数据结构与算法:排序算法(1)
目录
冒泡排序
思想
代码实现
优化
鸡尾酒排序
优缺点
适用场景
快速排序
介绍
流程
基准元素选择
元素交换
1.双边循环法
使用流程
代码实现
2.单边循环法
使用流程
代码实现
3.非递归实现
排序在生活中无处不在,看似简单,背后却隐藏着多种多样的算法和思想;
根据时间复杂度的不同,主流的排序算法可以分为三大类:
1.时间复杂度为O(n^2)的排序算法
冒泡排序
选择排序
插入排序
希尔排序
2.时间复杂度为O(nlogn)的排序算法
快速排序
归并排序
堆排序
3.时间复杂度为线性的排序算法
计数排序
桶排序
基数排序
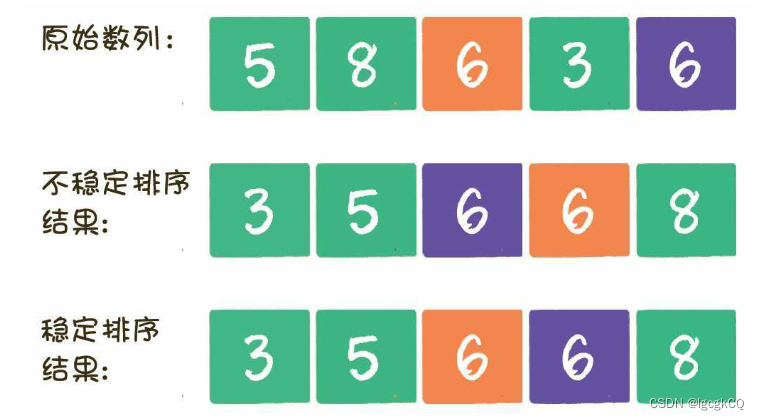
根据稳定性:稳定排序、不稳定排序(如果值相同的元素在排序后仍然保持着排序前的顺序,则这样的排序算法是稳定排序;如果值相同的元素在排序后打乱了排序前的顺序,则这样的排序算法是
不稳定排序)
冒泡排序
冒泡排序,是一种基础的交换排序;这种排序算法的每一个元素都可以像小气泡一样,根据自身大小,一点一点地向着数组的一侧移动
思想
把相邻的元素两两比较,当一个元素大于右侧相邻元素时,交换它们的位置;当一个元素小于或等于右侧相邻元素时,位置不变

