【生物信息学】使用谱聚类(Spectral Clustering)算法进行聚类分析
目录
一、实验介绍
二、实验环境
1. 配置虚拟环境
2. 库版本介绍
3. IDE
三、实验内容
0. 导入必要的工具
1. 生成测试数据
2. 绘制初始数据分布图
3. 循环尝试不同的参数组合并计算聚类效果
4. 输出最佳参数组合
5. 绘制最佳聚类结果图
6. 代码整合
一、实验介绍
本实验实现了使用谱聚类(Spectral Clustering)算法进行聚类分析
二、实验环境
本系列实验使用了PyTorch深度学习框架,相关操作如下(基于深度学习系列文章的环境):
1. 配置虚拟环境
深度学习系列文章的环境
conda create -n DL python=3.7 conda activate DLpip install torch==1.8.1+cu102 torchvision==0.9.1+cu102 torchaudio==0.8.1 -f https://download.pytorch.org/whl/torch_stable.html
conda install matplotlibconda install scikit-learn新增加
conda install pandasconda install seabornconda install networkxconda install statsmodelspip install pyHSICLasso注:本人的实验环境按照上述顺序安装各种库,若想尝试一起安装(天知道会不会出问题)
2. 库版本介绍
| 软件包 | 本实验版本 | 目前最新版 |
| matplotlib | 3.5.3 | 3.8.0 |
| numpy | 1.21.6 | 1.26.0 |
| python | 3.7.16 | |
| scikit-learn | 0.22.1 | 1.3.0 |
| torch | 1.8.1+cu102 | 2.0.1 |
| torchaudio | 0.8.1 | 2.0.2 |
| torchvision | 0.9.1+cu102 | 0.15.2 |
新增
| networkx | 2.6.3 | 3.1 |
| pandas | 1.2.3 | 2.1.1 |
| pyHSICLasso | 1.4.2 | 1.4.2 |
| seaborn | 0.12.2 | 0.13.0 |
| statsmodels | 0.13.5 | 0.14.0 |
3. IDE
建议使用Pycharm(其中,pyHSICLasso库在VScode出错,尚未找到解决办法……)
win11 安装 Anaconda(2022.10)+pycharm(2022.3/2023.1.4)+配置虚拟环境_QomolangmaH的博客-CSDN博客https://blog.csdn.net/m0_63834988/article/details/128693741https://blog.csdn.net/m0_63834988/article/details/128693741
三、实验内容
0. 导入必要的工具
import numpy as np
from sklearn.cluster import SpectralClustering
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from numpy import random
from sklearn import metrics1. 生成测试数据
random.seed(1)
x, y = make_blobs(n_samples=400, centers=4, cluster_std=1.5) 使用make_blobs方法生成了一个包含400个样本的数据集,共有4个聚类中心,每个聚类中心的标准偏差为1.5。
2. 绘制初始数据分布图
plt.scatter(x[:, 0], x[:, 1], c=y, label=len(np.unique(y)))
plt.title("Initial Data Distribution")
plt.show()将生成的数据集绘制成散点图,不同聚类的样本使用不同的颜色进行标记。

