MySQL索引、事务与存储引擎
索引 事务 存储引擎
- 一、索引
- 1.1 索引的概念
- 1.2 索引的实现原理
- 1.2 索引的作用
- 1.3 创建索引的依据
- 1.4 索引的分类和创建
- 1.4.1 普通索引 index
- 1.4.2 唯一索引 unique
- 1.4.3 主键索引 primary key
- 1.4.4 组合索引(单列索引与多列索引)
- 1.4.5 全文索引 fulltext
- 1.5 查看索引
- 1.6 删除索引
- 二、MySQL事务
- 2.1 事务的概念
- 2.2 事务的ACID特性
- 2.3 事务并发导致的问题
- 2.4 事务的隔离级别
- 2.4.1 四种隔离级别
- 2.4.2 管理事务隔离级别
- 1)设置隔离级别
- 2)查询隔离级别
- 2.5 事务控制语句
- 2.6 使用 set 设置控制事务(自动提交)
- 三、MySQL 存储引擎
- 3.1 存储引擎的概念
- 3.2 常用存储引擎(区别)
- 3.3 语句
- 3.3.1 查看
- 1)查看系统支持的存储引擎
- 2)查看表使用的存储引擎
- 3.3.2 修改存储引擎
- 3.3.3 创建
- 3.4 InnoDB行锁与索引的关系
- 3.4 死锁
- 3.5 如何尽可能避免死锁?
一、索引
索引:是排序的快速查找的特殊数据结构,定义作为查找条件的字段上,又称为键key,索引通过存储引擎实现。
1.1 索引的概念
索引是一个排序的列表,包含索引字段的值和其相对应的行数据所在的物理地址。
1.2 索引的实现原理
没有索引的情况下,要查询某行数据时,需要先扫描全表,再来定位某行数据,对于表数据很多的情况下,效率较低。
有了索引后,会先通过查找条件的字段值找到其索引对应的行数据的物理地址,然后根据物理地址访问相应的行数据。
1.2 索引的作用
加快表的查询速度,还可以对字段排序。
优点
1)设置了合适的索引之后,数据库利用各种快速定位技术,能够极大地加快查询速度,这是创建索引的最主要的原因;
2)当表很大或查询涉及到多个表时,使用索引可以成千上万倍地提高查询速度,避免排序和使用临时表;
3)可以降低数据库的IO成本(减少io次数),并且索引还可以降低数据库的排序成本,将随机I/O转为顺序I/O;
4)通过创建唯一性索引,可以保证数据表中每一行数据的唯一性;
5)可以加快表与表之间的连接;
6)在使用分组和排序时,减少分组和排序的时间;
7)建立索引在搜索和恢复数据库中的数据时能显著提高性能。
缺点
1)会额外占用磁盘空间;
2)更新包含索引的表会花费更多时间,效率会更慢。
1.3 创建索引的依据
1)表中的记录行数较多时,一般超过300行的表建议要有索引;
2)建议在表中的主键字段、外键字段、多表连接使用的公共关键字段、唯一性较好的字段、不经常更新的字段、经常出现在 where、group by、order by 子语句的字段、小字段上面创建索引;
3)不建议在唯一性较差的字段、更新太频繁的字段、大文本字段上面创建索引。
1.4 索引的分类和创建
create table test (id int,name varchar(10),address varchar(10),age int );
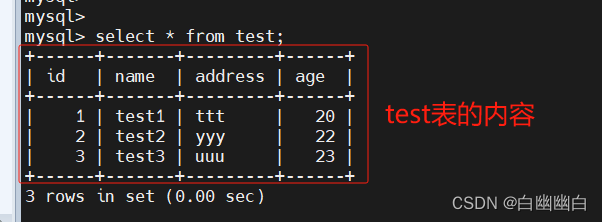
1.4.1 普通索引 index
最基本的索引类型,没有唯一性之类的限制。
直接创建索引
create index 索引名 on 表名 (字段);
#索引名建议以“_index”结尾
#举个例子
#创建
create index address_index on test (address);
#查看
show create table info \G;
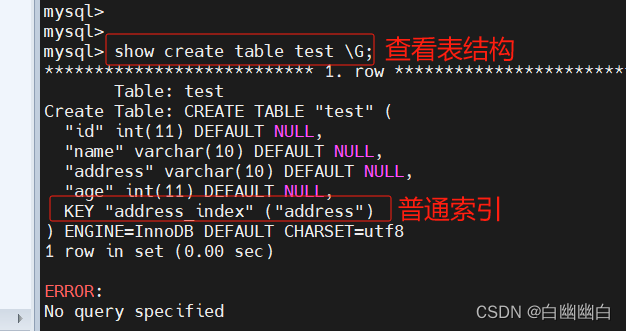
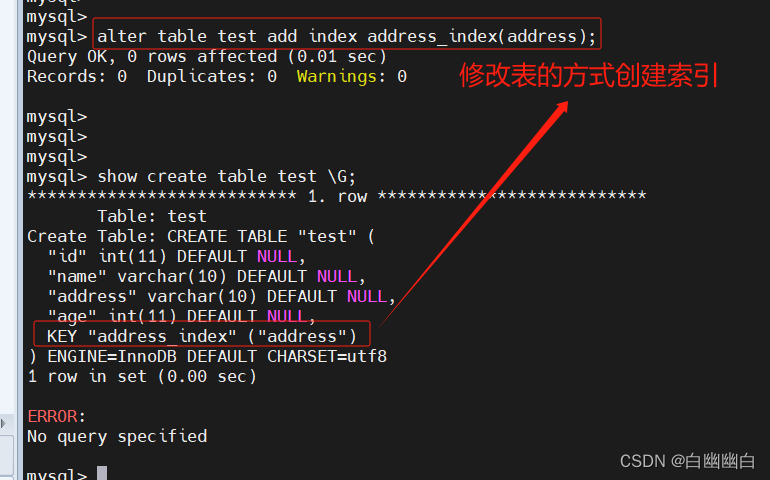
修改表方式创建
alter table 表名 add index 索引名 (字段);
#举个例子
