Pytorch单机多卡分布式训练
Pytorch单机多卡分布式训练
数据并行:
DP和DDP
这两个都是pytorch下实现多GPU训练的库,DP是pytorch以前实现的库,现在官方更推荐使用DDP,即使是单机训练也比DP快。
-
DataParallel(DP)
- 只支持单进程多线程,单一机器上进行训练。
- 模型训练开始的时候,先把模型复制到四个GPU上面,然后把数据分配给四个GPU进行前向传播,前向传播之后再汇总到卡0上面,然后在卡0上进行反向传播,参数更新,再将更新好的模型复制到其他几张卡上。

-
DistributedDataParallel(DDP)
-
支持多线程多进程,单一或者多个机器上进行训练。通常DDP比DP要快。
-
先把模型载入到四张卡上,每个GPU上都分配一些小批量的数据,再进行前向传播,反向传播,计算完梯度之后再把所有卡上的梯度汇聚到卡0上面,卡0算完梯度的平均值之后广播给所有的卡,所有的卡更新自己的模型,这样传输的数据量会少很多。
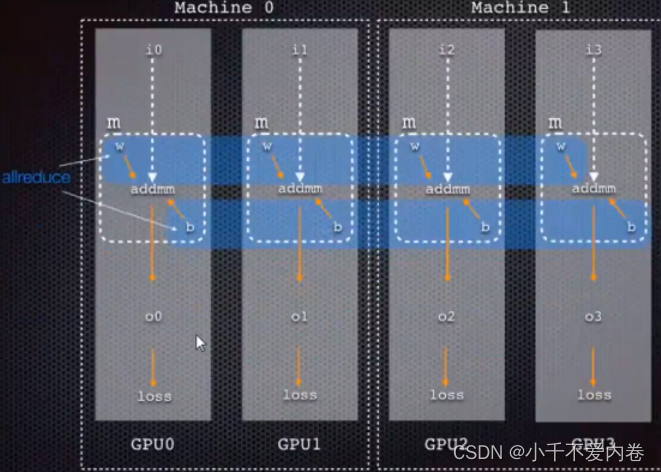
-
DDP代码写法
-
初始化
import torch.distributed as dist import torch.utils.data.distributed# 进行初始化,backend表示通信方式,可选择的有nccl(英伟达的GPU2GPU的通信库,适用于具有英伟达GPU的分布式训练)、gloo(基于tcp/ip的后端,可在不同机器之间进行通信,通常适用于不具备英伟达GPU的环境)、mpi(适用于支持mpi集群的环境) # init_method: 告知每个进程如何发现彼此,默认使用env:// dist.init_process_group(backend='nccl', init_method="env://") -
设置device
device = torch.device(f'cuda:{args.local_rank}') # 设置device,local_rank表示当前机器的进程号,该方式为每个显卡一个进程 torch.cuda.set_device(device) # 设定device -
创建dataloader之前要加一个sampler
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))]) data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True) train_sampler = torch.utils.data.distributed.DistributedSampler(data_set) # 加一个sampler data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256, sampler=train_sampler) -
torch.nn.parallel.DistributedDataParallel包裹模型(先to(device)再包裹模型)
net = torchvision.models.resnet101(num_classes=10) net.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False) net = net.to(device) net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[device], output_device=[device]) # 包裹模型 -
真正训练之前要set_epoch(),否则将不会shuffer数据
for epoch in range(10):train_sampler.set_epoch(epoch) # set_epochfor step, data in enumerate(data_loader_train):images, labels = dataimages, labels = images.to(device), labels.to(device)opt.zero_grad()outputs = net(images)loss = criterion(outputs, labels)loss.backward()opt.step()if step % 10 == 0:print("loss: {}".format(loss.item())) -
模型保存
if args.local_rank == 0: # local_rank为0表示master进程torch.save(net, "my_net.pth") -
运行
if __name__ == "__main__":parser = argparse.ArgumentParser()# local_rank参数是必须的,运行的时候不必自己指定,DDP会自行提供parser.add_argument("--local_rank", type=int, default=0)args = parser.parse_args()main(args) -
运行命令
