【MySQL基础 | 中秋特辑】多表查询详细总结
个人主页:兜里有颗棉花糖
欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创
收录于专栏【MySQL学习专栏】🎈
本专栏旨在分享学习MySQL的一点学习心得,欢迎大家在评论区讨论💌

目录
- 一、多表关系
- 多对一(一对多)
- 多对多案例演示
- 一对一案例演示
- 二、多表查询概述
- 多表查询分类
- 三、内连接
- 隐式内连接演示
- 显式内连接演示
- 四、外连接
- 左连接
- 右连接
- 五、自连接
- 案例1
- 案例2
- 六、联合查询
- 七、子查询
- 7.1标量子查询
- 案例1
- 案例2
- 7.2列子查询
- 案例1
- 案例2
- 案例3
- 7.3行子查询
- 案例
- 7.4表子查询
- 案例1
- 案例2
一、多表关系
我们在平常的项目开发中,数据库层面设计表结构时,会根据业务需求及业务模块之间的关系分析并设计表结构,由于业务之间相互关联,所以各个表结构也会之间也存在着各种联系。
各个表结构一般分为三种:多对一(多对一)、一对一、多对多。
多对一(一对多)
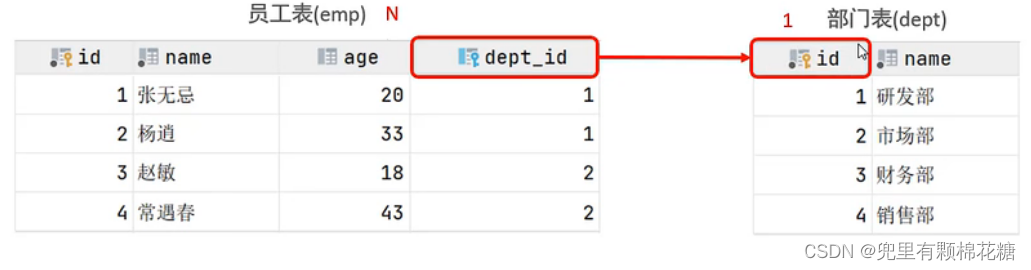
多对一(一对多)案例分析:比如部门和员工之间的关系就可以满足多对一(一对多),即
1个员工只能属于1个部门,但是一个部门下可以有多少个员工。数据库方面的实现:在多的一方建立外键,指向一的一方的主键。
举例,请看下图:
多对多案例演示
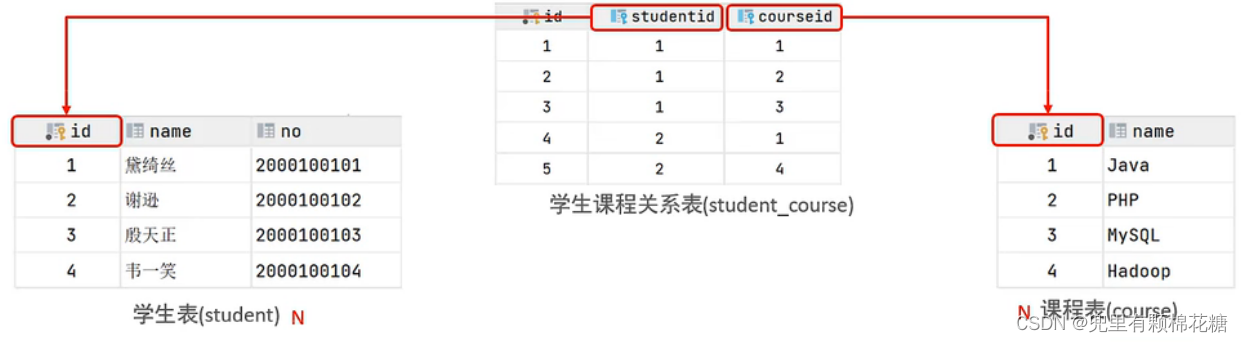
多对多案例分析:比如学生和选的课程之间的关系,即1个学生可以选择多门课程、同时1个课程也可以被多个学生选择。
数据库方面的实现:建立第三张中间表,中间表至少包含两个外键,分别关联两个主键(多对多关系中,只能通过中间表来维持关系)。
如下图举例(通过中间表就可以来维护学生表和课程表之间的关系。):
下面我们通过SQL语句来创建学生表和课程表,建表语句如下:
-- 多对多案例演示:学生表和课程表的创建
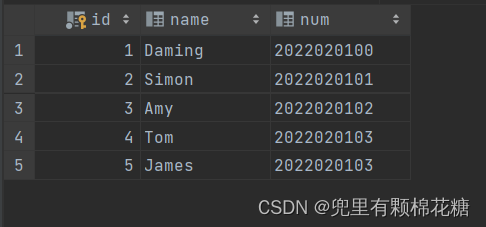
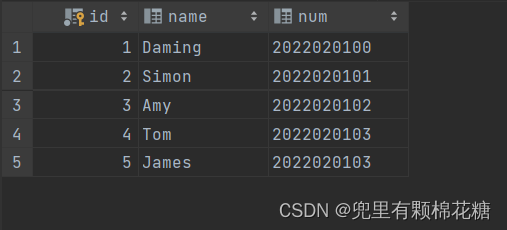
create table student(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',num varchar(10) comment '学号'
) comment '学生表';
-- 学生表数据插入
insert into student values(null,'Daming','2022020100'),(null,'Simon','2022020101'),(null,'Amy','2022020102'),(null,'Tom','2022020103'),(null,'James','2022020103');-- 课程表的创建
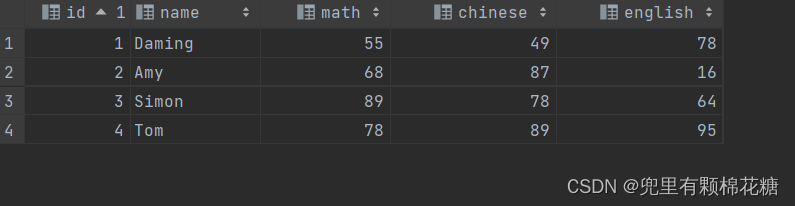
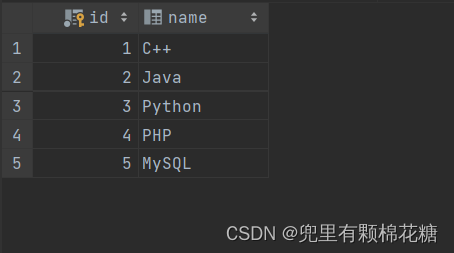
create table course(id int auto_increment primary key comment '主键ID',name varchar(10) comment '课程名称'
) comment '课程表';
-- 课程表数据插入
insert into course values(null,'C++'),(null,'Java'),(null,'Python'),(null,'PHP'),(null,'MySQL');
结果运行如下:
可以看到上图的学生表和课程表已经创建好了,但是两张表之间好像没有任何关系,所以我们需要建立中间表来维护两张表之间的关系。
中间表建表语句和插入数据如下:
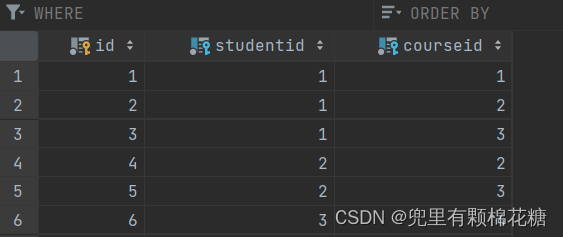
-- 学生课程中间表
create table student_course(id int auto_increment primary key comment '主键',studentid int not null comment '学生ID',courseid int not null comment '课程ID',constraint fk_courseid foreign key (courseid) references course(id),constraint fk_studentid foreign key (studentid) references course(id)
) comment '学生课程中间表';
insert student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2),(null,2,3),(null,3,4);
结果演示:
一对一案例演示
下面来看一对一多表关系的案例介绍:
案例:用户与用户详情的关系。
一对一的多表关系多用于单表拆分,将一个表中的基础字段放在一张表中,其它详情字段放在另一个表中,以便提高工作效率。
多对多关系在数据库层面的实现方式:在任意一方加入外键,关联另一方的主键,并且设置外键为唯一的(UNIQUE),即唯一约束。
下面是建表和添加数据的SQL语句,请看:
-- 一对一案例介绍
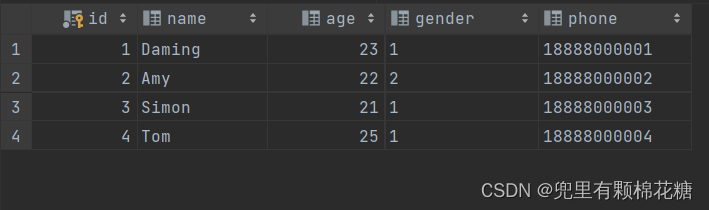
create table tb_user(id int auto_increment primary key comment '主键ID',name varchar(10) comment '姓名',age int comment '年龄',gender char(1) comment '1:男,2:女',phone char(11) comment '手机号'
) comment '用户基本信息表';
insert into tb_user(id,name,age,gender,phone) values(null,'Daming',23,'1','18888000001'),(null,'Amy',22,'2','18888000002'),(null,'Simon',21,'1','18888000003'),(null,'Tom',25,'1','18888000004');create table tb_user_edu(id int auto_increment primary key comment '主键ID',degree varchar(20) comment '学历',major varchar(30) comment '专业',primaryschool varchar(30) comment '小学',middleschool varchar(50) comment '中学',university varchar(30) comment '大学',userid int unique comment '用户名ID',constraint fk_userid foreign key (userid) references tb_user(id)
) comment '用户教育信息表';
insert into tb_user_edu(id,degree,major,primaryschool,middleschool,university,userid) values(null,'本科','绘画','北京市第一小学','北京市第一中学','北京大学',1),(null,'大专','游戏','浙江第一小学','浙江第一中学','浙江大学',2),(null,'本科','棋盘','杭州第一小学','杭州第一中学','清华大学',3),(null,'研究生','编程','青岛第一小学','青岛第一中学','青岛大学',4);
语句运行结果如下:

