Python与Scrapy:构建强大的网络爬虫
网络爬虫是一种用于自动化获取互联网信息的工具,在数据采集和处理方面具有重要的作用。Python语言和Scrapy框架是构建强大网络爬虫的理想选择。本文将分享使用Python和Scrapy构建强大的网络爬虫的方法和技巧,帮助您快速入门并实现实际操作价值。

一、Python语言与Scrapy框架简介
1、Python语言:Python是一种简洁而高效的编程语言,具有丰富的第三方库和强大的数据处理能力,适合用于网络爬虫的开发。
2、Scrapy框架:Scrapy是一个开源的Python框架,专门设计用于构建和运行网络爬虫。它提供了许多强大的功能,如异步IO、自动化请求管理和数据处理。
二、构建强大网络爬虫的步骤及技巧
1、安装和配置Python与Scrapy:
-
安装Python:从Python官网下载并安装最新版本的Python解释器。
-
安装Scrapy:使用包管理工具pip,在命令行中运行"pip install scrapy"即可安装Scrapy。
-
配置Scrapy:根据需求进行Scrapy的配置,如设置下载延迟、并发数和User-Agent等。
以下是一则代码示例:
# 使用 pip 安装Scrapy
pip install scrapy
# 创建一个新的Scrapy项目
scrapy startproject myproject
# 在settings.py文件中进行配置,例如设置下载延迟
DOWNLOAD_DELAY = 2
2、创建Scrapy项目和爬虫:
-
创建Scrapy项目:在命令行中运行"scrapy startproject project_name"命令即可创建一个Scrapy项目。
-
创建爬虫:通过运行"scrapy genspider spider_name domain"命令,可以在项目中创建一个新的爬虫。
以下是一则代码示例:
import scrapy
class MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com']def parse(self, response):# 提取页面的内容title = response.css('h1::text').get()yield {'title': title}
3、编写爬虫逻辑和数据处理:
-
爬虫逻辑:在爬虫文件中,使用Scrapy提供的选择器和请求方法来定义爬取页面的逻辑。
-
数据处理:通过使用Scrapy提供的Item和Pipeline,可以对爬取到的数据进行处理、清洗和持久化。
以下是一则代码示例:
import scrapy
from scrapy.item import Item, Field
class MyItem(Item):title = Field()content = Field()
class MySpider(scrapy.Spider):name = 'myspider'start_urls = ['http://www.example.com']def parse(self, response):item = MyItem()item['title'] = response.css('h1::text').get()item['content'] = response.css('p::text').getall()yield item
# 在配置文件settings.py中启用Pipeline
ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300,
}
4、调试和测试:
-
调试:使用Scrapy提供的调试工具,如登录中间件和Shell命令行,来辅助调试和测试爬虫。
-
测试:编写单元测试和集成测试,验证爬虫的正确性和稳定性。
以下是一则代码示例:
# 在命令行中运行
scrapy shell 'http://www.example.com'
这将打开Scrapy的Shell,您可以在其中执行和调试Scrapy的相关命令和代码。
5、反爬策略和扩展:
-
反爬策略:了解和应对常见的反爬机制,如IP封禁和验证码识别,并通过合理的爬取策略来规避反爬限制。
-
扩展功能:Scrapy提供了丰富的扩展机制,如中间件和信号,可以根据需求自定义功能并拓展爬虫的能力。
三、实际操作价值
1、使用Python与Scrapy构建强大的网络爬虫可以快速获取大量的有价值数据,满足数据采集和分析的需求。
2、Python语言和Scrapy框架在爬虫开发上具有丰富的工具和库,能够提高开发效率和代码质量。
3、掌握网络爬虫的基本原理和技巧,能够更好地理解和分析互联网上的数据,并应对各种复杂的爬取场景。
4、了解反爬策略和扩展功能能够提高爬虫的稳定性和可靠性,降低被目标网站检测和封禁的风险。
Python语言与Scrapy框架提供了强大的工具和库,帮助您构建强大、高效的网络爬虫。通过掌握构建步骤和技巧,您将能够快速入门并实现实际操作价值。希望本文对您在使用Python和Scrapy构建网络爬虫的过程中提供了启发和帮助。
相关文章:
Python与Scrapy:构建强大的网络爬虫
网络爬虫是一种用于自动化获取互联网信息的工具,在数据采集和处理方面具有重要的作用。Python语言和Scrapy框架是构建强大网络爬虫的理想选择。本文将分享使用Python和Scrapy构建强大的网络爬虫的方法和技巧,帮助您快速入门并实现实际操作价值。 一、Pyt…...

kind 安装 k8s 集群
在某些时候可能需要快速的部署一个k8s集群用于测试,不想部署复杂的k8s集群环境,这个时候我们就可以使用kind来部署一个k8s集群了,下面是使用kind部署的过程 一、安装单节点集群 1、下载kind二进制文件 [rootlocalhost knid]# curl -Lo ./kin…...

