数据仓库工作问题总结
1. ODS 层采用什么压缩方式和存储格式?
压缩采用 Snappy ,存储采用 orc ,压缩比是 100g 数据压缩完 10g 左右。
2. DWD 层做了哪些事?
1.、数据清洗
- 空值去除
- 过滤核心字段无意义的数据,比如订单表中订单 id 为 null,支付表中支付id 为空
- 对手机号、身份证号等敏感数据脱敏
- 对业务数据传过来的表进行维度退化和降维。
- 将用户行为宽表和业务表进行数据一致性处理
2、 清洗的手段
Sql、mr、rdd、kettle、Python(项目中采用 sql 进行清除)
3.、DWS 层做了哪些事?
1.、DWS 层有 3-5 张宽表(处理 100-200 个指标 70%以上的需求)
具体宽表名称:用户行为宽表,用户购买商品明细行为宽表,商品宽表,购物车、宽表,物流宽表、登录注册、售后等。
2.、哪个宽表最宽?大概有多少个字段?
最宽的是用户行为宽表。大概有60-100 个字段
4、数据漂移如何解决?
- 什么是数据漂移及情况
通常是指ods表的同⼀个业务⽇期数据中包含了前⼀天或后⼀天凌晨附近的数据或者丢失当天变更的数据,这种现象就叫做漂移, - 解决数据漂移方法
两种方案:
1.、多获取一点后⼀天的数据,保障数据只多不少
2、第⼀种⽅案⾥,时间戳字段分为四类:
- 数据库表中⽤来标识数据记录更新时间的时间戳字段(假设这类字段叫modified time )。
- 数据库⽇志中⽤来标识数据记录更新时间的时间戳字段·(假设这类宇段叫 log_time)。
- 数据库表中⽤来记录具体业务过程发⽣时间的时间戳字段 (假设这类字段叫 proc_time)。
- 标识数据记录被抽取到时间的时间戳字段(假设这类字段 extract time)。
理论上这⼏个时间应该是⼀致的,但往往会出现差异,造成的原因可能为:
5. 数据抽取需要⼀定的时间,extract_time 往往晚于前三个时间。
6. 业务系统⼿动改动数据并未更新 modfied_time。
7. ⽹络或系统压⼒问题,log_time 或 modified_time 晚于 proc_time。
通常都是根据以上的某⼏个字段来切分 ODS 表,这就产⽣了数据漂移。具体场
景如下:
- 根据 extract_time 进⾏同步。
- 根据 modified_time 进⾏限制同步, 在实际⽣产中这种情况最常⻅,但是往往会发⽣不更新 modified time⽽导致的数据遗漏,或者凌晨时间产⽣的数据记录漂移到后天 。由于⽹络或者系统压⼒问题, log_time 会晚proc_time ,从⽽导致凌晨时间产⽣的数据记录漂移到后⼀天。
- 根据 proc_time 来限制,会违背 ods 和业务库保持⼀致的原则,因为仅仅根据 proc_time 来限制,会遗漏很多其他过程的变化。
第⼆种解决⽅案:
- ⾸先通过 log_time多同步前⼀天最后 15 分钟和后⼀天凌晨开始 15 分钟的数据,然后⽤modified_time 过滤⾮当天的数据,这样确保数据不会因为系统问题被遗漏。
- 然后根据 log_time 获取后⼀天 15 分钟的数据,基于这部分数据,按照主键根据 log_time 做升序排序,那么第⼀条数据也就是最接近当天记录变化的。
- 最后将前两步的数据做全外连接,通过限制业务时间 proc_time 来获取想要的数据。
优化的场景
1、Hive 处理 100 亿+数据之性能优化
项目背景
有个关于bds项目,日增数据约6.5T,约100亿左右数据。通过清洗,输出不同5大维度,8 种粒度的依赖视图,以及相关的报表汇总统计。过程遇到了不少坑。在一些数据量大的场景下,很容易把一些潜在的问题就容易暴露出来,现总结如下
get_json_object()
描述:get_json_object 函数第一个参数填写 json 对象变量,第二个参数使用表示json变量标识,然后用.或[]读取对象或数组;定义:该方法只能接受两个参数,如果想要查看多个值,只能多写几个示例:selectgetjsonobject(′"name":"linda","server":"www.baidu.com"′,′表示json变量标识,然后用.或[]读取对象或数组; 定义:该方法只能接受两个参数,如果想要查看多个值,只能多写几个 示例:select get_json_object('{"name":"linda","server":"www.baidu.com"}','表示json变量标识,然后用.或[]读取对象或数组;定义:该方法只能接受两个参数,如果想要查看多个值,只能多写几个示例:selectgetjsonobject(′"name":"linda","server":"www.baidu.com"′,′.server’)
