提高接口自动化测试效率:使用 JMESPath 实现断言和数据提取!

前言
做接口自动化,断言是比不可少的。如何快速巧妙的提取断言数据就成了关键,当然也可以提高用例的编写效率。笔者在工作中接触到了JMESPath,那到底该如何使用呢?带着疑惑一起往下看。
JMESPath是啥?
JMESPath 是一种用于查询和转换 JSON 数据的简洁、强大的查询语言。它提供了一种灵活的方式来从复杂的 JSON 结构中提取所需的数据,并支持各种操作和函数,以满足不同的查询需求。
JMESPath如何使用?
在使用 JMESPath 查询 JSON 数据之前,我们需要安装 jmespath 库。安装命令如下:
pip install jmespath简单路径表达式
假设我们有以下的 JSON 数据:
data = {"name": "Alice","age": 25,"email": "alice@example.com"
}
我们想要从中提取"name"属性的值。使用 JMESPath,我们可以编写以下代码:
import jmespath
expression = "name"
result = jmespath.search(expression, data)
print(result) # 输出:Alice这里,我们定义了一个路径表达式"name",然后使用jmespath.search()函数将该表达式应用于数据data上。结果会被存储在result变量中,并输出为"Alice"。
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036
嵌套属性访问
当 JSON 数据具有嵌套结构时,可以使用点号 . 连接多个属性名来表示深层的属性访问。考虑以下 JSON 数据:
data = {"person": {"name": "Alice","age": 25,"email": "alice@example.com"}
}
我们要提取"name"属性,可以使用以下路径表达式:
expression = "person.name"
result = jmespath.search(expression, data)
print(result) # 输出:Alice
这里,我们将属性名 "person" 和 "name" 使用点号 . 连接起来,表示深层的属性访问。
复杂嵌套查询
假设我们有一个包含学生信息和他们的课程成绩的更复杂的 JSON 数据,如下所示:
data = {"students": [{"name": "Alice","courses": [{"name": "Math", "score": 95},{"name": "English", "score": 88}]},{"name": "Bob","courses": [{"name": "Math", "score": 75},{"name": "English", "score": 92}]}]
}
现在,假设我们想要获取每个学生的数学成绩。可以通过以下表达式实现:
expression = "students[].courses[?name == 'Math'].score"
再次执行查询并打印结果:
result = jmespath.search(expression, data)
print(result)输出结果将是一个包含每个学生数学成绩的列表:
[[95], [75]]列表索引
对于 JSON 中的列表属性,可以使用方括号 [index] 来指定索引位置来检索数据。假设我们有以下 JSON 数据:
data = {"fruits": ["apple", "banana", "cherry"]
}我们想要提取第二个元素,即"banana"。可以使用以下路径表达式:
expression = "fruits[1]"
result = jmespath.search(expression, data)
print(result) # 输出:banana
这里,我们使用方括号 [1] 来指定索引位置,表示提取第二个元素。
过滤器
JMESPath 提供了过滤器功能,使我们能够根据特定条件筛选出符合要求的数据。过滤器使用方括号 [?],后跟过滤条件。考虑以下 JSON 数据:
data = {"users": [{"name": "Alice", "age": 25},{"name": "Bob", "age": 30},{"name": "Charlie", "age": 28}]
}
我们想要提取年龄大于 25 岁的用户对象。可以使用以下路径表达式进行过滤:
expression = "users[?age > `25`]"
result = jmespath.search(expression, data)
print(result)输出结果为:
[ {"name": "Bob", "age": 30}, {"name": "Charlie", "age": 28}]这里,我们使用了过滤器 [?age > 25],表示只选择满足条件的用户对象。
合并操作
JMESPath 还支持合并操作符 [],用于将多个查询结果合并成一个列表。假设我们想要获取所有学生的所有课程名称。可以使用合并操作符 [] 来实现:
data = {"students": [{"name": "Alice","courses": [{"name": "Math", "score": 95},{"name": "English", "score": 88}]},{"name": "Bob","courses": [{"name": "Math", "score": 75},{"name": "English", "score": 92}]}]
}
获取所有学生的所有课程名称:
expression = "students[].courses[].name"
result = jmespath.search(expression, data)
print(result)
输出结果为:
['Math', 'English', 'Math', 'English']排序和切片
JMESPath 还支持对查询结果进行排序和切片操作。假设我们想要按学生年龄进行降序排序。可以使用排序函数 sort() 和逆序函数 reverse() 来实现:
data = {"students": [{"name": "Alice", "age": 20},{"name": "Bob", "age": 22},{"name": "Charlie", "age": 21}]
}得到按年龄降序排列的学生列表:
expression = "students | sort_by(@, &age) | reverse(@)"
result = jmespath.search(expression, data)
print(result) # [{'name': 'Bob', 'age': 22}, {'name': 'Charlie', 'age': 21}, {'name': 'Alice', 'age': 20}]切片
data = {"fruits": ["apple", "banana", "cherry"]
}
利用切片获取第一个元素
import jmespath
data = {"fruits": ["apple", "banana", "cherry"]
}
expression = "fruits[0:1]"
result = jmespath.search(expression, data)
print(result) # ['apple']管道
使用管道符号(|),将当前节点的结果传到管道符右侧继续投影。
data = {"students": [{"name": "Alice", "age": 20},{"name": "Bob", "age": 22},{"name": "Charlie", "age": 21}]
}获取所有的姓名:
expression = "students[*].name"
result = jmespath.search(expression, data)
print(result) # ['Alice', 'Bob', 'Charlie']如果在此基础上想要得到Bob这个值。我们尝试使用索引:
expression = "students[*].name[1]"
result = jmespath.search(expression, data)
print(result) # []发现执行结果是一个空列表,这个时候怎么办呢?使用管道表达式, <expression> | <expression>
expression = "students[*].name | [1]"内置函数
计算列表长度
data = {"students": [{"name": "Alice", "age": 20},{"name": "Bob", "age": 22},{"name": "Charlie", "age": 21}]
}
expression = "length(students)" # 也可以这样写expression = "students | length(@)"
result = jmespath.search(expression, data)
print(result) # 3length就是jmespath内置的函数。
当然还有一些其他常用的内置函数,比如:
starts_with(str, prefix): 检查字符串是否以指定前缀开头。ends_with(str, suffix): 检查字符串是否以指定后缀结尾。contains(str, substring): 检查字符串是否包含子字符串。length(arr): 返回数组的长度。
最后
jmespath确实很强大,通过逐步学习和实践,可以更好地掌握 JMESPath 的功能和灵活性。
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走!
软件测试面试文档
我们学习必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有字节大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
相关文章:
提高接口自动化测试效率:使用 JMESPath 实现断言和数据提取!
前言 做接口自动化,断言是比不可少的。如何快速巧妙的提取断言数据就成了关键,当然也可以提高用例的编写效率。笔者在工作中接触到了JMESPath,那到底该如何使用呢?带着疑惑一起往下看。 JMESPath是啥? JMESPath 是一…...
【Linux操作系统教程】用户管理与权限管理你真的懂了吗(三)
😄作者简介: 小曾同学.com,一个致力于测试开发的博主⛽️,主要职责:测试开发、CI/CD 如果文章知识点有错误的地方,还请大家指正,让我们一起学习,一起进步。😊 座右铭:不想…...