alter table test add index address_index(address);
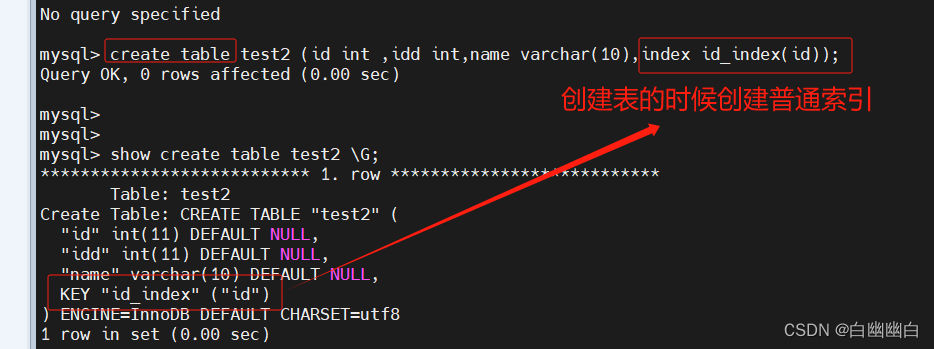
创建表的时候指定索引
create table 表名 ( 字段1 数据类型,字段2 数据类型[,...],index 索引名 (列名));
#举个例子
create table test2 (id int ,idd int,name varchar(10),index id_index(id));
1.4.2 唯一索引 unique
与普通索引类似,但区别是唯一索引列的每个值都唯一。
唯一索引允许有空值(注意和主键不同)。
如果是用组合索引创建,则列值的组合必须唯一。
添加唯一键将自动创建唯一索引。
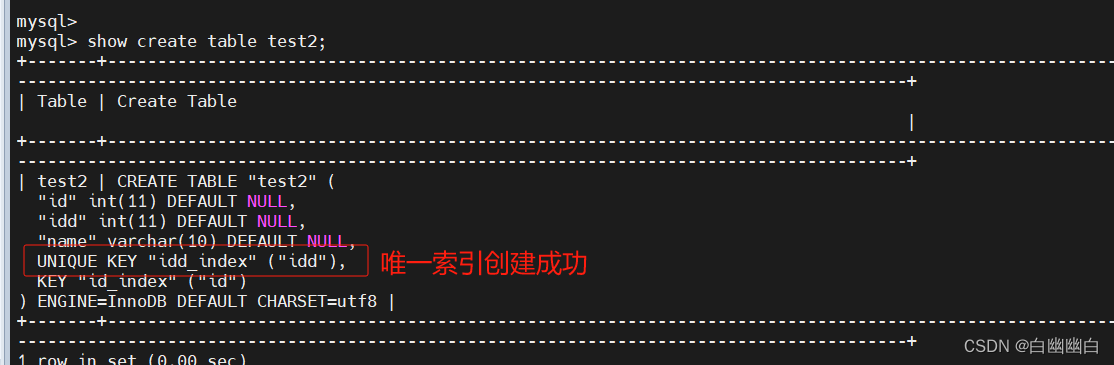
直接创建唯一索引
create unique index 索引名 on 表名 (字段);
#举个例子
create unique index idd_index on test2(idd);
修改表方式创建
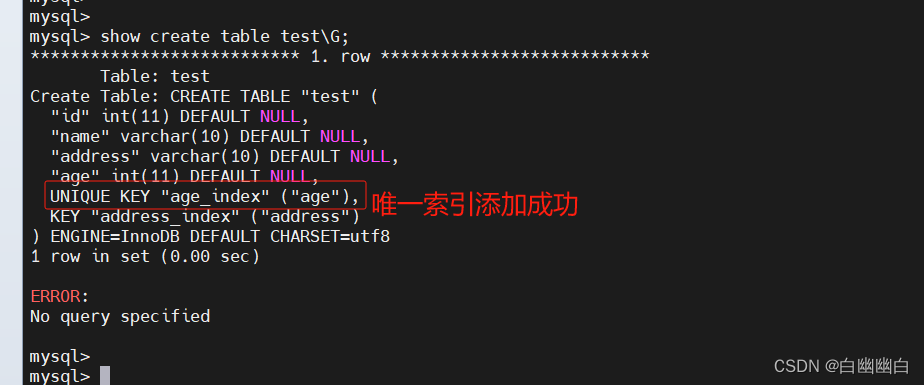
语法
alter table 表名 add unique 索引名 (字段);
#举个例子
alter table test add unique age_index(age);
创建表的时候指定
create table 表名 (字段1 数据类型,字段2 数据类型[,...],unique 索引名 (列名));
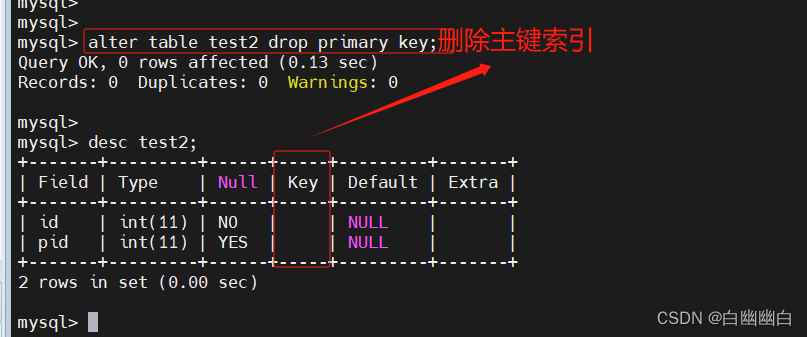
1.4.3 主键索引 primary key
主键索引是一种特殊的唯一索引,必须指定为“PRIMARY KEY”。
一个表只能有一个主键,不允许有空值。
添加主键将自动创建主键索引。
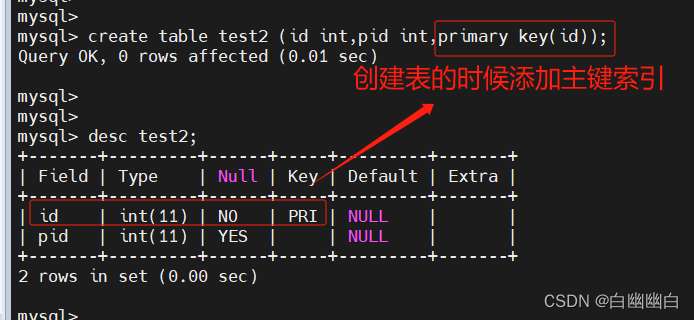
创建表的时候指定
create table 表名 ([...],primary key (列名));
#举个例子
create table test2 (id int,pid int,primary key(id));
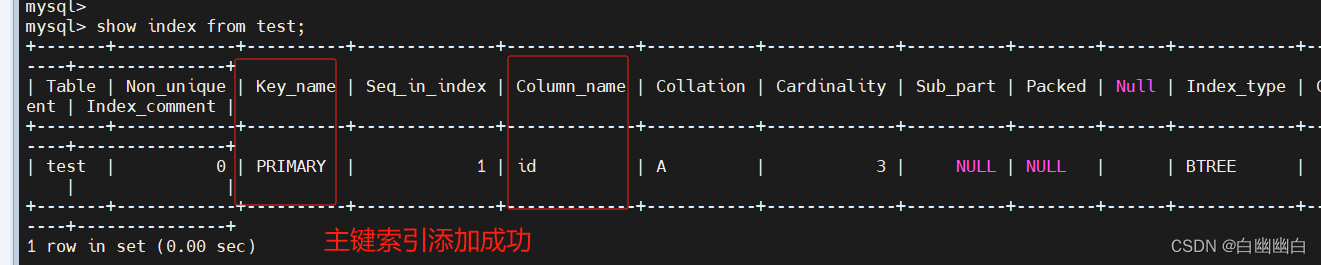
修改表的方式创建
alter table 表名 add primary key (字段);
#举个例子
alter table test add primary key(id);
1.4.4 组合索引(单列索引与多列索引)
可以是单列上创建的索引,也可以是在多列上创建的索引。
需要满足最左原则,因为 select 语句的 where 条件是依次从左往右执行的,所以在使用 select 语句查询时 where 条件使用的字段顺序必须和组合索引中的排序一致,否则索引将不会生效。
组合索引
create index 索引名 on 表名 (字段1, 字段2, 字段3,....); alter table 表名 add index 索引名 (字段1, 字段2, 字段3,....);create unique index 索引名 on 表名 (字段1, 字段2, 字段3,....); alter table 表名 add unique 索引名 (字段1, 字段2, 字段3,....);select ... from 表名 where 字段1=XX and 字段2=XX and 字段3=XX
#用 and 做条件逻辑运算符时,要创建组合索引且要满足最左原则
#用 or 做条件逻辑运算符时,所有字段都要单独创建单列索引
1.4.5 全文索引 fulltext
适合在进行模糊查询的时候使用,可用于在一篇文章中检索文本信息。
全文索引可以在 CHAR、VARCHAR 或者 TEXT 类型的列上创建。
直接创建索引
create fulltext index 索引名 on 表名 (字段);
#举个例子
create fulltext index name_index on test2 (name);

