深度学习之“制作自定义数据”--torch.utils.data.DataLoader重写构造方法。
深度学习之“制作自定义数据”–torch.utils.data.DataLoader重写构造方法。
前言:
本文讲述重写torch.utils.data.DataLoader类的构造方法,对自定义图片制作类似MNIST数据集格式(image, label),用于自己的Pytorch神经网络模型运行,代码已整理打包上传网盘,文末下载。tensor数据格式(N,C,H,W)
-
N:Batch,批处理大小,表示一个batch中的图像数量
-
C:Channel,通道数,表示一张图像中的通道数
-
H:Height,高度,表示图像垂直维度的像素数
-
W:Width,宽度,表示图像水平维度的像素数
-
例如下图输出一个批次的训练集数据就是一批次64张图片(N),3维通道数(C),一张图片高度32像素(H),一张图片宽度32像素(W)

步骤一
对图片整理分类(python代码os库进行对文件夹创建和图片的移动到文件夹),以文件夹名为图片的种类名,如下图所示:

步骤二
对所有种类文件夹进行遍历读入,将每个(图片的文件路径 )和(对应的标签)写入到txt文本中,结果为trian.txt 和 test.txt,作为训练集合测试集的数据准备。代码为CreateDataset01.py
# -*- coding: utf-8 -*-
# @Time : 2023/1/26/026 18:48
# @Author : LeeSheel
# @File : CreateDataset01.py
# @Project : 深度学习'''
生成训练集和测试集,保存在txt文件中本地电脑,只选取出3000张图片为训练集进行模型运行数据
'''import os
import random
train_ratio = 0.6
test_ratio = 1-train_ratio
train_list, test_list = [],[] #创建两个个列表,里面存放 图片路径+‘\t’+图片标签
data_list = []rootdata = r"D:\FreeDesk\大创项目\手写藏文字母识别\手写藏文字母数据\总数据"for root,dirs,files in os.walk(rootdata):# print(root)# print(dirs)# print(files)#拼接每个图片的绝对文件路径:for i in range(int(len(files)*train_ratio)):# print(files[i])#输出的是每个图片的名称# print(root+"---"+files[i]) #shu输出每个每个图片的文件夹路径----图片名称# print(os.path.join(root, files[i])) #拼接路径,# print(str(root).split("/")[-1]) #dui对root进行字符串切割,获得最后一个元素,代表每个图片的标签。class_flag = str(root).split("\\")[-1] #biaoqain标签data = os.path.join(root, files[i]) + '\t' + str(class_flag) + '\n'train_list.append(data)for i in range(int(len(files) * train_ratio),len(files)):# print(i)class_flag = str(root).split("\\")[-1] # biaoqain标签# print(class_flag)# print(files[i])data = os.path.join(root, files[i]) + '\t' + str(class_flag) + '\n'test_list.append(data)# print(train_list)
random.shuffle(train_list)
random.shuffle(test_list)with open('train.txt','w',encoding='UTF-8') as f:for train_img in train_list:f.write(str(train_img))with open('test.txt','w',encoding='UTF-8') as f:for test_img in test_list:f.write(test_img)## 随机抽取3000个作为本地train.txt 以及1000个作为本地test.txt# from random import sample
#
# print(sample(train_list, 30000)) # 随机抽取5个元素
# local_train_list = sample(train_list, 30000)
# print("dsdfsdfs")
# print(len(local_train_list))
# local_test_list = sample(test_list, 10000)
#
# with open('localtrain.txt','w',encoding='UTF-8') as f:
# for train_img in local_train_list:
# f.write(str(train_img))
#
# with open('localtest.txt','w',encoding='UTF-8') as f:
# for test_img in local_test_list:
# f.write(test_img)得到txt结果:(文件路径与标签以空格隔开):

