GEO生信数据挖掘(三)芯片探针ID与基因名映射处理
检索到目标数据集后,开始数据挖掘,本文以阿尔兹海默症数据集GSE1297为例
目录
处理一个探针对应多个基因
1.删除该行
2.保留分割符号前面的第一个基因
处理多个探针对应一个基因
详细代码案例一删除法
详细代码案例二 多个基因名时保留第一个基因名
小结
更新版本的代码全文
上节我们下载了基因芯片平台文件并注释,我们发现存在一个芯片探针ID匹配到多个基因的情况,本节来介绍处理方案。
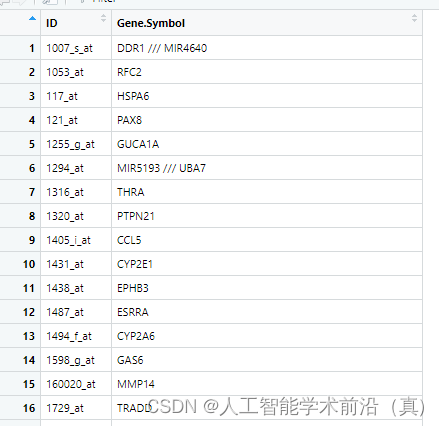
处理一个探针对应多个基因
我们通过简单检索发现两种方法:1.删除操作 2.保留分割符号前面的第一个基因
1.删除该行
#处理一个探针对应多个基因
#方案一:【删除该行】explan_final <- data.frame(explan_final[-grep("///",explan_final$"Gene.Symbol"),]) #去一对多,grep是包含的意思,-就是不包含
2.保留分割符号前面的第一个基因
#方案二:【保留第一个基因名】
ids = platform_file_set #探针列名和基因名两列
library(tidyverse)
test_function <- apply(ids,1,function(x){paste(x[1],str_split(x[2],'///',simplify=T),sep = "...")})
x = tibble(unlist(test_function))colnames(x) <- "ttt"
ids <- separate(x,ttt,c("ID","Gene.Symbol"),sep = "\\...")
dim(ids) #探针列名和基因名两列显然,第一个发现非常简单,在使用merge函数匹配时,会剔除更多的基因。第二个方法,会保留更多基因。
处理多个探针对应一个基因
表达矩阵中还有一个问题,如下图所示,很多探针指向同一个基因。
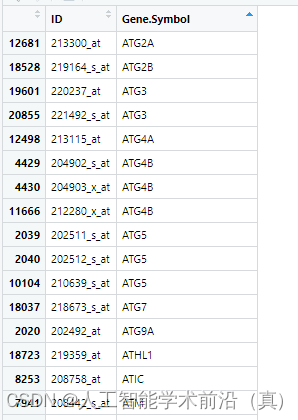
#把重复的Symbol 取每个基因所有探针的平均值或最大值作为基因的表达量
matrix <- aggregate(.~Gene.Symbol, matrix, mean) ##把重复的Symbol取平均值
matrix <- aggregate(.~Gene.Symbol, matrix, max) ##把重复的Symbol取最大值
详细代码案例一删除法
# 安装并加载GEOquery包 library(GEOquery)# 指定GEO数据集的ID gse_id <- "GSE1297"# 使用getGEO函数获取数据集的基础信息 gse_info <- getGEO(gse_id, destdir = ".", AnnotGPL = F ,getGPL = F) # Failed to download ./GPL96.soft.gz!# 提取基因表达矩阵 expression_data <- exprs(gse_info[[1]])#查看平台文件列名 colnames(annotation)#打印项目文件列表 dir() # 读取芯片平台文件txt platform_file <- read.delim("GPL96-57554.txt", header = TRUE, sep = "\t", comment.char = "#")#查看平台文件列名 colnames(platform_file)# 假设芯片平台文件中有两列,一列是探针ID,一列是基因名 #probe_names <- platform_file$ID #gene_symbols <- platform_file$Gene.Symbol platform_file_set=platform_file[,c(1,11)]#将Matrix格式表达矩阵转换为data.frame格式 exprSet <- data.frame(expression_data)#给表达矩阵新增加一列ID exprSet$ID <- rownames(exprSet) # 得到表达矩阵,行名为ID,需要转换,新增一列#矩阵表达文件和平台文件有相同列‘ID’,使用merge函数合并 express <- merge(x = exprSet, y = platform_file_set, by.x = "ID")#删除探针ID列 express$ID =NULLdim(express) exprSet = express #查看多少个基因重复了 table(duplicated(exprSet$Gene.Symbol))#处理重复基因,计算行平均值方案1 #rowMeans = apply(exprSet[,c(1:12)],1,function(x) mean(as.numeric(x), na.rm = T))####计算行平均值#处理重复基因,计算行平均值方案2 #matrix <- aggregate(.~Gene.Symbol, matrix, mean) ##把重复的Symbol取平均值 #row.names(matrix) <- matrix$Gene.Symbol #把行名命名为SYMBOL#处理重复基因,计算行平均值方案3 library(limma) #avereps 函数 exp_unique<-avereps(exp_symbol[,-c(32,ncol(exp_symbol))],ID=exp_symbol$Gene.Symbol)##把重复的Symbol取平均值#排序 exprSet = exprSet[order(rowMeans, decreasing = T),] dim(exprSet)#去掉重复基因 exprSet_2 = exprSet[!duplicated(exprSet[, dim(exprSet)[2]]),] dim(exprSet_2)#去掉缺失值 exprSet_na = na.omit(exprSet_2) explan_final = exprSet_na[exprSet_na$Gene.Symbol != "",] dim(explan_final)#处理一个探针对应多个基因[删除法] explan_final <- data.frame(explan_final[-grep("///",explan_final$"Gene.Symbol"),]) #去一对多,grep是包含的意思,-就是不包含 dim(explan_final)rownames(explan_final) <- explan_final$Gene.Symbol dim(explan_final) explan_final <- explan_final[,c(1:31)] # 此时explan_final为所需文件,行为基因,列为样本
> dim(explan_final)
[1] 12548 31
详细代码案例二 多个基因名时保留第一个基因名
# 安装并加载GEOquery包
library(GEOquery)# 指定GEO数据集的ID
gse_id <- "GSE1297"# 使用getGEO函数获取数据集的基础信息
gse_info <- getGEO(gse_id, destdir = ".", AnnotGPL = F ,getGPL = F) # Failed to download ./GPL96.soft.gz!# 提取基因表达矩阵
expression_data <- exprs(gse_info[[1]])# 提取注释信息
annotation <- featureData(gse_info[[1]])#查看平台文件列名
colnames(annotation)#打印项目文件列表
dir() # 读取芯片平台文件txt
platform_file <- read.delim("GPL96-57554.txt", header = TRUE, sep = "\t", comment.char = "#")#查看平台文件列名