修改表的方式创建
alter table 表名 add fulltext 索引名 (字段);
#举个例子
alter table test2 add fulltext name_index (name);
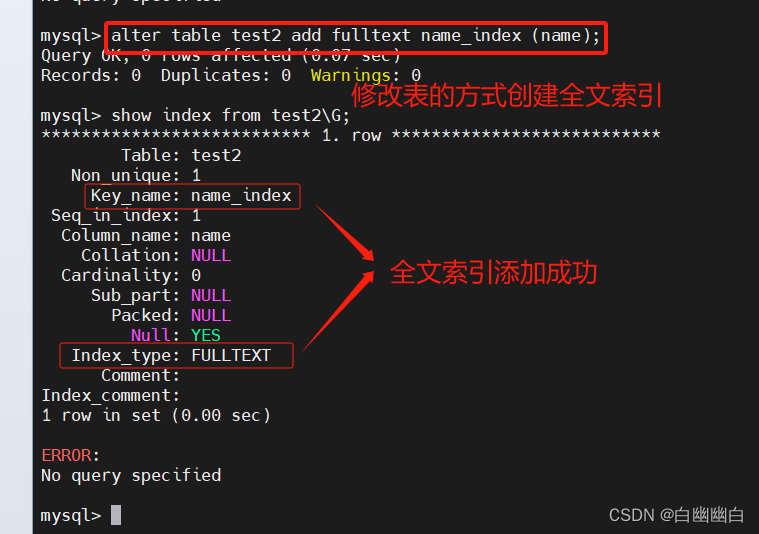
创建表的时候指定索引
create table 表名 (字段1 数据类型[,...],fulltext 索引名 (列名));
#数据类型可以为 char、varchar 或者 text
使用全文索引查询
select * from 表名 where match(列名) against('查询内容');insert into member values(1,'zhangsan',123123,123123,'nanjing','this is member!');
insert into member values(2,'lisi',456456,456456,'beijing','this is vip!');
insert into member values(3,'wangwu',789789,78979,'shanghai','this is vip member!');
select * from member where match(remark) against('vip');
支持模糊查询
select ... from 表名 where match(字段) against('查询内容');
1.5 查看索引
show create table 表名;
show index from 表名;
show keys from 表名;
各字段的含义如下
| 字段 | 含义 |
|---|---|
| Table | 表的名称 |
| Non_unique | 如果索引不能包括重复词,则为 0;如果可以,则为 1 |
| Key_name | 索引的名称 |
| Seq_in_index | 索引中的列序号,从 1 开始 |
| Column_name | 列名称 |
| Collation | 列以什么方式存储在索引中。在 MySQL 中,有值‘A’(升序)或 NULL(无分类) |
| Cardinality | 索引中唯一值数目的估计值 |
| Sub_part | 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为 NULL |
| Packed | 指示关键字如何被压缩。如果没有被压缩,则为 NULL |
| Null | 如果列含有 NULL,则含有 YES。如果没有,则该列含有 NO |
| Index_type | 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE) |
| Comment | 备注 |
1.6 删除索引
直接删除索引
drop index 索引名 on 表名;修改表方式删除索引
alter table 表名 drop index 索引名;
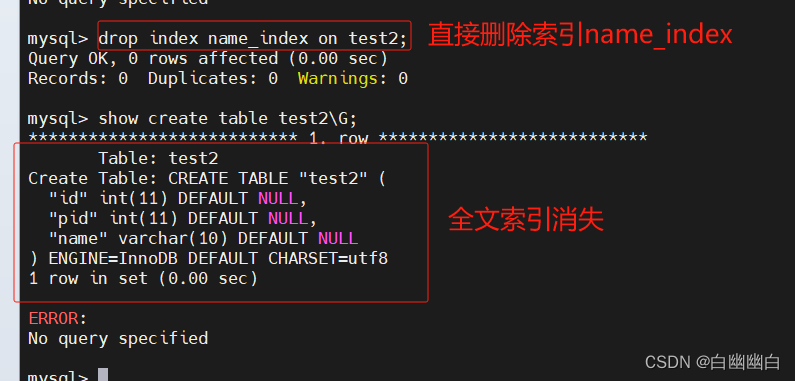
删除主键索引
alter table 表名 drop primary key;
二、MySQL事务
2.1 事务的概念
事务就是一组数据库操作序列(包含一个或者多个操作命令).
事务会把所有操作看作一个不可分割的整体向系统提交或撤销操作,所有操作要么都执行,要么都不执行.
2.2 事务的ACID特性
在可靠数据库管理系统(DBMS)中,事务(transaction)应该具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
这是可靠数据库所应具备的几个特性。
| 名称 | 描述 |
|---|---|
| 原子性(Atomicity) | 原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生 |
| 一致性(Consistency) | 事务前后数据的完整性必须保持一致 |
| 隔离性(Isolation) | 事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离 |
| 持久性(Durability) | 事务一旦被提交则不可逆,被持久化到数据库中,接下来即使数据库发生故障也不应该对其有任何影响 |
在事务管理中,原子性是基础,隔离性是手段,一致性是目的,持久性是结果。
2.3 事务并发导致的问题
| 名称 | 描述 |
|---|---|
| 脏读 | 指一个事务读取了另外一个事务未提交的数据 |
| 不可重复读 | 在一个事务内读取表中的某一行数据,多次读取结果不同 |
| 虚读(幻读) | 是指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致 |
| 丢失更新 | 两个事务同时读取同一条记录,导致修改结果覆盖 |
2.4 事务的隔离级别
事务的隔离级别决定了事务之间可见的级别。
2.4.1 四种隔离级别
MySQL事务支持如下四种隔离,用以控制事务所做的修改,并将修改通告至其它并发的事务。
1)未提交读( Read Uncommitted(RU))
允许脏读,即允许一个事务可以看到其他事务未提交的修改。
2)提交读(Read Committed(RC))
允许一个事务只能看到其他事务已经提交的修改,未提交的修改是不可见的,防止脏读。
3)可重复读(Repeatable Read(RR))—mysql默认的隔离级别
确保如果在一个事务中执行两次相同的SELECT语句,都能得到相同的结果,不管其他事务是否提交这些修改;
可以防止脏读和不可重复读。
4)串行读(Serializable)—相当于锁表
完全串行化的读,将一个事务与其他事务完全地隔离;
每次读都需要获得表级共享锁,读写相互都会阻塞;
可以防止脏读,不可重复读取和幻读,(事务串行化)会降低数据库的效率。
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 读已提交(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
mysql默认的事务处理级别是 repeatable read ,而Oracle和SQL Server是 read committed 。
事务隔离级别的作用范围分为两种:
● 全局级:对所有的会话有效
● 会话级:只对当前的会话有效
2.4.2 管理事务隔离级别
1)设置隔离级别
设置全局事务隔离级别
set global transaction isolation level read committed;
set @@global.tx_isolation='read-committed'; #重启服务后失效
设置会话事务隔离级别
set session transaction isolation level repeatable read;
set @@session.tx_isolation='repeatable-read';
2)查询隔离级别
查询全局事务隔离级别
show global variables like '%isolation%';
SELECT @@global.tx_isolation
查询会话事务隔离级别
show session variables like '%isolation%';
SELECT @@session.tx_isolation;
SELECT @@tx_isolation;
2.5 事务控制语句
#显式地开启一个事务
