【RK3588】YOLO V5在瑞芯微板子上部署问题记录汇总
YOLO V5训练模型部署到瑞芯微的板子上面,官方是有给出案例和转过详情的。并且也提供了Python版本的推理代码,以及C语言的代码。
但是,对于转换过程中的细节,哪些需要改?怎么改?如何改,和为什么这样改的问题,并没有给出详细的介绍。于是,本文就是对官方给出部分外的一个补充。这部分都是踩过坑的总结,相信会对你的操作会有较大帮助的。
一、从pytorch的pt到rknn转换
- 第一步: 使用
yolov5提供的export.py函数导出yolov5.onnx模型
python3 export.py --weights yolov5s.pt --img-size 640 --include onnx
- 第二步:使用
onnxsim简化导出的yolov5.onnx模型
onnxsim是一个基于ONNX规范的工具,通过简化ONNX模型和优化ONNX模型,帮助用户减小模型大小、提高模型的推理速度和减少推理过程中的内存开销。
onnxsim的工作原理是将一个ONNX模型简化成最少的节点,并优化这些节点,以最小化推理过程中的开销。
同时,onnxsim还可以处理支持的神经网络层类型,支持多个平台,例如:CPU,GPU, FPGA等。
onnxsim安装和使用:onnx-simplifier
pip3 install onnxsimThen:onnxsim input_onnx_model output_onnx_model
- 第三步:要完全使用rknn提供的部署转换代码,需要根据简化后的onnx模型,选取合适层的输出,以替代以下代码中的
‘378’,‘439’和‘500’,如下图onnx例子中的'onnx::Reshape_446',‘onnx::Reshape_484’,‘onnx::Reshape_522’。(这三个name,可能都是不一样的,是什么就填什么即可)
# Load ONNX model
print('--> Loading model')
ret = rknn.load_onnx(model=ONNX_MODEL, outputs=['onnx::Reshape_446', 'onnx::Reshape_484', 'onnx::Reshape_522'])
if ret != 0:print('Load yolov5 failed!')exit(ret)
print('done')
采用Netron打开的onnx文件,如下:
 疑问:为什么不用最后合并后的输出结果?
疑问:为什么不用最后合并后的输出结果?
因为,最后的形状不固定导致的,有可能5个框,有可能10个框。输出模型到固定大小,后续操作放到后处理,目的是为了加快模型的npu上的推理速度(这里是我的理解,不一定正确,欢迎补充)
在
PyTorch中,神经网络的输出形状通常是根据输入形状来自动计算的,而在ONNX中,输出形状需要在转换时进行显式指定,这是由于ONNX的静态图执行模型与PyTorch的动态图执行模型不同所致。
当你将PyTorch模型转换为ONNX模型时,你需要为ONNX模型中的每个输出定义固定的形状,以便在模型执行时为其分配正确的内存空间。如果输出形状不固定,那么ONNX运行时就需要在运行时动态调整输出形状,这将使得模型在部署时的性能受到影响。
因此,在转换PyTorch模型为ONNX模型时,你需要手动指定每个输出的固定形状,以便在执行时能够顺利运行。
Yolo v5的输出格式一般为a × b × c × 85的形式,其中:
a*b*c表示框的数目85则涵盖框的位置信息(xc,yc,w,h)、前景的置信度Pc和80个类别的预测条件概率c1,...,c80。(4+1+80,无背景类)
如果是你自己的模型,可能是只有3个目标类别,那么最后就是4+1+3=8,这个值记得在onnx模型中查看到。
二、需要注意事项
2.1、 设定anchor值
anchor的设定,在训练yolo v5模型时候,是可以设定自动适应,采用聚类的方式,通过标注的目标框的大小,给出anchor的值。在train.py中,noaotoanchor的默认为False,如果设定为True,则会使用默认的anchor设定。
所以,如果经过autoanchor,给出了新的anchor设定,那么在推理和转完rknn后的设定,都需要与之相匹配的anchor,这个很重要。
为什么官方和很多博客,都没有注意到这个问题呢?因为大多数情况下,aotoanchor并没有发挥作用。都是使用了默认的,导致很多人即便没有注意到这个问题,最后的结果也不差。
但是,如果是不一样的,结果就会比较差,这个值就需要对应的做修改了。
2.1.1、训练阶段记录
如果在训练阶段,你已经关注到autoAnchor的输出结果,可以在这里直接进行记录,在terminal打印的内容,大致如下:
AutoAnchor: 3.60 anchors/target, 0.974 Best Possible Recall (BPR). Anchors are a poor fit to dataset ⚠, attempting to improve...