输出结果:
www.baidu.com
json_tuple()
定义:当使用 json_tuple 对象时,可以显著提高效率,一次获取多个对象并且可以被组
合使用
示例:
select
json_tuple(’{“name”:“linda”,“server”:“www.baidu.com”}’,‘server’,
‘name’)
输出结果:
linda www.baidu.com
通常,我们通过一下两种函数进行解析 get_json_object()或 json_tuple()。假如要从一张stg层表中将json字符串解析成对相应的字符串,假设有10个字段,那么get_json_object()方法相当于一条记录使用 10 次函数,而 json_tuple()方法只是使用了一次,进行了批量解析,这种方式明显更高(脑补下 JVM 的知识点)。另外,确认是否所有的字段都有必要解析?解析的字段越多,意味着序列化和反序列化,以及解析的工作量,这都是很消耗 CPU。而 CPU 核数越多,意味着并行处理的 task 的能力越强。通过这种优化思路,生产环境解析 json 这张表的时间从 4.5 小时缩减到 0.5 小时。
3.大表和大表 join
比如单表 100 亿,设计到父子关系,需要 join 自己,尽管通过 where 语句缩小了数据量,还是将近有 50 亿之间的 join,并在此之上进行汇总计算。我这里用了 3 中解决方案。
(1)临时表 :创建临时表,将 join 结果方法临时表,再从临时表取数据计算,若失败重试(默认 3 次)再从临时表取数据,跑完数据,删除临时表。
(2)动态分区:默认是按天分区,可以根据 join 的关键 ID hash 到不同分区中去(如10 个)按分区 join,再合并结果。
(3)分桶: 跟动态分区有点像,根据 cluster(xxId)
基于 hive 的大数据量的优化处理实例
是关于大数据量的数据,具体为一个 1000 亿的轻度汇总数据,去关联一个 7 亿左右的
另一个轻度汇总数据。
主要遇到的问题有:
1,1000 亿的轻度汇总数据读写困难,耗费时间、资源大;
2,两表进行关联处理数据计算慢。
背景:(完全假设来说)
A 表是以用户、城市维度的出现次数数据,字段主要有 user_id、city_id,cnt
B 表是以用户、城市维度的出现次数标准数据,字段主要有 user_id、city_id,city_cnt
主要是求用户是否在某个省份达到出现次数标准的进度,比如说小a在石家庄出现2次,在保定出现 5 次。但是在石家庄出现的标准次数应该为 4 次,在保定出现的标准次数为 4 次。所以在河北出现的标准次数为8次,而小a达标的次数分别为2次和4次(超过标准按照标准统计),所以小a在河北出现的次数进度为67%。针对以上数据量,目前想到的方案有以下三种:
方案一:拆分数据、分散资源,建立多个计算 task
(1)由于目的是对用户进行统计,所以对 A、B 表以及目标表根据 user_id 首位数字设
置分区,将数据量拆分;首先需要对 user_id 首位数进行数据量查询,然后按照数据量的大小进行合理分配分区。
(2)根据分区建多个 task,跑入对应目标表的分区;
对相同分区下的用户数据进行数据计算,然后建立多个 task 进行跑数,分散资源。
方案二:维度进行高粒度汇总,减小数据量
(1)维护一张城市和省份的维度表,在 A 表的计算过程中进行聚合,直接输出用户到省份维度,省略用户对城市的维度(A 表)。这样的话,就获取不到 A 表,得不到用户对城市维度的明细数据,对与数仓建设和后期数据维护不友好,但是对于本次项目的统计确实性能得到很好的提升。如果效果不好的话可以再重复方案一在用户对省份维度上建立分区。
(2)再与其用户到省份维度的表进行关联。
方案三:维度直接汇总到最高用户维度,建立数组存储省份信息,最大粒度减小数据量。
(1)涉及到的底层表聚合到用户维度,其余对应的城市和次数字段做成数组进行存储。建立以 user_id 作为主键,其余字段作为数据 map 的表,最大限度的满足当前需求,但是不利于数仓基础表的维护,再做新需求利用到同样数据源还需要进行同样的操作
(2)解析数组,再进行关联,输入到目标表。
对所有汇总到用户维度的底层表进行解析数组,然后进行关联再计算。针对以上方案,如果既需要满足本需求,又有利于数仓建设的话,推荐方案一,如果是敏捷开发,满足此需求的话推荐方案三,对于数据集市建设,如果没必要细致到用户到城市维度的话,建议方案二,三种方案各有利弊,具体选择需要根据实际情况定夺。
相关文章:

数据仓库工作问题总结
1. ODS 层采用什么压缩方式和存储格式? 压缩采用 Snappy ,存储采用 orc ,压缩比是 100g 数据压缩完 10g 左右。 2. DWD 层做了哪些事? 1.、数据清洗 空值去除过滤核心字段无意义的数据,比如订单表中订单 id 为 nul…...

Java常用算法
关于时间复杂度: 平方阶 (O(n2)) 排序 各类简单排序:直接插入、直接选择和冒泡排序。线性对数阶 (O(nlog2n)) 排序 快速排序、堆排序和归并排序。O(n1)) 排序, 是介于 0 和 1 之间的常数。希尔排序。线性阶 (O(n)) 排序 基数排序,…...

插画网课平台排名
插画网课平台哪个好,插画网课排名靠前的有哪些,今天给大家梳理了国内5家专业的插画网课平台,各有优势和特色,给学插画的小伙伴提供选择,报插画网课一定要选择靠谱的,否则人钱两空泪两行! 一&am…...

雷达、定位、跟踪等信号处理邻域SCI期刊整理及推荐
雷达邻域SCI期刊整理及推荐:题名、刊物信息、撰写特点、审稿周期及投稿难度总结 定位/跟踪邻域SCI期刊整理及推荐:题名、刊物信息、撰写特点、审稿周期及投稿难度总结 估计/滤波/融合等信号处理邻域SCI期刊整理及推荐:题名、刊物信息、撰写…...

NDK C++ 指针常量 常量指针 常量指针常量
指针常量 常量指针 常量指针常量// 指针常量 常量指针 常量指针常量#include <iostream> #include <string.h> #include <string.h>using namespace std;int main() {// *strcpy (char *__restrict, const char *__restrict);// strcpy()int number 9;int n…...
(一))
常见前端基础面试题(HTML,CSS,JS)(一)
html语义化的理解 代码结构: 使页面在没有css的情况下,也能够呈现出好的内容结构 有利于SEO: 爬虫根据标签来分配关键字的权重,因此可以和搜索引擎建立良好的沟通,帮助爬虫抓取更多的有效信息 方便其他设备解析: 如屏幕阅读器、盲人阅读器、移动设备等,…...
Delphi RSA加解密
感谢、感谢、感谢大佬的分享,https://github.com/ZYHPRO/RSAEncryptAndDecode 目录 1. 前言 2. 准备工作 3. Demo注意事项说明 3.1 公钥、私钥文本格式 3.2 回车键的影响 3.3 中文加解密说明 4. 结语 1. 前言 最近工作上安排了一个项目,与工商银行之…...

