深度学习如何训练出好的模型
深度学习在近年来得到了广泛的应用,从图像识别、语音识别到自然语言处理等领域都有了卓越的表现。但是,要训练出一个高效准确的深度学习模型并不容易。不仅需要有高质量的数据、合适的模型和足够的计算资源,还需要根据任务和数据的特点进行合理的超参数调整、数据增强和模型微调。在本文中,我们将会详细介绍深度学习模型的训练流程,探讨超参数设置、数据增强技巧以及模型微调等方面的问题,帮助读者更好地训练出高效准确的深度学习模型。
本文将从数据、模型、超参数和训练中的技巧展开探讨
深度学习如何训练出好的模型
- 数据
- 数据集质量
- 数据增强
- 模型选择
- 超参数
- 训练中的技巧
数据
从数据层面上, 能够影响模型性能的有二个因素:
- 数据集的质量
- 数据增强
数据集质量
数据质量:数据应该是准确,完整,无误,且具有代表性。如果数据集有错误或缺失,将会影响模型的性能,选择分辨率越高肯定对模型是越好的,但是也要考虑到模型训练占用的内存够不够,因为分辨率越高,数据量就越大
数据量:更多的数据通常可以提高模型的性能,因为它使得模型更具有代表性和泛化能力。但是,数据集的大小也会影响训练时间和资源要求。但对模型训练收敛来说,数据量大小对于模型收敛没有决定性的影响,只能说数据量越大,同时数据多样性分布性很好,模型是一定会泛化
数据多样性:为了获得更好的泛化能力,数据集应该具有多样性。这意味着应该包含不同的样本,以便模型可以学习到数据中的各种模式。对于样本多样性来说,每一个类别的样本数量应该是一样的,最好是再增加负样本(正样本就是图像标注信息的,负样本没有标注信息的,举例说正样本图像中有人有车、负样本图像中就什么事物都没有)。其中正样本和负样本比例,建议为1:2或1:3,这是因为现实世界中负样本比正样本更多,但也要根据自己模型的场景来判断,如何过多的负样本,模型会偏向于识别负样本,而无法识别出正样本了。
数据预处理:在选择数据集之前,需要了解数据的特性并进行预处理。例如,对于图像分类问题,可能需要对图像进行缩放或裁剪,或者将像素值标准化到[0,1]范围内。
数据来源:应该选择可靠的数据来源。一些数据集可能来自于不可靠的或不真实的来源,这可能会导致模型的性能下降。
数据分割:在选择数据集时,应该将数据分成训练集,验证集和测试集。这样可以用来评估模型的泛化能力和性能。
数据标注:在某些任务中,需要对数据进行标注,以便训练模型。这可能需要大量的人工劳动力和时间成本。但也需要注意,虽然数据集不同类别数量达到一样的平衡,但如果一个类别在图像中标注的数量远大于另一个类别在图像中标注的数量,也会导致数据不平衡。因此需要采用一些方法调整,方法如下:
- 过采样(oversampling):对于少数类别的样本,可以通过复制、插值等方式来增加样本数量,从而使不同类别的样本数量更加均衡。
- 欠采样(undersampling):对于多数类别的样本,可以随机删除一部分样本,从而使不同类别的样本数量更加均衡。
- 权重调整(weighting):对于不同类别的样本,可以给每个样本赋予不同的权重,从而使模型更加关注少数类别的样本。一般来说,权重可以通过计算每个类别的样本比例的倒数得到。
例如,假设我们有一个二分类任务,其中少数类别的样本占总样本数的比例为0.1,多数类别的样本占总样本数的比例为0.9。那么我们可以将少数类别的样本赋予权重为1/0.1=10,多数类别的样本赋予权重为1/0.9=1.11,从而使得模型更加关注少数类别的样本。
在实现时,一般可以通过设置损失函数中不同类别的权重参数,或者使用一些针对不平衡数据的损失函数(如Focal Loss)来实现样本权重的调整。