python -m torch.distributed.launch --nproc_per_node=2 多卡训练.py # --nproc_per_node=2表示当前机器上有两个GPU可以使用
完整代码
import os
import argparse
import torch
import torchvision
import torch.distributed as dist
import torch.utils.data.distributedfrom torchvision import transforms
from torch.multiprocessing import Processdef main(args):# nccl: 后端基于NVIDIA的GPU-to-GPU通信库,适用于具有NVIDIA GPU的分布式训练# gloo: 后端是一个基于TCP/IP的后端,可在不同机器之间进行通信,通常适用于不具备NVIDIA GPU的环境。# mpi: 后端使用MPI实现,适用于具备MPI支持的集群环境。# init_method: 告知每个进程如何发现彼此,如何使用通信后端初始化和验证进程组。 默认情况下,如果未指定 init_method,PyTorch 将使用环境变量初始化方法 (env://)。dist.init_process_group(backend='nccl', init_method="env://") # nccl比较推荐device = torch.device(f'cuda:{args.local_rank}')torch.cuda.set_device(device)trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])data_set = torchvision.datasets.MNIST("./", train=True, transform=trans, target_transform=None, download=True)train_sampler = torch.utils.data.distributed.DistributedSampler(data_set)data_loader_train = torch.utils.data.DataLoader(dataset=data_set, batch_size=256, sampler=train_sampler)net = torchvision.models.resnet101(num_classes=10)net.conv1 = torch.nn.Conv2d(1, 64, (7, 7), (2, 2), (3, 3), bias=False)net = net.to(device)net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[device], output_device=[device])criterion = torch.nn.CrossEntropyLoss()opt = torch.optim.Adam(params=net.parameters(), lr=0.001)for epoch in range(10):train_sampler.set_epoch(epoch)for step, data in enumerate(data_loader_train):images, labels = dataimages, labels = images.to(device), labels.to(device)opt.zero_grad()outputs = net(images)loss = criterion(outputs, labels)loss.backward()opt.step()if step % 10 == 0:print("loss: {}".format(loss.item()))if args.local_rank == 0:torch.save(net, "my_net.pth")if __name__ == "__main__":parser = argparse.ArgumentParser()# must parse the command-line argument: ``--local_rank=LOCAL_PROCESS_RANK``, which will be provided by DDPparser.add_argument("--local_rank", type=int, default=0)args = parser.parse_args()main(args)参考:
https://zhuanlan.zhihu.com/p/594046884
https://zhuanlan.zhihu.com/p/358974461
相关文章:
Pytorch单机多卡分布式训练
Pytorch单机多卡分布式训练 数据并行: DP和DDP 这两个都是pytorch下实现多GPU训练的库,DP是pytorch以前实现的库,现在官方更推荐使用DDP,即使是单机训练也比DP快。 DataParallel(DP) 只支持单进程多线程…...

