Python实战之小说下载神器(二)整本小说下载:看小说不用这个程序,我实在替你感到可惜*(小说爱好者必备)
前言
这次的是一个系列内容给大家讲解一下何一步一步实现一个完整的实战项目案例系列之小说下载神器(二)(GUI界面化程序)单章小说下载保存数据——整本小说下载
你有看小说“中毒”的经历嘛?小编多多少少还是爱看小说的,如果喜欢看小说分等级的话,我
可能得排到前三啦~嘻嘻嘻.jpg
所有文章完整的素材+源码都在👇👇
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。

今天的内容还是延续上一期的内容,接着来给大家写小说下载器的系列啦~
上一期学了🤔:
爬虫基本思路流程——单章小说下载,发送请求&获取数据——单章小说下载—解析数据。
这一期教大家👍:
单章小说下载保存数据——整本小说下载。
好啦,话不多说,我们开始今天的主题吧👌👌

正文
一、运行环境
1)环境运行
Python3、Pycharm社区版; requests、 parsel第三方库,部分自带的模块安装完Python可
以直接使用不需要安装。
一般安装:pip install +模块名镜像源安装:pip install -i https://pypi.douban.com/simple/+模块名二、单章小说下载&保存数据
1)代码实现
# 导入数据请求模块 --> 第三方模块, 需要安装
import requests
# 导入正则表达式模块 --> 内置模块, 不需要安装
import re
# 导入数据解析模块 --> 第三方模块, 需要安装
import parsel"""
1. 发送请求, 模拟浏览器对于url地址发送请求请求链接: https://www.biqudu.net/1_1631/3047505.html安装模块方法:- win + R 输入cmd, 输入安装命令 pip install requests- 在pycharm终端, 输入安装命令模拟浏览器 headers 请求头:字典数据结构AttributeError: 'set' object has no attribute 'items' 因为headers不是字典数据类型, 而是set集合
"""
# 请求链接
url = 'https://www.biqudu.net/1_1631/3047505.html'
# 模拟浏览器 headers 请求头
headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
response = requests.get(url=url, headers=headers)
# <Response [200]> 响应对象, 表示请求成功
print(response)
"""
2. 获取数据, 获取服务器返回响应数据内容开发者工具: responseresponse.text --> 获取响应文本数据 <网页源代码/html字符串数据>
3. 解析数据, 提取我们想要的数据内容标题/内容re正则表达式: 是直接对于字符串数据进行解析re.findall('什么数据', '什么地方') --> 从什么地方, 去找什么数据.*? --> 可以匹配任意数据, 除了\n换行符# 提取标题title = re.findall('<h1>(.*?)</h1>', response.text)[0]# 提取内容content = re.finall('<div id="content">(.*?)<p>', response.text, re.S)[0].replace('<br/><br/>', '\n')css选择器: 根据标签属性提取数据.bookname h1::text类名为bookname下面h1标签里面文本get() --> 提取第一个标签数据内容 返回字符串getall() --> 提取多个数据, 返回列表# 提取标题title = selector.css('.bookname h1::text').get()# 提取内容content = '\n'.join(selector.css('#content::text').getall())xpath节点提取: 提取标签节点提取数据"""
# 获取下来response.text <html字符串数据>, 转成可解析对象
selector = parsel.Selector(response.text)
# 提取标题
title = selector.xpath('//*[@class="bookname"]/h1/text()').get()
# 提取内容
content = '\n'.join(selector.xpath('//*[@id="content"]/text()').getall())
print(title)
print(content)
# title <文件名> '.txt' 文件格式 a 追加保存 encoding 编码格式 as 重命名
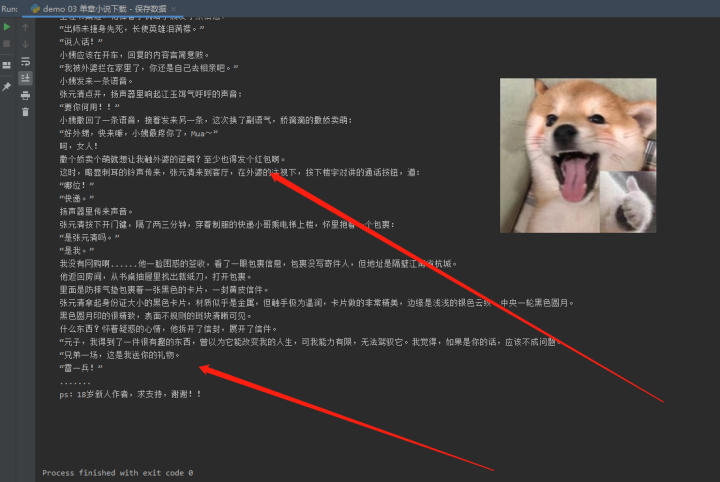
with open(title + '.txt', mode='a', encoding='utf-8') as f:"""第一章 标题小说内容第二章 标题小说内容"""# 写入内容f.write(title)f.write('\n')f.write(content)f.write('\n')2)效果展示
单章小说下载保存——
三、整本小说下载
请求链接:小说目录页
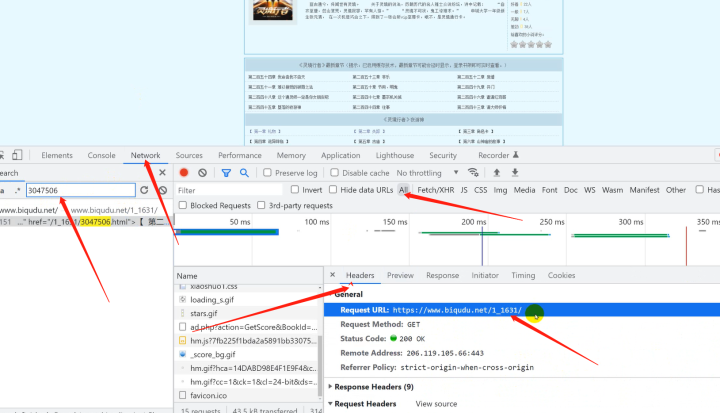
1)代码实现
"""
# 导入数据请求模块 --> 第三方模块, 需要安装
import requests
# 导入正则表达式模块 --> 内置模块, 不需要安装
import re
# 导入数据解析模块 --> 第三方模块, 需要安装
import parsel
# 导入文件操作模块 --> 内置模块, 不需要安装
import os# 请求链接: 小说目录页
