【数据结构】排序算法(二)—>冒泡排序、快速排序、归并排序、计数排序

👀樊梓慕:个人主页
🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》
🌝每一个不曾起舞的日子,都是对生命的辜负
目录
前言
1.冒泡排序
2.快速排序
2.1Hoare版
2.2占坑版
2.3前后指针版
2.4三数取中对快速排序的优化
2.5非递归版
3.归并排序
3.1递归版
3.2非递归版
3.3外排序问题
4.计数排序
前言
本篇文章博主将继续带来排序算法实现,主要讲解交换排序思想中的冒泡排序、三种快速排序递归版和一种非递归版,归并排序中的递归版和非递归版,以及计数排序的相关内容。
欢迎大家📂收藏📂以便未来做题时可以快速找到思路,巧妙的方法可以事半功倍。
=========================================================================
GITEE相关代码:🌟fanfei_c的仓库🌟
=========================================================================
1.冒泡排序
冒泡排序顾名思义,整个排序的过程就像泡泡不断上升,以升序为例,较大的数值会与较小的数值交换,每趟排序都可以将一个数放到合适的位置,比如最大值在最后,次大值放倒数第二个位置等。

图片取自GITHUB-Olivier Wietrich
所以我们需要双层循环控制。
- 在遍历整个序列的同时,内部的单趟排序要每次都减少一次比较(因为每趟排序都有一个元素到了合适的位置,就需要将这个元素剔除掉下次的排序中)
- 也同样的我们就可以知道外层循环需要执行n次才能让所有的元素放置在正确的位置上。
冒泡排序的特性总结:
- 冒泡排序是一种非常容易理解的排序
- 时间复杂度:O(N^2)
- 空间复杂度:O(1)
- 稳定性:稳定
代码实现:
// 冒泡排序
void BubbleSort(int* a, int n)
{for (int i = 0; i < n ; i++){int flag = 0;for (int j = 1; j < n - i; j++)//每次减少一个需要排序的元素{if (a[j-1] > a[j]){swap(&a[j], &a[j - 1]);flag = 1;}}if (flag == 0){break;}}
}2.快速排序
快速排序算法是由东尼·霍尔设计提出,接下来我会为大家讲解一下快排的霍尔版,以及后面各路大佬对快排的优化优化再优化。
快排的特性总结我放到快速排序部分最后罗列。
2.1Hoare版
Hoare版的思想不容易理解。
首先无论哪种版本的快排,核心思想都是任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值(可以理解为二叉树的结构),然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
那么我们如何进行操作呢?
单趟排序的思想:
以第一躺排序为例,先不考虑后面的递归,首先将待排序序列最左端的元素设定为我们首躺排序中需要找到合适位置的根(代码中备注三数取中的地方大家可以先不用管,先掌握思路,后面会讲)。
int keyi=left。
我们知道左指针left此时在最左端,右指针right此时在最右端,我们令右边先走(必须右边先走才能保证left与right相遇的点小于根keyi的点,这个后面也会讲,大家先往后捋思路),当右指针right指向小于根的点时,停下来,同样的,当左指针left指向大于根的点时,停下来,然后交换他们所指向的元素,此时是不是left指向的元素也小于根了,right同理。
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
swap(&a[left], &a[right]);
也就是说我们可以通过这样的操作来实现left左边的值都小于根,right右边的值都大于根,当left与right相遇时,由于相遇点必然小于根,所以我们交换根指向的元素与相遇点指向的元素,此时就完成了一趟排序,也成功实现了我们上面需要完成的功能。
递归的思想:
我们每一趟排序都可以将一个元素放在正确的位置,并且该元素左面的值都小于它,右面的值都大于它,那么我们就可以以该元素为分割点,他左面的序列执行单趟排序的算法,右面的序列同样要执行单趟排序的算法。
但是其实递归到后面有很大程度的浪费,比如二叉树的最后一层占据了整个二叉树节点数的50%,倒数第二层25% ……,我们发现在后面的排序中,其实递归是存在很大程度浪费的,所以我们可以在末尾几层不递归了,直接采用插入排序。
if ((end - begin + 1) > 10)
{……;
}
else
{InsertSort(a + begin, end - begin + 1);
}其实,在Release版本下影响并不大,因为编译器已经将递归的代价优化的很小了。
但这何必不是一种优化的手段,面试的时候可能会有用噢
大家有没有发现这就是二叉树中前序遍历的思想,先搞定根的位置,然后处理左子树,再处理右子树,不同的是我们只需控制左子树的下标范围和右子树的下标范围罢了。
图片取自wikipedia-Quicksort
那么为什么右边先走就能保证相遇点一定小于keyi点呢?
- 相遇之前最后一次挪动的指针,如果为右指针,代表左指针刚刚遇到大于keyi点的值,并完成了交换,然后新一轮循环右指针先走,那么右指针right停下来的位置必然就是此时刚刚交换完值的左指针的位置,而我们知道左指针此时指向的值一定小于keyi点。
- 相遇之前最后一次挪动的指针,如果为左指针,代表右指针刚刚遇到小于keyi点的值,左指针此时向右走与右指针相遇,所以相遇点此时的值一定小于keyi点。
代码实现:
// 快速排序hoare版本
int PartSort1(int* a, int left, int right)
{int midi = GetMidi(a, left, right);//三数取中,后面会讲swap(&a[midi], &a[left]);int keyi = left;while (left < right){//右边先走,确保left与right相遇在小于key的点while (left < right && a[right] >= a[keyi]){right--;}while (left < right && a[left] <= a[keyi]){left++;}swap(&a[left], &a[right]);//此时left的内容大于right的内容,交换两者}swap(&a[left], &a[keyi]);//将keyi的内容放到left与right的相遇点return left;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;// 小区间优化,小区间不再递归分割排序,降低递归次数if ((end - begin + 1) > 10){int keyi = PartSort3(a, begin, end);// [begin, keyi-1] keyi [keyi+1, end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{InsertSort(a + begin, end - begin + 1);}
