探索Java爬虫框架:解锁网络数据之门
引言:
随着互联网时代的发展,大量的数据被存储在各种网页中。对于开发者而言,如何高效地获取和处理这些网络数据成为了一个重要的问题。而Java作为一门强大的编程语言,也有许多优秀的爬虫框架供开发者选择和使用。本文将带您深入了解几种流行的Java爬虫框架,帮助您选择合适的框架来开发自己的爬虫程序。
1. Jsoup
Jsoup是一个用于解析HTML文档的Java库,它提供了简单易用的API,可以方便地进行网页内容的解析和处理。
首先,你需要导入Jsoup库。你可以从Jsoup的官方网站上下载最新的jar包,并将其添加到你的项目中。
然后,你可以使用Jsoup的connect方法来连接到一个URL,并使用get方法获取网页内容。接下来,你可以使用不同的方法来提取网页中的元素,例如通过标签名、类名、ID等等。
以下是一个简单的示例代码,演示了如何使用Jsoup解析网页内容:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;public class JsoupExample {public static void main(String[] args) {try {// 连接到一个URL并获取网页内容Document doc = Jsoup.connect("https://example.com").get();// 获取网页中的标题String title = doc.title();System.out.println("网页标题: " + title);// 获取所有的链接元素并打印出来Elements links = doc.select("a[href]");for (Element link : links) {System.out.println("链接: " + link.attr("href"));}// 获取特定标签名的元素并打印出来Elements paragraphs = doc.getElementsByTag("p");for (Element paragraph : paragraphs) {System.out.println("段落: " + paragraph.text());}} catch (Exception e) {e.printStackTrace();}}
}
2. HttpClient
Apache HttpClient是一个强大的HTTP客户端库,它可以用于发送HTTP请求和接收响应。通过使用HttpClient,可以编写自己的爬虫程序来模拟浏览器行为并获取网页内容。
首先,你需要导入HttpClient库。你可以从Apache HttpClient的官方网站上下载最新的jar包,并将其添加到你的项目中。
然后,你可以创建一个HttpClient对象,并使用HttpGet或HttpPost等方法来发送HTTP请求。接下来,你可以使用HttpResponse对象来获取响应,并处理响应的内容。
以下是一个简单的示例代码,演示了如何使用HttpClient发送HTTP请求并获取响应的内容:
import org.apache.http.HttpResponse;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.util.EntityUtils;public class HttpClientExample {public static void main(String[] args) {try {// 创建一个HttpClient对象HttpClient httpClient = HttpClientBuilder.create().build();// 创建一个HttpGet请求HttpGet httpGet = new HttpGet("https://example.com");// 发送请求并获取响应HttpResponse response = httpClient.execute(httpGet);// 获取响应的内容String content = EntityUtils.toString(response.getEntity());System.out.println("响应内容: " + content);} catch (Exception e) {e.printStackTrace();}}
}
3. WebMagic
WebMagic是一个基于Java的开源爬虫框架,它提供了一个灵活且易于使用的API,可以帮助开发人员快速开发爬虫程序。它支持多线程、分布式爬取,并且可以方便地进行网页解析和数据存储。
首先,你需要导入WebMagic库。你可以从WebMagic的官方网站上下载最新的jar包,并将其添加到你的项目中。
然后,你可以创建一个Spider对象,并定义爬取的起始URL和解析的规则。接下来,你可以使用Pipeline接口将爬取的数据进行处理和存储。
以下是一个简单的示例代码,演示了如何使用WebMagic开发一个简单的爬虫程序:
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.processor.PageProcessor;public class WebMagicExample implements PageProcessor {private Site site = Site.me().setRetryTimes(3).setSleepTime(1000);@Overridepublic void process(Page page) {// 解析网页内容String title = page.getHtml().xpath("//title/text()").get();System.out.println("网页标题: " + title);// 提取链接并加入到待爬取队列中page.addTargetRequests(page.getHtml().links().regex("https://example\\.com/.*").all());}@Overridepublic Site getSite() {return site;}public static void main(String[] args) {Spider.create(new WebMagicExample()).addUrl("https://example.com").run();}
}
4. Nutch
Nutch是一个开源的网络搜索引擎,它也可以作为一个爬虫框架来使用。Nutch提供了强大的爬取和索引功能,可以用于构建自己的爬虫程序。
要使用Nutch,你需要先下载和安装Nutch,并按照官方文档来进行配置和使用。
以下是一个简单的示例代码,演示了如何使用Nutch来爬取网页内容:
import org.apache.nutch.crawl.CrawlDatum;
import org.apache.nutch.crawl.CrawlDb;
import org.apache.nutch.crawl.Inlinks;
import org.apache.nutch.crawl.Injector;
import org.apache.nutch.crawl.LinkDb;
import org.apache.nutch.crawl.Nutch;
