CDH6.3.2 的pyspark读取excel表格数据写入hive中的问题汇总
需求:内网通过Excel文件将数据同步到外网的CDH服务器中,将CDH中的文件数据写入hive中。
CDH版本为:6.3.2
spark版本为:2.4
python版本:2.7.5
操作系统:CentOS Linux 7
集群方式:yarn-cluster
一、在linux中将excel文件转换成CSV文件,然后上传到hdfs中。
为何要先转csv呢?主要原因是pyspark直接读取excel的话,涉及到版本的冲突问题。commons-collections-3.2.2.jar 在CDH6.3.2中的版本是3.2.2.但是pyspark直接读取excel要求collections4以上的版本,虽然也尝试将4以上的版本下载放进去,但是也没效果,因为时间成本的问题,所以没有做过多的尝试了,直接转为csv后再读吧。
spark引用第三方包
1.1 转csv的python代码(python脚本)
#-*- coding:utf-8 -*-
import pandas as pd
import os, xlrd ,sysdef xlsx_to_csv_pd(fn):path1="/home/lzl/datax/"+fn+".xlsx"path2="/home/lzl/datax/"+fn+".csv"data_xls = pd.read_excel(path1, index_col=0)data_xls.to_csv(path2, encoding='utf-8')if __name__ == '__main__':fn=sys.argv[1]print(fn)try:xlsx_to_csv_pd(fn)print("转成成功!")except Exception as e:print("转成失败!")
1.2 数据中台上的代码(shell脚本):
#!/bin/bash
#@description:这是一句描述
#@author: admin(admin)
#@email:
#@date: 2023-09-26 14:44:3# 文件名称
fn="项目投运计划"# xlsx转换成csv格式
ssh root@cdh02 " cd /home/lzl/shell; python xlsx2csv.py $fn" # 将文件上传到hfds上
ssh root@cdh02 "cd /home/lzl/datax; hdfs dfs -put $fn.csv /origin_data/sgd/excel/"
echo "上传成功~!"# 删除csv文件
ssh root@cdh02 "cd /home/lzl/datax; rm -rf $fn.csv"
echo "删除成功~!"
二、pyspark写入hive中
2.1 写入过程中遇到的问题点
2.1.1 每列的前后空格、以及存在换行符等问题。采取的措施是:循环列,采用trim函数、regexp_replace函数处理。
# 循环对每列去掉前后空格,以及删除换行符
import pyspark.sql.functions as F
from pyspark.sql.functions import col, regexp_replacefor name in df.columns:df = df.withColumn(name, F.trim(df[name]))df = df.withColumn(name, regexp_replace(col(name), "\n", ""))
2.1.2 个别字段存在科学计数法,需要用cast转换
from pyspark.sql.types import *# 取消销售订单号的科学记数法
col="销售订单号"
df= df.withColumn(col,df[col].cast(DecimalType(10, 0)))
去掉换行符另一种方法:换行符问题也可以参照这个
2.2 数据中台代码(pyspark)
# -*- coding:utf-8
# coding=UTF-8# 引入sys,方便输出到控制台时不是乱码
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )# 引入模块
from pyspark.sql.types import IntegerType, DoubleType, StringType, StructType, StructField
from pyspark.sql import SparkSession
from pyspark import SparkContext, SparkConf, SQLContext
import pandas as pd
import pyspark.sql.functions as F
from pyspark.sql.functions import col, regexp_replace
from pyspark.sql.types import *# 设定资源大小
conf=SparkConf()\.set("spark.jars.packages","com.crealytics:spark-excel_2.11:0.11.1")\.set("spark.sql.shuffle.partitions", "4")\.set("spark.sql.execution.arrow.enabled", "true")\.set("spark.driver.maxResultSize","6G")\.set('spark.driver.memory','6G')\.set('spark.executor.memory','6G')# 建立SparkSession
spark = SparkSession \.builder\.config(conf=conf)\.master("local[*]")\.appName("dataFrameApply") \.enableHiveSupport() \.getOrCreate()# 读取cvs文件
# 文件名称和文件位置
fp= r"/origin_data/sgd/excel/项目投运计划.csv"
df = spark.read \.option("header", "true") \.option("inferSchema", "true") \.option("multiLine", "true") \.option("delimiter", ",") \.format("csv") \.load(fp)# 查看数据类型
# df.printSchema()# 循环对每列去掉前后空格,以及删除换行符
for name in df.columns:df = df.withColumn(name, F.trim(df[name]))df = df.withColumn(name, regexp_replace(col(name), "\n", ""))# 取消销售订单号的科学记数法
col="销售订单号"
df= df.withColumn(col,df[col].cast(DecimalType(10, 0)))df.show(25,truncate = False) # 查看数据,允许输出25行# 设置日志级别 (这两个没用)
sc = spark.sparkContext
sc.setLogLevel("ERROR")# 写入hive中
spark.sql("use sgd_dev") # 指定数据库# 创建临时表格 ,注意建表时不能用'/'和''空格分隔,否则会影响2023/9/4和2023-07-31 00:00:00这样的数据
spark.sql("""
CREATE TABLE IF NOT EXISTS ods_sgd_project_operating_plan_info_tmp (project_no string ,sale_order_no string ,customer_name string ,unoperating_amt decimal(19,2) , expected_operating_time string ,operating_amt decimal(19,2) , operating_progress_track string ,is_Supplied string ,operating_submit_time string ,Signing_contract_time string ,remake string )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
""")# 注册临时表
df.createOrReplaceTempView("hdfs_df")
# spark.sql("select * from hdfs_df limit 5").show() #查看前5行数据# 将数据插入hive临时表中
spark.sql("""insert overwrite table ods_sgd_project_operating_plan_info_tmp select * from hdfs_df
""")# 将数据导入正式环境的hive中
spark.sql("""insert overwrite table ods_sgd_project_operating_plan_info select * from ods_sgd_project_operating_plan_info_tmp
""")# 查看导入后的数据
spark.sql("select * from ods_sgd_project_operating_plan_info limit 20").show(20,truncate = False)# 删除注册的临时表
spark.sql("""drop table hdfs_df
""")# 删除临时表
spark.sql("""drop table ods_sgd_project_operating_plan_info_tmp
""")
关于spark的更多知识,可以参看Spark SQL总结
相关文章:

CDH6.3.2 的pyspark读取excel表格数据写入hive中的问题汇总
需求:内网通过Excel文件将数据同步到外网的CDH服务器中,将CDH中的文件数据写入hive中。 CDH版本为:6.3.2 spark版本为:2.4 python版本:2.7.5 操作系统:CentOS Linux 7 集群方式:yarn-cluster …...
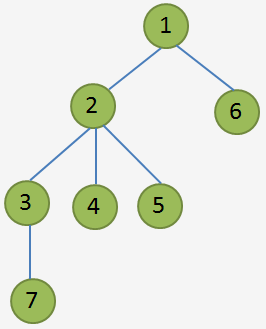
2120 -- 预警系统题解
Description OiersOiers 国的预警系统是一棵树,树中有 �n 个结点,编号 1∼�1∼n,树中每条边的长度均为 11。预警系统中只有一个预警信号发射站,就是树的根结点 11 号结点,其它 �−1…...
C++入门-day01
一、认识C C融合了三种不同的编程方式 C代表的过程性语言在C基础上添加的类、结构体puls代表的面向对象语言C模板支持泛型编程 C完全兼容C的特性 Tips:侯捷老师提倡的Modren C是指C11、C14、C17和C20这些新标准所引入的一系列新特性和改进。在我们练习的时候也应当去…...
Android开源 Skeleton 骨架屏 V1.3.0
目录 一、简介 二、效果图 三、引用 Skeleton 添加jitpack 仓库 添加依赖: 四、新增 “块”骨架屏 1、bind方法更改和变化: 2、load方法更改和变化: 五、关于上一个版本 一、简介 骨架屏的作用是在网络请求较慢时,提供基础占位&…...
)
网络资料搬运(2)
(1) Ubuntu 22.04: 为 Ubuntu22.04 系统添加中文输入法 linux解压gz文件的命令 Ubuntu20.04出现Unit ssh.service could not be found 详解使用SSH远程连接Ubuntu服务器系统 Configuring networks(配置网络) (2) Python && OpenCV: …...