注意,我们为tb_user_edu表中的userid建立了唯一约束,所以一条记录对应着一个用户的基本信息。
二、多表查询概述
多表查询顾名思义就是从多张表中查询数据。
通过多表查询,可以在关联的表之间建立联系,并从这些表中选择和过滤需要的数据。
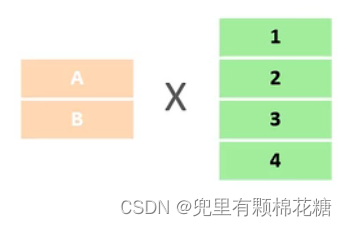
笛卡尔积:笛卡尔乘积是两个集合A、B所有组合的情况。如下图:
所以我们在多表查询中需要消除无效的笛卡尔积。
我们通过下面的两张表(emp员工表和dept部门表进行演示),建表语句如下:
-- 部门表
create table dept(id int auto_increment primary key comment 'ID' ,name varchar(10) not null comment '部门名称'
) comment '部门表';-- 员工表
create table emp(id int auto_increment primary key,name varchar(10) not null comment '姓名',age int comment '年龄',job varchar(10) comment '工作',salary int comment '薪资',entrydate date comment '入职时间',managerid int comment 'BossID',dept_id int comment '部门ID'
) comment '员工表';-- 部门表数据插入
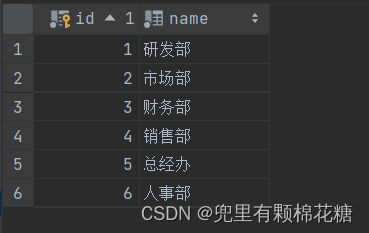
insert into dept(id,name) values(1,'研发部'),(2,'市场部'),(3,'财务部'),(4,'销售部'),(5,'总经办'),(6,'人事部');--员工表数据插入
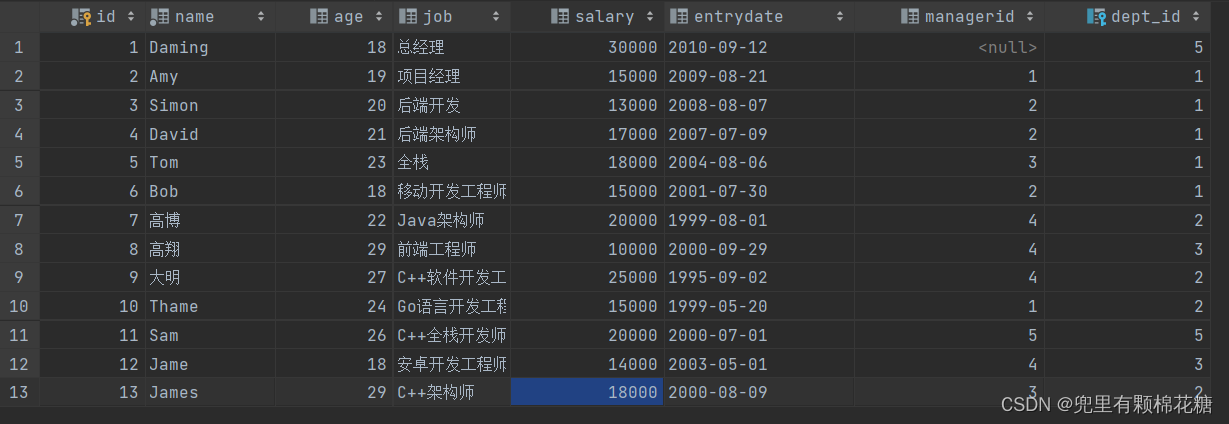
insert into emp(id,name,age,job,salary,entrydate,managerid,dept_id) values(1,'Daming',18,'总经理',30000,'2010-9-12',null,5),(2,'Amy',19,'项目经理',15000,'2009-8-21',1,1),(3,'Simon',20,'后端开发',13000,'2008-8-7',2,1),(4,'David',21,'后端架构师',17000,'2007-7-9',2,1),(5,'Tom',23,'全栈',18000,'2004-8-6',3,1),(6,'Bob',18,'移动开发工程师',15000,'2001-7-30',2,1),(7,'高博',22,'Java架构师',20000,'1999-8-1',4,2),(8,'高翔',29,'前端工程师',10000,'2000-9-29',4,3),(9,'大明',27,'C++软件开发工程师',25000,'1995-9-2',4,2),(10,'Thame',24,'Go语言开发工程师',15000,'1999-5-20',1,2),(11,'Sam',26,'C++全栈开发师',20000,'2000-7-1',5,5),(12,'Jame',18,'安卓开发工程师',14000,'2003-5-1',4,3),(13,'James',29,'C++架构师',18000,'2000-8-9',3,2);-- 外键添加