BEGIN 或 START TRANSACTION#提交事务,并使已对数据库进行的所有修改变为永久性的。
COMMIT 或 COMMIT WORK#回滚
#回滚会结束用户的事务,并撤销正在进行的所有未提交的修改。
ROLLBACK 或 ROLLBACK WORK#创建回滚点,相当于存档
#一个事务中可以有多个
#“S1”代表回滚点名称。
SAVEPOINT S1;#把事务回滚到标记点,相当于读档
ROLLBACK TO [SAVEPOINT] S1;
举个例子
#创建测试用表
use byyb;
create table account(
id int(10) primary key not null,
name varchar(40),
money double
);insert into account values(1,'A',1000);
insert into account values(2,'B',1000);
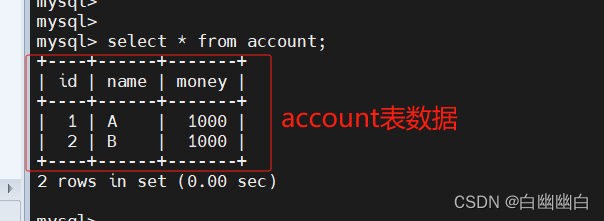
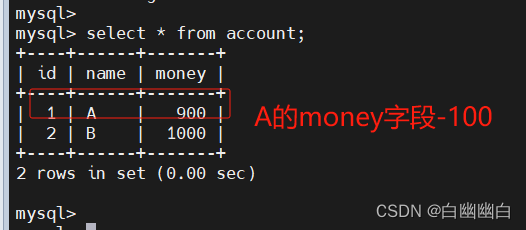
#测试提交事务
begin;
update account set money= money - 100 where name='A';
commit;
quitmysql -u root -p
use byyb;
select * from account;
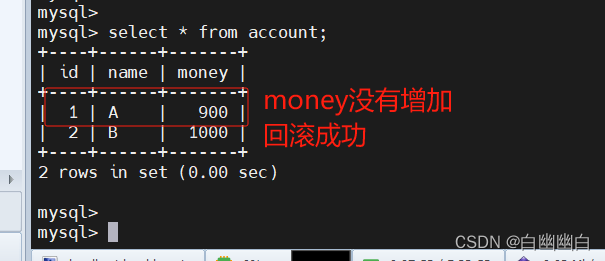
#测试回滚事务
begin;
update account set money= money + 100 where name='A';
rollback;mysql -u root -p
use byyb;
select * from account;
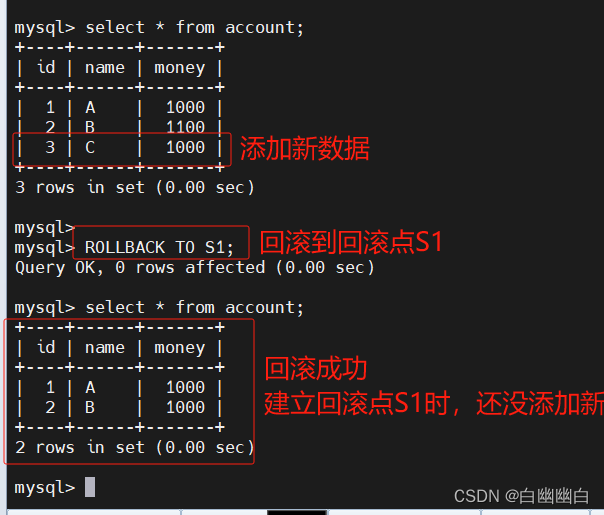
#测试多点回滚
begin;
update account set money= money + 100 where name='A';
SAVEPOINT S1;
update account set money= money + 100 where name='B';
SAVEPOINT S2;
insert into account values(3,'C',1000);select * from account;
ROLLBACK TO S1;
select * from account;
2.6 使用 set 设置控制事务(自动提交)
如果没有开启自动提交
当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback或者commit;,当前事务才算结束。
当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。
如果开起了自动提交
mysql会把每个sql语句当成一个事务,然后自动的commit。
当然无论开启与否,begin; commit|rollback; 都是独立的事务。
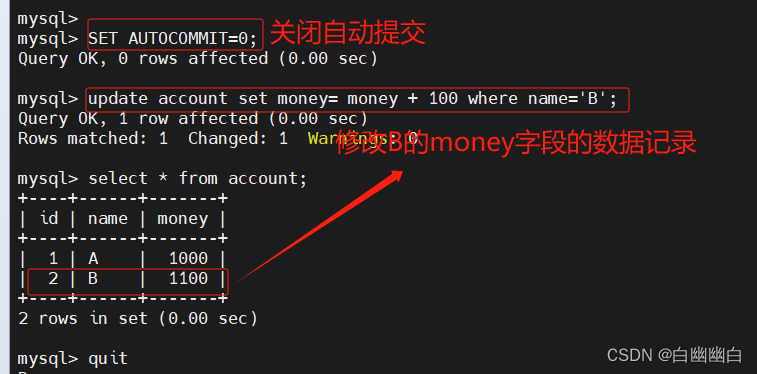
#禁止自动提交
SET AUTOCOMMIT=0;#开启自动提交,Mysql默认为1
SET AUTOCOMMIT=1;#查看Mysql中的AUTOCOMMIT值
SHOW VARIABLES LIKE 'AUTOCOMMIT';
use byyb;
select * from account;
SET AUTOCOMMIT=0;
update account set money= money + 100 where name='B';
select * from account;
quitmysql -u root -p
use byyb;
select * from account;
三、MySQL 存储引擎
3.1 存储引擎的概念
MyISAM 表支持 3 种不同的存储格式:
1)静态(固定长度)表
静态表是默认的存储格式。静态表中的字段都是非可变字段,这样每个记录都是固定长度的,这种存储方式的优点是存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多。
2)动态表
动态表包含可变字段,记录不是固定长度的,这样存储的优点是占用空间较少,但是频繁的更新、删除记录会产生碎片,需要定期执行 OPTIMIZE TABLE 语句或 myisamchk -r 命令来改善性能,并且出现故障的时候恢复相对比较困难。
3)压缩表
压缩表由 myisamchk 工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支。
3.2 常用存储引擎(区别)
常用存储引擎:InnoDB、MyISAM
MyISAM:不支持事务、外键约束,只支持表级锁定,适合单独的查询或插入的操作,读写并发能力较弱,支持全文索引,硬件资源占用较小,数据文件和索引文件是分开存储的。存储成三个文件:表结构文件.frm、数据文件.MYD、索引文件.MYI
使用场景:适用于不需要事务处理,单独的查询或插入数据的业务场景
InnoDB:支持事务、外键约束,支持行级锁定(在全表扫描时仍然会表级锁定),读写并发能力较好,支持全文索引(5.5版本之后),缓存能力较好可以减少磁盘IO的压力,数据文件也是索引文件。存储成两个文件:表结构文件.frm、数据文件.ibd
使用场景:适用于需要事务的支持,一致性要求高的,数据会频繁更新,读写并发高的业务场景
3.3 语句
3.3.1 查看
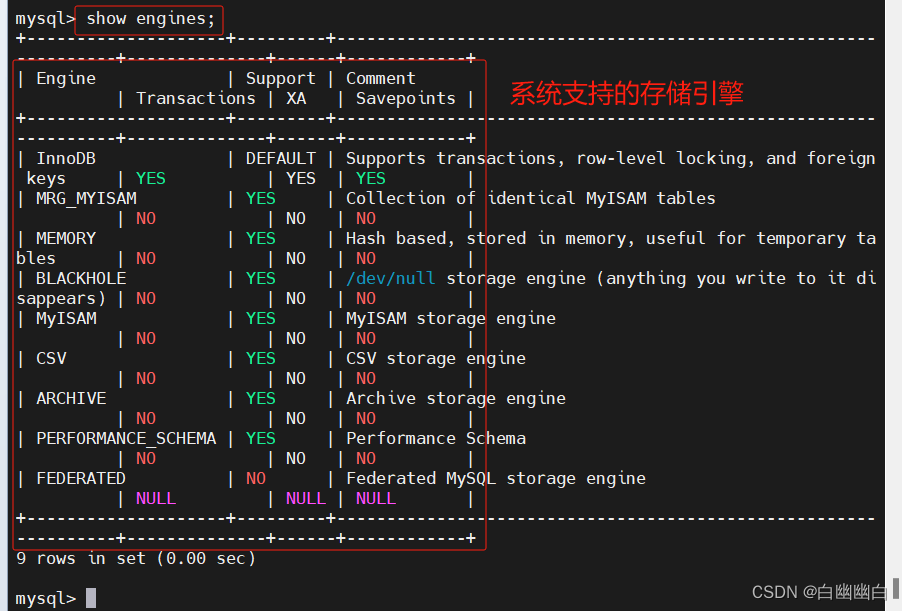
1)查看系统支持的存储引擎
show engines;
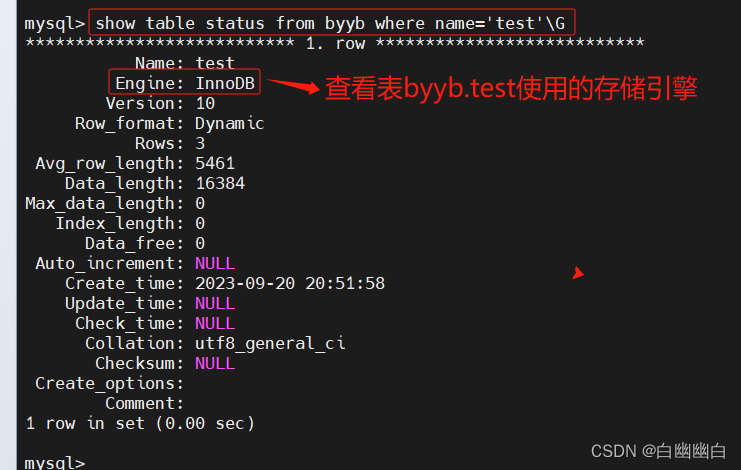
2)查看表使用的存储引擎
方法一
show table status from 库名 where name='表名'\G
#举个例子
show table status from byyb where name='test'\G
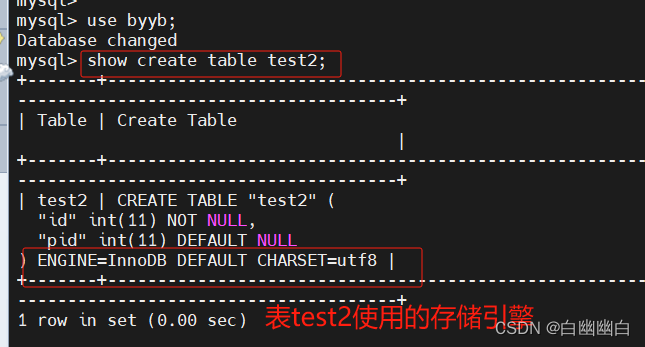
方法二
use 库名;
show create table 表名;
#举个例子
use byyb;
show create table testshow;
3.3.2 修改存储引擎
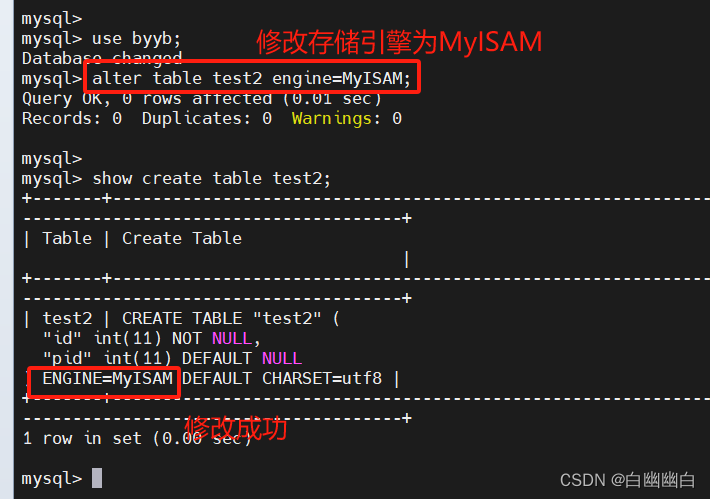
方法一:通过 alter table 修改
use 库名;
alter table 表名 engine=MyISAM;
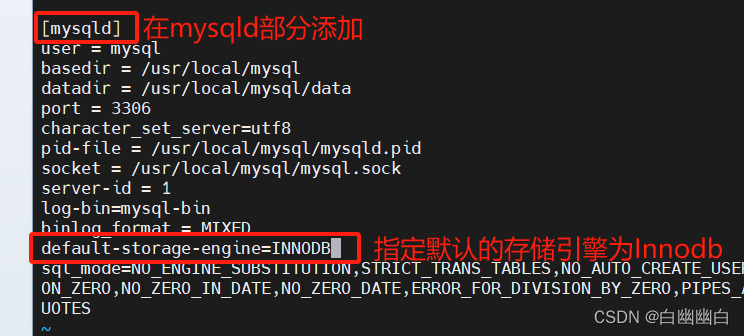
方法二:修改配置文件
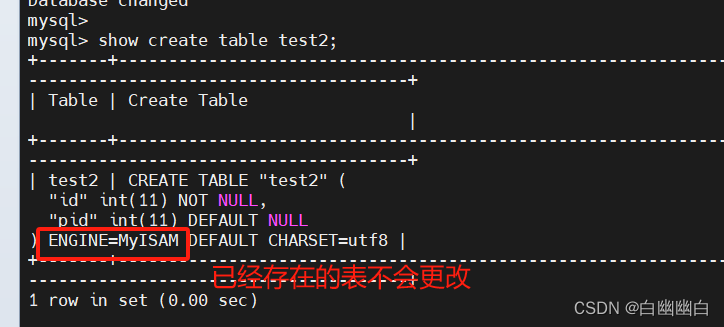
通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务。
此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会更改。
vim /etc/my.cnf
......
[mysqld]
......
default-storage-engine=INNODBsystemctl restart mysqld
3.3.3 创建
通过 create table 创建表时指定存储引擎
use 库名;
create table 表名(字段1 数据类型,...) engine=MyISAM;

