mysql优化之索引
索引官方定义:索引是帮助mysql高效获取数据的数据结构。
索引的目的在于提高查询效率,可以类比字典。
可以简单理解为:排好序的快速查找数据结构
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这种数据结构以某种方式(引用)指向数据。
这样就可以在这些数据结构的基础上实现高级查找算法,这种数据结构就是索引。
例如将id加索引,在mysql数据库里开辟一块存储空间来存放索引数据,查询的时候如果根据id去查询,就要走这个索引库,在索引库找到之后,就能定位这条数据,因为索引库的每一项和数据库的物理地址是绑定的,你能找到这条索引,就能找到这条数据所对应的物理地址,就可以直接获取这条数据。
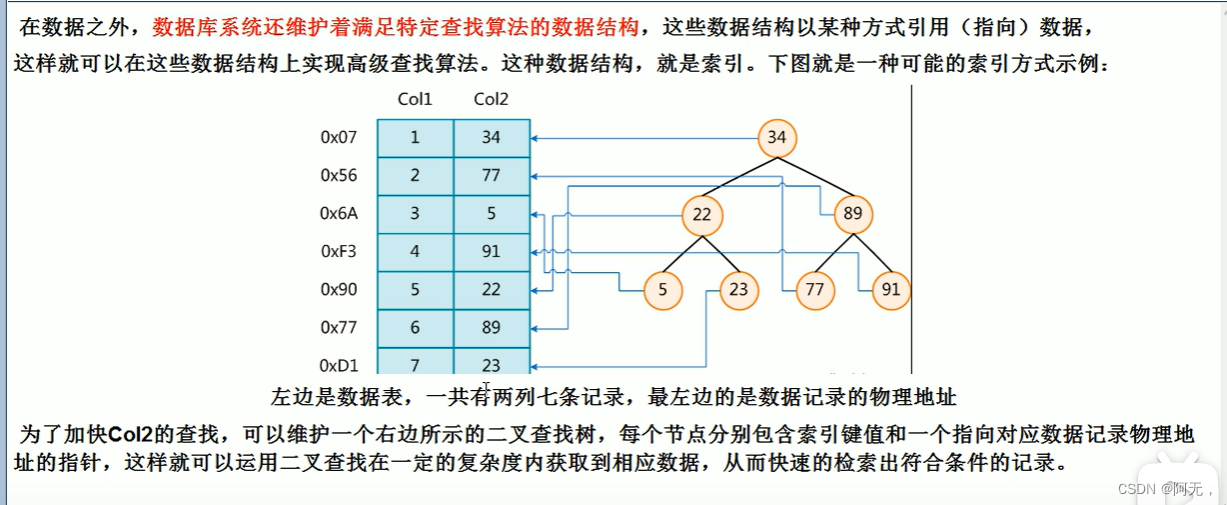
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
索引结构
我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,并不一定是二叉的)结构组织的索引。
其中聚集索引,次要索引,覆盖索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。
当然,除了B+树这种类型的索引外,还有哈希索引等。
BTree索引、hash索引、full-text全文索引、R-Tree索引,我们只关注BTree索引
BTree索引检索原理
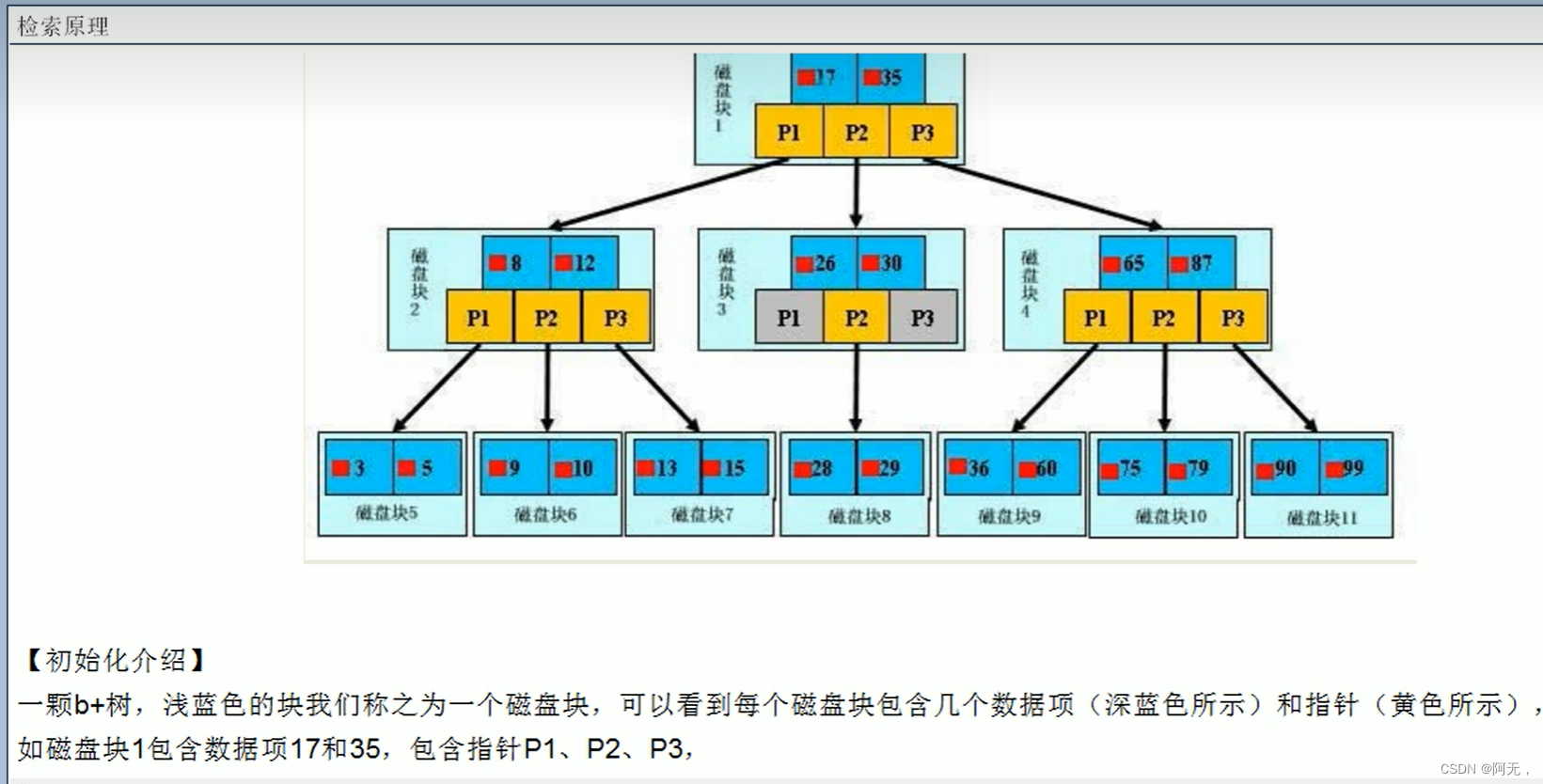

