MNIST手写数字辨识-cnn网路 (机器学习中的hello world,加油)
用PyTorch实现MNIST手写数字识别(非常详细) - 知乎 (zhihu.com)
参考来源(这篇文章非常适合入门来看,每个细节都讲解得很到位)
一、模块函数用法-查漏补缺:
1.关于torch.nn.functional.max_pool2d()的用法:
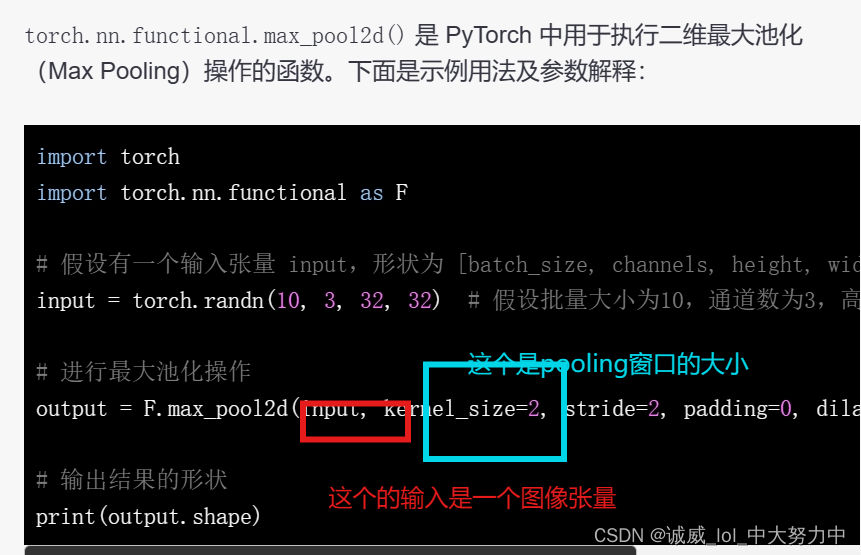