总结以上的信息,可以发现对于数据影响模型性能来说,主要围绕着数据的图像质量,和数据的平衡性展开(包含数据量大小、比例、标注数据量)
数据增强
在深度学习中,数据增强是一种非常重要的技术,它可以扩充数据集大小,提高模型的泛化能力,减轻过拟合的问题。下面是一些常见的数据增强方法,也说明了什么场景适合什么样的数据增强方法。
数据增强的方法除了将结构化数据转化为张量,以外其他方法也不是随便用的,一定结合合适的场景使用。
下面列举了一些常用的数据增强方法:
随机裁剪(Random cropping):在图像中随机选取一个区域进行裁剪,从而得到多个不同的裁剪结果。
随机翻转(Random flipping):对图像进行随机水平或垂直翻转,从而得到不同的镜像结果。
随机旋转(Random rotation):对图像进行随机旋转,从而得到不同的旋转角度和方向的图像。
随机缩放(Random scaling):对图像进行随机缩放,从而得到不同大小的图像。
随机颜色变换(Random color jitter):对图像进行随机颜色变换,如亮度、对比度、饱和度等的调整。
加噪声(Add noise):向图像中添加随机噪声,从而使模型更具有鲁棒性。
在实践中,通常会根据具体任务和数据集的特点选择适合的数据增强方法。其中随机裁剪、随机翻转、随机旋转是计算机视觉任务中通用的方法,不难想象一下,人为何在现实生活识别出事物呢,哪怕事物旋转过,只有部分呢
也需要考虑到实际场景中,选择合适的方法,具体情况就要自己多思考思考了,比如
- 一个场景就不存在事物旋转的可能,就没必要对数据进行旋转增强。
- 场景如果暴露在开阔的地方,就应该要考虑到光照的影响, 就需要对数据进行颜色上的增强,
同时,在使用数据增强方法时,需要注意避免对数据进行过度增强,否则会对模型的性能产生负面影响。此外,为了避免过拟合,也可以通过对不同数据集使用不同的数据增强策略来提高模型的泛化能力。
模型选择
选择适合自己的计算机视觉模型需要考虑多个因素,包括任务类型、数据集、模型复杂度和计算资源等。
首先,需要明确自己的任务类型是图像分类、目标检测、语义分割、实例分割、姿态估计、人脸识别、视频分析等,不同类型的任务需要使用不同的模型。
其次,需要考虑使用的数据集,数据集的规模、特点和难度等都会影响模型的表现和选择。例如,对于较小的数据集,可以使用轻量级的模型,而对于复杂的数据集,需要使用更复杂的模型,例如深度残差网络、注意力机制和Transformer等。
此外,还需要考虑计算资源的限制,例如计算能力、内存大小和显存大小等。如果计算资源有限,可以选择一些轻量级的模型或使用分布式训练等技术来加速训练。
最后,还需要考虑模型的复杂度和训练难度。一般来说,模型越复杂,需要的计算资源越多,训练难度也越大。因此,在选择模型时需要平衡模型复杂度和性能表现。
除了上述因素,还有一些其他的因素也需要考虑,例如:
- 准确度:模型的准确度是衡量模型好坏的重要指标之一。在实际应用中,需要根据自己的任务需求来选择准确度最高的模型。
- 可解释性:有些任务需要模型能够提供可解释性的结果,例如目标检测中需要知道每个检测框对应的物体类别、位置和大小等信息。因此,选择模型时需要考虑其可解释性。
- 实时性:有些应用需要模型能够实时响应,例如无人驾驶和机器人控制等。因此,选择模型时需要考虑其响应时间和效率。
- 数据增强:数据增强是一种常用的提升模型性能的技术,可以通过扩增数据集来减轻模型的过拟合问题。因此,选择模型时需要考虑其对数据增强的支持程度。
- 可迁移性:有些应用需要模型能够在不同的场景和任务中迁移,例如使用预训练模型进行微调。因此,选择模型时需要考虑其可迁移性。