索引数据为什么快?
- 索引数据存放是有规则的,顺序的,
- 查询的时候是有些算法的,例如最简单的折半
例如索引1-26,我们找16,
折半先找13,16比13大,就找13-26的中间值,19,
19比16大,就找13-19的中间值,16,就找着了
如果不使用索引,就是一条条找,得找16次才能找到
索引的优缺点
- 优点
- 提高数据检索的效率,降低数据库的io成本
- 通过索引列对数据进行排序,降低数据排序的成本,降低了cpu的消耗
- 缺点
-
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。 -
虽然索引大大提高了查询速度,却会降低更新表的速度,如对表进行增删改。
因为更新表时,mysql不仅要保存数据,还要更新添加了索引列的字段,也会调整因为更新所带来的键值变化后的索引信息 -
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
索引只是提高效率的一个因素,如果你的mysql有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询例如我们猜测客户可能会按照这样的字段去查询,就把索引建到这个字段上面,但是后面根据点击率分析和客户所筛选的条件发现,经常查询另一个字段,索引就需要优化和调整。
什么时候需要/不需要创建索引?
需要创建索引
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中排序、统计、分组的字段
- 查询中与其他表关联的字段,外键关系建立字段
不需要创建索引
-
表记录太少
-
更新非常频繁的字段不适合创建索引
除了更新数据本身外还需要更新BTree树,数据量大的话是很耗费资源的。
-
Where条件里用不到的字段不创建索引
-
唯一性太差(字段好多都是同一个值)(在查询的时候会索引失效)的字段不适合单独(可以使用联合索引)创建索引,即使频繁作为查询条件;
索引能够极大的提高数据检索效率,也能够改善排序分组操作的性能,但是我们不能忽略的一个问题就是索引是完全独立于基础数据之外的一部分数据,更新数据会带来的IO量和调整索引所致的计算量的资源消耗。