元素9作为数列中最大的元素,就像是汽水里的小气泡一样,“漂”到了最右侧;再经过多轮排序,所有元素都是有序的。
冒泡排序是一种稳定排序,值相等的元素并不会打乱原本的顺序。由于该排序算法的每一轮都要遍历所有元素,总共遍历(元素数量-1)轮,所以平均时间复杂度是O(n^2);
代码实现
public static void main(String[] args){int[] array = new int[]{5,8,6,3,9,2,1,7};bubbleSort(array);System.out.println(Arrays.toString(array));}public static void bubbleSort(int array[]){for(int i = 0; i < array.length - 1; i++){for(int j = 0; j < array.length - i - 1; j++){int tmp = 0;if(array[j] > array[j+1]){tmp = array[j];array[j] = array[j+1];array[j+1] = tmp;}}}}使用双循环进行排序。外部循环控制所有的回合,内部循环实现每一轮的冒泡处理,先进行元素比较,再进行元素交换
优化
利用布尔变量作为标记。如果在本轮排序中,元素有交换,则说明数列无序;如果没有元素交换,则说明数列已然有序,然后直接跳出大循环
public static void bubbleSort(int array[]){for(int i = 0; i < array.length - 1; i++){boolean isSorted = true;for(int j = 0; j < array.length - i - 1; j++){int tmp = 0;if(array[j] > array[j+1]){tmp = array[j];array[j] = array[j+1];array[j+1] = tmp;isSorted = false;}}if(isSorted){break;}}}鸡尾酒排序
鸡尾酒排序的元素比较和交换过程是双向的;排序过程就像钟摆一样,第1轮从左到右,第2轮从右到左,第3轮再从左到右……
public static void main(String[] args){int[] array = new int[]{5,8,6,3,9,2,1,7};bubbleSort(array);System.out.println(Arrays.toString(array));}public static void bubbleSort(int array[]){int tmp = 0;for(int i = 0; i < array.length/2; i++){//有序标记,每一轮的初始值都是trueboolean isSort = true;//奇数轮,从左向右比较和交换for(int j = i; j < array.length - i - 1; j++){if(array[j] > array[j+1]){tmp = array[j];array[j] = array[j+1];array[j+1] = tmp;//有元素交换,所以不是有序的,标记变为falseisSort = false;}}if(isSort){break;}//在偶数轮之前,将isSorted重新标记为trueisSort=true;//偶数轮,从右向左比较和交换for(int j=array.length-i-1; j>i; j--){if(array[j] < array[j-1]){tmp = array[j];array[j] = array[j-1];array[j-1] = tmp;//因为有元素进行交换,所以不是有序的,标记变为falseisSort = false;}}if(isSort){break;}}}代码外层的大循环控制着所有排序回合,大循环内包含2个小循环,第1个小循环从左向右比较并交换元素,第2个小循环从右向左比较并交换元素
优缺点
优点:能够在特定条件下,减少排序的回合数
缺点:代码量几乎增加了1倍
适用场景
大部分元素已经有序的情况
快速排序
介绍
快速排序也属于交换排序,通过元素之间的比较和交换位置来达到排序的目的。快速排序则在每一轮挑选一个基准元素,并让其他比它大的元素移动到数列一边,比它小的元素移动到数列的另一边,从而把数列拆解成两个部分;
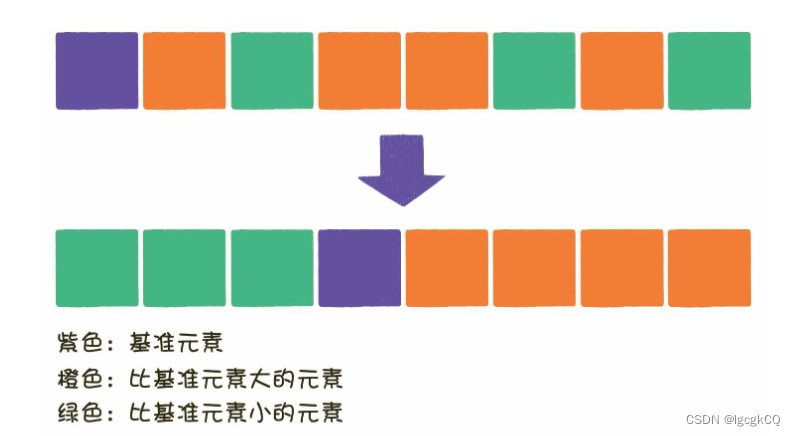
这种思路叫做分治法;
流程
在分治法的思想下,原数列在每一轮都被拆分成两部分,每一部分在下一轮又分别被拆分成两部分,直到不可再分为止

每一轮的比较和交换,需要把数组全部元素都遍历一遍,时间复杂度是O(n)。
基准元素选择
基准元素:在分治过程中,以基准元素为中心把其他元素移到它的左右两边。
1.直接选择数列的第1个元素