}2.2占坑版
核心思路不变,单趟排序的思想有所调整。
思路:
首先先将第一个数据存放在key中,形成第一个坑位。
int key = a[left];
int hole = left;
因为你的key首个取值在最左面,即坑位在最左面,所以找下一个坑位的位置应该从右面开始,当右指针指向的元素小于key时,形成新的坑位,再从左面开始找,当左指针指向的元素大于key时,形成新的坑位,重复这一过程;
while(left<right)
{
while (left<right && a[right] >= key)
{
right--;
}
a[hole]=a[right];
hole = right;
while (left<right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;}
直到左右指针相遇,相遇时我们把最开始保存的key值放到坑位中,返回坑的位置。
a[hole] = key;
return hole;
TIP:递归思想和Hoare版是一样的。
代码实现:
// 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{int midi = GetMidi(a, left, right);swap(&a[midi], &a[left]);int key = a[left];int hole = left;while (left < right){while (left<right && a[right] >= key){right--;}a[hole]=a[right];hole = right;while (left<right && a[left] <= key){left++;}a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;// 小区间优化,小区间不再递归分割排序,降低递归次数if ((end - begin + 1) > 10){int keyi = PartSort3(a, begin, end);// [begin, keyi-1] keyi [keyi+1, end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{InsertSort(a + begin, end - begin + 1);}
}2.3前后指针版
前后指针版的思想更加简单,他定义了两个指针,一个指针在前指向left,一个指针在后一个位置left+1,并且保存left此时的位置(因为left后面会移动走);
int prev = left;
int cur = left+1;
int keyi = left;
当cur指向的内容小于keyi指向的内容,就交换prev+1指向的元素与cur指向的元素(不能交换prev位置,因为prev首次在left位置,而left位置也就是keyi的位置的元素是重要的参照条件,要在最后交换),不管cur指向的元素小于或者大于等于keyi指向的元素,cur都向后移动,循环这个过程直到cur超过right;
while (cur <= right)
{
//cur指针指向的内容小于key时,交换prev指针和cur指针指向的内容
//因为要交换的是prev的下一个,所以要加这个判断,如果prev+1的位置等于cur的位置时,就不要交换了
if (a[cur] < a[keyi] && ++prev!=cur)
{
swap(&a[prev], &a[cur]);
}
cur++; //不管大于小于,cur前进都一格
}
最后将参照值与prev交换,返回该位置。
swap(&a[prev], &a[keyi]);
return prev;
本质上可以理解为把大于key的一段区间,推箱子似的往右推,并把小的甩到左面去。
代码实现:
// 快速排序前后指针法
int PartSort3(int* a, int left, int right)
{int midi = GetMidi(a, left, right);swap(&a[midi], &a[left]);int prev = left;int cur = left+1;int keyi = left;while (cur<=right){if(a[cur] < a[keyi]){swap(&a[++prev],&a[cur]);//这里相当于prev+1的位置等于cur的位置时也交换,浪费资源}cur++;}swap(&a[prev], &a[keyi]);return prev;
}// 快速排序前后指针法(优化版)
int PartSort3_1(int* a, int left, int right)
{int midi = GetMidi(a, left, right);swap(&a[midi], &a[left]);int prev = left;int cur = left + 1;int keyi = left;while (cur <= right){//cur指针指向的内容小于key时,交换prev指针和cur指针指向的内容//因为要交换的是prev的下一个,所以要加这个判断,如果prev+1的位置等于cur的位置时,就不要交换了if (a[cur] < a[keyi] && ++prev!=cur){swap(&a[prev], &a[cur]);}cur++; //不管大于小于,cur前进都一格}swap(&a[prev], &a[keyi]);return prev;
}void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;// 小区间优化,小区间不再递归分割排序,降低递归次数if ((end - begin + 1) > 10){int keyi = PartSort3(a, begin, end);// [begin, keyi-1] keyi [keyi+1, end]QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}else{InsertSort(a + begin, end - begin + 1);}