asp.net coremvc+efcore增删改查
下面是一个使用 EF Core 在 ASP.NET Core MVC 中完成增删改查的示例: 创建一个新的 ASP.NET Core MVC 项目。 安装 EF Core 相关的 NuGet 包。在项目文件 (.csproj) 中添加以下依赖项: <ItemGroup><PackageReference Include"Microsoft…...

Java基础面试,什么是面向对象,谈谈你对面向对象的理解
前言 马上就要找工作了,从今天开始一天准备1~2道面试题,来打基础,就从Java基础开始吧。 什么是面向对象,谈谈你对面向对象的理解? 谈到面向对象,那就不得不谈到面向过程。面向过程更加注重的是完成一个任…...
Ubuntu系统初始设置
更换国内源 安装截图工具 安装中文输入法 安装QQ 参考: 安装双系统win10Ubuntu20.04LTS(详细到我自己都害怕) 引导方式磁盘分区方法UEFIGPTLegancyMBR 安装网络助手 sudo apt install net-tools 安装VS Code 使用从官网下载.deb安装包…...

焕新古文化传承之路,AI为古彝文识别赋能
目录 1 古彝文与古典保护 2 古文识别的挑战 2.1 西文与汉文OCR 2.2 古彝文识别难点 3 合合信息:古彝文保护新思路 3.1 图像矫正 3.2 图像增强 3.3 语义理解 3.4 工程技巧 4 总结 1 古彝文与古典保护 彝文指的是云南、贵州、四川等地的彝族人使用的文字&am…...

毛玻璃动画交互效果
效果展示 页面结构组成 从上述的效果展示页面结构来看,页面布局都是比较简单的,只是元素的动画交互比较麻烦。 第一个动画交互是两个圆相互交错来回运动。第二个动画交互是三角绕着圆进行 360 度旋转。 CSS 知识点 animationanimation-delay绝对定位…...

Audio2Face的工作原理
预加载一个3D数字人物模型(Digital Mark),该模型可以通过音频驱动进行面部动画。 用户上传音频文件作为输入。 将音频输入馈送到预训练的深度神经网络中。 Audio2Face加载预制的3d人头mesh 3D数字人物面部模型由大量顶点组成,每个顶点都有xyz坐标。 深度神经网络输入音频特征,…...

【面试题】2023前端面试真题之JS篇
前端面试题库 (面试必备) 推荐:★★★★★ 地址:前端面试题库 表妹一键制作自己的五星红旗国庆头像,超好看 世界上只有一种真正的英雄主义,那就是看清生活的真相之后,依然热爱生活。…...
Mysql 分布式序列算法
接上文 Mysql分库分表 1.分布式序列简介 在分布式系统下,怎么保证ID的生成满足以上需求? ShardingJDBC支持以上两种算法自动生成ID。这里,使用ShardingJDBC让主键ID以雪花算法进行生成,首先配置数据库,因为默认的注…...

Windows/Linux双系统卸载Ubuntu
参考:双系统下完全卸载ubuntu...

asp.net core mvc 视图组件viewComponents
ASP.NET Core MVC 视图组件(View Components)是一种可重用的 UI 组件,用于在视图中呈现某些特定的功能块,例如导航菜单、侧边栏、用户信息等。视图组件提供了一种将视图逻辑与控制器解耦的方式,使视图能够更加灵活、可…...

如何保持终身学习
文章目录 2.1. 了解你的大脑2.2 学习是对神经元网络的塑造2.3 大脑的一生 3.学习的心里基础3.1 固定思维与成长思维3.2 我们为什么要学习 4. 学习路径4.1 构建知识模块4.2 大脑是如何使用注意力的4.3 提高专注力4.4 放松一下,学的更好4.5 巩固你的学习痕迹4.6 被动学…...
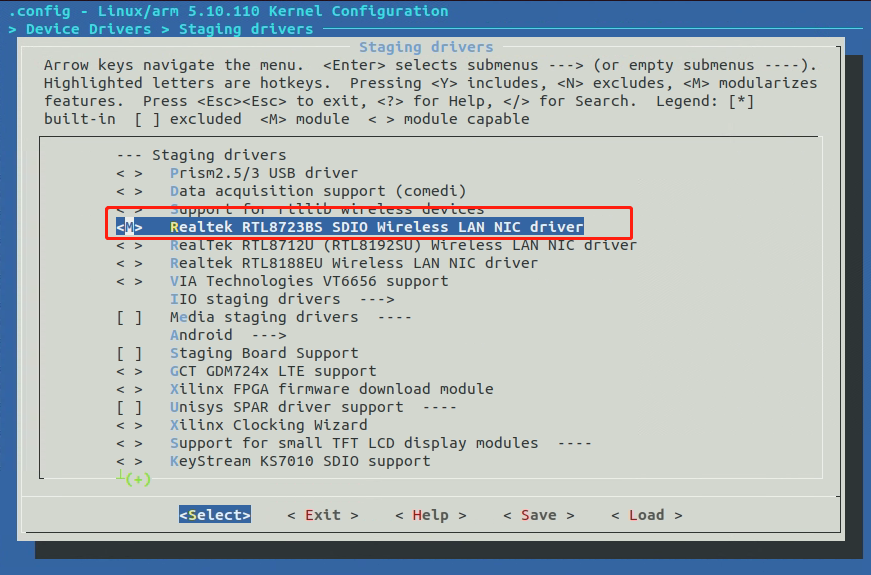
【RV1103】RTL8723bs (SD卡形状模块)驱动开发
文章目录 前言硬件分析Luckfox Pico的SD卡接口硬件原理图LicheePi zero WiFiBT模块总结 正文Kernel WiFi驱动支持Kernel 设备树支持修改一:修改二: SDK全局配置支持 wifi全局编译脚本支持编译逻辑拷贝rtl8723bs的固件到文件系统的固定目录里面去 上电后手…...