oracle基本操作
文章目录基本操作用户权限管理:权限传递:角色管理:数据导出:对于远程数据库查看表空间查看表空间路径查看被锁的对象基本操作 connect sys/zxm as sysdba-- 用 sys用户登录 create user jsdx identified by jsdx 创建用户 jsdx 密…...
hive只复制表结构不复制表数据
目录 一、背景 二、准备测试数据 1.建表 2.造测试数据 三、操作 1.CTAS (1).无分区表测试 (2).分区表测试 2.LIKE (1).无分区表测试 (2).分区表测试 一、背景 有一张ori_…...
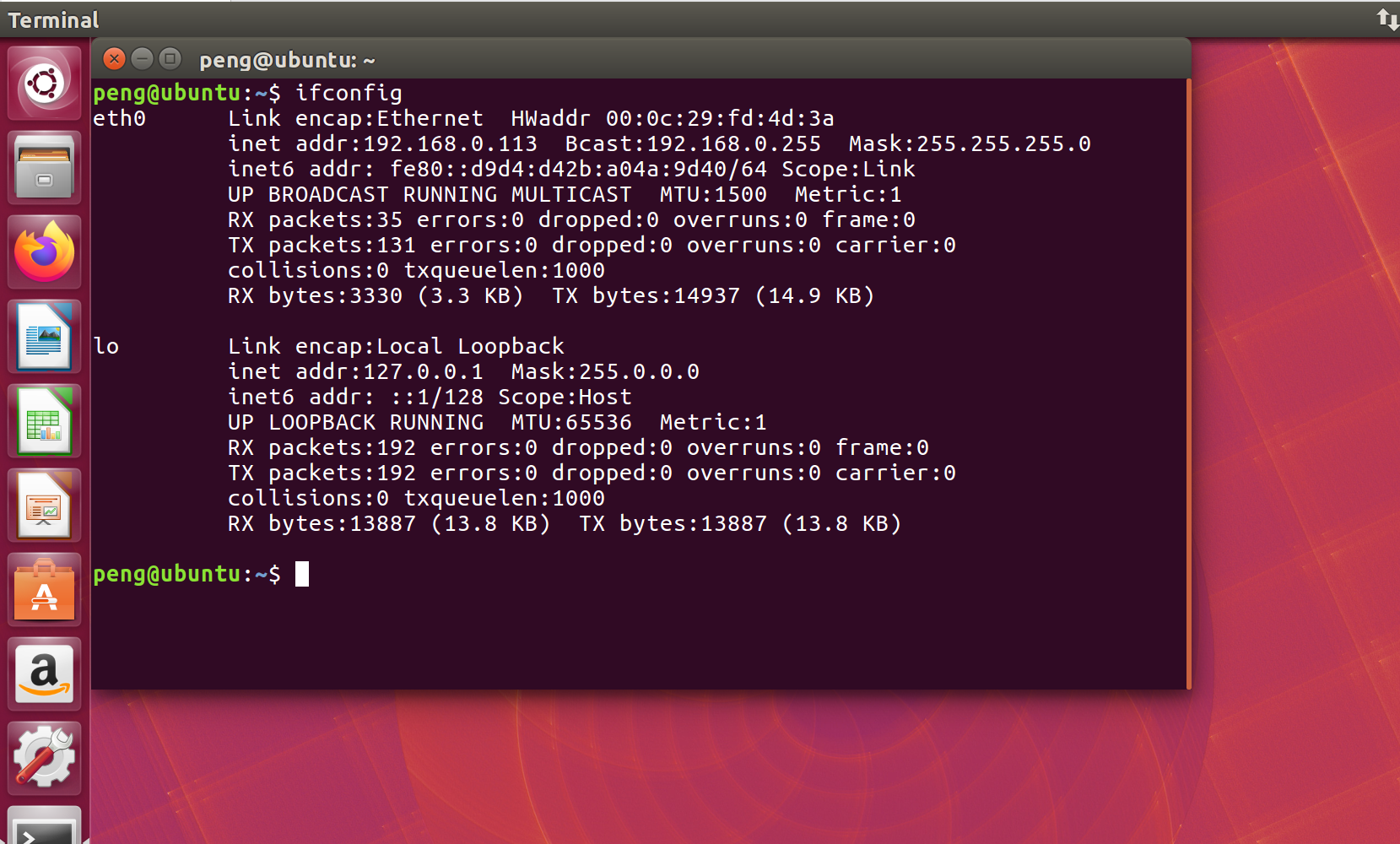
如何将Linux的NIC 名称更改为 eth0 而不是 enps33 或 enp0s25,只要几秒钟
概述 我们使用Linux系统,网卡名称通常都是eth0,但是有一些新的linux发行版,网卡名字 enps33 或 enp0s25。 pengubuntu:~$ ifconfig ens33 Link encap:Ethernet HWaddr 00:0c:29:fd:4d:3a inet addr:192.168.0.113 Bcast:192.168.0.…...