import org.apache.nutch.fetcher.Fetcher;
import org.apache.nutch.metadata.Metadata;
import org.apache.nutch.parse.Parse;
import org.apache.nutch.parse.Parser;
import org.apache.nutch.plugin.PluginRepository;
import org.apache.nutch.protocol.Content;
import org.apache.nutch.protocol.ProtocolFactory;
import org.apache.nutch.protocol.ProtocolOutput;
import org.apache.nutch.protocol.ProtocolStatus;
import org.apache.nutch.protocol.http.HttpProtocol;
import org.apache.nutch.util.NutchConfiguration;import java.util.Collection;
import java.util.Map;public class NutchExample {public static void main(String[] args) throws Exception {// 设置Nutch的配置NutchConfiguration conf = NutchConfiguration.create();// 初始化Nutch插件PluginRepository.init(conf);// 创建一个ProtocolFactory对象ProtocolFactory factory = new ProtocolFactory(conf);// 创建一个URLString url = "https://example.com";// 创建一个CrawlDatum对象CrawlDatum datum = new CrawlDatum();datum.setUrl(url);datum.setStatus(CrawlDatum.STATUS_INJECTED);datum.setFetchTime(System.currentTimeMillis());// 创建一个Fetcher对象Fetcher fetcher = new Fetcher(conf);// 获取网页内容ProtocolOutput output = fetcher.fetch(url, datum);// 检查网页内容的状态if (output.getStatus().isSuccess()) {// 获取网页内容Content content = output.getContent();// 打印网页内容System.out.println(content);// 创建一个Inlinks对象Inlinks inlinks = new Inlinks();// 创建一个Parser对象Parser parser = PluginRepository.get(conf).getParser(content.getContentType(), url);// 解析网页内容Parse parse = parser.getParse(url, content);// 获取网页中的元数据Metadata metadata = parse.getData().getParseMeta();// 打印网页中的元数据Map<String, Collection<String>> properties = metadata.getProperties();for (String key : properties.keySet()) {Collection<String> values = properties.get(key);for (String value : values) {System.out.println(key + ": " + value);}}} else {// 打印失败的状态ProtocolStatus status = output.getStatus();System.out.println("Failed: " + status.getMessage());}}
}
5. Selenium
Selenium是一个用于自动化浏览器操作的框架,它可以模拟用户在浏览器中的行为,执行JavaScript代码,并获取网页内容。通过使用Selenium,可以编写爬虫程序来处理一些需要JavaScript渲染的网页。
首先,你需要导入Selenium的库。你可以从Selenium的官方网站上下载最新的jar包,并将其添加到你的项目中。
然后,你可以创建一个WebDriver对象,并使用get方法来打开一个网页。接下来,你可以使用不同的方法来查找和操作网页中的元素。
以下是一个简单的示例代码,演示了如何使用Selenium来获取网页内容:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;public class SeleniumExample {public static void main(String[] args) {// 设置ChromeDriver的路径System.setProperty("webdriver.chrome.driver", "path/to/chromedriver");// 创建一个ChromeDriver对象WebDriver driver = new ChromeDriver();try {// 打开一个网页driver.get("https://example.com");// 获取网页中的标题String title = driver.getTitle();System.out.println("网页标题: " + title);// 查找并操作网页中的元素WebElement element = driver.findElement(By.tagName("a"));String linkText = element.getText();String linkUrl = element.getAttribute("href");System.out.println("链接文本: " + linkText);System.out.println("链接URL: " + linkUrl);} catch (Exception e) {e.printStackTrace();} finally {// 关闭浏览器driver.quit();}}
}
希望以上的每个点的详细介绍和代码演示对你有帮助。你可以根据自己的需求和项目的要求选择合适的爬虫框架来开发爬虫程序。每个框架都有详细的文档和示例代码可供参考,你可以进一步探索和学习。
Java爬虫框架为开发者提供了丰富的功能和灵活的编程接口,帮助他们快速构建和执行爬虫程序。在选择框架时,开发者可以根据自己的需求和项目要求,权衡各个框架的优缺点。无论是解析HTML文档、模拟浏览器行为还是分布式爬取,这些爬虫框架都能提供便捷的解决方案。通过深入学习和灵活运用这些框架,开发者可以轻松地获取和处理网络数据,为自己的项目带来更多的价值。
相关文章:

探索Java爬虫框架:解锁网络数据之门
引言: 随着互联网时代的发展,大量的数据被存储在各种网页中。对于开发者而言,如何高效地获取和处理这些网络数据成为了一个重要的问题。而Java作为一门强大的编程语言,也有许多优秀的爬虫框架供开发者选择和使用。本文将带您深入…...

智慧燃气平台的总体架构到底应怎样设计?
关键词:智慧燃气、智慧燃气平台、智能燃气、智能监控 智慧燃气平台功能设计的一些方向和思考: 1、资源统一,管理调度 城市燃气智慧调度运营管理平台收集并且整理出每个业务系统信息,并且根据所整理出的信息结果制定出标准规范&…...
MonkeyRunner测试步骤
首先把安卓SDK的 环境变量给配置好,这里就不再多解释,自己google 然后将自己的安卓设备打开调试模式,USB连接至电脑,运行CMD,输入命令adb devices 查看你的安卓设备的ID(ID后面写程序会调用),…...

Konva基本处理流程和相关架构设计
前言 canvas是使用JavaScript基于上下文对象进行2D图形的绘制的HTML元素,通常用于动画、游戏画面、数据可视化、图片编辑以及实时视频处理等方面。基于Canvas之上,诞生了例如 PIXI、ZRender、Fabric、Konva等 Canvas渲染引擎,兼顾易用的同时…...

人工智能AI知多少?
摘要 人工智能(Artificial Intelligence,简称AI)是一项前沿技术,正在快速发展并渗透到各个领域。然而,对于大多数人来说,人工智能仍然是一个陌生而复杂的概念。本文旨在对人工智能进行扫盲,介绍其基本概念、应用领域以及当前热门的人工智能模型。通过具体的例子,读者将…...

leetcode1610. 可见点的最大数目(java)
可见点的最大数目 题目描述滑动窗口 题目描述 难度 - 困难 leetcode1610. 可见点的最大数目 给你一个点数组 points 和一个表示角度的整数 angle ,你的位置是 location ,其中 location [posx, posy] 且 points[i] [xi, yi] 都表示 X-Y 平面上的整数坐标…...
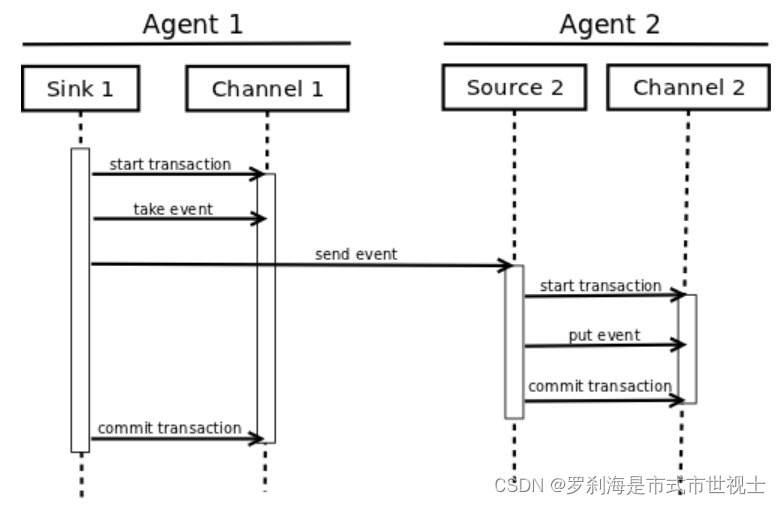
Apache Flume
Flume 1.9.0 Developer Guide【Flume 1.9.0开发人员指南】 Introduction【介绍】 摘自:Flume 1.9.0 Developer Guide — Apache Flume Overview【概述】 Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregati…...

