「大数据-2.0」安装Hadoop和部署HDFS集群
目录
一、下载Hadoop安装包
二、安装Hadoop
0. 安装Hadoop前的必要准备
1. 以root用户登录主节点虚拟机
2. 上传Hadoop安装包到主节点
3. 解压缩安装包到/export/server/目录中
4. 构建软链接
三、部署HDFS集群
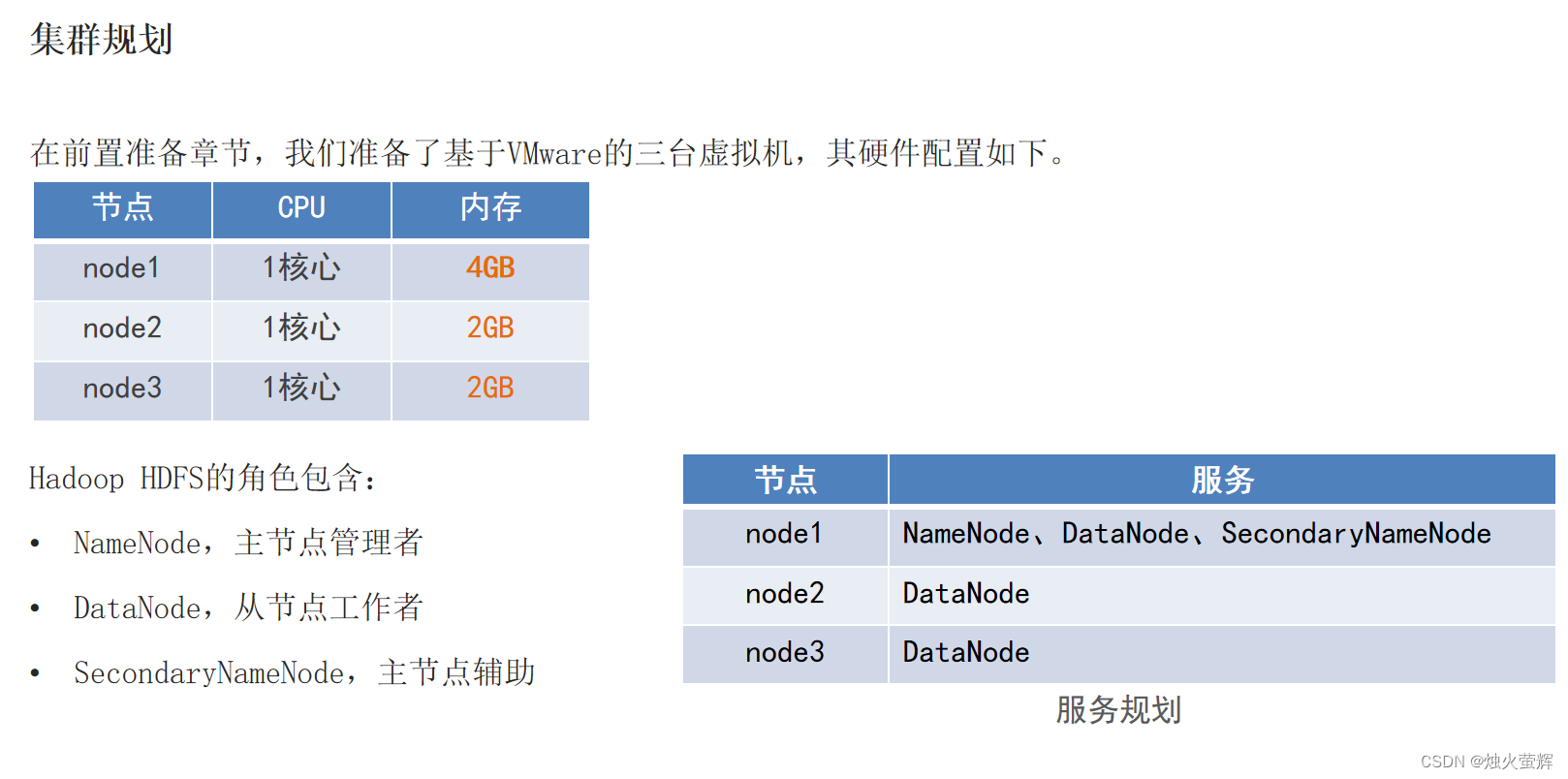
0. 集群部署规划
1. 进入hadoop安装包内
2 进入etc目录下的hadoop目录
3. 配置workers文件
4. 配置hadoop-env.sh文件
5.配置core-site.xml文件
6.配置hdfs-site.xml文件
7. 准备数据目录
8. 分发Hadoop文件夹
三、配置环境变量
四、为Hadoop用户授权
五、格式化HDFS文件系统
1. 格式化namenode
2. 一键启动hdfs集群
3. 使用jps检查运行中的进程
4. 查看HDFS WEBUI
六、拍摄快照保存配置好的虚拟机
七、启动和关闭HDFS集群
1. 一键启动HDFS集群
2. 一键关闭HDFS集群
一、下载Hadoop安装包
1. 官网下载
2. 百度网盘链接 提取码:2233
二、安装Hadoop
0. 安装Hadoop前的必要准备
在开始部署前,请确认已经完成前置准备中的服务器创建、固定IP、防火墙关闭、Hadoop用户创建、SSH免密、JDK部署等操作。 如果不确定,请看博主文章:http://t.csdn.cn/YlUi5
1. 以root用户登录主节点虚拟机
如博主的主节点为node1,所以在node1虚拟机中以root身份登录,进入/export/server/目录下。
2. 上传Hadoop安装包到主节点
将下载好的压缩包拖拽到远程终端软件 或 在远程终端软件中使用rz命令。
3. 解压缩安装包到/export/server/目录中
1. 进入/export/server/目录: cd /export/server/2. 解压到当前目录下: tar -zxvf hadoop-3.3.4.tar.gz
4. 构建软链接
ln -s /export/server/hadoop-3.3.4 hadoop
三、部署HDFS集群
0. 集群部署规划
1. 进入hadoop安装包内
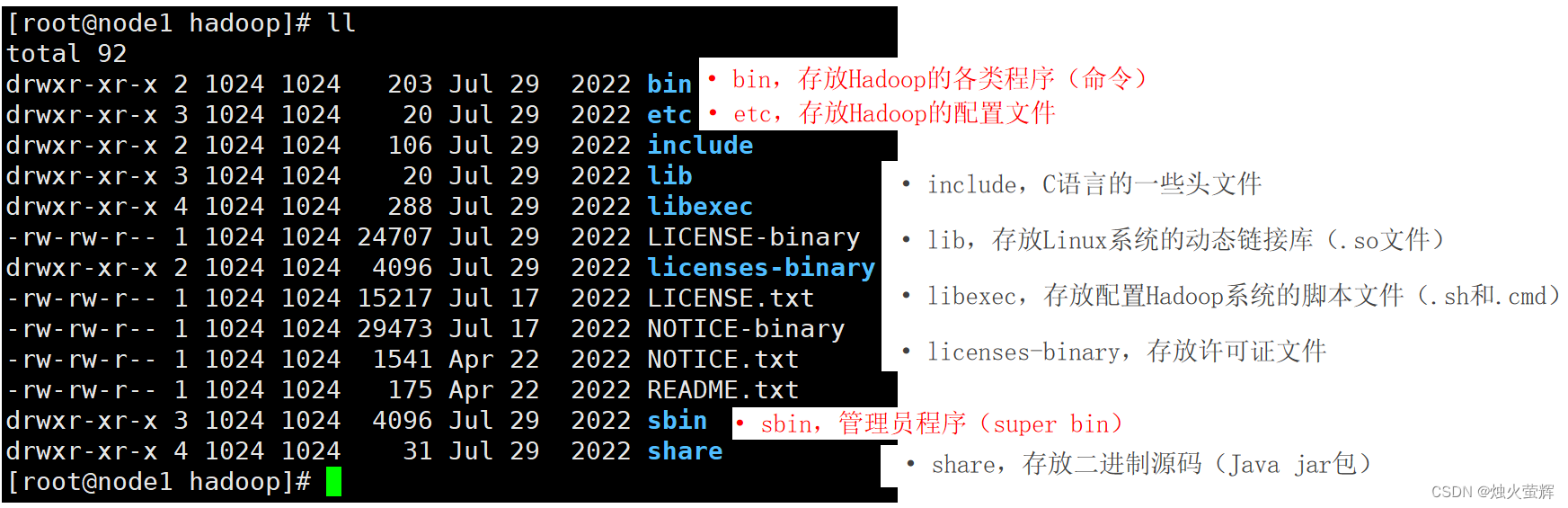
cd hadoopHadoop安装包的目录结构:
现在是集群部署的配置阶段,我们着重于etc目录。
2 进入etc目录下的hadoop目录
cd /etc/hadoop接下来主要要对以下四个文件进行配置:
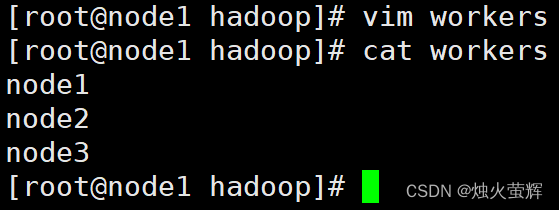
3. 配置workers文件
workers文件的作用是记录大数据集群中的从节点服务器。
配置步骤:
1. 使用vim打开workers: vim workers2. 按i进入插入模式3. 删除原来的lockhoot4. 写入: node1 node2 node35. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!强制保存并退出。
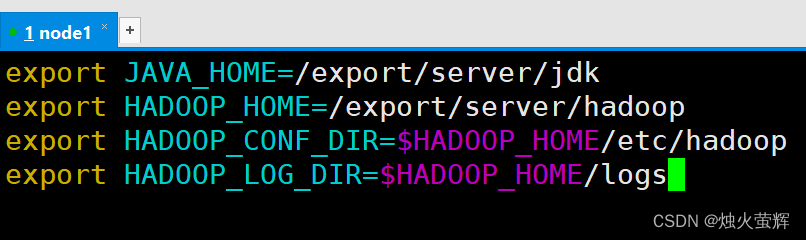
4. 配置hadoop-env.sh文件
hadoop-env.sh文件的作用是记录Hadoop在运行时会用到的一些环境变量。
配置步骤:
1. 使用vim打开hadoop-env.sh: vim hadoop-env.sh2. 按i进入插入模式3. 找个空白的地方(最上面)写入: export JAVA_HOME=/export/server/jdk export HADOOP_HOME=/export/server/hadoop export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_LOG_DIR=$HADOOP_HOME/logs4. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!强制保存并退出。说明: JAVA_HOME,指明JDK环境的位置在哪 HADOOP_HOME,指明Hadoop安装位置 HADOOP_CONF_DIR,指明Hadoop配置文件目录位置 HADOOP_LOG_DIR,指明Hadoop运行日志目录位置 通过记录这些环境变量, 来指明上述运行时的重要信息
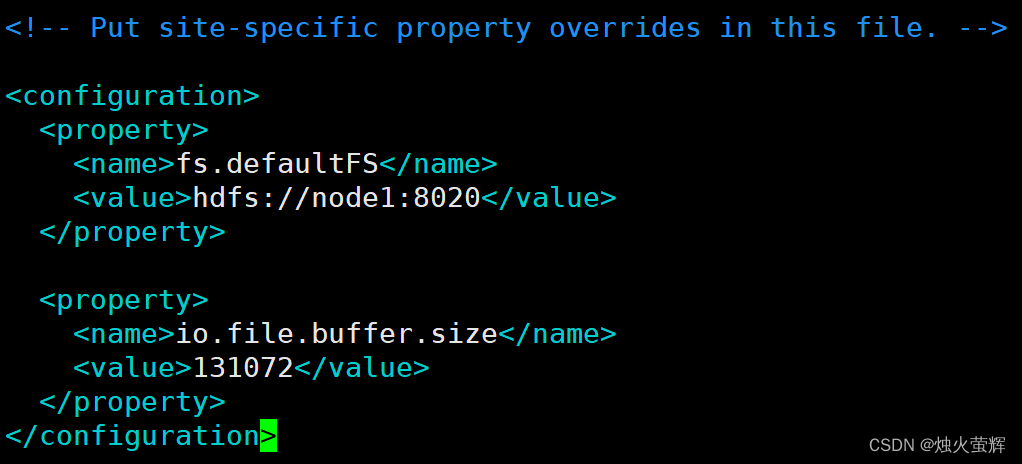
5.配置core-site.xml文件
该文件的作用是配置一些自定义设置,我们要在这里配置NameNode(主节点)的启动和缓冲区大小。
配置步骤:
1. 使用vim打开core-site.xml: vim core-site.xml2. 找到标签<configuration></configuration>3. 按i进入插入模式,在标签中间写入:<property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property>4. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!强制保存并退出。说明: 1.key:fs.defaultFS 含义:HDFS文件系统的网络通讯路径 值:hdfs://node1:8020 协议为hdfs:// namenode(主节点)为node1 namenode(主节点)通讯端口为8020 2.key:io.file.buffer.size 含义:io操作文件缓冲区大小 值:131072 bit 3.hdfs://node1:8020为整个HDFS内部的通讯地址,应用协议为hdfs://(Hadoop内置协议) 表明DataNode(从节点)将和node1的8020端口通讯,node1是NameNode(主节点)所在机器 此配置固定了node1必须启动NameNode(主节点)进程
6.配置hdfs-site.xml文件
该文件的作用也是配置一些自定义设置,我们要在这里配置:默认创建的文件权限、主节点数据的存储位置、NameNode(主节点)允许哪几个节点的DataNode(从节点)连接(即允许加入集群)、hdfs默认块大小、Namenode(主节点)处理的并发线程数、从DataNode(从节点)的数据存储目录。
配置步骤:
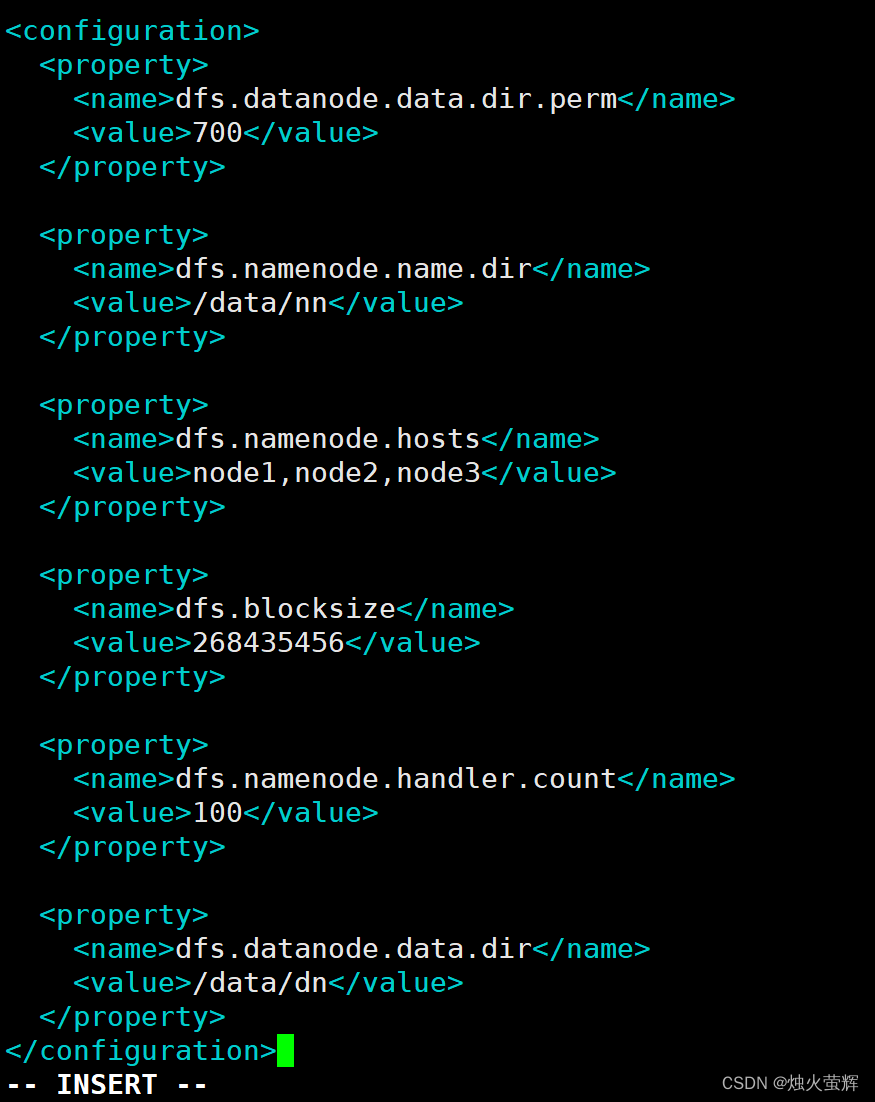
1. 使用vim打开hdfs-site.xml: vim hdfs-site.xml2. 找到标签<configuration></configuration>3. 按i进入插入模式,在标签中间写入:<property><name>dfs.datanode.data.dir.perm</name><value>700</value></property><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><property><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property>4. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!强制保存并退出。说明: 1.key:dfs.datanode.data.dir.perm 含义:hdfs文件系统,默认创建的文件权限设置 值:700,即:rwx------ 2.key:dfs.namenode.name.dir 含义:NameNode(主节点)元数据的存储位置 值:/data/nn,在node1节点的/data/nn目录下 3.key:dfs.namenode.hosts 含义:NameNode(主节点)允许哪几个DataNode(从节点)连接(即允许加入集群) 值:node1、node2、node3,这三台服务器被授权 4.key:dfs.blocksize 含义:hdfs默认块大小 值:268435456(256MB) 5.key:dfs.namenode.handler.count 含义:Namenode(主节点)处理的并发线程数 值:100,以100个并行度处理文件系统的管理任务 6.key:dfs.datanode.data.dir 含义:DataNode(从节点)的数据存储目录 值:/data/dn,即数据存放在node1、node2、node3,三台机器的/data/dn内
7. 准备数据目录
在之前的配置中,只是指定了主节点和从节点的数据放在哪个文件,但我们还没有真正的创建这些文件,现在我们就是要创建这些文件。
在上一步中的配置中,我们把 namenode数据存放在node1虚拟机的/data/nn目录下;datanode数据存放在node1、node2、node3虚拟机的/data/dn目录下。
所以我们要在node1虚拟机创建/data/nn目录和/data/dn目录;在node2、node3虚拟机创建/data/dn目录(不要少了data前面的/)。
步骤:
1.在node1虚拟机: mkdir -p /data/nn mkdir -p /data/dn2.在node2和node3虚拟机: mkdir -p /data/dn
8. 分发Hadoop文件夹
目前,已经基本完成Hadoop的配置操作,可以从node1将hadoop安装文件夹远程复制到node2、node3(通过scp命令)。
步骤:
1. 在node1虚拟机执行如下命令 cd /export/server scp -r hadoop-3.3.4 node2:`pwd`/ scp -r hadoop-3.3.4 node3:`pwd`/2. 在node2执行如下命令,为hadoop配置软链接 ln -s /export/server/hadoop-3.3.4 /export/server/hadoop3. 在node3执行如下命令,为hadoop配置软链接 ln -s /export/server/hadoop-3.3.4 /export/server/hadoop

