【C++】封装unordered_map和unordered_set(用哈希桶实现)
前言:
前面我们学习了unordered_map和unordered_set容器,比较了他们和map、set的查找效率,我们发现他们的效率比map、set高,进而我们研究他们的底层是由哈希实现。哈希是一种直接映射的方式,所以查找的效率很快。与学习红黑树和map、set的思路一样,我们现在学完了unordered_map和unordered_set,本章将模拟实现底层结构来封装该容器!
作者建议在阅读本章前,可以先去看一下前面的红黑树封装map和set——红黑树封装map和set
这两篇文章都重在强调泛型编程的思想,上一篇由于是初认识,作者讲解的会更详细一点~
目录
(一)如何复用一个哈希桶
1、结点的定义:
2、两个容器各自的模板参数类型编辑
3、改造哈希桶
(二)哈希桶的迭代器的模拟实现
1、begin()和end()的模拟实现
2、operator*和operator->及operator!=和operator==的模拟实现
3、operator ++的模拟实现
(三)迭代器和改造哈希桶的总代码
(四)封装unordered_map和unordered_set
(一)如何复用一个哈希桶
我们学习过知道,unordered_map和unordered_set容器存放的结点并不一样,为了让它得到复用,我们就需要对哈希桶进行改造,将哈希桶改造的更加泛型一点,既符合Key模型,也符合Key_Value模型。
1、结点的定义:
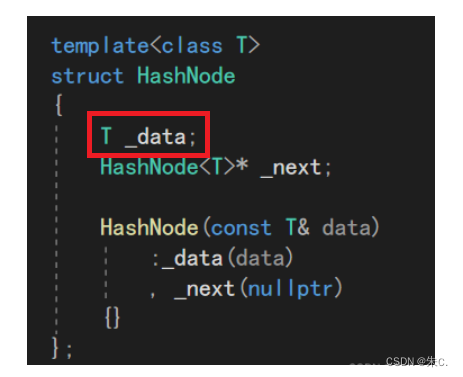
所以我们这里还是和封装map和set时一样,无论是Key还是Key_Value,都用一个类型T来接收,这里高维度的泛型哈希表中,实现还是用的是Kye_Value模型,K是不能省略的,同样的查找和删除要用,故我们可以引出两个容器各自模板参数类型。
2、两个容器各自的模板参数类型

如何取到想要的数据:
- 我们给每个容器配一个仿函数
- 各传不同的仿函数,拿到想要的不同的数据
同时我们再给每个容器配一个哈希函数。
3、改造哈希桶
通过上面1和2,我们可以把各自存放的数据泛化成data:

这样我们哈希桶的模板参数算是完成了
- 哈希函数我们可以自由选择并传
- 仿函数在各自容器的封装中实现,用于比较时我们可以取出各自容器想要的数据
我们把上一篇文章封装的哈希桶拿来改造:
//K --> 键值Key,T --> 数据
//unordered_map ->HashTable<K, pair<K, V>, MapKeyOfT> _ht;
//unordered_set ->HashTable<K, K, SetKeyOfT> _ht;
template<class K, class T, class KeyOfT, class HashFunc>
class HashTable
{template<class K, class T, class KeyOfT, class HashFunc>friend class __HTIterator;typedef HashNode<T> Node;
public:typedef __HTIterator<K, T, KeyOfT, HashFunc> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur){return iterator(cur, this);}}return end();}iterator end(){return iterator(nullptr, this);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}size_t GetNextPrime(size_t prime){const int PRIMECOUNT = 28;static const size_t primeList[PRIMECOUNT] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};//获取比prime大那一个素数size_t i = 0;for (i = 0; i < PRIMECOUNT; i++){if (primeList[i] > prime)return primeList[i];}return primeList[i];}pair<iterator, bool> Insert(const T& data){HashFunc hf;KeyOfT kot;iterator pos = Find(kot(data));if (pos != end()){return make_pair(pos, false);}//负载因子 == 1 扩容 -- 平均每个桶挂一个结点if (_tables.size() == _n){//size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;size_t newSize = GetNextPrime(_tables.size());if (newSize != _tables.size()){vector<Node*> newTable;newTable.resize(newSize, nullptr);//遍历旧表for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];//再对每个桶挨个遍历while (cur){Node* next = cur->_next;size_t hashi = hf(kot(cur->_data)) % newSize;//转移到新的表中cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}//将原表置空_tables[i] = nullptr;}newTable.swap(_tables);}}size_t hashi = hf(kot(data));hashi %= _tables.size();//头插到对应的桶即可Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;//有效数据加一_n++;return make_pair(iterator(newnode, this), true);}iterator Find(const K& key){if (_tables.size() == 0){return iterator(nullptr, this);}KeyOfT kot;HashFunc hf;size_t hashi = hf(key);//size_t hashi = HashFunc()(key);hashi %= _tables.size();Node* cur = _tables[hashi];//找到指定的桶之后,顺着单链表挨个找while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}//没找到返回空return iterator(nullptr, this);}bool Erase(const K& key){if (_tables.size() == 0){return false;}HashFunc hf;KeyOfT kot;size_t hashi = hf(key);hashi %= _tables.size();//单链表删除结点Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){//头删if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}
private://指针数组vector<Node*> _tables;size_t _n = 0;
};
主要改造的地方就是上述所注意的地方:
- 比较时需要调用各自的仿函数
- 调用外部传的哈希函数
还有对扩容的二次思考:
研究表明:除留余数法,最好模一个素数
- 通过查STL官方库我们也发现,其提供了一个取素数的函数
- 所以我们也提供了一个,直接拷贝过来
-
- 这样我们在扩容时就可以每次给素数个桶
-
- 在扩容时加了一条判断语句是为了防止素数值太大,过分扩容容易直接把空间(堆)干崩了
(二)哈希桶的迭代器的模拟实现
1、begin()和end()的模拟实现