上述示例中,输入张量 input 经过最大池化操作后,使用了 kernel_size=2 和 stride=2,所以输出张量 output 的高度和宽度均为输入的一半(32/2=16)。
2.pytorch中的view函数的用法:
http://t.csdn.cn/AAhdH
这一篇文章写得非常好
3.关于f.log_softmax(x,dim = -1)这个先进行softmax,再取log的函数的讲解:
http://t.csdn.cn/GIJ7g
这篇文章讲解得非常好,补充一点,dim的default值和softmax一样,都是-1,也就是计算最里面那个维度的softmax的结果
4.原来loss和counter计数器数组有这个作用:
train_losses = []
train_counter = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
5.关于F.nll_loss这个损失函数:
http://t.csdn.cn/ZoruZ
总的来说就是一句话“损失函数 nn.CrossEntropyLoss() 与 NLLLoss() 相同, 唯一的不同是它为我们去做 log_softmax.”
这篇文章讲述得非常清楚
6.关于loss.item()的作用:
http://t.csdn.cn/AvrnJ
这篇文章讲得非常清楚:
就是输出loss这个数值,但是呢,是用非常高的精度进行输出的,一般我们进行一各batch的训练后,就会得到这一次的loss单个数值,需要输出的话,最好就用item()
7.with torch.no_grad()的用法:
http://t.csdn.cn/STaKp
这篇文章讲述得非常清楚,就是不会进行gradient_descend操作,极大的节省了运算开销
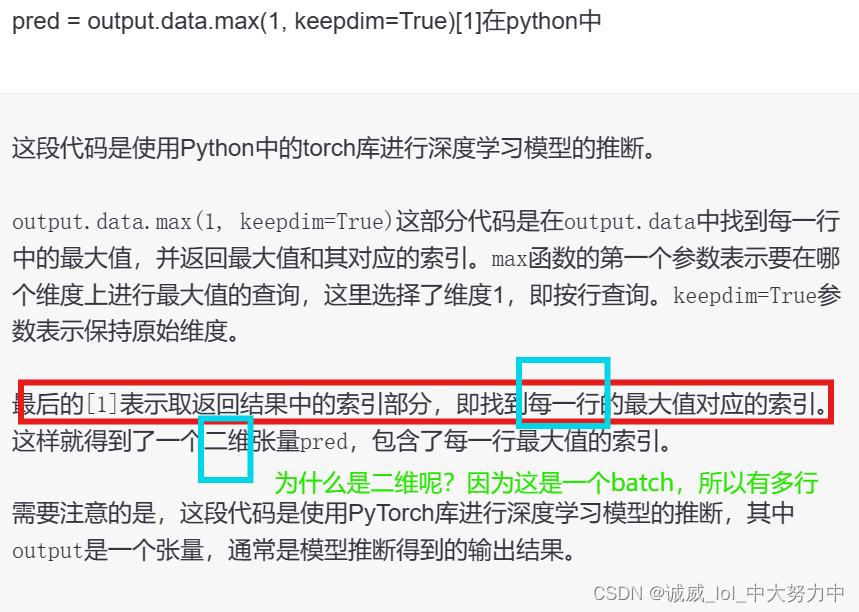
8.data.max()函数的用法:
http://t.csdn.cn/aBmin
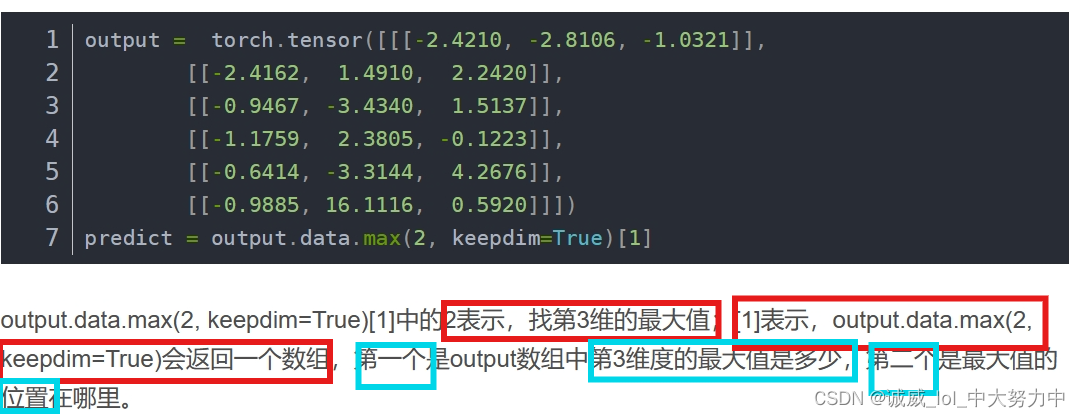
上面那里讲得不太好,还是chatGPT比较优秀
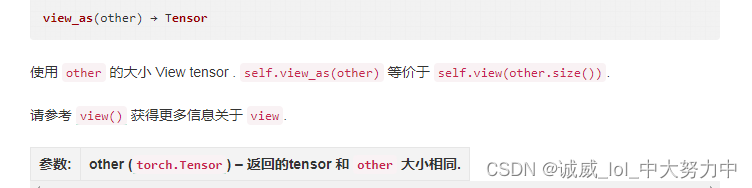
9.data.view_as()的用法:

10.torch.eq的用法:
http://t.csdn.cn/Tb0kY
这篇文章讲述得非常清楚,也就是对张量中的数值逐个进行比较,
返回的是同样形状的数据,每个位置要么True要么False,可以用.sum()求和得到True的总数
顺便提一下torch.sum的用法,
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(x.sum())输出的结果是21
二、各个部分的代码和注释:
#设置环境
import torch
import torchvision
from torch.utils.data import DataLoader#准备数据集
#1.设置必要的参数
n_epochs = 3
batch_size_train = 64 #所以呢,这个64其实就是下面train时候的batch_size大小
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
log_interval = 10 #这个就是后面用来输出的间隔
random_seed = 1
torch.manual_seed(random_seed)
#利用pytorch直接加载对应的train_data集 和 test_Data集
train_loader = torch.utils.data.DataLoader( #这里调用的是torch.utils.data.DataLoader的对象,实例化出train_dataloader#限免设置各个参数,比如,第一个就是Dataset参数,这里是引用MNIST作为参数,并且设置MNIST中的各个参数torchvision.datasets.MNIST('./data/', train=True, download=True, #设为train数据+下载transform=torchvision.transforms.Compose([ #对数据进行transform变换torchvision.transforms.ToTensor(), #先变tensor后进行Normlizetorchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size_train, shuffle=True) #这个loader的后两个参数batch_size和shuffle
#同样的道理设置test_data_loader
test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('./data/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size_test, shuffle=True)#查看一条数据:
examples = enumerate(test_loader) #enumerate返回一个(index,data)的元组,本身是一个迭代器,可以用于遍历test_loader
batch_idx, (example_data, example_targets) = next(examples)
print(example_targets) #输出测试(这里的test是有answer作为label的)的1000各answer
print(len(example_targets)) #总共1000各target
print(example_data.shape) #一共有1000张28*28的黑白灰度图#利用matplotlib进行绘制得到某些数据的可视化结果
import matplotlib.pyplot as plt
fig = plt.figure() #创建一个fig对象
for i in range(6):plt.subplot(2,3,i+1) #按照2行3列绘制6张图片plt.tight_layout() #设置紧密相连plt.imshow(example_data[i][0], cmap='gray', interpolation='none') #利用imshow在下方直接输出图像plt.title("Ground Truth: {}".format(example_targets[i]))#设置标题,就是label的数值plt.xticks([])plt.yticks([])
plt.show()#定义neural network的结构
import torch.nn as nn #引入neural network的库
import torch.nn.functional as F #引入nn总的常用Func
import torch.optim as optim #引入torch中的optimizerclass Net(nn.Module): #继承nn中的moduledef __init__(self): #定义这个网络结构的构造函数super(Net, self).__init__() #继承nn.Module的初始化构造self.conv1 = nn.Conv2d(1, 10, kernel_size=5)#参数:输入channel、输出channel、卷积核5*5(filters),strdie(default =1),padding(default=0)#所以1*28*28的图像通过后,10*21*21(10是filters的数量)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d() #这个函数http://t.csdn.cn/xK6og这篇文章讲得挺好的,就是让部分filters在某一层不工作,效果是有效防止overfitself.fc1 = nn.Linear(320, 50) #定义一个320 -->50 的Linear层函数self.fc2 = nn.Linear(50, 10) #定义一个50 -->10 的Linear层函数def forward(self, x): #下面就是直接进行整个network的作用过程定义了 , 输入1*28*28的灰度图x = F.relu(F.max_pool2d(self.conv1(x), 2)) #经过一个conv1卷积层后,经过1次2*2窗口的pooling得到,默认??padding=1,之后再算好了x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2)) #再通过conv2之后->通过conv2_drop->通过max_pool2dx = x.view(-1, 320) #第二维是320,并自动计算第一维x = F.relu(self.fc1(x)) #通过一个linear层之后,又通过一个relu的激活函数,最后输出的是第二维是50的结果x = F.dropout(x, training=self.training) #只有在training模式下才会调用dropout(让某些神经元“熄火”喵)x = self.fc2(x) #再让x通过一个linear层,输出的结果是2维的数据,第二维(共10列)return F.log_softmax(x) #最后通过对最里面那一层softmax层后,取log对数#创建model对象+设置optimizer优化器
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,momentum=momentum) #lr和momentum都是上面设置好的
#设置用于存储的数组结构:
train_losses = []
train_counter = [] #估计就是一个计数器的作用
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
#print(test_counter)输出[0,60000,120000,180000]不知道再干啥,反正上面的n——epoch==3#定义这个train函数:
