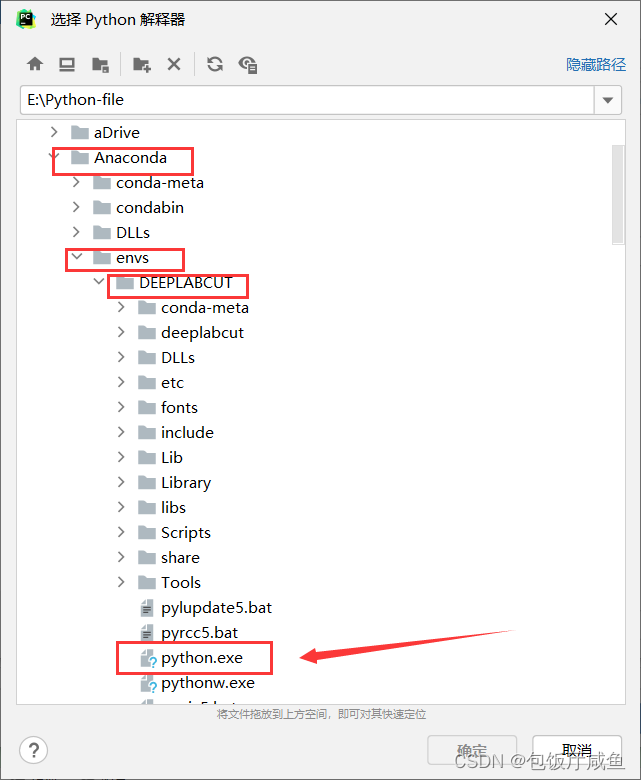
Pycharm----将Anaconda建立的环境导入
首先打开项目设置,点击添加 随后点击现有环境,点击三个。。。号进行添加 最后找到你Anaconda安装文件夹,envs找到你建立的环境名称,找到python.exe将它导入即可让现在的python环境为你建立的环境,同时还需要更改终端方…...

数字花园的指南针:微信小程序排名的提升之道
微信小程序,是一片数字花园,其中各种各样的小程序竞相绽放,散发出各自独特的芬芳。在这个花园中,排名优化就像是精心照料花朵的园丁,让我们一同走进这个数字花园,探寻如何提升微信小程序的排名优化…...

LRU与LFU的c++实现
LRU 是时间维度上最少使用 维持一个链表,最近使用的放在表头 淘汰表尾 LFU 是实际使用频率的最少使用 每一个对应的频率维持一个链表, 淘汰最低频率的最后一个 1. LRU LRU(Least Recently Used,最近最少使用)是一种常…...

什么是Docker和Docker-Compose?
Docker的构成 Docker仓库:https://hub.docker.com Docker自身组件 Docker Client:Docker的客户端 Docker Server:Docker daemon的主要组成部分,接受用户通过Docker Client发出的请求,并按照相应的路由规则实现路由分发…...
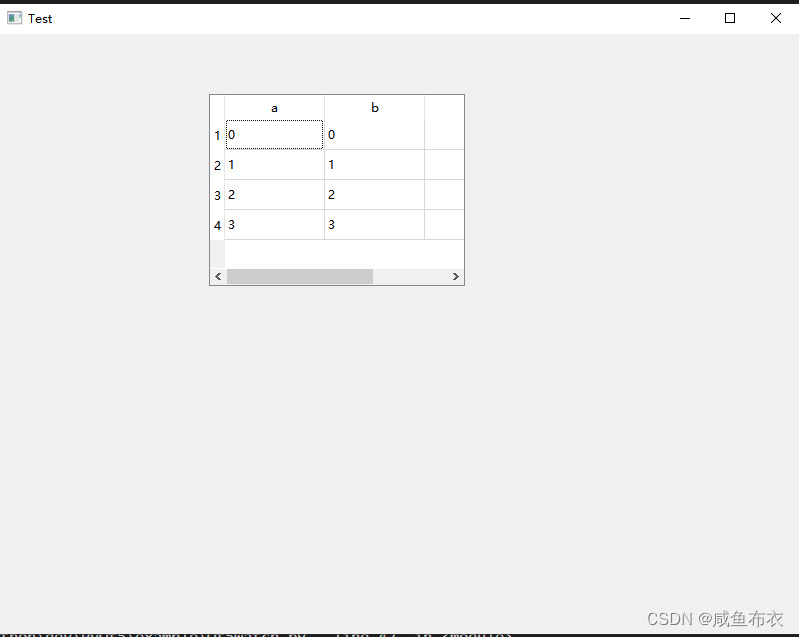
三.listview或tableviw显示
一.使用qt creator 转变类型 变形为listview或tableviw 二.导出ui文件为py文件 # from123.py 为导出 py文件 form.ui 为 qt creator创造的 ui 文件 pyuic5 -o x:\xxx\from123.py form.uifrom123.py listview # -*- coding: utf-8 -*-# Form implementation generated fro…...
【算法】一文带你从浅至深入门dp动态规划
文章目录 一、前言二、动态规划理论基础1、基本概念2、动态规划五部曲【✔】3、出错了如何排查? 三、实战演练🗡0x00 斐波那契数0x01 第N个泰波那契数0x02 爬楼梯0x03 三步问题0x04 使用最小花费爬楼梯⭐解法一解法二 0x05 解码方法* 四、总结与提炼 一、…...