SEO搜索引擎
利用搜索引擎的规则提高网站在有关搜索引擎内的自然排名,吸引更多的用户访问网站,提高网站的访问量,提高网站的销售能力和宣传能力,从而提升网站的品牌效应 搜索引擎优化的技术手段 黑帽SEO 通过欺骗技术和滥用搜索算法来推销毫不…...
动态规划-状态机(188. 买卖股票的最佳时机 IV)
状态分类: f[i,j,0]考虑前i只股票,进行了j笔交易,目前未持有股票 所能获得最大利润 f[i,j,1]考虑前i只股票,进行了j笔交易,目前持有股票 所能获得最大利润 状态转移: f[i][j][0] Math.max(f[i-1][j][0],f[…...
)
银行业务队列简单模拟(队列应用)
设某银行有A、B两个业务窗口,且处理业务的速度不一样,其中A窗口处理速度是B窗口的2倍 —— 即当A窗口每处理完2个顾客时,B窗口处理完1个顾客。给定到达银行的顾客序列,请按业务完成的顺序输出顾客序列。假定不考虑顾客先后到达的时…...

2023/8/8 下午10:42:04 objectarx
2023/8/8 下午10:42:04 objectarx 2023/8/8 下午10:42:16 ObjectARX(AutoCAD Runtime Extension)是用于开发和自定义AutoCAD软件的编程接口。ObjectARX允许开发者使用C++、.NET等编程语言来创建插件、扩展功能和定制化AutoCAD的行为。 通过ObjectARX,开发者可以访问Auto…...
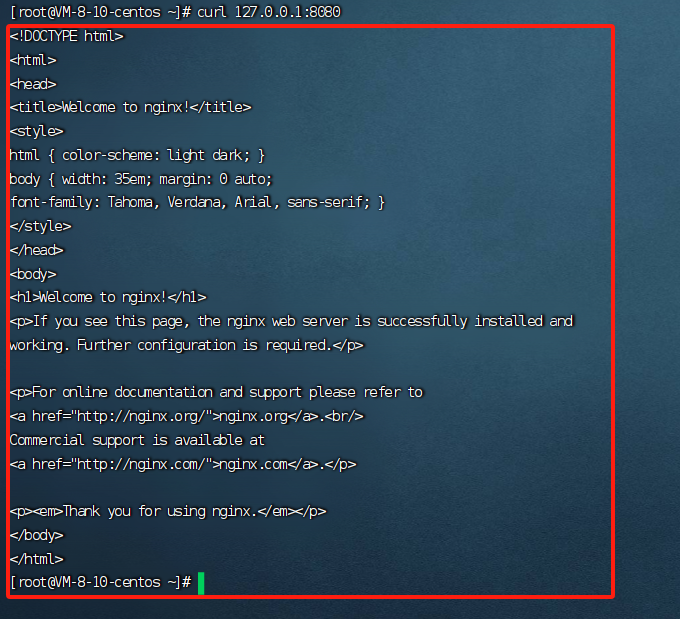
Day-06 基于 Docker安装 Nginx 镜像
1.去官方公有仓库查询nginx镜像 docker search nginx 2.拉取该镜像 docker pull nginx 3. 启动镜像,使用nginx服务,代理本机8080端口(测试是不是好使) docker run -d -p 8080:80 --name nginx-8080 nginx docker ps curl 127.0.0.1:8080...
