【深度学习实验】前馈神经网络(七):批量加载数据(直接加载数据→定义类封装数据)
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
三、实验内容
0. 导入必要的工具包
1. 直接加载鸢尾花数据集
a. 加载数据集
b. 数据归一化
c. 洗牌操作
d. 打印数据
2. 定义类封装数据
a. __init__(构造函数:用于初始化数据集对象)
b. __getitem__(获取指定索引处的样本)
c. __len__(获取数据集的长度)
3. 构建数据集(批量加载训练、验证、测试集)
4. 代码整合
一、实验介绍
在本系列先前的代码中,借助深度学习框架的帮助,已经完成了前馈神经网络的大部分功能。本文将基于鸢尾花数据集构建一个数据迭代器,以便在每次迭代时从全部数据集中获取指定数量的数据。(借助深度学习框架中的Dataset类和DataLoader类来实现此功能)
【深度学习】Pytorch 系列教程(十三):PyTorch数据结构:5、数据加载器(DataLoader)_QomolangmaH的博客-CSDN博客![]() https://blog.csdn.net/m0_63834988/article/details/132924381?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_63834988/article/details/132924381?spm=1001.2014.3001.5502
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下:
1. 配置虚拟环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlib conda install scikit-learn2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
三、实验内容
ChatGPT:
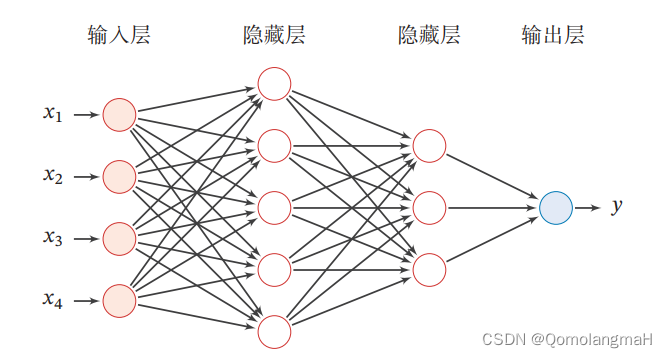
前馈神经网络(Feedforward Neural Network)是一种常见的人工神经网络模型,也被称为多层感知器(Multilayer Perceptron,MLP)。它是一种基于前向传播的模型,主要用于解决分类和回归问题。
前馈神经网络由多个层组成,包括输入层、隐藏层和输出层。它的名称"前馈"源于信号在网络中只能向前流动,即从输入层经过隐藏层最终到达输出层,没有反馈连接。
以下是前馈神经网络的一般工作原理:
输入层:接收原始数据或特征向量作为网络的输入,每个输入被表示为网络的一个神经元。每个神经元将输入加权并通过激活函数进行转换,产生一个输出信号。
隐藏层:前馈神经网络可以包含一个或多个隐藏层,每个隐藏层由多个神经元组成。隐藏层的神经元接收来自上一层的输入,并将加权和经过激活函数转换后的信号传递给下一层。
输出层:最后一个隐藏层的输出被传递到输出层,输出层通常由一个或多个神经元组成。输出层的神经元根据要解决的问题类型(分类或回归)使用适当的激活函数(如Sigmoid、Softmax等)将最终结果输出。
前向传播:信号从输入层通过隐藏层传递到输出层的过程称为前向传播。在前向传播过程中,每个神经元将前一层的输出乘以相应的权重,并将结果传递给下一层。这样的计算通过网络中的每一层逐层进行,直到产生最终的输出。
损失函数和训练:前馈神经网络的训练过程通常涉及定义一个损失函数,用于衡量模型预测输出与真实标签之间的差异。常见的损失函数包括均方误差(Mean Squared Error)和交叉熵(Cross-Entropy)。通过使用反向传播算法(Backpropagation)和优化算法(如梯度下降),网络根据损失函数的梯度进行参数调整,以最小化损失函数的值。