AutoAnchor: WARNING ⚠ Extremely small objects found: 764 of 27545 labels are <3 pixels in size
AutoAnchor: Running kmeans for 9 anchors on 27522 points...
AutoAnchor: Evolving anchors with Genetic Algorithm: fitness = 0.8052: 100%|██████████| 1000/1000 00:10
AutoAnchor: thr=0.25: 0.9996 best possible recall, 5.11 anchors past thr
AutoAnchor: n=9, img_size=640, metric_all=0.358/0.805-mean/best, past_thr=0.532-mean: 5,5, 7,8, 11,11, 17,17, 28,28, 41,37, 56,56, 79,82, 143,140
2.1.2、pt文件查询记录
查询autoAnchor记录到.pt文件内的anchor设定,如下:
import torch
import sys
sys.path.append("path/yolov5-master")
weights = 'best.pt'
model = torch.load(str(weights[0] if isinstance(weights, list) else weights), map_location='cpu')
model1 = model['ema' if model.get('ema') else 'model']
model2 = model1.float().fuse().model.state_dict()for k,v in model2.items():if 'anchor' in k:# print(k)# print(v)print(v.numpy().flatten().tolist())
打印结果:
Fusing layers...
[0.54345703125, 0.58251953125, 0.8525390625, 0.88818359375, 1.353515625, 1.318359375, 1.0859375, 1.0380859375, 1.75390625, 1.705078125, 2.38671875, 2.462890625, 1.7421875, 1.6787109375, 2.578125, 2.458984375, 3.904296875, 3.75]
[4.34765625, 4.66015625, 6.8203125, 7.10546875, 10.828125, 10.546875, 17.375, 16.609375, 28.0625, 27.28125, 38.1875, 39.40625, 55.75, 53.71875, 82.5, 78.6875, 124.9375, 120.0]
YOLOv5m summary: 308 layers, 21037791 parameters, 0 gradients
第二行是真的,需要取整。第一行…
经过我的发现,如果你打印的anchor就一行,那么可能是默认的anchor(默认使用COCO数据集的anchor),就是good fit to dataset,也就是默认的:
[[10, 13], [16, 30], [33, 23],
[30, 61], [62, 45],[59, 119],
[116, 90], [156, 198], [373, 326]]
2.2、rk3588推理性能
yolo v5m 量化前性能:
推理性能:Performance
Total Time(us): 194162
FPS: 5.15占用内存:Memory Profile Info Dump NPU model memory detail(bytes):Total Weight Memory: 39.83 MiBTotal Internal Tensor Memory: 19.50 MiBTotal Memory: 59.33 MiB
量化后性能
推理性能:Performance
Total Time(us): 137508
FPS: 7.27占用内存:Memory Profile Info Dump
NPU model memory detail(bytes):Total Weight Memory: 20.03 MiBTotal Internal Tensor Memory: 8.75 MiBTotal Memory: 28.78 MiB
总的来说:
- 模型时间效率上,量化后能降低
30%,194ms到137ms; - 占用内存上,量化后减少
50%,59Mib到29Mib;
三、C/C++ API部署
-
目标检测 YOLOv5 - 基于 瑞芯微 Rockchip RKNN C API 实现 ----------- github代码
-
yolov8 瑞芯微 RKNN 的 C++部署------------- github代码
上述两个参考链接,基本囊括了一下几个部分:
rknn模型转换Python rknn推理c/c++ rknn推理(YOLO v5部分是瑞芯微官方开放的代码)
如果你也是参考瑞芯微官方的C API代码,那么替换上你的模型后,有几个地方需要修改:
- 输入图像大小要改
anchor尺寸要改
const int anchor0[6] = {4, 5, 7, 7, 11, 11};
const int anchor1[6] = {17, 17, 28, 27, 38, 39};
const int anchor2[6] = {56, 54, 83, 79, 125, 120};- 前景
box阈值修改
const float box_conf_threswin = 0.25; nms阈值修改
const float nms_threswin = 0.1;- 类别置信度重新调整
objProbs.push_back(current_prob*box_confidence); - 针对各个类,采用不同的阈值(待补充,这部分瑞芯微未采用这种二次过滤方式)
尤其是anchor这里,如果设定的不对,那么输出的结果就会非常的奇怪。如果是对的,那么差异性相对会小很多(和本地pt测试结果对比)。
四、总结
本文是对YOLO V5模型部署到瑞芯微板子上遇到的问题汇总。当然可能还会存在其他的更多问题,但是暂时还没有遇到,所以后面如果还会遇到什么问题,还会补充到这里。
如果你也正在做这块,并且遇到了问题,可以评论交流。目前还发现就是转模型后的评估问题,这个后面也会按照官方教程进行测试,这是下一篇的预告,期待。
相关文章:
【RK3588】YOLO V5在瑞芯微板子上部署问题记录汇总
YOLO V5训练模型部署到瑞芯微的板子上面,官方是有给出案例和转过详情的。并且也提供了Python版本的推理代码,以及C语言的代码。 但是,对于转换过程中的细节,哪些需要改?怎么改?如何改,和为什么…...