colnames(platform_file)# 假设芯片平台文件中有两列,一列是探针ID,一列是基因名
#probe_names <- platform_file$ID
#gene_symbols <- platform_file$Gene.Symbol
platform_file_set=platform_file[,c(1,11)]#一个探针对应多个基因名,保留第一个基因名
ids = platform_file_set
library(tidyverse)
test_function <- apply(ids,1,function(x){paste(x[1],str_split(x[2],'///',simplify=T),sep = "...")})
x = tibble(unlist(test_function))colnames(x) <- "ttt"
ids <- separate(x,ttt,c("ID","Gene.Symbol"),sep = "\\...")
dim(ids)#将Matrix格式表达矩阵转换为data.frame格式
exprSet <- data.frame(expression_data)
dim(exprSet)#给表达矩阵新增加一列ID
exprSet$ID <- rownames(exprSet) # 得到表达矩阵,行名为ID,需要转换,新增一列
dim(exprSet)
#矩阵表达文件和平台文件有相同列‘ID’,使用merge函数合并
express <- merge(x = exprSet, y = ids, by.x = "ID")#删除探针ID列
express$ID =NULLdim(express) matrix = express
dim(matrix)
#查看多少个基因重复了
table(duplicated(matrix$Gene.Symbol))#把重复的Symbol取平均值
matrix <- aggregate(.~Gene.Symbol, matrix, mean) ##把重复的Symbol取平均值
row.names(matrix) <- matrix$Gene.Symbol #把行名命名为SYMBOLdim(matrix)matrix_na = na.omit(matrix) #去掉缺失值
dim(matrix_na)
matrix_final = matrix_na[matrix_na$Gene.Symbol != "",]
dim(matrix_final)matrix_final <- subset(matrix_final, select = -1) #删除Symbol列(一般是第一列)
dim(matrix_final)
> dim(matrix_final)
[1] 14826 31
小结
原始数据记录有22283条,多个探针对应一个基因采用取平均值处理,一个探针对应多个基因分别进行直接删除操作和保留第一个基因操作, 两种方法最终获得的数据记录分别为12548,14826。
更新版本的代码全文
# 安装并加载GEOquery包
library(GEOquery)# 指定GEO数据集的ID
gse_id <- "GSE1297"# 使用getGEO函数获取数据集的基础信息
gse_info <- getGEO(gse_id, destdir = ".", AnnotGPL = F ,getGPL = F) # Failed to download ./GPL96.soft.gz!# 提取基因表达矩阵
expression_data <- exprs(gse_info[[1]])# 提取注释信息
annotation <- featureData(gse_info[[1]])#查看平台文件列名
colnames(annotation)#打印项目文件列表
dir() # 读取芯片平台文件txt
platform_file <- read.delim("GPL96-57554.txt", header = TRUE, sep = "\t", comment.char = "#")#查看平台文件列名
colnames(platform_file)# 假设芯片平台文件中有两列,一列是探针ID,一列是基因名
#probe_names <- platform_file$ID
#gene_symbols <- platform_file$Gene.Symbol
platform_file_set=platform_file[,c(1,11)]#一个探针对应多个基因名,保留第一个基因名
ids = platform_file_set
library(tidyverse)
test_function <- apply(ids,1,function(x){paste(x[1],str_split(x[2],'///',simplify=T),sep = "...")})
x = tibble(unlist(test_function))colnames(x) <- "ttt"
ids <- separate(x,ttt,c("ID","Gene.Symbol"),sep = "\\...")
dim(ids)#将Matrix格式表达矩阵转换为data.frame格式
exprSet <- data.frame(expression_data)
dim(exprSet)#给表达矩阵新增加一列ID
exprSet$ID <- rownames(exprSet) # 得到表达矩阵,行名为ID,需要转换,新增一列
dim(exprSet)
#矩阵表达文件和平台文件有相同列‘ID’,使用merge函数合并
express <- merge(x = exprSet, y = ids, by.x = "ID")#删除探针ID列
express$ID =NULLdim(express) matrix = express
dim(matrix)
#查看多少个基因重复了
table(duplicated(matrix$Gene.Symbol))#把重复的Symbol取平均值
matrix <- aggregate(.~Gene.Symbol, matrix, mean) ##把重复的Symbol取平均值
row.names(matrix) <- matrix$Gene.Symbol #把行名命名为SYMBOLdim(matrix)matrix_na = na.omit(matrix) #去掉缺失值
dim(matrix_na)matrix_final = matrix_na[matrix_na$Gene.Symbol != "",]
dim(matrix_final)matrix_final <- subset(matrix_final, select = -1) #删除Symbol列(一般是第一列)
dim(matrix_final)
#+ 经过注释、探针名基因名处理、删除基因名为空值、删除缺失值 得到最终 matrix_final
#+==================================================================================
#+========================================================================================已经完成了部分的预处理工作了,在使用数据前还有一系列的质控要做,请看下节数据清洗。
相关文章:
GEO生信数据挖掘(三)芯片探针ID与基因名映射处理
检索到目标数据集后,开始数据挖掘,本文以阿尔兹海默症数据集GSE1297为例 目录 处理一个探针对应多个基因 1.删除该行 2.保留分割符号前面的第一个基因 处理多个探针对应一个基因 详细代码案例一删除法 详细代码案例二 多个基因名时保留第一个基因名…...