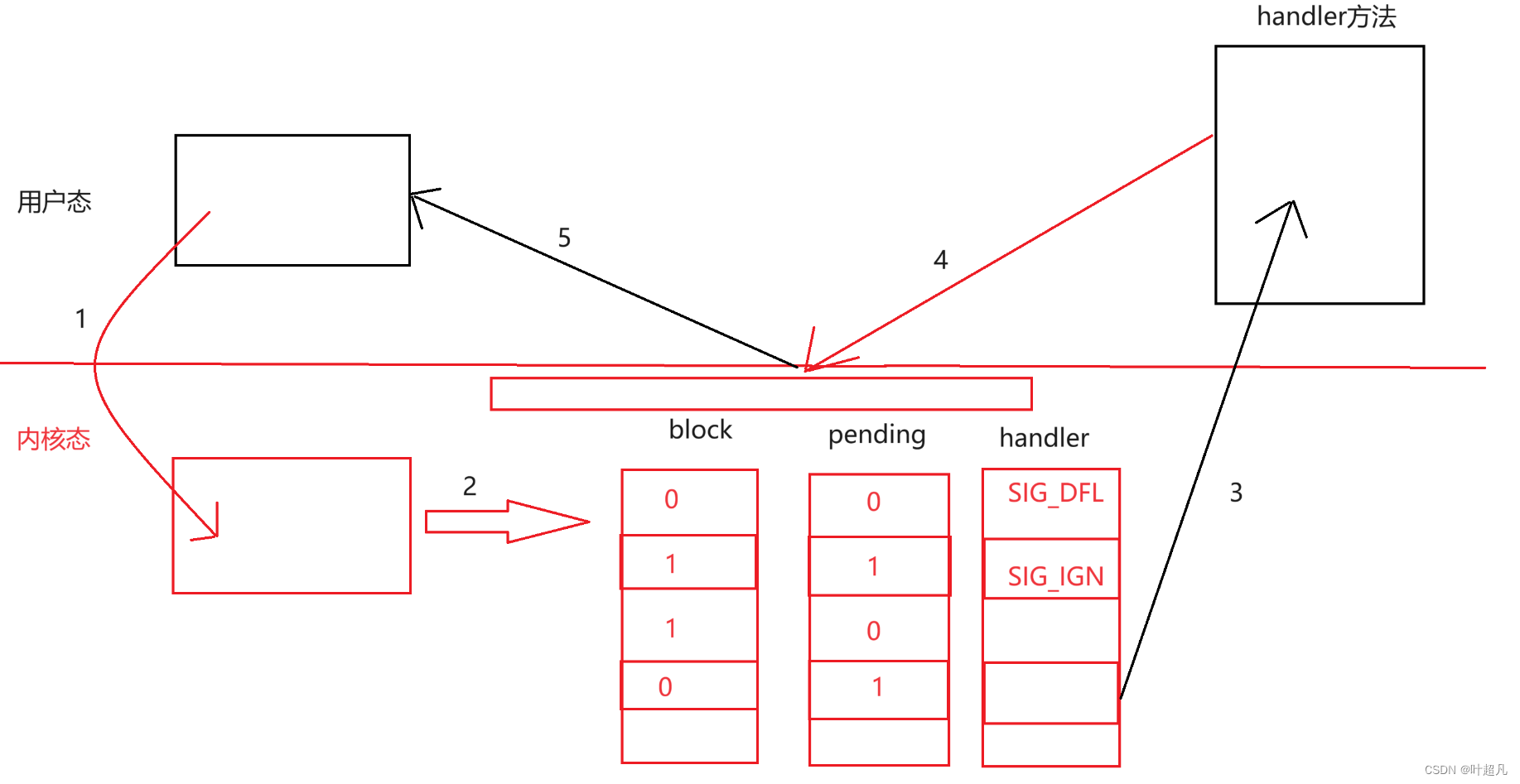
linux入门---信号的保存和捕捉
目录标题 信号的一些概念信号的保存pending表block表handler表 信号的捕捉内核态和用户态信号的捕捉 信号的一些概念 1.进程会收到各种各样的信号,那么程序对该信号进行实际处理的动作叫做信号的递达。 2.我们之前说过当进程收到信号的时候可能并不会立即处理这个信…...
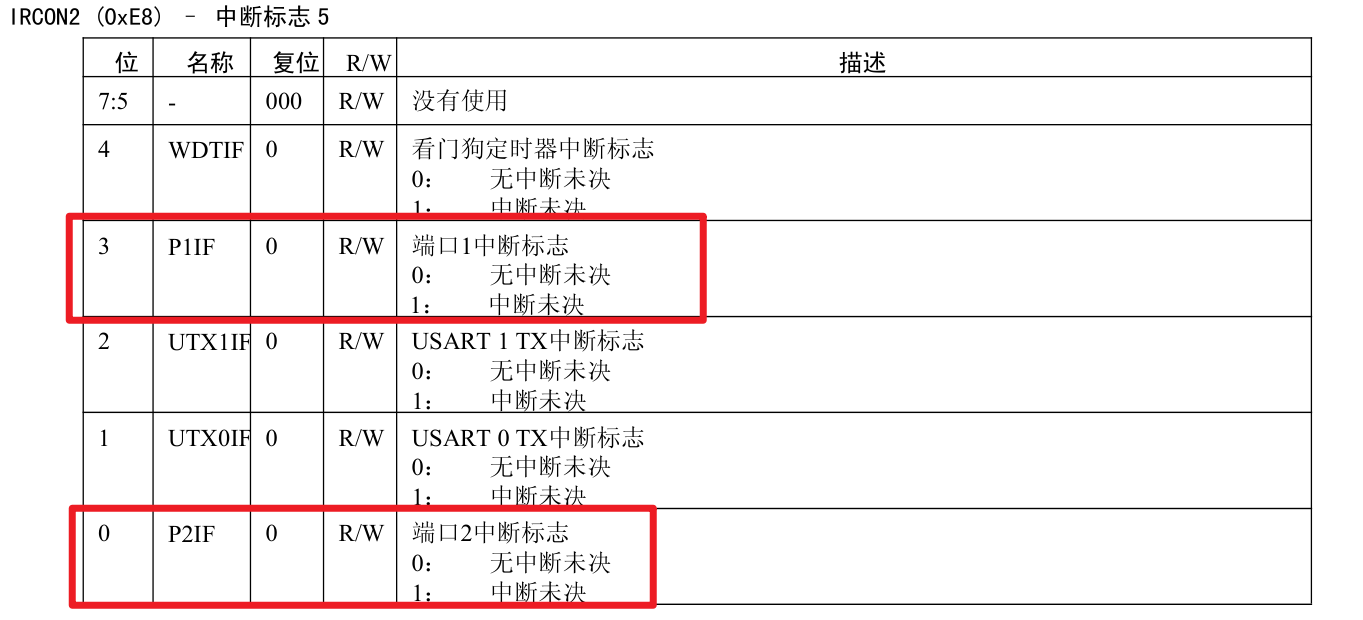
5.外部中断
中断初始化配置步骤: IO口初始化配置 开启中断总允许EA 打开某个IO口的中断允许 打开IO口的某一位的中断允许 配置该位的中断触发方式 中断函数: #pragma vector PxINT_VECTOR __interrupt void 函数名(void){}#pragma vector PxINT_VECTOR __int…...