3. 循环尝试不同的参数组合并计算聚类效果
gamma_best = 0
k_cluster_best = 0
CH = 0
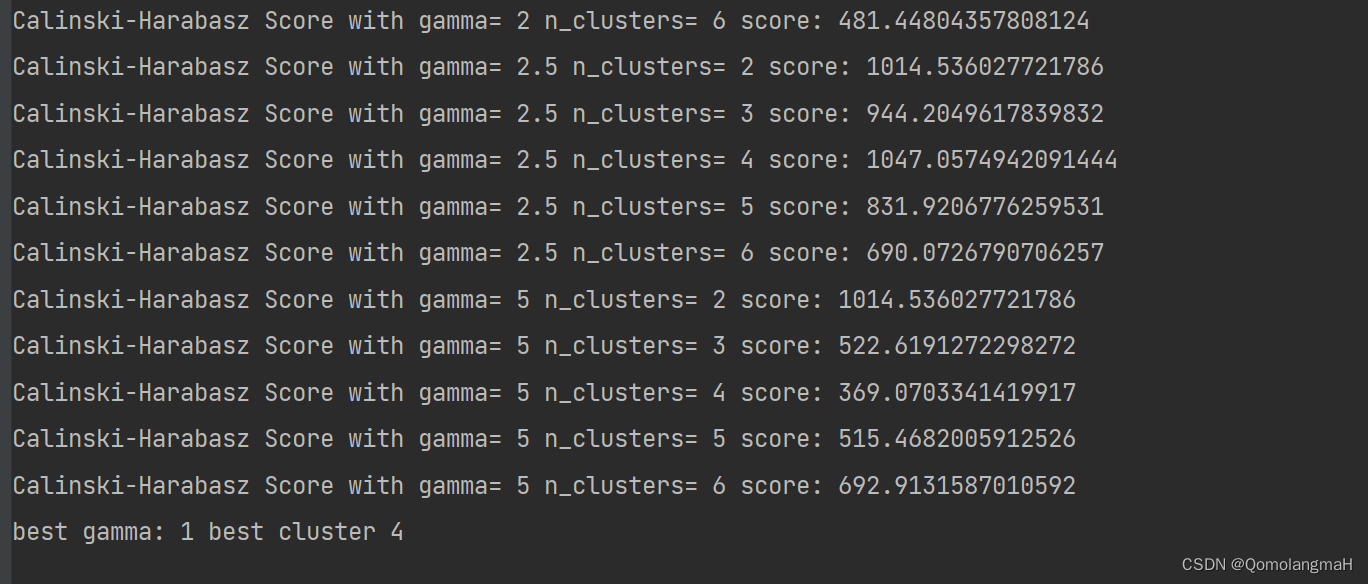
for index, gamma in enumerate((1, 1.5, 2, 2.5, 5)):for index, k in enumerate((2, 3, 4, 5, 6)):y_pred = SpectralClustering(n_clusters=k, gamma=gamma).fit_predict(x)print("Calinski-Harabasz Score with gamma=", gamma, "n_clusters=", k, "score:",metrics.calinski_harabasz_score(x, y_pred))curr_CH = metrics.calinski_harabasz_score(x, y_pred)if (curr_CH > CH):gamma_best = gammak_cluster_best = kCH = curr_CH- 使用嵌套的循环尝试不同的参数组合
- 其中
gamma代表谱聚类中的高斯核参数 k代表聚类的簇数。
- 其中
- 对于每一组参数,使用
SpectralClustering进行聚类,并计算聚类结果的 Calinski-Harabasz 得分(metrics.calinski_harabasz_score)。得分越高表示聚类效果越好。代码会记录得分最高的参数组合。
4. 输出最佳参数组合
print("best gamma:", gamma_best, "best cluster", k_cluster_best) 输出得分最高的参数组合(即最佳的 gamma 和 k)。
5. 绘制最佳聚类结 果图
f = plt.figure()
sc = SpectralClustering(n_clusters=k_cluster_best, gamma=gamma_best).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=sc)
plt.title("n_clusters: " + str(k_cluster_best))
plt.show() 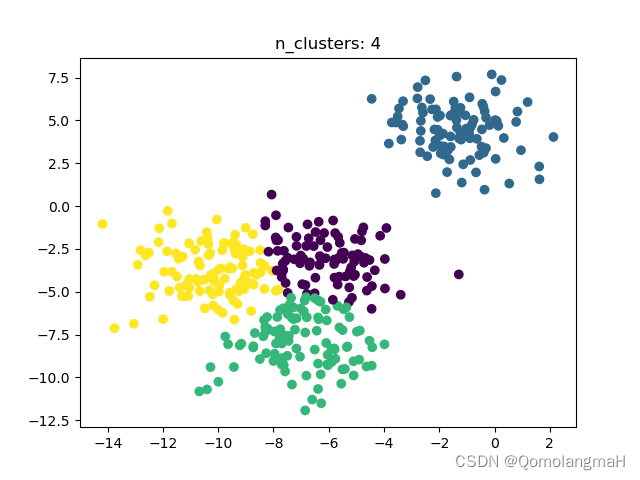
6. 代码整合
import numpy as np
from sklearn.cluster import SpectralClustering
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from numpy import random
from sklearn import metricsSpectralClustering(affinity='rbf', coef0=1, degree=3, gamma=1.0,kernel_params=None, n_clusters=4, n_init=10,n_neighbors=10)# scikit中的make_blobs方法常被用来生成聚类算法的测试数据,make_blobs会根据用户指定的特征数量、中心点数量、范围等来生成几类数据,这些数据可用于测试聚类算法的效果
random.seed(1)
# n_samples:样本数 n_features:int,可选(默认值= 2)centers:要生成的中心数或固定的中心位置 cluster_std: 聚类的标准偏差
x, y = make_blobs(n_samples=400, centers=4, cluster_std=1.5)
plt.scatter(x[:, 0], x[:, 1], c=y, label=len(np.unique(y)))
plt.title("Initial Data Distribution")
plt.show()gamma_best = 0
k_cluster_best = 0
CH = 0
for index, gamma in enumerate((1, 1.5, 2, 2.5, 5)):for index, k in enumerate((2, 3, 4, 5, 6)):y_pred = SpectralClustering(n_clusters=k, gamma=gamma).fit_predict(x)# 卡林斯基哈拉巴斯得分(Calinski Harabasz score),本质是簇间距离与簇内距离的比值,整体计算过程与方差计算方式类似,也称为方差比标准,# 通过计算类内各点与类中心的距离平方和来度量类内的紧密度(类内距离),各个类中心点与数据集中心点距离平方和来度量数据集的分离度(类间距离),# 较高的 Calinski Harabasz 分数意味着更好的聚类print("Calinski-Harabasz Score with gamma=", gamma, "n_clusters=", k, "score:",metrics.calinski_harabasz_score(x, y_pred))curr_CH = metrics.calinski_harabasz_score(x, y_pred)if (curr_CH > CH):gamma_best = gammak_cluster_best = kCH = curr_CHprint("best gamma:", gamma_best, "best cluster", k_cluster_best)f = plt.figure()
sc = SpectralClustering(n_clusters=k_cluster_best, gamma=gamma_best).fit_predict(x)
plt.scatter(x[:, 0], x[:, 1], c=sc)
plt.title("n_clusters: " + str(k_cluster_best))
plt.show()
请详细介绍上述代码相关文章:
【生物信息学】使用谱聚类(Spectral Clustering)算法进行聚类分析
目录 一、实验介绍 二、实验环境 1. 配置虚拟环境 2. 库版本介绍 3. IDE 三、实验内容 0. 导入必要的工具 1. 生成测试数据 2. 绘制初始数据分布图 3. 循环尝试不同的参数组合并计算聚类效果 4. 输出最佳参数组合 5. 绘制最佳聚类结果图 6. 代码整合 一、实验介绍…...