- 以第一个桶中第一个不为空的结点为整个哈希桶的开始结点
- 以空结点为哈希桶的结束结点
2、operator*和operator->及operator!=和operator==的模拟实现
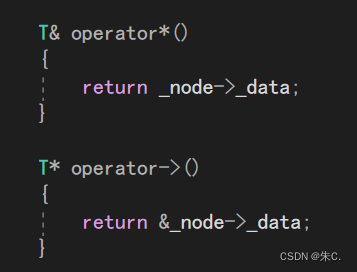

这两组和之前实现的一模一样,大家自行理解。
3、operator ++的模拟实现

注:
- 这里要在哈希桶的类外面访问其私有成员
- 我们要搞一个友元类
- 迭代器类是哈希桶类的朋友
- 这样就可以访问了

思路:
- 判断一个桶中的数据是否遍历完
- 如果所在的桶没有遍历完,在该桶中返回下一个结点指针
- 如果所在的桶遍历完了,进入下一个桶
- 判断下一个桶是否为空
- 非空返回桶中第一个节点
- 空的话就遍历一个桶
- 后置++和之前一眼老套路,不赘述
注意:
unordered_map和unordered_set是不支持反向迭代器的,从底层结构我们也能很好的理解(单链表找不了前驱)所以不支持实现迭代器的operator- -
最后注意一点,我们需要知道哈希桶大小,所以不仅要传结点地址,还要传一个哈希桶,这样才能知道其大小,除此,由于哈希桶改造在后面,所以我们要在前面声明一下:

(三)迭代器和改造哈希桶的总代码
#include<vector>
#include<string>
#include<iostream>
using namespace std;template<class K>
struct DefaultHash
{size_t operator()(const K& key){return (size_t)key;}
};template<>
struct DefaultHash<string>
{size_t operator()(const string& key){//BKDRsize_t hash = 0;for (auto ch : key){hash = hash * 131 + ch;}return hash;}
};namespace Bucket
{template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data), _next(nullptr){}};template<class K, class T, class KeyOfT, class HashFunc>class HashTable;//哈希桶的迭代器template<class K, class T, class KeyOfT, class HashFunc>class __HTIterator{typedef HashNode<T> Node;typedef __HTIterator<K, T, KeyOfT, HashFunc> Self;public:Node* _node;__HTIterator() {};//编译器的原则是向上查找(定义必须在前面,否则必须先声明)HashTable<K, T, KeyOfT, HashFunc>* _pht;__HTIterator(Node* node, HashTable<K, T, KeyOfT, HashFunc>* pht):_node(node), _pht(pht){}Self& operator++(){if (_node->_next){_node = _node->_next;}else//当前桶已经走完了,要走下一个桶{KeyOfT kot;HashFunc hf;size_t hashi = hf(kot(_node->_data)) % _pht->_tables.size();hashi++;//找下一个不为空的桶 -- 访问到了哈希表中私有的成员(友元)for (; hashi < _pht->_tables.size(); hashi++){if (_pht->_tables[hashi]){_node = _pht->_tables[hashi];break;}}//没有找到不为空的桶,用nullptr去做end标识if (hashi == _pht->_tables.size()){_node = nullptr;}}return *this;}T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator!=(const Self& s) const{return _node != s._node;}bool operator==(const Self& s) const{return _node == s._node;}};//K --> 键值Key,T --> 数据//unordered_map ->HashTable<K, pair<K, V>, MapKeyOfT> _ht;//unordered_set ->HashTable<K, K, SetKeyOfT> _ht;template<class K, class T, class KeyOfT, class HashFunc>class HashTable{template<class K, class T, class KeyOfT, class HashFunc>friend class __HTIterator;typedef HashNode<T> Node;public:typedef __HTIterator<K, T, KeyOfT, HashFunc> iterator;iterator begin(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];if (cur){return iterator(cur, this);}}return end();}iterator end(){return iterator(nullptr, this);}~HashTable(){for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_tables[i] = nullptr;}}size_t GetNextPrime(size_t prime){const int PRIMECOUNT = 28;static const size_t primeList[PRIMECOUNT] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};//获取比prime大那一个素数size_t i = 0;for (i = 0; i < PRIMECOUNT; i++){if (primeList[i] > prime)return primeList[i];}return primeList[i];}pair<iterator, bool> Insert(const T& data){HashFunc hf;KeyOfT kot;iterator pos = Find(kot(data));if (pos != end()){return make_pair(pos, false);}//负载因子 == 1 扩容 -- 平均每个桶挂一个结点if (_tables.size() == _n){//size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;size_t newSize = GetNextPrime(_tables.size());if (newSize != _tables.size()){vector<Node*> newTable;newTable.resize(newSize, nullptr);//遍历旧表for (size_t i = 0; i < _tables.size(); i++){Node* cur = _tables[i];//再对每个桶挨个遍历while (cur){Node* next = cur->_next;size_t hashi = hf(kot(cur->_data)) % newSize;//转移到新的表中cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}//将原表置空_tables[i] = nullptr;}newTable.swap(_tables);}}size_t hashi = hf(kot(data));hashi %= _tables.size();//头插到对应的桶即可Node* newnode = new Node(data);newnode->_next = _tables[hashi];_tables[hashi] = newnode;//有效数据加一_n++;return make_pair(iterator(newnode, this), true);}iterator Find(const K& key){if (_tables.size() == 0){return iterator(nullptr, this);}KeyOfT kot;HashFunc hf;size_t hashi = hf(key);//size_t hashi = HashFunc()(key);hashi %= _tables.size();Node* cur = _tables[hashi];//找到指定的桶之后,顺着单链表挨个找while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}//没找到返回空return iterator(nullptr, this);}bool Erase(const K& key){if (_tables.size() == 0){return false;}HashFunc hf;KeyOfT kot;size_t hashi = hf(key);hashi %= _tables.size();//单链表删除结点Node* prev = nullptr;Node* cur = _tables[hashi];while (cur){if (kot(cur->_data) == key){//头删if (prev == nullptr){_tables[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}private://指针数组vector<Node*> _tables;size_t _n = 0;};
}(四)封装unordered_map和unordered_set
有了上面的哈希桶的改装,我们这里的对map和set的封装就显得很得心应手了。
unordered_map的封装:
#include "HashTable.h"namespace zc
{template<class K, class V, class HashFunc = DefaultHash<K>>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:typedef typename Bucket::HashTable<K, pair<K, V>, MapKeyOfT, HashFunc>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}V& operator[](const K& key){pair<iterator, bool> ret = insert(make_pair(key, V()));return ret.first->second;}private:Bucket::HashTable<K, pair<K, V>, MapKeyOfT, HashFunc> _ht;};void test_map(){unordered_map<string, string> dict;dict.insert(make_pair("sort", "排序"));dict.insert(make_pair("left", "左边"));dict.insert(make_pair("left", "下面"));dict["string"];dict["left"] = "上面";dict["string"] = "字符串";unordered_map<string, string>::iterator it = dict.begin();while (it != dict.end()){cout << it->first << " " << it->second << endl;++it;}cout << endl;for (auto e : dict){cout << e.first << " " << e.second << endl;}}}这里unordered_map中的operator[ ]我们知道其原理之后,模拟实现就非常方便,直接调用插入函数,控制好参数和返回值即可。
对unordered_set的封装:
#include "HashTable.h"#include "HashTable.h"namespace zc
{template<class K, class HashFunc = DefaultHash<K>>class unordered_set{struct SetKeyOfT{const K& operator()(const K& key){return key;}};public://2.48typedef typename Bucket::HashTable<K, K, SetKeyOfT, HashFunc>::iterator iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}pair<iterator, bool> insert(const K& key){return _ht.Insert(key);}iterator find(const K& key){return _ht.Find(key);}bool erase(const K& key){return _ht.Erase(key);}private:Bucket::HashTable<K, K, SetKeyOfT, HashFunc> _ht;};struct Date{Date(int year = 1, int month = 1, int day = 1):_year(year), _month(month), _day(day){}bool operator==(const Date& d) const{return _year == d._year&& _month == d._month&& _day == d._day;}int _year;int _month;int _day;};struct DateHash{size_t operator()(const Date& d){//return d._year + d._month + d._day;size_t hash = 0;hash += d._year;hash *= 131;hash += d._month;hash *= 1313;hash += d._day;//cout << hash << endl;return hash;}};void test_set(){unordered_set<int> s;//set<int> s;s.insert(2);s.insert(3);s.insert(1);s.insert(2);s.insert(5);s.insert(12);unordered_set<int>::iterator it = s.begin();//auto it = s.begin();while (it != s.end()){cout << *it << " ";++it;}cout << endl;for (auto e : s){cout << e << " ";}cout << endl;unordered_set<Date, DateHash> sd;sd.insert(Date(2022, 3, 4));sd.insert(Date(2022, 4, 3));}
}
最后大家可以利用代码中给的测试函数进行测试!
感谢你的阅读!
相关文章:
【C++】封装unordered_map和unordered_set(用哈希桶实现)
前言: 前面我们学习了unordered_map和unordered_set容器,比较了他们和map、set的查找效率,我们发现他们的效率比map、set高,进而我们研究他们的底层是由哈希实现。哈希是一种直接映射的方式,所以查找的效率很快…...