位运算笔记
1. 为什么要学位运算 因为这是计算机内部运算的语言,所以会非常快。 本人是因为学习算法经常遇见一些求二进制中的0和1的各种操作,好多都不知道所以特此整理一下,如有不对,烦请指正。 2. 什么是位运算 程序中的所有数在计算机内存…...

2023全国首个区块链平台发布,区块链绿色消费积分系统玩法悄然上市
全国首个区块链平台发布,区块链绿色消费积分系统玩法悄然上市 2023-02-23 16:15梦龙 大家好,我是你们熟悉而又陌生的好朋友梦龙,一个创业期的年轻人 2月22日,首届中国数字产权创新大会在成都举办。在本次大会上,全国…...

【异常】因为忘加了租户查询条件,导致重复ID导入失败Duplicate entry ‘XXX‘ for key ‘PRIMARY‘
一、异常说明 Error updating database. Cause: java.sql.SQLIntegrityConstraintViolationException: Duplicate entry 670 for key PRIMARYThe error may exist in /mall/admin/mapper/GoodsCategoryMapper.java (best guess)The error may involve .admin.mapper.GoodsCate…...

证明CPU指令是乱序执行的
承接上文CPU缓存一致性原理双击QQ.exe从磁盘加载到内存里面,内存里面就会有了一个进程,进程产生的时候会产生一个主线程,就是main方法所在的线程,cpu会找到main开始的地方,把它的指令读取过来放到程序计数器࿰…...

css 属性和属性值的定义
文章目录css文本属性作业列表属性背景属性作业css文本属性 序号属性描述说明1font-size字体大小浏览器默认16px;2font-family字体当字体是中文字体,英文字体,中间有空格时候,要加双引号,多字体之间用逗号隔开 默认微软…...

Python获取中国大学MOOC某课程评论及其参与人数
文章目录前言一、需求二、分析三、运行结果前言 本系列文章来源于真实的需求本系列文章你来提我来做本系列文章仅供学习参考 一、需求 1、课程参加人数 2、课程学员名称及其评论 二、分析 首先查看网页源代码是否有需要的数据 课程参加人数 课程学员名称及其评论 F12 打开浏…...

【C++】类和对象(完结篇)
文章目录1. 再谈构造函数1.1 初始化列表1.2 explicit关键字2. static 成员2.1 静态成员变量2.1 静态成员函数2.3 练习2.4 总结3. 匿名对象4. 友元4.1 友元函数4.2 友元类5. 内部类6. 拷贝对象时编译器的一些优化7. 再次理解类和对象这篇文章呢,我们来再来对类和对象…...

低代码开发可以解决哪些问题?
低代码开发可以解决哪些问题?如果用4句话去归纳,低代码开发可以解决以下问题—— 为企业提供更高的灵活性,用户可以突破代码的限制自主开发业务应用;通过减少对专业软件开发人员的依赖,公司可以快速响应市场上的新业务…...