3.4 InnoDB行锁与索引的关系
InnoDB行锁是通过给索引项加锁来实现的,如果没有索引,InnoDB将通过隐藏的聚簇索引来对记录加锁。
1)
delete from t1 where id=1;
如果id字段是主键,innodb对于主键使用了聚簇索引,会直接锁住整行记录。
如果id字段是主键,innodb对于主键使用了聚簇索引,会直接锁住整行记录。
2)
delete from t1 where name='aaa';
如果name字段是普通索引,会先锁住索引的两行,接着会锁住相应主键对应的记录。
如果name字段是普通索引,会先锁住索引的两行,接着会锁住相应主键对应的记录。
3)
delete from t1 where age=23;
如果age字段没有索引,会使用全表扫描过滤,这时表上的各个记录都将加上锁。
如果age字段没有索引,会使用全表扫描过滤,这时表上的各个记录都将加上锁。
3.4 死锁
死锁是指两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
案例:
create table t1(id int primary key, name char(3), age int);
insert into t1 values(1,'aaa',22);
insert into t1 values(2,'bbb',23);
insert into t1 values(3,'aaa',24);
insert into t1 values(4,'bbb',25);
insert into t1 values(5,'ccc',26);
insert into t1 values(6,'zzz',27);session 1 session 2
begin; begin;
delete from t1 where id=5; select * from t1 where id=1 for update;
delete from t1 where id=1; #死锁发生 update t1 set name='abc' where id=5; #死锁发生#for update 可以为数据库中的行上一个排它锁。当一个事务的操作未完成时候,其他事务可以读取但是不能写入或更新。
#共享锁:又叫做读锁,当用户要进行数据的读取时,对数据加上共享锁,共享锁可以同时加上多个。
#排他锁:又叫做写锁,当用户要进行数据的写入时,对数据加上排他锁,排他锁只可以加一个,它和其它的排他锁,共享锁都相斥。
3.5 如何尽可能避免死锁?
1)使用更合理的业务逻辑,以固定的顺序访问表和行;
2)大事务拆小;
大事务更倾向于死锁,如果业务允许,将大事务拆小;
3)在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率;
4)降低隔离级别。
如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁;
5)为表添加合理的索引。
n;
delete from t1 where id=5;
select * from t1 where id=1 for update;
delete from t1 where id=1; #死锁发生
update t1 set name=‘abc’ where id=5; #死锁发生
#for update 可以为数据库中的行上一个排它锁。当一个事务的操作未完成时候,其他事务可以读取但是不能写入或更新。
#共享锁:又叫做读锁,当用户要进行数据的读取时,对数据加上共享锁,共享锁可以同时加上多个。
#排他锁:又叫做写锁,当用户要进行数据的写入时,对数据加上排他锁,排他锁只可以加一个,它和其它的排他锁,共享锁都相斥。
## 3.5 如何尽可能避免死锁?
1)<font color='cornflowerblue'>使用更合理的业务逻辑,以固定的顺序访问表和行</font>;2)<font color='cornflowerblue'>大事务拆小</font>;大事务更倾向于死锁,如果业务允许,将大事务拆小;3)在同一个事务中,尽可能做到<font color='cornflowerblue'>一次锁定所需要的所有资源,减少死锁概率</font>;4)<font color='cornflowerblue'>降低隔离级别</font>。如果业务允许,将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁;5)<font color='cornflowerblue'>为表添加合理的索引</font>。如果不使用索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
相关文章:
MySQL索引、事务与存储引擎
索引 事务 存储引擎 一、索引1.1 索引的概念1.2 索引的实现原理1.2 索引的作用1.3 创建索引的依据1.4 索引的分类和创建1.4.1 普通索引 index1.4.2 唯一索引 unique1.4.3 主键索引 primary key1.4.4 组合索引(单列索引与多列索引)1.4.5 全文索引 fulltex…...