别人做的百度百科词条信息不全,如何更正自己的百度百科词条
很多人自己的百度百科词条是别人上传上去的,自己压根不知道,而且里面的信息内容要么不全,要么是有错漏的,但自己想要更正自己的百度百科词条又不知道如何更正,下面洛希爱做百科网和大家介绍一些百科经验知识。 首先百…...
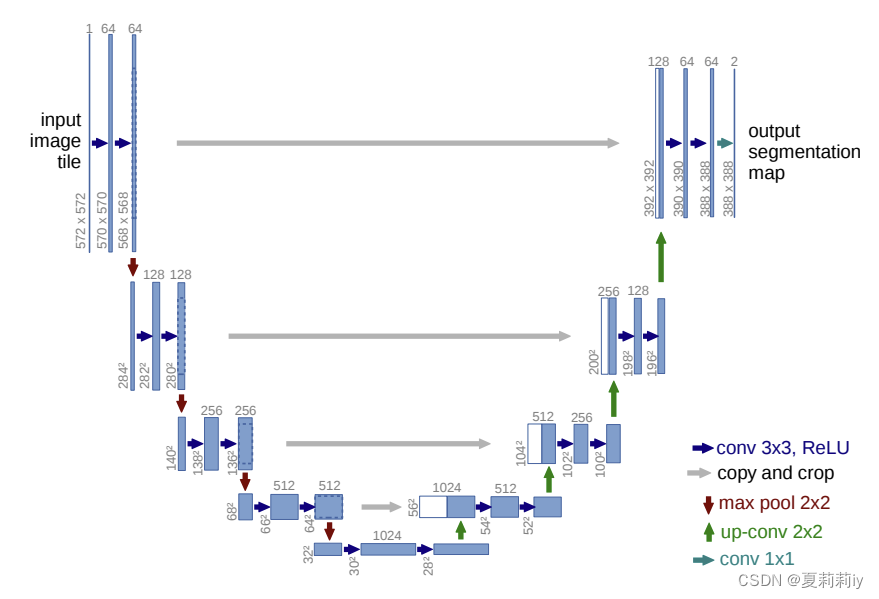
[论文精读]U-Net: Convolutional Networks for BiomedicalImage Segmentation
论文原文:U-Net: Convolutional Networks for Biomedical Image Segmentation (arxiv.org) 英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔…...
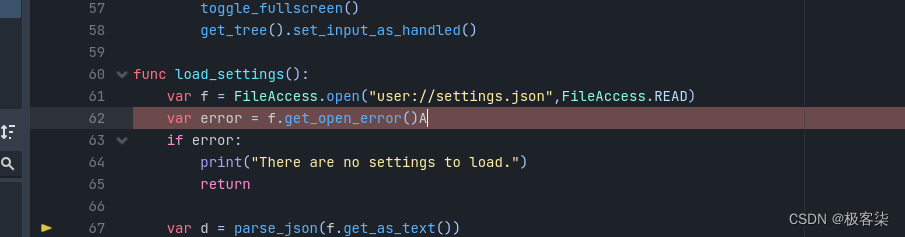
Godot Identifier “File“ not declared in the current scope.
解决方案: f FileAccess.open(savedir, FileAccess.READ)...