Leetcode 2871. Split Array Into Maximum Number of Subarrays
Leetcode 2871. Split Array Into Maximum Number of Subarrays 1. 解题思路2. 代码实现 题目链接:2871. Split Array Into Maximum Number of Subarrays 1. 解题思路 这一题实现上其实还是比较简单的,就是一个贪婪算法,主要就是思路上需要…...

Java基础---第十三篇
系列文章目录 文章目录 系列文章目录一、有数组了为什么还要搞个 ArrayList 呢?二、说说什么是 fail-fast?三、说说Hashtable 与 HashMap 的区别一、有数组了为什么还要搞个 ArrayList 呢? 通常我们在使用的时候,如果在不明确要插入多少数据的情况下,普通数组就很尴尬了,…...

Java 文档注释
Java 文档注释 目录 Java 文档注释 javadoc 标签 文档注释 javadoc输出什么 实例 Java只是三种注释方式。前两种分别是// 和/* */,第三种被称作说明注释,它以/** 开始,以 */结束。 说明注释允许你在程序中嵌入关于程序的信息。你可以使…...

【多媒体技术与实践】多媒体计算机系统概述
数码相机是利用___感受光信号, 使转换为电信号,再经模/数转换变成数字信号,存储在相机内部的存储器中。 选择一项: a. RGB b. OCR c. CCD d. MPEG 正确答案是:CCD 最基本的多媒体计算机是指安装了_部件的计算机。…...
)
DirectX 3D C++ 圆柱体的渲染(源代码)
作业内容 请勿抄袭 代码功能:渲染一个绕中心轴自转的圆柱体。要求该圆柱体高度为3.0,半径为0.5。 #include <windows.h> #include <d3d11.h> #include <d3dx11.h> #include <d3dcompiler.h> #include <xnamath.h> #incl…...

搭建前端框架
在终端进入web目录,然后创建vuecrud工程 创建工程并引入ElementUI和axios手把手教学>传送门:VueCLI脚手架搭建...

2310C++构造对象
原文 本文展示一个构造对象方式,用户无需显式调用构造器.对有参构造器类,该实现在构造改对象时传递默认值来构造. 当然用户也可指定(绑定)某个参数的值.实现思路参考boost-ext/di的实现.看下示例: 构 成员{整 x10; }; 构 成员1{整 x11; }; 类 例子1{ 公:例子1(成员 x,成员1 x…...
nginx多文件组织
背景: nginx的话,有时候,想部署多个配置,比如:使用不同的端口配置不同的web工程。 比如:8081部署:项目1的web页面。 8082部署:项目2的web页面。 1)nginx.conf worker_processes…...

扩容LVM卷导致lvm元数据丢失的恢复过程
一、问题描述 因某次MySQL binlog占用过高扩容时,是直接对云盘操作,而扩容直接操作了lvm卷而未操作云盘分区,并随后执行了扩容的partprobe,resize2fs卷等操作;最后,显示并未扩容成功,重启系统后…...

【MySQL教程】| (1-1) 2023MySQL-8.1.0 安装教程
文章目录 一、安装包下载二、安装配置1、解压安装包2、编写MySQL配置文件3、初始化MySQL数据库3、安装mysql服务并启动4、MySQL服务5、连接MySQL6、修改密码 三、配置环境变量四、防止mysql自启动拖慢开机时间 近日有粉丝问到mysql在win11的安装中遇到一些问题,应粉…...