力扣 -- 96. 不同的二叉搜索树
解题步骤: 参考代码: class Solution { public:int numTrees(int n) {vector<int> dp(n1);//初始化dp[0]1;//填表for(int i1;i<n;i){for(int j1;j<i;j){//状态转移方程dp[i](dp[j-1]*dp[i-j]);}}//返回值return dp[n];} }; 你学会了吗&…...
)
经典算法-枚举法(百钱买百鸡问题)
题目: 条件:现有 100 元,一共要买公鸡、母鸡、小鸡三种鸡,已知公鸡 5 元一只,母鸡 3 元一只,1 元可以买三只小鸡。 要求:公鸡、母鸡、小鸡都要有,一共买 100 只鸡。有哪几种买法&am…...
Gurobi设置初始可行解
目录 1. 决策变量的Start属性直接设置变量的初始值 1.1 Start:MIP变量的起始值(初值)double类型,可更改 1.2 StartNodeLimit:限制了在完善一组输入部分变量的初始解时,MIP所探索的分支定界的节点的数量 …...
Zabbix配置监控文件系统可用空间小于30GB自动告警
一、创建监控项 二、配置监控项 #输入名称–>键值点击选择 #找到磁盘容量点击 注: 1、vfs 该键值用于检测磁盘剩余空间,zabbix 内置了非常多的键值可以选着使用 2、单位B不需要修改,后期图表中单位和G拼接起来就是GB 3、更新时间 10S…...