索引分类
- 单值索引:一个索引只包含一个列,一个表可以有多个单列索引
- 唯一索引:索引列的值必须唯一(身份证号),但允许有空值
- 复合索引:一个索引包含多列
# 创建
CREATE [UNIQUE] INDEX indexName on myTable(columnname(length));
ALTER mytable ADD [UNIQUE] INDEX [indexName] ON (columnname(length));# 删除
DROP INDEX [indexName] ON mytable;# 查看
SHOW INDEX FROM tableName;# 四种方式来添加数据表的索引# 添加一个主键,代表索引值必须是唯一的,且不能为null
ALTER TABLE tbl_name ADD PRIMARY KEY(column_list);# 索引值必须是唯一的(除了null外,null可能会出现多次)
ALTER TABLE tbl_name ADD UNIQUE index_name(column_list);# 添加普通索引,索引值可重复
ALTER TABLE tbl_name ADD INDEX index_name(column_list);# 指定索引为FULLTEXT,用于全文索引
ALTER TABLE tbl_name ADD FULLTEXT index_name(column_list);
性能分析前提知识
mysql query optimizer mysq查询优化器

mysql常见瓶颈

explain 解释,查看sql执行计划

作用
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用(哪些索引被实际使用)
- 表之间的引用
- 每张表有多少行被优化器查询
使用
mysql> explain select * from tbl_emp;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+
| 1 | SIMPLE | tbl_emp | NULL | ALL | NULL | NULL | NULL | NULL | 8 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)# id(表的读取顺序)
# select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序。
# id相同,执行顺序由上至下(就是说先加载的是tbl_dept表)
# 执行顺序和sql的编写顺序有没有关系暂时未知,测试的话是没有关系的
# id越大越先被执行,(如果是子查询,id的序号会递增)
# id有相同有不同
# 在一个sql语句中,id既有相同的,也有不同的
# id相同,顺序执行,id越大越先被执行
# 出现这种情况实际上就是有一张虚表,就是查出一张表来给它取个别名,但是我和老师的sql一模一样就是结果不一样,有时间再看这个吧
mysql> explain select * from tbl_emp te, tbl_dept td where te.deptId=td.id;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | td | NULL | ALL | PRIMARY | NULL | NULL | NULL | 5 | 100.00 | NULL |
| 1 | SIMPLE | te | NULL | ALL | fk_dept_id | NULL | NULL | NULL | 8 | 20.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)mysql> explain select * from tbl_dept where id=(select deptId from tbl_emp where id=1);
+----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | PRIMARY | tbl_dept | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
| 2 | SUBQUERY | tbl_emp | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+----------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
2 rows in set, 1 warning (0.00 sec)# select_type,表示select_type语句的类型(数据读取操作的操作类型)
