redis 核心数据结构
一、简述
redis是一个开源的使用C语言编写的一个kv存储系统,是一个速度非常快的非关系远程内存数据库。它支持包括String、List、Set、Zset、hash五种数据结构。
除此之外,通过复制、持久化和客户端分片等特性,用户可以很方便地将redis扩展成一个能够包含数百GB数据和每秒处理上百万次的请求的系统。目前支持多种语言的api,方便用户使用。
redis同时也内置了事务、LUA脚本、复制等功能,提供两种持久化选项,一种是每隔一段时间将数据导入到磁盘(RDB快照模式),另一种是追加命令到日志中(AOF模式)。如果只是作为高效的内存数据库使用也可以关闭持久化功能。
通过哨兵(sentinel)和自动分区(Cuuster)的方式可以提高redis服务器的高可用性。
与关系型数据库相比,redis的命令请求不需要经过查询分析器或查询优化器进行处理,也避免了更新数据时引起的随机读\写,这些慢操作。它直接读写内存中的数据,并且数据是按照一定的数据结构存储的,所以它的速度非常快。
- redis命令手册:http://www.redis.cn/commands.html
- redis 命令说明:https://www.redis.net.cn/order/
二、数据类型
声明:这里的数据类型是value的数据类型,key的数据类型(
区分大小写)都是字符串;
1.1 数据类型的使用场景分别是什么?
Redis 提供了丰富的数据类型,常见的有五种数据类型:String(字符串),Hash(哈希),List(列表),Set(集合)、Zset(有序集合)。
随着 Redis 版本的更新,后面又支持了四种数据类型: BitMap(2.2 版新增)、HyperLogLog(2.8 版新增)、GEO(3.2 版新增)、Stream(5.0 版新增)。 Redis 五种数据类型的应用场景:
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能以消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
1.2 五种常见的 Redis 数据类型是怎么实现?
Redis 数据类型和底层数据结构的对应关图,上边是 Redis 6.0 之前版本,现在看还是有点过时了,下边是现在 Redis 7.0 版本的。

1.3 String 类型的内部实现
String 类型的底层的数据结构实现主要是 SDS(简单动态字符串)。 SDS 和我们认识的 C 字符串不太一样,之所以没有使用 C 语言的字符串表示,因为 SDS 相比于 C 的原生字符串:
- SDS 不仅可以保存文本数据,还可以保存二进制数据。因为 SDS 使用 len 属性的值而不是空字符来判断字符串是否结束,并且 SDS 的所有 API 都会以处理二进制的方式来处理 SDS 存放在 buf[] 数组里的数据。所以 SDS 不光能存放文本数据,而且能保存图片、音频、视频、压缩文件这样的二进制数据。
- SDS 获取字符串长度的时间复杂度是 O(1)。因为 C 语言的字符串并不记录自身长度,所以获取长度的复杂度为 O(n);而 SDS 结构里用 len 属性记录了字符串长度,所以复杂度为 O(1)。
- Redis 的 SDS API 是安全的,拼接字符串不会造成缓冲区溢出。因为 SDS 在拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。
1.4 为什么重新设计 SDS 数据结构?
C语言没有Java里面的String类型,只能是靠自己的char[]来实现,字符串在 C 语言中的存储方式,想要获取 「Redis」的长度,需要从头开始遍历,直到遇到 ‘\0’ 为止。所以,Redis 没有直接使用 C 语言传统的字符串标识,而是自己构建了一种名为简单动态字符串 SDS(simple dynamic string)的抽象类型,并将 SDS 作为 Redis 的默认字符串。
C语言的char[]数组 和SDS字符串的对比

C 源码中体现形式

1.5 SDS 底层物理编码方式有哪些?
SDS底层物理编码由 int、embstr、raw 三种方式组成。其中embstr 与 raw 类型底层的数据结构其实都是 SDS (简单动态字符串,Redis 内部定义 sdshdr 一种结构)。只有整数才会使用 int,如果是浮点数, Redis 内部其实先将浮点数转化为字符串值,然后再保存。
不同编码类型的对比

底层数据结构体现

1.5 List 类型内部实现
Redis3.0 之前
在Redis3.0之前,list采用的底层数据结构是ziplist压缩列表+linkedList双向链表,然后在高版本的Redis中底层数据结构是quicklist(替换了ziplist+linkedList),而quicklist也用到了ziplist。
- 如果列表的元素个数小于 512 个(默认值,可由 list-max-ziplist-entries 配置),列表每个元素的值都小于 64 字节(默认值,可由 list-max-ziplist-value 配置),Redis 会使用压缩列表作为 List 类型的底层数据结构;
- 如果列表的元素不满足上面的条件,Redis 会使用双向链表作为 List 类型的底层数据结构;
优缺点分析