2.随机选择一个元素
可以随机选择一个元素作为基准元素,并且让基准元素和数列首元素交换位置
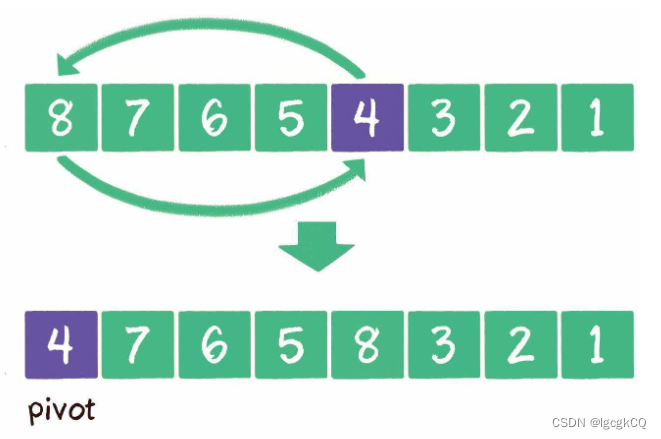
元素交换
选定了基准元素以后,我们要做的就是把其他元素中小于基准元素的都交换到基准元素一边,大于基准元素的都交换到基准元素另一边。
有两种实现元素交换的方法:双边循环法、单边循环法
1.双边循环法
实现了元素的交换,让数列中的元素依据自身大小,分别交换到基准元素的左右两边。
使用流程
1.选定基准元素pivot,并且设置两个指针left和right,指向数列的最左和最右两个元素
2.从right指针开始,让指针所指向的元素和基准元素做比较。如果大于或等于pivot,则指针向左移动;如果小于pivot,则right指针停止移动,切换到left指针
3.轮到left指针行动,让指针所指向的元素和基准元素做比较。如果小于或等于pivot,则指针向右移动;如果大于pivot,则left指针停止移动
4.指针大于基准元素时,所指定的元素进行交换,并切换指针
5.当左、右指针重合时,把重合点的元素和基准元素进行交换
代码实现
public static void main(String[] args){int[] array = new int[]{5,8,6,3,9,2,1,7};bubbleSort(array, 0, array.length-1);System.out.println(Arrays.toString(array));}public static void bubbleSort(int[] arr, int startIndex,int endInde){//递归结束:startIndex >= endInde时if(startIndex >= endInde){return;}//得到基准元素int pivotIndex = partition(arr, startIndex, endInde);//根据基准元素,分成两部分进行递归排序bubbleSort(arr,startIndex,pivotIndex-1);bubbleSort(arr,pivotIndex+1,endInde);}/*** 双边循环法,返回基准元素位置* @param arr 待交换的数组* @param startIndex 起始下标* @param endIndex 结束下标* @return*/private static int partition(int[] arr, int startIndex,int endIndex){//取第1个位置(也可以选择随机位置)的元素作为基准元素int pivot = arr[startIndex];int left = startIndex;int right = endIndex;while (left != right){//控制right 指针比较并左移while(left<right && arr[right] > pivot){right--;}//控制left 指针比较并右移while(left<right && arr[left] > pivot){left++;}if(left < right){int p = arr[left];arr[left] = arr[right];arr[right] = p;}}//pivot 和指针重合点交换arr[startIndex] = arr[left];arr[left] = pivot;return left;}2.单边循环法
双边循环法从数组的两边交替遍历元素,虽然更加直观,但是代码实现相对烦琐。而单边循环法则简单得多,只从数组的一边对元素进行遍历和交换。
使用流程
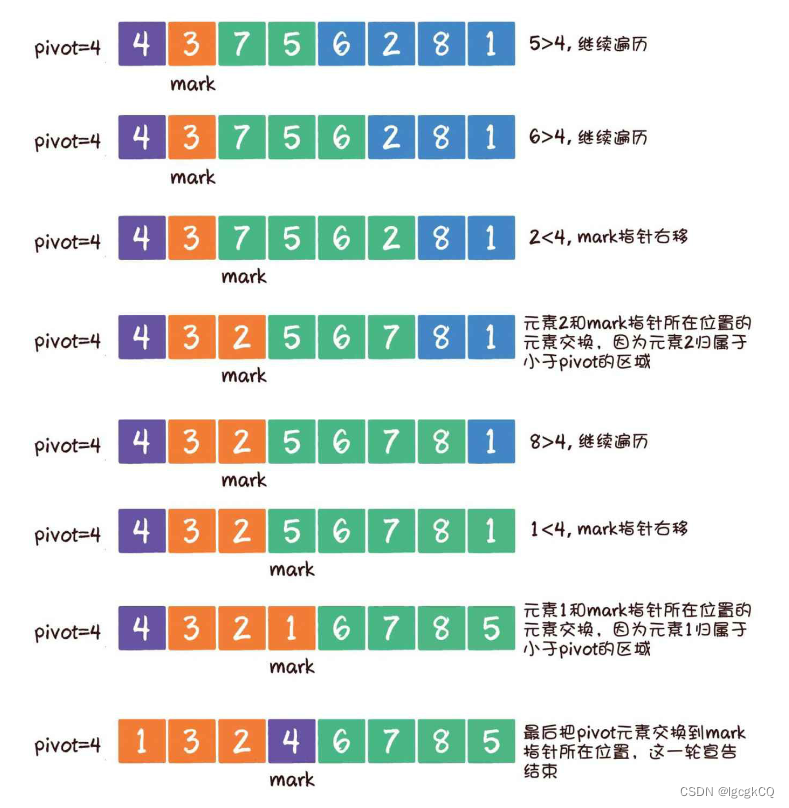
1.首先选定基准元素pivot。同时,设置一个mark指针指向数列起始位置,这个mark指针代表小于基准元素的区域边界
2.从基准元素的下一个位置开始遍历数组;如果遍历到的元素大于基准元素,就继续往后遍历;如果遍历到的元素小于基准元素,则需要做两件事:第一,把mark指针右移1位,因为小于pivot的区域边界增大了1;第二,让最新遍历到的元素和mark指针所在位置的元素交换位置,因为最新遍历的元素归属于小于pivot的区域
代码实现
public static void main(String[] args){int[] array = new int[]{5,8,6,3,9,2,1,7};bubbleSort(array, 0, array.length-1);System.out.println(Arrays.toString(array));}public static void bubbleSort(int[] arr, int startIndex,int endInde){//递归结束:startIndex >= endInde时if(startIndex >= endInde){return;}//得到基准元素int pivotIndex = partition(arr, startIndex, endInde);//根据基准元素,分成两部分进行递归排序bubbleSort(arr,startIndex,pivotIndex-1);bubbleSort(arr,pivotIndex+1,endInde);}/*** 双边循环法,返回基准元素位置* @param arr 待交换的数组* @param startIndex 起始下标* @param endIndex 结束下标* @return*/private static int partition(int[] arr, int startIndex,int endIndex){//取第1个位置(也可以选择随机位置)的元素作为基准元素int pivot = startIndex;int mark = endIndex;for(int i=startIndex+1; i<=endIndex; i++){if(arr[i]<pivot){mark++;int p = arr[mark];arr[mark] = arr[i];arr[i] = p;}}//pivot 和指针重合点交换arr[startIndex] = arr[mark];arr[mark] = pivot;return mark;}3.非递归实现