alter table emp add constraint fk_emp_dept_id foreign key (dept_id) references dept(id);
部门表和员工结果如下:
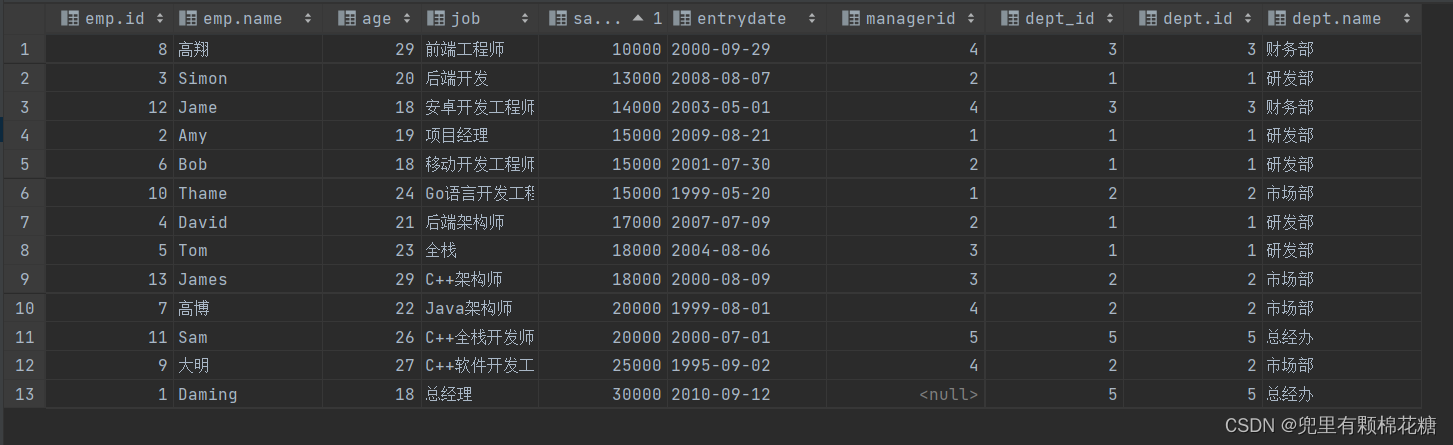
下面我们上述表为例来演示一下多表查询:
SQL语句:
select * from emp,dept where emp.dept_id = dept.id;
查询结果如下:
多表查询分类
多表查询主要分为两大类:连接查询和子查询。
其中连接查询主要分为三种:内连接、外连接、自连接。
内连接:用于查询A、B交集部分的数据。
外连接:分为左外连接(查询左表所有数据和A、B集合的交集部分的数据)和右外连接(查询右表所有数据和A、B集合的交集部分的数据)。
自连接:当前的表与自身的连接查询,自连接必须使用表别名。
三、内连接
内连接:查询的是两张表交集的部分。
内连接分为隐式内连接和显式内连接。
隐式内连接语法:
SELECT 字段列表 FROM 表1,表2 WHERE 条件...;
显式内连接语法:
SELECT 字段列表 FROM 表1 [INNER] JOIN 表2 ON 连接条件...;
隐式内连接演示
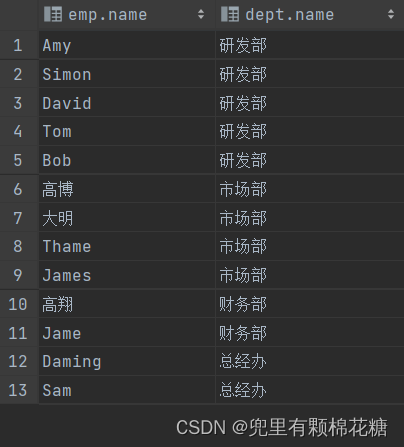
案例:查询每一个员工的姓名以及该员工所关联部门的名称(隐式内连接演示)。
表结构:emp,dept
连接条件:emp.dept_id = dept.id;
隐式内连接查询语句:
select emp.name,dept.name from emp,dept where emp.dept_id = dept.id;
演示结果如下:
显式内连接演示
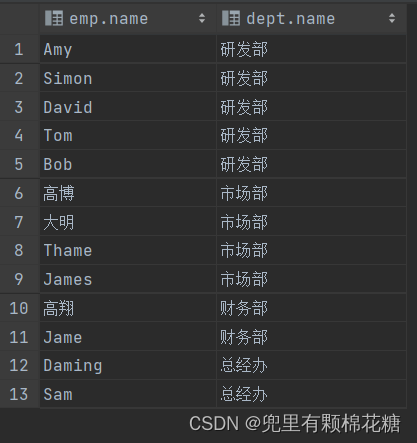
案例:查询每一个员工的姓名以及该员工所关联部门的名称(显式内连接实现)。
表结构:emp,dept
连接条件:emp.dept_id = dept.id;
显式内连接查询语句:
select emp.name,dept.name from emp inner join dept where emp.dept_id = dept.id;
查询结果如下:
四、外连接
外连接分为左外连接和右外连接。
左外连接:查询表1(左表)中的所有数据,这其中包含了表1和表2的交集部分的数据。
左连接
左外连接查询语法:
SELECT 字段列表 FROM 表1 LEFT [OUTER] JOIN 表2 ON 条件;
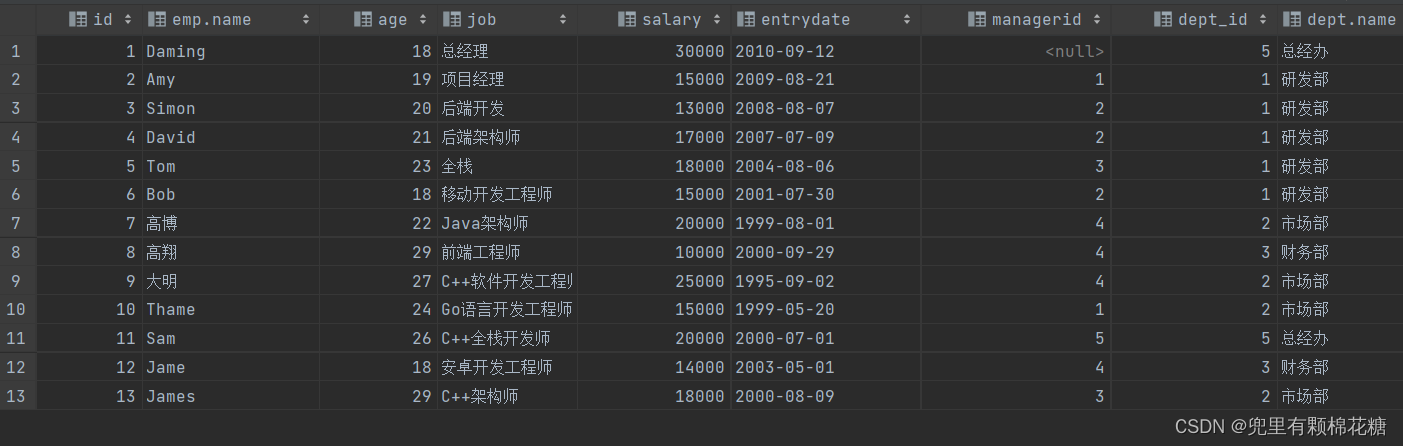
案例演示:查询emp表中的所有数据,和对应的部门信息(使用左外连接)。
查询语句:
select emp.* ,dept.name from emp left outer join dept on emp.dept_id = dept.name;
查询结果如下:
右连接
右连接:查询表2(右表)中的所有数据,这其中包含了表1和表2的交集部分的数据。
右外连接查询语法:
SELECT 字段列表 FROM 表1 RIGHT [OUTER] JOIN 表2 ON 条件;
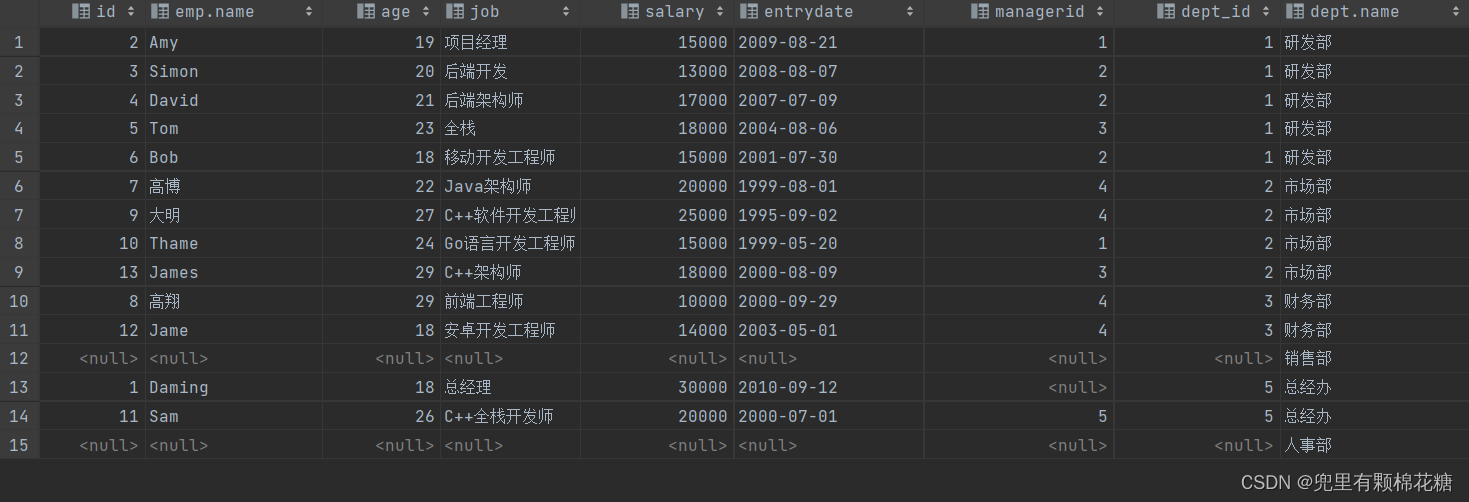
案例演示:查询dept表中的所有数据,和对应的员工信息(使用右外连接)。
查询语句:
select emp.*,dept.name from emp right outer join dept on emp.dept_id = dept.id;