前馈神经网络的优点包括能够处理复杂的非线性关系,适用于各种问题类型,并且能够通过训练来自动学习特征表示。然而,它也存在一些挑战,如容易过拟合、对大规模数据和高维数据的处理较困难等。为了应对这些挑战,一些改进的网络结构和训练技术被提出,如卷积神经网络(Convolutional Neural Networks)和循环神经网络(Recurrent Neural Networks)等。
本系列为实验内容,对理论知识不进行详细阐释
(咳咳,其实是没时间整理,待有缘之时,回来填坑)
0. 导入必要的工具包
import torch
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader
Dataset和DataLoader类用于处理数据集和数据加载
1. 直接加载鸢尾花数据集
加载鸢尾花数据进行归一化并可选地进行洗牌操作,以便于后续的深度学习任务。
import torch
from sklearn.datasets import load_irisdef load_data(shuffle=True):x = torch.tensor(load_iris().data)y = torch.tensor(load_iris().target)# 数据归一化x_min = torch.min(x, dim=0).valuesx_max = torch.max(x, dim=0).valuesx = (x - x_min) / (x_max - x_min)if shuffle:idx = torch.randperm(x.shape[0])x = x[idx]y = y[idx]return x, ya. 加载数据集
-
调用
load_iris().data函数加载数据,并使用torch.tensor将数据转换为PyTorch张量,将结果赋值给变量x。 -
调用
load_iris().target函数加载目标变量,并使用torch.tensor将数据转换为PyTorch张量,将结果赋值给变量y。
b. 数据归一化
-
计算矩阵
x每列的最小值。-
torch.min函数的dim参数设置为0表示按列计算最小值,.values属性获取最小值的张量。
-
-
计算矩阵
x每列的最大值。-
torch.max函数的dim参数设置为0表示按列计算最大值,.values属性获取最大值的张量。
-
-
x = (x-x_min)/(x_max-x_min):对矩阵x进行归一化处理,将每个元素减去最小值,然后除以最大值与最小值之差。这样可以将数据缩放到0和1之间。
c. 洗牌操作
-
if shuffle::如果shuffle参数为True,执行以下代码块。-
idx = torch.randperm(x.shape[0]):生成一个随机排列的索引,范围从0到x的行数减1。torch.randperm函数返回一个随机排列的整数序列。 -
x = x[idx]:根据生成的随机索引对矩阵x进行行重排,打乱数据的顺序。 -
y = y[idx]:根据生成的随机索引对向量y进行行重排,保持目标变量与输入数据的对应关系。
-
-
return x, y:返回处理后的输入特征矩阵x和目标变量向量y。
d. 打印数据
x, y = load_data()
print("Input features (x):")
print(x)
print("Target variables (y):")
print(y)

