一文读懂 Redis 缓存系统
【摘要】本文介绍了Redis缓存原理、详细解析了缓存模型、缓存一致性和缓存异常场景。
【作者】李杰,专注于Java虚拟机技术、云原生技术领域的探索与研究。
尽管(关系型)数据库系统 (SQL) 带来了许多出色的属性,例如 ACID,但为了保持这些属性,数据库的性能在“ 3 高” 条件环境下下往往显得捉襟见肘、苍白无力 。
为了解决这个问题,我们往往需要在应用层(即处理业务逻辑的后端代码)和存储层(即 SQL 数据库)之间增加一个缓存层。该缓存层通常使用内存缓存来实现,毕竟,传统 SQL 数据库的性能瓶颈通常发生在二级存储(即硬盘)的 I/O 层面。随着主内存 (RAM) 的价格在过去十年中下降,故将(至少部分)数据存储在主内存中以提高性能便是一种性价比较高的解决方案。基于当前的技术发展现状,Redis 便成为当下一种较为流行的选择。
当然,大多数系统只将所谓的“热数据”存储在缓存层(即主内存)中。基于帕累托原理(也称为 80/20 法则),对于大多数事件,大约 80% 的影响来自 20% 的原因。为了节省成本,我们只需要将这 20% 存储在缓存层中。为了识别“热数据”,我们可以指定驱逐策略(例如 LFU 或 LRU )来确定哪些数据将过期。
缓存概述
缓存是一种“预热”技术,用于将经常访问的数据存储在临时存储器(称为缓存)中,以减少硬盘驱动器的读/写。缓存无处不在,基于此技术可以大大地提高 Web 应用程序的性能。
通常,在最初的单体架构模型,当用户向我们的服务发送一个消息请求时,Web 服务器首先会读取或写入数据库再返回响应。在缓存的情况下,服务器首先检查缓存副本是否存在,如果存在则从缓存返回数据而不是询问数据库。它节省了时间和数据库的计算工作量。
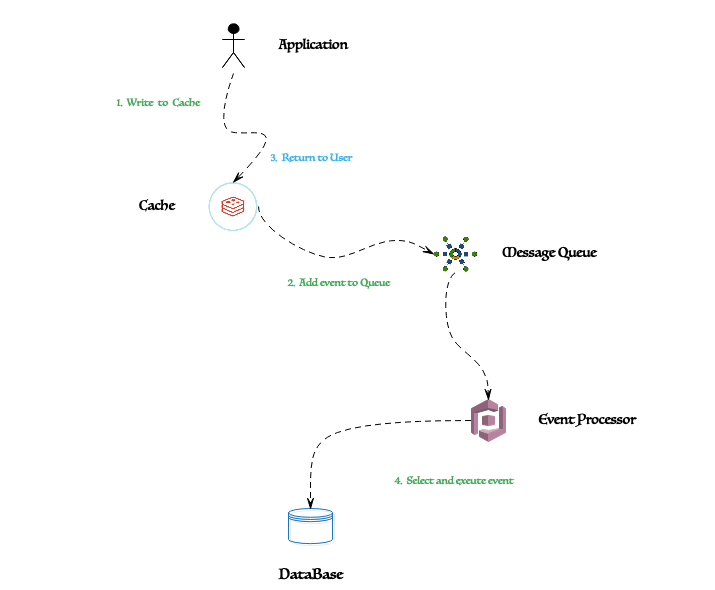
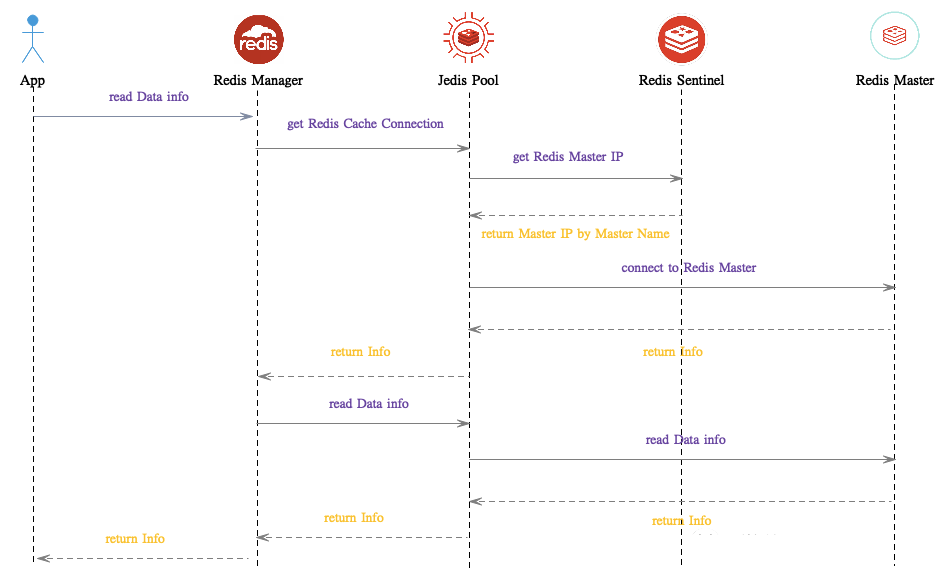
下面简要介绍一下应用程序如何请求 Redis ,此处主要基于 Master-Slave-Sentinel 模式的集群,App 通过调用 Redis Client ,例如,Jedis、Lettuce 及 Redisson 等来与 Redis Sentinel 通信,当 Redis Master 切换至 Slave 时,Application 依旧能够正常工作,如下为详细的时序图:
缓存模型
在分布式系统中,基于 CAP 定理指导,根据业务需求和上下文选择这些策略,通常可将其划分为常规模式和 Cache-Aside 模式。在开始之前,让我们通过刷新缓存的方式来了解常用的缓存模式,具体如下所 示:
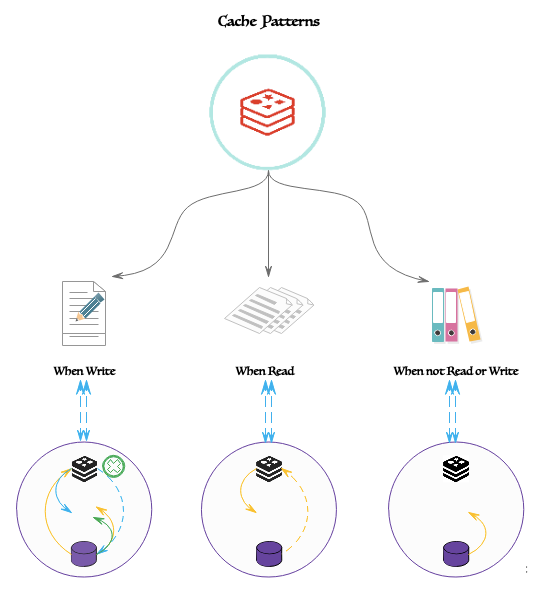
写模型
1、Write Through:即“直写”。此模型为同步写入数据库后再缓存。这是安全的,因为它首先写入数据库,但比后写慢。与写无效相比,它为先写后读场景提供了更好的性能。在这种写入策略中,数据首先写入缓存,然后写入数据库。缓存与数据库串联,写入总是通过缓存到主数据库。
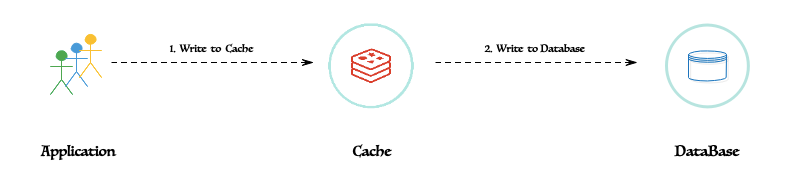
直写模式的算法是:
1)对于不可变操作(读取):
此策略不处理不可变操作。它应该与通读模式相结合。
2)对于可变操作(创建、更新、删除):
客户端只需要在 Redis 中创建、更新或删除条目。缓存层必须以原子方式将此更改同步到 MySQL。
直写模式的缺点也很明显。首先,许多缓存层本身并不支持这一点。其次,Redis 是缓存而不是 RDBMS。它的设计并非具有弹性。因此,更改在复制到 MySQL 之前可能会丢失。即使 Redis 现在已经支持 RDB 和 AOF 等持久化技术,但仍然不推荐这种方式。
就其本身而言,直写缓存似乎没有太大作用,实际上,它们会引入额外的写入延迟,因为数据先写入缓存,然后再写入主数据库。但是当与通读缓存配对时,我们可以获得通读的所有好处,并且我们还可以获得数据一致性保证,使我们免于使用缓存失效技术。
DynamoDB Accelerator (DAX) 是读取/写入缓存的一个很好的例子。它与 DynamoDB 和应用程序内联。可以通过 DAX 对 DynamoDB 进行读取和写入。
2、Write Behind:即“后写或回写”。基于此策略 ,应用程序将数据写入缓存,缓存会立即确认,并在延迟一段时间后将数据写回数据库 。这对于写入速度非常快,如果将同一键上的多个写入合并为一次对数据库的写入,则速度会更快。但是数据库长时间与缓存不一致,如果在数据刷新到数据库之前进程崩溃,可能会丢失数据。RAID 卡是这种模式的一个很好的例子,为了避免数据丢失,通常需要 RAID 卡上的电池备份单元将数据保存在缓存中,但尚未登陆到磁盘。