三、配置环境变量
为了方便我们操作Hadoop,可以将Hadoop的一些脚本、程序配置到PATH中(通过配置profile文件),方便后续使用。
1. 修改/etc目录下的profile文件:
1. 使用vim打开/etc下的profile文件: vim /etc/profile2. 按i进入插入模式,在末尾追加写入: export HADOOP_HOME=/export/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin3. 按下Esc退出插入模式,按下Shift+:进入底行模式,按下wq!强制保存并退出。
2. 启动上面的配置
source /etc/profile
3. 在node2和node3虚拟机中重复上面的步骤。
四、为Hadoop用户授权
到了这里,hadoop部署的准备工作基本完成,为了确保安全,hadoop系统不以root用户启动,我们以普通用户hadoop来启动整个Hadoop服务。所以,现在需要对文件权限进行授权。
1. 以root身份,在node1、node2、node3三台虚拟机上均执行如下命令:
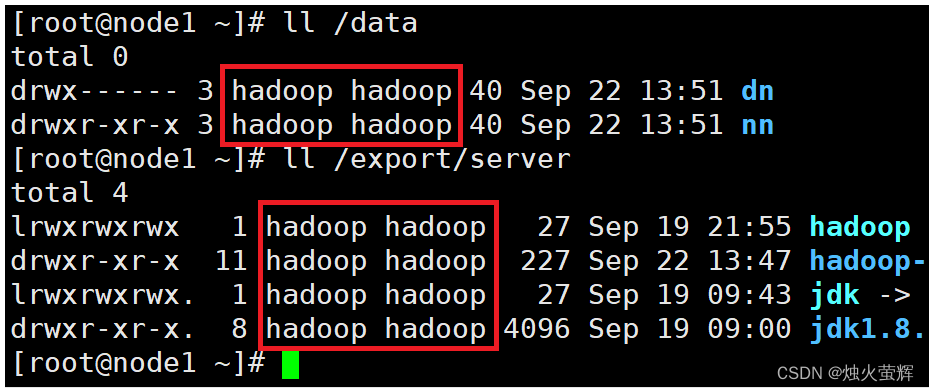
# 以root身份,在三台服务器上均执行 chown -R hadoop:hadoop /data chown -R hadoop:hadoop /export
2. 检查
五、格式化HDFS文件系统
前期准备全部完成,现在对整个文件系统执行初始化,以下命令在主节点虚拟机node1中执行即可。
1. 格式化namenode
1. 在主节点虚拟机node1中切换到hadoop用户 su - hadoop 2. 格式化namenode hadoop namenode -format这样表示格式化成功了
2. 一键启动hdfs集群
1. 回到根目录 cd 2. 一键启动hdfs集群 start-dfs.sh
3. 使用jps检查运行中的进程
在终端中输入jps,如果显示内容像图片中的一样基本上表示整个配置都成功了:
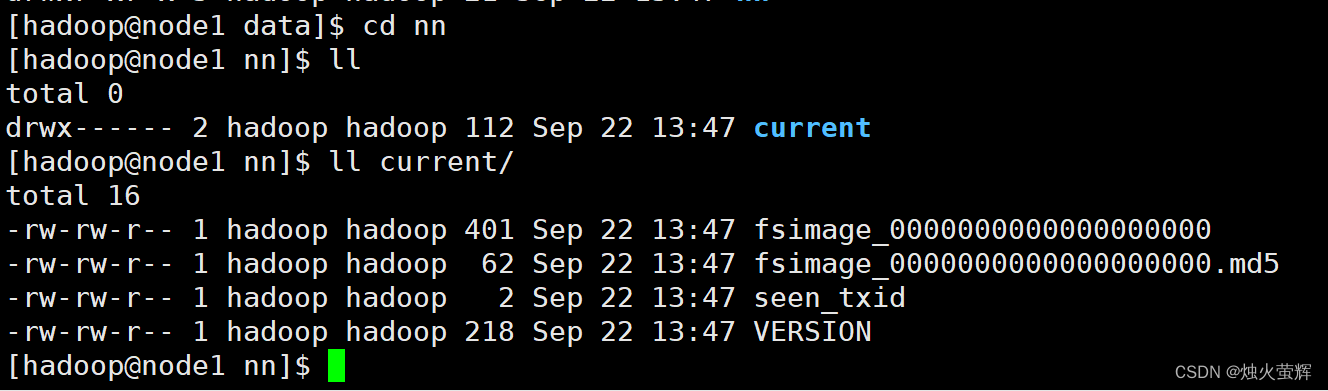
如果jps中没有Datanode,证明clusterID有问题:
原因是多次格式化NameNode会重新生成新的clusterID(集群ID)
我们要做的是在主节点node1下找到正确的clusterID,然后更改所有从节点的clusterID。
步骤:
1. 进入node1虚拟机下的/data/nn/current/目录 cd /data/nn/current/2. 打开VERSION文件 vim VERSION3. 复制clusterID4. 退出,然后进入/data/dn/current/目录 cd /data/dn/current/5. 打开VERSION文件, 然后用刚才复制的内容替换这里的clusterID6. 进入node2虚拟机下的/data/dn/current/目录 cd /data/dn/current/7. 打开VERSION文件, 然后用刚才复制的内容替换这里的clusterID8. 进入node3虚拟机下的/data/dn/current/目录 cd /data/dn/current/9. 打开VERSION文件, 然后用刚才复制的内容替换这里的clusterID
4. 查看HDFS WEBUI
启动Hadoop后,可以在浏览器打开: http://node1:9870,即可查看到hdfs文件系统的管理网页。
能够打开这个网址,且Live Nodes 为3,就表示我们的Hadoop部署完全成功了!