Redis3.0 之后
主要通过quicklist实现,它实际上是 zipList 和 linkedList 的混合体,它将 linkedList按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。

quicklist就是「双向链表 + 压缩列表」组合,因为一个 quicklist 就是一个链表,而链表中的每个元素又是一个压缩列表
Redis7 实现
因为ziplist存在连续更新问题,所以在redis7 废除 ziplist 底层结构, 使用新的数据结构 listpack 紧凑链表,彻底解决这个问题。
List 使用 quicklist 来存储,quicklist 存储了双向链表,每个节点都是一个 listpack。
redis7 源码体现

1.6 已有 ziplist,为什么又出 listpack?
listpack 是 Redis 设计用来取代掉 ziplist 的数据结构,它通过每个节点记录自己的长度且放在节点的尾部,来彻底解决掉了 ziplist 存在的连锁更新的问题。
ziplist 的连锁更新问题
1)ziplist存储结构


2)复现场景
压缩列表新增某个元素或修改某个元素时,如果空间不不够,压缩列表占用的内存空间就需要重新分配。而当新插入的元素较大时,可能会导致后续元素的 prevlen 占用空间都发生变化,从而引起「连锁更新」问题,导致每个元素的空间都要重新分配,造成访问压缩列表性能的下降。
案例说明:压缩列表每个节点正因为需要保存前一个节点的长度字段,就会有连锁更新的隐患
第一步:现在假设一个压缩列表中有多个连续的、长度在 250~253 之间的节点,如下图:
因为这些节点长度值小于 254 字节,所以 prevlen 属性需要用 1 字节的空间来保存这个长度值,一切OK,O(∩_∩)O哈哈~

第二步:这时,如果将一个长度大于等于 254 字节的新节点加入到压缩列表的表头节点,即新节点将成为entry1的前置节点,如下图:

因为entry1节点的prevlen属性只有1个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作并将entry1节点的prevlen 属性从原来的 1 字节大小扩展为 5 字节大小。
第三步:连续更新问题出现