}2.4三数取中对快速排序的优化
这就是上面所有快排方法中都用到的一个排序前的操作,那么为什么要加这一段操作呢?
我们直到快排是一种极为有效的排序方法,但当他遇到较为有序的序列进行排序时,或者极端一点,当他排已经有序的一段序列时,他的时间复杂度是O(N^2),每趟排序时间复杂度量级为N,需要N趟。
因为有序,所以他每次选取的根都在一侧,而不是最理想的中间位置,也就是说这棵递归二叉树严重偏离。
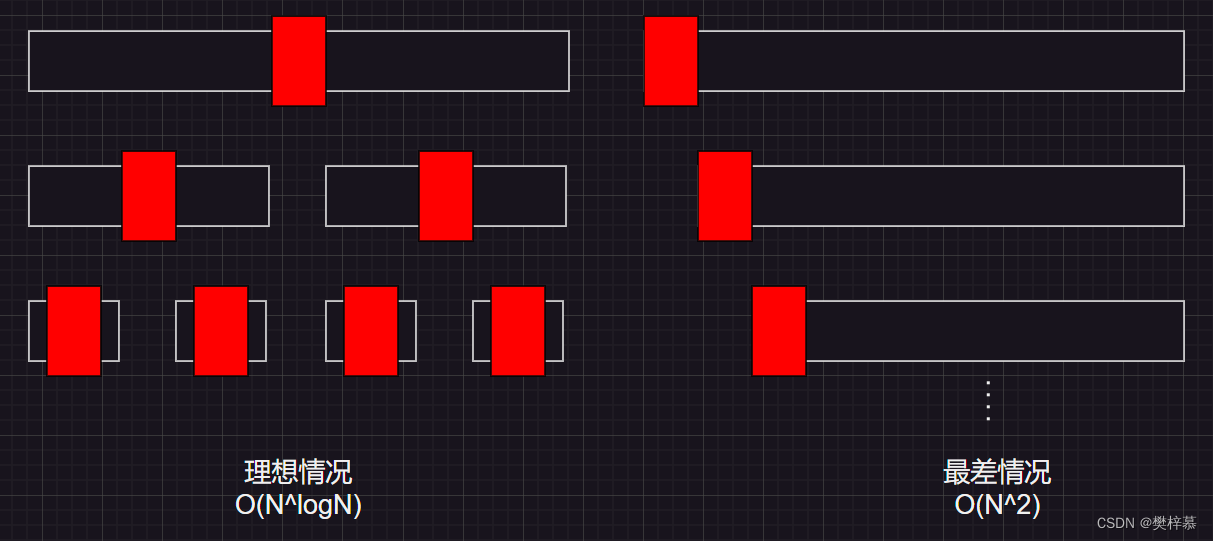
图 理想情况与最差情况的对比
那么怎么办呢?
我们只需要利用三数取中,避免每次都取到最小的值或最大的值作为坑位(参照值);
对比序列两侧和中间值,取中间大小的那个值与left指向的内容交换即可。
代码实现:
//三数取中
//三数取中对于已经有序的序列使用快速排序有很好的优化作用
int GetMidi(int* a, int left, int right)
{int mid = (left + right) / 2;if (a[mid] > a[left]){if (a[mid] < a[right]){return mid;}else if(a[left]>a[right]){return left;}else{return right;}}else//a[mid]<a[left]{if (a[right] > a[left]){return left;}else if(a[right]<a[left] && a[right]<a[mid]){return mid;}else{return right;}}
}
2.5非递归版
非递归方式实现快排可以采用栈的数据结构也可以采用队列的数据结构辅助完成。
比如用栈的数据结构进行实现。
代码实现:
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right)
{ST st;STInit(&st);STPush(&st, right);//入右取左STPush(&st, left);//入左取右//先入后出while (!STEmpty(&st)){int begin = STTop(&st);STPop(&st);int end = STTop(&st);STPop(&st);int keyi = PartSort3_1(a, begin, end);if (keyi+1<end)//将右半序列压栈{STPush(&st, end);STPush(&st, keyi + 1);}if (begin<keyi-1)//将左半序列压栈{STPush(&st, keyi - 1);STPush(&st, begin);}}STDestroy(&st);
}快速排序的特性总结:
- 快速排序整体的综合性能和使用场景都是比较好的
- 时间复杂度:O(N^logN) //在使用三数取中优化后
- 空间复杂度:O(logN)
- 稳定性:不稳定
3.归并排序
归并排序的核心思路:
- 将已有序的子序列合并,得到完全有序的序列;
- 即先使每个子序列有序,再使子序列段间有序。
归并排序的特性总结我放到归并排序部分最后罗列。
3.1递归版
在递归版中,依照归并排序的核心思路,我们需要先将子序列有序,再最后合并子序列,那么很容易会联想到二叉树部分的后序遍历思想,即先解决左右子树,最后解决根。
回归到排序中,就是先将整个待排序序列拆分成N多个子序列(左右子树),然后将子序列(根)进行排序操作即可。
现在我们需要解决的就只是如何将子序列进行排序的问题了。
子序列排序:
- 我们可以创建一个临时数组,将子序列再拆分想象为两段,在这两段上分别定义左右指针,右指针用来标记结束位置,左指针依次与另一端左指针比较大小;
- 假设排升序,那我们就将小的那一段先放到临时数组中,依此类推,如果有一段先结束了(左指针超过右指针),那么证明另一段序列剩下的数据都大于该段序列此时左指针指向的值,所以直接追加到临时数据即可;
- 最后再将排好序的临时数组拷贝回原数组即可。
代码实现:
//归并排序子函数
void _MergeSort(int* a, int* tmp, int begin, int end)
{if (end <= begin){return;}int mid = (begin + end) / 2;_MergeSort(a, tmp, begin, mid);_MergeSort(a, tmp, mid + 1, end);//后序思想int begin1 = begin;int end1 = mid;int begin2 = mid + 1;int end2 = end;int inrex = begin;while (begin1<=end1 && begin2 <= end2){if(a[begin1] <= a[begin2])//这里如果为<,那么该排序方法就为不稳定的tmp[inrex++] = a[begin1++];elsetmp[inrex++] = a[begin2++];}//如果两段比较序列中的任意一段有剩余//说明该段序列剩下的数据都大于或都小于另一段序列的某个值//则将该段直接追加给tmp数组中即可while (begin1 <= end1){tmp[inrex++] = a[begin1++];}while (begin2 <= end2){tmp[inrex++] = a[begin2++];}//最后将排好序的tmp数组拷贝到a数组中memcpy(a+begin, tmp+begin, (end - begin + 1)*sizeof(int));
}// 归并排序递归实现
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(n*sizeof(int));if (tmp == NULL){perror("malloc fail");exit(-1);}_MergeSort(a, tmp, 0, n - 1);return;
}3.2非递归版
非递归版的思想是先将整个序列划分为N多个子序列,然后将这些子序列两两进行比较排序后放到临时数组,执行完一遍,将子序列减少一半(代码中是利用gap实现这个思路),再重复这一过程。
但非递归有一个很容易出现的问题:数组越界访问。
我们每次执行完一遍后,是利用gap*=2实现的减少一半子序列,可是每次gap变为之前的二倍的时候,由于begin和end的取值就是依据gap来定义的。
比如:end2=i+2*gap-1;
想一想是不是很容易越界?
那么我们如何解决这一问题呢?