CSS基础语法第二天
目录 一、复合选择器 1.1 后代选择器 1.2 子代选择器 1.3 并集选择器 1.4 交集选择器 1.4.1超链接伪类 二、CSS特性 2.1 继承性 2.2 层叠性 2.3 优先级 基础选择器 复合选择器-叠加 三、Emmet 写法 3.1HTML标签 3.2CSS 四、背景属性 4.1 背景图 4.2 平铺方式 …...
ThreeJS - 封装一个GLB模型展示组件(TypeScript)
一、引言 最近基于Three.JS,使用class封装了一个GLB模型展示,支持TypeScript、支持不同框架使用,具有多种功能。 (下图展示一些基础的功能,可以自行扩展,比如光源等) 二、主要代码 本模块依赖…...

HashMap面试题
1.hashMap底层实现 hashMap的实现我们是要分jdk 1.7及以下版本,jdk1.8及以上版本 jdk 1.7 实现是用数组链表 jdk1.8 实现是用数组链表红黑树, 链表长度大于8(TREEIFY_THRESHOLD)时,会把链表转换为红黑树,…...

Java编程技巧:swagger2、knif4j集成SpringBoot或者SpringCloud项目
目录 1、springbootswagger2knif4j2、springbootswagger3knif4j3、springcloudswagger2knif4j 1、springbootswagger2knif4j 2、springbootswagger3knif4j 3、springcloudswagger2knif4j 注意点: Api注解:Controller类上的Api注解需要添加tags属性&a…...
)
第三章:最新版零基础学习 PYTHON 教程(第九节 - Python 运算符—Python 中的除法运算符)
除法运算符允许您将两个数字相除并返回商,即,第一个数字或左侧的数字除以第二个数字或右侧的数字并返回商。 Python 中的除法运算符 除法运算符有两种类型: 浮点数除法整数除法(向下取整除法)整数相除时,结果四舍五入为最接近的整数,并用符号“//”表示。浮点数“/”…...

【python】导出mysql数据,输出excel!
参考https://blog.csdn.net/pengneng123/article/details/131111713 import pymysql import pandas as pd #import openpyxl import xlsxwriterdb pymysql.connect(host"10.41.241.114", port***,user***,password***,charsetutf8mb4 )cursor db.cursor() #创建游…...