entry1节点原本的长度在250~253之间,因为刚才的扩展空间,此时entry1节点的长度就大于等于254,因此原本entry2节点保存entry1节点的 prevlen属性也必须从1字节扩展至5字节大小。entry1节点影响entry2节点,entry2节点影响entry3节点…一直持续到结尾。
这种在特殊情况下产生的连续多次空间扩展操作就叫做「连锁更新」
1.7 Hash 类型内部实现
Hash 类型的底层数据结构是由压缩列表或哈希表实现的:
- 如果哈希类型元素个数小于 512 个(默认值,可由 hash-max-ziplist-entries 配置),所有值小于 64 字节(默认值,可由 hash-max-ziplist-value 配置)的话,Redis 会使用压缩列表作为 Hash 类型的底层数据结构;
- 如果哈希类型元素不满足上面条件,Redis 会使用哈希表作为 Hash 类型的底层数据结构。
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
1.8 Set 类型内部实现
Redis用整数集合(intset)或 哈希表 hashtable存储set。
- 如果集合中的元素都是整数且元素个数小于 512 (默认值,set-maxintset-entries配置)个,Redis 会使用整数集合(intset)作为 Set 类型的底层数据结构;
- 如果集合中的元素不满足上面条件,则 Redis 使用哈希表(数组+链表)作为 Set 类型的底层数据结构,key就是元素的值,value为null
1.9 ZSet 类型内部实现
Zset 类型的底层数据结构是由压缩列表或跳表实现的:
- 如果有序集合的元素个数小于 128 个,并且每个元素的值小于 64 字节时,Redis 会使用压缩列表作为 Zset 类型的底层数据结构;
- 如果有序集合的元素不满足上面的条件,Redis 会使用跳表作为 Zset 类型的底层数据结构;
在 Redis 7.0 中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
三、总结
本章介绍了redis的十大数据结构和它们使用的底层存储原理,为了达到节省内存和快速访问的目的每种数据结构可能有两种存储和访问结构,在必要的时候会由一种结构转换成另一种结构,但这个转换的过程会消耗系统性能和内存空间的,所以在使用的过程中需要注意这些配置参数,开发中尽量避免达到这些峰值,使得redis能够持续的提供高效的服务。
3.1 类型以及常见场景
- String 类型的应用场景:缓存对象、常规计数、分布式锁、共享 session 信息等。
- List 类型的应用场景:消息队列(但是有两个问题:1. 生产者需要自行实现全局唯一 ID;2. 不能消费组形式消费数据)等。
- Hash 类型:缓存对象、购物车等。
- Set 类型:聚合计算(并集、交集、差集)场景,比如点赞、共同关注、抽奖活动等。
- Zset 类型:排序场景,比如排行榜、电话和姓名排序等。
Redis 后续版本又支持四种数据类型,它们的应用场景如下:
- BitMap(2.2 版新增):二值状态统计的场景,比如签到、判断用户登陆状态、连续签到用户总数等;
- HyperLogLog(2.8 版新增):海量数据基数统计的场景,比如百万级网页 UV 计数等;
- GEO(3.2 版新增):存储地理位置信息的场景,比如滴滴叫车;
- Stream(5.0 版新增):消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
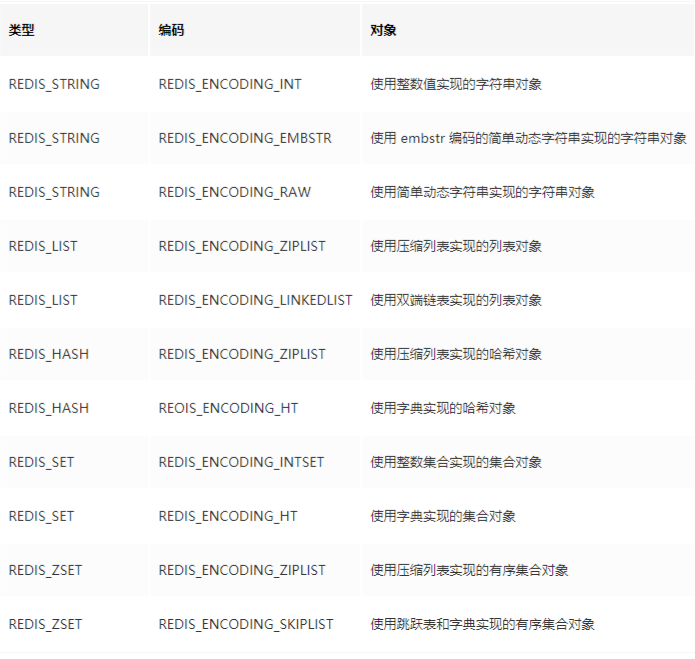