Write Behind 模式的算法是:
1)对于不可变操作(读取):
此策略不处理不可变操作。它应该与通读模式相结合。
2)对于可变操作(创建、更新、删除):
客户端只需要在 Redis 中创建、更新或删除条目。缓存层将更改保存到消息队列中并向客户端返回成功。更改会异步复制到 MySQL,并且可能在 Redis 向客户端发送成功响应后发生。
后写模式与直写不同,因为它异步地将更改复制到 MySQL。它提高了吞吐量,因为客户端不必等待复制发生。具有高持久性的消息队列可能是一种可能的实现。Redis 流(自 Redis 5.0 起受支持)可能是一个不错的选择。为了进一步提高性能,可以结合更改并批量更新 MySQL(以节省查询次数)。
Write Behind 模式的缺点是相似的。首先,许多缓存层本身并不支持这一点。其次,使用的消息队列必须是 FIFO(先进先出)。否则,对 MySQL 的更新可能会乱序,因此最终结果可能不正确。
回写缓存提高了写入性能,适用于写入繁重的工作负载。与通读结合使用时,它适用于混合工作负载,其中最近更新和访问的数据始终在缓存中可用。
它对数据库故障具有弹性,并且可以容忍一些数据库停机时间。如果支持批处理或合并,它可以减少对数据库的总体写入,从而减少负载并降低成本,如果数据库提供程序按请求数量收费,例如动态数据库。请记住,DAX 是直写的,因此如果应用程序写入繁重,则不会看到任何成本降低。
一些开发人员将 Redis 用于缓存和回写,以更好地吸收峰值负载期间的峰值。主要缺点是如果缓存失败,数据可能会永久丢失。
大多数关系数据库存储引擎(即 InnoDB)在其内部默认启用回写缓存。查询首先写入内存并最终刷新到磁盘。
3、Write invalidate:类似于直写,先写入数据库,然后使缓存无效。在并发更新的情况下,这简化了缓存和数据库之间的一致性处理。我们不需要复杂的同步,权衡是命中率较低,因为我们总是使缓存无效并且下一次读取将始终未命中。
读模型
Read Through:即“ 通读 ”。当读取未命中时,需要从数据库中加载并保存到缓存中。这种模式的主要问题是基于某些特定的场景有时需要预热缓存。通读缓存与数据库保持一致。当缓存未命中时,它会从数据库中加载丢失的数据,填充缓存并将其返回给应用程序。
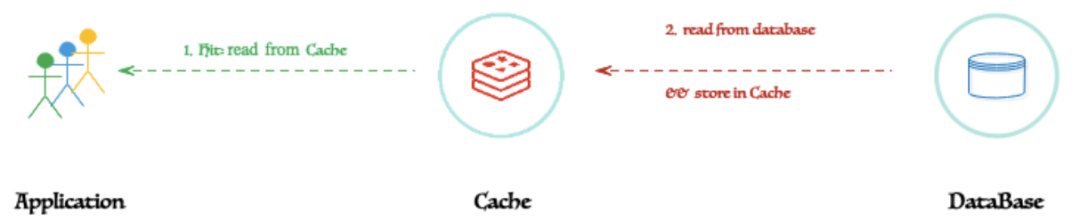
通读模式的算法是:
1、对于不可变操作(读取):
客户端将始终简单地从缓存中读取。缓存命中或缓存未命中对客户端是透明的。如果是缓存未命中,缓存应该具有自动从数据库中获取的能力。
2、对于可变操作(创建、更新、删除):
此策略不处理可变操作。它应该与直写(或后写)模式结合使用。
通读模式的一个主要缺点是许多缓存层可能不支持它。例如,Redis 将无法自动从 MySQL 获取(除非为 Redis 编写插件)。
Cache-Aside 和 Read-Through 策略都是延迟加载数据,即仅在第一次读取时加载。其适用 用例场景如下所示:
虽然 Read- Through 和 Cache-Aside 非常相似,但至少有两个关键区别:
在缓存侧,应用程序负责从数据库中获取数据并填充缓存。在通读中,此逻辑通常由库或独立缓存提供程序支持。
与 Cache-Aside 不同,Read-Through Cache 中的数据模型不能与数据库的数据模型不同。
当多次请求相同的数据时,通读缓存最适合读取繁重的工作负载。例如,一个新闻故事。缺点是当第一次请求数据时,总是会导致缓存未命中,并招致将数据加载到缓存中的额外惩罚。开发人员通过手动发出查询来“加热”或“预热”缓存来处理这个问题。就像 cache-aside 一样,缓存和数据库之间的数据也有可能不一致,解决方法在于写入策略,我们将在下面看到。
不读或不写模型
Refresh ahead:预测热点数据并自动刷新数据库中的缓存,永不阻塞读取,最适合小型只读数据集,例如邮政编码列表缓存,我们可以定期刷新整个缓存,因为它很小并且是只读的。如果能够可以准确地预测最常读取哪些键,那么,还可以在此模式中预热这些键。最后,如果数据在系统之外更新而系统无法收到通知,可能必须使用此模式。
在大多数场景下,我们通常使用通读和直写/后写/写无效等模型。针对 Refresh-ahead 模型,其可以单独使用,也可以作为一种优化来预测和预热读取以进行通读。由谁负责缓存维护,调用者或专用层有两种实现模式。
1、Cache-Facade:缓存层是一个库或服务委托写入数据库,我们只与缓存层交谈。然后数据库对我们的应用程序是透明的。缓存层可以处理一致性和故障转移。例如,许多数据库都有自己的缓存,这是缓存外观的一个很好的例子。我们还可以编写一些进程内 DAO 层来读取/写入具有嵌入式缓存层的实体,从调用者的角度来看,这个小层也是一个缓存门面。
2、Cache-Aside:我们的应用程序保持缓存一致性,这意味着应用程序代码更复杂,但这提供了更大的灵活性。例如,像数据库查询缓存这样的缓存外观模式只能缓存行,如果想缓存带有行的 Java POJO 或 Kotlin 数据类,则将缓存放在一边要容易得多。但是它仍然可以使用缓存门面,例如,将 Spring 缓存作为门面库来缓存 POJO,并在后台自动处理数据库中的 POJO。
当缓存不支持原生的读通和写通操作,并且资源需求不可预测时,我们使用这种缓存侧模式。
1)读取:尝试命中缓存。如果没有命中,则从数据库中读取,然后更新缓存。
2)写入:先写入数据库,然后删除缓存条目。这里一个常见的陷阱是人们错误地用值更新了缓存,高并发环境下的双写会使缓存变脏。
在这种模式下,仍然有可能出现脏缓存。在满足这两种情况时会发生上述情况:读取数据库并更新缓存、 更新数据库并删除缓存。
缓存一致性