【切片】基础不扎实引发的问题
本次文章主要是来聊聊关于切片传值需要注意的问题,如果不小心,则很容易引发线上问题,如果不够理解,可能会出现奇奇怪怪的现象 问题情况: 小 A 负责一个模块功能的实现,在调试代码的时候可能不仔细&#x…...

CVE-2023-5129 libwebp堆缓冲区溢出漏洞影响分析
漏洞简述 近日苹果、谷歌、Mozilla和微软等公司积极修复了libwebp组件中的缓冲区溢出漏洞,相关时间线如下: 9月7日,苹果发布紧急更新,修复了此前由多伦多大学公民实验室报告的iMessage 0-click 漏洞,漏洞被认为已经被…...

leetcode做题笔记155. 最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。 实现 MinStack 类: MinStack() 初始化堆栈对象。void push(int val) 将元素val推入堆栈。void pop() 删除堆栈顶部的元素。int top() 获取堆栈顶部的元素。int get…...

蓝海彤翔亮相2023新疆网络文化节重点项目“新疆动漫节”
9月22日上午,2023新疆网络文化节重点项目“新疆动漫节”(以下简称“2023新疆动漫节”)在克拉玛依科学技术馆隆重开幕,蓝海彤翔作为国内知名的文化科技产业集团应邀参与此次活动,并在美好新疆e起向未来动漫展映区设置展…...

【AI视野·今日NLP 自然语言处理论文速览 第四十四期】Fri, 29 Sep 2023
AI视野今日CS.NLP 自然语言处理论文速览 Fri, 29 Sep 2023 Totally 45 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers MindShift: Leveraging Large Language Models for Mental-States-Based Problematic Smartphone Use Interve…...
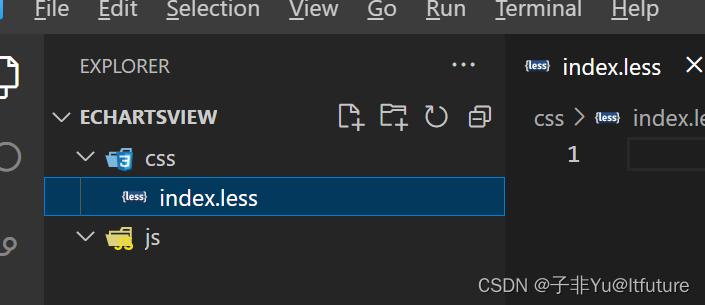
【VsCode】vscode创建文件夹有小图标显示和配置
效果 步骤 刚安装软件后, 开始工作目录下是没有小图标显示的。 如下图操作,安装vscode-icons 插件,重新加载即可 创建文件夹,显示图标如下:...

celery分布式异步任务队列-4.4.7
文章目录 celery介绍兼容性简单使用安装使用方式 功能介绍常用案例获取任务的返回值任务中使用logging定义任务基类 任务回调函数No result will be storedResult will be stored任务的追踪、失败重试 python setup.py installln -s /run/shm /dev/shmOptional configuration, …...

解决M2苹果芯片Mac无法安装python=3.7的虚拟环境
问题描述 conda无法安装python3.7的虚拟环境: conda create -n py37 python3.7出现错误 (base) ➜ AzurLaneAutoScript git:(master) conda create -n alas python3.7.6 -y Collecting package metadata (current_repodata.json): done Solving environment: fa…...
Sound/播放提示音, Haptics/触觉反馈, LocalNotification/本地通知 的使用
1. Sound 播放提示音 1.1 音频文件: tada.mp3, badum.mp3 1.2 文件位置截图: 1.3 实现 import AVKit/// 音频管理器 class SoundManager{// 单例对象 Singletonstatic let instance SoundManager()// 音频播放var player: AVAudioPlayer?enum SoundOption: Stri…...