3.2 底层数据类型对应底层数据结构
1)String (字符串)
1. int:8个字节的长整型。
2. embstr:小于等于44个字节的字符串。
3. raw:大于44个字节的字符串。
Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
2)Hash(哈希)
ziplist(压缩列表):当哈希类型元素个数小于hash-max-ziplist-entries 配置(默认512个)、同时所有值都小于hash-max-ziplist-value配置(默认64 字节)时,Redis会使用ziplist作为哈希的内部实现,ziplist使用更加紧凑的 结构实现多个元素的连续存储,所以在节省内存方面比hashtable更加优秀。
hashtable(哈希表):当哈希类型无法满足ziplist的条件时,Redis会使 用hashtable作为哈希的内部实现,因为此时ziplist的读写效率会下降,而hashtable的读写时间复杂度为O(1)。
3)List(列表)
ziplist(压缩列表):当列表的元素个数小于list-max-ziplist-entries配置 (默认512个),同时列表中每个元素的值都小于list-max-ziplist-value配置时 (默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使 用。
linkedlist(链表):当列表类型无法满足ziplist的条件时,Redis会使用 linkedlist作为列表的内部实现。quicklist ziplist和linkedlist的结合以ziplist为节点的链表(linkedlist)
Redis7 开始废弃ziplist(压缩列表)、使用listpack(紧凑链表) 代替。
listpack(紧凑列表):当列表的元素个数小于list-max-listpack-entries配置 (默认512个),同时列表中每个元素的值都小于list-max-listpack-value配置时 (默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使 用。
4)set (集合)
intset(整数集合):当集合中的元素都是整数且元素个数小于set-max-intset-entries配置(默认512个)时,Redis会用intset来作为集合的内部实现,从而减少内存的使用。
hashtable(哈希表):当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现。
5)Sorted Set (有序集合)
ziplist(压缩列表):当有序集合的元素个数小于zset-max-ziplist- entries配置(默认128个),同时每个元素的值都小于zset-max-ziplist-value配 置(默认64字节)时,Redis会用ziplist来作为有序集合的内部实现,ziplist 可以有效减少内存的使用。
skiplist(跳跃表):当ziplist条件不满足时,有序集合会使用skiplist作 为内部实现,因为此时ziplist的读写效率会下降。
Redis7 开始废弃ziplist(压缩列表)、使用listpack(紧凑链表) 代替。
listpack(紧凑列表):当列表的元素个数小于list-max-listpack-entries配置 (默认512个),同时列表中每个元素的值都小于list-max-listpack-value配置时 (默认64字节),Redis会选用ziplist来作为列表的内部实现来减少内存的使 用。
3.3 底层数据结构时间复杂度