步骤三
将步骤二得到的train.txt 和 test.txt 转化为train_loader 和 test_loader,重写LoadData类的构造方法,将train.txt文本转为train_dataset ,将test.txt转为test_dataset,最后再使用torch.utils.data.DataLoader()进行转为train_loader 和 test_loader: 就可以用于调用模型训练了。
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=64,shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=64,shuffle=True)重写LoadData类的构造方法代码(这里的transforms.Normalize()图像标准化,可以使用下文的python代码求出mean和std,填入标准化数值。),步骤三代码为 CreateDataloader02.py:
# -*- coding: utf-8 -*-
# @Time : 2023/1/26/026 18:56
# @Author : LeeSheel
# @File : CreateDataloader02.py
# @Project : 深度学习
import torch
from PIL import Image
import torchvision.transforms as transforms
from PIL import ImageFile
ImageFile.LOAD_TRUNCATED_IMAGES = True
from torch.utils.data import Datasetclass LoadData(Dataset):def __init__(self, txt_path, train_flag=True):self.imgs_info = self.get_images(txt_path)self.train_flag = train_flagself.train_tf = transforms.Compose([# 随机旋转图片transforms.RandomHorizontalFlip(),# 将图片尺寸resize到32x32transforms.Resize((32, 32)),# 将图片转化为Tensor格式transforms.ToTensor(),# 正则化(当模型出现过拟合的情况时,用来降低模型的复杂度)transforms.Normalize((0.96934927, 0.9696228, 0.9695143), (0.124204025, 0.12326231, 0.12356147)) # 图像标准化])self.val_tf = transforms.Compose([# 将图片尺寸resize到32x32transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.96934927, 0.9696228, 0.9695143), (0.124204025, 0.12326231, 0.12356147))])def get_images(self, txt_path):with open(txt_path, 'r', encoding='utf-8') as f:imgs_info = f.readlines()imgs_info = list(map(lambda x:x.strip().split('\t'), imgs_info))return imgs_infodef __getitem__(self, index):img_path, label = self.imgs_info[index]img = Image.open(img_path)img = img.convert('RGB')if self.train_flag:img = self.train_tf(img)else:img = self.val_tf(img)label = int(label)return img, labeldef __len__(self):return len(self.imgs_info)train_dataset = LoadData("train.txt", True)print("训练接数据个数:", len(train_dataset))
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,batch_size=64,shuffle=True)
for image, label in train_loader:print(image.shape)print(image)# img = transform_BZ(image)# print(img)print(label)breaktest_dataset = LoadData("test.txt", False)
print("测试集数据个数:", len(test_dataset))
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,batch_size=64,shuffle=True)
求图片标准化transforms.Normalize()参数 代码
# -*- coding: utf-8 -*-
# @Time : 2023/1/31/031 18:18
# @Author : LeeSheel
# @File : 计算std和mea.py
# @Project : 深度学习
import numpy as np
import cv2
import os# img_h, img_w = 32, 32
img_h, img_w = 32, 32 # 经过处理后你的图片的尺寸大小
means, stdevs = [], []
img_list = []imgs_path = "D:\\0" # 数据集的路径采用绝对引用
imgs_path_list = os.listdir(imgs_path)len_ = len(imgs_path_list)
i = 0
for item in imgs_path_list:img = cv2.imread(os.path.join(imgs_path, item))img = cv2.resize(img, (img_w, img_h))img = img[:, :, :, np.newaxis]img_list.append(img)i += 1print(i, '/', len_)imgs = np.concatenate(img_list, axis=3)
imgs = imgs.astype(np.float32) / 255.for i in range(3):pixels = imgs[:, :, i, :].ravel() # 拉成一行means.append(np.mean(pixels))stdevs.append(np.std(pixels))# BGR --> RGB , CV读取的需要转换,PIL读取的不用转换
means.reverse()
stdevs.reverse()print("normMean = {}".format(means))
print("normStd = {}".format(stdevs))
代码下载:
链接:https://pan.baidu.com/s/1fa_gdLYXagu65P2uYpepqA?pwd=xx78
提取码:xx78