数据大屏定时请求后端数据
需求: 因为大屏基本从上午展示到晚上,不会频繁去打开页面。 前端实现: 在Vue的created钩子函数中发送初次请求,并使用JavaScript中的setInterval函数来设置整点定时发送请求。以下是一个示例 <template><div><h1…...
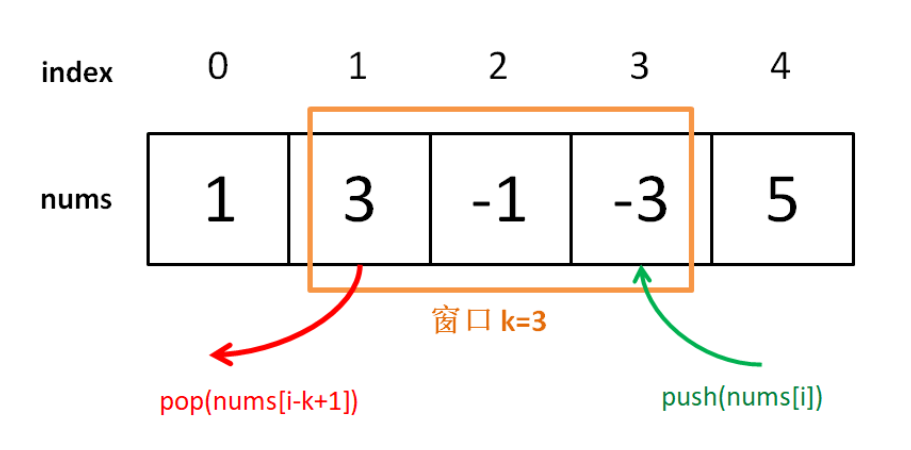
数据结构--队列
一、队列是什么 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作,而在表的后端(rear)进行插入操作,队列是一种操作受限制的线性表。进行插入操作的端称为队尾&…...
Python绘图系统25:新增8种绘图函数
文章目录 常用绘图函数单选框的更改逻辑源代码 Python绘图系统: 前置源码: Python打造动态绘图系统📈一 三维绘图系统 📈二 多图绘制系统📈三 坐 标 轴 定 制📈四 定制绘图风格 📈五 数据生成导…...