进程调度算法之先来先服务(FCFS),短作业优先(SJF)以及高响应比优先(HRRN)
1.先来先服务(FCFS) first come first service 1.算法思想 主要从“公平”的角度考虑(类似于我们生活中排队买东西的例子) 2.算法规则 按照作业/进程到达的先后顺序进行服务。 3.用于作业/进程调度 用于作业调度时,考虑的是哪个作业先…...
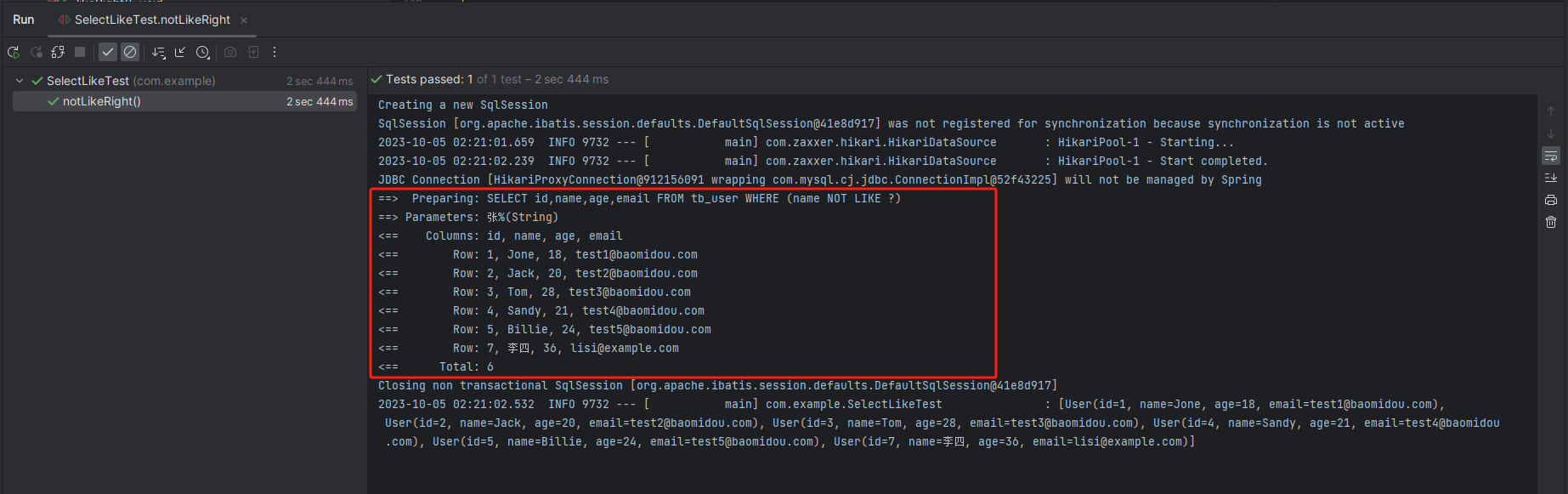
MyBatisPlus(九)模糊查询
说明 模糊查询,对应SQL语句中的 like 语句,模糊匹配“要查询的内容”。 like /*** 查询用户列表, 查询条件:姓名包含 "J"*/Testvoid like() {String name "J";LambdaQueryWrapper<User> wrapper ne…...
Spring 原理
它是一个全面的、企业应用开发一站式的解决方案,贯穿表现层、业务层、持久层。但是 Spring仍然可以和其他的框架无缝整合。 1 Spring 特点 轻量级控制反转面向切面容器框架集合 2 Spring 核心组件 3 Spring 常用模块 4 Spring 主要包 5 Spring 常用注解 bean…...