- 可扩展性:有些应用需要模型能够在不同的设备和平台上运行,例如嵌入式设备和移动设备等。因此,选择模型时需要考虑其可扩展性。
综上所述,选择适合自己的计算机视觉模型需要考虑多个因素,需要根据具体的应用场景和任务需求进行选择。同时,也需要关注最新的研究进展和算法,以便更好地应对不断变化的计算机视觉任务和应用需求
具体模型选择,小编觉得可以先从模型的复杂度,实时性,准确性先考虑过滤掉不合适的模型,然后从一个模型复杂多小的模型开始,使用它的预训练模型进行训练,通过训练后的loss和收敛情况等因素,来判断是否选择更复杂的模型
超参数
在深度学习中,超参数是指那些需要手动设置的参数,这些参数不能直接从数据中学习得到,而需要通过调整和优化来得到最优的模型。超参数的选择对模型的训练和泛化性能有很大的影响。
以下是常见的超参数及其作用:
- Learning rate(学习率):学习率控制了参数更新的速度,太小的学习率会导致训练速度过慢,而太大的学习率则可能导致训练不稳定,甚至无法收敛。通常需要根据具体问题和网络结构进行调整。
- Batch size(批大小):批大小指每次迭代使用的样本数量,过小的批大小会增加训练时间,而过大的批大小会占用过多的内存。通常需要在训练开始时进行调整。
- Number of epochs(迭代次数):迭代次数指训练的轮数,过少的迭代次数会导致欠拟合,而过多的迭代次数则会导致过拟合。通常需要根据训练集和验证集的表现来确定。
- Dropout rate(丢弃率):丢弃率指在训练过程中随机丢弃一定比例的神经元,从而防止过拟合。过高的丢弃率会导致模型欠拟合,而过低的丢弃率则会导致过拟合。通常需要根据具体问题和网络结构进行调整。
- Regularization(正则化):正则化通过惩罚模型复杂度来防止过拟合,常见的正则化方法包括L1正则化和L2正则化。需要根据具体问题进行调整。
- Optimizer(优化器):优化器控制了模型参数的更新方式,常见的优化器包括SGD、Adam和RMSprop等。不同的优化器对于不同的问题和网络结构可能有不同的效果。
在深度学习训练中,超参数是指在训练过程中需要手动设置的参数,例如学习率、批量大小、正则化系数等。超参数的不同取值会对模型的性能产生不同的影响,因此需要进行合理的设置。
如果超参数过大,可能会导致模型过拟合,即在训练集上表现良好,但在测试集或新数据上表现较差;如果超参数过小,可能会导致模型欠拟合,即模型在训练集和测试集上的表现都较差。因此,需要根据数据集和模型结构进行调整。
一般来说,设置超参数时需要先使用默认值或经验值作为起点,然后进行逐步调整和验证。通常情况下,学习率可以设置为0.001或0.0001;批量大小可以设置为32或64;正则化系数可以设置为0.01或0.001等。这些值也可以根据具体任务和数据集进行微调。
此外,还有一些更高级的超参数设置方法,例如网格搜索、随机搜索、贝叶斯优化等。
训练中的技巧
因为训练深度学习模型,成本更高,不可能使用多钟超参数组合,来训练模型,找出其中最优的模型,那如何成本低的情况下训练出好的模型呢
在成本低的情况下,可以采用以下方法训练出好的模型:
- 提前停止:在训练模型时,我们可以跟踪验证集的性能,并在性能不再提高时停止训练。这可以防止模型过度拟合并节省训练时间。
- 随机搜索超参数:超参数是模型的配置选项,如层数、节点数、学习率等。随机搜索超参数可以帮助我们找到最优的模型,而不需要尝试所有可能的超参数组合。
- 使用预训练模型:预训练模型是在大型数据集上训练的模型,可以作为初始模型来加速训练过程,并提高模型性能。