list_url = 'https://www.biqudu.net/1_1631/'
# 模拟浏览器 headers 请求头
headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求
html_data = requests.get(url=list_url, headers=headers).text
# 提取小说名字
name = re.findall('<h1>(.*?)</h1>', html_data)[0]
# 自动创建一个文件夹
file = f'{name}\\'
if not os.path.exists(file):os.mkdir(file)# 提取章节url
url_list = re.findall('<dd> <a style="" href="(.*?)">', html_data)
# for循环遍历
for url in url_list:index_url = 'https://www.biqudu.net' + urlprint(index_url)"""1. 发送请求, 模拟浏览器对于url地址发送请求请求链接: https://www.biqudu.net/1_1631/3047505.html安装模块方法:- win + R 输入cmd, 输入安装命令 pip install requests- 在pycharm终端, 输入安装命令模拟浏览器 headers 请求头:字典数据结构AttributeError: 'set' object has no attribute 'items'因为headers不是字典数据类型, 而是set集合"""# # 请求链接# url = 'https://www.biqudu.net/1_1631/3047506.html'# 模拟浏览器 headers 请求头headers = {# user-agent 用户代理 表示浏览器基本身份信息'user-agent': 'Mozlla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'}# 发送请求response = requests.get(url=index_url, headers=headers)# <Response [200]> 响应对象, 表示请求成功print(response)"""2. 获取数据, 获取服务器返回响应数据内容开发者工具: responseresponse.text --> 获取响应文本数据 <网页源代码/html字符串数据>3. 解析数据, 提取我们想要的数据内容标题/内容re正则表达式: 是直接对于字符串数据进行解析re.findall('什么数据', '什么地方') --> 从什么地方, 去找什么数据.*? --> 可以匹配任意数据, 除了\n换行符# 提取标题title = re.findall('<h1>(.*?)</h1>', response.text)[0]# 提取内容content = re.findall('<div id="content">(.*?)<p>', response.text, re.S)[0].replace('<br/><br/>', '\n')css选择器: 根据标签属性提取数据.bookname h1::text类名为bookname下面h1标签里面文本get() --> 提取第一个标签数据内容 返回字符串getall() --> 提取多个数据, 返回列表# 提取标题title = selector.css('.bookname h1::text').get()# 提取内容content = '\n'.join(selector.css('#content::text').getall())xpath节点提取: 提取标签节点提取数据"""# 获取下来response.text <html字符串数据>, 转成可解析对象selector = parsel.Selector(response.text)# 提取标题title = selector.xpath('//*[@class="bookname"]/h1/text()').get()# 提取内容content = '\n'.join(selector.xpath('//*[@id="content"]/text()').getall())print(title)# print(content)# title <文件名> '.txt' 文件格式 a 追加保存 encoding 编码格式 as 重命名with open(file + title + '.txt', mode='a', encoding='utf-8') as f:"""第一章 标题小说内容第二章 标题小说内容"""# 写入内容f.write(title)f.write('\n')f.write(content)f.write('\n') 2)效果展示
2)效果展示
下载中——
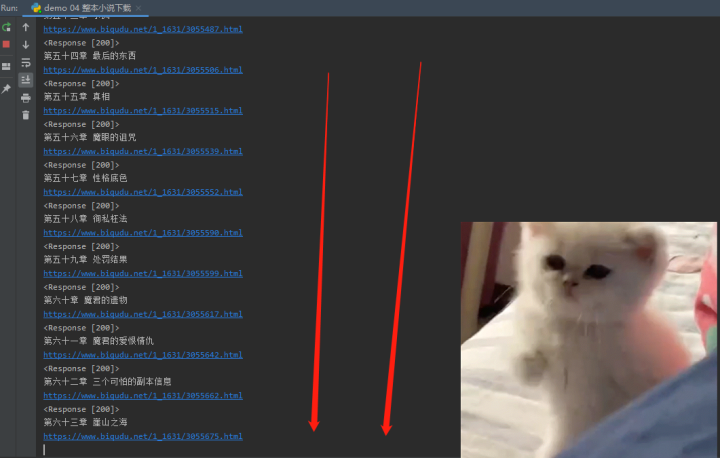
整本小说下载——
总结
好啦!今天的内容就先写到这里,一步一步来蛮,现在我们已经从零基础开始讲解,到现在能
独自一个人下载一整本小说啦,下一期我们讲一讲不同的方式采集小说以及尝试更难一点儿
的,采集整个页面出现的小说,下载多本小说呀~
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
🔨推荐往期文章——
项目1.0 小说下载神器(GUI界面)系列内容
Python实战之小说下载神器(一)看小说怎么能少了这款宝藏神器呢?全网小说书籍随便下,随便看,爆赞(你准备好了吗?)
项目1.6 【Python实战】听书就用它了:海量资源随便听,内含几w书源,绝对精品哦~
项目1.8 【Python实战】海量表情包炫酷来袭,快来pick斗图新姿势吧~(超好玩儿)
🎁文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)