图 越界的情况分析
if (begin2 >= n)//包含了上图中提到的前三种情况,直接break
{
break;
}
if (end2 >= n)//到这说明begin2未越界,end2越界,将end2重新修正
{
end2 = n - 1;
}
代码实现:
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(n * sizeof(int));if (tmp == NULL){perror("malloc fail");exit(-1);}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2*gap){int begin1 = i;int end1 = i + gap-1;int begin2 = i + gap;int end2 = i + 2 * gap - 1;int inrex = i;//如果begin2已经越界,则直接跳过本次归并if (begin2 >= n){break;}if (end2 >= n)//到这说明begin2未越界,end2越界,将end2重新修正{end2 = n - 1;}while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2])//这里如果为<,那么该排序方法就是不稳定的tmp[inrex++] = a[begin1++];elsetmp[inrex++] = a[begin2++];}while (begin1 <= end1){tmp[inrex++] = a[begin1++];}while (begin2 <= end2){tmp[inrex++] = a[begin2++];}//将本次归并结果拷贝回a数组memcpy(a + i, tmp + i, (end2-i+1)* sizeof(int));//这里的第三个参数也是避免越界的重要因素}gap *= 2;}free(tmp);return;
}归并排序的特性总结:
- 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
- 时间复杂度:O(N*logN)
- 空间复杂度:O(N)
- 稳定性:稳定
3.3外排序问题
前面讲到的所有排序方法都是内排序,就是在内存中排序的方法。
那么他们能不能对磁盘中的数据进行排序呢?
答案是不能,注意磁盘中不支持下标随机访问,一般在磁盘中都是顺序写顺序读。
- 你可能有使用fseek调整文件指针的想法,可是那样效率极差。
而归并排序的思想却可以帮助我们实现外排序,即在磁盘中进行排序。
比如现在有一个4G大小的数据文件,要求你对该文件进行排序操作。
- 依据归并排序的思想,我们就可以将他先切分成几(4)份新文件(大小1G),每份新文件就可以读取到内存中利用内排序的方法进行排序;
- 然后将这几段有序的新文件用文件指针打开,利用归并思想比较然后覆盖写入可以放下两段序列的新文件;
- 重复这一过程,直到覆盖写入原4G大小的文件中。
4.计数排序
计数排序的思想就是先统计出相同数据出现的次数,然后根据他们出现的次数将序列回收到原来的序列中。
简单点就是:
- 先求出待排序序列最大最小值,从而得到待排序序列取值的范围,然后创建一个这么大范围的计数数组;
- 之后再遍历原数组,谁出现了,就在谁的计数数组位置上+1,可以得到每个元素出现的次数;
- 最后再根据他们出现的次数,依次放回。
虽然看着很傻瓜式的方法,但是大家不妨观察下代码实现部分,其实设计逻辑非常巧妙,我已经在源代码中注释出来了, 大家可以学习下。