(二) gitblit用户使用教程
(一)gitblit安装教程 (二) gitblit用户使用教程 (三) gitblit管理员手册 目录 网页访问git客户端设置推送错误配置查看当前配置 日常使用仓库分组my profile修改上传代码简洁 网页访问 点击Advanced... 点击Accept the Risk and Contiue 初始用户名和密码都是admin,点击login…...
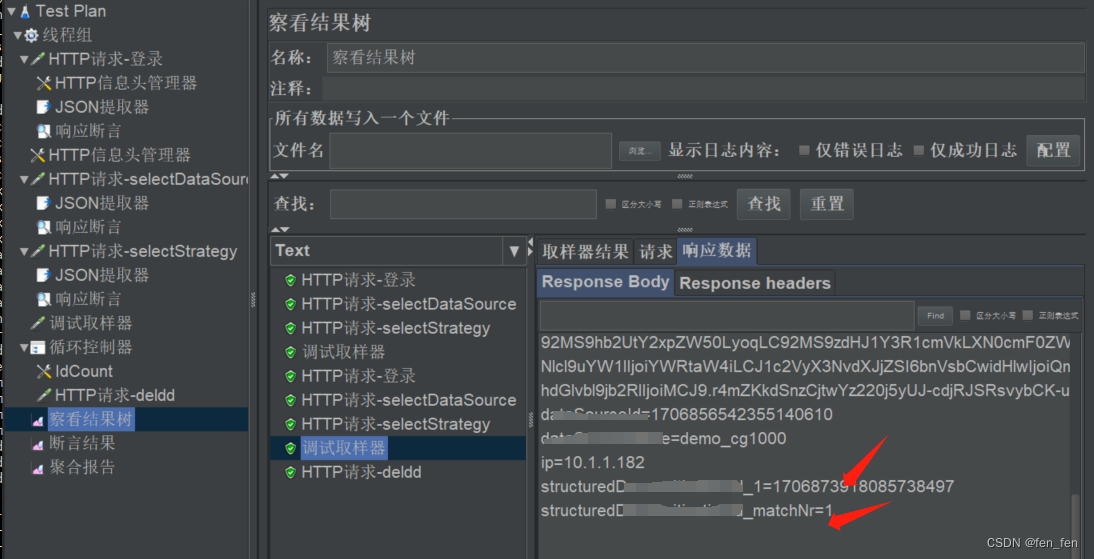
8.3Jmeter使用json提取器提取数组值并循环(循环控制器)遍历使用
Jmeter使用json提取器提取数组值并循环遍历使用 响应返回值例如: {"code":0,"data":{"totalCount":11,"pageSize":100,"totalPage":1,"currPage":1,"list":[{"structuredId":&q…...
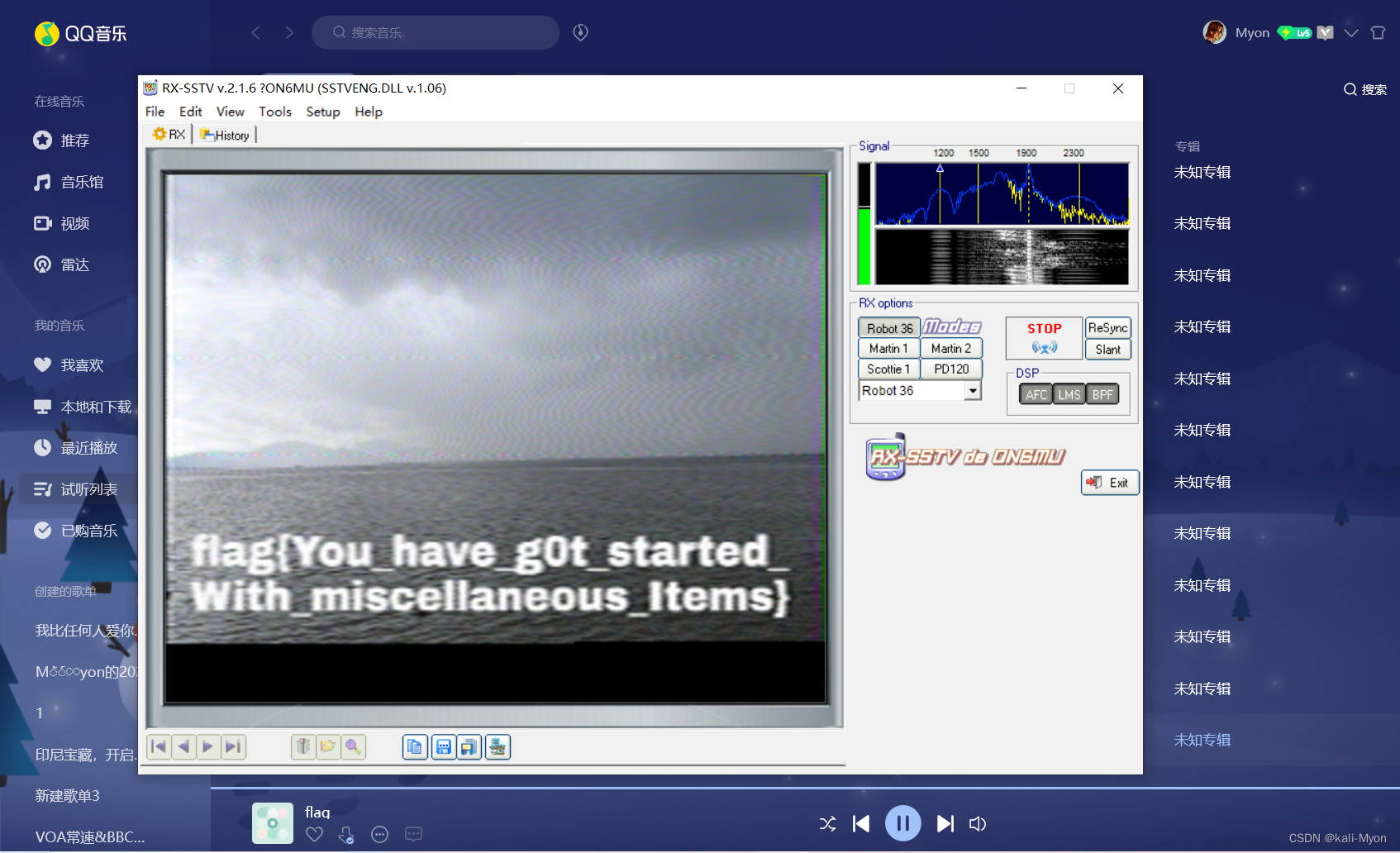
SNERT预备队招新CTF体验赛-Misc(SWCTF)
目录 1、最简单的隐写 2、旋转我 3、is_here 4、zip伪加密 5、压缩包密码爆破 6、我就藏在照片里 7、所以我放弃了bk 8、套娃 9、来自银河的信号 10、Track_Me 11、勇师傅的奇思妙想 1、最简单的隐写 下载附件后,图片格式并不支持打开 根据题目提示&…...
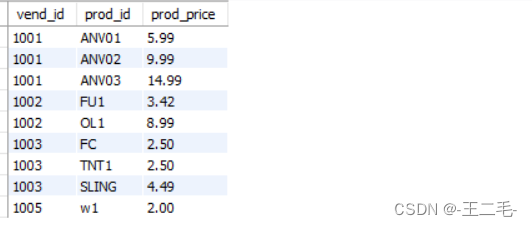
MySql017——组合查询
一、UNION作用 可用UNION操作符来组合数条SQL查询。 二、UNION 使用规则 1、UNION的使用很简单。所需做的只是给出每条SELECT语句,在各条语句之间放上关键字UNION。2、UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔ÿ…...
)
【0224】源码分析RelFileNode对smgr访问磁盘表文件的重要性(2)
1. RelFileNode的角色 RelFileNode 是一个结构体数据类型,声明于relfilenode.h(src\include\storage )头文件中,该数据类型十分重要,因为它 “提供所有我们需要知道的物理访问关系表的信息。” smgr要访问磁盘上面的数据表文件,则需要此RelFileNode提供必要信息。 可以说…...