基于微信小程序的明星应援小程序设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言系统主要功能:具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计…...

try catch 中的finally什么时候运行
try catch 中的finally什么时候运行 在Java、C#等编程语言中,try-catch-finally语句块用于处理异常。finally块的执行时机通常是在try块中的代码执行完毕之后,无论try块中的代码是否引发了异常。 具体执行顺序如下: 1、try块中的代码首先被…...

力扣 -- 322. 零钱兑换(完全背包问题)
参考代码: 未优化代码: class Solution { public:int coinChange(vector<int>& coins, int amount) {int n coins.size();const int INF 0x3f3f3f3f;//多开一行,多开一列vector<vector<int>> dp(n 1, vector<i…...

[python]pip安装requiements.txt跳过错误包继续安装
在linux上可以用下面操作进行 while read requirement; do sudo pip install $requirement; done < requirement.txt 在windows上写个脚本 import sys from pip._internal import main as pip_maindef install(package):pip_main([--default-timeout1000,install,-U, pac…...

1.5 计算机网络的类别
思维导图: 1.5.1 计算机网络的定义 我的笔记: #### 精确定义: 计算机网络没有统一的精确定义,但一种较为接近的定义是:计算机网络主要由一些通用的、可编程的硬件互连而成,这些硬件并非专门用来实现某一特…...
Go 基本数据类型和 string 类型介绍
Go 基础之基本数据类型 文章目录 Go 基础之基本数据类型一、整型1.1 平台无关整型1.1.1 基本概念1.1.2 分类有符号整型(int8~int64)无符号整型(uint8~uint64) 1.2 平台相关整型1.2.1 基本概念1.2.2 注意点1.2.3 获取三个类型在目标…...
打印如何不换行?)
Python中print()打印如何不换行?
文章目录 Python中print()打印如何不换行python2.xpython3.x print()函数语法objects基本语法sep基本语法end基本语法 Python中print()打印如何不换行 print() 函数用于打印输出,是python中最常见的一个内置函数。 如何在Python中打印两个或多个变量、语句时而不进…...

python 学习随笔 4
列表list 将序列前几个进行替换(数量可以不同) 将序列进行间隔替换(必须保证数量相同,否则报错) 删除序列内元素 向序列后新增一个元素 向序列后新增多个元素 将序列进行数乘(不是产生几个序列哦࿰…...

【网络安全-信息收集】网络安全之信息收集和信息收集工具讲解
一,域名信息收集 1-1 域名信息查询 可以用一些在线网站进行收集,比如站长之家 域名Whois查询 - 站长之家站长之家-站长工具提供whois查询工具,汉化版的域名whois查询工具。https://whois.chinaz.com/ 可以查看一下有没有有用的信息…...
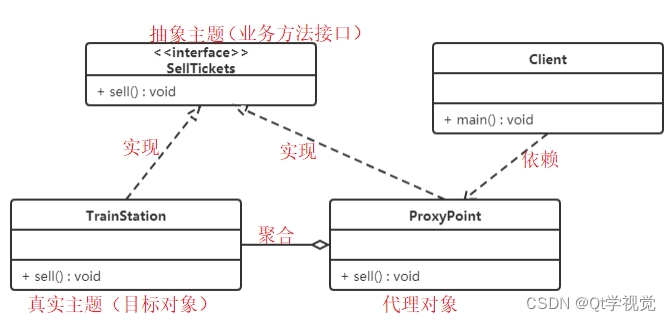
设计模式12、代理模式 Proxy
解释说明:代理模式(Proxy Pattern)为其他对象提供了一种代理,以控制对这个对象的访问。在某些情况下,一个对象不适合或者不能直接引用另一个对象,而代理对象可以在客户端和目标对象之间起到中介的作用。 抽…...