2. 定义类封装数据
创建一个用于处理鸢尾花数据集的自定义数据集(继承自Dataset类),该自定义数据集类可以用于创建鸢尾花数据集的训练集、验证集或测试集对象,并提供给__getitem__和__len__方法,以便能够使用DataLoader类进行数据加载和批处理操作。
class IrisDataset(Dataset):def __init__(self, mode='train', num_train=120, num_dev=15):super(IrisDataset,self).__init__()x, y = load_data(shuffle=True)if mode == 'train':self.x, self.y = x[:num_train], y[:num_train]elif mode == 'dev':self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]else:self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]def __getitem__(self, idx):return self.x[idx], self.y[idx]def __len__(self):return len(self.x)-
class IrisDataset(Dataset)::定义了一个名为IrisDataset的类,该类继承自Dataset类,表示一个自定义的数据集。
a. __init__(构造函数:用于初始化数据集对象)
-
该函数接受三个参数:
-
mode表示数据集模式(默认为'train') -
num_train表示训练样本的数量(默认为120) -
num_dev表示验证样本的数量(默认为15)。
-
-
super(IrisDataset, self).__init__():调用父类Dataset的构造函数,确保正确地初始化基类。 -
x, y = load_data(shuffle=True):调用之前定义的load_data函数加载数据集。 -
如果数据集模式为'train':
-
将前
num_train个训练样本赋值给类的成员变量self.x和self.y,表示训练数据集。
-
-
如果数据集模式为'dev':
-
将从第
num_train个样本开始的num_dev个样本赋值给类的成员变量self.x和self.y,表示验证数据集。
-
-
如果数据集模式不是'train'也不是'dev':
-
将从第
num_train + num_dev个样本开始的剩余样本赋值给类的成员变量self.x和self.y,表示测试数据集。
-
b. __getitem__(获取指定索引处的样本)
-
return self.x[idx], self.y[idx]:根据索引idx返回对应位置的输入特征和目标变量。
c. __len__(获取数据集的长度)
-
return len(self.x):返回数据集的长度,即样本数量。
3. 构建数据集(批量加载训练、验证、测试集)
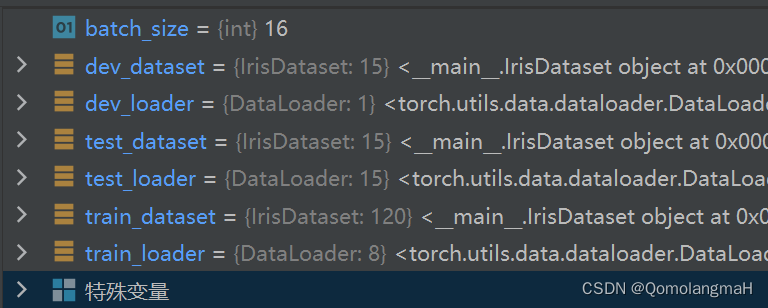
batch_size = 16# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=True)- 使用自定义的数据封装类加载鸢尾花数据集的训练集、验证集和测试集,并使用
DataLoader进行批量加载。train_dataset是要加载的数据集对象,batch_size是批量大小,表示每个批次的样本数量,shuffle=True表示在每个迭代周期中对数据进行随机洗牌。- 将验证集数据集加载到
dev_loader中,未指定shuffle参数,默认为False,不进行洗牌。 - 将测试集数据集加载到
test_loader中,将batch_size设置为1,表示每个批次只包含一个样本,同时指定shuffle=True,在每个迭代周期中对数据进行随机洗牌。
4. 代码整合
# 导入必要的工具包
import torch
from sklearn.datasets import load_iris
from torch.utils.data import Dataset, DataLoader# 此函数用于加载鸢尾花数据集
def load_data(shuffle=True):x = torch.tensor(load_iris().data)y = torch.tensor(load_iris().target)# 数据归一化x_min = torch.min(x, dim=0).valuesx_max = torch.max(x, dim=0).valuesx = (x - x_min) / (x_max - x_min)if shuffle:idx = torch.randperm(x.shape[0])x = x[idx]y = y[idx]return x, y# 构建自己的数据集,继承自Dataset类
class IrisDataset(Dataset):def __init__(self, mode='train', num_train=120, num_dev=15):super(IrisDataset, self).__init__()x, y = load_data(shuffle=True)if mode == 'train':self.x, self.y = x[:num_train], y[:num_train]elif mode == 'dev':self.x, self.y = x[num_train:num_train + num_dev], y[num_train:num_train + num_dev]else:self.x, self.y = x[num_train + num_dev:], y[num_train + num_dev:]def __getitem__(self, idx):return self.x[idx], self.y[idx]def __len__(self):return len(self.x)batch_size = 16# 分别构建训练集、验证集和测试集
train_dataset = IrisDataset(mode='train')
dev_dataset = IrisDataset(mode='dev')
test_dataset = IrisDataset(mode='test')train_loader = DataLoader(train_dataset, batch_size=batch_size,shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=1, shuffle=True)相关文章:
【深度学习实验】前馈神经网络(七):批量加载数据(直接加载数据→定义类封装数据)
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 三、实验内容 0. 导入必要的工具包 1. 直接加载鸢尾花数据集 a. 加载数据集 b. 数据归一化 c. 洗牌操作 d. 打印数据 2. 定义类封装数据 a. __init__(构造函数:用于初始化数据集对象) b.…...