Mydb数据库问题
1、请简要介绍一下这个基于 Java 的简易数据库管理系统。它的主要功能是什么? TM(Transaction Manager):事务管理器,用于维护事务的状态,并提供接口供其他模块查询某个事务的状态。DM(Data Man…...

部署并应用ByteTrack实现目标跟踪
尽管YOLOv8已经集成了ByteTrack算法,但在这里我还是想利用ByteTrack官网的代码,自己实现目标跟踪。 要想应用ByteTrack算法,首先就要从ByteTrack官网上下载并安装。虽然官网上介绍得很简单,只需要区区6行代码,但对于国…...

MacOS怎么配置JDK环境变量
1 输入命令看是否配置了JDk 的环境变量:echo $JAVA_HOME 要是什么也没输出 证明是没配置 2 输入命令编辑 sudo vim ~/.bash_profile 然后按 i ,进入编辑模式,粘贴下面的代码,注意:JAVA_HOME后面路径需要改成自己的版…...

Spring Boot 开发16个实用的技巧
当涉及到使用Spring Boot开发应用程序时,以下是16个实用的技巧: 1. **使用Spring Initializr**:Spring Initializr是一个快速创建Spring Boot项目的工具,可以帮助您选择项目依赖和生成项目骨架。 2. **自动配置**:Sp…...

《机器学习实战》学习记录-ch2
PS: 个人笔记,建议不看 原书资料:https://github.com/ageron/handson-ml2 2.1数据获取 import pandas as pd data pd.read_csv(r"C:\Users\cyan\Desktop\AI\ML\handson-ml2\datasets\housing\housing.csv")data.head() data.info()<clas…...
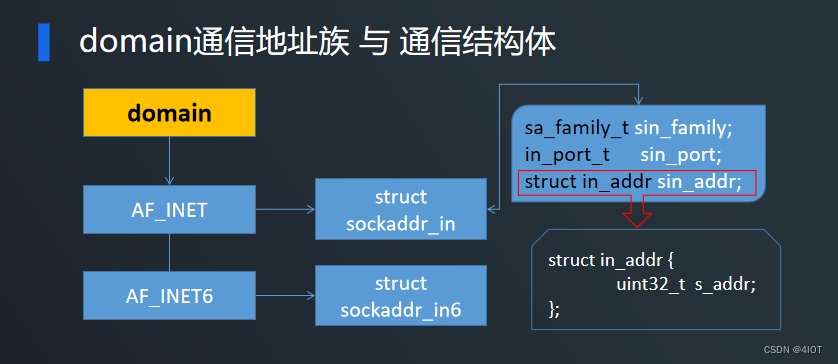
lv7 嵌入式开发-网络编程开发 07 TCP服务器实现
目录 1 函数介绍 1.1 socket函数 与 通信域 1.2 bind函数 与 通信结构体 1.3 listen函数 与 accept函数 2 TCP服务端代码实现 3 TCP客户端代码实现 4 代码优化 5 练习 1 函数介绍 其中read、write、close在IO中已经介绍过,只需了解socket、bind、listen、acc…...
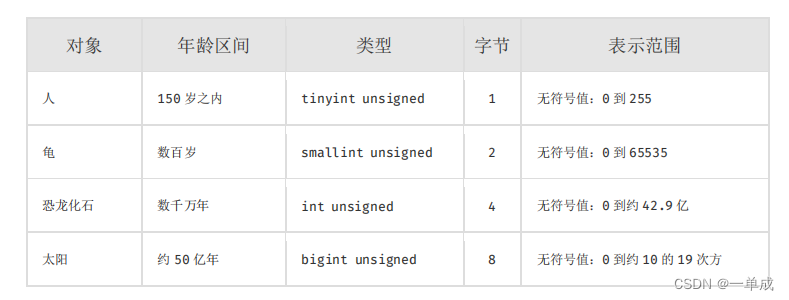
mysql技术文档--阿里巴巴java准则《Mysql数据库建表规约》--结合阿丹理解尝试解读--国庆开卷
阿丹: 国庆快乐呀大家! 在项目开始前一个好的设计、一个健康的表关系,不仅会让开发变的有趣舒服,也会在后期的维护和升级迭代中让系统不断的成长。那么今天就认识和解读一下阿里的准则!! 建表规约 表达是…...
Qt+openCV学习笔记(十六)Qt6.6.0rc+openCV4.8.1+emsdk3.1.37编译静态库
前言: 有段时间没来写文章了,趁编译库的空闲,再写一篇记录文档 WebAssembly的发展逐渐成熟,即便不了解相关技术,web前端也在不经意中使用了相关技术的库,本篇文档记录下如何编译WebAssembly版本的openCV&…...