【Java 进阶篇】JDBC ResultSet 遍历结果集详解
在Java数据库编程中,经常需要执行SQL查询并处理查询结果。ResultSet(结果集)是Java JDBC中用于表示查询结果的关键类之一。通过遍历ResultSet,我们可以访问和操作从数据库中检索的数据。本文将详细介绍如何使用JDBC来遍历ResultSe…...
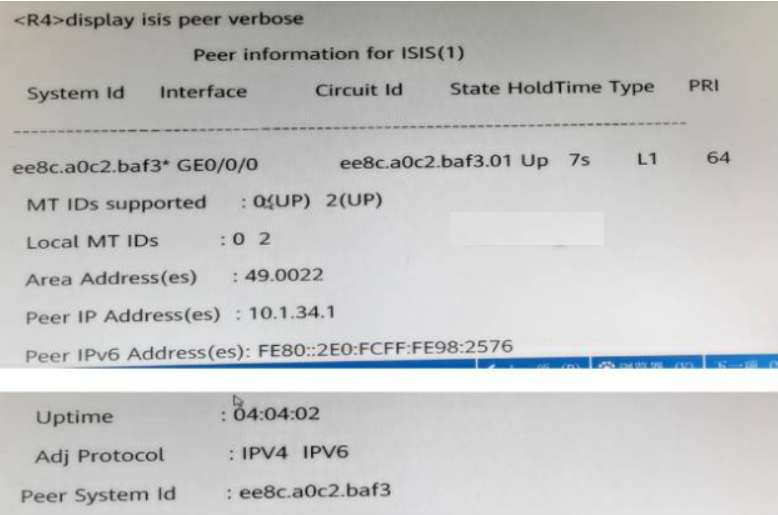
华为数通方向HCIP-DataCom H12-831题库(单选题:161-180)
第161题 某台路由器Router LSA如图所示,下列说法中错误的是? A、本路由器已建立邻接关系 B、本路由器为DR C、本路由支持外部路由引入 D、本路由器的Router ID为10.0.12.1 答案: B 解析: 一类LSA的在transnet网络中link id值为DR的route id ,但Link id的地址不是10.0.12.…...

【VsCode】SSH远程连接Linux服务器开发,搭配cpolar内网穿透实现公网访问
文章目录 前言1、安装OpenSSH2、vscode配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 前言 远程…...

java并发编程 守护线程 用户线程 main
经常使用线程,没有对守护线程和用户线程的区别做彻底了解 下面写4个例子来验证一下 源码如下 /* Whether or not the thread is a daemon thread. */ private boolean daemon false;/*** Marks this thread as either a {linkplain #isDaemon daemon} thread*…...
wxWidgets(1):在Ubuntu 环境中搭建wxWidgets 库环境,安装库和CodeBlocks的IDE,可以运行demo界面了,继续学习中
1,选择使用 wxWidgets 框架 选择这个主要是因为完全的开源,不想折腾 Qt的库,而且打包的文件比较大。 网络上面有很多的对比,而且使用QT的人比较多。 但是我觉得wxwidgets 更加偏向 c 语法本身,也有助学习C。 没有太多…...