3.4 数据类型与物理编码对应表
相关文章:
redis 核心数据结构
一、简述 redis是一个开源的使用C语言编写的一个kv存储系统,是一个速度非常快的非关系远程内存数据库。它支持包括String、List、Set、Zset、hash五种数据结构。 除此之外,通过复制、持久化和客户端分片等特性,用户可以很方便地将redis扩展…...
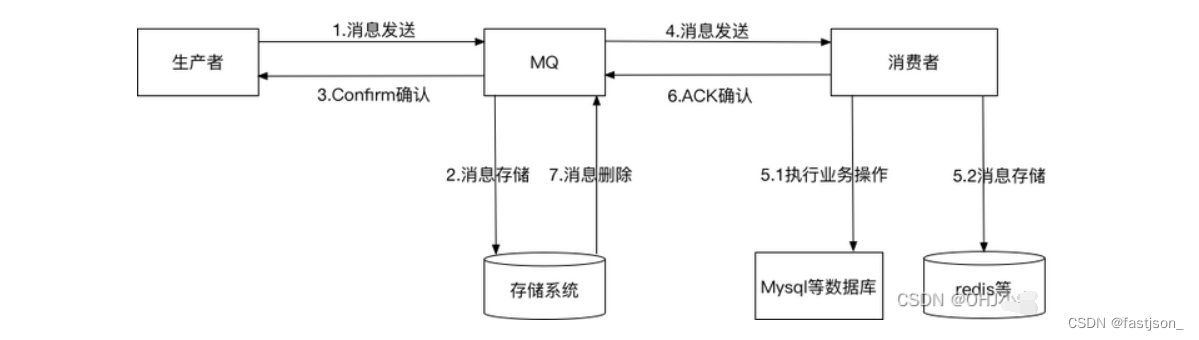
RabbitMQ消息可靠性(一)-- 生产者消息确认
前言 在项目中,引入了RabbitMQ这一中间件,必然也需要在业务中增加对数据安全性的一层考虑,来保证RabbitMQ消息的可靠性,否则一个个消息丢失可能导致整个业务的数据出现不一致等问题,对系统带来巨大的影响,…...

9 种方法使用 Amazon CodeWhisperer 快速构建应用
Amazon CodeWhisperer 是一款很赞的生成式人工智能编程工具。自从在工作中使用了 CodeWhisperer,我发现不仅代码编译的效率有所提高,应用开发的工作也变得快乐起来。然而,任何生成式 AI 工具的有效学习都需要初学者要有接受新工作方式的心态和…...
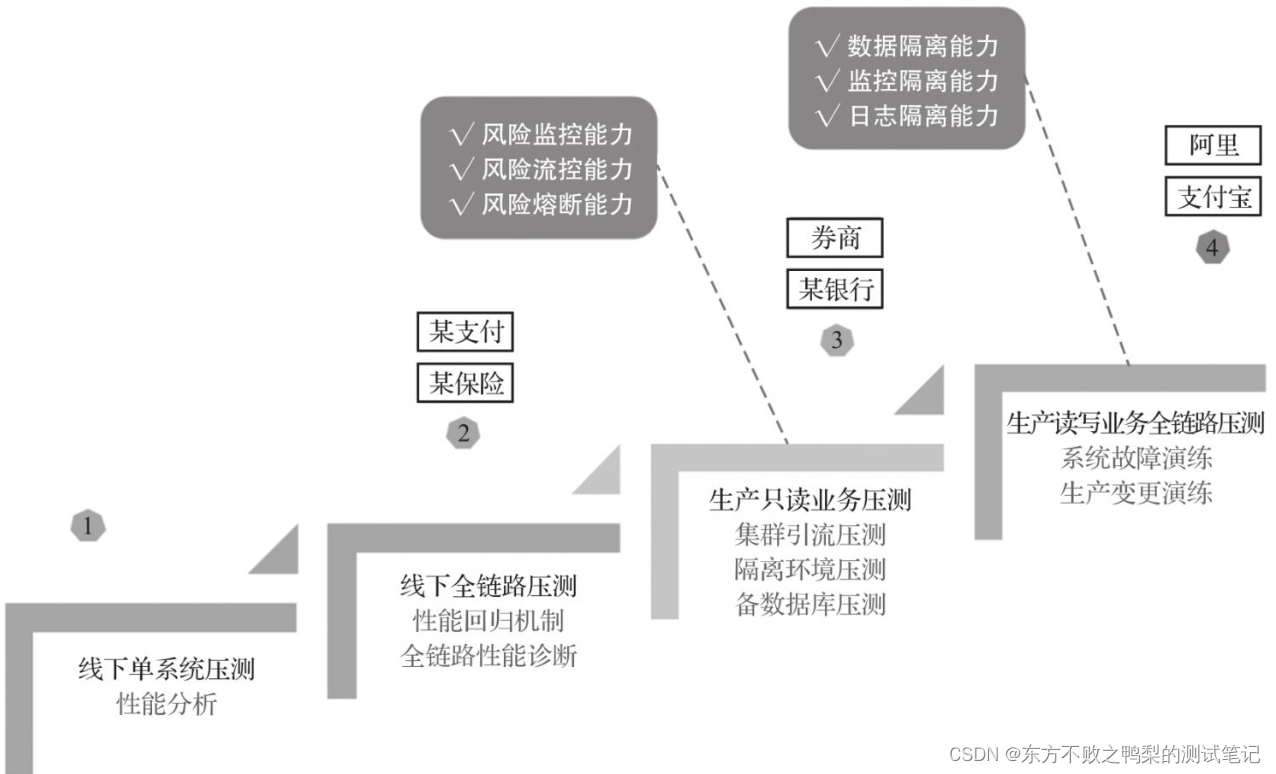
性能测试-性能工程落地的4个阶段(21)
性能工程按照不同的内容和目的划分为4个阶段,分别是线下单系统压测分析阶段、线下全链路压测分析阶段、生产只读业务压测及容量评估阶段、生产读写业务全链路压测及容量评估阶段。(也可以理解为一个企业性能测试体系的发展阶段) 线下单系统压测分析阶段 针对单系统的性能…...