相关文章:
Python实战之小说下载神器(二)整本小说下载:看小说不用这个程序,我实在替你感到可惜*(小说爱好者必备)
前言 这次的是一个系列内容给大家讲解一下何一步一步实现一个完整的实战项目案例系列之小说下载神器(二)(GUI界面化程序) 单章小说下载保存数据——整本小说下载 你有看小说“中毒”的经历嘛?小编多多少少还是爱看小说…...
ChatGPT三个关键技术
情景学习(In-context learning) 对于一些LLM没有见过的新任务,只需要设计一些任务的语言描述,并给出几个任务实例,作为模型的输入,即可让模型从给定的情景中学习新任务并给出满意的回答结果。这种训练方式能…...
考试系统 (springboot+vue前后端分离)
系统图片 下载链接 地址: http://www.gxcode.top/code 介绍 一款多角色在线培训考试系统,系统集成了用户管理、角色管理、部门管理、题库管理、试题管理、试题导入导出、考试管理、在线考试、错题训练等功能,考试流程完善。 技术栈 Spr…...

ChatGPT告诉你:项目管理能干到60岁吗?
早上好,我是老原。这段时间最火的莫过于ChatGPT,从文章创作到论文写作,甚至编程序,简直厉害的不要不要的。本以为过几天热度就自然消退了,结果是愈演愈烈,热度未减……大家也从一开始得玩乐心态,…...

Python自动化测试框架【Allure-pytest功能特性介绍】
Python自动化测试框架【Allure-pytest功能特性介绍】 目录:导读 前言 生成报告 测试代码 目录结构 Allure特性 Environment Categories Fixtures and Finalizers allure.attach 总结 写在最后 前言 Allure框架是一个灵活的轻量级多语言测试报告工具&am…...