六、拍摄快照保存配置好的虚拟机
0. 为什么需要拍摄快照?
拍快照相当于给当前虚拟机的配置做一个备份,将来有问题,直接按照快照还原虚拟机即可,不需要删除再重新配置。
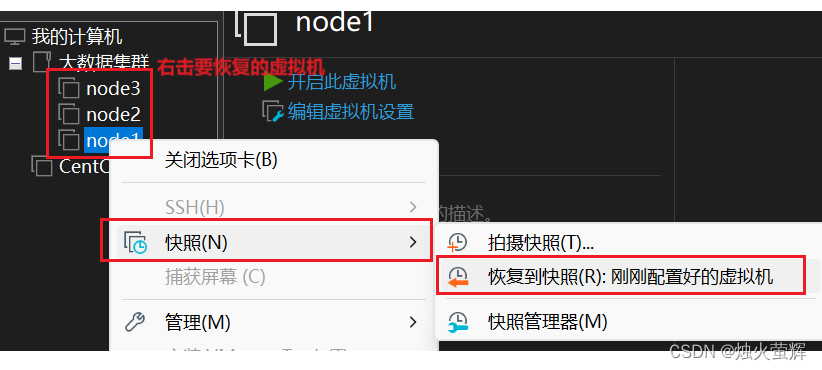
1. 在VMware将所有虚拟机关机
2. 拍摄快照
3. 如何使用快照恢复?