小程序 navigateBack 携带参数返回的三种方式(详细)
如果觉着主图好看,点个赞,你早晚也会看到这么好看的景色! 第一种方式 getCurrentPages 获取当前页面栈。数组中第一个元素为首页,最后一个元素为当前页面。不要尝试修改页面栈,会导致路由以及页面状态错误。不要在 App.onLaunch 的时候调用 getCurrentPages(),此时 page …...
通过内网穿透实现远程连接群晖Drive,轻松实现异地访问群晖NAS
文章目录 前言1.群晖Synology Drive套件的安装1.1 安装Synology Drive套件1.2 设置Synology Drive套件1.3 局域网内电脑测试和使用 2.使用cpolar远程访问内网Synology Drive2.1 Cpolar云端设置2.2 Cpolar本地设置2.3 测试和使用 3. 结语 前言 群晖作为专业的数据存储中心&…...

vue3 + vite常用工具
1. plop 1.1 安装 yarn add plop -D1.2 使用 1.2.1 package.json 配置脚本命令 "scripts": {"dev": "vite --mode dev","build": "vue-tsc --noEmit && vite build","serve": "vite preview"…...

Vue框架分享与总结
总结开发中最常用的vue语法,以及对特定语法的理解。vue官网 文章目录 一、创建vue项目1、使用开发工具创建2、使用命令行创建3、vue框架结构4、Vue文件结构 二、Vue 常用模板语法1、v-if、v-show2、v-for3、v-on4、v-bind5、v-model 三、组件通信1、父组件给子组件传…...
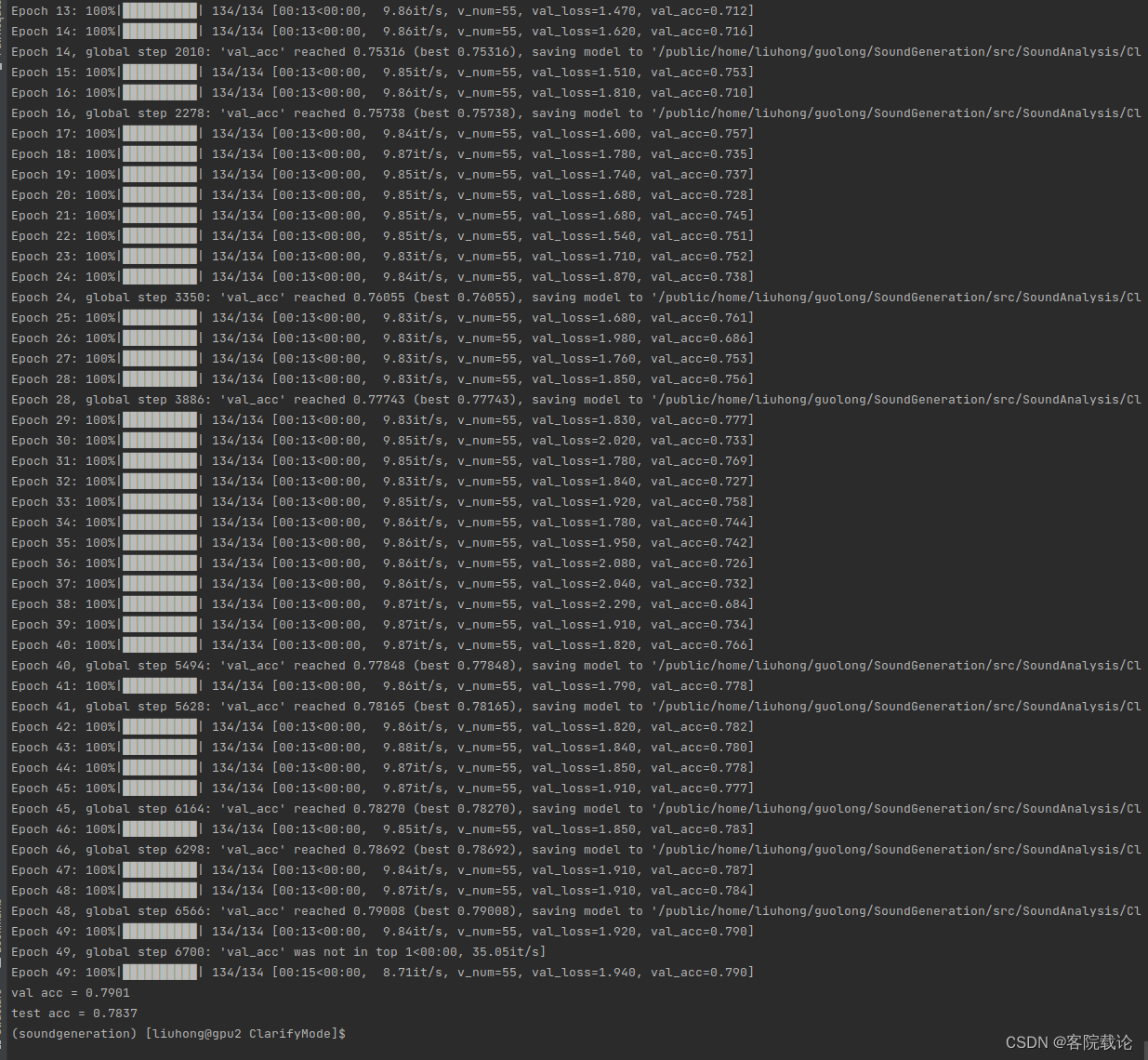
声音生成评价指标——使用声音分类模型评价生成声音质量(基于resnetish、VGGish、AlexNet)
文章目录 引言正文数据预处理将wav转成log-mel频谱图进行保存创建dataset类保存数据 模型定义模型训练过程训练代码定义loss为nan从AlexNet到ResNetloss上下剧烈波动——使用学习率衰减策略学习率调整——根据准确率来调整学习率数据处理问题 模型的测试 总结 引言 这篇文章主要…...
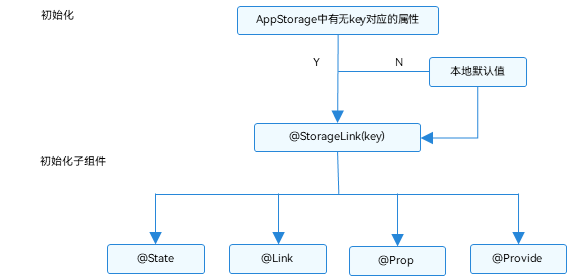
HarmonyOS学习路之方舟开发框架—学习ArkTS语言(状态管理 六)
AppStorage:应用全局的UI状态存储 AppStorage是应用全局的UI状态存储,是和应用的进程绑定的,由UI框架在应用程序启动时创建,为应用程序UI状态属性提供中央存储。 和LocalStorage不同的是,LocalStorage是页面级的&…...