Oracle实现主键字段自增
Oracle实现主键自增有4种方式: Identity Columns新特性自增(Oracle版本≥12c)创建自增序列,创建表时,给主键字段默认使用自增序列创建自增序列,使用触发器使主键自增创建自增序列,插入语句&…...
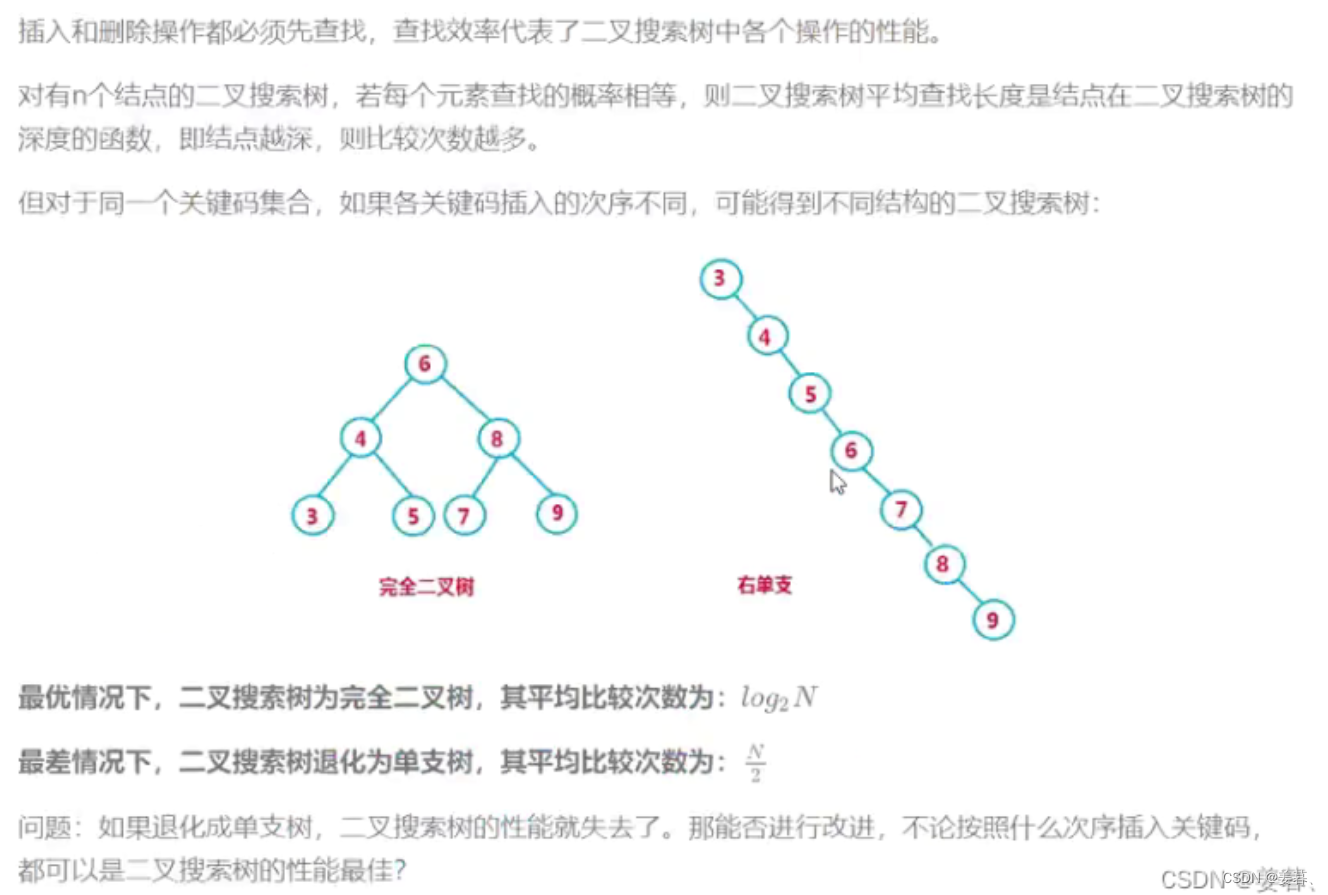
【C++数据结构】二叉树搜索树【完整版】
目录 一、二叉搜索树的定义 二、二叉搜索树的实现: 1、树节点的创建--BSTreeNode 2、二叉搜索树的基本框架--BSTree 3、插入节点--Insert 4、中序遍历--InOrder 5、 查找--Find 6、 删除--erase 完整代码: 三、二叉搜索树的应用 1、key的模型 &a…...