七、启动和关闭HDFS集群
Hadoop HDFS组件内置了HDFS集群的一键启停脚本。
1. 一键启动HDFS集群
$HADOOP_HOME/sbin/start-dfs.sh
2. 一键关闭HDFS集群
$HADOOP_HOME/sbin/stop-dfs.sh
关闭虚拟机前一定要先关闭HDFS集群,然后用 init 0 断开Xshell等远程连接!
------------------------END-------------------------
才疏学浅,谬误难免,欢迎各位批评指正。
相关文章:
「大数据-2.0」安装Hadoop和部署HDFS集群
目录 一、下载Hadoop安装包 二、安装Hadoop 0. 安装Hadoop前的必要准备 1. 以root用户登录主节点虚拟机 2. 上传Hadoop安装包到主节点 3. 解压缩安装包到/export/server/目录中 4. 构建软链接 三、部署HDFS集群 0. 集群部署规划 1. 进入hadoop安装包内 2 进入etc目录下的hadoop…...
文档在线预览word、pdf、excel文件转html以实现文档在线预览
目录 一、前言 1、aspose2 、poi pdfbox3 spire二、将文件转换成html字符串 1、将word文件转成html字符串 1.1 使用aspose1.2 使用poi1.3 使用spire2、将pdf文件转成html字符串 2.1 使用aspose2.2 使用 poi pbfbox2.3 使用spire3、将excel文件转成html字符串 3.1 使用aspose…...