华为全联接大会2023 | 尚宇亮:携手启动O3社区发布
2023年9月20日,在华为全联接大会2023上,华为正式发布“联接全球服务工程师,聚合用户服务经验”的知识经验平台,以“Online 在线、Open 开放、Orchestration 协同”为理念,由华为、伙伴和客户携手,共同构建知…...

MySQL数据库查缺补漏——基础篇
MySQL数据库查缺补漏-基础篇 基础篇 net start mysql80[服务名] net stop mysql80 create database pshdhx default charset utf8mb4; 为什么不使用utf8?因为其字符占用三个字节,有四个字节的字符,所有需要设置为utf8mb4; 数值类型&…...

ESP8266 WiFi物联网智能插座—电能计量
目录 1、芯片功能 2、性能指标 3、寄存器说明 4、UART通信协议 4.1、写操作帧格式和时序 4.2、读操作帧格式和时序 4.3、读取全电参数数据包 4.4、配置波特率 4.5、UART保护机制 5、功能说明 5.1、电流电压瞬态波形计量 5.2、有功功率 5.3、有功功率防潜动 5.4、电能计量 5.5、…...

“智慧”北京,人工智能引领“新风尚”
原创 | 文 BFT机器人 北京时间,9月15日,北京人工智能产业峰会暨中关村科学城科创大赛颁奖典礼在北京中关村举行,同时惠阳还举行了“中关村人工智能大模型产业集聚区”启动建设的揭牌仪式。 此次大会围绕北京AI产业的建设与发展,各…...