相关文章:
深度学习之“制作自定义数据”--torch.utils.data.DataLoader重写构造方法。
深度学习之“制作自定义数据”–torch.utils.data.DataLoader重写构造方法。 前言: 本文讲述重写torch.utils.data.DataLoader类的构造方法,对自定义图片制作类似MNIST数据集格式(image, label),用于自己的Pytorc…...
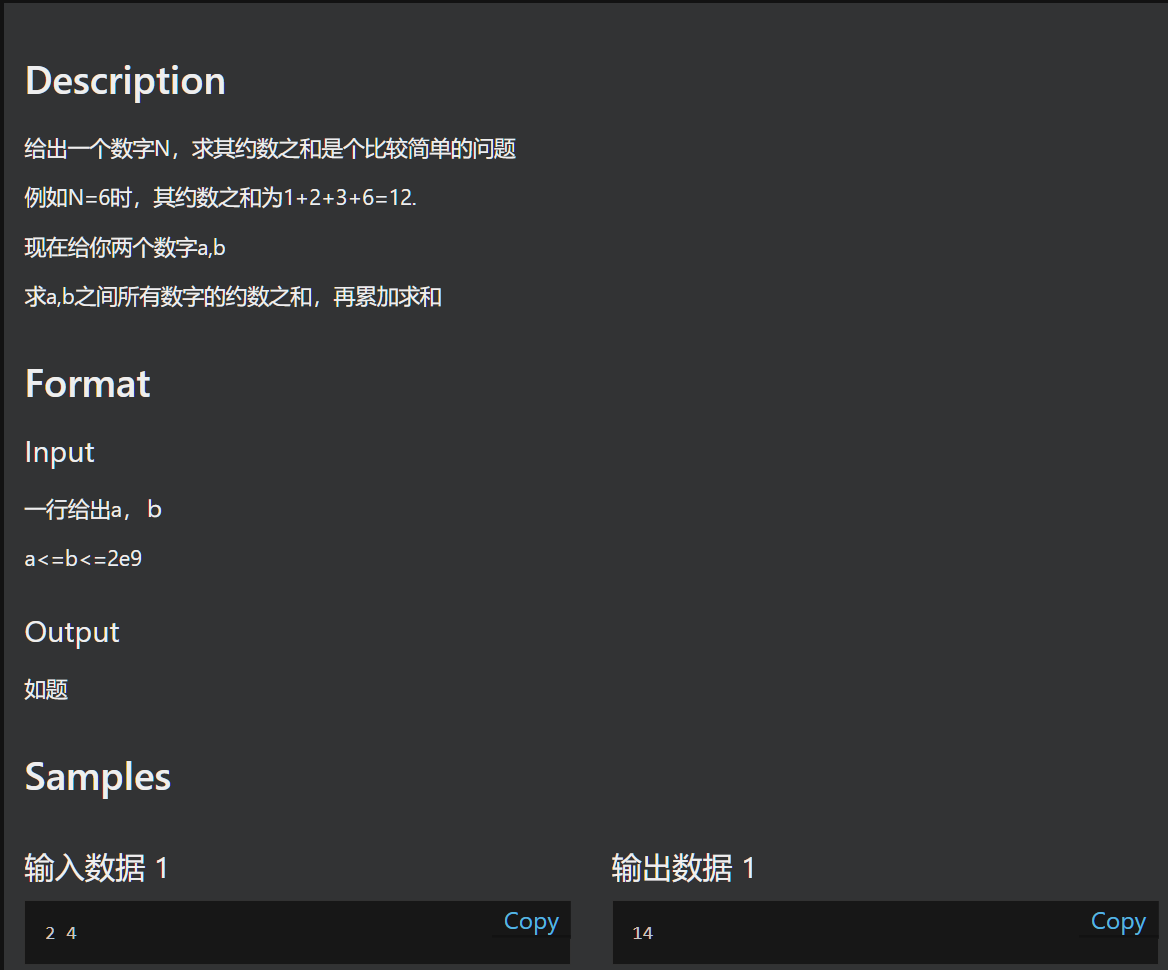
#G. 求约数个数之六
我们先求到区间[1..b]之间的所有约数之和于是结果就等于 [1..b]之间的所有约数之和减去[1..a-1]之间的约数之和很明显这两个问题是同性质的问题,只是右端点不同罢了.明显对于1到N之间的数字,其约数范围也为1到N这个范围内。于是我们可以枚举约数L,当然这…...

如何为Java文件代码签名及添加时间戳?
Java是一种流行的编程语言,大多数组织都使用它来开发业务应用程序。由于其高使用率,攻击者总是试图找到其中的漏洞并基于它利用软件。为了防止此类攻击, 为 Java 文件(.jar)进行代码签名并添加时间戳,可以防…...

Xamarin.Forsm for Android 显示 PDF
背景 某些情况下,需要让用户阅读下发的文件,特别是红头文件,这些文件一般都是使用PDF格式下发,这种文件有很重要的一点就是不能更改。这时候就需要使用原文件进行展示。 Xamarin.Forms Android 中的 WebView 控件是不能直接显示的…...