FFmpeg视音频分离器----向雷神学习
雷神博客地址:https://blog.csdn.net/leixiaohua1020/article/details/39767055 本程序可以将封装格式中的视频码流数据和音频码流数据分离出来。 在该例子中, 将FLV的文件分离得到H.264视频码流文件和MP3 音频码流文件。 注意: 这个是简化版…...

CentOS 8开启bbr
CentOS 8 默认内核版本为 4.18.x,内核版本高于4.9 就可以直接开启 BBR,所以CentOS 8 启用BBR非常简单不需要再去升级内核。 开启bbr echo "net.core.default_qdiscfq" >> /etc/sysctl.conf echo "net.ipv4.tcp_congestion_contro…...
Redis的安装与基本使用
文章目录 Linux 环境下安装Redis下载Redis 安装包解压安装包安装Redis进入redis安装包下编译并且安装到指定目录下 启动redis配置远程访问找到Redis.config文件 Windows 环境下安装Redis说明官方提供方式安装或启用WSL2在WSL(Ubuntu)上安装Redis启动Redi…...
2014 款金旅牌小型客车 发动机怠速抖动、加速无力
故障现象 一辆2014款金旅牌小型客车,搭载JM491Q-ME发动机,累计行驶里程约为20万km。车主反映,最近该车发动机怠速抖动、加速无力,且经常缺少冷却液。 故障诊断 根据车主描述的故障现象,初步判断该车气缸垫损坏&#…...