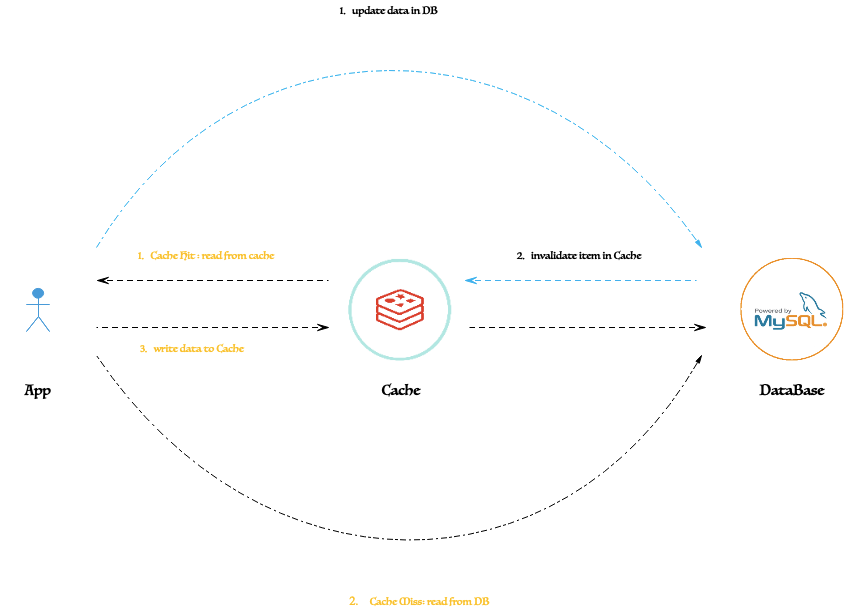
缓存一致性模型(参考)图
如何保障缓存(Redis)与 数据存储(数据库)之间的数据一致性,通常 有多种 设计实现策略,本文重点针对 Cache Aside Pattern(旁路缓存模式) 进行简要解析,此模型也是在实际的业务场景中使用较为广泛的。具体如下。
在 Cache Aside Pattern 模型中,通常写请求场景基本流程主要为:先更新 DB,然后直接删除 Cache 。
在业务场景实现中,如果更新数据库成功,而进行缓存删除操作时出现失败的情况下,简单地说,通常主要有以下两个解决方案:
1、缩短 Cache 失效时间:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。此方案在实际的业务场景中通常 不推荐,本质上治标不治本。
2、增加 Cache 更新重试机制:如果 Cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 Key 存入队列中,等缓存服务可用之后,再将缓存中对应的 Key 删除即可。可考虑使用消息队列。此方案算是一种 常用的解决策略,能够满足绝大多数业务场景需要。
其实,从本质上而言,缓存方案的规划设计往往依赖于实际的业务场景需求,毕竟,技术是为业务服务的。可能有时我们引入缓存之后,为了解决短期内的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
缓存异常场景
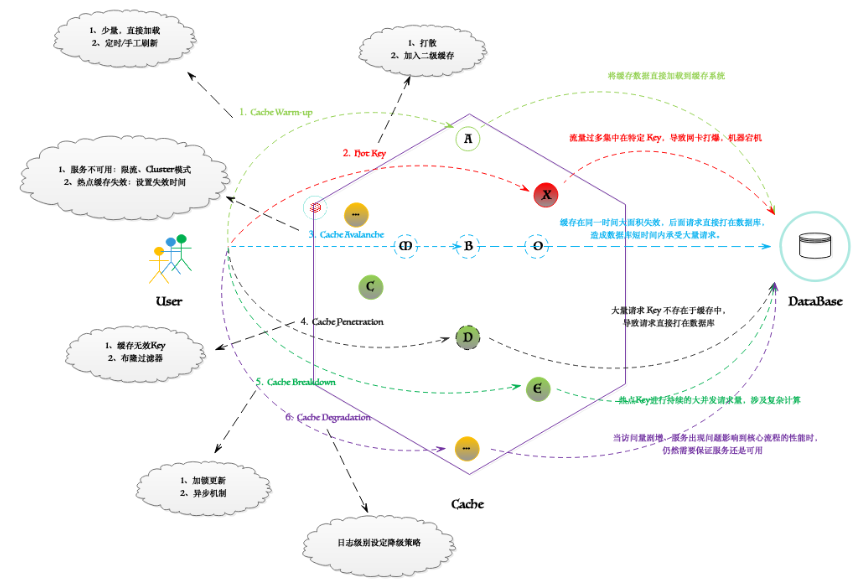
缓存场景模型图
其实。在实际的场景中,考虑到各种应用异常和业务故障,通常不可能完全使用分布式缓存和数据库系统来实现线性一致性模型。每一种缓存模式都有其自身的局限性,在某些情况下我们无法获得顺序一致性,或者有时会在缓存和数据库之间获得意外延迟。对于笔者在本文中展示的所有的解决方案,依据不同的业务需求总是会遇到高并发的极端情况。因此,对此没有灵丹妙药,在选择解决方案之前了解限制并定义特定的一致性要求。
如果想要实现线性一致性和容错性,建议最好不要使用缓存策略,可考虑其他的方案。以上为 Redis 缓存系统相关解析,希望对大家有用。
活动时间~