def train(epoch): #这里的epoch是传递进来的参数network.train() #开启train模式for batch_idx, (data, target) in enumerate(train_loader):#迭代器:以batch为单位逐个从train_loader中获取 索引、data图像数据、label作为target数据optimizer.zero_grad() #因为torch中的grad是累加的,所以需要在每个batch训练之前利用optimizer.zero_grad()清零output = network(data) #将data图像数据通过network网络得到output输出结果loss = F.nll_loss(output, target) #这个loss_func只是比cross_entropy少一个对输入数据的log_softmax操作loss.backward()optimizer.step() #loss.backward + optimizer.step()常规更新模型参数的操作if batch_idx % log_interval == 0: #下面都是没啥用的间隔输出操作,上面设置的log_interval =10#每经过10各batch处理输出一次:#第几个epoch,第几个图像,总共的train有多少图像,已经完成了百分之几的batch,这个batch的loss值print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, batch_idx * len(data), len(train_loader.dataset),100. * batch_idx / len(train_loader), loss.item())) #将这个batch的loss值添加到train_losses数组中(注意,这里好像是每隔10个batch记录一次loss)train_losses.append(loss.item())train_counter.append( #在counter中记录这个batch在考虑epoch情况下的位置(batch_idx*64) + ((epoch-1)*len(train_loader.dataset))) #这个64是train时候的batch_size上面写了#将当前的network的参数状态state_dice存储到对应的路径下, 同时optimizer的状态也要存储?why感觉optim没啥用torch.save(network.state_dict(), './model.pth')torch.save(optimizer.state_dict(), './optimizer.pth')#train(1) #传递参数epoch=1进行train一次
#这里的train有个地方很有意思,它只是输出loss,没有利用argmax计算出对应的one-hot vec,从而没法和label进行比较得到acc#定义test函数,并且进行test测试 (不用想,大概率和train的内容没有太大的区别,不过是少了backward和step的更新)
def test():network.eval() #开启model的eval模式test_loss = 0 #设置loss和acc初值correct = 0with torch.no_grad(): #不计算SGDfor data, target in test_loader: #非enumerate,非迭代器版本,不会返回索引,获取data图像batch和target的labels数值output = network(data) #调用network获取output结果test_loss += F.nll_loss(output, target, size_average=False).item() #这里计算出这一次的 output和target之间的losspred = output.data.max(1, keepdim=True)[1] #通过data.max函数获取对应的索引,这是一个索引的数组,因为是一个batch一起预测的correct += pred.eq(target.data.view_as(pred)).sum() #如果pred和target数组对应位置比较,计算总共相等的位置的数量test_loss /= len(test_loader.dataset) #计算平均的losstest_losses.append(test_loss) #将这一次的平均loss加入到test_losses数组中#输出:#这一次的平均loss,总数中正确预测的数目,正确率print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))#test()#调用上述定义的test函数#再调用一次test()
test()
for epoch in range(1, n_epochs + 1): #调用n_epochs个数的train和测试结果train(epoch)test()#下面对上述获取到的数据进行图像的绘制
#绘制图像一开始出错了,我怀疑是我多进行了一次test(),导致x和y的大小不对应
import matplotlib.pyplot as plt
fig = plt.figure() #创建figure对象
plt.plot(train_counter, train_losses, color='blue') #绘制曲线图,x是train计数,y是trainloss
#plt.scatter(test_counter, test_losses, color='red') #绘制散点图,x是test_counter计数,y是test_losses数据
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen') #x轴标题
plt.ylabel('negative log likelihood loss') #y轴标题
plt.show() #绘制结果#抽取几个直观的例子进行测试:examples = enumerate(test_loader) #获取test_loader的迭代器
batch_idx, (example_data, example_targets) = next(examples) #获取第一个test_loader中的batch
with torch.no_grad():output = network(example_data) #将example_data数据通过network得到output
fig = plt.figure() #创建figure对象
for i in range(6): #构建2行3列的图像排列plt.subplot(2,3,i+1)plt.tight_layout() #紧密排列plt.imshow(example_data[i][0], cmap='gray', interpolation='none') #利用imshow输出example图像plt.title("Prediction: {}".format(output.data.max(1, keepdim=True)[1][i].item())) #输出预测结果,结果非常美妙plt.xticks([])plt.yticks([])
plt.show() #绘制-这个似乎可以不用#为了能够持续训练,这里考虑 获取 上一次的 model_dict 和 optim_dict
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate,momentum=momentum)network_state_dict = torch.load('model.pth')
continued_network.load_state_dict(network_state_dict)
optimizer_state_dict = torch.load('optimizer.pth')
continued_optimizer.load_state_dict(optimizer_state_dict)#再接着上面练上6次
for i in range(4, 9):test_counter.append(i*len(train_loader.dataset))train(i)test()#同样进行图像的绘制
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red') #因为之前多test了一次,所以这里应该还是会出错
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
plt.show()第一个再vscode完成的神经网络训练, 撒花庆祝!!🎉
相关文章:
MNIST手写数字辨识-cnn网路 (机器学习中的hello world,加油)
用PyTorch实现MNIST手写数字识别(非常详细) - 知乎 (zhihu.com) 参考来源(这篇文章非常适合入门来看,每个细节都讲解得很到位) 一、模块函数用法-查漏补缺: 1.关于torch.nn.functional.max_pool2d()的用法: 上述示例…...