查询结果如下:
五、自连接
子连接查询语法:
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件...;
子连接查询可以是内连接查询,也可以是外连接查询。
下面来进行具体案例的举例:
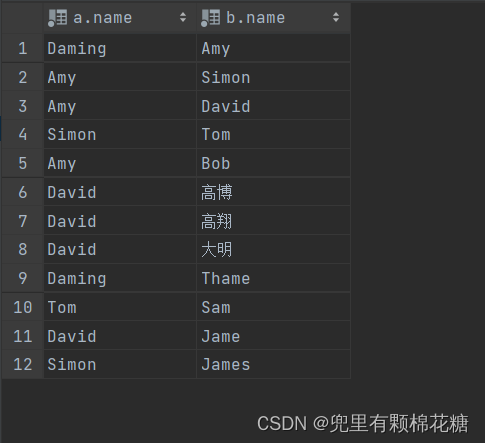
案例1
案例1:查询员工及其所属领导的名字。
查询语句:
select a.name,b.name from emp a,emp b where a.id = b.managerid;
查询结果演示:
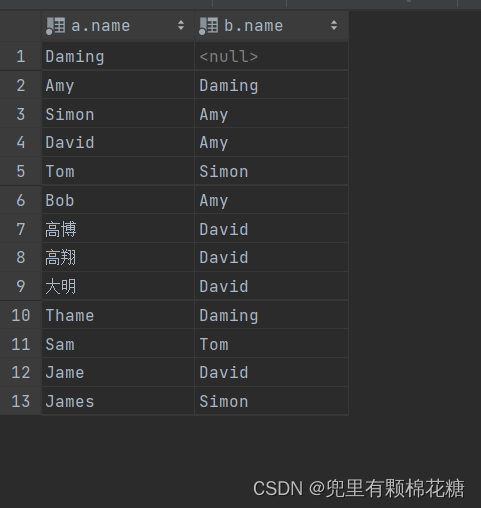
案例2
案例2:查询所有员工及其所属领导的名字,即使该员工没有所属领导,也需要查询出来。
查询语句:select a.name,b.name from emp a left outer join emp b on a.managerid = b.id;
查询结果如下:
六、联合查询
联合查询关键字:UNION、UNION ALL。
联合查询就是把多次查询的结果合并起来,从而形成一个新的查询结果集。
联合查询语法:
SELECT 字段列表 FROM 表A...
UNION[ALL]
SELECT 字段列表 FROM 表B...;
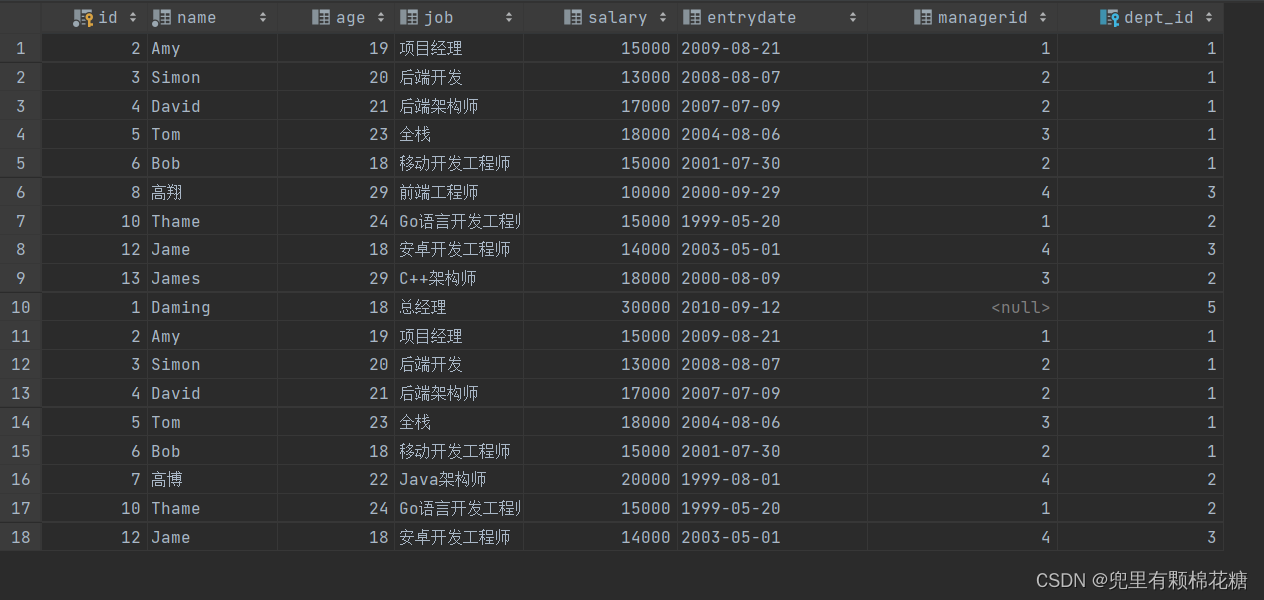
案例演示:将薪资低于19000的员工和年龄超过25岁的员工全部查询出来。
查询语句:
select * from emp where salary < 19000
union all
select * from emp where age < 25;
查询结果如下(可以看到有18条记录):
如果想要查询结果进行去重的话,我们需要把关键字ALL去掉即可去重,请看:
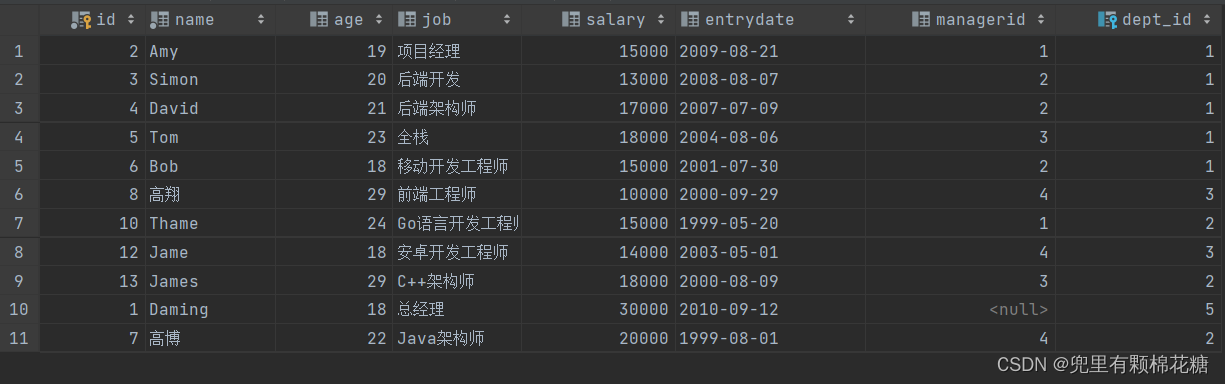
可以看到去重之后的结果总共有11条记录。
联合查询注意事项:
- 联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
- union all会将全部的数据合在一起(并不会进行去重),而union会对合并后的数据进行去重。
七、子查询
概念:SQL语句中嵌套着SELECT语句,称为嵌套查询,又称子查询。
格式如下:
SELECT * FROM t1 WHERE column1 = (SELECT column1 FROM t2);
注意:子查询的外部可以是INSERT/UPDATE/DELETE/SELECT中的任何一个。
根据子查询的结果不同,将子查询分为4类:
- 标量子查询(子查询结果为单个值)
- 列子查询(子查询结果为一列)
- 行子查询(子查询结果为一行)
- 表子查询(子查询结果为多列多行)
根据子查询位置,分为:WHERE之后、FROM之后、SELECT之后。
7.1标量子查询
标量子查询的结果是单个值(数字、字符串、日期等),标量子查询是子查询中最为简单的一种形式。
标量子查询常用操作符:= <> > < >= <=
下面我们来具体演示两个案例:
案例1
案例:查询市场部的所有员工信息。
解析:由于在emp表中是没有市场部这个部门名称的,所以我们把此问题拆分为两步:a.查询市场部的部门id b.根据部门id来查询员工信息。
查询语句:
select * from emp where dept_id = (select id from dept where name = '市场部');
查询结果:

案例2
案例:查询在Tom入职之后的员工信息。
解析:依旧是分为两步走:a.查询Tom的入职时间 b.根据Tom的入职时间来查询员工信息
查询语句:
select * from emp where entrydate > (select entrydate from emp where name = 'Tom');
查询结果:

7.2列子查询
列子查询返回的结果是一列(可以是多行),将这种子查询称为列子查询。
列子查询常用操作符:IN、NOT IN、ALL、ANY、SOME。

我们接下来依旧是来通过案例来学习列子查询。
案例1
案例介绍:查询市场部和销售部的所有员工信息。
查询语句:
select * from emp where dept_id in(select id from dept where name = '市场部' or name = '销售部');
查询结果:

案例2
案例介绍:查询比市场部所有人工资都低的员工信息。
解析:如果将问题拆分的话会分为3步:a. 查询市场部的部门id b.根据市场部的部门id查询市场部人员的工资情况 c.根据市场部人员的工资情况来查询比市场部所有人工资都低的员工信息。
查询语句1(拆分):
select id from dept where name = '市场部';
select salary from emp where dept_id = (select id from dept where name = '市场部');
select * from emp where salary < all(select salary from emp where dept_id = (select id from dept where name = '市场部'));
查询语句2(使用列子查询):
select * from emp where salary < all(select salary from emp where dept_id = (select id from dept where name = '市场部'));
查询结果:

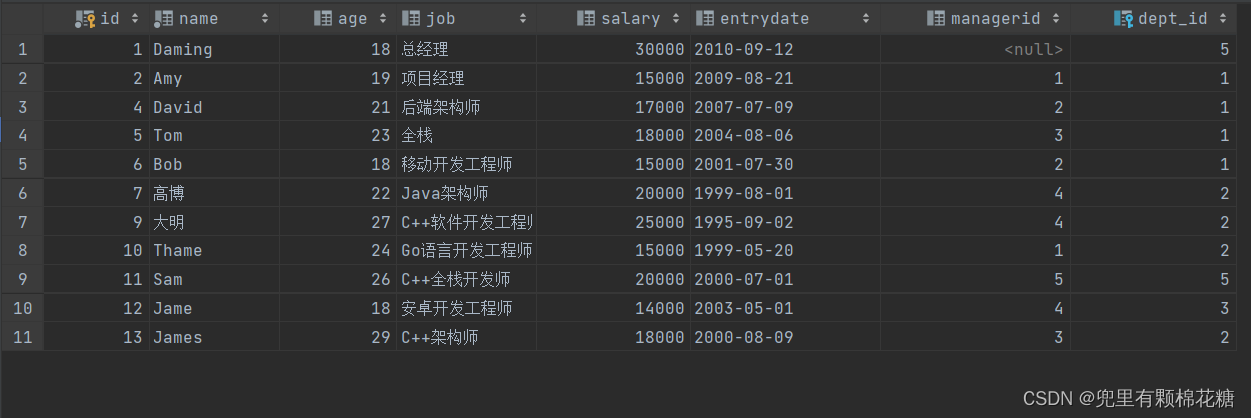
案例3
案例介绍:查询比研发部中任意一人工资高的员工信息。
查询语句:
select * from emp where salary > some(select salary from emp where dept_id = (select id from dept where name = '研发部'));
查询结果:
7.3行子查询
行子查询返回的是一行(可以是多列)。
行子查询常用操作符:=、<>、IN、NOT IN。
案例
案例介绍:查询与Amy工资及直属领导相同的员工信息。
查询语句:
select * from emp where (salary,managerid) = (select salary,managerid from emp where name = 'Amy');
查询结果:

7.4表子查询
表子查询返回的是多行多列。
常用操作符:IN。
案例1
案例介绍:查询与Amy和Tom职位和薪资相同的员工信息。
查询语句:
select * from emp where(job,salary) in(select job,salary from emp where name = 'Amy' or name = 'Tom');
查询结果:

哈哈,这里查询出来的结果依旧是Amy和Tom,并不是因为查询语句出错了,而是因为当时表中没有合适的数据。
案例2
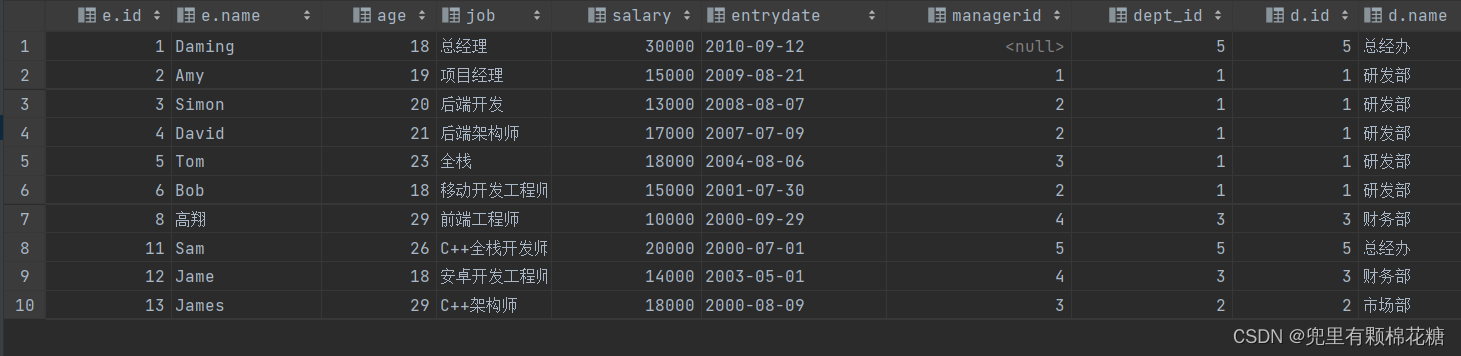
案例介绍:查询入职时间是2000-1-1之后的员工信息以及部门信息。
查询语句:
select * from (select * from emp where entrydate > '2000-1-1') e left outer join dept d on e.dept_id = d.id;
查询结果:
好了,以上就是本文的全部内容。主要讲解了MySQL中的多表查询,其中包括连接查询和子查询。
就到这里吧,再见啦友友们!!!
相关文章:
【MySQL基础 | 中秋特辑】多表查询详细总结
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【MySQL学习专栏】🎈 本专栏旨在分享学习MySQL的一点学习心得,欢迎大家在评论区讨论💌 目录 一、多表…...

21天学会C++:Day14----模板
CSDN的uu们,大家好。这里是C入门的第十四讲。 座右铭:前路坎坷,披荆斩棘,扶摇直上。 博客主页: 姬如祎 收录专栏:C专题 目录 1. 知识引入 2. 模板的使用 2.1 函数模板 2.2 类模板 3. 模板声明和定义…...
MQ - 32 基础功能:消息查询的设计
文章目录 导图概述什么时候会用到消息查询消息队列支持查询的理论基础消息数据存储结构关于索引的一些知识点内核支持简单查询根据 Offset 查询数据根据时间戳查询数据根据消息 ID 查询数据借助第三方工具实现复杂查询第三方引擎支持查询工具化简单查询总结导图 概述 从功能上…...
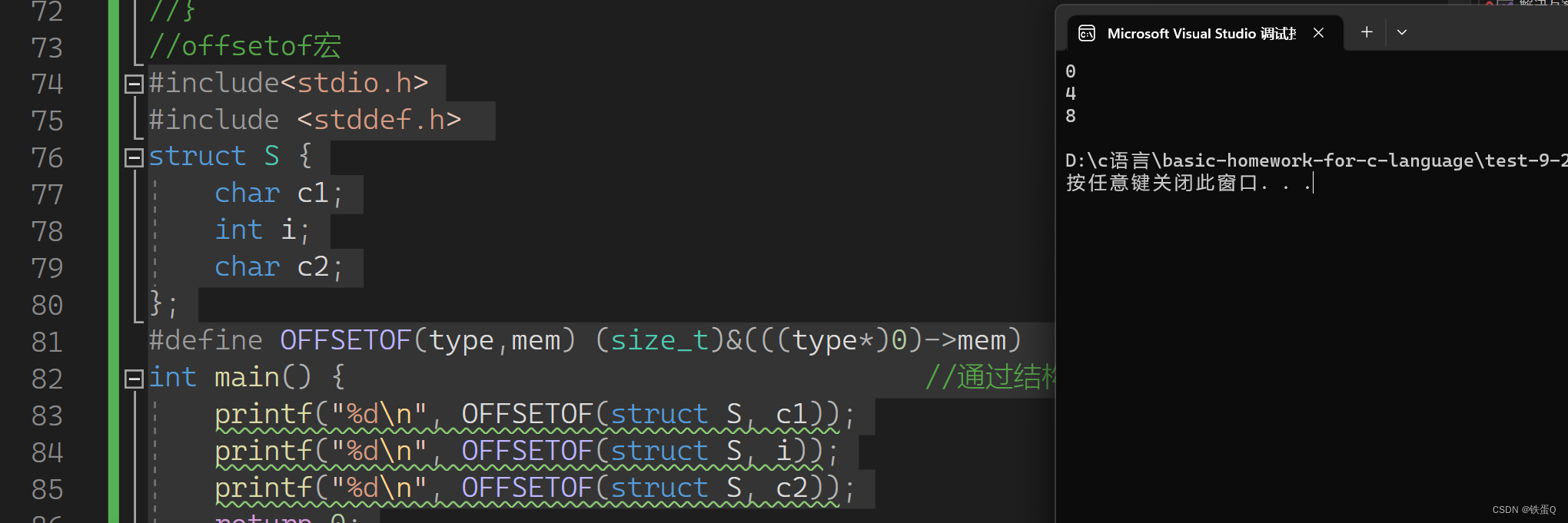
c语言练习66:模拟实现offsetof
模拟实现offsetof #define offsetof(StructType, MemberName) (size_t)&(((StructType *)0)->MemberName) StructType是结构体类型名,MemberName是成员名。具体操作方法是: 1、先将0转换为一个结构体类型的指针,相当于某个结构体的首…...

数据库缓存服务器集群 redis集群
redis 提升数据库性能,缓解数据库压力 2.NoSql产品 产品: redis,mongodb,memcached 名词解释:非关系型数据库 以键值对的方式存储数据---(Key-Value)的形式 3.NoSql的优点 高可扩展性 分布式计算 低成本 架构的灵活性&…...
[密码学入门]仿射密码(Affine)
加密算法y(axb)mod N 解密算法x*(y-b)mod N(此处的为a关于N的乘法逆元,不是幂的概念) 如何求,涉及的知识挺多,还没想好怎么写,丢番图方程,贝祖定理(又译裴蜀定理),扩展欧…...

【Maven】SpringBoot多模块项目利用reversion占位符,进行版本管理.打包时版本号不能识别问题
问题原因: 多模块项目使用reversion点位符进行版管理,打包时生成的pom文件未将 {reversion}占位符替换为真实版本号。 而当子模块被依赖时,引入的pom文件中版本号是:{reversion}。而根据这个版本号去找相应父模块时肯定是找不到的…...