R语言逻辑回归、决策树、随机森林、神经网络预测患者心脏病数据混淆矩阵可视化...
全文链接:https://tecdat.cn/?p33760 众所周知,心脏疾病是目前全球最主要的死因。开发一个能够预测患者心脏疾病存在的计算系统将显著降低死亡率并大幅降低医疗保健成本。机器学习在全球许多领域中被广泛应用,尤其在医疗行业中越来越受欢迎。机器学习可…...

网站被劫持了怎么办
网站被劫持了怎么办 建议新建一个index.html文件,文件中只写几个数字,上传到网站根目录,然后访问网站域名,看看是不是正常,从而可以确定是程序问题还是域名被劫持的问题。 如果是域名被劫持,你可以登录你的…...

【面试题精讲】Java包装类缓存机制
有的时候博客内容会有变动,首发博客是最新的,其他博客地址可能会未同步,认准https://blog.zysicyj.top 首发博客地址[1] 面试题手册[2] 系列文章地址[3] 1. 什么是 Java 包装类缓存机制? Java 中的包装类(Wrapper Class)是为了将…...

网络相关知识
0 socket SOCK_DGRAM #无连接UDP SOCK_STREAM #面向连接TCP 1 UDP 1.1 检测UDP yum install -y nc 使用netcat测试连通性 服务器端启动 UDP 30003 端口 nc -l -u 30003 客户端连接服务器的30003端口(假设服务的IP地址是119.23.67.12) nc -u 119…...

商品冷启动推荐综述
About Me: LuckBoyPhd/Resume (github.com) (1)一种基于三部图网络的协同过滤算法 推荐系统是电子商务领域最重要的技术之一,而协同过滤算法又是推荐系统用得最广泛的.提出了一种基于加权三部图网络的协同过滤算法,用户、产品及标签都被考虑到算法中,并且研究了标签结点的度对…...
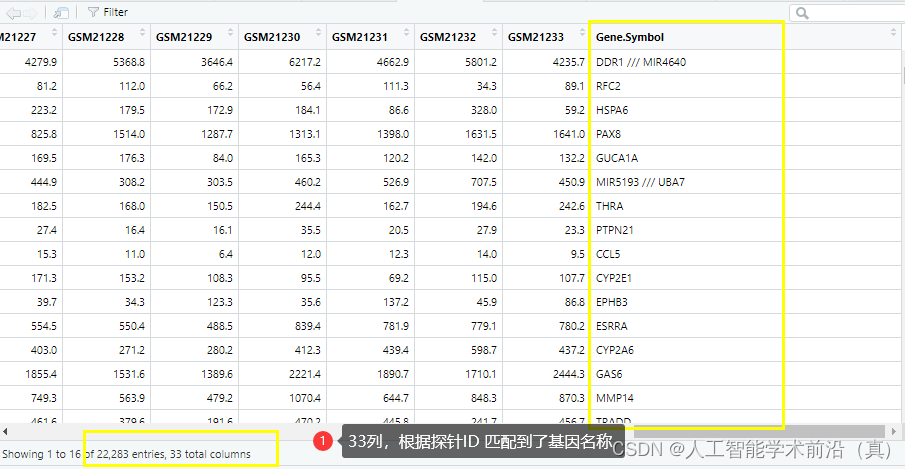
GEO生信数据挖掘(二)下载基因芯片平台文件及注释
检索到目标数据集后,开始数据挖掘,本文以阿尔兹海默症数据集GSE1297为例 目录 下载平台文件 1.AnnotGPL参数改为TRUE,联网下载芯片平台的soft文件。(国内网速奇慢经常中断) 2.手工去GEO官网下载 转换芯片探针ID为gene name 拓…...
淘宝电商必备的大数据应用
在日常生活中,大家总能听到“大数据”“人工智能”的说法。现在的大数据技术应用,从大到巨大科学研究、社会信息审查、搜索引擎,小到社交联结、餐厅推荐等等,已经渗透到我们生活中的方方面面。到底大数据在电商行业可以怎么用&…...