超简单免费转换ape到flac
1. 安装最新版的ffmpeg 2. 安装cywin环境 3. 设置path到ffmpeg export PATH$PATH:"PATH/TO/FFMPEG/BIN" 4.到ape所在的目录,执行以下命令 find . -iname "*.ape" | while read line; do fb${line::-4}; fn"$fb.flac";echo ffm…...

JavaScript混淆加密
什么是JS混淆加密? JavaScript混淆加密是一种通过对源代码进行变换,使其变得难以理解和分析的技术。它的目标是增加攻击者破解代码的难度,同时保持代码的功能不受影响。混淆加密的目的是使代码难以逆向工程,从而防止攻击者窃取知…...
Java8特性-Lambda表达式
📕概述 在Java 8中引入了Lambda表达式作为一项重要的语言特性,可以堪称是一种语法糖。Lambda表达式使得以函数式编程的方式解决问题变得更加简洁和便捷。 Lambda表达式的语法如下: (parameters) -> expression (参数) -> {代码}其中&…...
通过Power Platform自定义D365CE业务需求 - 1. Microsoft Power Apps 简介
Microsoft Power Apps是一个趋势性的、无代码和无代码的商业应用程序开发平台,配有一套应用程序、服务和连接器。其数据平台为构建适合任何业务需求的自定义业务应用程序提供了快速开发环境。随着无代码、少代码应用程序开发的引入,任何人都可以快速构建低代码应用程序,并与…...