相信大家缕清计数排序的思路后,就会发现他适合数据非常紧凑的数据排序,并且在很多情况下,他的时间复杂度非常低。
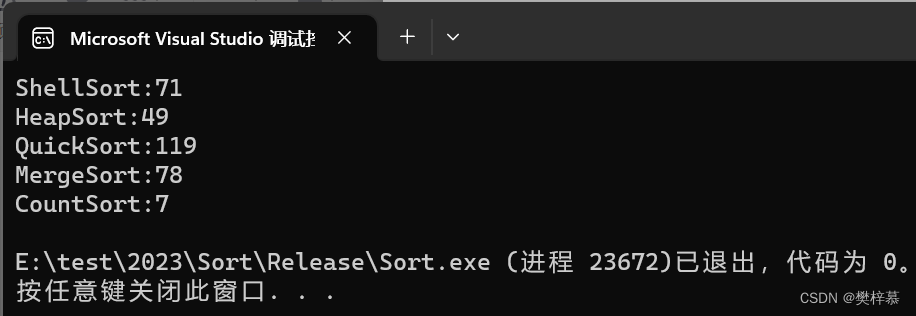
图 数据量1e6的情况下各排序速度比较(单位:ms)
代码实现:
// 计数排序
void CountSort(int* a, int n)
{int max = a[0];int min = a[0];for (int i = 0; i < n; i++){if (a[i] > max)max = a[i];if (a[i] < min)min = a[i];}//计算范围int range = max - min + 1;//创建计数数组int* count = (int*)malloc(sizeof(int) * range);if (count == NULL){perror("malloc fail");exit(-1);}memset(count, 0, sizeof(int) * range);统计出现数据次数(普通思路)//for (int i = 0; i < range; i++)//{// for (int j = 0; j < range; j++)// {// if (count[i] == a[j])// count[i]++;// }//}//统计出现数据次数(非常巧妙)for (int i = 0; i < n; i++){count[a[i] - min]++;}int j = 0;for (int i = 0; i < range; i++){while (count[i]--){a[j++] = i + min;}}
}计数排序的特性总结:
- 计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
- 时间复杂度:O(MAX(N,范围))
- 空间复杂度:O(范围)
- 稳定性:稳定
📣📣📣截至到这里,博主现阶段对于排序的内容就结束啦📣📣📣
💯那么你是否有所收获呢💯
🀄排序的思想学习很重要,只要你掌握了这种排序思想,那么代码实现就只是时间的问题了🀄
=========================================================================
如果你对该系列文章有兴趣的话,欢迎持续关注博主动态,博主会持续输出优质内容
🍎博主很需要大家的支持,你的支持是我创作的不竭动力🍎
🌟~ 点赞收藏+关注 ~🌟
=========================================================================
相关文章:
【数据结构】排序算法(二)—>冒泡排序、快速排序、归并排序、计数排序
👀樊梓慕:个人主页 🎥个人专栏:《C语言》《数据结构》《蓝桥杯试题》《LeetCode刷题笔记》《实训项目》 🌝每一个不曾起舞的日子,都是对生命的辜负 目录 前言 1.冒泡排序 2.快速排序 2.1Hoare版 2.2占…...
SpringCloud-消息组件
1 简介 了解过RabbitMQ后,可能我们会遇到不同的系统在用不同的队列。比如系统A用的Kafka,系统B用的RabbitMQ,但是没了解过Kafka,因此可以使用Spring Stream,它能够屏蔽地产,像JDBC一样,只关心SQ…...
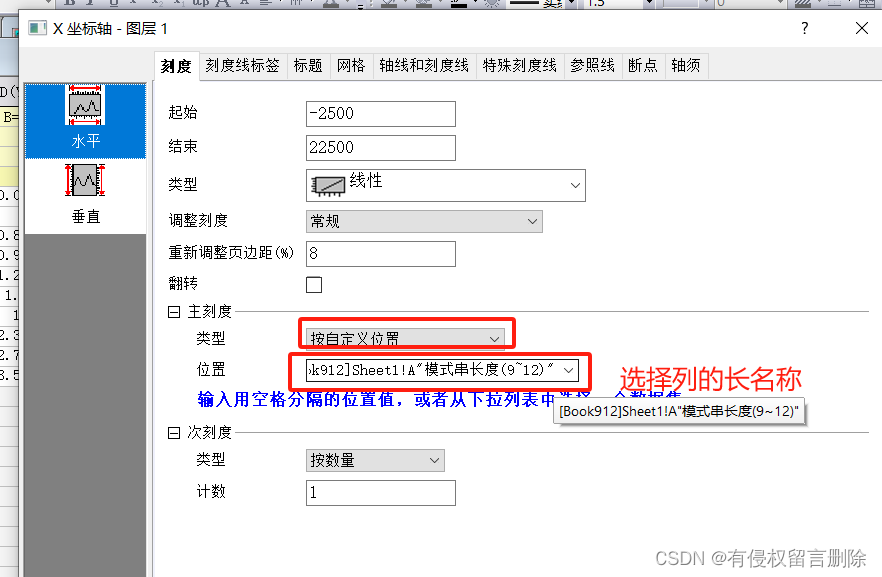
oringin的x轴(按x轴规定值)绘制不规律的横坐标
1.双击x轴 2.选择刻度线标签 3.选择刻度...