气体放电模拟装置中1Pa~101kPa范围内的真空度控制技术
摘要:针对微间隙气体放电特性分析中需要对不同真空压力进行精密控制的要求,本文提出了相应的解决方案。解决方案采用了双路调节技术,由真空计、电控针阀和真空压力控制器组成进气和排气控制回路,可实现真空度1Pa~101kPa全量程范围…...

华为OD机试 - 构成正方形的数量 - 数据结构map(Java 2023 B卷 100分)
目录 专栏导读一、题目描述二、输入描述三、输出描述四、Java算法源码五、效果展示1、输入2、输出3、说明 华为OD机试 2023B卷题库疯狂收录中,刷题点这里 专栏导读 本专栏收录于《华为OD机试(JAVA)真题(A卷B卷)》。 …...

sql on条件判断是要注意null值
我是因为用了merge into语法,然后on条件中判断的字段是可配置的,这就导致了,有时候判断条件多的情况下,判断的字段会碰到有null值的情况,如果on两边的字段都是null,null和null对比就会导致结果为false&…...

9.22(一):数组扁平化
ES6的flat方法 const arr[1,2,[33,44,5,[6,7]],3]// es6中的flat方法function arr1() { //数组自带的扁平化方法,flat的参数代表的是需要展开几层, //如果是Infinity的话,就是不管嵌套几层,全部都展开return arr.flat(Infinity) } let resul…...

【vue2第十九章】手动修改ESlint错误 和 配置自动化修改ESlint错误
目标:认识代码规范 代码规范:一套写代码的约定规则。例如:“赋值符号的左右是否需要空格”,"一句结束是否是要加;”等 为什么要使用代码规范? 在团队开发时,提高代码的可读性。 在创建项目时,我们选择的就是一套完整的代码…...
计算机网络常见面试题
目录 一、谈一谈对OSI七层模型和TCP/IP四层模型的理解? 答:OSI七层模型主要分为: TCP/IP四层协议: 二、谈谈TCP协议的3次握手过程? 三、TCP协议为什么要3次握手?2次,4次不行吗? …...
springboot整合MeiliSearch轻量级搜索引擎
一、Meilisearch与Easy Search点击进入官网了解,本文主要从小微型公司业务出发,选择meilisearch来作为项目的全文搜索引擎,还可以当成来mongodb来使用。 二、starter封装 1、项目结构展示 2、引入依赖包 <dependencies><dependenc…...

禁用鼠标的侧边按键
新买了个鼠标,整体都不错,就是鼠标左侧有两个按键,大拇指经常无意触碰到,造成误操作。 就想着关闭侧边按键功能。以下这批文章帮了大忙! 鼠标侧键屏蔽,再也不用担心按到侧键了。_禁用鼠标侧键_挣扎的蓝藻…...
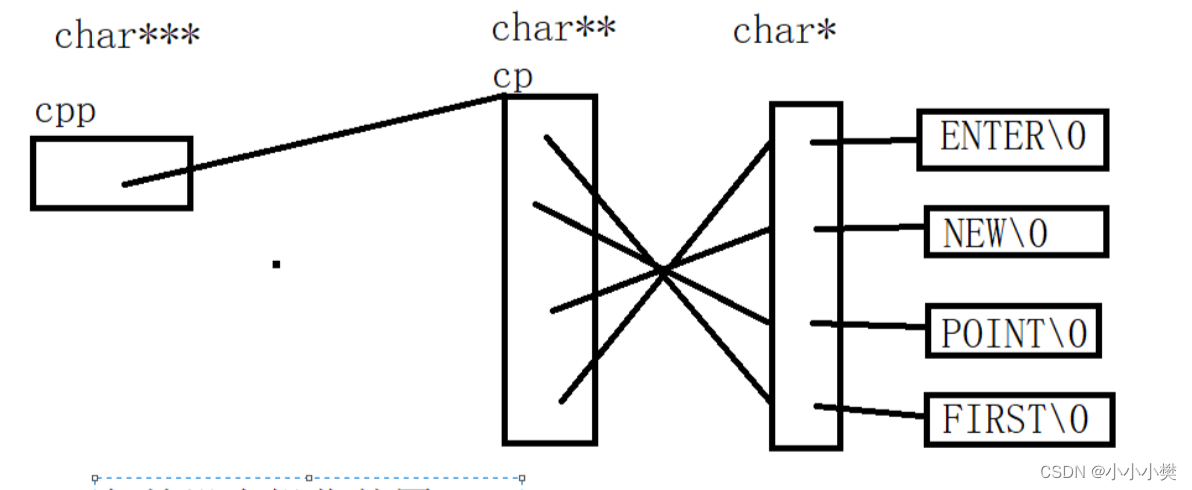
【C语言】数组和指针刷题练习
指针和数组我们已经学习的差不多了,今天就为大家分享一些指针和数组的常见练习题,还包含许多经典面试题哦! 一、求数组长度和大小 普通一维数组 int main() {//一维数组int a[] { 1,2,3,4 };printf("%d\n", sizeof(a));//整个数组…...