# simple,表示简单查询,其中不包含连接查询和子查询
# primary,表示主查询,或者是最外面的查询语句(最后加载的那个)
# subquery,在select或where列表中包含了子查询
# derived,from列表包含的子查询,mysql会递归执行这些子查询,把结果放在临时表里。
# union,若第二个select出现在union之后,则被标记为union;
# 若union包含在from子句的子查询中,外层select将被标记为derived
# union result 从union表获取结果的select# type,访问类型,显示查询使用了何种类型
# 从最好到最差依次是(以下是常见的,除此之外还有很多种):
# 一般来说,得保证查询至少打到range级别,最好能达到ref
# system > const > eq_ref > ref > range > index > all
# system 表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不记# const 表示通过索引一次就找到了,const用于比较primary key或者unique索引。
# 因为只匹配一行数据,所以很快
# 如将主键置于where列表中,mysql就能将该查询转换为一个常量。# eq_ref 唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
# 例如两表连接,对外键设置索引,此时两表连接查询只查询到一条记录
# 例如员工表和部门表,而此时查的部门是ceo办公室,自然就只有一条记录
#简单地说是const是直接按主键或惟一键读取,eq_ref用于联表查询的状况,按联表的主键或惟一键联合查询。# ref 非唯一性索引扫描,返回匹配某个单独值的所有行。# range 只检索给定范围的行,使用一个索引来选择行
# 例如在where语句中出现between、<、>、in等的查询
# 这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。# index 与all区别为index类型只遍历索引树。这通常比all快,因为索引文件通常比数据文件小。# all 全表扫描# possible_keys
# 显示可能应用在这张表中的索引,一个或多个。
# 查询涉及到字段上若存在索引,则该索引将被列出,但不一定被查询实际使用# key
# 实际使用的索引。如果为null,则没有使用索引
# 查询中若使用了覆盖索引,则该索引仅出现在key列表中
# 覆盖索引:sql语句中查询的字段和复合索引的字段、顺序都一致# key_len
# 表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好
# 精度的意思是,where后跟一个条件,索引长度肯定更小,但是精度也更小
# 如果再跟一个条件,索引长度大了,但是精度肯定高了
# key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的# ref
# 显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
# 这句话的意思是,如果那一列where后面的条件值是个常量的话就显示 const,否则就是列名# rows
# 根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数# filtered
# 存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例
# 只做参考,不需要刻意关注
extra 包含不适合在其他列中显示但十分重要的额外信息
# using filesort(不好,尽量消除)
# 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序读取
# mysql中无法利用索引完成的排序操作称为 文件排序
# 大概意思就是我们自己建立的索引因为一些原因没有或部分使用到,mysql内部自己又建立了一个索引
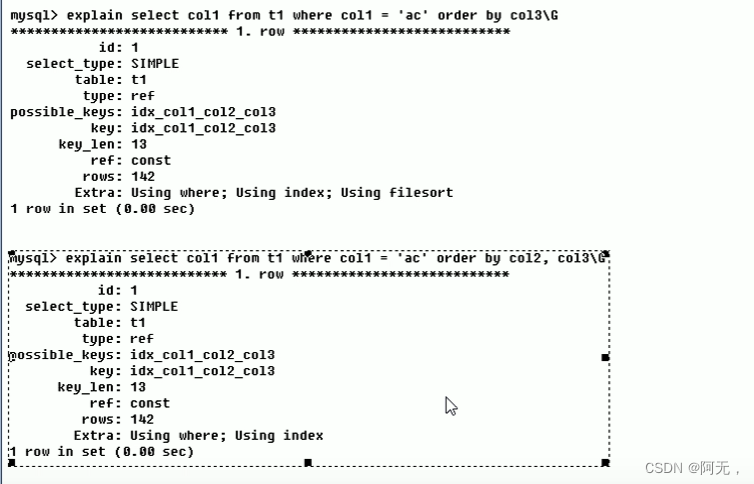
以上实例,索引的顺序如果和查询排序的字段一致的话,就不会出现 using filesort,效率就更高,反之则效率更低
# Using temporary(不好,尽量消除)
# 使用临时表保存中间结果,mysql在对查询结果排序时使用临时表。
# 常见于 order by 和 group by
# 会加大空间的占用,影响效率
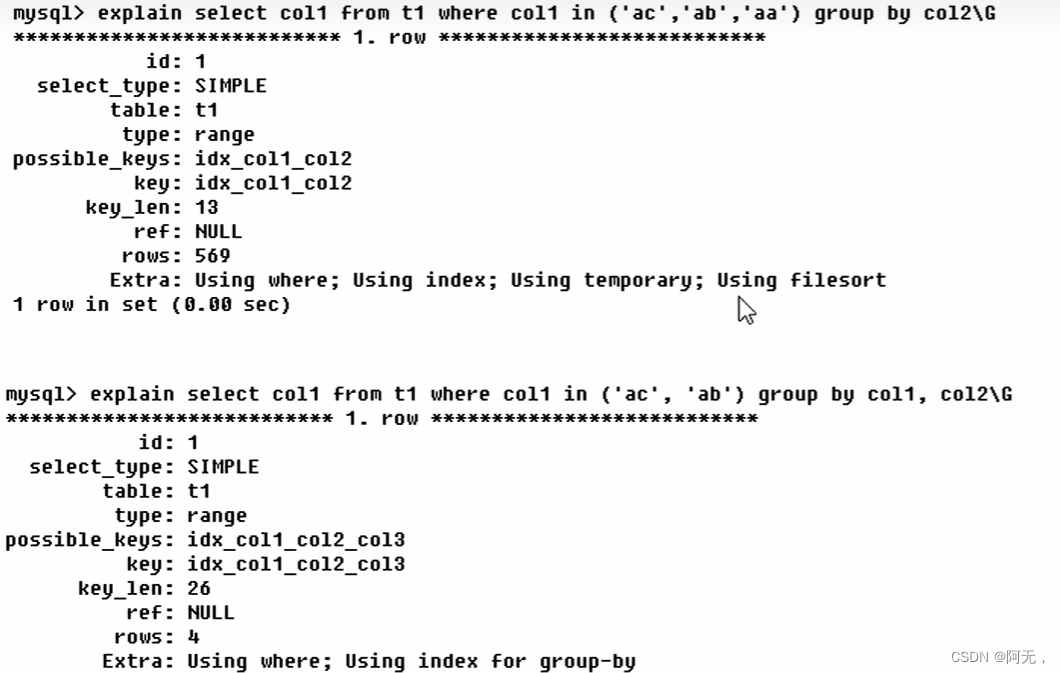
# using index
# 表示相应的select操作中使用了覆盖索引,避免访问了表的数据行,效率不错!
# 如果同时出现using where,表明索引被用来执行索引键值的查找
# 如果没有同时出现using where,表明索引用来读取数据而非执行查找动作# using where
# 使用了where过滤# using join buffer
# 使用了连接缓存
# join使用过多,可以把配置文件的缓冲区调大
# # impossible where
# where子句的值总是false,不能用来获取任何元组
# 例如 where name='zs' and name = 'ls'
# 一个人是不会有两个名字的
using filesort,using temporary, using index是重点,其他了解即可
demo