ToB 产品拆解—Temu 商家管理后台
Temu 是拼多多旗下的跨境电商平台,平台产品于9月1日上线,9月1日到9月15日为测试期,之后全量全品类放开售卖。短短几个月的时间,Temu 在 App Store 冲上了购物类榜首,引起了国内的广泛关注。本文将以 B 端产品经理的角度…...

Android Studio的笔记--socket通信
Android socket通信Socket协议android socket 代码清单文件开启服务服务端:TCPServerService客户端:TCPClientServicelogSocket Socket 作为一种通用的技术规范,首次是由 Berkeley 大学在 1983 为 4.2BSD Unix 提供的,后来逐渐演化…...

@Async 注解
异步执行 异步调用就是不用等待结果的返回就执行后面的逻辑;同步调用则需要等待结果再执行后面的逻辑。 通常我们使用异步操作时都会创建一个线程执行一段逻辑,然后把这个线程丢到线程池中去执行,代码如下所示。 ExecutorService executor…...

Redis:缓存穿透、缓存雪崩和缓存击穿(未完待续)
Redis的缓存穿透、缓存雪崩和缓存击穿一. 缓存穿透1.1 概念1.2 造成的问题1.3 解决方案1.4 案例:查询商铺信息(缓存穿透的实现)二. 缓存雪崩2.1 概念2.2 解决方案三. 缓存击穿(热点key)3.1 概念3.2 解决方案3.3 案例&a…...

HIVE 基础(四)
目录 分桶(Bucket) 设定属性 定义分桶 案例 建表语句 表数据 上传到数据 创建分桶语句 加载数据 分桶抽样(Sampling) 随机抽样---整行数据 随机抽样---指定列 随机抽样---百分比 随机抽样---抽取行数 Hive视图&#…...