把原本的递归实现转化成一个栈的实现,在栈中存储每一次方法调用的参数
public static void main(String[] args){int[] array = new int[]{5,8,6,3,9,2,1,7};bubbleSort(array, 0, array.length-1);System.out.println(Arrays.toString(array));}public static void bubbleSort(int[] arr, int startIndex,int endInde){Stack<Map<String, Integer>> quickSortStack = new Stack<Map<String, Integer>>();Map rootParam = new HashMap();rootParam.put("startIndex", startIndex);rootParam.put("endIndex", endInde);quickSortStack.push(rootParam);while (!quickSortStack.isEmpty()) {Map<String, Integer> param = quickSortStack.pop();int pivotIndex = partition(arr, param.get("startIndex"),param.get("endIndex"));if(param.get("startIndex") < pivotIndex -1){Map<String, Integer> leftParam = new HashMap<String,Integer>();leftParam.put("startIndex", param.get("startIndex"));leftParam.put("endIndex", pivotIndex-1);quickSortStack.push(leftParam);}if(pivotIndex + 1 < param.get("endIndex")){Map<String, Integer> rightParam = new HashMap<String,Integer>();rightParam.put("startIndex", pivotIndex + 1);rightParam.put("endIndex", param.get("endIndex"));quickSortStack.push(rightParam);}}}/*** 双边循环法,返回基准元素位置* @param arr 待交换的数组* @param startIndex 起始下标* @param endIndex 结束下标* @return*/private static int partition(int[] arr, int startIndex,int endIndex){//取第1个位置(也可以选择随机位置)的元素作为基准元素int pivot = startIndex;int mark = endIndex;for(int i=startIndex+1; i<=endIndex; i++){if(arr[i]<pivot){mark++;int p = arr[mark];arr[mark] = arr[i];arr[i] = p;}}//pivot 和指针重合点交换arr[startIndex] = arr[mark];arr[mark] = pivot;return mark;} 非递归方式代码的变动只发生在quickSort方法中。该方法引入了一个存储Map类型元素的栈,用于存储每一次交换时的起始下标和结束下标。
每一次循环,都会让栈顶元素出栈,通过partition方法进行分治,并且按照基准元素的位置分成左右两部分,左右两部分再分别入栈。当栈为空时,说明排序已经完毕,退出循环
相关文章:
数据结构与算法:排序算法(1)
目录 冒泡排序 思想 代码实现 优化 鸡尾酒排序 优缺点 适用场景 快速排序 介绍 流程 基准元素选择 元素交换 1.双边循环法 使用流程 代码实现 2.单边循环法 使用流程 代码实现 3.非递归实现 排序在生活中无处不在,看似简单,背后却隐藏…...
NotePad++ 在行前/行后添加特殊字符内容方法
我们在处理数据时,会遇到需要在每行数据前面、后面、开头、结尾添加各种不一样的字符 如果数据不多,我们可以自己手动的去添加,但如果达到了成百上千行,此时再机械的手动添加是不现实的 这里教给大家如何快速的在数据每行的前后…...
【JavaEE】多线程案例-线程池
文章目录 1. 什么是线程池2. 为什么要使用线程池(线程池有什么优点)3. 如何使用Java标准库提供的线程池3.1 创建一个线程池对象3.2 什么是工厂模式3.3 为什么要使用工厂模式3.4 Executors 创建不同具有不同特性的线程池3.5 ThreadPool 类的构造方法3.6 线…...
服务器搭建(TCP套接字)-fork版(服务端)
基础版的服务端虽然基本实现了服务器的基本功能,但是如果客户端的并发量比较大的话,服务端的压力和性能就会大打折扣,为了提升服务端的并发性能,可以通过fork子进程的方式,为每一个连接成功的客户端fork一个子进程,这样…...