单表优化案例
/*
UNSIGNEDunsigned(无符号)是一种数据类型的修饰符。它可以用于整型数据类型,例如INT、BIGINT等。在无符号的二进制表示中,数据类型将仅仅包含非负整数。使用unsigned的主要好处是它可以在不改变数据类型的前提下,增加数据类型所能存储的最大值。例如,INTUNSIGNED的最大值为4294967295,而INT的最大值仅为2147483647。这可以极大地提高存储空间的利用率,并且可以避免使用较大的数据类型来存储小的非负整数。*/show tables;
CREATE TABLE if NOT EXISTS article(id INT(10) UNSIGNED NOT NULL PRIMARY KEY auto_increment,author_id int(10) UNSIGNED NOT NULL,category_id int(10) UNSIGNED NOT NULL,views int(10) UNSIGNED NOT NULL,comments int(10) UNSIGNED NOT NULL,title VARBINARY(255) NOT NULL,content text NOT NULL)INSERT INTO article(`author_id`,`category_id`,`views`,`comments`,`title`,`content`) VALUES (1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(3,3,3,3,'3','3')# 查询category_id为1且comments大于1的情况下,views最多的article_id
mysql> explain select id,author_id from article where category_id = 1 and comments>1 order by views desc limit 1;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | article | NULL | ALL | NULL | NULL | NULL | NULL | 4 | 25.00 | Using where; Using filesort |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)# 很显然,type all和Using filesort 都是最坏的情况,必须优化# 一眼看到这个题是应该创建category_id,comments,views的符合索引
# 索引确实被用到了,但是文件排序依然存在
# 原因是因为 > 会导致索引失效,使索引断了# 那我们就跳过它,只为其他两个字段建立复合索引
mysql> create index category_views on article (category_id,views);mysql> explain select id,author_id from article where category_id = 1 and comments=1 order by views desc limit 1;
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | article | NULL | ref | category_views | category_views | 4 | const | 2 | 25.00 | Using where |
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)这个说的是建立三个字段的索引的情况

正如丘吉尔所说,世界上没有永远的朋友,也没有永远的敌人,只有永恒的利益。
鬼吹灯
天下霸唱
部分知识引用自:
https://www.bilibili.com/video/BV1KW411u7vy/?p=5&spm_id_from=pageDriver&vd_source=64c73c596c59837e620fed47fa27ada7
相关文章:
mysql优化之索引
索引官方定义:索引是帮助mysql高效获取数据的数据结构。 索引的目的在于提高查询效率,可以类比字典。 可以简单理解为:排好序的快速查找数据结构 在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这种数据…...
文件系统详解
目录 文件系统(1) 第一节文件系统的基本概念 一、文件系统的任务 二、文件的存储介质及存储方式 三、文件的分类 第二节 文件的逻辑结构和物理结构 一、文件的逻辑结构 二、文件的物理结构 文件系统(2) 第三节 文件目…...