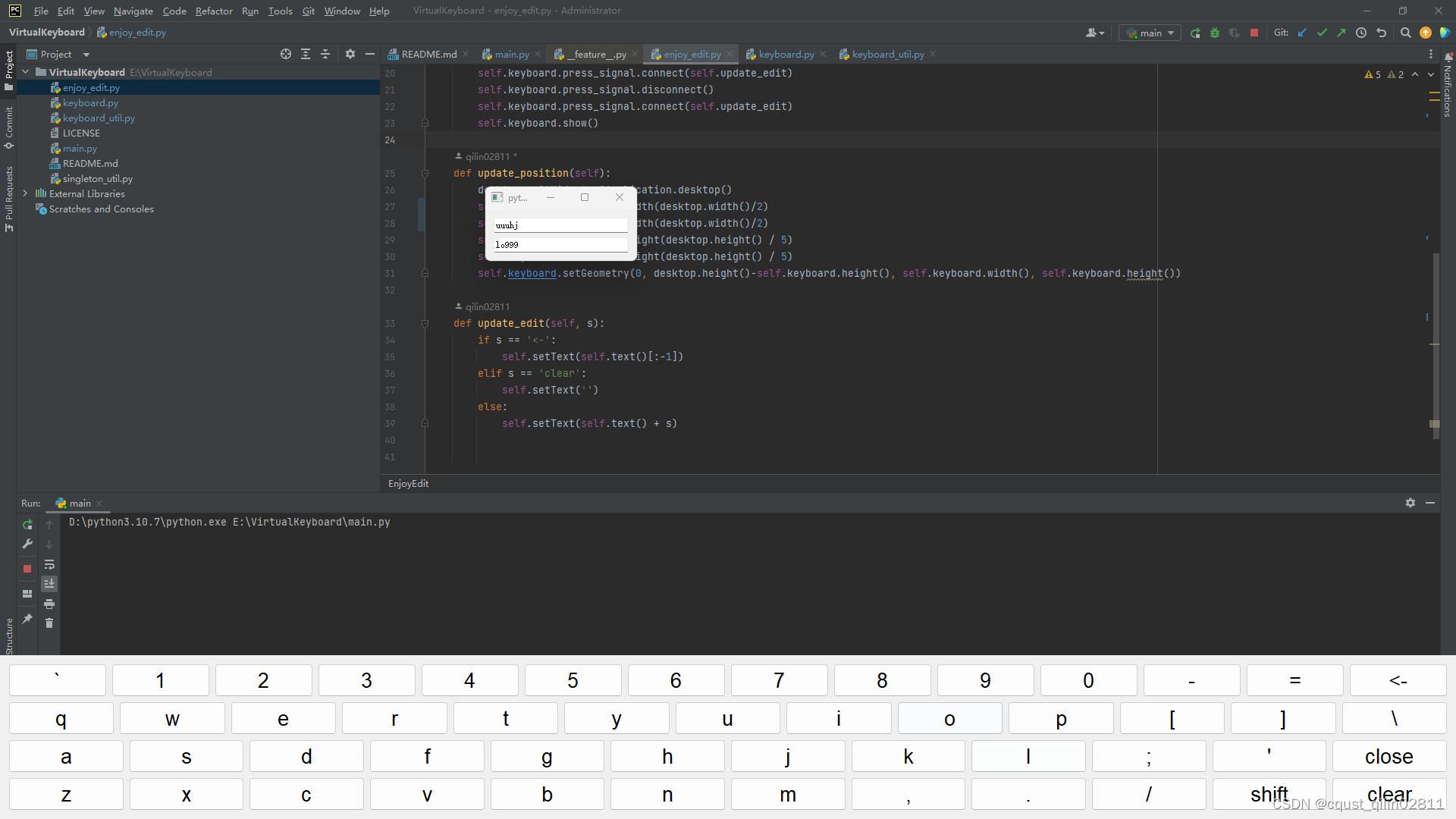
简易实现QT中的virtualkeyboard及问题总结
文章目录 前言:一、虚拟键盘的实现综合代码 二、为什么选用QWidget而不适用QDialog实现键盘三、从窗体a拉起窗体b后,窗体b闪退问题的探讨四、关闭主窗口时子窗口未关闭的问题 前言: 本文章主要包含四部分: 虚拟键盘的实现&#…...

景联文科技可为多模态语音翻译模型提供数据采集支持
8月22日Facebook的母公司Meta Platforms发布了一种能够翻译和转录数十种语言的人工智能模型——SeamlessM4T,可以在日常生活中或者商务交流中为用户提供更便捷的翻译和转录服务。 相较于传统的文本翻译,这项技术的最大区别在于它可以实现端到端的语音翻译…...

定时器分批请求数据
<!DOCTYPE html> <html><script>//需要分页的数组let arr [1,2,3,4,5,6,7,8,9,10]//分割数组,每页3条splitArr(arr,4)/*** 分割数组*/function splitArr(idList,size){//当前页数let num 1//共多少页let count Math.ceil(idList.length / siz…...