狮子鱼社区团购小程序v18.1独立全开源版+小程序前端
狮子鱼社区团购商城系统小程序V18.1独立开源版,该系统本身就非常完善也没更新的必要,此系统拿来即用非常方便,同一版一样人类小徐特别优化很多细节首页美化了下,如小程序端授权窗口美化了下,该版本用户授权接口正常。功…...

深拷贝和浅拷贝的区别
本文内容 主要阐述下深拷贝和浅拷贝的区别 通俗理解 深拷贝和浅拷贝最根本的区别在于是否真正获取一个对象的复制实体,而不是引用。 假设B复制了A,修改A的时候,看B是否发生变化: 如果B跟着也变了,说明是浅拷贝&…...

利用优化算法提高爬虫任务调度效率
目录 一、任务调度优化的重要性 二、选择合适的优化算法 三、建立任务调度模型 四、设计适应性函数 五、算法实施和调优 六、性能评估和优化结果分析 代码示例 总结 随着网络信息的爆炸式增长,网络爬虫在信息获取和数据挖掘等领域的应用越来越广泛。然而&am…...
Swiper的使用流程
1.官网查看演示 Swiper演示 - Swiper中文网 2.找到想使用的 比如想使用 卡片切换(255) 记住这个名字 3.去下载示例 下载Swiper - Swiper中文网 4.找到对应文件 5.根据里面引入的东西加到自己的页面 一定要引入swiper的 js 和 css html结构要按示例对应的三层结构 需要 …...

如何快速实现一个可视化看板?
一、用python实现一个可视化数据看板,最多支持多大体量的数据处理? Python可以通过多种可视化库来实现数据看板,例如Matplotlib、Seaborn、Plotly等。这些库可以处理各种规模的数据,从小型数据集到大型数据集都可以应用。 对于小型…...

