【python函数】torch.nn.Embedding函数用法图解
学习SAM模型的时候,第一次看见了nn.Embedding函数,以前接触CV比较多,很少学习词嵌入方面的,找了一些资料一开始也不是很理解,多看了两遍后,突然顿悟,特此记录。
SAM中PromptEncoder中运用nn.Embedding:
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
torch.nn.Embedding官方页面
1. torch.nn.Embedding介绍
(1)词嵌入简介
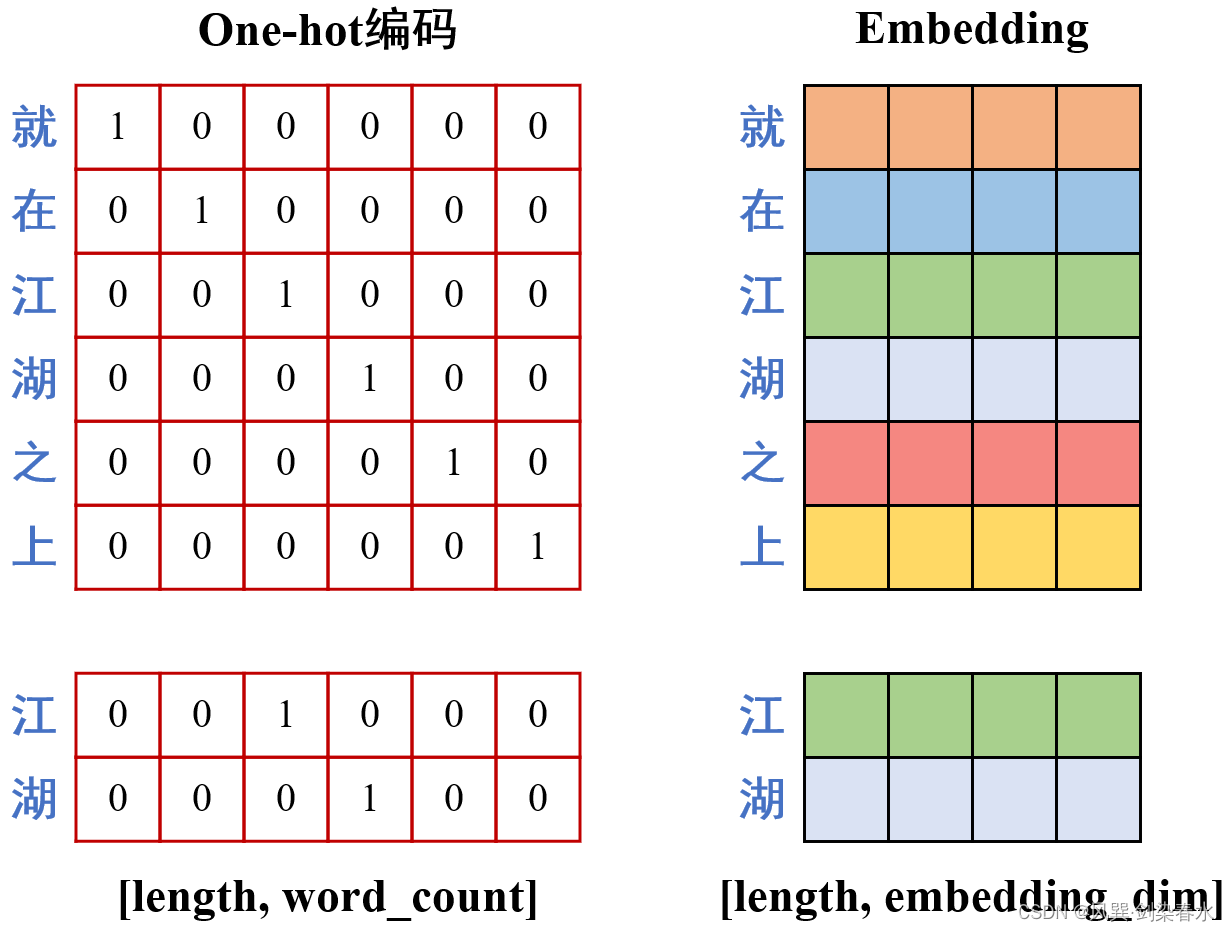
关于词嵌入,这篇文章讲的挺清楚的,相比于One-hot编码,Embedding方式更方便计算,例如在“就在江湖之上”整个词典中,要编码“江湖”两个字,One-hot编码需要 [ l e n g t h , w o r d _ c o u n t ] {[length, word\_count]} [length,word_count] 大小的张量,其中 w o r d _ c o u n t {word\_count} word_count 为词典中所有词的总数,而Embedding方式的嵌入维度 e m b e d d i n g _ d i m {embedding\_dim} embedding_dim 可远远小于 w o r d _ c o u n t {word\_count} word_count 。在运用Embedding方式编码的词典时,只需要词的索引,下图例子中: “江湖”——>[2, 3]
(2)重要参数介绍
nn.embedding就相当于一个词典嵌入表:
torch.nn.Embedding(num_embeddings, embedding_dim, padding_idx=None, max_norm=None, norm_type=2.0, scale_grad_by_freq=False, sparse=False, _weight=None, _freeze=False, device=None, dtype=None)
常用参数:
① num_embeddings (int): 词典中词的总数
② embedding_dim (int): 词典中每个词的嵌入维度
③ padding_idx (int, optional): 填充索引,在padding_idx处的嵌入向量在训练过程中没有更新,即它是一个固定的“pad”。对于新构造的Embedding,在padding_idx处的嵌入向量将默认为全零,但可以更新为另一个值以用作填充向量。