2023年中国研究生数学建模竞赛D题解题思路
为了更好的帮助大家第一天选题,这里首先为大家带来D题解题思路,分析对应赛题之后做题阶段可能会遇到的各种难点。 稍后会带来D题的详细解析思路,以及相关的其他版本解题思路 成品论文等资料。 赛题难度评估:A、B>C>E、F&g…...
在编译源码的环境下,搭建起Discuz!社区论坛和WordPress博客的LNMP架构
目录 一.编译安装nginx 二.编译安装MySQL 三.编译安装PHP 四.安装论坛 五.安装wordpress博客 六.yum安装LNMP架构(简要过程参考) 一.编译安装nginx 1)关闭防火墙,将安装nginx所需软件包传到/opt目录下 systemctl stop fire…...

腾讯面试题:无网络环境,如何部署Docker镜像?
亲爱的小伙伴们,大家好!我是小米,很高兴再次和大家见面。今天,我要和大家聊聊一个特别有趣的话题——腾讯面试题:无网络环境,如何部署Docker镜像?这可是一个技术含量颇高的问题哦!废…...

医学影像信息(PACS)系统软件源码
PACS系统是PictureArchivingandCommunicationSystems的缩写,与临床信息系统(ClinicalInformationSystem,CIS)、放射学信息系统(RadiologyInformationSystem,RIS)、医院信息系统(HospitalInformationSystem,HIS)、实验室信息系统(L…...
【01】FISCOBCOS的系统环境安装
我们选择ubuntu系统 01 https://www.ubuntu.org.cn/global 02 03下载最新版 04等待下载 00提前准备好VM,点击创建新的虚拟机 01选择自定义安装 02一直下一步到 03 04 05其他的默认即可 06 07 08 09 10 11一直默认到下面 12 13等待安装 安装后重启即可…...

flutter 权限和图片权限之前的冲突
权限插件 permission_handler: ^9.2.0想调起相册和视频,这个插件只有Permission.storage.request().,获取存储权限。 问题是android 13的一些手机,系统设置没有存储权限,用了上面这个权限,三次拒绝后就永久拒绝了&…...
:读取视频和保存视频)
OpenCV(四十八):读取视频和保存视频
OpenCV(Open Source Computer Vision Library)是一个功能强大的开源计算机视觉库,它提供了丰富的功能,包括读取和保存视频。下面分别演示如何使用OpenCV来读取视频和保存视频。 1. 读取视频: 在OpenCV中我们要获取一…...

如何在react/next.js app中的同级组件间传递数据
这篇文章也可以在我的博客中查看 问题 为什么会有这么奇怪的需求?在事情真正发生前真的难说,但真遇到一个需要这么做的情况。 最近想做一个网页时钟,它的结构如下: 时钟(计算时间,组织各个要素ÿ…...
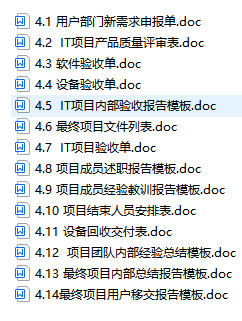
软件需求文档、设计文档、开发文档、运维文档大全
在软件开发过程中,文档扮演着至关重要的角色。它不仅记录了项目的需求、设计和开发过程,还为项目的维护和管理提供了便利。本文将详细介绍软件开发文档的重要性和作用,以及需求分析、软件设计、开发过程、运维管理和项目管理等方面的文档要求…...
排序算法-----归并排序
目录 前言: 归并排序 1. 定义 2.算法过程讲解 2.1大致思路 2.2图解示例 拆分合成步骤 编辑 相关动态图 3.代码实现(C语言) 4.算法分析 4.1时间复杂度 4.2空间复杂度 4.3稳定性 前言: 今天我们就开始学习新的排序算法…...
)
别再硬编码数据了!用QAbstractTableModel+QTableView打造你的第一个Qt桌面表格应用(附完整源码)
从零构建Qt桌面表格应用:实战学生信息管理系统 在桌面应用开发领域,数据展示与交互一直是核心需求。无论是企业内部的员工管理系统,还是学校里的成绩统计工具,一个高效、美观的表格界面往往能极大提升工作效率。对于C开发者而言&a…...