相关文章:
一文读懂 Redis 缓存系统
【摘要】本文介绍了Redis缓存原理、详细解析了缓存模型、缓存一致性和缓存异常场景。 【作者】李杰,专注于Java虚拟机技术、云原生技术领域的探索与研究。 尽管(关系型)数据库系统 (SQL) 带来了许多出色的属性,例如 ACID&#x…...

初识Java 10-1 集合
目录 泛型和类型安全的集合 基本概念 添加一组元素 打印集合 List Iterator(迭代器) 本笔记参考自: 《On Java 中文版》 在进行程序设计时我们会发现,程序总是会根据某些在运行时才能知道的条件来创建新的对象。这意味着&am…...
系统调用)
Linux- pipe()系统调用
管道 管道(Pipe)是一种用于进程间通信(IPC)的简单而有效的方式。在UNIX和类UNIX操作系统(如Linux)中,管道提供了一种让一个进程将其输出发送给另一个进程的输入的机制。管道通常用于数据流的单…...
数据库常用指令
检查Linux系统是否已经安装了MySQL: sudo service mysql start...

[Studio]Manifest merger failed with multiple errors, see logs 解决方法
记录一个引入库时经常会出错的问题 最近使用一个图片上传库后项目代码报了一个错: Execution failed for task :app:processDebugManifest. > Manifest merger failed with multiple errors, see logs* Try: Run with --info or --debug option to get more lo…...

【数据结构与算法】不就是数据结构
前言 嗨喽小伙伴们你们好呀,好久不见了,我已经好久没更新博文了!之前因为实习没有时间去写博文,现在已经回归校园了。我看了本学期的课程中有数据结构这门课程(这么课程特别重要),因为之前学过一点…...
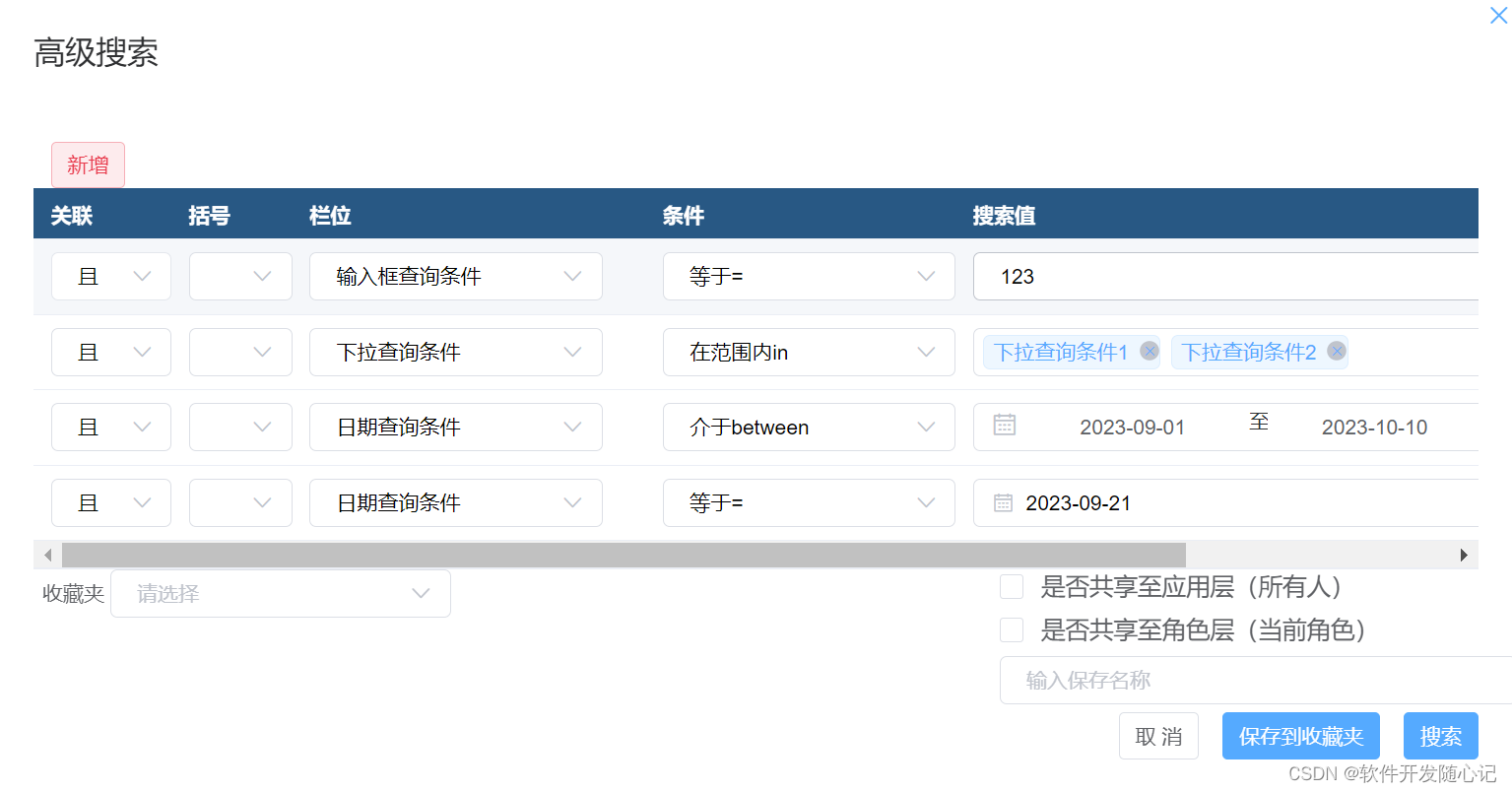
封装一个高级查询组件
封装一个高级查询组件 背景一,前端相关代码二,后端相关代码三,呈现效果总结 背景 业务有个按照自定义选择组合查询条件,保存下来每次查询的时候使用的需求。查了一下项目里的代码没有现成的组件可以用,于是封装了一个 …...