输入: I n p u t ( ∗ ) {Input(∗)} Input(∗): IntTensor 或者 LongTensor,为任意size的张量,包含要提取的所有词索引。
输出: O u t p u t ( ∗ , H ) {Output(∗, H)} Output(∗,H): ∗ {∗} ∗ 为输入张量的size, H {H} H = embedding_dim
2. torch.nn.Embedding用法
(1)基本用法
官方例子如下:
import torch
import torch.nn as nnembedding = nn.Embedding(10, 3)
x = torch.LongTensor([[1, 2, 4, 5], [4, 3, 2, 9]])y = embedding(x)print('权重:\n', embedding.weight)
print('输出:')
print(y)
查看权重与输出,打印如下:
权重:Parameter containing:
tensor([[ 1.4212, 0.6127, -1.1126],[ 0.4294, -1.0121, -1.8348],[-0.0315, -1.2234, -0.4589],[ 0.6131, -0.4381, 0.1253],[-1.0621, -0.1466, 1.7412],[ 1.0708, -0.7888, -0.0177],[-0.5979, 0.6465, 0.6508],[-0.5608, -0.3802, -0.4206],[ 1.1516, 0.4091, 1.2477],[-0.5753, 0.1394, 2.3447]], requires_grad=True)
输出:
tensor([[[ 0.4294, -1.0121, -1.8348],[-0.0315, -1.2234, -0.4589],[-1.0621, -0.1466, 1.7412],[ 1.0708, -0.7888, -0.0177]],[[-1.0621, -0.1466, 1.7412],[ 0.6131, -0.4381, 0.1253],[-0.0315, -1.2234, -0.4589],[-0.5753, 0.1394, 2.3447]]], grad_fn=<EmbeddingBackward0>)
家人们,发现了什么,输入 x {x} x 的 s i z e {size} size 大小为 [ 2 , 4 ] {[2, 4]} [2,4] ,输出 y {y} y 的 s i z e {size} size 大小为 [ 2 , 4 , 3 ] {[2, 4, 3]} [2,4,3] ,下图清晰的展示出nn.Embedding干了个什么事儿:

nn.Embedding相当于是一本词典,本例中,词典中一共有10个词 X 0 {X_0} X0~ X 9 {X_9} X9,每个词的嵌入维度为3,输入 x {x} x 中记录词在词典中的索引,输出 y {y} y 为输入 x {x} x 经词典编码后的映射。
注意:此时存在一个问题,词索引是不能超出词典的最大容量的,即本例中,输入 x {x} x 中的数值取值范围为 [ 0 , 9 ] {[0, 9]} [0,9]。
(2)自定义词典权重
如上所示,在未定义时,nn.Embedding的自动初始化权重满足 N ( 0 , 1 ) {N(0,1)} N(0,1) 分布,此外,nn.Embedding的权重也可以通过from_pretrained来自定义:
import torch
import torch.nn as nnweight = torch.FloatTensor([[1, 2.3, 3], [4, 5.1, 6.3]])
embedding = nn.Embedding.from_pretrained(weight)
x = torch.LongTensor([1, 0, 0])
y = embedding(x)
print(y)
输出为:
tensor([[4.0000, 5.1000, 6.3000],[1.0000, 2.3000, 3.0000],[1.0000, 2.3000, 3.0000]])
(3)padding_idx用法
padding_idx可用于指定词典中哪一个索引的词填充为0。
import torch
import torch.nn as nnembedding = nn.Embedding(10, 3, padding_idx=5)
x = torch.LongTensor([[5, 2, 0, 5]])
y = embedding(x)
print('权重:\n', embedding.weight)
print('输出:')
print(y)
输出为:
权重:Parameter containing:
tensor([[ 0.1831, -0.0200, 0.7023],[ 0.2751, -0.1189, -0.3325],[-0.5242, -0.2230, -1.1677],[-0.4078, -1.2141, 1.3185],[ 0.8973, -0.9650, 0.5420],[ 0.0000, 0.0000, 0.0000],[ 0.0597, 0.6810, -0.2595],[ 0.6543, -0.6242, 0.2337],[-0.0780, -0.9607, -0.0618],[ 0.2801, -0.6041, -1.4143]], requires_grad=True)
输出:
tensor([[[ 0.0000, 0.0000, 0.0000],[-0.5242, -0.2230, -1.1677],[ 0.1831, -0.0200, 0.7023],[ 0.0000, 0.0000, 0.0000]]], grad_fn=<EmbeddingBackward0>)
词典中,被padding_idx标定后的词嵌入向量可被重新定义:
import torch
import torch.nn as nnpadding_idx=2
embedding = nn.Embedding(3, 3, padding_idx=padding_idx)
print('权重:\n', embedding.weight)with torch.no_grad():embedding.weight[padding_idx] = torch.tensor([1.1, 2.2, 3.3])
print('权重:\n', embedding.weight)
输出为:
权重:Parameter containing:
tensor([[ 0.7247, 0.7553, -1.8226],[-1.3304, -0.5025, 0.5237],[ 0.0000, 0.0000, 0.0000]], requires_grad=True)
权重:Parameter containing:
tensor([[ 0.7247, 0.7553, -1.8226],[-1.3304, -0.5025, 0.5237],[ 1.1000, 2.2000, 3.3000]], requires_grad=True)
相关文章:
【python函数】torch.nn.Embedding函数用法图解
学习SAM模型的时候,第一次看见了nn.Embedding函数,以前接触CV比较多,很少学习词嵌入方面的,找了一些资料一开始也不是很理解,多看了两遍后,突然顿悟,特此记录。 SAM中PromptEncoder中运用nn.Emb…...
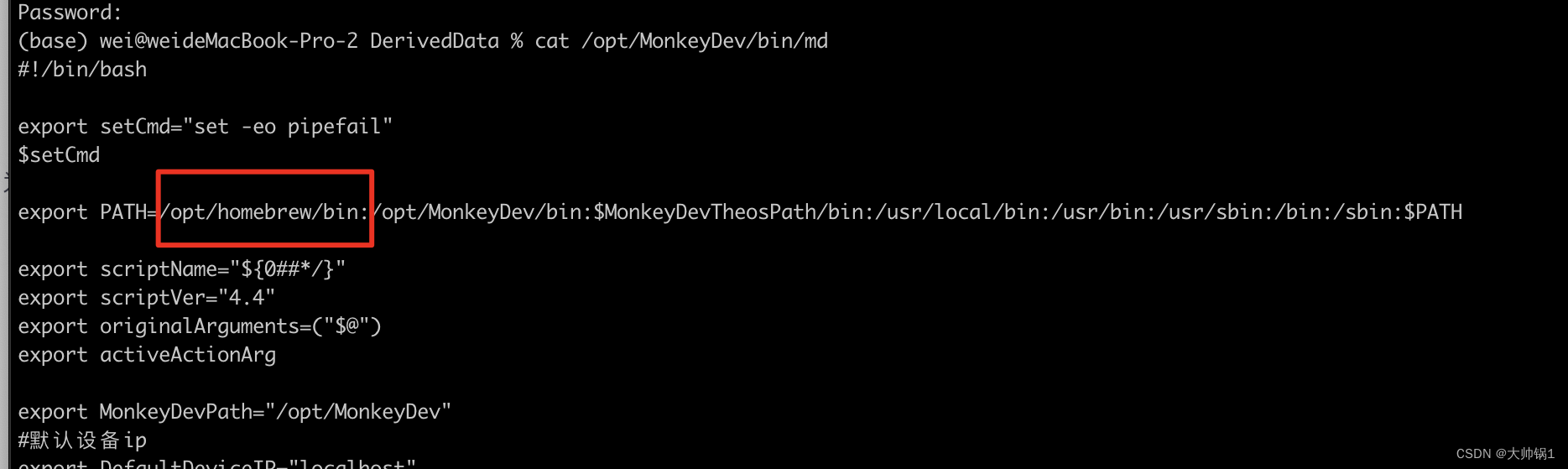
with ldid... /opt/MonkeyDev/bin/md: line 326: ldid: command not found
吐槽傻逼xcode 根据提示 执行了这个脚本/opt/MonkeyDev/bin/md 往这里面添加你brew install 安装文件的目录即可...