Vue watch实时计算器
watch实时计算器 可以自己选择、-、*、 参考代码 <!DOCTYPE html> <html> <head><meta charset"utf-8"><title></title><script src"https://cdn.bootcdn.net/ajax/libs/vue/2.7.10/vue.js"></script>…...

Java中的super关键字
super 是Java中的一个关键字,它可以用来引用当前对象的父类(超类)的成员变量或方法。主要有以下用途: 访问父类的成员变量: 当子类和父类中有同名的成员变量时,可以使用super关键字来访问父类的成员变量。 …...

MySQL数据库入门到精通6--进阶篇(锁)
5. 锁 5.1 概述 锁是计算机协调多个进程或线程并发访问某一资源的机制。在数据库中,除传统的计算资源(CPU、RAM、I/O)的争用以外,数据也是一种供许多用户共享的资源。如何保证数据并发访问的一致性、有效性是所有数据库必须解决…...

js的继承
一、原型链继承 将父类的实例作为子类的原型 function Father(){this.name Tony }function Son() {}Son.prototype new Father()let son new Son();console.log(son.name) // Tony缺点: 父类所有的引用类型属性都会被所有子类共享,一个子类修改了属…...

HONEYWELLL 05701-A-0325 控制脉冲模块
运动控制: HONEYWELLL 05701-A-0325 控制脉冲模块可以用于运动控制应用,例如控制步进电机或伺服电机,以实现精确的位置和速度控制。 定位系统: 在自动化设备和机器人中,这些模块可以用于确定物体的位置和方向…...
Qt扩展-QCustomPlot 简介及配置
QCustomPlot 简介及配置 一、概述二、安装教程三、帮助文档的集成 一、概述 QCustomPlot是一个用于绘图和数据可视化的Qt 控件。它没有进一步的依赖关系,并且有良好的文档记录。这个绘图库专注于制作好看的、发布质量的2D绘图、图形和图表,以及为实时可…...

python教程:selenium WebDriver 中的几种等待--sleep(),implicitly_wait(),WebDriverWait()
大家早好、午好、晚好吖 ❤ ~欢迎光临本文章 如果有什么疑惑/资料需要的可以点击文章末尾名片领取源码 强制等待:sleep() import time sleep(5) #等待5秒设置固定休眠时间,单位为秒。 由python的time包提供, 导入 time 包后就可以使用。’ 缺点: 不…...
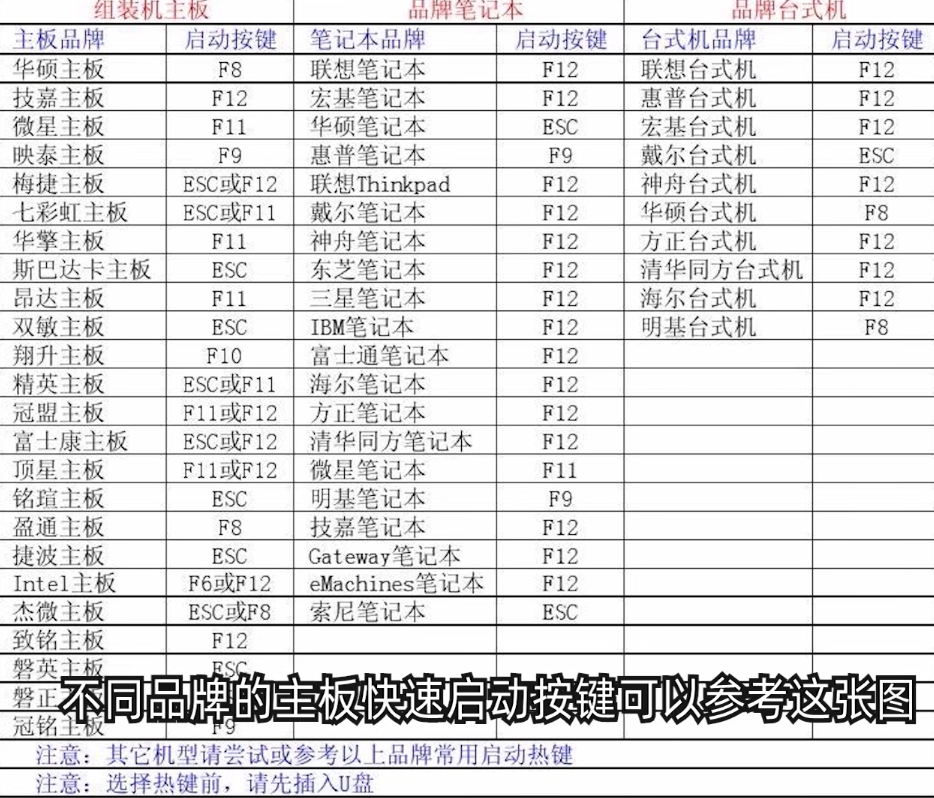
从裸机开始安装操作系统
目录 一、预置知识 电脑裸机 win10版本 官方镜像 V.S. 正版系统 二、下载微软官方原版系统镜像 三、使用微PE系统维护U盘 四、安装操作系统 五、总结 一、预置知识 电脑裸机 ●只有硬件部分,还未安装任何软件系统的电脑叫做裸机。 ●主板、硬盘、显卡等必…...

redhat 6.1 测试环境安装 yum
redhat 6.1 测试环境安装 yum 记录 1. 新建虚拟机 1.1 自定义建立虚拟机 自定义创建新的虚拟机 选择硬件兼容性 创建空白硬盘,稍后选择 iso 文件创建系统。 选择操作系统类型 为虚拟机命名 选择处理器配置 选择虚拟机内存 选择虚拟机网络类型 选择…...
WARNING:tensorflow:Your input ran out of data; interrupting training. 解决方法
问题详情: WARNING:tensorflow:Your input ran out of data; interrupting training. Make sure that your dataset or generator can generate at least steps_per_epoch * epochs batches (in this case, 13800 batches). You may need to use the repeat() funct…...