论文笔记《3D Gaussian Splatting for Real-Time Radiance Field Rendering》
项目地址 原论文 Abstract 最近辐射场方法彻底改变了多图/视频场景捕获的新视角合成。然而取得高视觉质量仍需神经网络花费大量时间训练和渲染,同时最近较快的方法都无可避免地以质量为代价。对于无边界的完整场景(而不是孤立的对象)和 10…...

数据库管理系统,数据库,sql的基本介绍以及它们之间的关系
数据库管理系统(Database Management System,简称DBMS)是一种软件工具或系统,用于管理和维护数据库的创建、访问、更新和管理。DBMS允许用户在数据库中存储、检索和操作数据,同时提供了数据安全性、完整性和一致性的控…...
)
【Flowable】Springboot使用Flowable(一)
一、项目依赖 <dependency><groupId>org.flowable</groupId><artifactId>flowable-engine</artifactId><version>6.3.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>my…...

戳泡泡小游戏
欢迎来到程序小院 戳泡泡 玩法: 鼠标点击上升的起泡泡,点击暴躁记录分数,不要让泡泡越过屏幕,共有三次复活生命,会有随机星星出现,点击即可暴躁全屏哦^^。开始游戏https://www.ormcc.com/play/gameStart/1…...

Redis缓存
1. Redis缓存相关问题 1.1 缓存穿透 缓存穿透是指查询一个数据库一定不存在的数据。 我们以前正常的使用Redis缓存的流程大致是: 1、数据查询首先进行缓存查询 2、如果数据存在则直接返回缓存数据 3、如果数据不存在,就对数据库进行查询࿰…...

mysql 插入更新数据
insert into insert into 语句进行插入时,如果插入的字段包含 主键或者唯一索引字段,那么, 1)主键或唯一索引 已存在,则插入失败 1062 - Duplicate entry 1 for key PRIMARY 2)只有主键或者唯一索 引不存…...
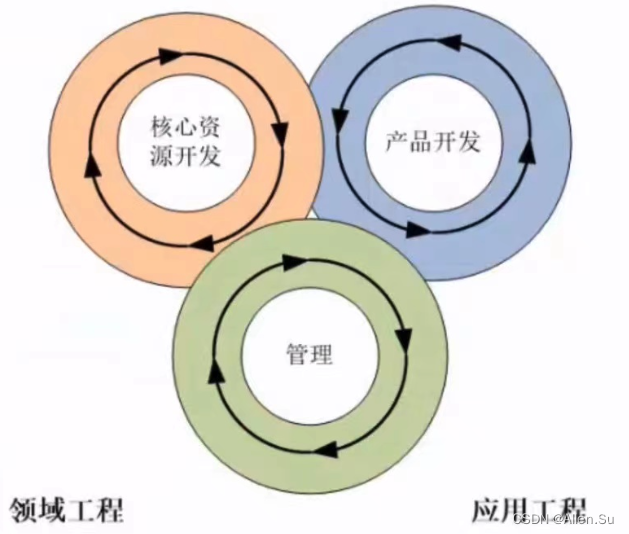
系统架构设计高级技能 · 软件产品线
现在的一切都是为将来的梦想编织翅膀,让梦想在现实中展翅高飞。 Now everything is for the future of dream weaving wings, let the dream fly in reality. 点击进入系列文章目录 系统架构设计高级技能 软件产品线 一、产品线概述二、产品线的过程模型2.1 双生命…...