ubuntu安装MySQL
一行指令即可! sudo apt install mysql-server常用MySQL服务指令 sudo service mysql status # 查看服务状态 sudo service mysql start # 启动服务 sudo service mysql stop # 停止服务 sudo service mysql restart # 重启服务终端里面进入Mysql 其中-u后面root是我的用户名…...

背包问题学习笔记-多重背包问题
题意描述: 有 N 种物品和一个容量是 V 的背包。第 i 种物品最多有 si 件,每件体积是 vi,价值是 wi。求解将哪些物品装入背包,可使物品体积总和不超过背包容量,且价值总和最大。 输出最大价值。输入格式 第一行两个整数…...

Net相关的各类开源项目
Net相关的各类开源项目 WPFHandyControlLive-ChartsWPFDeveloperswpf-uidesignStylet WebScheduleMasterYiShaAdminBlog.CoreNebula.AdminNewLife.CubeOpenAuth UnityuGUIUnityCsReferenceEpitomeMyUnityFrameWorkKSFrameworkTowerDefense-GameFramework-Demo 通用ClientServer…...
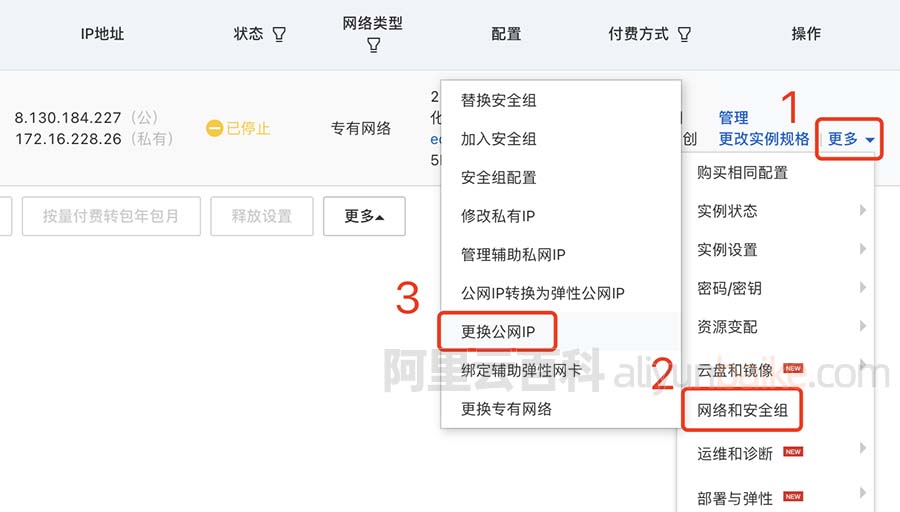
阿里云服务器修改IP地址的两种方法
阿里云服务器可以更换IP地址吗?可以的,创建6小时以内的云服务器ECS可以免费更换三次公网IP地址,超过6小时的云服务器,可以将公网固定IP地址转成弹性EIP,然后通过换绑EIP的方式来更换IP地址。阿里云服务器网分享阿里云服…...

SpringMVC的数据绑定
一、前言 SpringMVC的数据绑定是指将HTTP请求参数绑定到Java对象上。这样可以方便地从请求中获取数据并将其传递给业务逻辑。在SpringMVC中,可以使用RequestParam和ModelAttribute等注解来实现数据绑定。 二、使用RequestParam注解 RequestParam注解用于将请求参…...

1.1.OpenCV技能树--第一单元--OpenCV简介
目录 1.文章内容来源 2.OpenCV简介 3.课后习题代码复现 4.易错点总结与反思 1.文章内容来源 1.题目来源:https://edu.csdn.net/skill/practice/opencv-77f629e4593845b0bf97e74ca8ec95ae/8292?languageopencv&materialId20807 2.资料来源:https://edu.csdn.net/skill…...

transformer不同的包加载模型的结构不一样
AutoModel AutoModelForTokenClassification 结论: AutoModel加载的模型与AutoModelForTokenClassification最后一层是不一样的,从这个模型来看,AutoModelForTokenClassification加载的结果是对的 问题: 为什么AutoModel和Aut…...
【MyBatis-Plus】快速精通Mybatis-plus框架—核心功能
刚才的案例中都是以id为条件的简单CRUD,一些复杂条件的SQL语句就要用到一些更高级的功能了。 1.条件构造器 除了新增以外,修改、删除、查询的SQL语句都需要指定where条件。因此BaseMapper中提供的相关方法除了以id作为where条件以外,还支持…...