代码随想录第七章 栈与队列
1、leecode232 用栈实现队列 使用栈模拟队列的行为,仅使用一个栈是不行的,所以需要两个栈,一个是输入栈,一个是输出栈。 #include<iostream> #include<vector> #include<string> #include<stack> #incl…...
——4.5. 同义词(Synonym))
SQL Server对象类型(5)——4.5. 同义词(Synonym)
4.5. 同义词(Synonym) 4.5.1. 同义词概念 与Oracle中相同,SQL Server中的同义词是虚的、被定义的模式对象,其本身并不存储任何数据。其用途之一就是为其他类型基础对象提供一个别名;用途之二就是为应用提供一个抽象层,以方便后期应用相关的基础对象的更改和维护。用户可…...
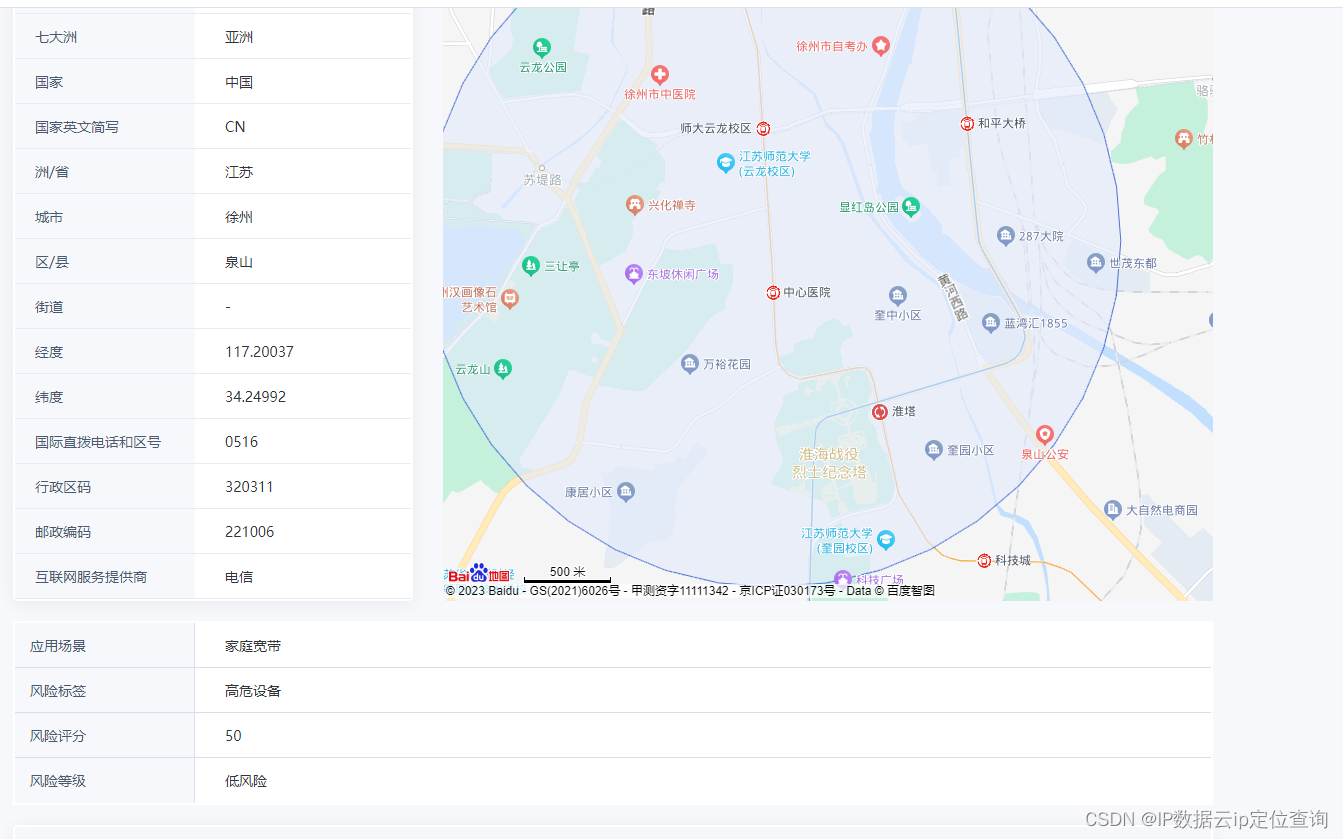
IP风险查询:抵御DDoS攻击和CC攻击的关键一步
随着互联网的普及,网络攻击变得越来越普遍和复杂,对企业和个人的网络安全构成了重大威胁。其中,DDoS(分布式拒绝服务)攻击和CC(网络连接)攻击是两种常见且具有破坏性的攻击类型,它们…...

Tune-A-Video论文阅读
论文链接:Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation 文章目录 摘要引言相关工作文生图扩散模型文本到视频生成模型文本驱动的视频编辑从单个视频生成 方法前提DDPMsLDMs 网络膨胀微调和推理模型微调基于DDIM inversio…...