面试问题回忆
(1)查看端口 lsof -i:8080 / netstat lsof -i:8080:查看8080端口占用 lsof abc.txt:显示开启文件abc.txt的进程 lsof -c abc:显示abc进程现在打开的文件 lsof -c -p 1234:列出进程号为1234的进程所打开…...
更多场景、更多选择,Milvus 新消息队列 NATS 了解一下
在 Milvus 的云原生架构中,消息队列(Log Broker)可谓任重道远,它不仅要具备流式数据持久性、支持 TT 同步、事件通知等能力,还要确保工作节点从系统崩溃中恢复时增量数据的完整性。 在 Milvus 的架构中,一切…...
如何通过python实现一个web自动化测试框架?
要实现一个web自动化测试框架,可以使用Python中的Selenium库,它是最流行的Web应用程序测试框架之一。以下是一个基本的PythonSelenium测试框架的示例: 1、安装Selenium 在终端中输入以下命令,使用 pip 安装 Selenium:…...

Linux —— 信号阻塞
目录 一,信号内核表示 sigset_t sigprocmask sigpending 二,捕捉信号 sigaction 三,可重入函数 四,volatile 五,SIGCHLD 信号常见概念 实际执行信号的处理动作,称为信号递达Delivery;信…...
【【萌新编写riscV之计算机体系结构之CPU 总二】】
萌新编写riscV之计算机体系结构之CPU 总二(我水平太差总结不到位) 在学习完软件是如何使用之后 我们接下来要面对的问题是 整个程序是如何运转的这一基本逻辑 中央处理器(central processing unit,CPU)的任务就是负责提取程序指令࿰…...
error:03000086:digital envelope routines::initialization error
项目背景 前端vue项目启动突然报错error:03000086:digital envelope routines::initialization error 我用的开发工具是vscode,node版本是v18.17.0 前端项目版本如下↓ 具体报错如下↓ 报错原因 node版本过高 解决方法 1输入命令 $env:NODE_OPTIONS"--op…...
暴涨130万粉仅用3个月,一招转型成B站热门UP主
- 导语 起号难、找不到内容方向、没流量、没粉丝等等运营困境环绕在创作者之间,近期,有黑马UP主短时间内就在B站涨粉百万,飞升成为热门UP主,以下,飞瓜数据(B站版)剖析黑马UP主运营技巧…...