[golang gui]fyne框架代码示例
1、下载GO Go语言中文网 golang安装包 - 阿里镜像站(镜像站使用方法:查找最新非rc版本的golang安装包) golang安装包 - 中科大镜像站 go二进制文件下载 - 南京大学开源镜像站 Go语言官网(Google中国) Go语言官网(Go团队) 截至目前(2023年9月17日&#x…...
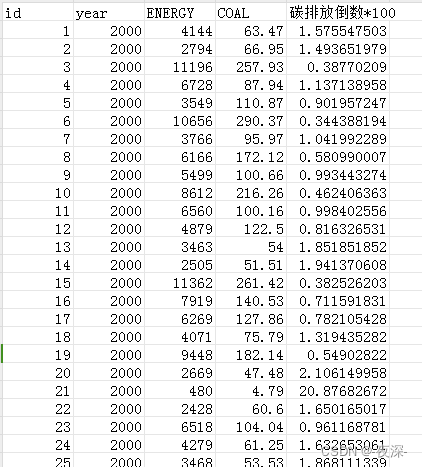
2000-2018年各省能源消费和碳排放数据
2000-2018年各省能源消费和碳排放数据 1、时间:2000-2018年 2、范围:30个省市 3、指标:id、year、ENERGY、COAL、碳排放倒数*100 4、来源:能源年鉴 5、指标解释: 2018年碳排放和能源数据为插值法推算得到 碳排放…...