TouchGFX之字体缓存
使用二进制字体需要将整个字体加载到存储器。 在某些情况下,如果字体很大,如大字号中文字体,则这样做可能不可取。 字体缓存使应用能够从外部存储器只能加载显示字符串所需的字母。 这意味着整个字体无需保存到在可寻址闪存或RAM上ÿ…...
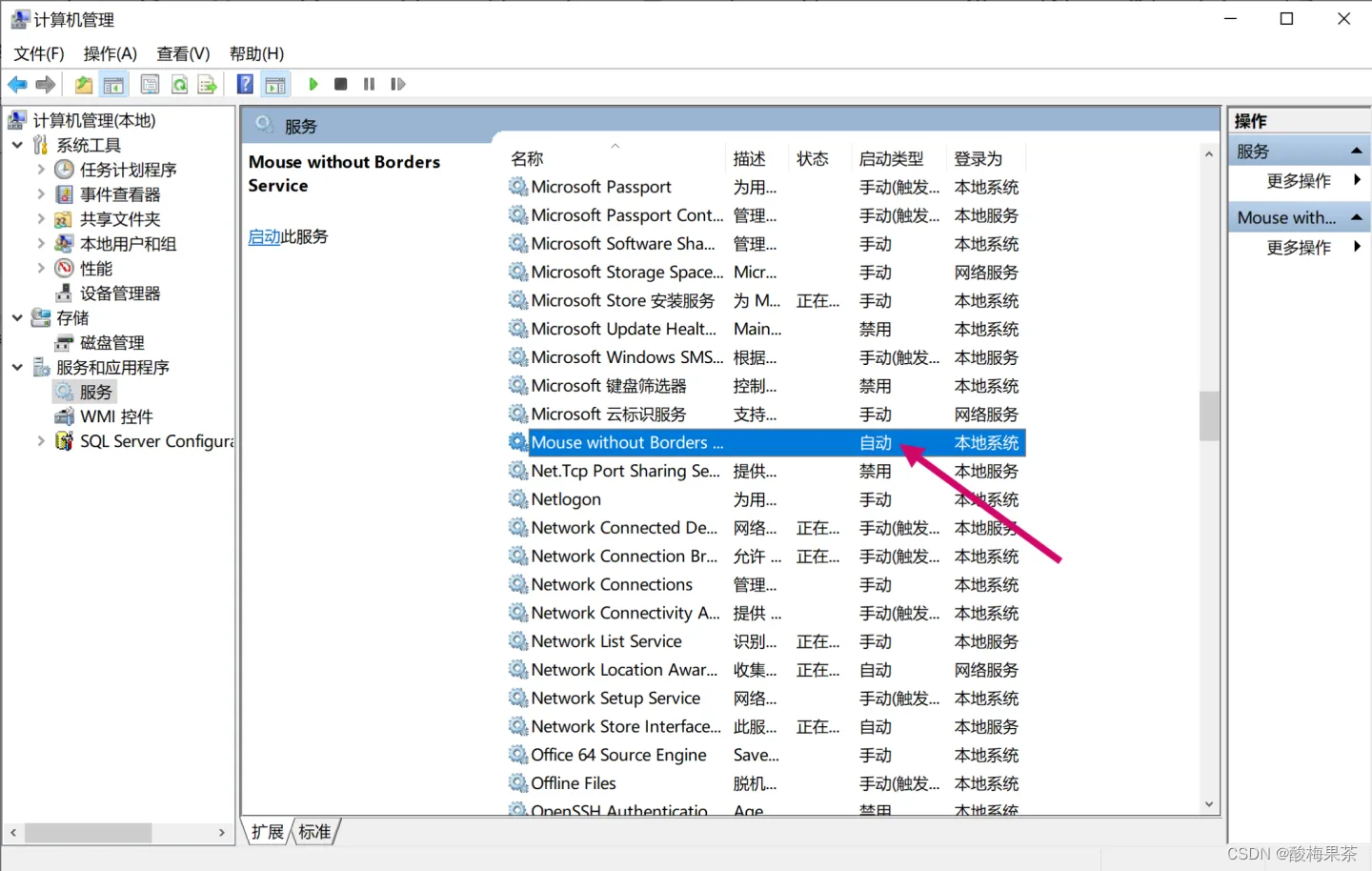
windows系统关闭软件开机自启的常用两种方法
win10中安装软件时经常会默认开机自启动,本文主要介绍两种关闭软件开机自启动方法。 方法1 通过任务管理器设置 1.在任务管理器中禁用开机自启动:打开任务管理器,右键已启动的软件,选择禁用。 方法2 通过windows服务控制开机自启…...