- 迁移学习:迁移学习是指将预训练模型应用于新的任务,然后微调以适应新任务。这可以帮助我们在小数据集上训练出更好的模型。
- 批量正则化技术:批量正则化技术,如批量归一化(Batch Normalization)和权重衰减(Weight Decay)等,可以帮助我们训练出更加稳定和准确的模型。
- 硬件优化:使用更好的硬件,如GPU和TPU等,可以帮助我们加速模型训练,并节省时间和成本。
- 对比实验:进行对比实验也是选择最优模型的一种方法。对比实验是指将不同的模型在相同的数据集和任务下进行训练和测试,并通过一些评价指标来比较它们的性能。可以先选择一些常用的模型作为基准线,例如ResNet、Inception、VGG等,再尝试一些新的模型,如EfficientNet、RegNet、Vision Transformer等,将它们在相同的数据集和任务下进行训练和测试,比较它们的性能差异,找出最优的模型。需要注意的是,对比实验需要选择适当的评价指标,例如准确率、F1值、平均精度均值(mAP)等,同时还需要考虑训练时间、模型大小、推理速度等因素。因此,综合考虑多个方面才能得出较为准确的结论。
- 集成学习:是指将多个模型的预测结果进行组合,从而得到更加准确的预测结果的方法。常见的集成学习方法包括投票、平均值、堆叠等。投票是指将多个模型的预测结果进行投票,选择得票数最多的结果作为最终预测结果。平均值是指将多个模型的预测结果进行平均,作为最终预测结果。堆叠是指将多个模型的预测结果作为输入,训练一个新的模型来得到最终预测结果。需要注意的是,集成学习需要选择多个性能相近的模型进行组合,否则可能会降低预测性能。同时,集成学习也需要考虑模型的训练时间、模型大小等因素。
夹带一些私货我的AI女友




相关文章:
深度学习如何训练出好的模型
深度学习在近年来得到了广泛的应用,从图像识别、语音识别到自然语言处理等领域都有了卓越的表现。但是,要训练出一个高效准确的深度学习模型并不容易。不仅需要有高质量的数据、合适的模型和足够的计算资源,还需要根据任务和数据的特点进行合…...

智慧教室系统--重点设备监控系统
随着教育信息化的不断发展,智慧教室已成为现代教育的重要组成部分。而智慧教室的设备管理和维护也变得越来越重要。一旦智慧教室的重要设备出现故障或异常,将会对教学活动产生不利影响,因此建立智慧教室重点设备监控系统是必要的。一、智慧教…...
Linux中断处理
目录 一、什么是中断 二、中断处理原理 三、中断接口 3.1 中断申请 3.2 中断释放 3.3 中断处理函数原型 四、按键驱动 一、什么是中断 一种硬件上的通知机制,用来通知CPU发生了某种需要立即处理的事件 分为: 1. 内部中断 CPU执行程序的过程中&am…...

python中安装gurobi和pycharm没有语法提示问题解决
安装gurobi第一步 :下载gurobi ( http://www.gurobi.com ) ,需要注册账号第二步、申请License注册如果可以通过校园网, 则直接生成。不能的话,通过网站,发邮件申请 http://www.gurobi.cn/NewsView1.Asp?id4第三、邮件…...
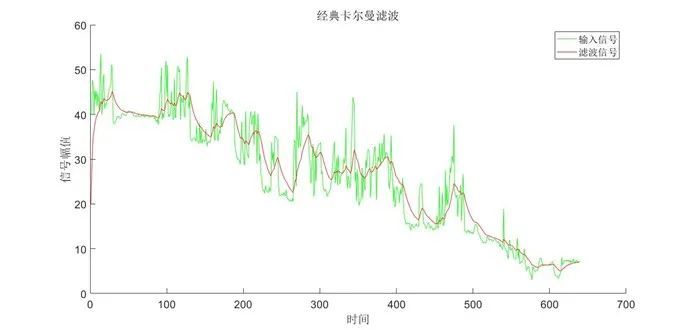
滤波算法:经典卡尔曼滤波
卡尔曼滤波实质上就是基于观测值以及估计值二者的数据对真实值进行估计的过程。预测步骤如图1所示: 图1 卡尔曼滤波原理流程图 假设我们能够得到被测物体的位置和速度的测量值 ,在已知上一时刻的最优估计值 以及它的协方差矩阵 的条件下ÿ…...