C# ref 学习1
ref 关键字用在四种不同的上下文中; 1.在方法签名和方法调用中,按引用将参数传递给方法。 2.在方法签名中,按引用将值返回给调用方。 3.在成员正文中,指示引用返回值是否作为调用方欲修改的引用被存储在本地,或在一般…...
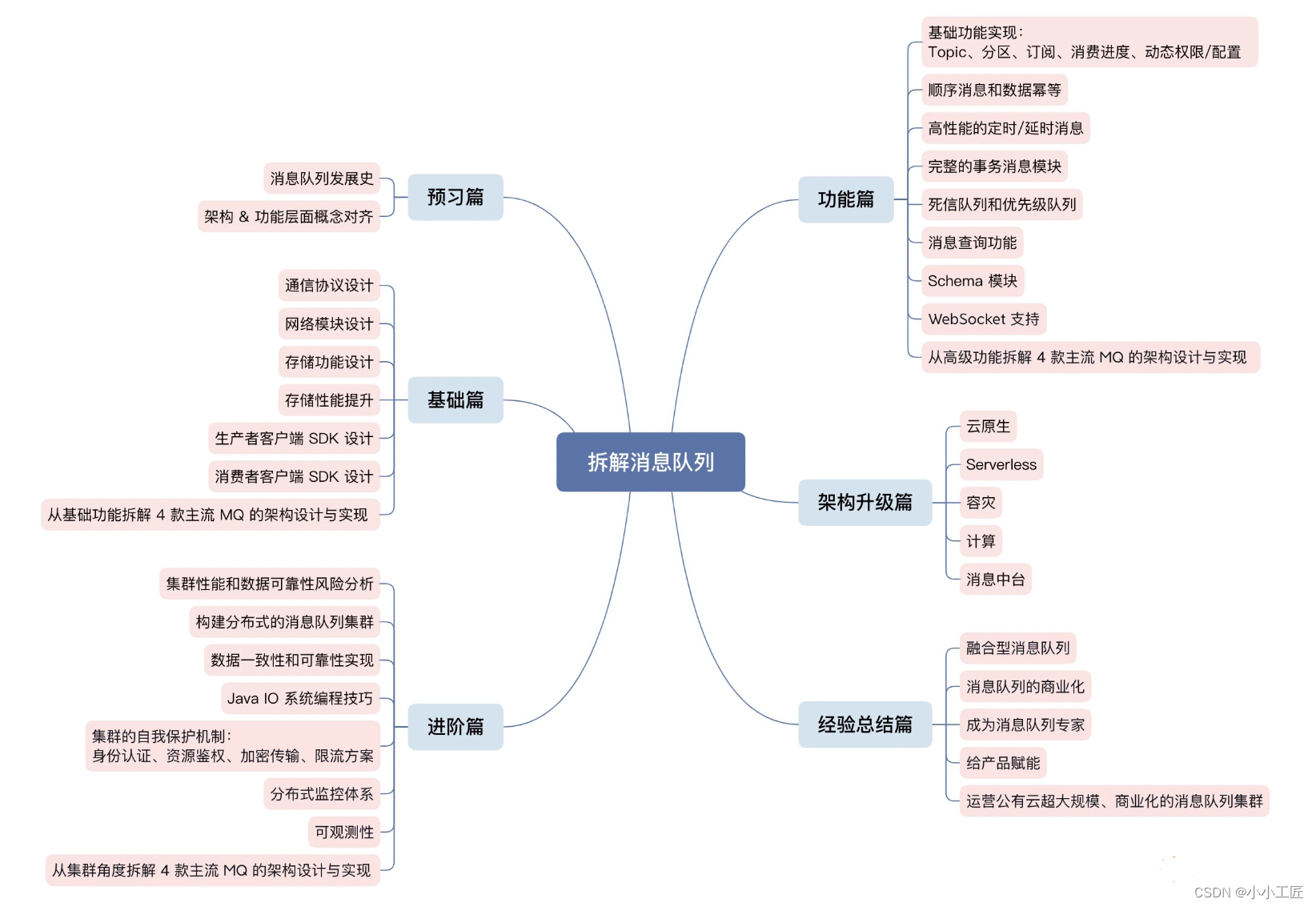
MQ - 08 基础篇_消费者客户端SDK设计(下)
文章目录 导图Pre概述消费分组协调者消费分区分配策略轮询粘性自定义消费确认确认后删除数据确认后保存消费进度数据消费失败处理从服务端拉取数据失败本地业务数据处理失败提交位点信息失败总结导图 Pre...