Dataset和DataLoader用法
Dataset和DataLoader用法 在d2l中有简洁的加载固定数据的方式,如下 d2l.load_data_fashion_mnist() # 源码 Signature: d2l.load_data_fashion_mnist(batch_size, resizeNone) Source: def load_data_fashion_mnist(batch_size, resizeNone):"""…...
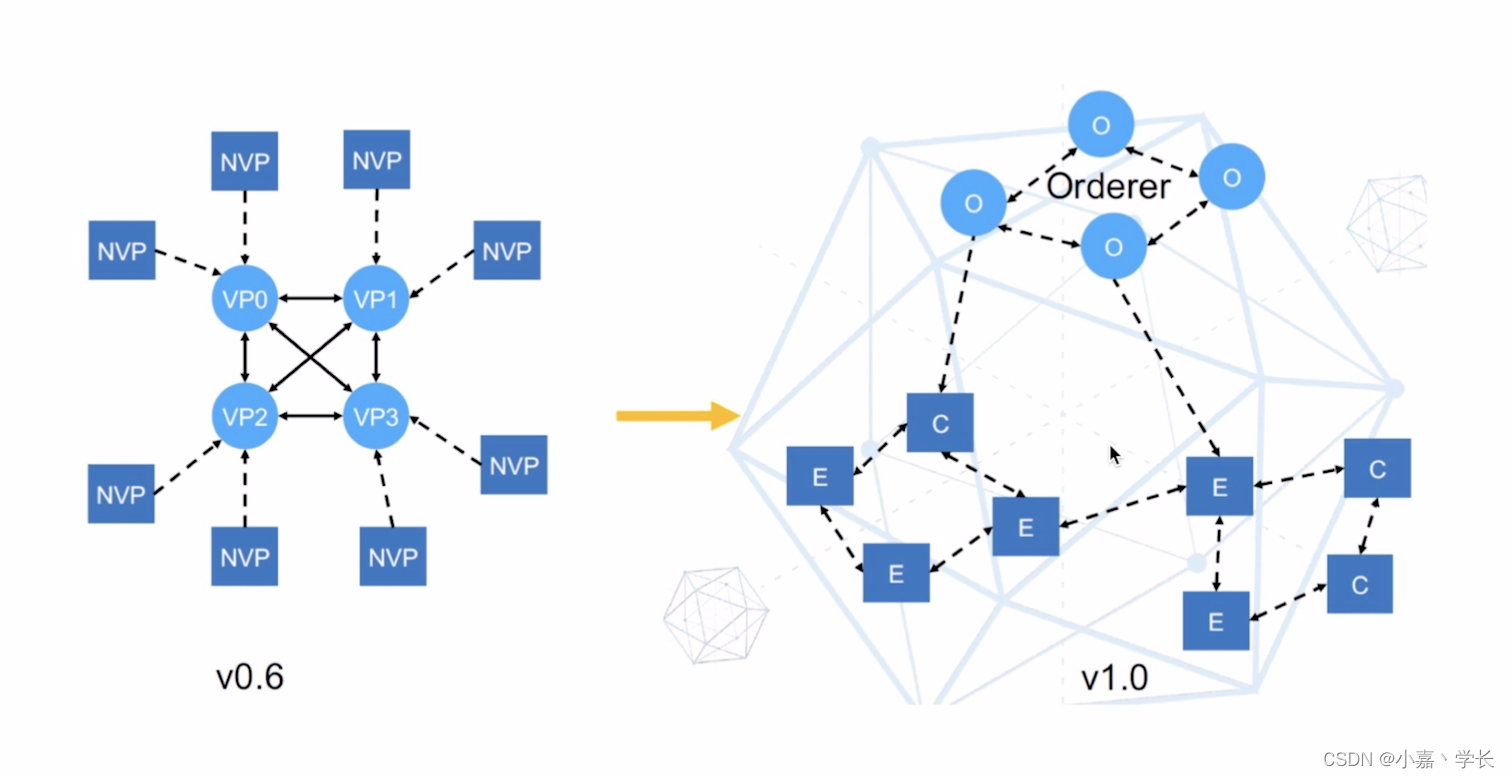
【跟小嘉学习区块链】二、Hyperledger Fabric 架构详解
系列文章目录 【跟小嘉学习区块链】一、区块链基础知识与关键技术解析 【跟小嘉学习区块链】一、区块链基础知识与关键技术解析 文章目录 系列文章目录[TOC](文章目录) 前言一、Hyperledger 社区1.1、Hyperledger(面向企业的分布式账本)1.2、Hyperledger社区组织结构 二、Hype…...