缺失的第一个正数:高效解法与技术
缺失的第一个正数:高效解法与技术 背景 在计算机编程中,有时候需要寻找一个未排序整数数组中没有出现的最小的正整数。这篇技术博客将详细讨论这个问题,并提供一个时间复杂度为 O(n) 且只使用常数级别额外空间的解决方案。 问题描述 leet…...
)
常用的辅助网站(持续更新)
标题 一、uni-app方向二、H5方向 一、uni-app方向 1、uni-app官网 地址:https://uniapp.dcloud.net.cn/ 2、香蕉云编 地址:https://www.yunedit.com/ 描述:一般用来配置ios证书或安卓证书、上传ios包至商店 3、uView 地址:http…...

LeetCode 75 - 01 : 最小面积矩形
type pair struct{x, y int }func minAreaRect(points [][]int)int{mp : map[pair]struct{}{}// 将二维数组中的坐标映射到map中for i : range points{mp[pair{points[i][0], points[i][1]}] struct{}{}}// 将结果设置为一个最大值,防止影响求最小值的逻辑res : ma…...
每日一题:请解释什么是闭包(Closure)?并举一个实际的例子来说明。(前端初级)
今天继续在前端初级笔试题中被AI虐: 碱面的答案,问题:初级,回答:初级https://bs.rongapi.cn/1702510598371151872/14我的回答如下: 闭包是指由大括号包裹的一个区域,这个区域代表了一个变量生效…...

广告主必看!NetMarvel五大优势驱动出海App投放增长
App出海走到今天,流量红利早就不存在,摆在广告主面前最棘手的两个问题,一是不起量,二是买量成本太高,得不偿失。 如何在确保出海应用用户规模有所增长的同时,也保证整体ROI处在较高水平?NetMar…...

数据结构与算法之复杂度
时间复杂度 1.抓大头 2.常数用o(1),低阶函数也用o(1)代替(直接去掉) 3.取最坏情况 对数相关写法的规定...