基于PyTorch搭建FasterRCNN实现目标检测
基于PyTorch搭建FasterRCNN实现目标检测 1. 图像分类 vs. 目标检测 图像分类是一个我们为输入图像分配类标签的问题。例如,给定猫的输入图像,图像分类算法的输出是标签“猫”。 在目标检测中,我们不仅对输入图像中存在的对象感兴趣。我们还…...
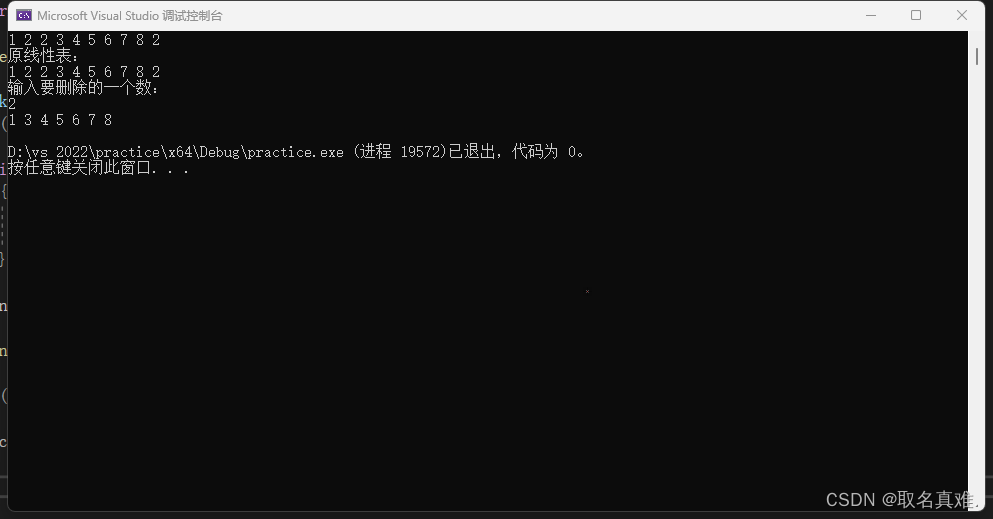
线性表应用(非递减合并、分解链表、删除线性表)
将两个非递减的有序链表合并为一个非递增的有序链表。要求结果链表仍使用原来两个链表的存储空间,不另外占用其它的存储空间。表中允许有重复的数据。 #include<iostream> using namespace std; typedef struct list {int data;list* next; }list,*linklist;…...
【C++面向对象侯捷下】1.导读
文章目录 来源:我的百度网盘 百科全书 专家书籍 C标准库 C编译器...
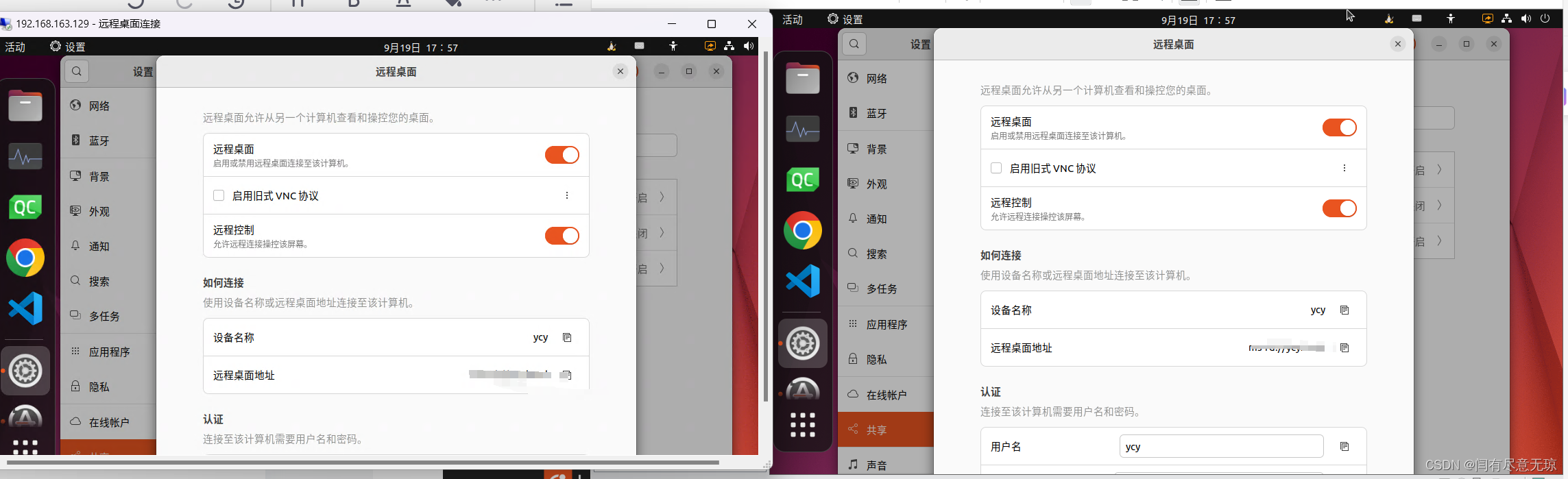
Ubuntu22.04 vnc远程黑屏
一、原因 原因是Ubuntu22.04使用的gnome启用了Wayland。vnc、teamviewer、向日葵、todesk等均无法使用或者远程黑屏等。 简单的说vnc、teamviewer、向日葵、todesk等均基于xorg实现(xorg太流行),并不兼容Wayland,所以vnc无法正常…...

【1区TOP】Elsevier旗下CCF推荐,仅3个月左右录用!
01 期刊简介 CCF推荐人工智能类SCIE&EI 【期刊概况】IF:8.0-9.0,JCR1区,中科院2区TOP; 【版面类型】正刊; 【检索情况】SCIE&EI双检,CCF推荐; 【数据库收录年份】1992年ÿ…...

CentOS下安装Python3
一、电脑有网络: 1、直接使用yum包管理安装: yum是CentOS的默认包管理器,在安装软件时非常方便。要安装Python3,可以使用以下命令: sudo yum install python3等待安装完成后,查看python3是否安装完成 //不…...