有名管道及其应用
创建FIFO文件 1.通过命令: mkfifo 文件名 2.通过函数: mkfifo #include <sys/types.h> #include <sys/stat.h> int mkfifo(const char *pathname, mode_t mode); 参数: -pathname:管道名称的路径 -mode:文件的权限&a…...

加州大学伯克利分校 计算机科学专业
加州大学伯克利分校 计算机科学专业 cs 61a cs 61b cs61c...
一个关于 i++ 和 ++i 的面试题打趴了所有人
前言 都说大城市现在不好找工作,可小城市却也不好招人。 我们公司招了挺久都没招到,主管感到有些心累。 我提了点建议,是不是面试问的太深了,在这种小城市,能干活就行。 他说自己问的面试题都很浅显,如果答…...

程序员的快乐如此简单
最近在GitHub上发起了一个关于Beego框架的小插件的开源仓库,这一举动虽然看似微小,但其中的快乐和意义却是无法用言语表达的。 Beego是一个开源的Go语言Web框架,它采用了MVC架构模式,并集成了很多常用的功能和中间件。小插件是指…...

浅谈云原生Cloud Native
目录 1.云原生是什么2.云原生与传统软件有什么区别3.云原生有哪些代表性的技术 1.云原生是什么 云原生(Cloud Native)是一种构建和运行应用程序的方法,可以充分利用云计算模型的优势。云原生是一种面向服务的架构(SOA)…...
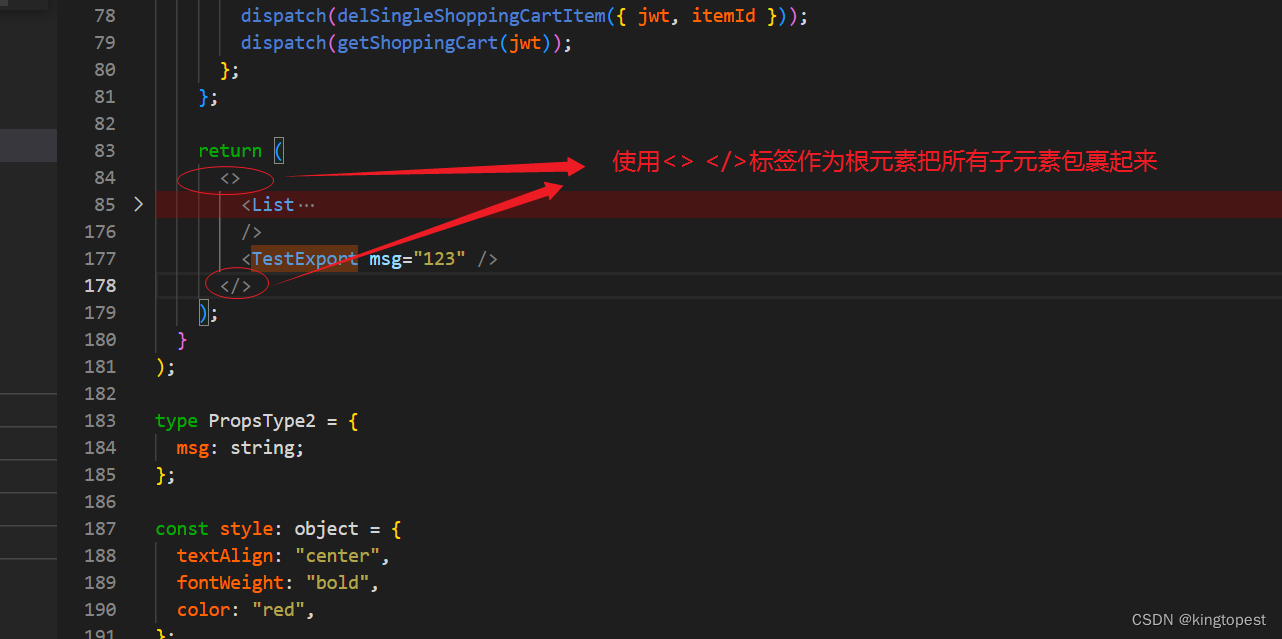
解决react报错“JSX 表达式必须具有一个父元素“
现象如下: 原因: 新插入的dom元素跟已有的dom元素平级了,必须创建一个共有的根元素 解决办法: 使用<> </>标签作为根元素,把所有子元素包裹起来 <> ....原代码 </> 问题解决!…...