ChunJun(OldNameIsFlinkX)
序言 ChunJun主要是基于Flink实时计算框架,封装了不同数据源之间的数据导入与导出功能.我们只需要按照ChunJun的要求提供原始与目标数据源的相关信息给Chunjun,然后它会帮我们生成能运行与Flink上的算子任务执行,这样就避免了我们自己去根据不同的数据源重新编辑读入与读出的方…...
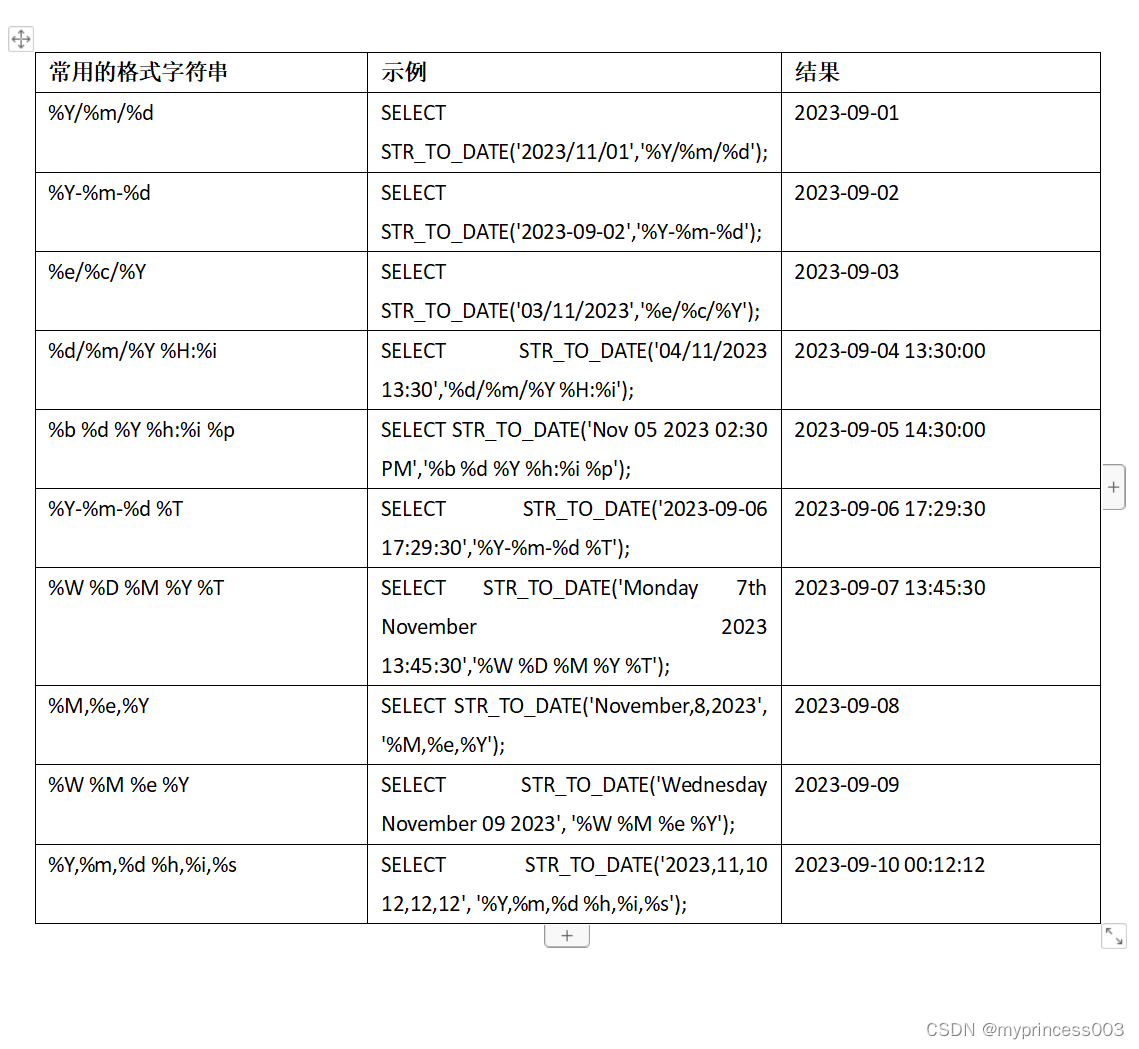
MySQL的时间差函数、日期转换计算函数
MySQL的时间差函数(TIMESTAMPDIFF、DATEDIFF)、日期转换计算函数(date_add、day、date_format、str_to_date) 时间差函数(TIMESTAMPDIFF、DATEDIFF) 需要用MySQL计算时间差,使用TIMESTAMPDIFF、DATEDIFF,记录一下实验结果 --0 …...

【神印王座】悲啸洞穴之物揭晓,圣采儿差点被骗,幸好龙皓晨聪明
Hello,小伙伴们,我是小郑继续为大家深度解析神印王座。 神印王座动漫现阶段已经出到龙皓晨等人接取新任务深入魔族地界的阶段,而龙皓晨等人接取的任务想必现在大家都知道了,那就是探索魔族地界中的悲啸洞穴。但是大家知道悲啸洞穴里面藏着什么…...

告别手改脚本!用CANoe Panel面板做个变量控制台,测试效率翻倍
告别手改脚本!用CANoe Panel面板打造智能变量控制台 在车载网络测试领域,效率提升往往隐藏在那些被忽视的日常操作细节中。当测试工程师频繁打开CAPL脚本修改超时阈值、调整诊断ID或切换测试模式时,不仅打断了工作流,更在团队协作…...
)
极简风项目交付倒计时!:紧急修复MJ --v 6.2中隐藏的1.33倍宽高比偏移Bug,避免客户验收驳回(含补救Prompt包)
更多请点击: https://intelliparadigm.com 第一章:极简风项目交付倒计时! 当交付周期压缩至 72 小时,极简风不再是一种美学选择,而是工程效率的刚性约束。我们摒弃冗余文档、跳过非核心评审环节,聚焦于可…...

高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题
高考解析几何“秒杀”技巧:用极点极线快速搞定椭圆定点定值难题 解析几何作为高考数学的压轴题型,常常让考生望而生畏。面对复杂的计算和抽象的条件,如何在有限时间内快速找到突破口?极点极线理论作为高等几何中的重要工具&#x…...

低温预警!固化慢、易开裂……密封胶冬季施工手册
低温预警!固化慢、易开裂……密封胶冬季施工手册 硅酮耐候密封胶主要作用是保障幕墙的气密性、水密性。其出现问题,可能会导致耐候密封失效,从而造成幕墙漏水漏气,影响幕墙的正常使用。耐候密封胶由于考虑到现场施工,几乎都是单组分硅酮密封胶产品。进入冬季,气候变化明…...

Python数据聚合抓取工具:从配置化引擎到实战避坑指南
1. 项目概述:一个多功能的“聚合爪”工具最近在GitHub上闲逛,发现了一个名字挺有意思的项目:al1enjesus/polyclawster。这个名字拆开看,“poly”代表多,“clawster”听起来像是“claw”(爪子)和…...

CFD工程师必看:TVD格式选型指南——从SUPERBEE到UMIST,哪个才是你的菜?
CFD工程师必看:TVD格式选型实战指南——从工程场景到最优解 在计算流体力学(CFD)的世界里,TVD格式就像赛车手的轮胎选择——没有绝对的好坏,只有场景的适配。当你在汽车外气动分析中遇到激波振荡,或在燃烧模拟中面临虚假扩散时&am…...

Python Reddit数据采集与分析实战:从API调用到舆情监控
1. 项目概述与核心价值最近在开源社区里,一个名为openshrug/reddit-intel的项目引起了我的注意。乍一看,这像是一个针对 Reddit 平台的数据抓取或分析工具,但深入探究后,我发现它的定位远不止于此。它更像是一个为开发者、数据分析…...

Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈
Qwen2.5-14B实战指南:3个关键步骤突破本地大模型部署瓶颈 【免费下载链接】Qwen2.5-14B 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/Qwen2.5-14B 当开发者面对复杂的代码生成任务或技术文档分析需求时,往往会受限于云端API的延迟和…...

016、Git版本控制与协作开发流程
016 Git版本控制与协作开发流程 一个让我熬夜到凌晨三点的.gitignore 去年做一款基于STM32U5的TinyML手势识别项目,团队四个人,代码库从第一天就开始膨胀。第三天晚上,我习惯性git push,然后去睡觉。凌晨三点被手机震醒——同事在群里@我:“你push了个啥?编译不过了。”…...

WELearn网课助手完整指南:5大核心功能彻底解放你的英语学习时间
WELearn网课助手完整指南:5大核心功能彻底解放你的英语学习时间 【免费下载链接】WELearnHelper 显示WE Learn随行课堂题目答案;支持班级测试;自动答题;刷时长;基于生成式AI(ChatGPT)的答案生成 项目地址: https://g…...