抖音批量下载工具:如何快速提取无水印视频和背景音乐
抖音批量下载工具:如何快速提取无水印视频和背景音乐 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...

K6性能测试实战:HTTP请求、指标监控与自动化阈值校验
1. 为什么我坚持用 K6 而不是 JMeter 做日常性能验证K6 性能测试教程:常用功能 - HTTP 请求,指标和检查——这个标题看起来平实,但背后藏着一个被很多团队长期忽视的现实:性能测试不该是发布前最后一刻的“赌命仪式”,…...

终极硬件信息伪装技术:5大内核级修改方案深度解析
终极硬件信息伪装技术:5大内核级修改方案深度解析 【免费下载链接】EASY-HWID-SPOOFER 基于内核模式的硬件信息欺骗工具 项目地址: https://gitcode.com/gh_mirrors/ea/EASY-HWID-SPOOFER 硬件指纹追踪已成为现代数字隐私面临的最大威胁之一。无论是网站追踪…...

博弈编码:用激励相容机制实现抗女巫攻击的去中心化机器学习
1. 项目概述:当编码遇见博弈论在分布式计算和存储领域,编码理论(Coding Theory)一直扮演着“守护神”的角色。无论是经典的纠删码(Erasure Code)还是更复杂的再生码(Regenerating Codeÿ…...

Windows和Office激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程
Windows和Office激活终极指南:KMS_VL_ALL_AIO智能脚本完整教程 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows激活弹窗烦恼吗?Office突然变成只读模式影响…...

DLSS Swapper:游戏性能优化的终极智能管家
DLSS Swapper:游戏性能优化的终极智能管家 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 想象一下,你刚刚下载了一款最新的3A大作,却发现游戏中的DLSS版本过时,导致帧率…...

我从一次与人工智能无关的数据会议中学到的三大关键数据经验
原文:towardsdatascience.com/three-crucial-data-lessons-that-i-learned-from-a-data-conference-thats-not-related-to-ai-f802f7097d67?sourcecollection_archive---------8-----------------------#2024-10-29 在组织中帮助促进分析卓越的被低估概念 https:/…...

Unity中Newtonsoft.Json三种安装方式深度对比
1. 为什么Unity项目里装个Json库要纠结三天?——从一次崩溃说起Newtonsoft.Json,也就是大家常说的Json.NET,在C#生态里几乎是序列化的代名词。但放到Unity里,它却是个“熟悉的陌生人”:你写惯了JsonConvert.SerializeO…...

多指灵巧手技术解析与应用实践
1. 多指灵巧手技术概述 多指灵巧手作为机器人操作系统的核心执行部件,其设计理念直接决定了机器人在非结构化环境中的操作能力。这类机械手通过模拟人类手指的解剖学结构和运动方式,实现了从简单抓取到复杂精细操作的功能跨越。与传统的二指夹持器相比&a…...

Windows 11硬件限制绕过终极指南:3种实用方法让老电脑轻松升级
Windows 11硬件限制绕过终极指南:3种实用方法让老电脑轻松升级 【免费下载链接】MediaCreationTool.bat Universal MCT wrapper script for all Windows 10/11 versions from 1507 to 21H2! 项目地址: https://gitcode.com/gh_mirrors/me/MediaCreationTool.bat …...