【Spring面试】八、事务相关
文章目录 Q1、事务的四大特性是什么?Q2、Spring支持的事务管理类型有哪些?Spring事务实现方式有哪些?Q3、说一下Spring的事务传播行为Q4、说一下Spring的事务隔离Q5、Spring事务的实现原理Q6、Spring事务传播行为的实现原理是什么?…...

Windows平台Qt6中UTF8与GBK文本编码互相转换、理解文本编码本质
快速答案 UTF8转GBK QString utf8_str"中UTF文"; std::string gbk_str(utf8_str.toLocal8Bit().data());GBK转UTF8 std::string gbk_str_given_by_somewhere"中GBK文"; QString utf8_strQString::fromLocal8Bit(gbk_str_given_by_somewhere.data());正文…...

【探索Linux】—— 强大的命令行工具 P.9(进程地址空间)
阅读导航 前言一、内存空间分布二、什么是进程地址空间1. 概念2. 进程地址空间的组成 三、进程地址空间的设计原理1. 基本原理2. 虚拟地址空间 概念 大小和范围 作用 虚拟地址空间的优点 3. 页表 四、为什么要有地址空间五、总结温馨提示 前言 前面我们讲了C语言的基础知识&am…...

ESP32主板-MoonESP32
产品简介 Moon-ESP32主板,一款以双核芯片ESP32-E为主芯片的主控板,支持WiFi和蓝牙双模通信,低功耗,板载LED指示灯,引出所有IO端口,并提供多个I2C端口、SPI端口、串行端口,方便连接,…...

Python 图片处理笔记
import numpy as np import cv2 import os import matplotlib.pyplot as plt# 去除黑边框 def remove_the_blackborder(image):image cv2.imread(image) #读取图片img cv2.medianBlur(image, 5) #中值滤波,去除黑色边际中可能含有的噪声干扰#medianBlur( Inp…...
SpringCloud Ribbon--负载均衡 原理及应用实例
😀前言 本篇博文是关于SpringCloud Ribbon的基本介绍,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,您的满意是我的动力…...
Redis的介绍以及简单使用
Redis(Remote Dictionary Server)是一个开源的内存数据存储系统,它以键值对的形式将数据存在内存中,并提供灵活、高性能的数据访问方式。Redis具有高速读写能力和丰富的数据结构支持,可以广泛应用于缓存、消息队列、实…...
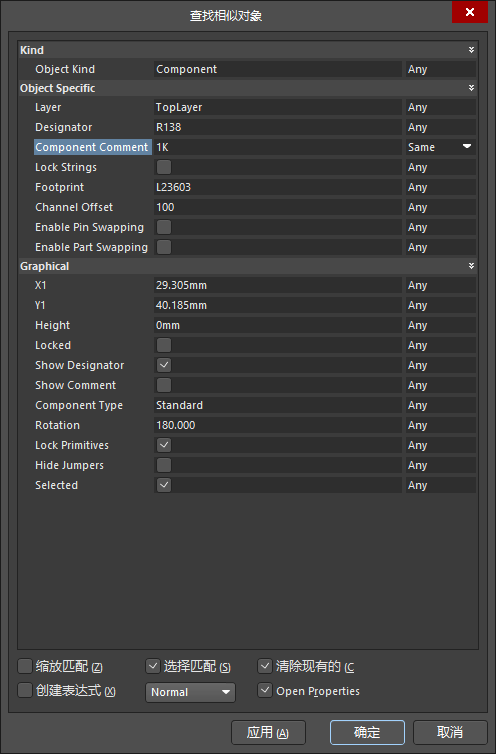
ad18学习笔记十二:如何把同属性的元器件全部高亮?
1、先选择需要修改的器件的其中一个。 2、右键find similar objects,然后在弹出的对话框中,将要修改的属性后的any改为same 3、像这样勾选的话,能把同属性的元器件选中,其他器件颜色不变 注意了,如果这个时候ÿ…...

SpringSecurity 核心过滤器——SecurityContextPersistenceFilter
文章目录 前言过滤器介绍用户信息的存储获取用户信息存储用户信息获取用户信息 处理逻辑总结 前言 SecurityContextHolder,这个是一个非常基础的对象,存储了当前应用的上下文SecurityContext,而在SecurityContext可以获取Authentication对象…...
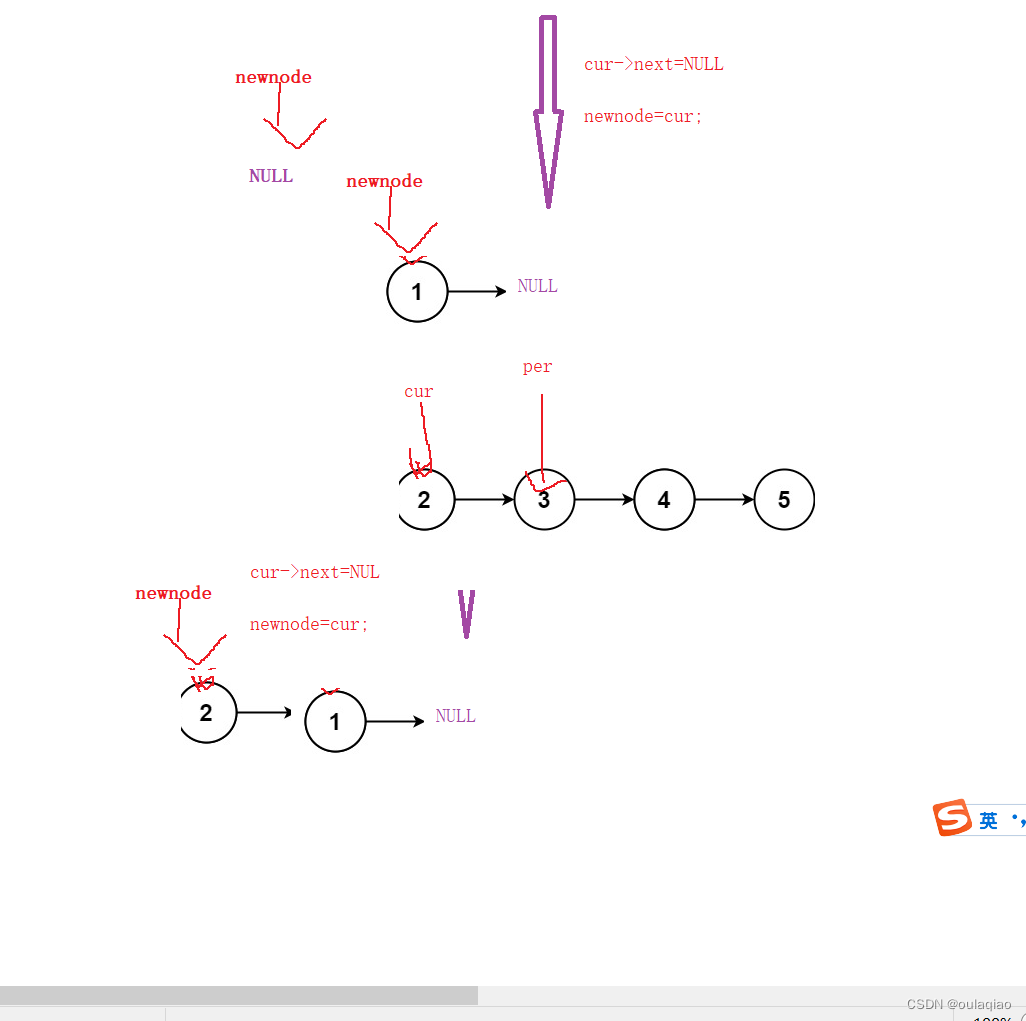
反转单链表
思路图1: 代码: struct ListNode* reverseList(struct ListNode* head){if(headNULL)//当head是空链表时 {return head; }struct ListNode* n1NULL;struct ListNode* n2head;struct ListNode* n3head->next;if(head->nextNULL)//当链表只有一个节…...
加速新药问世,药企如何利用云+网的优势?
随着计算能力的不断提高和人工智能技术的迅速发展,药物研发领域正迎来一场革命。云端强大的智能算法正成为药物研发企业的得力助手,推动着药物的精确设计和固相筛选。这使得药物设计、固相筛选以及药物制剂开发的时间大幅缩短,有望加速新药物…...