flask框架(下)
文章目录flask框架(下)werkzeug简介请求上下文flask 处理方案回到 wsgi_app 方法中push 源码总结补充flask框架(下) werkzeug简介 Werkzeug是一个WSGI工具包,他可以作为一个Web框架的底层库。这里稍微说一下, werkzeug 不是一个web服务器,也…...
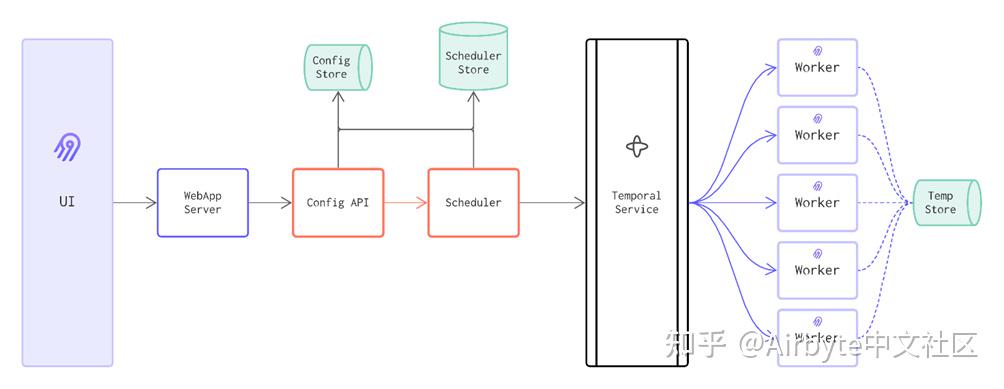
Airbyte架构
作为一款技术复杂的数据集成管道,Airbyte的架构模式非常清晰明了。Airbyte应用模式Airbyte管道架构UI:一个易于使用的图形界面,用于与Airbyte API进行交互。WebApp Server:处理 UI 和 API 之间的连接。Config Store:存…...
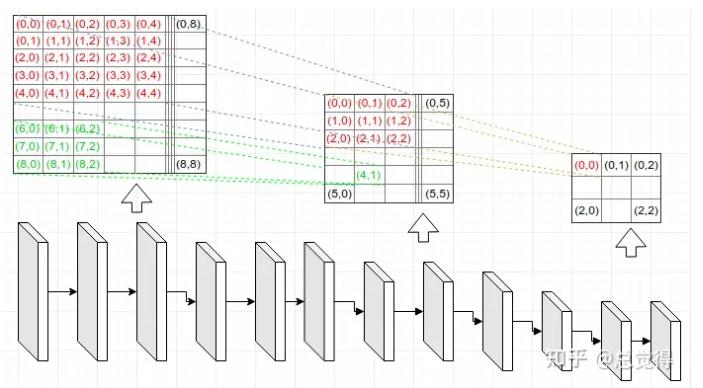
anchor box只是先验知识,bounding box是一种过程,ground truth才是标准答案,
anchor boxes是一组提前预定义的边框,这些框的宽高和数据集中目标物体的宽高大体是一致的,换句话说,数据集中的绝大多数物体都能找到与其大小一致的anchor box。 举例来说,如果数据集中包含苹果、猫,那么这组anchor bo…...