C语言学习系列-->字符函数和字符串函数
文章目录 一、字符函数1、字符分类函数2、字符转换函数 二、字符串函数1、strlen概述模拟实现 2、strcpy概述模拟实现 3、strcat概述模拟实现 3、strcmp概述模拟实现 4、有限制的字符串函数strncpystrncatstrncmp 4、strstr概述模拟实现 一、字符函数 1、字符分类函数 包含头…...

尖端AR技术如何在美国革新外科手术实践?
AR智能眼镜已成为一种革新性的工具,在外科领域具有无穷的优势和无限的机遇。Vuzix与众多医疗创新企业建立了长期合作关系,如Pixee Medical、Medacta、Ohana One、Rods & Cones、Proximie等。这些公司一致认为Vuzix智能眼镜可有效提升手术实践&#x…...

【木板】Python实现-附ChatGPT解析
1.题目 木板 时间限制:1s 空间限制:256MB 限定语言:不限题目描述: 小明有n块木板,第i (1<=i<=n) 块木板的长度为ai.小明买了一块长度为m的木料,这块木料可以切割成任意块,拼接到已有的木板上用来加长木板。 小明想让最短的木板尽量长。 请问小明加长木板后,最短木板…...
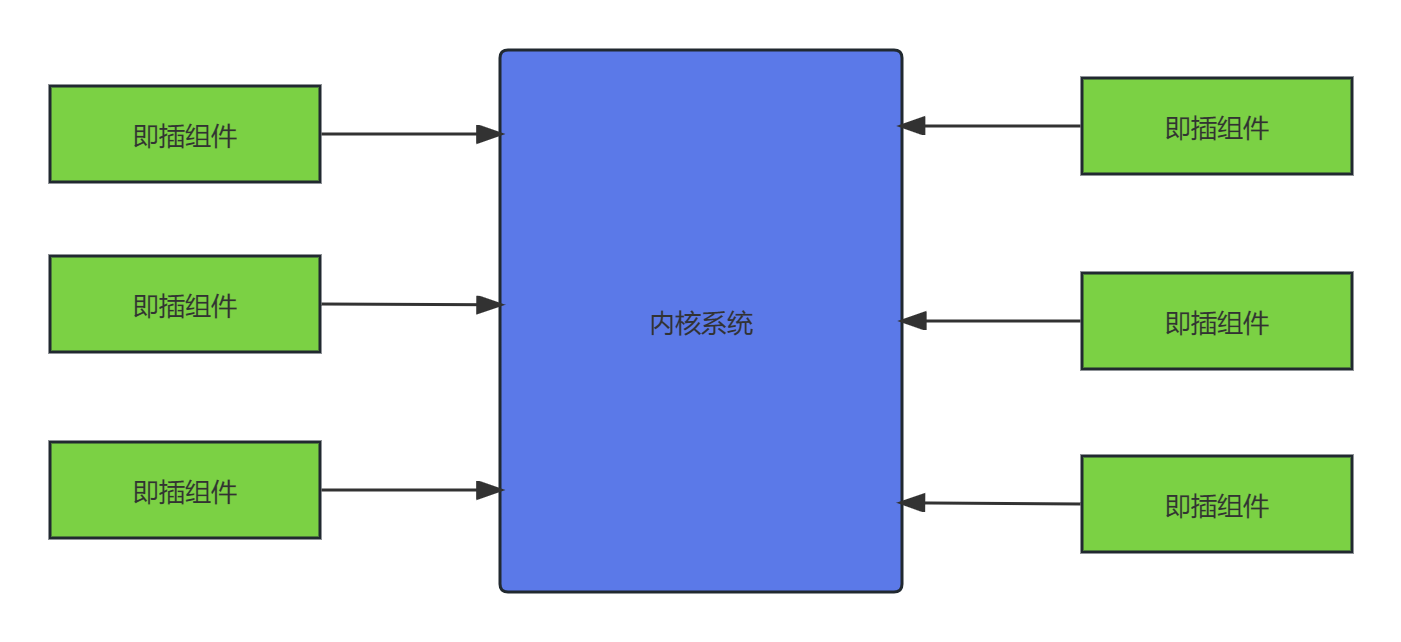
第一章:绪论
1.1 系统架构概述 架构是体现在组件中的一个系统的基本组织、它们彼此的关系与环境的关系以及指导它的设计和发展的原则。 系统是组织起来完成某一特定功能火一组功能的组件集。系统这个术语包括了单独的应用程序、传统意义上的系统、子系统、系统之系统、产品线、整个企业及…...