【Linus】vim的使用:命令模式、底行模式、插入模式、视图模式、替换模式的常用操作介绍
目录 注意:以下操作前提是要确保你输入法是英文模式 一、进入和退出各个模式的方法 1.命令模式 2.底行模式 3.插入模式 4.视图模式 5.替换模式 二、在命令模式中一些常用的操作 1.移动光标 2.删除文字 3.复制 4.替换 5.撤销上一次操作 6.更改 7.跳至指…...

leetcode第362场周赛补题
8029. 与车相交的点 - 力扣(LeetCode) 思路:差分数组 class Solution { public:int numberOfPoints(vector<vector<int>>& nums) {int diff[102] {}; for(auto p : nums)//差分{diff[p[0]] ;diff[p[1] 1] -- ;}int res …...

SpringMvc 之crud增删改查应用
目录 1.创建项目 2.配置文件 2.1pom.xml文件 2.2 web.xml文件 2.3 spring-context.xml 2.4 spring-mvc.xml 2.5 spring-MyBatis.xml 2.6 jdbc.properties 数据库 2.7 generatorConfig.xml 2.8 日志文件log4j2 3.后台代码 3.1 pageBean.java 3.2切面类 3.3 biz层…...
【业务功能109】微服务-springcloud-springboot-Skywalking-链路追踪-监控
Skywalking skywalking是一个apm系统,包含监控,追踪,并拥有故障诊断能力的 分布式系统 一、Skywalking介绍 1.什么是SkyWalking Skywalking是由国内开源爱好者吴晟开源并提交到Apache孵化器的产品,它同时吸收了Zipkin /Pinpoint …...

《向量数据库指南》——AI原生向量数据库Milvus Cloud 2.3架构升级
架构升级 GPU 支持 早在 Milvus 1.x 版本,我们就曾经支持过 GPU,但在 2.x 版本中由于切换成了分布式架构,同时出于对于成本方面的考虑,暂时未加入 GPU 支持。在 Milvus 2.0 发布后的一年多时间里,Milvus 社区对 GPU 的呼声越来越高,再加上 NVIDIA 工程师的大力配合——为…...

Flutter中实现交互式Webview的方法
前言: Flutter是一款强大的跨平台移动应用开发框架,而Webview则是在应用中展示Web内容的重要组件。本文将介绍如何在Flutter应用中实现交互式的Webview,以便为用户提供更加丰富的内容和功能。 1. 引入webview_flutter插件 要在Flutter应用中…...

【Java Web】用Redis优化登陆模块
使用Redis存储验证码 验证码需要频繁访问和封信,对性能要求高;验证码不需要永久保存,通常在很短时间内失效;分布式部署,存在Session共享问题; 使用Redis存储登陆凭证 处理每次请求时,都要查询用…...
华为云云耀云服务器L实例评测|docker私有仓库部署手册
【软件安装版本】【集群安装(是)(否)】 版本号 文档编写 文档审核 创建日期 修改日期 1.0 jzg jzg 2023.9.13 一. 部署规划与架构 1. 规划:(集群:网络规划&…...
)
JAVA-3DES对称加解密工具(不依赖第三方库)
import javax.crypto.Cipher; import javax.crypto.spec.SecretKeySpec; import java.nio.charset.StandardCharsets; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException;public class EncryptUtil {// 密钥public static final String ENCR…...
)
基于Matlab卡尔曼滤波的IMU和GPS组合导航数据融合(附上源码+数据)
本文介绍了如何使用Matlab实现惯性测量单元(IMU)和全球定位系统(GPS)组合导航数据融合的卡尔曼滤波算法。通过将IMU和GPS的测量数据进行融合,可以提高导航系统的精度和鲁棒性。我们将详细介绍卡尔曼滤波的原理和实现步…...
)
net自动排课系统完整源码(适合智慧校园)
目录 1 net自动排课系统完整源码(适合智慧校园) 1.1 后台管理admin 1.1.1 菜单 1.1.2 教学计划 net自动排课系统完整源码(适合智慧校园) 后台管理admin<%@ Page Language="C#" AutoEventWireup="true" CodeBehind=&...