Flutter层对于Android 13存储权限的适配问题
感觉很久没有写博客了,不对,的确是很久没有写博客了。原因我不怎么想说,玩物丧志了。后面渐渐要恢复之前的写作节奏。今天来聊聊我最近遇到的一个问题: Android 13版本对于storage权限的控制问题。 我们都知道,Andro…...
Android kotlin开源项目-功能标题目录
目录 一、BRVAH二、开源项目1、RV列表动效(标题目录)2、拖拽与侧滑(标题目录)3、数据库(标题目录)4、树形图(多级菜单)(标题目录)5、轮播图与头条(标题目录)6…...

Linux下,基于TCP与UDP协议,不同进程下单线程通信服务器
C语言实现Linux下,基于TCP与UDP协议,不同进程下单线程通信服务器 一、TCP单线程通信服务器 先运行server端,再运行client端输入"exit" 是退出 1.1 server_TCP.c **#include <my_head.h>#define PORT 6666 #define IP &qu…...

qt功能自己创作
按钮按下三秒禁用 void MainWindow::on_pushButton_5_clicked(){// 锁定界面setWidgetsEnabled(ui->centralwidget, false);// 创建一个定时器,等待3秒后解锁界面QTimer::singleShot(3000, this, []() {setWidgetsEnabled(ui->centralwidget, true);;//ui-&g…...
Linux网络编程:使用UDP和TCP协议实现网络通信
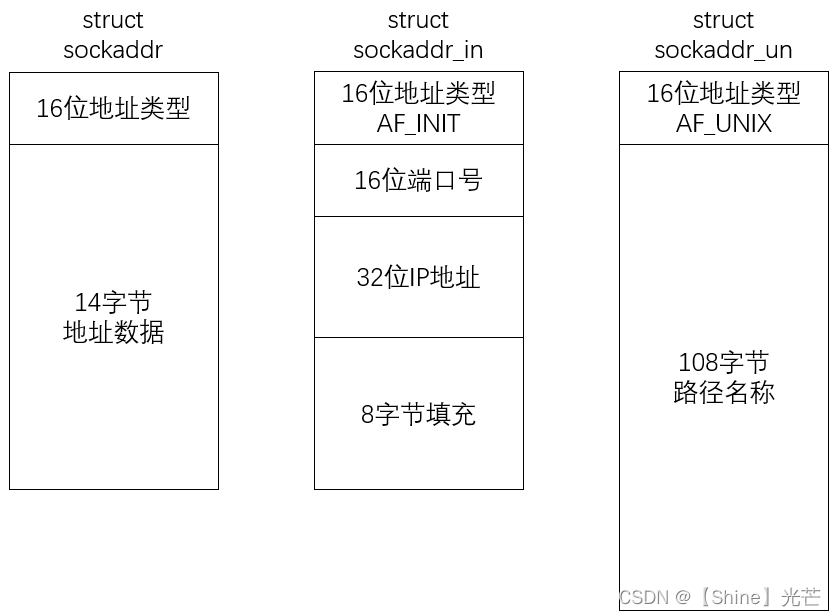
目录 一. 端口号的概念 二. 对于UDP和TCP协议的认识 三. 网络字节序 3.1 字节序的概念 3.2 网络通信中的字节序 3.3 本地地址格式和网络地址格式 四. socket编程的常用函数 4.1 sockaddr结构体 4.2 socket编程常见函数的功能和使用方法 五. UDP协议实现网络通信 5.…...
【后端速成 Vue】初识指令(上)
前言: Vue 会根据不同的指令,针对标签实现不同的功能。 在 Vue 中,指定就是带有 v- 前缀 的特殊 标签属性,比如: <div v-htmlstr> </div> 这里问题就来了,既然 Vue 会更具不同的指令&#…...

爬虫 — Scrapy-Redis
目录 一、背景1、数据库的发展历史2、NoSQL 和 SQL 数据库的比较 二、Redis1、特性2、作用3、应用场景4、用法5、安装及启动6、Redis 数据库简单使用7、Redis 常用五大数据类型7.1 Redis-String7.2 Redis-List (单值多value)7.3 Redis-Hash7.4 Redis-Set (不重复的)7.5 Redis-Z…...
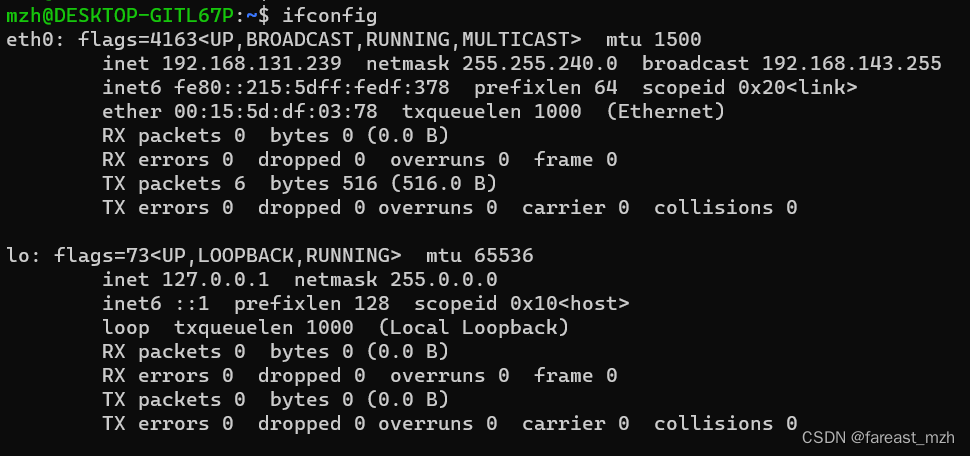
tcpdump常用命令
需要安装 tcpdump wireshark ifconfig找到网卡名称 eth0, ens192... tcpdump需要root权限 网卡eth0 经过221.231.92.240:80的流量写入到http.cap tcpdump -i eth0 host 221.231.92.240 and port 80 -vvv -w http.cap ssh登录到主机查看排除ssh 22端口的报文 tcpdump -i …...
计算机网络运输层网络层补充
1 CDMA是码分多路复用技术 和CMSA不是一个东西 UPD是只确保发送 但是接收端收到之后(使用检验和校验 除了检验的部分相加 对比检验和是否相等。如果不相同就丢弃。 复用和分用是发生在上层和下层的问题。通过比如时分多路复用 频分多路复用等。TCP IP 应用层的IO多路复用。网…...