C++面试知识点总结
知识点总结 <<符号表示该语句将把这个字符串发送给cout;该符号指出了信息流动的路径;cout的对象属性包括一个插入运算符(<<),它可以将其右侧的信息插入到流中,endl:重起一行。在输出流中插入en…...

从智能手机到智能机器人:小米品牌的高端化之路
原创 | 文 BFT机器人 前言 在前阵子落幕的2023世界机器人大会“合作之夜”上,北京经济技术开发区管委会完成了与世界机器人合作组织、小米机器人等16个重点项目签约,推动机器人创新链和产业链融合,其中小米的投资额达到20亿! 据了…...

深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用
深度学习推荐系统(八)AFM模型及其在Criteo数据集上的应用 1 AFM模型原理及其实现 沿着特征工程自动化的思路,深度学习模型从 PNN ⼀路⾛来,经过了Wide&Deep、Deep&Cross、FNN、DeepFM、NFM等模型,进⾏了大量的、基于不…...

【Spring】aop的底层原理
🎄欢迎来到边境矢梦的csdn博文🎄 🎄本文主要梳理 Spring 中的切面编程aop的底层原理和重点注意的地方 🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以…...
微信小程序开发---基本组件的使用
目录 一、scroll-view (1)作用 (2)用法 二、swiper和swiper-item (1)作用 (2)用法 三、text (1)作用 (2)使用 四、rich-tex…...

SpringBoot国际化配置组件支持本地配置和数据库配置
文章目录 0. 前言i18n-spring-boot-starter1. 使用方式0.引入依赖1.配置项2.初始化国际化配置表3.如何使用 2. 核心源码实现一个拦截器I18nInterceptorI18nMessageResource 加载国际化配置 3.源码地址 0. 前言 写个了原生的SpringBoot国际化配置组件支持本地配置和数据库配置 背…...
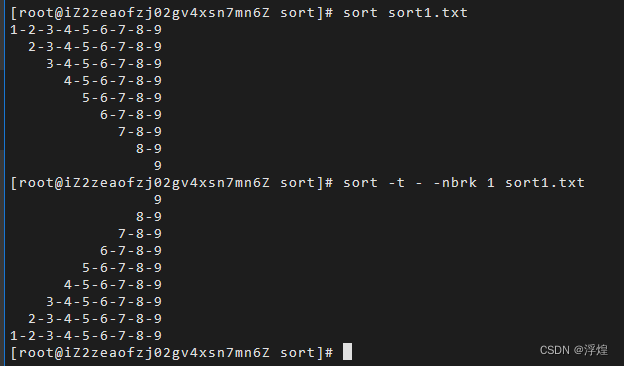
Shell编程之sort
sort 命令将文件的每一行作为比较对象,通过将不同行进行相互比较,从而得到最终结果。从首字符开始,依次按ASCII码值进行比较,最后将结果按升序输出。 基本语法 sort (选项)(参数) 常用选项 常用选项 -n根据字符串的数字比较-r…...

windows docker 容器启动报错:Ports are not available
docker 启动容器报错: (HTTP code 500) server error - Ports are not available: listen tcp 0.0.0.0:6379: bind: An attempt was made to access a socket in a way forbidden by its access permissions. 问题排查 检查端口是否被其它程序占用:nets…...

