spark SQL 任务参数调优1
1.背景
要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。
一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行(Execution) 三大过程。其中Spark SQL 解析和优化如下图

-
Parser模块:未解析的逻辑计划,将SparkSql字符串解析为一个抽象语法树/AST。语法检查,不涉及表名字段。
-
Analyzer模块:解析后的逻辑计划,该模块会遍历整个AST,并对AST上的每个节点进行数据类型的绑定以及函数绑定,然后根据元数据信息Catalog对数据表中的字段和基本函数进行解析。
-
Optimizer模块:该模块是Catalyst的核心,主要分为RBO和CBO两种优化策略,其中RBO是基于规则优化(谓词下推(Predicate Pushdown) 、常量累加(Constant Folding) 、列值裁剪(Column Pruning)),CBO是基于代价优化。
-
SparkPlanner模块:优化后的逻辑执行计划OptimizedLogicalPlan依然是逻辑的,并不能被Spark系统理解,此时需要将OptimizedLogicalPlan转换成physical plan(物理计划),如join算子BroadcastHashJoin、ShuffleHashJoin以及SortMergejoin 。
-
CostModel模块:主要根据过去的性能统计数据,选择最佳的物理执行计划。这个过程的优化就是CBO(基于代价优化)。
在实际Spark执行完成一个数据生产任务(执行一条SQL)的基本过程:
(1)对SQL进行语法分析,生成逻辑执行计划
(2)从Hive metastore server获取表信息,结合逻辑执行计划生成并优化物理执行计划
(3)根据物理执行计划向Yarn申请资源(executor),调度task到executor执行。
(4)从HDFS读取数据,任务执行,任务执行结束后将数据写回HDFS。
上述运行过程
过程 (2)主要是driver的处理能力
过程 (3)主要是executor 、driver的处理能力、作业运行行为
本文从作业的运行过程(2)(3)各选择一个参数介绍从而了解运行过程。
目前的spark参数以及相关生态的参数列表几百个:
Hadoop参数:https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
hive参数:Configuration Properties - Apache Hive - Apache Software Foundation
spark参数:spark 配置参数 Configuration - Spark 3.5.0 Documentation
spark 优化参数 Performance Tuning - Spark 3.5.0 Documentation
spark 执行参数 Spark SQL and DataFrames - Spark 2.0.0 Documentation
各个公司自定义参数:set spark.sql.insertRebalancePartitionsBeforeWrite.enabled = true
其他网上参考的参数:Hive常用参数总结-CSDN博客
参数列表
| 参数类型 | 参数 | 设置值 | 描述 |
| 资源利用 | spark.driver.memory | 5g | --driver-memory 5G 每个exector的内存大小,后缀"k", "m", "g" or "t" |
| input split | spark.hadoop.hive.exec.orc.split.strategy spark.hadoop.mapreduce.input.fileinputformat.split.maxsize; spark.hadoop.mapreduce.input.fileinputformat.split.minsize; | BI 、ETL 、HYBRID | |
| shuffle | spark.sql.shuffle.partitions | 200 | |
| spark.default.parallelism | 80, 100, 200, 300 | ||
| join |
1.spark.hadoop.hive.exec.orc.split.strategy 参数
1. 参数作用:参数控制在读取ORC表时生成split的策略,影响任务执行时driver压力和mapper 数量。
2. 参数介绍 : 参数来源于hive :hive.exec.orc.split.strategy官方定义如下图,当任务执行开始时,ORC有三种分割文件的策略 BI 、ETL 、HYBRID(默认)
HYBRID模式:文件数过多和文件小的场景下,当文件数大于mapper count (总文件大小/hadoop默认分割大小128M) 且文件大小小于HDFS默认(128M)的大小。
ETL:生成分割文件之前首先读取ORC文件的footer(存储文件信息的文件),
BI: 直接分割文件,没有访问HDFS上的数据。
ORC文件的footer是什么?
ORC 文件原理:全称 Optimized Row Columnar 1.ORC是一个文件格式比较高效的读取、写入、处理hive数据。(我之前理解是一个高效压缩文件)。2.序列化和压缩: intger和String 序列化。按照文件块增量的压缩。
文件结构:三级结构:stripes 存在具体的数据行组(索引、数据行、stripe footer 的信息),file footer 文件的辅助信息(stripe的列表、每个stripe行数、列的数据类型、列上聚合信息 最大值最小值),psotscipt 文件的压缩参数和压缩后的大小。
3.使用方法和场景: 因此ETL模式下读取的file footer是每个orc文件块的辅助信息。对于一些较大的ORC表,footer可能非常大,ETL模式下读取大量hdfs的数据信息切分文件,导致driver的开销压力过大,这种情况适用BI模式比较合适。
一些配合使用参数 如:spark.hadoop.mapreduce.input.fileinputformat.split.maxsize; spark.hadoop.mapreduce.input.fileinputformat.split.minsize; map输入最小最大分割块,maxsize 和minsize在输入端控制ORC文件的分割合并。当spark 从hive表中读取数据是会创建一个HadoopRDD的实例,HadoopRDD根据computeSplitSize方法分割文件(org.apache.hadoop.mapreduce.lib.input.FileInputFormat ) Math.max(minSize, Math.min(maxSize, blockSize) 源代码Source code,因此文件表的小文件过多3M大小,根据公式一个小文件就是一个split分割生成大量的patitions,导致tasks数量就巨大,整个任务性能瓶颈可能在读取资源数据缓解。
文件分割源码