RK3399平台开发系列讲解(LED子系统篇)LED子系统详解
🚀返回专栏总目录 文章目录 一、设备树编写二、LED子系统2.1、用户态2.2、内核驱动三、驱动代码3.1、平台设备驱动的注册3.2、平台设备驱动的probe四、使用方法沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇将详细介绍LED子系统。 一、设备树编写 节点属性添加…...
 的数据结构)
LeetCode 432. 全 O(1) 的数据结构
LeetCode 432. 全 O(1) 的数据结构 难度:hard\color{red}{hard}hard 题目描述 请你设计一个用于存储字符串计数的数据结构,并能够返回计数最小和最大的字符串。 实现 AllOneAllOneAllOne 类: AllOne()AllOne()AllOne() 初始化数据结构的对…...
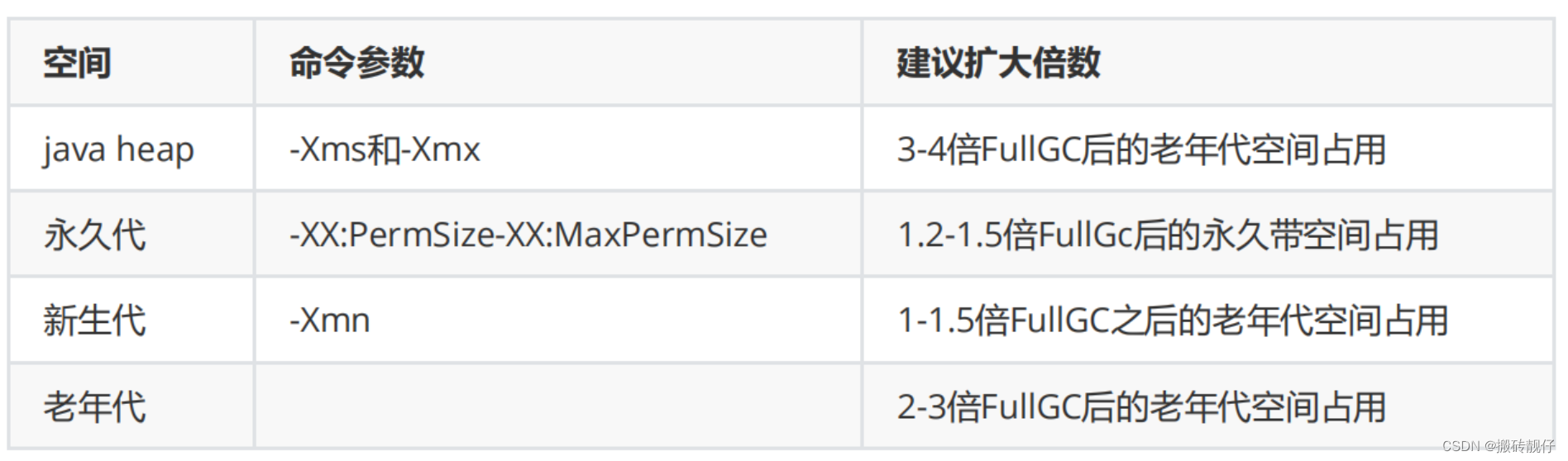
再析jvm
前言 希望自己每一次学习都有不同的理解 文章目录前言1. jvm的组成取消永久代使用元空间原因2. 运行时数据区3. 堆栈区别队列和栈,队列先进先出,栈先进后出从栈顶弹出4. GC、内存溢出、垃圾回收4.1 如何确定引用是否会被回收4.1.1 Java中的引用类型4.1.…...