[VIM]VIM初步学习-3
3-1 编写 vim 配置,我的 vim 我做主_哔哩哔哩_bilibili...
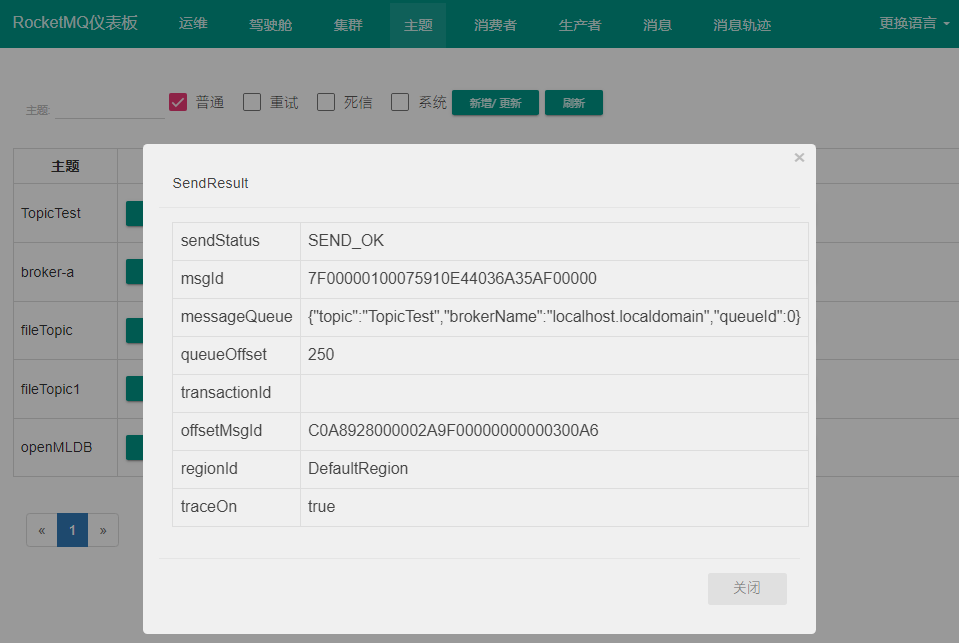
RocketMQ Dashboard说解
RocketMQ Dashboard 是 RocketMQ 的管控利器,为用户提供客户端和应用程序的各种事件、性能的统计信息,支持以可视化工具代替 Topic 配置、Broker 管理等命令行操作。 介绍 功能概览 面板功能运维修改nameserver 地址; 选用 VIPChannel驾驶舱查看 …...
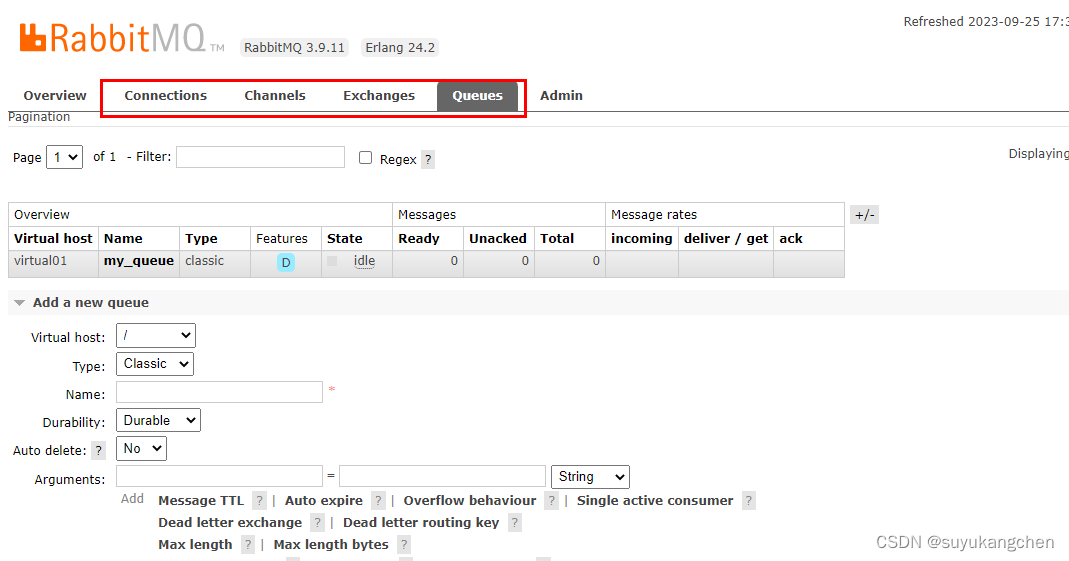
【RabbitMQ实战】05 RabbitMQ后台管理
一、多租户与权限 1.1 vhost的概念 每一个 RabbitMQ服务器都能创建虚拟的消息服务器,我们称之为虚拟主机(virtual host),简称为 vhost。每一个 vhost本质上是一个独立的小型RabbitMQ服务器,拥有自己独立的队列、交换器及绑定关系等,并且它拥…...

PHP8中final关键字的应用-PHP8知识详解
在PHP8中,final的中文含义是最终的、最后的意思。被final修饰过的类和方法就是“最终的版本”。 如果关键字final放在类的前面,则表示该类不能被继承。 如果关键字final放在方法的前面,则表示该 方法不能被重新定义。 如果有一个类的格式为…...