 spark.sql.files.maxPartitionBytes 单partition的最大字节数, 为了防止把已经设置好的分割块再次合并,可以将 set spark.hadoopRDD.targetBytesInPartition=-1。
spark.sql.files.maxPartitionBytes 单partition的最大字节数, 为了防止把已经设置好的分割块再次合并,可以将 set spark.hadoopRDD.targetBytesInPartition=-1。

2.spark.sql.shuffle.partitions
参数作用: 在任务有shuffle时候(join或者聚合场景下)控制partitions的数量。
参数介绍:
| Property Name | Default | meaning | 链接 | 翻译 | 不同点 | 共同点 |
| spark.sql.shuffle.partitions | 200 | Configures the number of partitions to use when shuffling data for joins or aggregations. | Spark SQL and DataFrames - Spark 2.0.0 Documentation | Spark SQL中shuffle过程中Partition的数量 | 仅适用于DataFrame ,group By, join 触发数据shuffle,因此这些数据转换后的结果会导致分区大小需要通过Spark.sql.shuffle.partitions 中设置的值。 | 配置shuffle partitions 的数量 |
| spark.default.parallelism | For distributed shuffle operations like reduceByKeyand join, the largest number of partitions in a parent RDD. For operations like parallelizewith no parent RDDs, it depends on the cluster manager:
| Default number of partitions in RDDs returned by transformations like join, reduceByKey, and parallelize when not set by user. | Configuration - Spark 3.5.0 Documentation | 1.reduceByKey 1.若当前RDD执行shuffle操算子如reducebykey 和join ,则为在父RDD中最大的partition数。 | spark.default.parallelism 是随 RDD 引入的,当用户未设置时候,返回reduceByKey(), groupByKey(), join() 转换的默认分区数,仅适用于RDD。 |
参数用法:在提交作业的通过 --conf 来修改这两个设置的值,方法如下:或者
spark-submit --conf spark.sql.shuffle.partitions=300 --conf spark.default.parallelism=300