C++中string对象之间比较、char*之间比较
#include <cstring> //char* 使用strcmp #include <string> //string 使用compare #include <iostream> using namespace std; int main() {string stringStr1 "42";string stringStr2 "42";string stringStr3 "213";cout …...

MVVM模式理解
链接: MVVM框架理解及其原理实现 - 知乎 (zhihu.com) 重点: 1.将展示的界面窗口和创建的构件是数据进行分离 2.利用一个中间商进行数据的处理,所有的数据通过中间商进行处理...

js常用的数组处理方法
some 方法 用于检查数组中是否至少有一个元素满足指定条件。如果有满足条件的元素,返回值为 true,否则返回 false。 const numbers [1, 2, 3, 4, 5];const hasEvenNumber numbers.some((number) > number % 2 0); console.log(hasEvenNumber); /…...

[Document]VectoreStoreToDocument开发
该document是用来检索文档的。 第一步:定义组件对象,该组件返回有两种类型:document和text。 第二步:获取需要的信息,向量存储库,这里我使用的是内存向量存储(用该组件拿到文档,并检…...
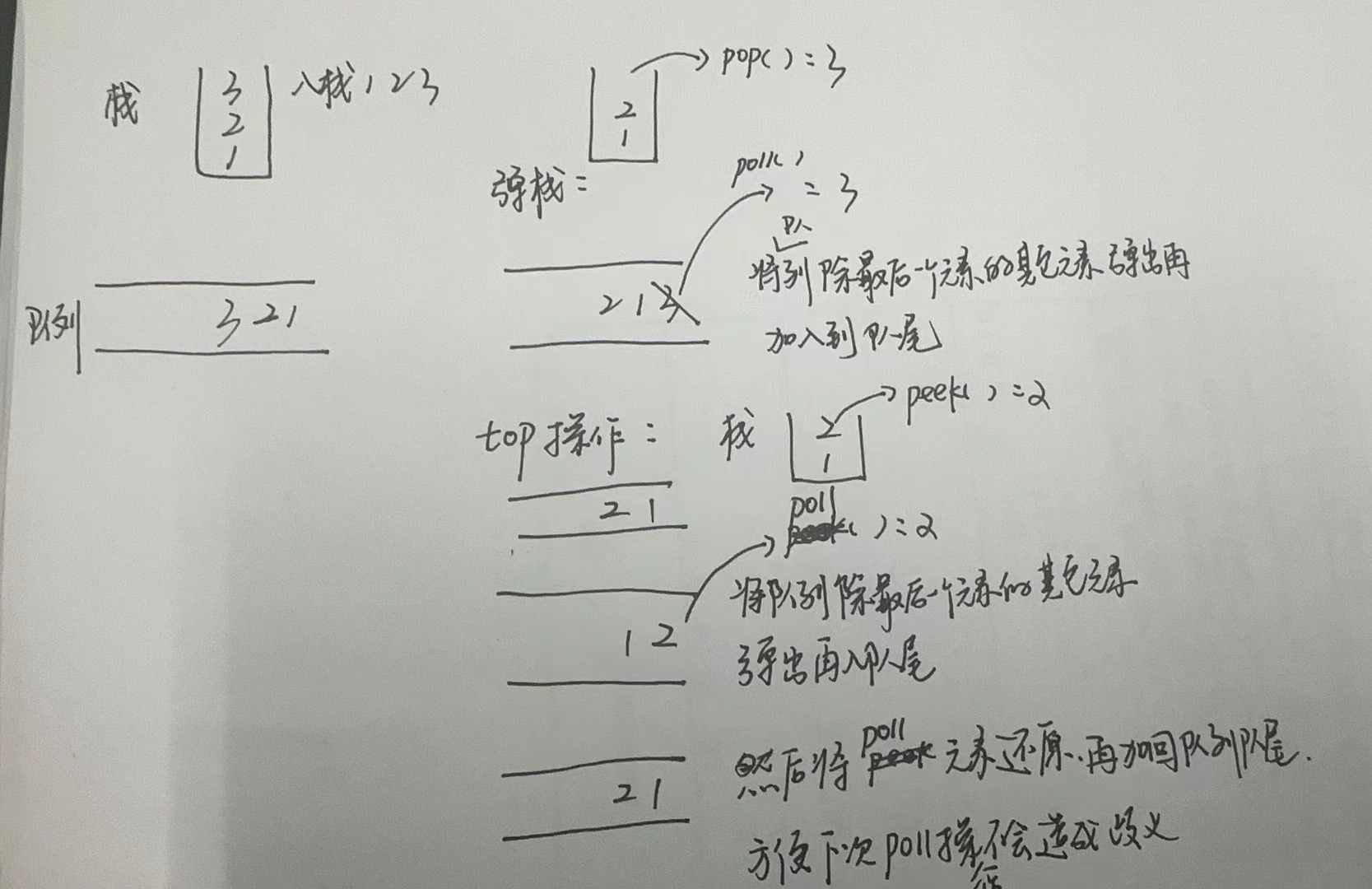
【LeetCode-简单题】225. 用队列实现栈
文章目录 题目方法一:单个队列实现 题目 方法一:单个队列实现 入栈 和入队正常进行出栈的元素其实就是队列的尾部元素,所以直接将尾部元素弹出即可,其实就可以将除了最后一个元素的其他元素出队再加入队,然后弹出队首元…...
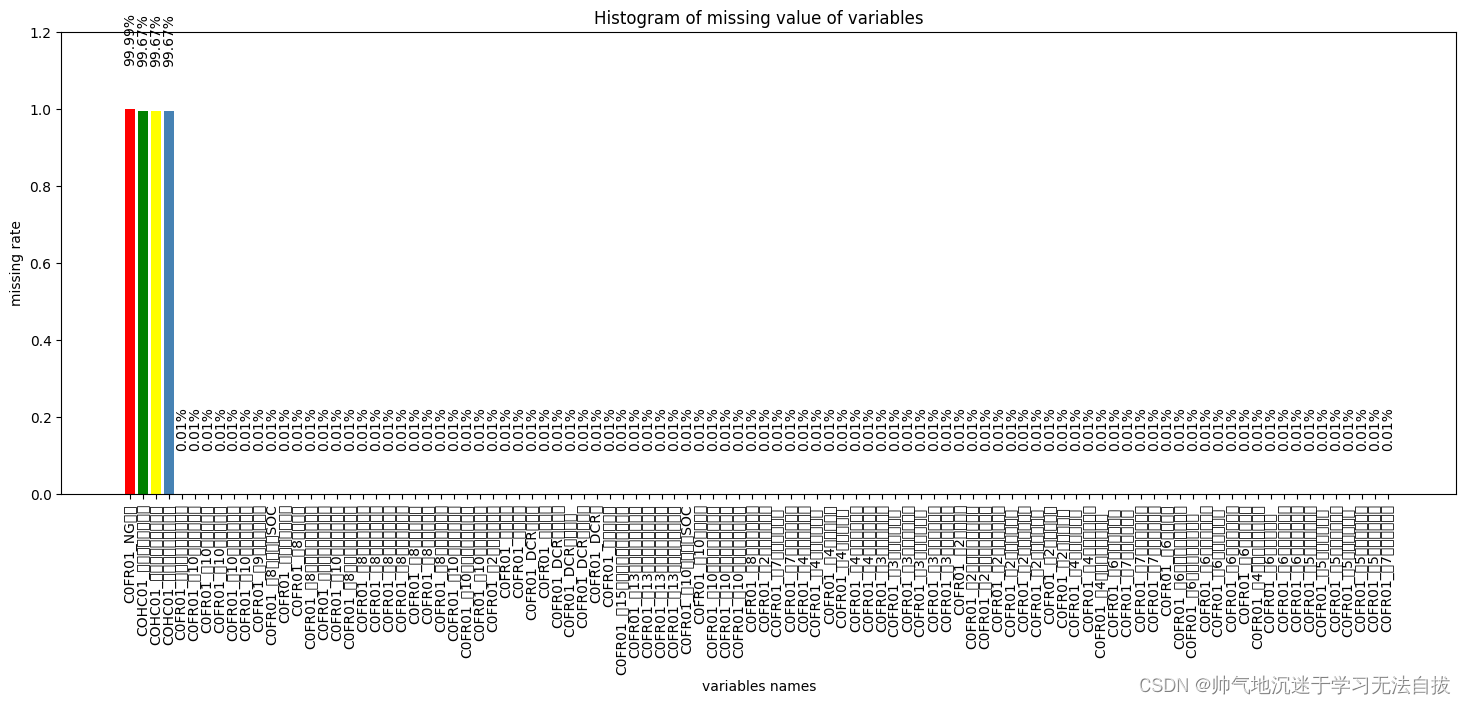
数据预处理方式合集
删除空行 #del all None value data_all.dropna(axis1, howall, inplaceTrue) 删除空列 #del all None value data_all.dropna(axis0, howall, inplaceTrue) 缺失值处理 观测缺失值 观测数据缺失值有一个比较好用的工具包——missingno,直接传入DataFrame&…...