ZXing - barcode scanning library for Java, Android
官网 GitHub - zxing/zxing: ZXing ("Zebra Crossing") barcode scanning library for Java, Android 使用说明 Getting Started Developing zxing/zxing Wiki GitHub 参考 Android中二维码的扫描与生成(zxing库)_android 二维码生成-C…...

MySQL存储引擎:选择合适的引擎优化数据库性能
什么是存储引擎? 在MySQL中,存储引擎是数据库管理系统的一部分,负责数据的存储、检索和管理。 常见的MySQL存储引擎 InnoDB InnoDB是MySQL的默认存储引擎,它支持事务和行级锁定,适用于大多数在线事务处理ÿ…...

IV测试仪选购避坑指南,这几点一定要提前了解
在光伏产业链中,IV测试仪应用广泛,覆盖组件分选、实验室检定、电站验收、运维排查等场景。市面上仪器品类繁杂,包含台式实验室款、生产线分选款、户外检测款,价格差距悬殊。不少采购人员不懂场景适配,盲目比价、堆砌参…...

RootlessJamesDSP:无Root环境下的Android全局音频处理方案解析
1. 项目概述:在无根环境中驯服音频的“魔法师”如果你是一个对手机音质有追求的安卓用户,或者是一个喜欢折腾音频处理插件的玩家,那么你很可能听说过或者用过 JamesDSP。它是一款功能强大的音频处理引擎,能够通过复杂的算法&#…...

从零开始使用 Node js 调用 Taotoken 多模型 API 的实践感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从零开始使用 Node.js 调用 Taotoken 多模型 API 的实践感受 作为一名 Node.js 后端开发者,我最近在项目中接入了 Taot…...

不止于水:用MS动力学模拟和RDF分析,探究任意离子/分子在溶液中的溶剂化结构
从水到多元溶液:MS动力学模拟与RDF分析的高级应用指南 当我们需要理解溶液中离子或分子的行为时,径向分布函数(RDF)分析提供了一个强有力的工具。传统的纯水体系研究固然重要,但现实中的溶液系统往往更为复杂——电解液中的锂离子、蛋白质溶液…...

RAG开发实战:Langchain-RAG-DevelopmentKit核心架构与工程化指南
1. 项目概述:一个面向RAG应用开发的“瑞士军刀”如果你正在或打算基于LangChain构建检索增强生成(RAG)应用,那么你大概率会遇到一个经典困境:从零开始搭建一个健壮、可扩展的RAG系统,需要整合的组件和技术栈…...

终极Windows和Office激活指南:5分钟搞定系统激活难题
终极Windows和Office激活指南:5分钟搞定系统激活难题 【免费下载链接】KMS_VL_ALL_AIO Smart Activation Script 项目地址: https://gitcode.com/gh_mirrors/km/KMS_VL_ALL_AIO 还在为Windows系统频繁弹出激活提示而烦恼吗?Office突然变成只读模式…...

GPU云服务器选型指南:从核心参数到实际部署的深度解析
在当下人工智能跟高性能计算急剧速度发展状况里,GPU云服务器正沿着从专业领域迈向更为广泛应用场景的路径前行。对于构成企业的开发者、相关技术团队来讲,怎样精准无误理解这一技术方案所具备的本质,并且于实际选型期间做出合乎情理的判断&am…...

Avalonia AI助手插件:为.NET跨平台UI开发注入专家级智能
1. 项目概述:一个为Avalonia开发者量身定制的AI助手插件如果你正在使用Avalonia这个跨平台的.NET UI框架,并且同时也在探索如何利用像Claude、ChatGPT、GitHub Copilot这样的AI助手来提升开发效率,那么你很可能遇到过这样的困境:当…...

如何解决Funannotate数据库安装失败:从403错误到完整部署的实战指南
如何解决Funannotate数据库安装失败:从403错误到完整部署的实战指南 【免费下载链接】funannotate Eukaryotic Genome Annotation Pipeline 项目地址: https://gitcode.com/gh_mirrors/fu/funannotate Funannotate是真核基因组注释的强大工具,但在…...

Cursor Pro永久免费使用终极指南:如何绕过试用限制完整教程
Cursor Pro永久免费使用终极指南:如何绕过试用限制完整教程 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached you…...