sqlContext.setConf("spark.sql.shuffle.partitions", "300")
sqlContext.setConf("spark.default.parallelism", "300”)
参数介绍2.0:chatGPT3.5 的答案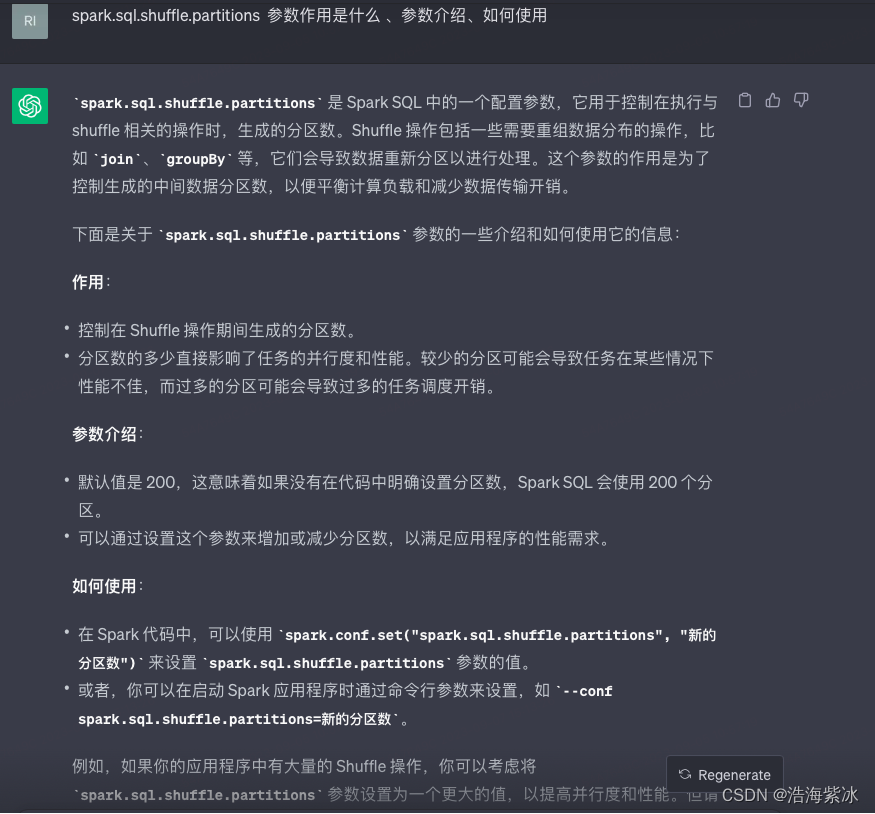
理解spark的并行度:
-
资源的并行 exector数和cpu core数
-
数据的并行 spark作业在各个stage的task 的数量是并行执行,task数量设置成Spark Application总CPU core数量的2~3倍,同时尽量提升Spark运行效率和速度;
扩展: flink 的并行度
参考文档:
1.Spark SQL底层执行流程详解(好文收藏)-腾讯云开发者社区-腾讯云 spark 执行原理
2.ORC 参数:Configuration Properties - Apache Hive - Apache Software Foundation
3.ORC文件定义: LanguageManual ORC - Apache Hive - Apache Software Foundation
4.oRC解读: 深入理解ORC文件结构-CSDN博客
5.hadoop input: How does Spark SQL decide the number of partitions it will use when loading data from a Hive table? - Stack Overflow
6.文件分割:从源码看Spark读取Hive表数据小文件和分块的问题 - 掘金, How does Spark SQL decide the number of partitions it will use when loading data from a Hive table? - Stack Overflow
7.spark手册:How to Set Apache Spark Executor Memory - Spark By {Examples}
8.并行: performance - What is the difference between spark.sql.shuffle.partitions and spark.default.parallelism? - Stack Overflow
9.flink的并行 : 并行执行 | Apache Flink
10.reducebykey :scala - reduceByKey: How does it work internally? - Stack Overflow
11.key values : 4. Working with Key/Value Pairs - Learning Spark [Book]
12.spark并行: Spark调优之 -- Spark的并行度深入理解(别再让资源浪费了)_spark并行度-CSDN博客
13.场景: spark SQL 任务参数调优1
相关文章:
spark SQL 任务参数调优1
1.背景 要了解spark参数调优,首先需要清楚一部分背景资料Spark SQL的执行原理,方便理解各种参数对任务的具体影响。 一条SQL语句生成执行引擎可识别的程序,解析(Parser)、优化(Optimizer)、执行…...