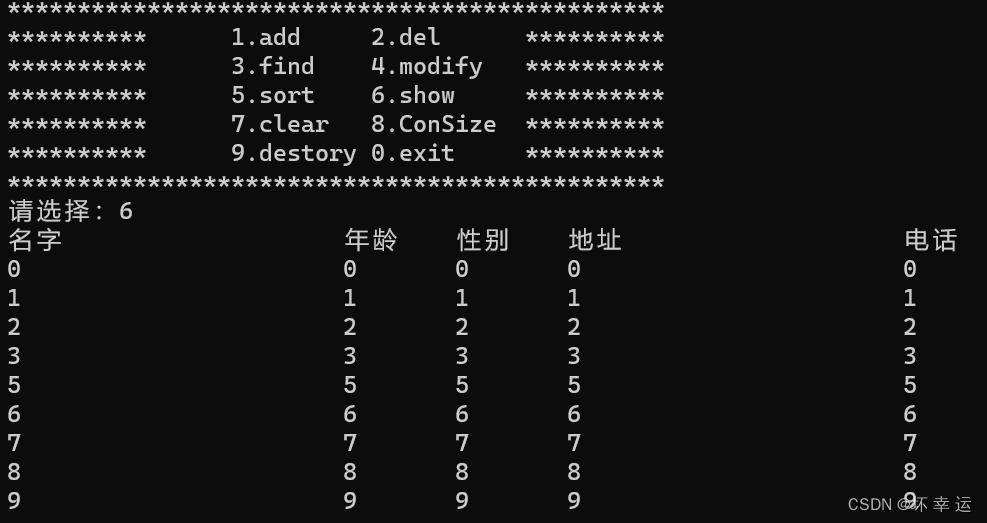
带你轻松实现通讯录(C语言版)
文章目录前言通讯录初始化通讯录运行的基本框架和菜单增添联系人删除联系人查找联系人修改联系人信息展示通讯录通讯录联系人个数排序通讯录文件操作储存通讯录信息销毁通讯录整体代码Contacts.hContacts.ctest.c写在最后前言 学习C语言的小伙伴,相信都要经历实现通…...
渗透测试之交换式网络嗅探实验
渗透测试之交换式网络嗅探实验实验目的一、实验原理1.1 网络嗅探器Sniffer的工作原理1.2 网络嗅探器的分类1.3 网络嗅探器Sniffer的作用二、实验环境2.1 操作机器2.2 实验工具Sniffer2.3 安装工具Sniffer三、实验步骤1. 熟悉Sniffer工具的启动2. 进行监听3. 熟悉Sniffer工具的介…...
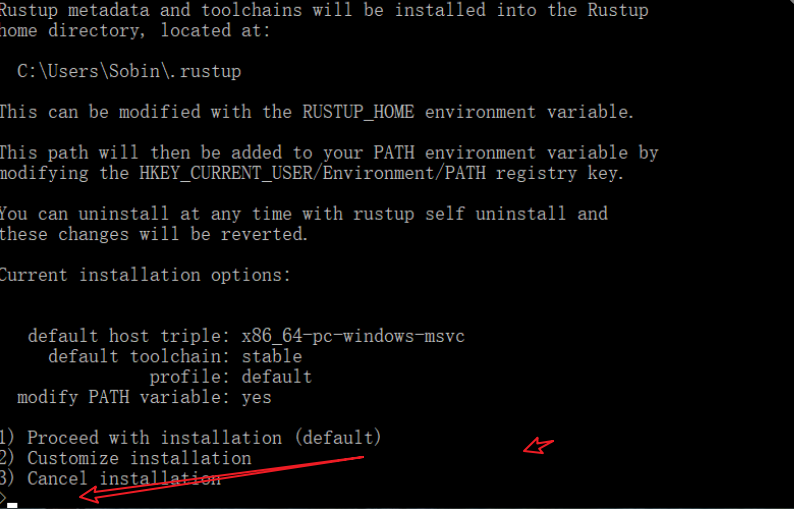
rust 安装
rust 安装一、需要一个c的环境二、配置环境变量三、开始安装一、需要一个c的环境 安装Visual Studio 二、配置环境变量 Rust需要安装两个东西,一个是rustup,一个是cargo。所以你需要设置两个环境变量来分别指定他们的安装目录。 通过RUSTUP_HOME指定…...