解放双手:5分钟快速上手智慧树自动化学习工具的完整指南
解放双手:5分钟快速上手智慧树自动化学习工具的完整指南 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 你是否厌倦了每天重复点击智慧树视频的枯燥…...

计算机视觉导航评估框架:从算法指标到用户体验的完整闭环
1. 项目概述:为什么我们需要一个“导航评估框架”?在计算机视觉辅助视障人士导航这个领域,我见过太多“实验室里的英雄”和“现实中的矮子”。一个算法在精心布置的走廊里识别障碍物准确率高达99.9%,但一到人潮涌动的火车站广场&a…...

从零构建大模型推理引擎:KV缓存、算子融合与量化优化实战
1. 项目概述:从零理解大模型推理引擎如果你正在关注大语言模型(LLM)的实际应用,特别是如何让这些动辄数百亿参数的“庞然大物”在你的本地机器或服务器上高效地跑起来,那么你很可能已经听说过“推理引擎”这个词。anik…...

多模态大模型在光谱分析中的应用:温度参数调优与性能评估
1. 项目概述:当光谱分析遇上多模态大模型光谱分析,无论是红外、拉曼还是近红外光谱,一直是材料科学、生物医药、环境监测等领域的“火眼金睛”。它能通过物质与光的相互作用,揭示出样品的成分、结构乃至状态信息。然而,…...
)
别再手动造数据了!用Python的imgaug库5分钟搞定深度学习图像增强(附关键点/边界框处理避坑指南)
深度学习图像增强实战:用imgaug打造高效数据流水线 在计算机视觉项目中,数据增强是提升模型泛化能力的关键步骤。传统手动处理方式不仅耗时耗力,还难以保证处理一致性。本文将深入探讨如何利用Python的imgaug库快速构建自动化图像增强流程&am…...

JavaScript自动化PPT生成:如何用代码解放你的演示文稿生产力
JavaScript自动化PPT生成:如何用代码解放你的演示文稿生产力 【免费下载链接】PptxGenJS Build PowerPoint presentations with JavaScript. Works with Node, React, web browsers, and more. 项目地址: https://gitcode.com/gh_mirrors/pp/PptxGenJS 还在为…...

如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南
如何用GHelper解决华硕笔记本性能管理难题:轻量级开源工具的完整指南 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivoboo…...

Qt 批量读取Excel数据:从性能瓶颈到优化实践
1. 为什么Qt读取Excel会卡成PPT? 第一次用Qt操作Excel表格时,我兴冲冲写了个循环读取单元格的代码。结果打开包含5000行数据的文件后,进度条像蜗牛爬坡,鼠标指针转成彩色圆圈,程序直接卡成PPT幻灯片模式——这场景估计…...

imFile下载管理器:从入门到精通的免费全能下载解决方案
imFile下载管理器:从入门到精通的免费全能下载解决方案 【免费下载链接】imfile-desktop A full-featured download manager. 项目地址: https://gitcode.com/gh_mirrors/im/imfile-desktop imFile是一款功能全面的免费下载管理器,支持HTTP、FTP、…...
,让开源检索进入“所想即所得”时代)
别再Ctrl+F GitHub了!Perplexity高级提示词工程(含18个已验证模板),让开源检索进入“所想即所得”时代
更多请点击: https://intelliparadigm.com 第一章:Perplexity GitHub资源检索的范式革命 从关键词匹配到语义理解的跃迁 传统 GitHub 搜索依赖精确的仓库名、文件路径或正则表达式,而 Perplexity 引入的 LLM 驱动检索将自然语言查询&#x…...