算法练习2——移除元素
LeetCode 27 移除元素 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。 不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。 元素的顺序可以改变。你不需要考虑…...
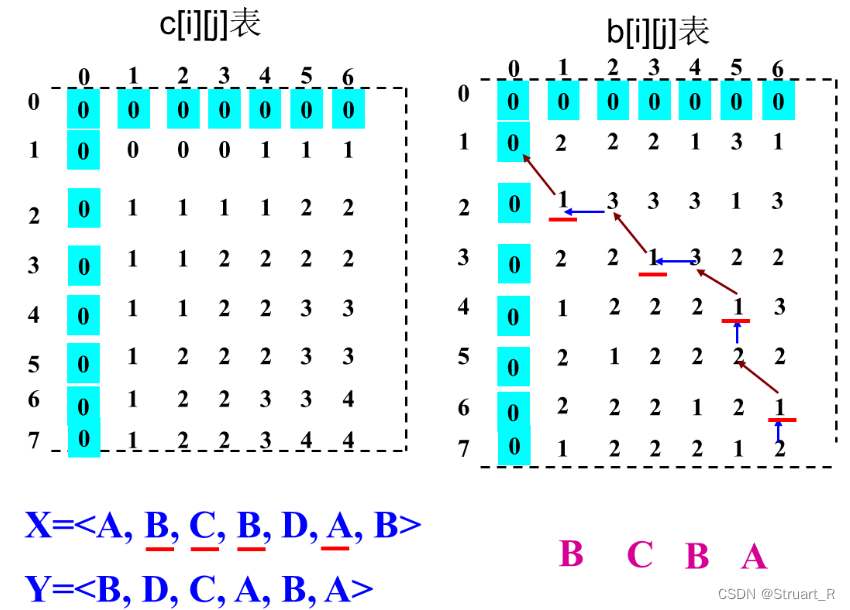
动态规划算法(2)--最大子段和与最长公共子序列
目录 一、最大子段和 1、什么是最大子段和 2、暴力枚举 3、分治法 4、动态规划 二、最长公共子序列 1、什么是最长公共子序列 2、暴力枚举法 3、动态规划法 4、完整代码 一、最大子段和 1、什么是最大子段和 子段和就是数组中任意连续的一段序列的和,而…...
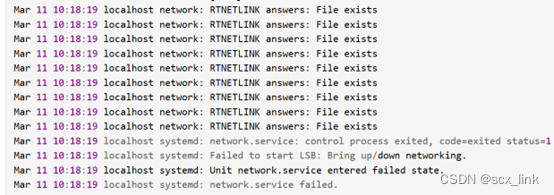
CentOS上网卡不显示的问题
文章目录 1.问题描述 1.问题描述 ifconfig下看不到ens33网卡了。systemctl status network #查看网卡状态报下面的问题网上说的解决方式有以下三种: 第一种: 和 NetworkManager 服务有冲突,这个好解决,直接关闭 NetworkManger 服…...

localStorage实现历史记录搜索功能
📝个人主页:爱吃炫迈 💌系列专栏:JavaScript 🧑💻座右铭:道阻且长,行则将至💗 文章目录 为什么使用localStorage如何使用localStorage实现历史记录搜索功能(…...

计算机网络(一):概述
参考引用 计算机网络微课堂-湖科大教书匠计算机网络(第7版)-谢希仁 1. 计算机网络在信息时代的作用 计算机网络已由一种通信基础设施发展成为一种重要的信息服务基础设施计算机网络已经像水、电、煤气这些基础设施一样,成为我们生活中不可或…...

visual code 下的node.js的hello world
我装好了visual code ,想运行一个node.js 玩玩。也就是运行一个hello world。 一:安装node.js : 我google 安装node.js 就引导我到下载页面:https://nodejs.org/en/download 有 Windows Installer (.msi) 还有Windows Binary (…...
)
MySQL——四、SQL语句(下篇)
MySQL 一、常见的SQL函数1、数学函数2、日期函数3、分组函数(聚合函数)4、流程控制函数 二、where条件查询和order by排序三、分组统计四、多表关联查询1、交叉连接CROSS2、内连接inner3、外连接:outer4、子查询 五、分页查询 一、常见的SQL函数 1、length(str):获…...