ATECLOUD电源测试软件平台如何测试电源纹波?
电源纹波是影响电源稳定性的重要因素,过大的纹波会导致电源模块的工作效率降低,可能使电源模块直接损坏。使用ATECLOUD碘盐测试软件平台对纹波进行测试,检测其工作情况,以确保其稳定性和性能。 电源纹波的产生 电源的纹波通俗的来…...
数据结构与算法:排序算法(2)
目录 堆排序 使用步骤 代码实现 计数排序 适用范围 过程 代码实现 排序优化 桶排序 工作原理 代码实现 堆排序 二叉堆的特性: 1. 最大堆的堆顶是整个堆中的最大元素 2. 最小堆的堆顶是整个堆中的最小元素 以最大堆为例,如果删除一个最大堆的…...
1_图神经网络GNN基础知识学习
文章目录 安装PyTorch Geometric安装工具包 在KarateClub数据集上使用图卷积网络 (GCN) 进行节点分类两个画图函数Graph Neural Networks数据集:Zacharys karate club network.PyTorch Geometric数据集介绍 edge_index使用networkx可视化展示 Graph Neural Networks…...
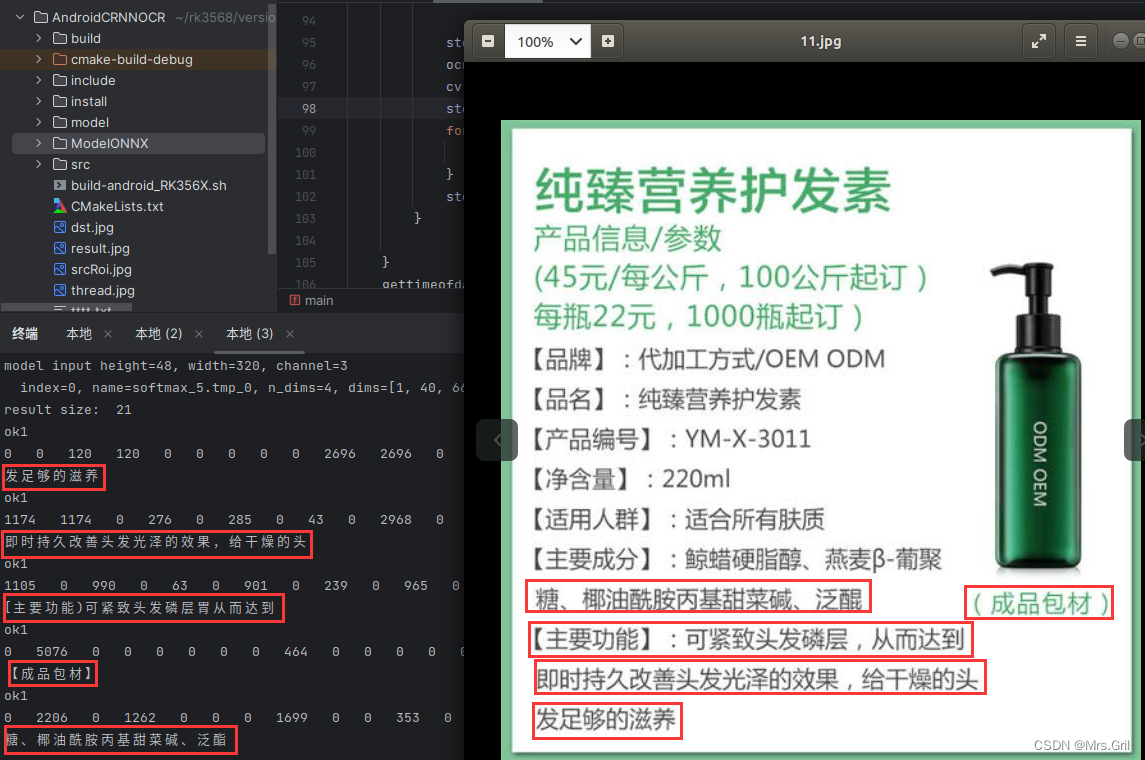
瑞芯微:基于RK3568的ocr识别
光学字符识别(Optical Character Recognition, OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。亦即将图像中的文字进行识别,并以文本的形式返回。OCR的应用场景 卡片证件识别类:大陆、港澳…...

C++真的是 C加加
📝个人主页:夏目浅石. 📌博客专栏:C的故事 🏠学习社区:夏目友人帐. 文章目录 前言Ⅰ. 函数重载0x00 重载规则0x01 函数重载的原理名字修饰 Ⅱ. 引用0x00 引用的概念0x01 引用和指针区分0x03 引用的本质0x04…...
)
java学习--day5 (java中的方法、break/continue关键字)
文章目录 day4作业今天的内容1.方法【重点】1.1为什么要有方法1.2其实已经见过方法1.3定义方法的语法格式1.3.1无参无返回值的方法1.3.2有参无返回值的方法1.3.3无参有返回值的方法1.3.4有参有返回值的方法 2.break和continue关键字2.1break;2.2continue; 3.案例关于方法的练习…...
MFC主框架和视类PreCreateWindow()函数学习
在VC生成的单文档应用程序中,主框架类和视类均具有PreCreateWindow函数; 从名字可知,可在此函数中添加一些代码,来控制窗口显示后的效果; 并且它有注释说明, Modify the Window class or styles here by…...