【华为OD机试python】报数游戏【2023 B卷|100分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 100个人围成一圈,每个人有一个编码,编号从1开始到100。 他们从1开始依次报数,报到为M的人自动退出圈圈,然后下一个人接着从1开始报数, 直到剩余的人数小于M。 请问最后剩余的人在原先…...

ARM内存访问指令LDRB与LDREX详解及应用
1. ARM内存访问指令概述在嵌入式系统开发中,对内存的高效访问是保证程序性能的关键。ARM架构提供了丰富的内存访问指令集,其中LDRB和LDREX是两种具有代表性的指令。LDRB(Load Register Byte)用于从内存加载字节数据,而…...

从Solyndra事件看美国太阳能产业转型与能源创新体系构建
1. 从Solyndra事件看美国太阳能产业的十字路口2011年秋天,加州弗里蒙特市,一家名为Solyndra的太阳能公司大门前,联邦官员正将一箱箱文件搬上卡车,而当地几乎所有的电视台摄像机都记录下了这一幕。这家曾获得美国能源部5.35亿美元贷…...

期货交易者最大的心魔:为什么你总想“落袋为安”?从海桑的交易系统看盈利奔跑
期货交易者的盈利困境:如何克服"落袋为安"的本能冲动 在期货交易的世界里,有一种奇怪的现象:许多交易者能够保持不错的胜率,却始终无法实现账户的持续增长。他们往往在盈利时过早离场,而在亏损时却坚持持有&…...

Taotoken在数据预处理与分析脚本中调用大模型的集成案例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken在数据预处理与分析脚本中调用大模型的集成案例 应用场景类,设想一个数据科学家使用Python脚本进行数据分析时…...
)
Linux驱动开发避坑指南:手把手教你实现三种mmap内存映射(附完整代码)
Linux驱动开发实战:三种mmap内存映射方案深度解析与性能对比 在嵌入式系统和图形处理领域,直接访问内核内存的需求日益增长。想象一下这样的场景:你正在开发一个视频处理驱动,需要将摄像头采集的高清帧数据传输到用户空间进行实时…...

038翻转二叉树
翻转二叉树 题目链接:https://leetcode.cn/problems/invert-binary-tree/description/?envTypestudy-plan-v2&envIdtop-100-liked 我的解答: public TreeNode invertTree(TreeNode root) {if(rootnull){return null;}TreeNode temproot.left;roo…...
从混乱到秩序:如何用TrguiNG汉化版重塑你的Transmission下载管理体验
从混乱到秩序:如何用TrguiNG汉化版重塑你的Transmission下载管理体验 【免费下载链接】TrguiNG Transmission WebUI 基于 openscopeproject/TrguiNG 汉化和改进 项目地址: https://gitcode.com/gh_mirrors/tr/TrguiNG 你是否还在为Transmission简陋的原生Web…...
)
老笔记本焕发第二春:微星GT60升级GTX1060保姆级避坑指南(含硬件ID修改)
微星GT60笔记本升级GTX1060全流程实战:从硬件改造到驱动破解 当手头的微星GT60笔记本逐渐跟不上现代游戏需求时,许多玩家会考虑升级显卡来延续它的使用寿命。MXM接口的GTX1060显卡因其性价比和性能表现成为热门选择,但整个升级过程充满技术陷…...

新手避坑指南:用Virtuoso和Calibre做DRC/LVS检查时,IO Pad和电源连接的那些坑
数字后端验证实战:Virtuoso与Calibre中的DRC/LVS避坑指南 第一次用Virtuoso和Calibre做DRC/LVS检查的新手工程师,往往会在IO Pad和电源连接上栽跟头。这些看似基础的问题,轻则导致验证失败,重则影响芯片功能。本文将结合SIMC 0.18…...

基于MCP协议与本地全文检索的电子元件文档AI查询系统
1. 项目概述:为LLM构建一个本地化的电子元件文档搜索引擎如果你是一名嵌入式工程师、硬件开发者,或者像我一样,经常需要和德州仪器(TI)、意法半导体(ST)、亚德诺(ADI)这些…...