社招前端二面面试题总结
代码输出结果 var A {n: 4399}; var B function(){this.n 9999}; var C function(){var n 8888}; B.prototype A; C.prototype A; var b new B(); var c new C(); A.n console.log(b.n); console.log(c.n);输出结果:9999 4400 解析: conso…...
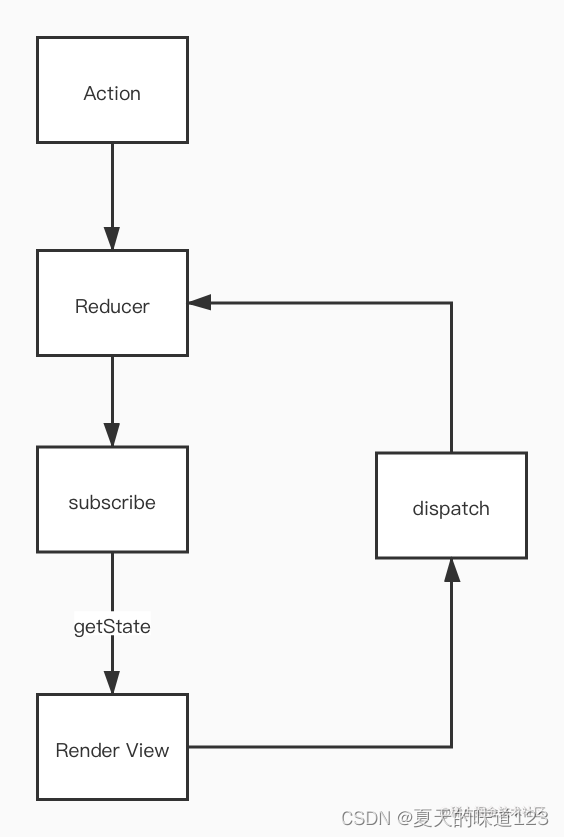
人人能读懂redux原理剖析
一、Redux是什么? 众所周知,Redux最早运用于React框架中,是一个全局状态管理器。Redux解决了在开发过程中数据无限层层传递而引发的一系列问题,因此我们有必要来了解一下Redux到底是如何实现的? 二、Redux的核心思想…...
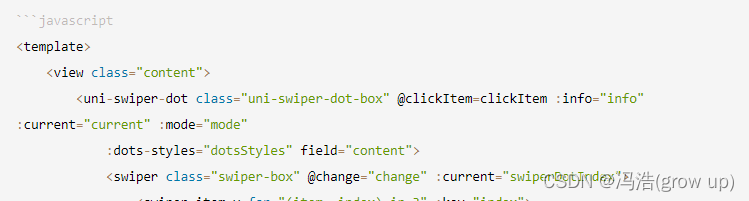
uniCloud云开发----7、uniapp通过uni-swiper-dot实现轮播图
uniapp通过uni-swiper-dot实现轮播图前言效果图1、官网实现的效果2、需求中使用到的效果图官网提供的效果图源码1、html部分2、js部分3、css部分根据需求调整轮播图前言 uni-swiper-dot.文档 uni-swiper-dot 轮播图指示点 - DCloud 插件市场 本次展示根据需求制作的和官网用到…...

IM即时通讯构建企业协同生态链
在当今互联网信息飞速发展的时代,随着企业对协同办公要求的提高,协同办公的定义提升到了智能化办公的范畴。大多企业都非常重视构建连接用户、员工和合作伙伴的生态平台,利用即时通讯软件解决企业内部的工作沟通、信息传递和知识共享等问题。…...

Python实现构建gan模型, 输入一个矩阵和两个参数值,输出一个矩阵
构建一个GAN模型,使用Python实现,该模型将接受一个矩阵和两个参数值作为输入,并输出另一个矩阵。GAN(生成对抗网络)是一种深度学习模型,由生成器和判别器两部分组成,可以用于生成具有一定规律性的数据,如图像或音频。 # 定义生成器 def make_generator(noise_dim, dat…...
开学准备哪些电容笔?ipad触控笔推荐平价
在现代,数码产品的发展受到高技术的驱动。不管是在工作上,还是在学习上,大的显示屏可以使图像更加清晰。Ipad将成为我们日常生活中不可或缺的一部分,无论现在或将来。如果ipad配上一款方便操作的电容笔,将极大地提高我…...

放下和拿起 解放自己
放下太难,从过去中解放自己 工作这么久了,第一次不拿包上班,真爽 人的成长都是在碰撞和摸索中产生的,通过摸索,知道自己能力的边界和欲望的边界以及身体的边界,这三个决定了 你能做什么 你能享受什么&…...

100%BIM学员的疑惑:不会CAD可以学Revit吗?
在新一轮科技创新和产业变革中,信息化与建筑业的融合发展已成为建筑业发展的方向,将对建筑业发展带来战略性和全局性的影响。 建筑业是传统产业,推动建筑业科技创新,加快推进信息化发展,激发创新活力,培育…...

经常会采坑的javascript原型应试题
一. 前言 原型和原型链在面试中历来备受重视,经常被提及。说难可能也不太难,但要真正完全理解,吃透它,还是要多下功夫的。 下面为大家简单阐述我对原型和原型链的理解,若是觉得有说的不对的地方ÿ…...