Linux 中使用 docker-compose 部署 MongoDB 6 以上版本副本集及配置 SSL / TLS 协议
一、准备环境 MongoDB 副本集部署至少 3 个节点(奇数节点),为了保障数据安全性,可考虑将 MongoDB 节点分布在不同的主机上,本示例使用一台主机部署 3 个 MongoDB示例。 1、创建 MongoDB 集群数据相关目录 # 创建 Mo…...

JavaWeb--Mybatis练习
Mybatis练习Mybatis练习1 配置文件实现CRUD1.1 环境准备1.2 查询所有数据1.2.1 编写接口方法1.2.2 编写SQL语句1.2.3 编写测试方法1.2.4 起别名解决上述问题1.2.5 使用resultMap解决上述问题1.2.6 小结1.3 查询详情1.3.1 编写接口方法1.3.2 编写SQL语句1.3.3 编写测试方法1.3.4…...

XXPermissions:Android权限管理框架的架构设计与最佳实践
XXPermissions:Android权限管理框架的架构设计与最佳实践 【免费下载链接】XXPermissions Android Permissions Framework, Adapt to Android 16 项目地址: https://gitcode.com/GitHub_Trending/xx/XXPermissions 在Android应用开发中,权限管理一…...

基于EMA与轻量级机器学习的Wi-Fi链路质量预测实战
1. 项目概述与核心价值在工业自动化、仓储物流和智能制造等场景里,无线网络的稳定性正变得前所未有的重要。想象一下,一个自动导引运输车(AGV)正在执行物料搬运任务,或者一个机械臂正在与中央控制系统进行实时数据同步…...

Python Android打包终极指南:5个实战技巧解决移动开发痛点
Python Android打包终极指南:5个实战技巧解决移动开发痛点 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android Python-for-Android(简称p4…...

ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现
ROS机器人仿真架构解析:基于wpr_simulation的移动操作机器人技术实现 【免费下载链接】wpr_simulation 项目地址: https://gitcode.com/gh_mirrors/wp/wpr_simulation 在机器人操作系统(ROS)开发领域,硬件依赖和测试成本一直是制约算法迭代效率的…...

8大网盘文件直链一键获取:LinkSwift让你的下载速度突破限速瓶颈
8大网盘文件直链一键获取:LinkSwift让你的下载速度突破限速瓶颈 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云…...

量子计算中的随机基准测试与Grover算法实现
1. 量子计算中的随机基准测试原理与应用随机基准测试(Randomized Benchmarking, RB)是量子计算领域评估量子门操作保真度的黄金标准方法。与传统直接测量单个量子门误差不同,RB通过随机量子门序列的统计特性来提取平均门保真度,这种方法对状态制备和测量…...

小学阶段物理学习书籍推荐
结合小学阶段认知特点,推荐以下几本兼具趣味性和实用性的物理启蒙书籍,适配不同年级孩子的学习需求: 一、低龄(1-2年级/6-8岁):趣味感知,激发好奇 1、漫画物理全套6册 用孩子最喜欢的漫画形式拆…...

Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南
Hotkey Detective:3步快速定位Windows快捷键冲突的终极指南 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是…...

Wireshark与Fiddler联手解密HTTPS流量实战指南
1. 为什么单靠Wireshark看不了真正的HTTPS请求内容?你有没有试过在Wireshark里抓到一堆TLSv1.3的Encrypted Handshake Message,点开Application Data全是乱码,连自己发的登录请求里用户名填的是“admin”还是“test123”都看不到?…...

德国、奥地利和瑞士 SaaS 市场销售策略大揭秘:风险优先,节奏放慢!
1. 嵌入工作流介绍嵌入工作流有其官网主页,具备多种功能,如 ChatGPT 集成、专家支持、无需编码、白标、集成等;还有多种解决方案,包括代理商、CRM、iPaaS 替代方案、物业管理、房地产、初创企业、WordPress 插件、增加收入等&…...