Docker版部署RocketMQ开启ACL验证
一、拉取镜像 docker pull apache/rocketmq:latest 二、准备挂载目录 mkdir /usr/local/rocketmq/data mkdir /usr/local/rocketmq/conf 三、运行 docker run \ -d \ -p 9876:9876 \ -v /usr/local/rocketmq/data/logs:/home/rocketmq/logs \ -v /usr/local/rocketmq/data…...
【RabbitMQ实战】04 RabbitMQ的基本概念:Exchange,Queue,Channel等
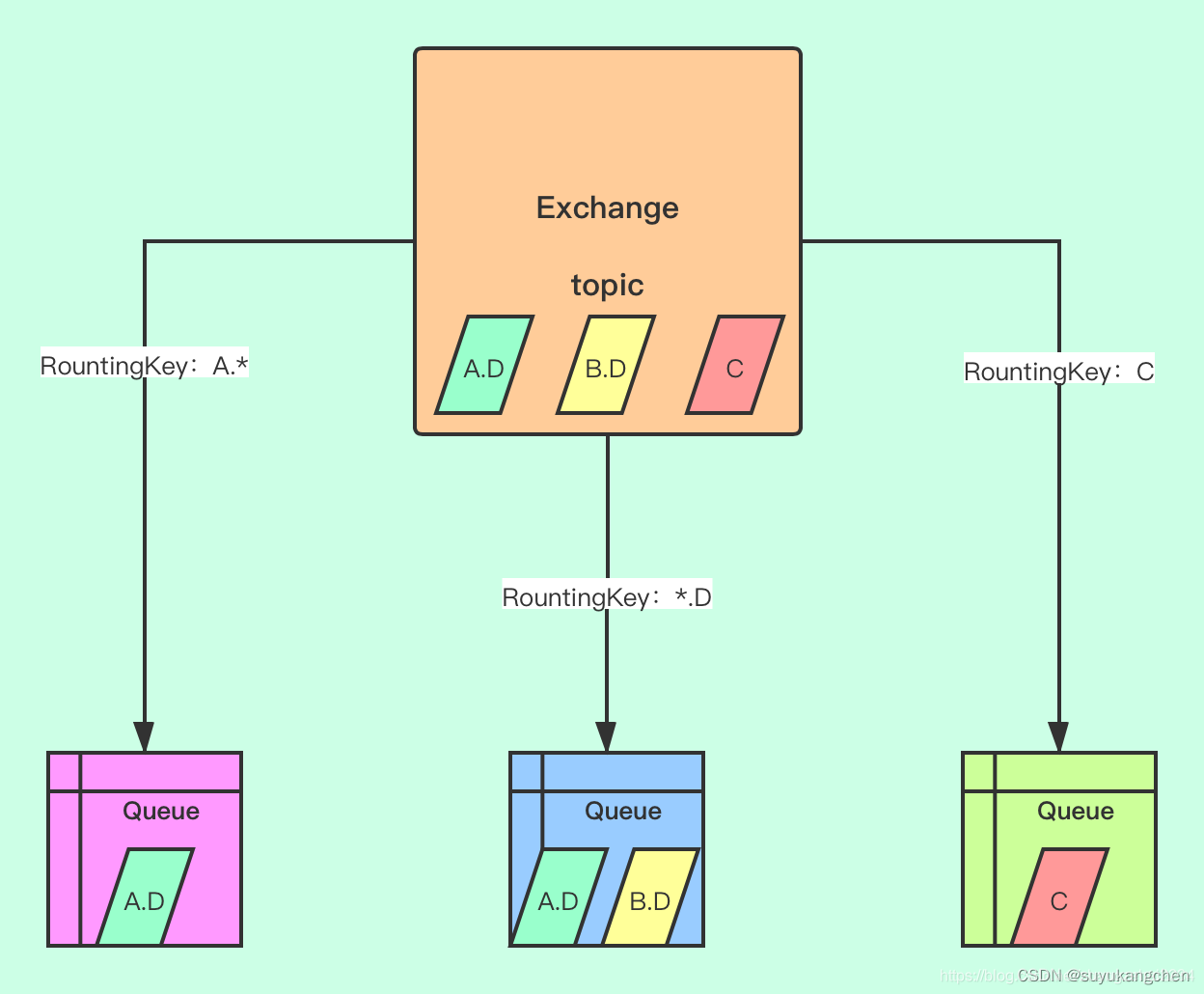
一、简介 Message Queue的需求由来已久,80年代最早在金融交易中,高盛等公司采用Teknekron公司的产品,当时的Message queuing软件叫做:the information bus(TIB)。 TIB被电信和通讯公司采用,路透…...

APACHE NIFI学习之—RouteOnAttribute
RouteOnAttribute 描述: 使用属性表达式语言根据其属性路由数据流,每个表达式必须返回Boolean类型的值(true或false)。 标签: attributes, routing, Attribute Expression Language, regexp, regex, Regular Expression, Expression Language, 属性, 路由, 表达式, 正则…...
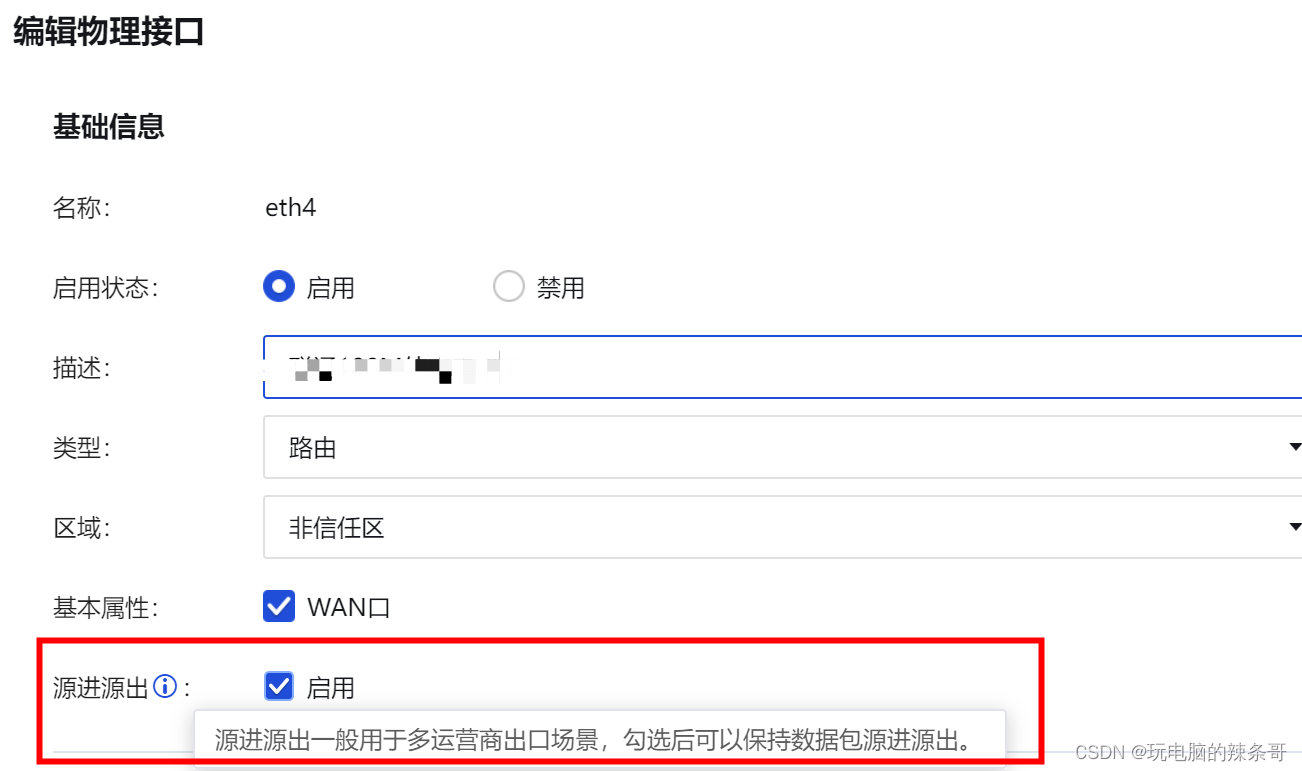
防火墙网络接口下面多个外网地址,只有第一地址可以访问通其他不通
环境: 主备防火墙 8.0.75 AF-2000-FH2130B-SC 问题描述: 两台防火墙双击热备,高可用防火墙虚拟网络接口Eth4下面有多个外网地址,只有第一地址可以访问通其他不通 解决方案: 1.检查防火墙路由设置(未解决…...