Spring学习笔记7 Bean的生命周期
Spring学习笔记6 Bean的实例化方式_biubiubiu0706的博客-CSDN博客 Spring其实就是一个管理Bean对象的工厂.它负责对象的创建,对象的销毁. 这样我们才可以知道在哪个时间节点上调用了哪个类的哪个方法,知道代码该写在哪里 Bean的生命周期之粗略5步 Bean生命周期的管理可以参考S…...

React 如何导出excel
在现代的Web开发中,数据导出是一个非常常见的需求。而在React应用中,我们经常需要将数据导出为Excel文件,以便用户可以轻松地在本地计算机上查看和编辑。本文将介绍如何在React应用中实现导出Excel文件的功能。 章节一:安装依赖 …...

Texlive2020 for win10 宏包更新
用命令提示符更新texlive的宏包,这个方法非常简单实用 1.以管理员身份打开命令提示符 2.系统自动选择镜像网站 tlmgr option repository ctan 3.更新宏包 tlmgr update --self --all 其中–self参数表示升级tlmgr本身,–all表示升级所有宏包,这样就可以将所有宏包更新了 4.列…...

Ps 在用鼠标滚轮缩放图片时,速度太快?
1.原因 在于安装了第三方鼠标优化软件Mos,它起着对第三方鼠标全局浏览效果的优化,使浏览更加顺滑,而不精确,消除了mac使用第三方鼠标浏览页面时的卡顿问题。这也使得像ps、ai这类软件,在进行页面缩放时,变得…...
基于docker进行Grafana + prometheus实现服务监听
基于docker进行Grafana Prometheus实现服务监听 Grafana安装Prometheus安装Jvm监控配置服务器主机监控(基础cpu,内存,磁盘,网络) Grafana安装 docker pull grafana/grafanamkdir /server/grafanachmod 777 /server/grafanadocker run -d -p…...

模型层及ORM介绍
模型层及ORM介绍 模型层 负责跟数据库之间进行通信 配置MySQL,下载MySQLclient 创建数据库 进入mysql数据库执行create database 数据库名 default charset utf8通常数据库名跟项目名保持一致settings.py里进行数据库的配置修改 DATABASES 配置项的内容&#x…...

QQ邮箱怎么设置SMTP接口服务器?
在现如今信息快速传递的时代,邮件已成为我们工作、学习和生活中必不可少的一部分。而作为每位用户必备的一款邮箱,QQ邮箱一直以其稳定、高效、安全的特点深受大家的青睐。但是你是否觉得每次发邮件都需要打开QQ邮箱网页,进行繁琐的操作很是麻…...
【操作系统笔记四】高速缓存
CPU 高速缓存 存储器的分层结构: 问题:为什么这种存储器层次结构行之有效呢? 衡量 CPU 性能的两个指标: 响应时间(或执行时间):执行一条指令平均时间 吞吐量,就是 1 秒内 CPU 可以…...

uniapp获取openid
要获取用户的openid,需要使用微信小程序的登录API。以下是一个简单的示例代码: // 在page中引入wx-login组件 import wxLogin from /components/wx-loginexport default {components: { wxLogin },data() {return {openid: }},methods: {// wxLogin组件…...

测试工程师面试之设计测试用例
以下的问题答案,仅供参考,如小伙伴们有更好的答案,欢迎大家评论区留言,谢谢大家 测试工程师面试之设计测试用例 1、请说一说简单用户界面登陆过程都需要做哪些分析2、 请对此系统设计测试用例:一个系统,多个…...

html页面仿word文档样式(vue页面也适用)
目录 文章title: 标题: 正文: 完整代码: 页面效果: 文章title: <div><h3 style"display: flex;justify-content: center; align-items: center; color: #000;">实验室招新报名公…...