java CAS详解(深入源码剖析)
CAS是什么 CAS是compare and swap的缩写,即我们所说的比较交换。该操作的作用就是保证数据一致性、操作原子性。 cas是一种基于锁的操作,而且是乐观锁。在java中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等之前获得锁的线程释放锁之后&am…...
1786_MTALAB代码生成把通用函数生成独立文件
全部学习汇总: GitHub - GreyZhang/g_matlab: MATLAB once used to be my daily tool. After many years when I go back and read my old learning notes I felt maybe I still need it in the future. So, start this repo to keep some of my old learning notes…...
2023/09/19 qt day3
头文件 #ifndef WIDGET_H #define WIDGET_H #include <QWidget> #include <QDebug> #include <QTime> #include <QTimer> #include <QPushButton> #include <QTextEdit> #include <QLineEdit> #include <QLabel> #include &l…...
—— Docker Rootless 让你的容器更安全)
Docker 学习总结(78)—— Docker Rootless 让你的容器更安全
前言 在以 root 用户身份运行 Docker 会带来一些潜在的危害和安全风险,这些风险包括: 容器逃逸:如果一个容器以 root 权限运行,并且它包含了漏洞或者被攻击者滥用,那么攻击者可能会成功逃出容器,并在宿主系统上执行恶意操作。这会导致宿主系统的安全性受到威胁。 特权升…...
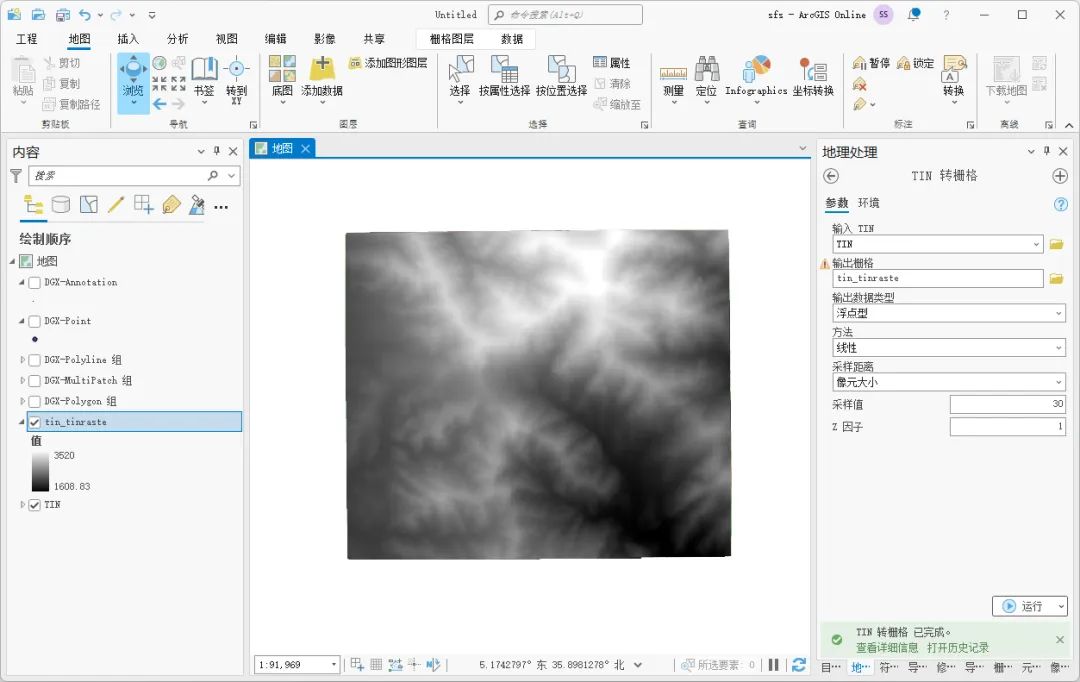
如何使用ArcGIS Pro将等高线转DEM
通常情况下,我们拿到的等高线数据一般都是CAD格式,如果要制作三维地形模型,使用栅格格式的DEM数据是更好的选择,这里就为大家介绍一下如何使用ArcGIS Pro将等高线转DEM,希望能对你有所帮助。 创建TIN 在工具箱中选择“…...