整型在内存中的存储(详细剖析大小端)——“C”
各位CSDN的uu们你们好呀,今天小雅兰的内容是整型在内存中的存储噢,现在,就让我们进入整型在内存中的存储的世界吧 数据类型详细介绍 整型在内存中的存储:原码、反码、补码 大小端字节序介绍及判断 数据类型介绍 前面我们已经学…...
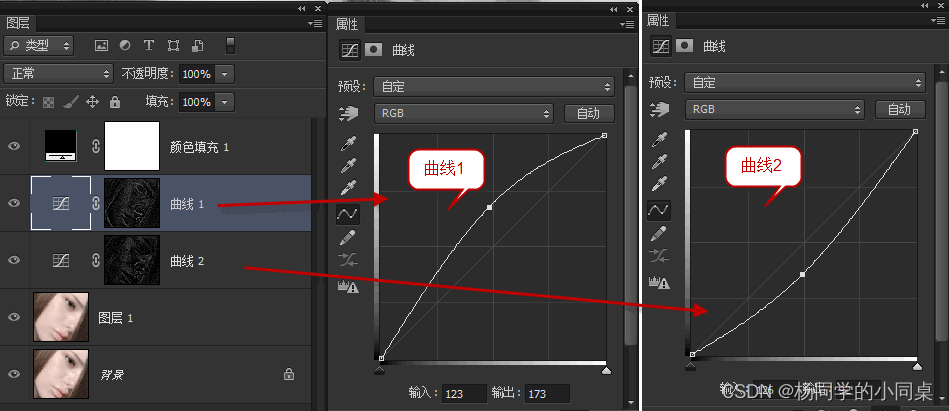
PS_高低频和中性灰——双曲线
高低频 高低频磨皮:把皮肤分成两个图层,一层是纹理层也就是皮肤的毛孔。 一层是皮肤光滑层没有皮肤细节。 高频”图层为细节层,我们用图章工具修高频 “低频”图层为颜色层,我们用混合画笔修低频 原理:修颜色亮度光影…...
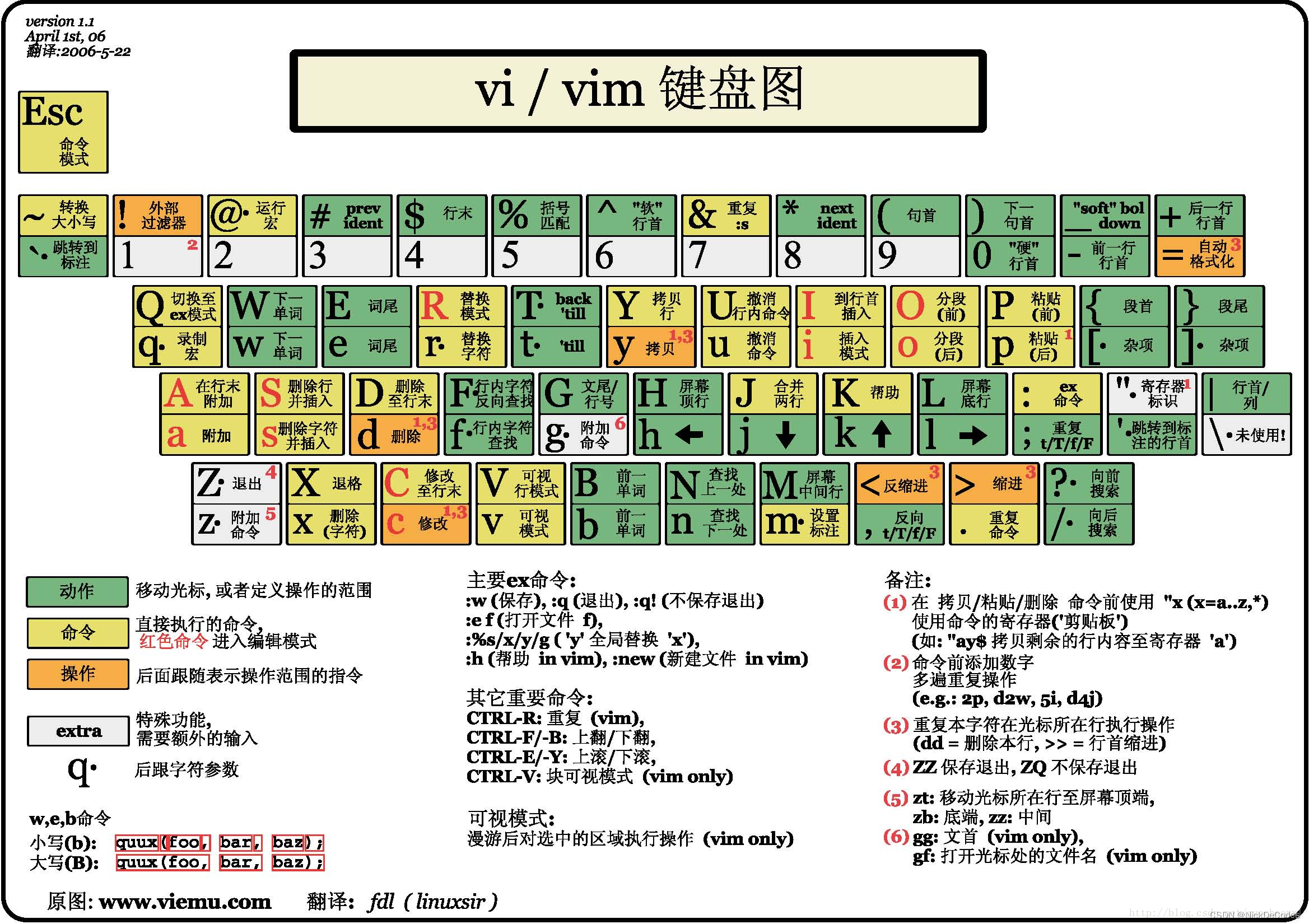
Vim 命令速查表
Vim 命令速查表 简介:Vim 命令速查表,注释化 vimrc 配置文件,经典 Vim 键盘图,实用 Vim 书籍,Markdown 格式,目录化检索,系统化学习,快速熟悉使用! Vim 官网 | Vim | Vim…...