如何在控制台打印sql语句
步骤一: log4j2.xml中做以下配置 <logger name"xxx.infrastructure.mysql.mapper"level"debug" additivity"false"><appender-ref ref"Console"/></logger>步骤二:IDEA下载Free Mybatis Plu…...

Ecqlipse32:车规级嵌入式LCD显示驱动框架
1. 项目概述Ecqlipse32 是一款专为大众汽车集团 CARIAD 车载信息娱乐系统(IVI)平台定制开发的嵌入式 TFT-LCD 显示驱动框架,面向基于 ARM Cortex-M 系列微控制器(特别是 STM32H7 和 NXP i.MX RT117x 等高性能 MCU)的车…...
)
新质生产力水平测算(版本3,2010-2023年)
1、搜数据皮皮侠,编号14172、使用兑换码0447220m6ZHB006826sU14Vv数据来源《中国统计年鉴》、《中国能源统计年鉴》、《中国工业统计年鉴》、《中国环境统计年鉴》、能源统计局、省级统计年鉴。时间跨度2010-2023年区域跨度全国31个省市自治区(不含港澳台…...

在 AWS 私有环境中使用 Terraform 设置 Pypi 镜像
原文:towardsdatascience.com/set-up-a-pypi-mirror-in-an-aws-private-environment-with-terraform-f0fcc1b67cc0?sourcecollection_archive---------7-----------------------#2024-03-06 https://medium.com/florentpajot?sourcepost_page---byline--f0fcc1b67…...
)
避坑指南:SAP冲销原因配置常见错误及解决方案(附SPRO操作截图)
SAP FI模块冲销原因配置实战避坑指南 刚接触SAP FI模块的财务顾问们,在配置冲销原因时往往会遇到各种"坑"。这些看似简单的后台配置,一旦出错可能导致整个月结流程卡壳。本文将结合真实项目案例,带你避开那些教科书上不会写的配置陷…...

HagiCode Soul 平台技术解析:从需求萌发到独立平台的演进之路狼
1 安装与初始化 # 全局安装 OpenSpec npm install -g fission-ai/openspeclatest # 在项目目录下初始化 cd /path/to/your-project openspec init 初始化时,OpenSpec 会提示你选择使用的 AI 工具(Claude Code、Cursor、Trae、Qoder 等)。 3 O…...

Cross Q: Enhancing Deep Reinforcement Learning with Batch Normalization and Wide Critic Networks for
1. 深度强化学习的样本效率困境 深度强化学习(Deep Reinforcement Learning, DRL)近年来在游戏AI、机器人控制等领域取得了显著进展,但样本效率(Sample Efficiency)问题始终是制约其实际应用的瓶颈。简单来说ÿ…...
)
告别Excel!用QT的QTableWidget打造你的第一个桌面端数据管理工具(附完整源码)
从Excel到专业桌面应用:基于QT的QTableWidget数据管理系统实战 在数据处理领域,Excel长期占据主导地位,但当数据量增长到数千行、需要复杂业务逻辑或多人协作时,电子表格的局限性就暴露无遗。许多开发者都面临过这样的困境&#x…...

filezilla求助
求助各位,filezilla一直这样连接不上,之前是连接成功之后就超时,按网上说的关了防火墙,把设置改为主动,然后禁用超时,就一直这样了,我们老师的源代码和交作业都要用ftp,真没办法了...

C#的[DoesNotReturn]和[DoesNotReturnIf]:帮助流分析的特性
C#的[DoesNotReturn]和[DoesNotReturnIf]特性是编译器流分析的重要工具,它们通过显式标记方法或代码块的终止行为,帮助开发者编写更安全、更高效的代码。这些特性在异常处理、条件终止等场景中尤为实用,能够显著提升代码的可读性和静态分析的…...

毕业论文开挂指南:好写作AI助你实现学术写作“降维打击”
写论文这件事,你需要的不是更拼命的自己,而是一套颠覆认知的思维加速器 深夜的自习室,你面前的Word文档还停留在那行刺眼的光标,而这已经是你刷的第三个整晚了。论文进度:0字。 你开始怀疑人生:明明看了那…...