【HTTP】URL结构、HTTP请求和响应的报文格式、HTTP请求的方法、常见的状态码、GET和POST有什么区别、Cookie、Session等重点知识汇总
目录 URL格式 HTTP请求和响应报文的字段? HTTP请求方法 常见的状态码 GET 和 POST 的区别 Cookie 和 Session URL格式 ?:是用来分割URL的主体部分(通常是路径)和查询字符串(query string)…...

苹果mac电脑显示内存不足如何解决?
忍痛删应用、删文档、删照片视频等等一系列操作都是众多Mac用户清理内存空间的方法之一,悲催的是一顿“猛如虎的操作”下,释放出来的内存空间却少的可怜,原因很简单,这样释放内存空间是无效的。如何合理有效的清理内存空间&#x…...

如何在Windows 10上安装Go并搭建本地编程环境
引言 Go是在谷歌的挫折中诞生的编程语言。开发人员不得不不断地选择一种执行效率高但需要长时间编译的语言,或者选择一种易于编程但在生产环境中运行效率低的语言。Go被设计为同时提供这三种功能:快速编译、易于编程和在生产中高效执行。 虽然Go是一种通用的编程语…...
晶面并构建真空层,一步步教你分析晶体生长)
保姆级教程:用Materials Studio切(111)晶面并构建真空层,一步步教你分析晶体生长
从零开始掌握Materials Studio晶体表面建模:以(111)晶面为例的完整实战指南 在材料模拟与计算化学领域,精确构建晶体表面模型是研究催化反应、界面特性以及材料生长机制的基础环节。Materials Studio作为业界广泛采用的模拟平台,其表面建模功…...

电气噪声抑制实战:从原理到电磁屏蔽的电子系统稳定性设计
1. 项目概述:无处不在的“隐形杀手”——电气噪声作为一名在电子硬件开发一线摸爬滚打了十多年的工程师,我处理过无数稀奇古怪的故障。很多时候,问题不是出在核心算法或主控芯片上,而是一个看不见摸不着的“隐形杀手”——电气噪声…...
利用CTranslate2与INT8量化,实现Whisper语音识别7倍加速
1. 项目概述:当Whisper遇上CTranslate2,语音转文字的“涡轮增压”如果你尝试过OpenAI的Whisper模型来做语音识别,大概率会被它的准确性所折服,但同时也可能被其缓慢的推理速度所困扰。尤其是在处理长音频文件或需要批量处理时&…...

卡梅德生物技术快报|骆驼纳米抗体:从原核表达、高通量测序到分子对接全流程实现
1. 问题背景(技术痛点)靶向结合分子开发中,传统抗体制备存在:分子量大,扩散与穿透效率有限;文库构建与淘选周期长,难以规模化;原核表达与纯化体系不稳定,批次差异大&…...

全球BGA锡球市场高速成长:2025年2.55亿美元筑基,2032年剑指4.43亿,8.3%CAGR锚定长期高增长逻辑
BGA锡球(BGA Solder Ball) 是用于替代IC元件封装结构中引脚的核心连接件,满足电性互连及机械连接的双重要求。简而言之,它是BGA封装工艺中不可或缺的焊接材料。QYResearch调研显示,2025年全球BGA锡球市场规模大约为2.5…...

轻量级网页自动化工具 xiaoclaw:基于 CDP 的高效实践指南
1. 项目概述:一个轻量级、可编程的网页自动化工具最近在折腾一些需要自动处理网页数据的小项目,比如定时抓取某个网站的价格变动、自动填写表单、或者模拟一些重复性的点击操作。一开始想用传统的Selenium,但总觉得它有点“重”,启…...

水介导软模板 COF|MS 模拟细节全拆解
#MaterialsStudio #COF 模拟 #Nature 子刊 #科研干货 #分子模拟🔥Nature 子刊 COF 重磅突破!四川大学团队首次用软模板法做出有序分级孔 COF里面的 Materials Studio 模拟部分写得超规范新手做 COF 晶体模拟直接抄作业👇✅ 模拟工具与核心方法…...

Cursor Pro功能完全解锁指南:三步实现免费无限使用终极方案
Cursor Pro功能完全解锁指南:三步实现免费无限使用终极方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...

【信息科学与工程学】【通信工程】第四十四篇 城域网络设计10 城域网中涉及的数学物理、数学化学及数学地理01
城域网中涉及的数学、数学物理、数学化学及数学地理方法,并按照您要求的表格格式进行呈现。 编号 领域 类型 城域网领域 子领域 城域网架构 城域网中的数学/数学物理/数学化学方法/算法/现象 现象描述/算法/函数逐步推理思考的数学方程式(完整的参数列表、常数、变量、…...

苹果手机照片去背景怎么操作?2026年最全工具对比指南
最近有个朋友问我,怎样才能快速给iPhone拍的照片去背景,特别是想换成不同颜色的背景或者制作透明背景图。我才意识到,现在很多人其实都需要这样的功能——无论是为了制作证件照、商品图,还是用于社交媒体。今天我就把这些年用过的…...