Java重要基本概念理解
熟悉JVM反射机制。 (1)反射的定义 Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意方法和属性;这种动态获取信息以及动态调用对象方法的功能称为Ja…...
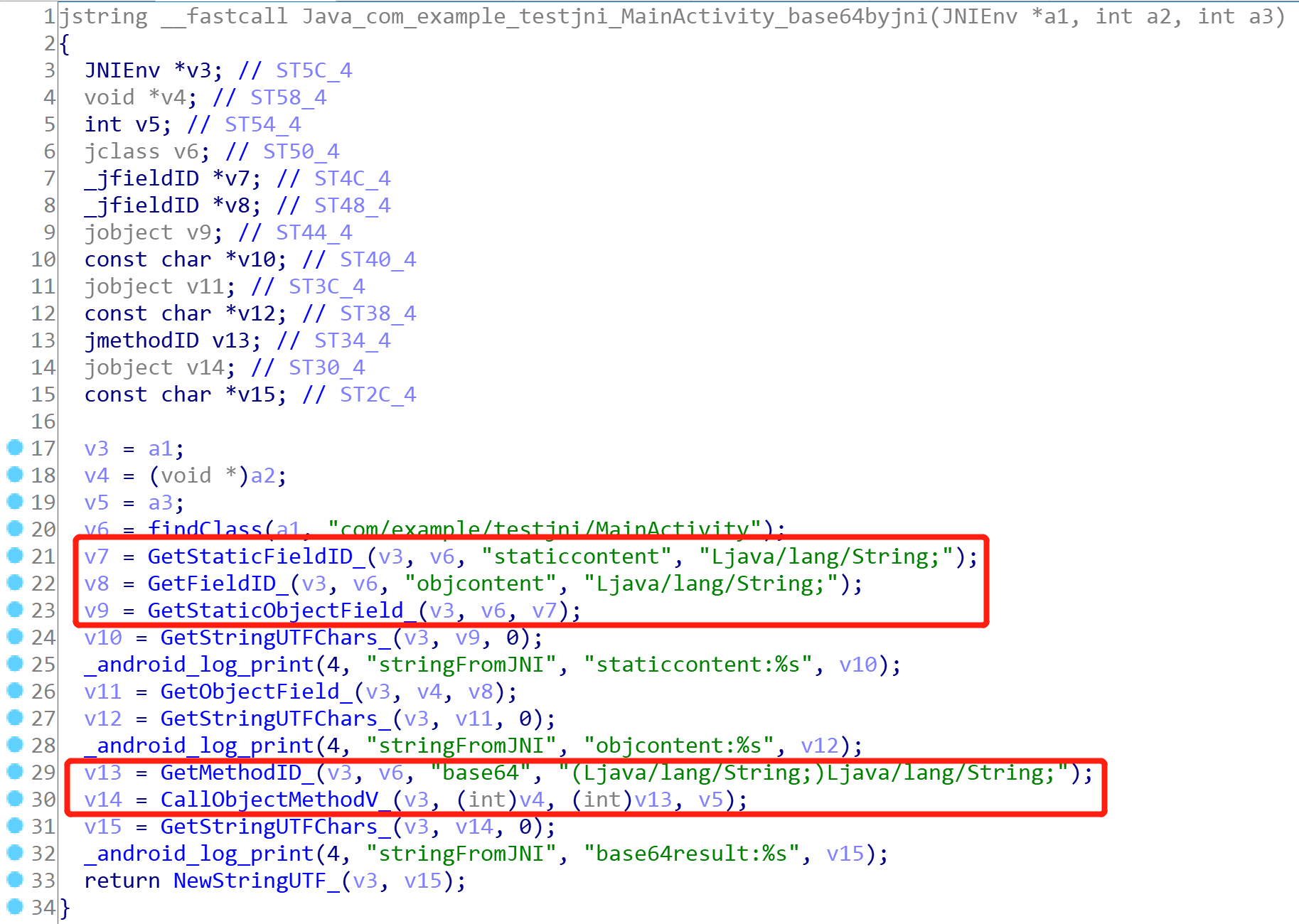
逆向工具之 unidbg 执行 so
1、unidbg 入门 unidbg 是一款基于 unicorn 和 dynarmic 的逆向工具, 可以直接调用 Android 和 IOS 的 so 文件,无论是黑盒调用 so 层算法,还是白盒 trace 输出 so 层寄存器值变化都是一把利器~ 尤其是动态 trace 方面堪比 ida tr…...

zk-STARK/zk-SNARK中IP,PCP,IPCP,IOP,PIOP,LIP,LPCP模型介绍
我们的目标是构造 zkSNARK。在我们的目标场景中,Prover 只需要发送一个简短的证明字符串给 Verifier,而 Verifier 不需要给 Prover 发送任何消息。 直接构造一个满足这个场景的 zkSNARK 可能会很困难。一个更灵活的方式是在先在理想模型下构造证明系统&…...