完全背包—动态规划
一、背包问题概述 如图,完全背包与01背包的区别只有一点:01背包中每个物品只能取一个而完全背包中每个物品可以取无数个。解决完全背包问题必须首先弄明白01背包,不清楚的可以看我的这篇文章01背包—动态规划。 二、例题 重量价值物品0115物…...

消息队列MQ介绍
消息队列技术是分布式应用间交换信息的一种技术。消息队列可驻留在内存或磁盘上,队列存储消息直到它们被应用程序读走。通过消息队列,应用程序可独立地执行--它们不需要知道彼此的位置、或在继续执行前不需要等待接收程序接收此消息。 消息中间件概述 消息队列技术是…...

C语言进阶(八)—— 链表
1. 链表基本概念1.1 什么是链表链表是一种常用的数据结构,它通过指针将一些列数据结点,连接成一个数据链。相对于数组,链表具有更好的动态性(非顺序存储)。数据域用来存储数据,指针域用于建立与下一个结点的…...

手工测试用例就是自动化测试脚本——使用ruby 1.9新特性进行自动化脚本的编写
昨天因为要装watir-webdriver的原因将用了快一年的ruby1.8.6升级到了1.9。由于1.9是原生支持unicode编码,所以我们可以使用中文进行自动化脚本的编写工作。 做了简单的封装后,我们可以实现如下的自动化测试代码。请注意,这些代码是可以正确运…...

亚马逊卖家公开信息数据提取:反爬攻防战与 Python 批量采集实战
摘要: 批量获取亚马逊(Amazon)第三方卖家的商业名称、信用代码和注册地址等信息,对于跨境 B2B 拓客和供应链分析具有重要意义。然而,亚马逊的 Cloudflare 盾和 Robot 验证码构成了极高的反爬门槛。本文将深度解析亚马逊…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

别再乱算相似度了!用Python实战二元变量聚类:从Jaccard系数到病人分组
医疗数据分析实战:用Python实现基于Jaccard系数的病人症状聚类在医疗数据分析领域,如何从海量病人症状数据中发现潜在规律一直是临床研究的难点。传统方法往往依赖医生经验或简单统计,而现代数据挖掘技术为我们提供了更科学的解决方案。本文将…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

光效崩坏?噪点泛滥?色温漂移?——Midjourney专业级光效渲染全流程校准协议,含ACEScg色彩空间适配模板
更多请点击: https://kaifayun.com 第一章:光效崩坏、噪点泛滥与色温漂移的系统性归因诊断 图像采集链路中出现的光效崩坏、噪点泛滥与色温漂移并非孤立现象,而是光学设计、传感器响应、ISP管线调度及环境耦合失配共同作用的结果。三者常呈现…...

如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析
如何让Rhino 3D模型在Blender中保持完整数据:import_3dm插件深度解析 【免费下载链接】import_3dm Blender importer script for Rhinoceros 3D files 项目地址: https://gitcode.com/gh_mirrors/im/import_3dm 当建筑师需要在Blender中渲染Rhino设计的建筑模…...

DragonBones与Godot集成:骨骼动画的可编程化实践
1. 为什么在Godot里用DragonBones不是“锦上添花”,而是“绕不开的刚需” 去年上线一个横版动作手游Demo时,美术团队交来一套20个角色、每个角色含8套动画(待机/跑动/跳跃/攻击/受击/死亡/闪避/必杀)的Spine资源。我兴冲冲导入God…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

Keil µVision反汇编窗口内容导出方案与调试技巧
1. 问题背景与需求解析在嵌入式开发过程中,调试环节往往占据大量时间。Keil Vision作为业界广泛使用的集成开发环境(IDE),其调试器功能强大但某些细节功能仍有提升空间。最近我在使用C251架构开发汽车电子控制单元时,就遇到了一个看似简单却影…...

MeloTTS实战指南:解决多语言TTS部署中的核心挑战
MeloTTS实战指南:解决多语言TTS部署中的核心挑战 【免费下载链接】MeloTTS High-quality multi-lingual text-to-speech library by MyShell.ai. Support English, Spanish, French, Chinese, Japanese and Korean. 项目地址: https://gitcode.com/GitHub_Trendin…...