LeetCode 周赛上分之旅 #49 再探内向基环树
⭐️ 本文已收录到 AndroidFamily,技术和职场问题,请关注公众号 [彭旭锐] 和 BaguTree Pro 知识星球提问。 学习数据结构与算法的关键在于掌握问题背后的算法思维框架,你的思考越抽象,它能覆盖的问题域就越广,理解难度…...

kubernetes-v1.23.3 部署 kafka_2.12-2.3.0
文章目录 [toc]构建 debian 基础镜像部署 zookeeper配置 namespace配置 gfs 的 endpoints配置 pv 和 pvc配置 configmap配置 service配置 statefulset 部署 kafka配置 configmap配置 service配置 statefulset 这里采用的部署方式如下: 使用自定义的 debian 镜像作为…...

位置编码器
目录 1、位置编码器的作用 2、代码演示 (1)、使用unsqueeze扩展维度 (2)、使用squeeze降维 (3)、显示张量维度 (4)、随机失活张量中的数值 3、定义位置编码器类,我…...
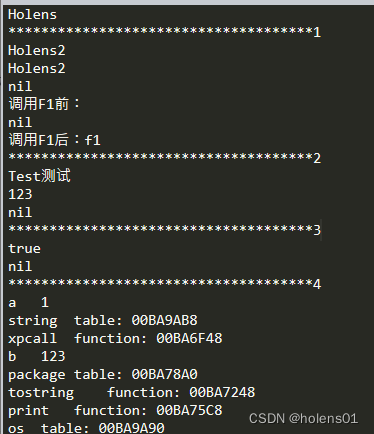
Lua多脚本执行
--全局变量 a 1 b "123"for i 1,2 doc "Holens" endprint(c) print("*************************************1")--本地变量(局部变量) for i 1,2 dolocal d "Holens2"print(d) end print(d)function F1( ..…...