for forin forof forEach map区别
一、总结 相同点:都是串行遍历。不同点: 二、for of循环 设计目的:遍历所有数据结构的统一方法。原理:会调用数据结构的Symbol.iterator方法。 只要数据结构定义了Symbol.iterator属性,就能用for of遍历它的成员。…...
)
特殊时间(蓝桥杯)
特殊时间 问题描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 2022年2月22日22:20 是一个很有意义的时间, 年份为 2022 , 由 3 个 2 和 1 个 0 组成, 如果将月和日写成 4 位, 为 0222 , 也是由 3 个 2 和 1 个 0 组 成…...
VUE路由与nodeJS环境搭建
VUE路由 Vue路由是Vue.js提供的路由管理工具,它允许我们在应用程序中实现页面之间的导航,从而使单页面应用程序的开发更加方便。通过Vue路由,我们可以轻松地创建和管理多个视图,并在这些视图之间导航。 Vue路由使用HTML5的Histo…...
)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战)
别再只用GitHub了!手把手教你用GitLab搭建团队专属代码仓库(从群组到项目实战) 在开源生态中,GitHub无疑是代码托管平台的代名词。但对于需要私有化部署和精细权限控制的团队而言,GitLab提供了更完整的DevOps解决方案。…...

AgentVault Memory:构建本地AI编码记忆库,实现跨工具语义搜索与知识管理
1. 项目概述:为什么我们需要一个统一的AI编码记忆库如果你和我一样,每天的工作流里塞满了各种AI编码助手——Claude Code在终端里处理一个项目,Cursor在IDE里开着,偶尔切到OpenCode或者Codex处理点零碎任务。每次对话都充满了宝贵…...

AI安全自动化测试:FuzzyAI模糊测试框架实战指南
1. 项目概述:当AI安全遇上自动化“模糊测试” 在大型语言模型(LLM)如ChatGPT、Claude、Gemini等日益普及的今天,我们享受其强大能力的同时,也面临着一个严峻的挑战:如何确保它们的安全与可控?你…...

数据库完整性约束与安全机制全解析
一、数据库完整性约束1、数据库完整性基本概念与核心机制(1)完整性定义与作用数据库完整性(Database Integrity)是指在任何情况下保证数据的正确性(Validity)和一致性(Consistency)&…...

Flutter For Openharmony第三方库: animated_text_kit 的鸿蒙化适配指南
Flutter 三方库 animated_text_kit 的鸿蒙化适配指南 欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net 前言:文字是可动的 嘿~亲爱的开发者小伙伴们,大家好呀!👋 今天我们要一起探索一个超级有…...

Enzyme协议:DeFi资产管理智能合约架构与实战指南
1. 项目概述:当智能合约遇上资产管理如果你在区块链领域,特别是DeFi(去中心化金融)生态里待过一段时间,大概率听说过“Enzyme”这个名字。它不是一个新概念,但绝对是DeFi乐高积木中一块承重墙级别的组件。简…...

一分钟看懂大模型备案
大模型备案,全称 “生成式人工智能服务上线备案”,是国内面向公众提供大模型服务的法定合规流程,核心是审核模型安全、数据合规与内容可控,未备案违规上线最高罚一千万元,该处罚依据主要来自两大核心法规:1…...
:框架、流程与量化基础)
信息安全工程师-网络安全风险评估(上篇):框架、流程与量化基础
一、引言 (一)核心定位与定义 网络安全风险评估是信息安全管理体系的核心方法论,在软考信息安全工程师考试中属于信息安全管理模块的高频考点,占比约 8-10 分。其标准定义为:依据 GB/T 20984-2007《信息安全技术 信息…...

高海拔环境下的硬件设计挑战与GPS定位故障分析
1. 从数据记录到真实体验:高海拔环境下的技术挑战作为一名电子工程师,我习惯了在实验室里与精密的仪器和数据打交道,一切都在可控范围内。但当你带着自己设计的设备,踏上非洲之巅乞力马扎罗的征途时,现实会给你上一堂生…...

Poppins字体终极指南:免费开源的多语言几何无衬线字体完全解析
Poppins字体终极指南:免费开源的多语言几何无衬线字体完全解析 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 如果你正在寻找一款既现代又专业的免费字体ÿ…...