3步告别CAD重复劳动:Python自动化绘图终极指南
3步告别CAD重复劳动:Python自动化绘图终极指南 【免费下载链接】pyautocad AutoCAD Automation for Python ⛺ 项目地址: https://gitcode.com/gh_mirrors/py/pyautocad 还在为AutoCAD中那些重复、机械的绘图任务感到疲惫吗?每天花费数小时手动绘…...

T12 vs JBC焊台DIY终极对比:从5块钱的‘白菜白光’到千元性能,我该选哪个?
T12 vs JBC焊台DIY终极对比:从5块钱的‘白菜白光’到千元性能,我该选哪个? 在电子维修和DIY领域,一把趁手的焊台就像厨师的刀具一样重要。面对市场上琳琅满目的选择,T12和JBC无疑是两个最受关注的方案。前者以极低的成…...

Go语言Envoy实战:高性能代理与负载均衡
Go语言Envoy实战:高性能代理与负载均衡 1. Envoy概述 Envoy是Lyft开源的高性能代理,常作为服务网格的数据平面,提供负载均衡、熔断、重试等功能。 2. Go控制平面实现 package envoyimport ("api/envoy/api/v2/core""api/envoy…...

从蛋白质分类到社交网络:Graph Pooling在实际项目里到底怎么用?
从蛋白质分类到社交网络:Graph Pooling实战选型指南 在生物信息实验室里,研究员小李正盯着屏幕上错综复杂的蛋白质相互作用网络发愁——如何将这个包含数千个原子的三维结构转化为机器学习模型可处理的表征?与此同时,某社交平台算…...
)
用Python+OpenCV给《梦幻西游》写个自动挖图脚本(附完整代码与避坑指南)
用PythonOpenCV实现《梦幻西游》自动挖宝图的全流程实战 最近在技术社区看到不少关于游戏自动化的讨论,尤其是像《梦幻西游》这类经典MMORPG,很多开发者尝试用计算机视觉技术实现自动化操作。作为一个长期关注OpenCV应用的开发者,我花了三周…...

Apache Atlas UI实战:从数据资产发现到血缘追溯的完整操作指南
1. Apache Atlas入门:数据治理的瑞士军刀 第一次接触Apache Atlas时,我正被公司混乱的数据资产搞得焦头烂额。报表数据频繁出错却找不到源头,新来的同事总在问"这个字段是什么意思",业务部门抱怨找不到他们需要的数据..…...

Windows Cleaner:如何系统性地解决Windows磁盘空间管理难题
Windows Cleaner:如何系统性地解决Windows磁盘空间管理难题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款基于Python和PyQt5框…...

本地部署YakGPT:打造私有化ChatGPT前端,实现语音交互与数据安全
1. 项目概述:为什么我们需要一个本地运行的ChatGPT UI? 如果你和我一样,已经深度依赖ChatGPT来处理日常工作,从代码调试到文案构思,那你肯定也经历过官方网页端那令人捉急的加载速度,或者在移动端上打字的…...

C++异步日志系统
文章目录异步日志系统1. 项目背景2. 设计思路2.1 核心架构2.2 关键技术点3. 实现细节3.1 线程安全的日志队列 (LogQueue)3.2 动态格式化与回退机制 (formatMessage)3.3 自动化管理4. 接口说明日志级别 (LogLevel)核心方法5. 使用指南5.1 快速上手5.2 注意事项6. 总结7.Code异步…...