蓝桥杯每日一题2023.10.2
时间显示 - 蓝桥云课 (lanqiao.cn) 题目描述 题目分析 输入为毫秒,故我们可以先将毫秒转化为秒,由于只需要输出时分,我们只需要将天数去除即可,可以在这里多训练一次天数判断 #include<bits/stdc.h> using namespace std…...
红外遥控器 数据格式,按下及松开判断
红外遥控是一种无线、非接触控制技术,具有抗干扰能力强,信息传输可靠,功耗低,成本低,易实现等显著优点,被诸多电子设备特别是家用电器广泛采用,并越来越多的应用到计算机系统中。 同类产品的红…...
)
win32进程间通信方式(13种)
win32进程间通信 文件映射共享内存匿名管道命名管道远程过程调用(RPC)对象连接与嵌入(OLE)动态数据交换(DDE)剪贴板WM_COPYDATA消息邮件槽其它 文件映射 特点:本地间通信,不能用于网…...

基于Vue+ELement搭建动态树与数据表格实现分页模糊查询
🎉🎉欢迎来到我的CSDN主页!🎉🎉 🏅我是Java方文山,一个在CSDN分享笔记的博主。📚📚 🌟推荐给大家我的专栏《ELement》。🎯🎯 …...

多线程案例 - 单例模式
单例模式 ~~ 单例模式是常见的设计模式之一 什么是设计模式 你知道象棋,五子棋,围棋吗?如果,你想下好围棋,你就不得不了解一个东西,”棋谱”,设计模式好比围棋中的 “棋谱”. 在棋谱里面,大佬们,把一些常见的对局场景,都给推演出来了,照着棋谱来下棋,基本上棋力就不会差到哪…...
云原生Kubernetes:对外服务之 Ingress
目录 一、理论 1.Ingress 2.部署 nginx-ingress-controller(第一种方式) 3.部署 nginx-ingress-controller(第二种方式) 二、实验 1.部署 nginx-ingress-controller(第一种方式) 2.部署 nginx-ingress-controller(第二种方式) 三、问题 1.启动 nginx-ingress-controll…...

Java21 新特性
文章目录 1. 概述2. JDK21 安装与配置3. 新特性3.1 switch模式匹配3.2 字符串模板3.3 顺序集合3.4 记录模式(Record Patterns)3.5 未命名类和实例的main方法(预览版)3.6 虚拟线程 1. 概述 2023年9月19日 ,Oracle 发布了…...