微信小程序底部安全区域高度获取
CSS 属性 safe-area-inset-bottom safe-area-inset-bottom 就是安全区的高度 padding-bottom:env(safe-area-inset-bottom); wx.getSystemInfoSync() wx.getSystemInfoSync()可以获取系统信息 let system wx.getSystemInfoSync() let bottomSafe system.screenHeight -…...
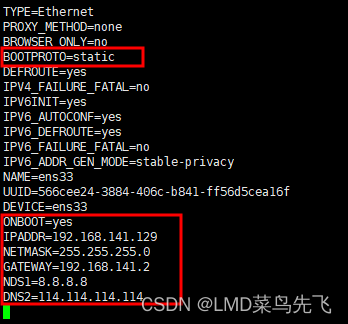
虚拟机部署linux网络连接配置
1、虚拟机安装linux后,配置网络访问 虚拟机网络设置为NAT模式 linux网络配置好IP,主要是以下网络配置 2、linux没有ifconfig命令,ifconfig命令是在net-tools.x86_64包里 yum install net-tools.x86_64安装...
)
2591. 将钱分给最多的儿童(Java)
给你一个整数 money ,表示你总共有的钱数(单位为美元)和另一个整数 children ,表示你要将钱分配给多少个儿童。 你需要按照如下规则分配: 所有的钱都必须被分配。 每个儿童至少获得 1 美元。 没有人获得 4 美元。 请你…...

卫星热真空测试中射频功率测量的关键技术突破
1. 卫星热真空测试中的射频功率测量挑战在卫星研制过程中,热真空测试(TVAC)是验证航天器能否承受太空极端环境的关键环节。测试环境需要模拟太空中的高真空(<510⁻⁶ Torr)和极端温度(-196℃至140℃&…...

Claw Mentor:为OpenClaw智能体实现自动化配置同步与社区化演进
1. 项目概述:为你的AI智能体引入“导师”机制在AI智能体(Agent)开发领域,尤其是基于OpenClaw这类开源框架时,我们常常面临一个困境:如何持续地学习和迭代,跟上领域内最佳实践的发展速度…...

AI助手自我进化框架:异步复盘与技能固化工程实践
1. 项目概述:一个让AI助手学会自我进化的“内功心法”如果你用过Claude、ChatGPT或者国内的一些大模型,肯定有过这样的体验:你跟它聊得挺好,让它帮你写个代码、分析个文档,它都能干。但聊着聊着,你发现它好…...

别再只会用默认蓝色了!MATLAB scatter函数调色全攻略,从单色到渐变一次搞定
MATLAB散点图色彩艺术:从基础调色到数据驱动的视觉叙事 科研图表的美学价值往往被低估——直到你看到那些配色糟糕的论文插图。MATLAB的scatter函数远不止是绘制点集的工具,当掌握其色彩控制逻辑后,它能成为数据故事讲述的视觉利器。本文将彻…...

实战指南:深度解析N_m3u8DL-RE如何高效破解流媒体下载三大技术难题
实战指南:深度解析N_m3u8DL-RE如何高效破解流媒体下载三大技术难题 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_…...

Ubuntu 18.04上Qt程序报‘xcb’插件错误?别急着重装,试试这个ldd排查法
Ubuntu 18.04 Qt程序xcb插件错误排查指南:从日志分析到依赖修复 当你满怀期待地在Ubuntu 18.04上启动精心开发的Qt应用程序时,屏幕上突然跳出"Could not load the Qt platform plugin xcb"的错误提示,这种挫败感开发者都深有体会。…...
)
SITS 2026议程背后隐藏的3条技术演进红线(附Gartner/IEEE双认证时间轴对比图)
更多请点击: https://intelliparadigm.com 第一章:2026奇点智能技术大会完整议程曝光:SITS 2026四大看点抢先看 全球瞩目的奇点智能技术大会(Singularity Intelligence Technology Summit, SITS)将于2026年5月12–15日…...

野火IM 1.4.7版本发布:新增多项Server API接口,附多版本升级注意事项
野火IM 1.4.7:新增接口拓展功能边界野火IM 1.4.7版本正式发布,带来了一系列功能更新。新增了获取所有机器人的Server API接口、获取某个电话号码的用户列表的Server API接口,还为机器人添加了根据邮箱获取用户信息和批量获取用户信息的接口。…...

【独家首发】SITS2026现场网络压力测试原始数据曝光:127台AI终端并发接入下AP吞吐衰减曲线与信道冲突热力图
更多请点击: https://intelliparadigm.com 第一章:AI技术大会现场网络服务:SITS2026 在 SITS2026(Smart Infrastructure & Trusted Systems 2026)AI技术大会现场,主办方部署了基于 eBPF Kubernetes 的…...

解锁老旧Mac的终极秘籍:OpenCore Legacy Patcher让2008-2017款设备焕发新生
解锁老旧Mac的终极秘籍:OpenCore Legacy Patcher让2008-2017款设备焕发新生 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否正为手中的老旧…...