D3KeyHelper:暗黑3游戏宏助手终极指南,五分钟轻松搞定技能连点
D3KeyHelper:暗黑3游戏宏助手终极指南,五分钟轻松搞定技能连点 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 想要在《暗黑破…...

面壁智能开源端侧多模态大模型MiniCPM-V 4.6,性能登顶同尺寸榜首,降低开发门槛
【导语:5月13日,面壁智能联合清华大学与OpenBMB开源社区,发布并开源新一代端侧多模态大模型MiniCPM-V 4.6。该模型以轻量级参数实现性能与效率突破,在评测中超越竞品,还降低了运行内存需求和计算成本,支持多…...

WarcraftHelper:免费终极指南,让魔兽争霸III在现代系统上流畅运行
WarcraftHelper:免费终极指南,让魔兽争霸III在现代系统上流畅运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHel…...

深入USB总线:图解移远EC20在Linux下如何从硬件接口到虚拟出5个ttyUSB
深入USB总线:图解移远EC20在Linux下如何从硬件接口到虚拟出5个ttyUSB 当我们拆解一台嵌入式设备时,常会遇到4G模块这类看似独立却又深度集成的组件。以移远EC20为例,它表面上通过MiniPCIE接口与主机通信,实则内部隐藏着一套复杂的…...
)
告别离线语音包:用Google Cloud Text-to-Speech API为你的App注入更自然的人声(附Android集成代码)
云端语音合成技术实战:为移动应用注入自然语音的完整方案 在移动应用开发中,语音合成(TTS)技术正成为提升用户体验的关键要素。传统离线语音引擎往往面临发音生硬、语调单一和语种支持有限的问题,而现代云端语音合成API则提供了接近真人、富有…...

软考高级信息系统项目管理师备考笔记-第14章项目沟通管理
第14章项目沟通管理备考知识点及历年真题 一、历年真题分布 2023年5月 选择题3分 案例6分 2023年11月 选择题3分 案例5分第一批、案例10分第二批 2024年5月 选择题3分 案例16分第一批 2025年5月 选择题2分 案例4分第一批、案例9分第二批 二、备考学习笔记 14.1 …...

2026 最稳 AI 论文工具合集:好用不踩雷
毕业季的论文关卡,早已不是 “单打独斗” 的时代。从选题迷茫、大纲混乱,到文献难找、格式崩溃,再到查重超标、AI 率预警,每一个卡点都在消耗本科生的时间与精力。随着 AI 技术深度渗透学术场景,一批专注毕业论文写作的…...

Adobe-GenP 3.0终极指南:如何免费激活Adobe CC全系列软件
Adobe-GenP 3.0终极指南:如何免费激活Adobe CC全系列软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款强大的Adobe Creative Cl…...

如何使用MIKE IO高效处理水文数据:从零开始构建专业工作流
如何使用MIKE IO高效处理水文数据:从零开始构建专业工作流 【免费下载链接】mikeio Read, write and manipulate dfs0, dfs1, dfs2, dfs3, dfsu and mesh files. 项目地址: https://gitcode.com/gh_mirrors/mi/mikeio 水文数据处理是环境科学、水利工程和海洋…...

【DSP学习】外部中断实验-基于普中DSP28335开发攻略
参考材料 普中DSP28335开发攻略 一、外部中断配置 1 失能 CPU 级中断,并初始化 PIE 控制器寄存器和 PIE 中断向量表在前面学习中断章节中,我们知道 F28335 的外设中断需通过 PIE 控制器来管理,因此需要初始化 PIE 相应的寄存器和中断向量表。…...