ARM DCC通信机制与RealMonitor协议栈解析
1. ARM DCC通信机制深度解析 调试通信通道(Debug Communications Channel, DCC)是ARM架构中用于主机调试器与目标设备通信的基础设施。不同于常规的串口或USB调试接口,DCC直接利用ARM核心的调试组件实现,具有以下显著特点: 寄存器级通信 &a…...

Speechless:三步完成微博PDF备份的终极免费Chrome扩展
Speechless:三步完成微博PDF备份的终极免费Chrome扩展 【免费下载链接】Speechless 把新浪微博的内容,导出成 PDF 文件进行备份的 Chrome Extension。 项目地址: https://gitcode.com/gh_mirrors/sp/Speechless 在数字时代,我们的社交…...

从零构建现代化Web控制面板:安全架构与实时监控实践
1. 项目概述:一个为开发者设计的现代化控制面板最近在GitHub上看到一个挺有意思的项目,叫clawpanel,作者是kweephyo-pmt。光看名字,你可能会联想到“爪子”和“面板”,感觉像是个带点攻击性或工具属性的管理界面。实际…...

NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南
NVIDIA Profile Inspector终极显卡优化工具:简单易用的性能调校完整指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector NVIDIA Profile Inspector是一款专业的显卡优化工具,专为…...

别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题
别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题 调试Camera模块时,MIPI信号问题往往是硬件工程师最头疼的挑战之一。当系统出现图像异常、花屏或无法识别时,大多数工程师的第一反应是检查CSI-…...

AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型
AI Agent产品经理的新思维:从功能设计到AI原生产品的方法论转型 各位产品同行、AI从业者,大家好!我是连续3年深耕AI工具Agent产品、从C端信息流(今日头条/抖音生态)PM成功转型AI原生垂直工具PM的张小白——过去两年&am…...

系统管理员AI编程实战:基于Claude的运维自动化脚本开发指南
1. 项目概述:一个面向系统管理员的Claude-Code学习与实践仓库最近在整理自己的技术栈时,发现很多系统管理员同行对如何将大型语言模型(LLM)高效地融入日常运维工作流感到困惑。大家普遍觉得这些AI工具很强大,但具体到写…...

大语言模型并行推理技术Hogwild! Inference解析
1. 大语言模型并行推理的技术挑战在传统的大语言模型推理过程中,文本生成采用的是严格的自回归方式,即每个token的生成都依赖于之前所有token的输出。这种串行模式虽然保证了生成的连贯性,但也带来了显著的性能瓶颈。以1750亿参数的GPT-3为例…...

基于Blazor与LLamaSharp构建本地大模型ChatGPT式Web应用
1. 项目概述与核心价值最近在折腾一个内部工具,想把本地大模型的能力和类似ChatGPT的对话体验结合起来,部署成一个Web应用。找了一圈,发现一个挺有意思的项目叫“BLlamaSharp.ChatGpt.Blazor”。光看这个名字,信息量就很大了&…...

学生综合素质评价系统设计实现【附程序】
✨ 长期致力于综合素质评价、AHP层次分析、BP神经网络、遗传算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)三层指标体系构建与AHP动态权重分配&…...