机器学习和深度学习综述
机器学习和深度学习综述 1. 人工智能、机器学习、深度学习的关系 近些年人工智能、机器学习和深度学习的概念十分火热,但很多从业者却很难说清它们之间的关系,外行人更是雾里看花。在研究深度学习之前,先从三个概念的正本清源开始。概括来说…...
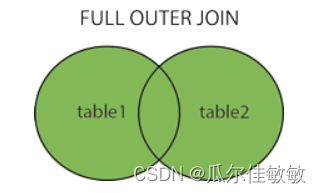
SQL零基础入门学习(八)
SQL零基础入门学习(七) SQL 连接(JOIN) SQL join 用于把来自两个或多个表的行结合起来。 下图展示了 LEFT JOIN、RIGHT JOIN、INNER JOIN、OUTER JOIN 相关的 7 种用法。 SQL JOIN SQL JOIN 子句用于把来自两个或多个表的行结合起来,基…...
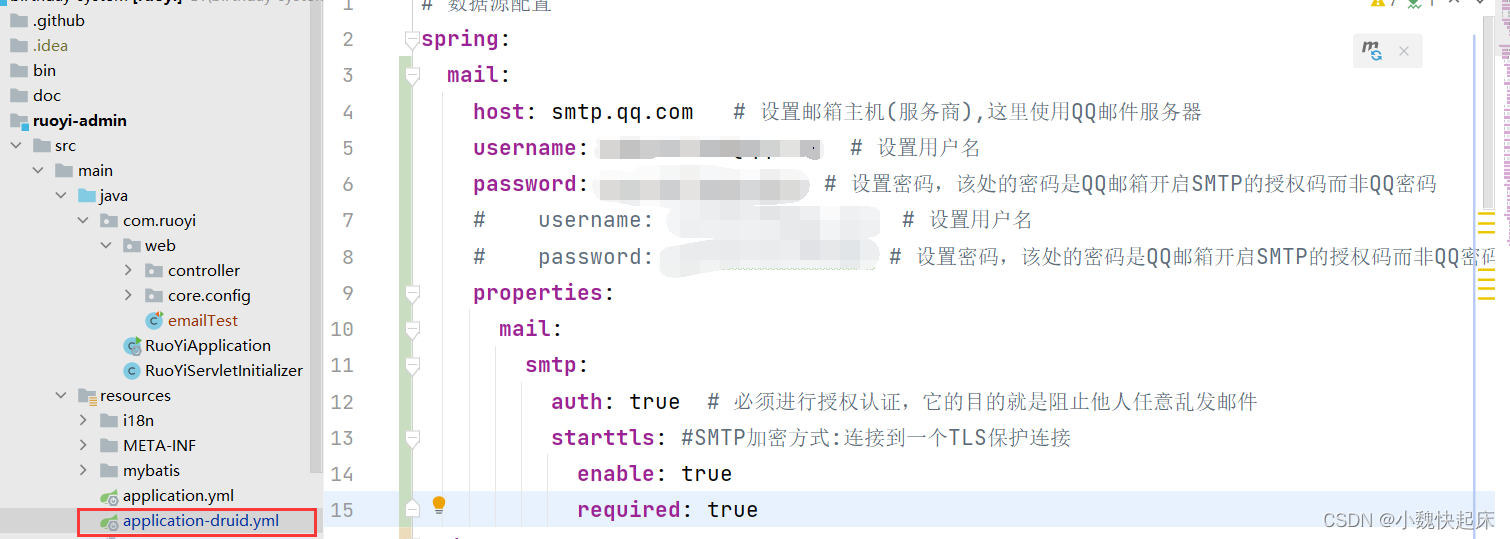
若依系统如何集成qq邮件发送【超详细,建议收藏】
若依系统的部署博主就不在这儿阐述了,默认大家的电脑已经部署好了若依系统,这里直接开始集成邮件系统,首先我们得需要对qq邮箱进行配置;一套学不会你来打我😀; 一、开启我们的qq邮箱发送邮件的配置 1、先进…...