Matlab匿名函数教程
Matlab匿名函数是一种方便、简洁的函数定义方式,可以在不使用函数文件的情况下,直接在命令行或脚本中定义函数。本文将介绍Matlab匿名函数的基本语法和用法。 匿名函数的基本语法如下: function_handle (input_variables) expression其中&…...

如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南
如何快速掌握雀魂Mod Plus:解锁全角色皮肤的新手完全指南 【免费下载链接】majsoul_mod_plus 雀魂解锁全角色、皮肤、装扮等,支持全部服务器。 项目地址: https://gitcode.com/gh_mirrors/ma/majsoul_mod_plus 还在为无法获得心仪角色和皮肤而烦恼…...

从零构建开源任务管理中枢:TaskWing部署、插件化与自动化实战
1. 项目概述:从零到一,打造你的个人任务管理中枢如果你和我一样,每天被各种待办事项、项目进度、临时想法和会议记录搞得焦头烂额,那么你肯定不止一次地想过:有没有一个工具,能真正“懂”我,能把…...

uni-app iOS后台运行 uni-app App如何实现后台定位或音乐播放
iOS上uni.startBackgroundTask基本无效,仅音频播放、定位更新、后台数据刷新三类能力合规;后台定位需manifest声明原生权限地理围栏事件;无声音频保活须onLaunch配置AudioSession并延迟播放。uni.startBackgroundTask 在 iOS 上基本无效&…...

Adams驱动函数里那个神秘的‘d’到底怎么用?手把手教你避开单位换算的坑
Adams驱动函数中‘d’符号的终极指南:从原理到实战避坑 刚接触Adams的工程师们,你们是否曾在深夜盯着屏幕上那个诡异的机械臂运动轨迹百思不得其解?明明输入的是90度,为什么模型转得像陀螺一样疯狂?这一切的罪魁祸首很…...

视频解密神器:3步搞定Widevine加密,重新掌控你的数字内容
视频解密神器:3步搞定Widevine加密,重新掌控你的数字内容 【免费下载链接】video_decrypter Decrypt video from a streaming site with MPEG-DASH Widevine DRM encryption. 项目地址: https://gitcode.com/gh_mirrors/vi/video_decrypter 还在为…...

模拟计算机应急救场:从400Hz电源故障看经典工程思维
1. 项目概述:一次由模拟计算机主导的“救场”1984年,在宾夕法尼亚州费城的一个大型测试实验室里,一个为海军战斗机设计的红外跟踪系统正面临一场突如其来的危机。这个系统被安装在一个三轴液压驱动的万向节上,需要在特定的400赫兹…...

半导体IP产业变革:从EDA历史看IP组装业务的未来
1. 项目概述:从EDA的剧本看IP产业的未来 在半导体行业摸爬滚打了十几年,我见过太多关于“IP核”和“EDA工具”的讨论,但很少有人能像Arteris的CEO Charlie Janac那样,把这两者的关系与未来看得如此透彻。他有一句话让我印象极深&a…...
)
【AI原生架构黄金法则】:SITS 2026现场实录的7条反直觉设计铁律(仅限首批参会专家内部流出)
AI原生应用架构设计:SITS 2026技术专家实战经验分享 更多请点击: https://intelliparadigm.com 第一章:SITS 2026现场共识与AI原生架构范式跃迁 在SITS 2026全球智能系统技术峰会上,来自37个国家的架构师、AI平台工程师与标准化组…...

Oracle数据库深度解析:从入门到精通的全面指南
在当今数据驱动的时代,数据库管理系统(DBMS)已成为企业信息化建设的核心。作为全球领先的商业数据库产品,Oracle数据库凭借其卓越的性能、高可用性和强大的扩展能力,长期占据市场主导地位。本文将为您带来一份从入门到…...

原来市面上这些匹克球装备制造厂,都有啥独特之处?
匹克球运动近年来愈发火热,市面上的匹克球装备制造厂也如雨后春笋般涌现,每个品牌都有其独特的优势和特点。下面为你介绍其中一部分具有代表性的厂家及其独特之处。凯瑞麟体育用品:科技与文化的融合凯瑞麟体育用品成立于2025年11月࿰…...