基于Java的校园失物招领平台设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

〔024〕Stable Diffusion 之 模型训练 篇
✨ 目录 🎈 训练集准备🎈 训练集预处理🎈 数据清洗🎈 下载训练源码🎈 训练文件配置🎈 脚本运行🎈 实战测试🎈 训练集准备 声明: 该文中所涉及到的女神图片均来自于网络,仅用作技术教程演示,图片已码一般同一个训练集需要准备 20~40 张不同角度的照片,当然可…...

【MySQL入门到精通-黑马程序员】MySQL基础篇-DML
文章目录 前言一、DML-介绍二、DML-添加数据三、DML-修改数据四、DML-删除数据总结 前言 本专栏文章为观看黑马程序员《MySQL入门到精通》所做笔记,课程地址在这。如有侵权,立即删除。 一、DML-介绍 DML(Data Manipulation Language…...

【ARMv8 SIMD和浮点指令编程】NEON 加载指令——如何将数据从内存搬到寄存器(LDxLDxR)?
将内存中的数据搬到 NEON 寄存器,有很多指令可以完成,熟悉这些指令是必须的。 1 LD1 (multiple structures) 将多个单元素结构加载到一个,两个,三个或四个寄存器上。该指令从内存中加载多个单元结构,并将结果写入一、二、三或四个 SIMD&FP 寄存器。 无偏移 一个寄存…...

超高清电视普及困境解析:从技术参数到生态系统的完整思考
1. 超高清电视的“非主流”开局:一场始于2013年的行业迷思 如果你在2013年初的拉斯维加斯CES展上,听到关于“Ultra HDTV”(超高清电视,后文简称UHDTV)的喧嚣,感觉就像身处一场盛大的交响乐彩排现场——乐手…...

基于SpringBoot+Vue的网上商城系统管理系统设计与实现【Java+MySQL+MyBatis完整源码】
💡实话实说:有自己的项目库存,不需要找别人拿货再加价,所以能给到超低价格。摘要 随着互联网技术的快速发展,电子商务已成为现代商业活动的重要组成部分。网上商城系统作为电子商务的核心载体,为用户提供了…...

AI编码助手技能开发:基于Agent Skills打造智能命令行速查工具
1. 项目概述:一个能“听懂人话”的开发者命令行技能如果你和我一样,每天在终端和代码编辑器里花费大量时间,那你肯定对“命令遗忘症”深有体会。明明上周才用过git worktree来并行处理两个功能分支,今天突然想不起来具体的参数顺序…...

MTKClient终极指南:免费解锁联发科设备的完整刷机解决方案
MTKClient终极指南:免费解锁联发科设备的完整刷机解决方案 【免费下载链接】mtkclient MTK reverse engineering and flash tool 项目地址: https://gitcode.com/gh_mirrors/mt/mtkclient MTKClient是一款专为联发科(MediaTek)芯片设备…...

WarcraftHelper:魔兽争霸3终极增强插件完全指南
WarcraftHelper:魔兽争霸3终极增强插件完全指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专为魔兽争霸3设计的…...


AI自主报告正常胸片:技术原理、临床价值与英国NHS实践挑战
1. 项目概述:当AI开始“读”胸片作为一名在医学影像和人工智能交叉领域摸爬滚打了十多年的从业者,我亲眼见证了AI从实验室里的新奇玩具,逐渐成长为临床医生案头一个值得信赖的“第二双眼睛”。最近,一个特别的应用场景正在全球范围…...

探索One-Language/One:统一编程范式如何重塑全栈开发体验
1. 项目概述:从“One”到“One-Language/One”的深度解构最近在GitHub上看到一个挺有意思的项目,叫“One-Language/One”。光看这个名字,可能很多人会有点懵,这到底是个啥?是又一个编程语言?还是一个框架&a…...

为什么你的Gemini写作总像“AI腔”?资深技术文档架构师揭秘3层语义校准法
更多请点击: https://intelliparadigm.com 第一章:为什么你的Gemini写作总像“AI腔”?资深技术文档架构师揭秘3层语义校准法 Gemini 生成的技术文档常被诟病为“语法正确但语义失焦”——术语堆砌、逻辑断层、人机语感割裂。根本原因在于模…...

GPU需求曲线重塑:从季节性疲软到持续高烧的产业变革
1. 从“季节性疲软”到“持续高烧”:GPU需求曲线的范式转移如果你在2020年之前关注过半导体行业,尤其是PC和图形处理器市场,你会熟悉一个词:“季节性”。通常,第二季度是传统的淡季,消费者在经历了第一季度…...