前端-CSS-zxst
CSS 层叠样式表,为了定义HTML标签的样式 内联样式 在标签内部通过 style 属性设置样式值样式名:样式值;样式名:样式值; 内部样式 在 head 标签内通过 style 标签选择器设置样式,供这个网页上的元素使用 外部样式 在 head 标签内通过 link 标签引入外部…...
|LuatOS-SOC接口|官方demo|学习(19):fonts库)
合宙Air105|fonts库|mcu.ticks()|LuatOS-SOC接口|官方demo|学习(19):fonts库
基础资料 基于Air105开发板:Air105 - LuatOS 文档 上手:开发上手 - LuatOS 文档 探讨重点 官方fonts库函数介绍以及利用mcu.ticks()计算程序运行周期相关内容的学习及探讨。 软件版本 AIR105:LuatOSAIR105 base 22.12 bsp V0014 32bit …...

成都欢蓬电商:抖音直播卖药灰度测试通告
据报道,近日有MCN机构透露,目前抖音直播卖药为“测试项目,谨慎试跑中”; “仍处于灰度测试,至于测试多久,抖音官方确实没有答复,需要看第一阶段数据,然后定夺,预计4月份会纳入更多机…...

1.1计算机和编成语言
一、C 语言简介历史C 语言最初是作为 Unix 系统的开发工具而发明的。1969年,美国贝尔实验室的肯汤普森(Ken Thompson)与丹尼斯里奇(Dennis Ritchie)一起开发了Unix 操作系统。Unix 是用汇编语言写的,无法移…...

解析 xml 文件 - xml.etree ElementTree
目录1、导入模块 →\rightarrow→ 读取文件 →\rightarrow→ 获取根节点 →\rightarrow→ 获取根节点的标签与属性2、遍历一级子节点、获取子节点的标签 与 属性3、通过索引 获取数据4、Element.findall()、Element.find() - 按照 tag 值查找 子节点5、Element.iter() - 循环迭…...
LeetCode Cookbook 哈希表(collections.Counter()和collections.defaultdict())
好久不更了,这次一鼓作气,学完它! 文章目录LeetCode Cookbook 哈希表30. 串联所有单词的子串36. 有效的数独(很不错的循环题目)49. 字母异位词分组290. 单词规律447. 回旋镖的数量575. 分糖果594. 最长和谐子序列599. …...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

13456
12356...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器
PvZ Toolkit终极指南:三步掌握植物大战僵尸最强修改器 【免费下载链接】pvztoolkit 植物大战僵尸 PC 版综合修改器 项目地址: https://gitcode.com/gh_mirrors/pv/pvztoolkit PvZ Toolkit是一款专为植物大战僵尸PC版设计的综合修改器工具,能够让你…...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...

Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量 Hermes Agent 是一个流行的 AI 代理开发框架࿰…...

Metabase:零代码 BI 数据可视化工具,自建数据看板
Metabase:零代码 BI 数据可视化工具,自建数据看板 在数据驱动决策的时代,能快速看到业务数据的变化趋势至关重要。然而,专业 BI 工具(如 Tableau、Power BI)价格昂贵,而让每个业务同学都学 SQL …...

哪款台灯护眼效果最好孩子用?实测口碑爆款护眼灯品牌,买前必看
哪款台灯护眼效果最好孩子用?作为家长,最揪心的就是孩子的视力问题。有数据显示,现在孩子近视率越来越高,小学就有不少戴眼镜的,中学更是过半,看着实在让人担心。 孩子每天低头写作业、看书,灯光…...

抖音内容自动化采集与管理的技术实现方案
抖音内容自动化采集与管理的技术实现方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support. 抖音批量下载工具&am…...