基于Python的Discord机器人开发:从自动化管理到插件化架构实战
1. 项目概述:一个为Discord社区量身打造的智能助手 如果你在运营一个Discord服务器,无论是游戏公会、技术社区还是兴趣小组,肯定遇到过这样的场景:新成员加入后,需要手动发送欢迎消息、引导他们阅读规则;成…...
)
告别ST-LINK Utility!STM32CubeProg保姆级安装指南(含Java环境配置与常见报错解决)
从ST-LINK Utility到STM32CubeProg:嵌入式开发者的无缝迁移实战手册 当ST官方宣布STM32CubeProg将全面取代ST-LINK Utility时,许多习惯了旧工具的开发者都面临着一个现实问题:如何在不中断项目进度的情况下完成工具链的平稳过渡?作…...

5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南
5分钟掌握HunterPie:解决《怪物猎人:世界》战斗信息盲区的终极指南 【免费下载链接】HunterPie-legacy A complete, modern and clean overlay with Discord Rich Presence integration for Monster Hunter: World. 项目地址: https://gitcode.com/gh_…...

CANN/asc-devkit asc_select矢量选择函数
asc_select 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com…...

【信息科学与工程学】【数据科学】 第三篇 数学基础
数学知识体系:现代核心领域的深度架构 数学知识体系:历史脉络与逻辑结构总览表 时代/脉络 核心分支 核心概念/定理/理论 历史渊源/思想脉络 与其他领域的连接 数学哲学/元视角 1. 古典起源与奠基 (公元前 ~ 16世纪) 算术 自然数、素数、整除、欧几里…...

算法21,搜索插入位置
一道经典的二分查找应用题,通常被称为“搜索插入位置”。笔记中的思路非常清晰,下面为你整理这道题的具体解法、代码实现以及需要注意的细节。1. 题目理解题目描述:给定一个排序数组和一个目标值,在数组中找到目标值,并…...

深度解析 TailGrids 3.0:现代化 React UI 库的重构之道
一、引言在前端技术高速迭代的今天,UI 组件库作为开发效率的核心支撑,正朝着 “工程化、标准化、智能化” 的方向演进。TailGrids 3.0 作为一次从内核到生态的全面重构,并非简单的功能迭代,而是深度融合 React、Tailwind CSS 与 F…...

Python3.8环境下的OpenOPC实战:从模拟服务器搭建到KEPServerEX数据读写一条龙
Python3.8环境下的OpenOPC实战:从模拟服务器搭建到KEPServerEX数据读写全流程指南 工业自动化领域的数据采集一直是开发者需要掌握的核心技能之一。对于没有硬件设备或OPC服务器许可的学习者来说,如何在本地搭建完整的测试环境成为入门的第一道门槛。本文…...

避开这些坑!用Vivado FIFO IP核做跨时钟域处理的5个实战细节
避开这些坑!用Vivado FIFO IP核做跨时钟域处理的5个实战细节 在FPGA设计中,跨时钟域(CDC)数据传输一直是工程师们面临的棘手问题。Xilinx Vivado提供的FIFO IP核因其稳定性和易用性,成为处理CDC问题的首选方案。然而&a…...
)
保姆级教程:SAP S/4HANA数据迁移,用LTMC从零导入会计科目(附模板避坑指南)
SAP S/4HANA会计科目迁移实战:LTMC工具全流程详解与避坑手册 当企业首次部署SAP S/4HANA时,会计科目主数据的迁移往往是财务模块实施的关键第一步。不同于传统ECC系统,S/4HANA的简化数据模型对会计科目结构提出了新要求,而Migrati…...