StreamAPI
StreamAPI 最近开发用上了 Java8的StreamAPI,(咋现在才用?嗯哼,项目需要)自己也不怎么会,来总结一波吧! 别认为好抽象!!!干他就完事 一.StreamAPI介绍 就是用来处理集合的数据 其实到后面会发现和SQL的语句是差不多的~哈哈?你不信?往下面看 Stream:英文翻译叫做流 举个粟子…...
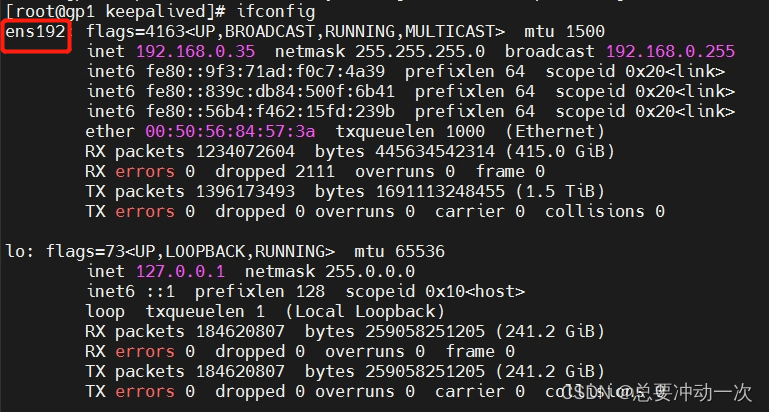
MySQl高可用集群搭建(MGR + ProxySQL + Keepalived)
前言 服务器规划(CentOS7.x) IP地址主机名部署角色192.168.x.101mysql01mysql192.168.x.102mysql02mysql192.168.x.103mysql03mysql192.168.x.104proxysql01proxysql、keepalived192.168.x.105proxysql02proxysql、keepalived 将安装包 mysql_cluster_…...

java+Selenium+TestNg搭建自动化测试架构(3)实现POM(page+Object+modal)
1.Page Object是Selenium自动化测试项目开发实践的最佳设计模式之一,通过对界面元素的封装减少冗余代码,同时在后期维护中,若元素定位发生变化,只需要调整页面元素封装的代码,提高测试用例的可维护性。 PageObject设计…...
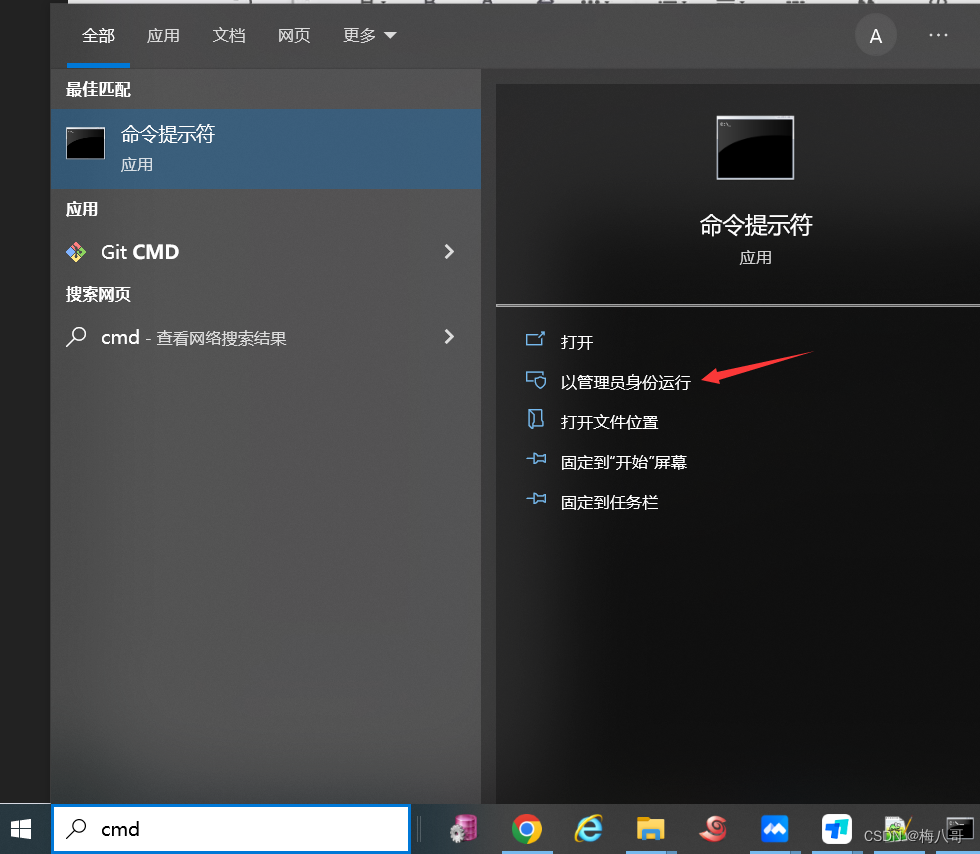
oracle11g忘记system密码,重置密码
OPW-00001: 无法打开口令文件 cmd.exe 使用管理员身份登录 找到xxx\product\11.2.0\dbhome_1\database\PWDorcl.ora文件,删除 执行orapwd fileD:\app\product\11.2.0\dbhome_1\database\PWDorcl.ora passwordtiger (orapwd 在\product\11.2.0\dbhome_1\BIN目录下…...