【前端】jquery获取data-*的属性值
通过jquery获取下面data-id的值 <div id"getId" data-id"122" >获取id</div> 方法一:dataset()方法 //data-前缀属性可以在JS中通过dataset取值,更加方便 console.log(getId.dataset.id);//112//赋值 getId.dataset.…...
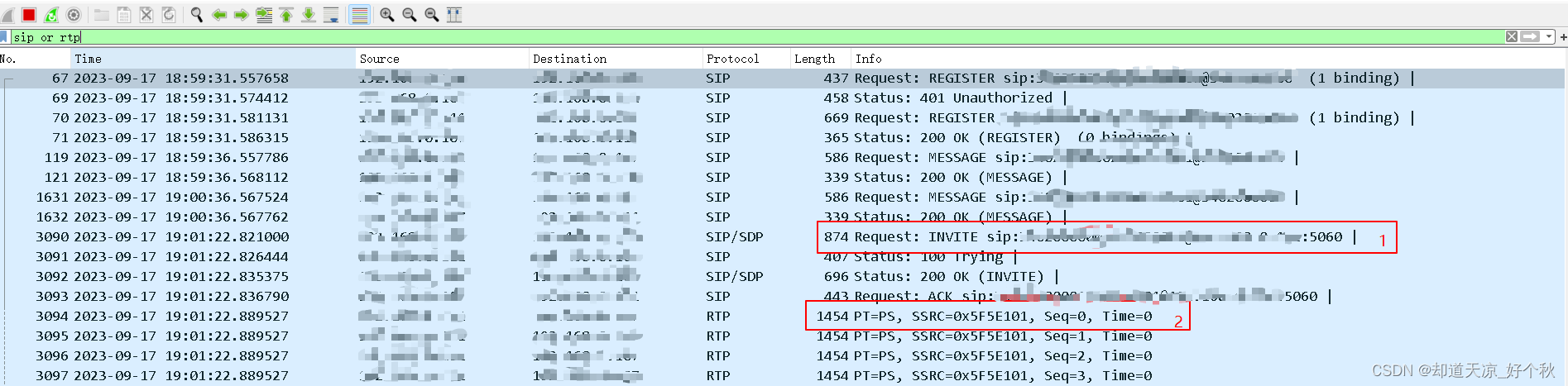
GB28181学习(五)——实时视音频点播(信令传输部分)
要求 实时视音频点播的SIP消息应通过本域或其他域的SIP服务器进行路由、转发,目标设备的实时视音频流宜通过本域的媒体服务器进行转发;采用INVITE方法实现会话连接,采用RTP/RTCP协议实现媒体传输;信令流程分为客户端主动发起和第…...

CMU开源localPlanner避坑指南:从仿真到实车,ROS小车部署的5个关键步骤
CMU开源localPlanner避坑指南:从仿真到实车,ROS小车部署的5个关键步骤 当学术论文中的算法终于有了开源实现,那种跃跃欲试的心情每个机器人开发者都懂。但真正把代码下载到本地,准备部署到自己的ROS小车上时,才发现从理…...

AI Agent沙箱环境部署指南:从Docker容器化到生产级运维
1. 项目概述:构建一个生产级的AI Agent沙箱环境最近在折腾一个挺有意思的项目,叫NemoClaw OpenClaw Sandbox。简单来说,它是一套完整的、开箱即用的部署方案,能帮你在自己的云服务器(VPS)上,快速…...

新手入门零门槛,Captain AI助你7天玩转Ozon
在俄罗斯跨境电商的风口下,Ozon平台吸引了无数新手商家入局。然而,流程繁琐、经验不足、语言不通三大门槛,让超过60%的新手在入驻前3个月就铩羽而归。据行业数据显示,Ozon新手商家的3个月存活率不足40%,其中80%的失败都…...

3个技巧快速掌握arp-scan局域网设备发现
3个技巧快速掌握arp-scan局域网设备发现 【免费下载链接】arp-scan The ARP Scanner 项目地址: https://gitcode.com/gh_mirrors/ar/arp-scan 在网络管理工作中,您是否经常遇到这样的困扰:明明设备连接了网络,却无法通过常规ping命令发…...

青龙脚本自动化:五款实用脚本助你轻松管理日常任务
青龙脚本自动化:五款实用脚本助你轻松管理日常任务 【免费下载链接】huajiScript 滑稽の青龙脚本库 项目地址: https://gitcode.com/gh_mirrors/hu/huajiScript 在当今快节奏的数字时代,自动化工具已成为提升效率的必备利器。如果你正在寻找一款能…...
 微服务测试策略-单元到集成到契约到端到端分层实战)
自动化测试(十) 微服务测试策略-单元到集成到契约到端到端分层实战
微服务测试策略:单元→集成→契约→端到端分层实战前面咱们分别聊了单元测试、接口测试、契约测试。今天把它们串起来,聊聊微服务架构下怎么设计完整的测试策略——每一层测什么、怎么测、用什么工具。一、微服务测试的"金字塔"变体 单体应用的…...

汉字信息聚合工具开发:从数据可视化到工程实践
1. 项目概述:一个汉字学习者的“浏览器” 如果你是一个对汉字结构、字源、演变历史有浓厚兴趣的学习者,或者是一位从事中文教学、字体设计、文化研究的专业人士,你肯定有过这样的经历:为了查清一个汉字的来龙去脉,你需…...

革新Mac软件管理体验:Applite智能图形化工具深度解析
革新Mac软件管理体验:Applite智能图形化工具深度解析 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为繁琐的命令行安装而烦恼?是否曾因复杂的Hom…...

WebRTC、SIP通话背后的隐形功臣:手把手调试G711A/G711U的PCM音频数据
WebRTC与SIP通话背后的音频基石:G711编解码实战解析 实时音视频通信已经成为现代互联网的基础设施,从在线会议到客服电话,背后都离不开高效的音频编解码技术。在众多音频编码标准中,G711系列以其简单可靠的特性,依然活…...
)
Win11精简版系统缺失画图工具?三步教你从微软商店找回(附快速启动技巧)
Win11精简版系统缺失画图工具?三步教你从微软商店找回(附快速启动技巧) 不少追求系统流畅性的用户会选择安装第三方精简版Win11系统,却在需要基础功能时发现连画图工具都找不到了。这并非微软的疏漏,而是精简版系统为了…...