Rest Template 使用
大家好我是苏麟 今天带来Rest Template . spring框架中可以用restTemplate来发送http连接请求, 优点就是方便. Rest Template 使用 Rest Template 使用步骤 /*** RestTemple:* 1.创建RestTemple类并交给IOC容器管理* 2. 发送http请求的类*/ 1.注册RestTemplate对象 SpringB…...
IDEA git操作技巧大全,持续更新中
作者简介 目录 1.创建新项目 2.推拉代码 3.状态标识 5.cherry pick 6.revert 7.squash 8.版本回退 9.合并冲突 1.创建新项目 首先我们在GitHub上创建一个新的项目,然后将这个空项目拉到本地,在本地搭建起一个maven项目的骨架再推上去࿰…...
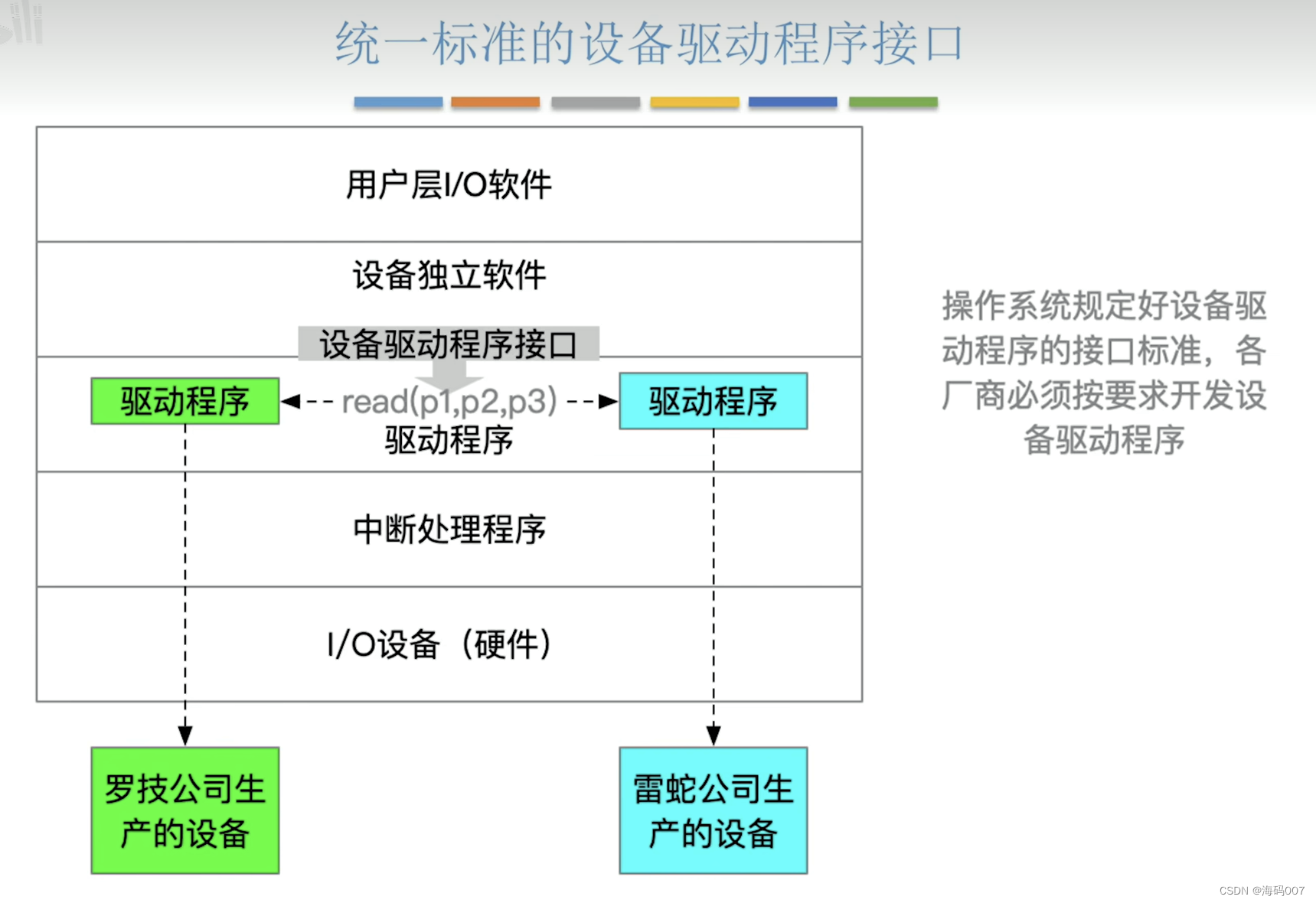
计算机操作系统 (王道考研)笔记(四)I/O系统
目录 1 I/O1.1 I/O 概念和分类1.1.1 I/O 定义1.1.2 I/O 分类 1.2 I/O控制器1.3 I/O 软件层次结构1.4 I/O 应用程序接口和驱动程序应用接口 1 I/O 1.1 I/O 概念和分类 1.1.1 I/O 定义 BIOS(英文:Basic Input/Output System),即基…...
【Java基础】抽象类和接口的使用
个人主页:兜里有颗棉花糖 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【JavaSE_primary】 本专栏旨在分享学习JavaSE的一点学习心得,欢迎大家在评论区讨论💌 目录 一、抽象类抽象类概念…...