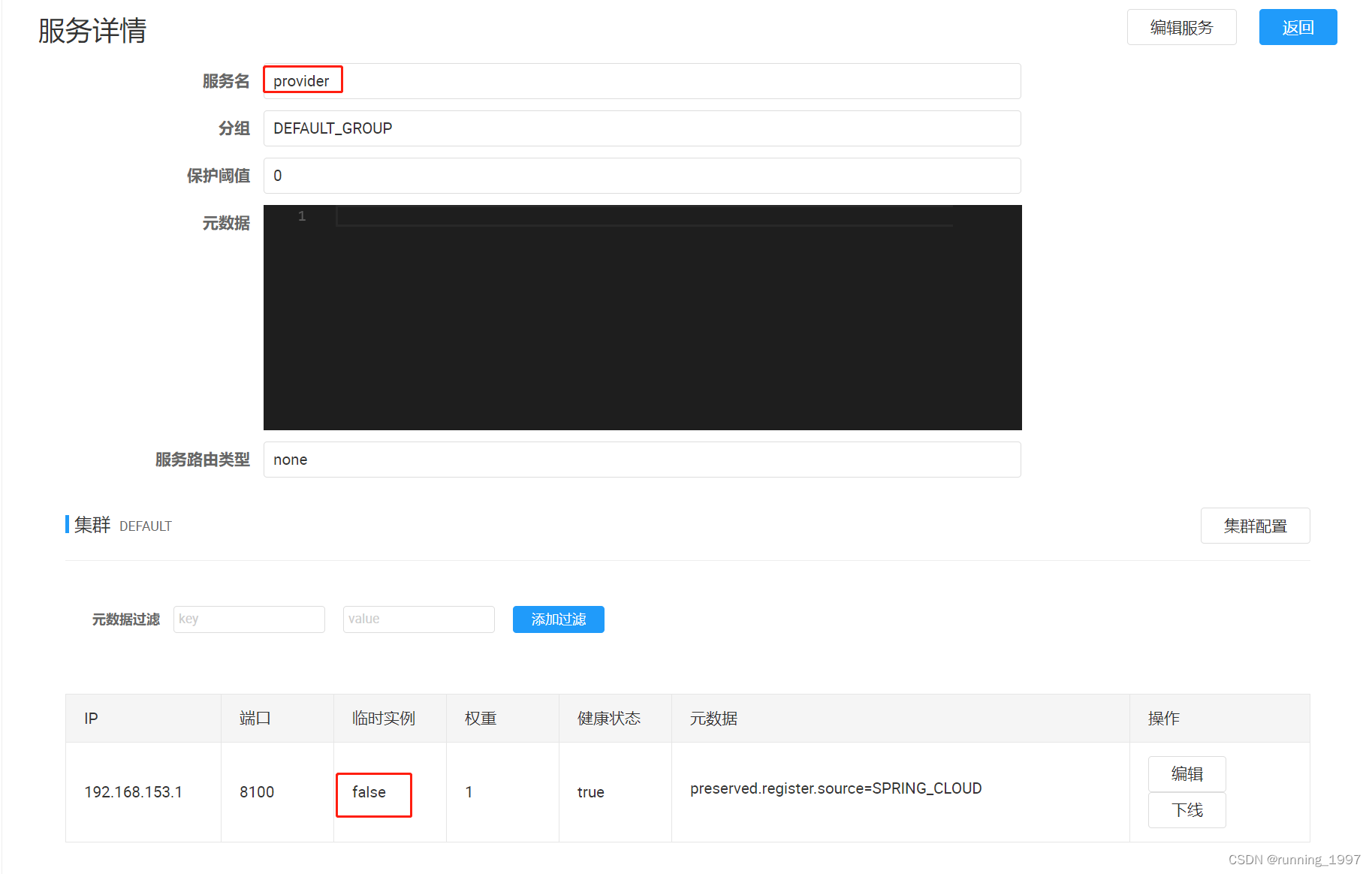
Spirng Cloud Alibaba Nacos注册中心的使用 (环境隔离、服务分级存储模型、权重配置、临时实例与持久实例)
文章目录 一、环境隔离1. Namespace(命名空间):2. Group(分组):3. Services(服务):4. DataId(数据ID):5. 实战演示:5.1 默…...

26663-2011 大型液压安全联轴器 课堂随笔
声明 本文是学习GB-T 26663-2011 大型液压安全联轴器. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 1 范围 本标准规定了大型液压安全联轴器的分类、技术要求、试验方法及检验规则等。 本标准适用于联接两同轴线的传动轴系,可起到限制…...
ChatGPT架构师:语言大模型的多模态能力、幻觉与研究经验
来源 | The Robot Brains Podcast OneFlow编译 翻译|宛子琳、杨婷 9月26日,OpenAI宣布ChatGPT新增了图片识别和语音能力,使得ChatGPT不仅可以进行文字交流,还可以给它展示图片并进行互动,这是一次ChatGPT向多模态进化的…...