springboot下spring方式实现Websocket并设置session时间
概述 springboot实现websocket有4种方式 servlet,spring,netty,stomp 使用下来spring方式是最简单的. springboot版本:3.1.2 jdk:17 当前依赖版本 <dependency><groupId>org.springframework.boot<…...
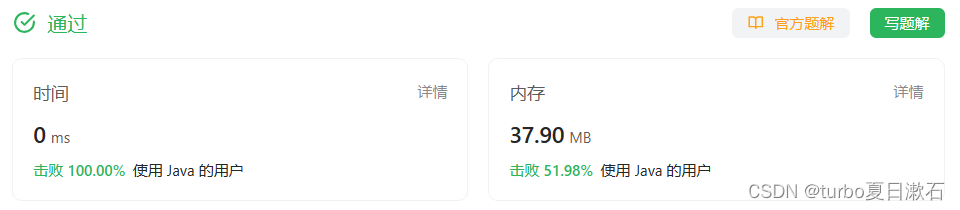
LeetCode算法二叉树—相同的树
目录 100. 相同的树 - 力扣(LeetCode) 代码: 运行结果: 给你两棵二叉树的根节点 p 和 q ,编写一个函数来检验这两棵树是否相同。 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是…...
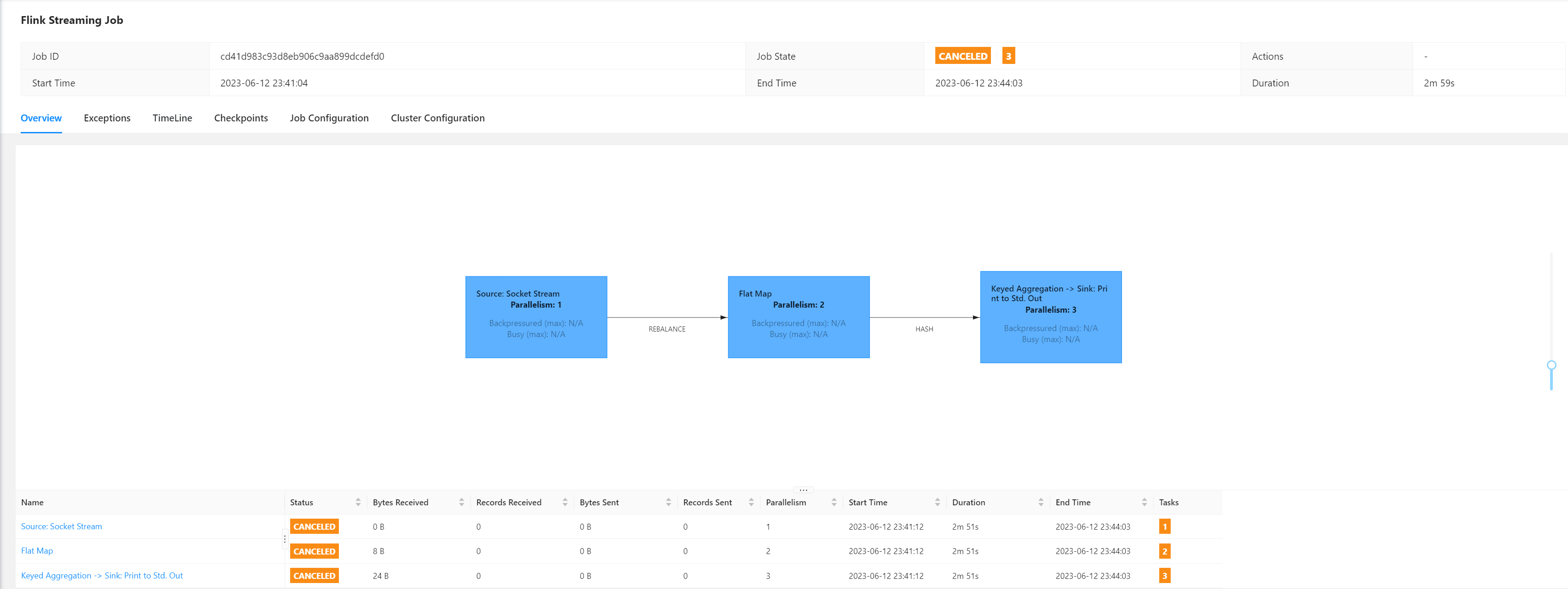
搭建Flink集群、集群HA高可用以及配置历史服务器
Flink集群搭建 Flink集群搭建集群规划下载并解压安装包修改集群配置分发安装目录启动集群访问Web UI Flink集群HA高可用概述集群规划配置flink配置master、workers配置ZK分发安装目录启动HA集群测试 Flink参数配置配置历史服务器概述配置启动、停止历史服务器提交一个Job任务查…...
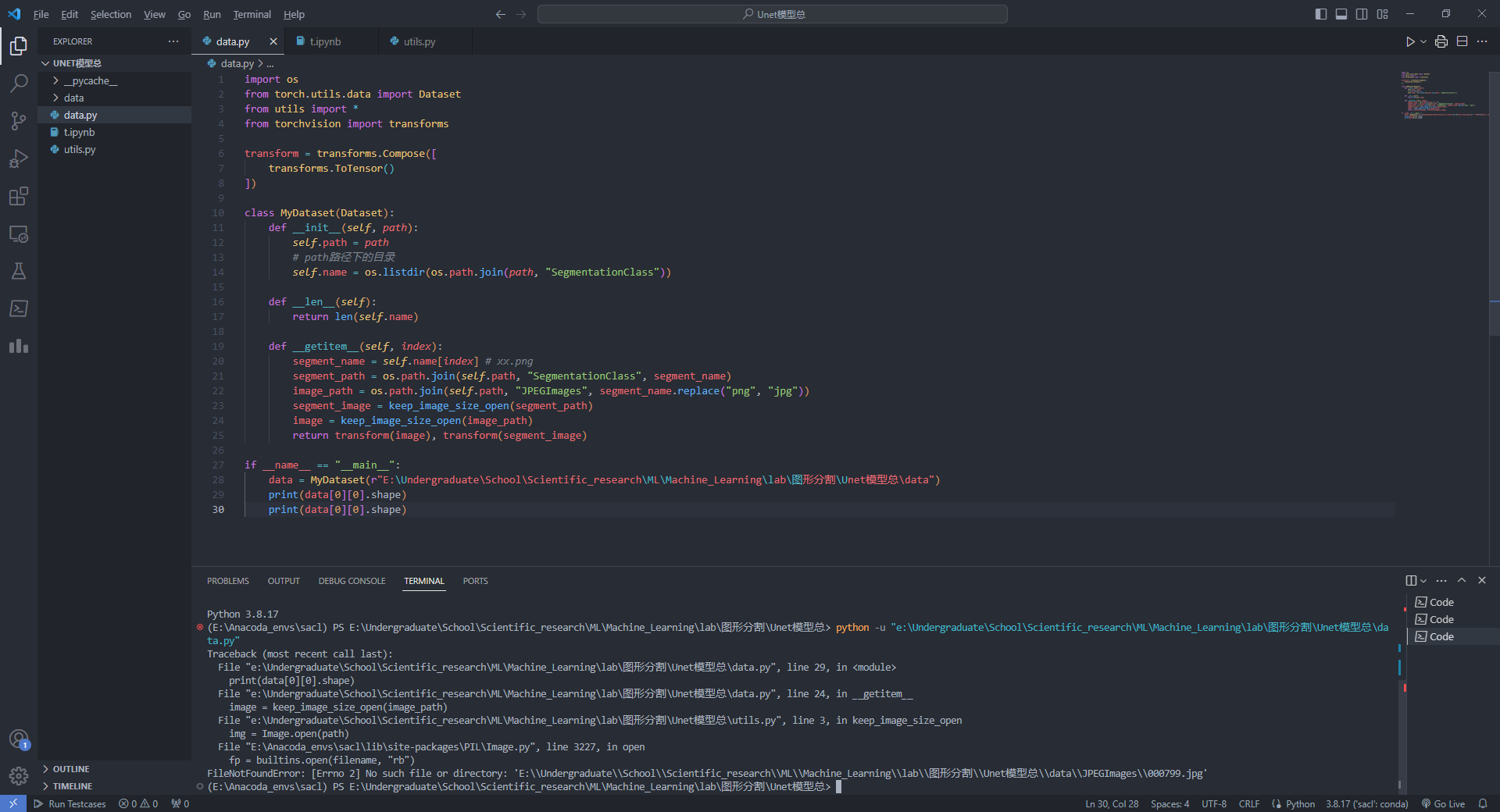
vscode终端中打不开conda虚拟包管理
今天,想着将之前鸽的Unet网络模型给实现一下,结果发现,在vscode中运行python脚本,显示没有这包,没有那包。但是在其他的ipynb中是有的,感觉很奇怪。我检查了一下python版本,发现不是我深度学习的…...

【音视频】MP4封装格式
基本概念 使用MP4box.js查看MP4内部组成结构 整体结构 数据索引(moov)数据流包(mdat) 各个包的位置,大小,信息,时间戳,编码方式等全在数据索引 数据流包只有纯二进制码流数据 数据…...