Golang的性能优化
欢迎,学习者们,来到Golang性能优化的令人兴奋的世界!作为开发者,我们都努力创建高效、闪电般快速的应用程序,以提供出色的用户体验。在本文中,我们将探讨优化Golang应用程序性能的基本技巧。所以࿰…...

基于MCP的任务编排框架:让AI代理动态规划与执行复杂工作流
1. 项目概述:一个面向AI代理的任务编排与执行框架最近在折腾AI应用开发,特别是想让大语言模型(LLM)能更“自主”地完成一些复杂任务时,发现了一个绕不开的痛点:任务编排。你给模型一个目标,比如…...

Cerebro:为AI构建持久记忆与认知能力的本地化MCP工具系统
1. 项目概述:为AI赋予持久记忆与认知能力如果你和我一样,每天都在和Claude、ChatGPT这类大语言模型打交道,那你一定遇到过这个让人头疼的问题:每次开启一个新的对话会话,AI就像得了“健忘症”,之前聊过的项…...

从0到1掌握Ansible:让自动化运维不再是梦想
最近在公司推进自动化运维的时候,发现很多同事对Ansible还是一知半解,要么就是简单用用,要么就是直接放弃。其实Ansible真的没那么复杂,我用了这么多年,今天就把我的实战经验分享给大家。 说实话,刚开始接…...

LVGL列表控件实战:5分钟搞定一个带图标和事件响应的菜单界面
LVGL列表控件实战:5分钟打造高交互性嵌入式菜单界面 在嵌入式设备的人机交互设计中,菜单界面是最基础也最关键的组件之一。想象一下,当你需要为智能家居控制面板设计一个简洁明了的操作菜单,或者为工业设备开发一个功能选择界面时…...

从规范到验证:构建企业级环境变量与密钥安全管理体系
1. 项目概述:从“裸奔”到“装甲车”的密钥管理进化在开发一个现代应用时,我们几乎不可避免地要和一堆敏感信息打交道:数据库密码、API密钥、第三方服务的访问令牌、加密盐值……这些信息,我们通常称之为“环境变量”或“密钥”。…...

Taotoken用量看板与成本管理功能的实际使用体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板与成本管理功能的实际使用体验 对于需要持续调用大模型API的项目而言,成本的可观测与可控性是管理中的…...

谷歌seo搜索引擎优化教程有吗?只需4步:快速提升关键词前10概率
搜索结果首页占据了超过 94% 的点击流量。如果你的网站排在第二页,那几乎等同于不存在。很多人在寻找 谷歌seo搜索引擎优化教程有吗?只需4步:快速提升关键词前10概率 的答案时,容易被复杂的技术词汇绕晕。提升排名的过程其实是关于…...

模拟工程师必备:口袋参考指南的实战价值与核心应用
1. 为什么每个硬件工程师都需要一本“口袋参考书”?前几天整理书桌,翻出来一本2016年从TI官网下载打印的《模拟工程师口袋参考指南》,纸张已经有点发黄,边角也卷了。但就是这么一本薄薄的小册子,从毕业到现在ÿ…...

为AI智能体构建可编程邮箱:mailbot实战指南
1. 项目概述:为AI智能体打造专属的“可编程邮箱”如果你正在开发一个AI智能体,无论是客服机器人、自动化工作流还是个人助理,让它具备收发邮件的能力往往是刚需。传统的做法是什么?要么去折腾Gmail的API,忍受OAuth授权…...

开发AI智能体时利用Taotoken统一调度多模型提升任务完成率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 开发AI智能体时利用Taotoken统一调度多模型提升任务完成率 在构建需要处理复杂、多模态任务的AI智能体时,单一模型的能…...