Python蒙特卡洛树搜索实战:手把手教你调参,让黑白棋AI从‘菜鸟’变‘高手’
Python蒙特卡洛树搜索实战:从调参到策略优化的完整指南 蒙特卡洛树搜索(MCTS)作为近年来最成功的游戏AI算法之一,已经在围棋、黑白棋等策略游戏中展现出惊人的实力。但很多开发者在实现基础版本后,常常陷入性能瓶颈——…...

Windows系统级课堂管理软件反控制技术实现:JiYuTrainer内核驱动与API拦截架构解析
Windows系统级课堂管理软件反控制技术实现:JiYuTrainer内核驱动与API拦截架构解析 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 在现代化教育信息化环境中ÿ…...

喜马拉雅音频本地化实战:绕过xm格式,直接获取mp3文件的两种方法对比
喜马拉雅音频本地化实战:两种高效获取MP3文件的技术方案深度评测 作为国内领先的音频分享平台,喜马拉雅拥有海量优质内容,但其特有的XM格式却给用户跨平台使用带来了困扰。许多技术爱好者尝试过各种转换工具,却发现市面上几乎没有…...

如何做谷歌SEO排名优化?搞定高质量外链的4种高成功率技巧
很多刚接触谷歌SEO的朋友发现,自己的网站内容写了不少,可排名始终在搜索结果的五六页开外晃悠。排除掉网站技术层面的小毛病,最让大家头疼的往往就是外链。你可以把外链看作是其他网站给你的“信任投票”,如果投给你的都是些街边的…...

长期使用Taotoken Token Plan套餐带来的成本控制感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken Token Plan套餐带来的成本控制感受 1. 从按需付费到预算规划 对于个人开发者或小型团队而言,大模型…...

如何高效使用Fast-GitHub加速插件:5个提升GitHub访问速度的实用技巧
如何高效使用Fast-GitHub加速插件:5个提升GitHub访问速度的实用技巧 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 还…...

终极SQLC资源管理指南:轻松优化内存、CPU和磁盘使用的7个实用策略
终极SQLC资源管理指南:轻松优化内存、CPU和磁盘使用的7个实用策略 【免费下载链接】sqlc Generate type-safe code from SQL 项目地址: https://gitcode.com/gh_mirrors/sq/sqlc sqlc是一个强大的工具,能够从SQL生成类型安全的代码,帮…...

【独家首发】ElevenLabs中文语音优化白皮书:针对普通话声调、儿化音与连读现象的5层微调协议
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs超写实语音生成教程 ElevenLabs 是当前业界领先的 AI 语音合成平台,其模型在语调自然度、情感表达力与跨语言一致性方面表现卓越。本章将指导你完成从 API 接入到高质量语音生成的…...

Modbus RTU 与 Modbus TCP 深入指南-附录:快速参考表
十五、附录:快速参考表 15.1 Modbus RTU 帧示例速查 操作请求帧(十六进制)响应帧示例读线圈(1个)01 01 00 00 00 01 CRC01 01 01 01 CRC读离散输入01 02 00 00 00 01 CRC01 02 01 00 CRC读保持寄存器(1个…...

ZeroAPI:基于订阅与任务感知的AI模型智能路由插件设计与实践
1. 项目概述:ZeroAPI,一个为AI订阅服务而生的智能路由插件如果你和我一样,手头订阅了不止一个AI服务——比如OpenAI的ChatGPT Plus、月之暗面的Kimi、智谱AI的GLM,可能还有MiniMax或者通义千问——那你一定遇到过这个烦恼…...