C语言:选择+编程(每日一练Day9)
目录 选择题: 题一: 题二: 题三: 题四: 题五: 编程题: 题一:自除数 思路一: 题二:除自身以外数组的乘积 思路二: 本人实力有限可能对…...

蓝桥等考Python组别十三级003
第一部分:选择题 1、Python L13 (15分) 运行下面程序,输出的结果是( )。 t = (1, 2, 2, 1, 4, 3, 2) print(t.count(2)) 1234正确答案:C 2、Python L13 (...

2023年CSP-J真题详解+分析数据(选择题篇)
目录 前言 2023CSP-J江苏卷详解 小结 前言 下面由我来给大家讲解一下CSP-J的选择题部分。 2023CSP-J江苏卷详解 1.答案 A 解析:const在C中是常量的意思,其作用是声明一个变量,值从头至尾不能被修改 2.答案 D 解析:八进制…...
基于三平面映射的地形纹理化【Triplanar Mapping】
你可能遇到过这样的地形:悬崖陡峭的一侧的纹理拉伸得如此之大,以至于看起来不切实际。 也许你有一个程序化生成的世界,你无法对其进行 UV 展开和纹理处理。 推荐:用 NSDT编辑器 快速搭建可编程3D场景 三平面映射(Trip…...
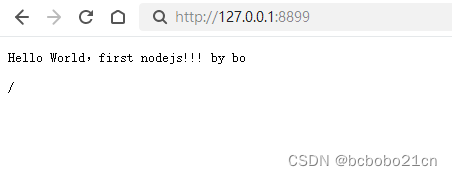
初步了解nodejs语法和web模块
在此, 第一个Node.js实例_js firstnode-CSDN博客 通过node运行一个简单的server.js,实现了一个http服务器; 但是还没有解析server.js的代码,下面看一下; require 指令 在 Node.js 中,使用 require 指令来…...
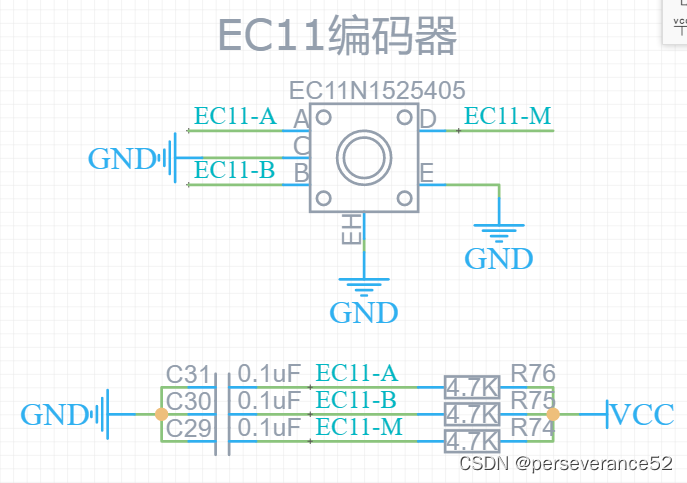
51单片机+EC11编码器实现可调参菜单+OLED屏幕显示
51单片机+EC11编码器实现可调参菜单+OLED屏幕显示 📍相关篇《stc单片机使用外部中断+EC11编码器实现计数功能》 🎈《STC单片机+EC11编码器实现调节PWM输出占空比》 🌼实际操作效果 🍁整个项目实现框架: 📓EC11接线原理图: 📓项目工程简介 📝仅凭借一个EC11编…...
数据结构刷题训练——二叉树篇(一)
📙作者简介: 清水加冰,目前大二在读,正在学习C/C、Python、操作系统、数据库等。 📘相关专栏:C语言初阶、C语言进阶、C语言刷题训练营、数据结构刷题训练营、有感兴趣的可以看一看。 欢迎点赞 👍…...
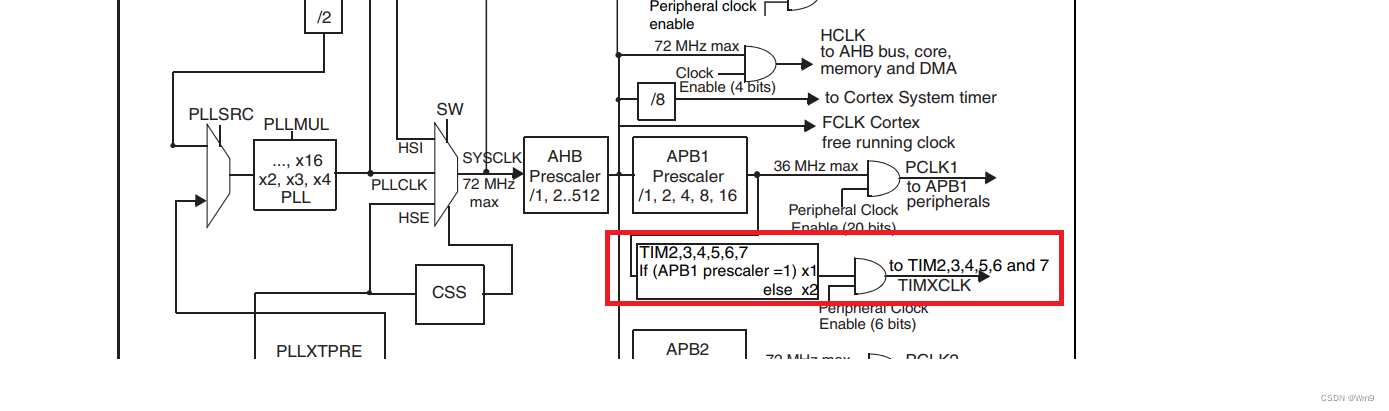
2023版 STM32实战5 基本定时器中断
基本定时器简介与特性 -1-时钟可分频 -2-计数模式只可以选择累加 -3-只可以用来定时(含中断) 查看时钟源 如图定时器7的时钟最大为72MHZ 定时时间的计算 通用定时器的时间计算公式为 Tout ((arr1)(psc1&…...