SPA首屏加载速度慢
什么是首屏加载 首屏时间(First Contentful Paint),指的是浏览器从响应用户输入网址地址,到首屏内容渲染完成的时间,此时整个网页不一定要全部渲染完成,但需要展示当前视窗需要的内容 首屏加载可以说是用…...
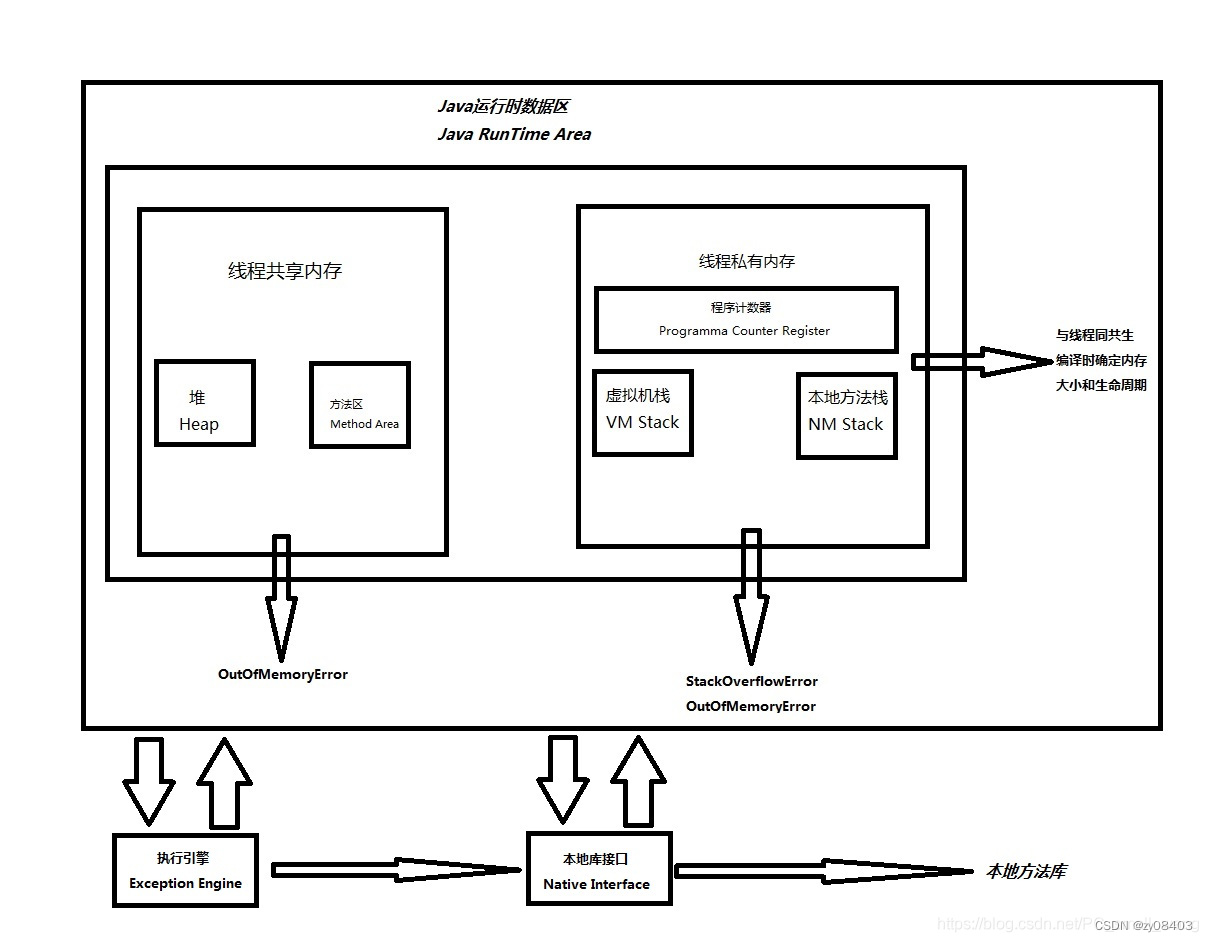
JVM执行流程
一、Java为什么是一种跨平台的语言? 通常,我们编写的java源代码会被JDK的编译器编译成字节码文件,再由JVM将字节码文件翻译成计算机读的懂得机器码进行执行;因为不同平台使用的JVM不一样,所以不同的JVM会把相同的字节码…...

laravel 凌晨0点 导出数据库
一、创建导出模型 <?php namespace App\Models;use Illuminate\Support\Facades\DB;class DbBackup {private $table;public function __construct(){$this->table env(DB_DATABASE);}public function run($file ){$file !$file ? public_path($this->t…...
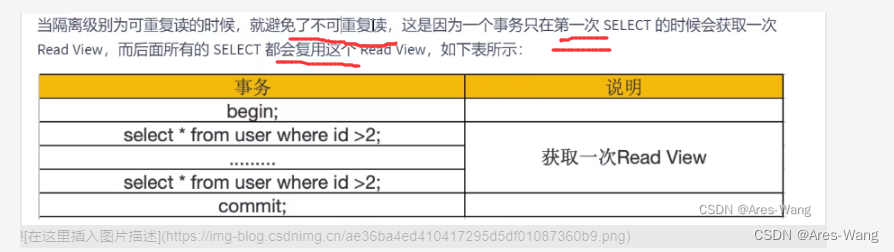
mysql MVCC多版本并发控制
mvcc的概念 mvcc 的实现依赖于: 隐藏字段 行格式(row_id,trx_id,roll_ponter)UndologRead view innodb 存储引擎的表来说,聚集索引记录中都包含两个必要的隐藏字段,row_id(如果没有聚集索引,才会创建的) …...

new/delete, malloc/free 内存泄漏如何检测
区别: 首先new/delete是运算符,malloc/free是库函数。malloc/free只开辟内存不初始化;new/delete及开辟内存也初始化。抛出异常的方式:new/delete开辟失败使用抛出bad_alloc;malloc/free通过返回值判断。malloc和new区…...