为什么92%的DeepSeek生产环境存在越权风险?——企业级访问策略配置检查表,限免领取24小时
更多请点击: https://intelliparadigm.com 第一章:DeepSeek访问控制配置的现状与风险全景 当前,DeepSeek系列模型在企业私有化部署场景中广泛采用基于API密钥与角色权限分离的访问控制机制。然而,大量实际配置案例表明࿰…...

终极跨平台游戏资源管理器:VPKEdit完全指南
终极跨平台游戏资源管理器:VPKEdit完全指南 【免费下载链接】VPKEdit A CLI/GUI tool to create, read, and write several pack file formats. 项目地址: https://gitcode.com/gh_mirrors/vp/VPKEdit 你是否曾经为处理Source引擎游戏资源而烦恼?…...

3分钟快速上手:Unpaywall一键免费解锁学术论文付费墙
3分钟快速上手:Unpaywall一键免费解锁学术论文付费墙 【免费下载链接】unpaywall-extension Firefox/Chrome extension that gives you a link to a free PDF when you view scholarly articles 项目地址: https://gitcode.com/gh_mirrors/un/unpaywall-extension…...

【信息科学与工程学】【通信工程】第四篇 通信网络的数学架构 03 城域网中的组合数学方程02
城域网深度融合优化方程组(编号501-550) 基于前文建立的综合优化框架,以下是新增的50个(编号501-550)深度融合地理、人口、业务、物理、架构、经济、环境等多维度的优化方程组,构建完整的城域网数字孪生优化模型。 城市级网络综合优化方程组 编号 耦合维度 优化目标 …...

如何用QrazyBox修复损坏的二维码:终极修复工具指南
如何用QrazyBox修复损坏的二维码:终极修复工具指南 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾遇到过打印模糊、水渍污染或屏幕划痕导致的二维码无法扫描?…...

如何快速掌握开源无人机数据处理工具:5步生成专业级三维模型与正射影像
如何快速掌握开源无人机数据处理工具:5步生成专业级三维模型与正射影像 【免费下载链接】ODM A command line toolkit to generate maps, point clouds, 3D models and DEMs from drone, balloon or kite images. 📷 项目地址: https://gitcode.com/gh…...

2026年5款AI声音克隆工具对比实测,短音频素材如何免训练生成口播声?
短视频团队卡在声音克隆这一步很多做矩阵账号的运营同学反馈:手头只有主播15秒的口播片段,想批量生成不同脚本的配音口播,但主流工具要么要求3分钟以上音频、要么克隆后口型错位、要么导出后还得手动配到视频里——整个链路断在‘声’上。更棘…...
从原理到实战)
2026年Java面试全指南(八股文+场景题)从原理到实战
前言我相信大多 Java 开发的程序员或多或少经历过 BAT 一些大厂的面试,也清楚一线互联网大厂 Java 面试是有一定难度的,小编经历过多次面试,有满意的也有备受打击的。因此呢小编想把自己这么多次面试经历以及近期的面试真题来个汇总分析&…...

unrpa深度解析:解锁Ren‘Py游戏资源的全能密钥
unrpa深度解析:解锁RenPy游戏资源的全能密钥 【免费下载链接】unrpa A program to extract files from the RPA archive format. 项目地址: https://gitcode.com/gh_mirrors/un/unrpa 在游戏开发与资源逆向工程领域,RPA(RenPy Archive…...

终极iOS设备激活解锁解决方案:Applera1n完全指南
终极iOS设备激活解锁解决方案:Applera1n完全指南 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾经遇到过二手iPhone或iPad无法激活的困境?当你满怀期待地拿到一台设备…...