css3实现页面元素抖动效果
html <div id"shake" class"shape">horizontal shake</div>js(vue3) function shake(elemId) {const elem document.getElementById(elemId)console.log(获取el, elem)if (elem) {elem.classList.add(shake)setTimeou…...

AI写作净化器:识别与消除AI文本痕迹的实用指南
1. 项目概述:为什么我们需要一个“AI写作净化器”? 如果你和我一样,每天都要和AI助手打交道,无论是用它写邮件、生成报告,还是草拟技术文档,那你一定对那种“AI味儿”深有体会。那种感觉就像喝了一杯过度调…...
)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南)
RT-Thread Sensor框架实战:5分钟搞定INA226电流电压功率监测(含I2C避坑指南) 在嵌入式系统开发中,精准监测电流、电压和功率是许多应用场景的核心需求,无论是电池管理系统、智能硬件功耗分析,还是工业设备状…...

初次使用Taotoken平台从注册到完成API调用的全程指引
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初次使用Taotoken平台从注册到完成API调用的全程指引 对于初次接触大模型API的开发者而言,从注册平台到成功发出第一个…...

基于MCP协议与向量数据库构建AI编程助手私有记忆系统
1. 项目概述:为你的AI编程助手打造一个“记忆宫殿”如果你和我一样,重度依赖Cursor这类AI编程助手,那你肯定遇到过这个痛点:昨天刚和它深入讨论过一个复杂的业务逻辑实现,今天想参考一下,却发现在浩如烟海的…...

Word转Markdown踩过的那些坑:Writage插件失效、Pandoc命令报错怎么办?
Word转Markdown实战避坑指南:从工具失效到完美转换的完整方案 每次技术分享会上,总有人问我:"为什么我的Word转Markdown总出问题?"这让我想起自己刚接触文档转换时踩过的无数坑——插件神秘消失、命令行报错、格式全乱套…...

从零构建Telegram天气机器人:Python异步编程与API集成实战
1. 项目概述:一个能聊天的天气机器人 如果你用过Telegram,大概率会见过或者用过一些机器人。它们能帮你查新闻、翻译、管理任务,甚至陪你聊天。今天要聊的这个项目, imkarimkarim/Telegram-Weather-Bot ,就是一个典型…...

TEdit地图编辑器:从新手到专家的泰拉瑞亚世界创作指南
TEdit地图编辑器:从新手到专家的泰拉瑞亚世界创作指南 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you ch…...

3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南
3步打造专属桌面歌词体验:LyricsX macOS歌词神器完全指南 【免费下载链接】Lyrics Swift-based iTunes plug-in to display lyrics on the desktop. 项目地址: https://gitcode.com/gh_mirrors/lyr/Lyrics LyricsX是一款专为macOS用户设计的开源桌面歌词显示…...
)
省下PLC的钱!用海康VC3000工控机GPIO控制LED灯(C# WinForm实战)
海康VC3000工控机GPIO控制实战:低成本替代PLC的完整方案 在工业自动化领域,PLC(可编程逻辑控制器)长期以来都是控制系统的核心组件。但对于简单的指示灯控制、报警系统或小型继电器控制这类基础应用,动辄数千元的PLC模…...

避坑指南:NRF52832低功耗调试,为什么你的电流下不去?
NRF52832低功耗调试实战:从百微安到个位数的终极指南 当你满怀期待地将NRF52832的低功耗模式配置完毕,却发现实际电流依然高达几十甚至上百微安时,那种挫败感我深有体会。这不是简单的数据手册参数未达标问题,而往往是一系列隐蔽陷…...