环境-使用vagrant快速创建linux虚拟机
1.下载软件 虚拟机 Oracle VM VirtualBox 镜像 Vagrant by HashiCorp (vagrantup.com) 如果下载慢,可以复制下载链接,使用迅雷下载 2.安装 根据提示点击下一步即可,建议安装到空间较大的非系统盘。 打开 window cmd 窗口,…...
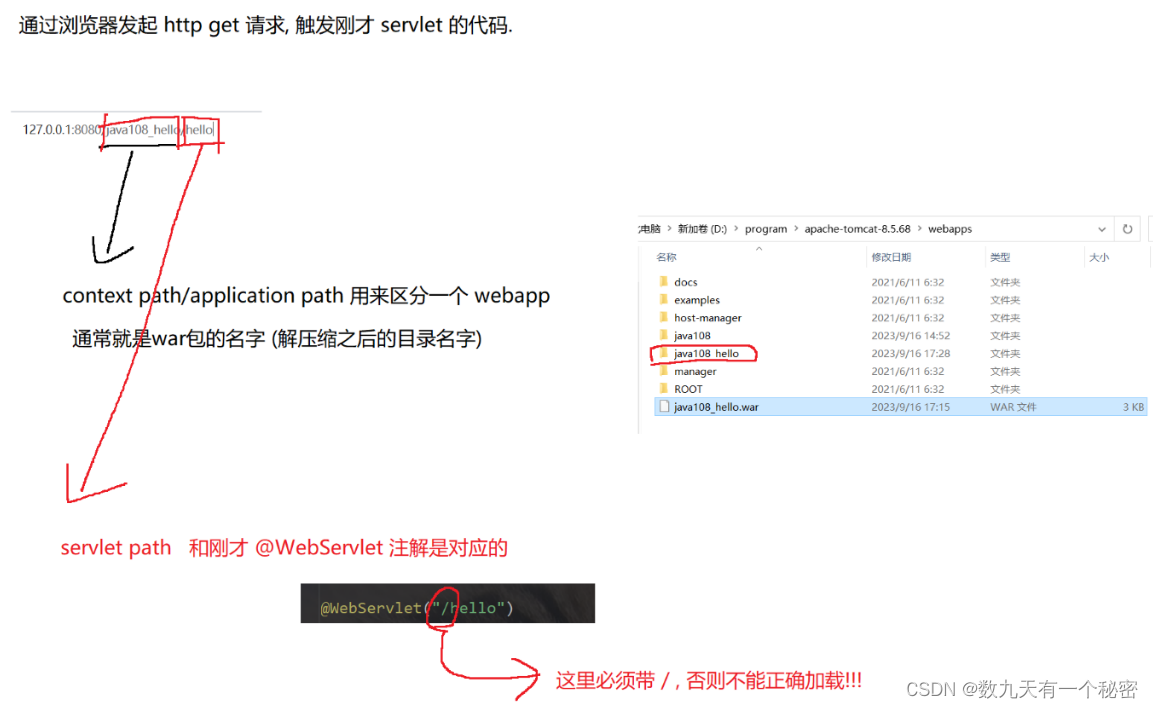
10.1网站编写(Tomcat和servlet基础)
一.Tomcat: 1.Tomcat是java写的,运行时需要依赖jre,所以要装jdk. 2.建议配置好环境变量. 3.默认端口号8080(业务端口)可能会被占用,建议改一下(本人改成了9999). 4.另一个默认端口是8005(管理端口). 二Servlet基础(编写一个hello world代码): 整体分为7个步骤,分别是创建…...

告别外挂SDRAM!用SWM34SRET6这颗内置8MB内存的MCU驱动4.3寸屏,成本直降
告别外挂SDRAM!用SWM34SRET6这颗内置8MB内存的MCU驱动4.3寸屏,成本直降 在嵌入式显示项目中,驱动TFT-LCD屏幕往往需要搭配外置SDRAM芯片来满足帧缓冲需求。这不仅增加了BOM成本,还占用了宝贵的PCB面积,更让布线复杂度直…...

别死磕数据线!聊聊EMMC BGA布线里那些能删掉的‘废脚’
别死磕数据线!EMMC BGA布线中那些被忽略的"废脚"优化策略 在PCB layout工程师的日常工作中,EMMC存储器的BGA封装布线常常让人头疼不已。0.5mm的球间距、密集的数据线、严格的阻抗要求,这些因素叠加在一起,往往让设计者…...

卡尔曼滤波在目标跟踪中的应用:原理、建模与工程调参实战
1. 项目概述:从“猜”到“算”的跟踪艺术在目标跟踪这个领域,无论是自动驾驶中预测前车的轨迹,还是无人机锁定移动的物体,亦或是视频监控里框住一个行走的人,我们核心要解决的都是一个问题:如何在充满噪声和…...

不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响
不只是连线:深入理解模拟版图中电阻的‘Segment’与‘M’参数对实际阻值的影响 在模拟集成电路设计中,电阻作为最基本的无源元件之一,其版图实现往往被初学者视为简单的金属连线问题。然而,当设计从原理图转向物理实现时ÿ…...

程序员的写作技巧:如何写出受欢迎的技术博客
在软件测试行业快速发展的今天,技术博客不仅是知识沉淀的载体,更是测试从业者提升个人影响力、拓展职业边界的重要途径。一篇受欢迎的技术博客,能让你的经验被更多人看见,甚至成为行业内的标杆。那么,软件测试从业者该…...

3分钟终极指南:如何将任何网页一键转换为Figma设计稿?
3分钟终极指南:如何将任何网页一键转换为Figma设计稿? 【免费下载链接】figma-html Convert any website to editable Figma designs 项目地址: https://gitcode.com/gh_mirrors/fi/figma-html 你是否经常遇到这样的困扰:看到一个设计…...

基于遗传算法的VRPTW问题求解:从元胞数组编码到多约束优化
1. 遗传算法与VRPTW问题初探 第一次接触带时间窗的车辆路径问题(VRPTW)时,我被它复杂的约束条件弄得头晕眼花。想象一下你是一家物流公司的调度员,手上有7辆载重不同的货车,需要给16个客户送货。每个客户都有特定的需求…...

RTOS如何通过确定性调度与内存管理增强嵌入式系统安全可靠性
1. 项目概述:为什么我们需要关注实时操作系统的安全与可靠?在嵌入式、工业控制、汽车电子乃至航空航天这些领域里,系统一旦“死机”或“反应迟钝”,后果往往不是重启一下那么简单。轻则产线停摆、设备损坏,重则可能危及…...

5分钟快速上手SignTools:自托管iOS应用签名平台完整教程
5分钟快速上手SignTools:自托管iOS应用签名平台完整教程 【免费下载链接】SignTools ✒ A free, self-hosted platform to sideload iOS apps without a computer 项目地址: https://gitcode.com/gh_mirrors/si/SignTools 想要在iOS设备上自由安装第三方应用…...

G-Helper完整指南:3分钟掌握华硕笔记本性能优化神器
G-Helper完整指南:3分钟掌握华硕笔记本性能优化神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Expe…...