Java开发推荐关注的网站
一、开发者社区 阿里云开发者社区:https://developer.aliyun.com/腾讯云开发者社区:https://cloud.tencent.com/developer 二、开发规范 阿里巴巴Java开发规范 github地址:https://github.com/alibaba/p3c gitcode地址:https:/…...
OpenHarmony社区运营报告(2023年8月)
本月快讯 2023年8月3日,OpenAtom OpenHarmony(以下简称“OpenHarmony”)发布了Beta2版本。OpenHarmony 4.0 Beta2在系统能力、应用框架、分布式通信、媒体功能、安全性等方面进行了全面升级。其中,ArkUI增强了界面组件能力&#x…...
)
Web学习笔记-React(路由)
笔记内容转载自 AcWing 的 Web 应用课讲义,课程链接:AcWing Web 应用课。 CONTENTS 1. Web分类2. Route组件3. URL中传递参数4. Search Params传递参数5. 重定向6. 嵌套路由 本节内容是如何将页面和 URL 一一对应起来。 1. Web分类 Web 页面可以分为两…...
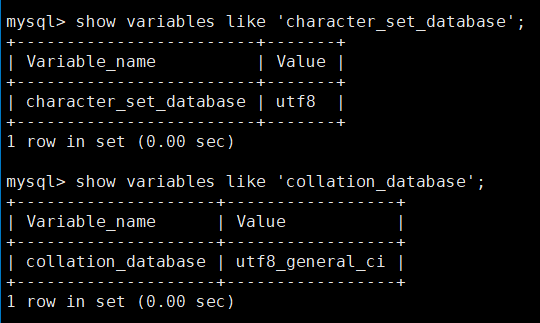
MySQL无法查看系统默认字符集以及校验规则
show variables like character_set_database; show variables like collation_database;这个错误信息表示MySQL在尝试访问performance_schema.session_variables表时,发现该表不存在。这个问题可能是由于MySQL的版本升级导致的。解决这个问题的一种方法是运行mysql…...

不负昭华,前程似锦,新一批研发效能认证证书颁发丨IDCF
亲爱的认证学员, 恭喜你成功获得由国家工业和信息化部教育与考试中心颁发的职业技术证书——《研发效能(DevOps)工程师国家职业技术认证》。你的努力和才华得到了官方的认可,这是你职业生涯中的一个重要的里程碑。 这个证书不仅代表着你的专业知识和技…...

深入Windows内核的“心脏”:通过WRK源码理解ntoskrnl.exe与HAL的协作机制
深入Windows内核的“心脏”:通过WRK源码理解ntoskrnl.exe与HAL的协作机制 在计算机科学领域,操作系统内核堪称最复杂的软件工程之一。作为Windows操作系统的核心,ntoskrnl.exe与硬件抽象层(HAL)的协作机制长期以来都是开发者们津津乐道的话题…...

大数据量存储终极指南:10个高效数据分片技巧
大数据量存储终极指南:10个高效数据分片技巧 【免费下载链接】til :memo: Today I Learned 项目地址: https://gitcode.com/gh_mirrors/ti/til 在当今数据爆炸的时代,高效处理和存储海量数据已成为企业技术架构的核心挑战。数据分片作为一种关键的…...

【独家首发】DeepSeek-VL与R1在HumanEval上的性能断层:87.3 vs 62.1分,这15.2分差距究竟卡在哪一行代码?
更多请点击: https://intelliparadigm.com 第一章:DeepSeek-VL与R1在HumanEval上的性能断层现象 HumanEval 是评估代码生成模型逻辑正确性的黄金基准,其测试集由 164 道手写 Python 编程题构成,每题包含函数签名、文档字符串和若…...

基于MCP协议与HaE工具构建AI安全情报助手实战指南
1. 项目概述:一个为安全工程师量身定制的“情报雷达”如果你是一名安全工程师、渗透测试人员或者负责企业安全运营的从业者,那么你一定对“信息收集”和“威胁情报”这两个词深有体会。每天,我们都需要从海量的数据源中——无论是公开的漏洞库…...

ThunderAI:开源本地AI助手桌面应用部署与核心架构解析
1. 项目概述:一个开源的AI助手桌面应用 最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“ThunderAI”。这名字听起来就挺带劲,对吧?点进去一看,是个用Python写的桌面应用程序,核心功能是把几个…...

内容创作团队如何通过多模型选型提升文案生成质量与效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何通过多模型选型提升文案生成质量与效率 对于新媒体运营和内容营销团队而言,持续产出高质量、风格多样…...

QProcess::FailedToStart “No program defined“。qtcreator用的好好的,然后就不能调试了
点击 项目-》运行-》执行档根本原因:执行档:路径为空 解决办法:添加这样执行档 就有路径了。就可以用了...

Windows和Office激活难题终结者:KMS智能激活脚本全攻略
Windows和Office激活难题终结者:KMS智能激活脚本全攻略 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 你是否曾为Windows系统那恼人的激活提醒而烦恼?是否因为Office突然…...

3分钟解决Windows 11 LTSC应用生态缺失:微软商店一键恢复终极指南
3分钟解决Windows 11 LTSC应用生态缺失:微软商店一键恢复终极指南 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore 你是否正在使用Windows …...

【博安通BW16模组专题②】实战TCP客户端:从指令到云端数据透传
1. 认识BW16模组的TCP客户端功能 博安通BW16模组作为一款高性价比的物联网通信模块,其TCP客户端功能在实际项目中应用广泛。简单来说,TCP客户端就是能够主动连接服务器的终端设备,比如我们常见的智能家居设备连接云端服务器,就是典…...