Java ORM Bee,多表关联更新
Bee V2.1.8 增加支持多表的update, insert, delete; 使用FK注解进行关联. 如果子实体没有用上FK声明的字段(即FK的字段没有值),则不执行,防止更新到多余记录 外键有一个没有设置时,跳过。 更多实例,请查看样例工程:https://gitee.com/automvc/bee-exam 或:h…...

Java 读取excel文件
导入: 先导入依赖: <!-- 文件上传 --> <dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpmime</artifactId><version>4.5.7</version> </dependency> <!-- JSON -…...
:数据分析 | 数据挖掘 | 十大算法之一)
PageRank(上):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据开发、数据分析等。 🐴欢迎小伙伴们点赞👍🏻、收藏⭐️、…...

吃鸡达人专享!提高战斗力,分享干货,查询装备皮肤,保护账号安全!
大家好!作为专业吃鸡行家,我将为您带来一些热门话题和实用内容,帮助您提升游戏战斗力,分享顶级游戏作战干货,并提供便捷的作图工具和查询服务。让我们一起享受吃鸡的乐趣! 首先,我要推荐一款绝地…...
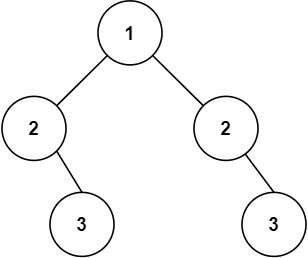
力扣第101题 c++ 递归 迭代 双方法 +注释 ~
题目 101. 对称二叉树 简单 给你一个二叉树的根节点 root , 检查它是否轴对称。 示例 1: 输入:root [1,2,2,3,4,4,3] 输出:true示例 2: 输入:root [1,2,2,null,3,null,3] 输出:false提示&a…...
Go:实现SMTP邮件发送订阅功能(包含163邮箱、163企业邮箱、谷歌gmail邮箱)
需求很简单,就是用户输入自己的邮箱后,使用官方邮箱给用户发送替邮件模版 目录 前置邮件模版邮箱开启SMTP服务163邮箱163企业邮箱谷歌gmail邮箱腾讯企业邮箱-失败其他邮箱-未操作 邮件发送核心代码config.yaml配置读取邮件相关配置发送邮件 附录 前置 邮…...
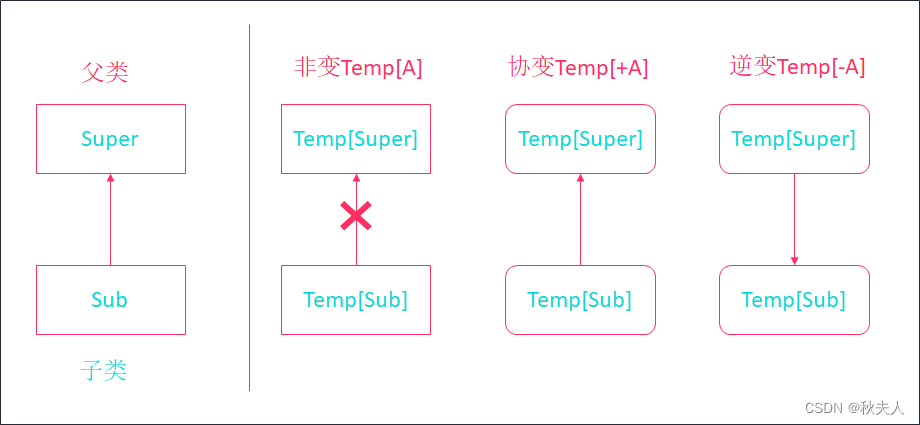
Scala第十六章节
Scala第十六章节 scala总目录 文档资料下载 章节目标 掌握泛型方法, 类, 特质的用法了解泛型上下界相关内容了解协变, 逆变, 非变的用法掌握列表去重排序案例 1. 泛型 泛型的意思是泛指某种具体的数据类型, 在Scala中, 泛型用[数据类型]表示. 在实际开发中, 泛型一般是结合…...

C语言 实现 链 显示 效果 查找 修改 删除
显示所有信息 2023年10月1日的描述:今天放假 2023年10月2日的描述:今天有体育 2023年10月3日的描述:今天有数学 2023年10月4日的描述:今天有语文 2023年10月5日的描述:今天有政治 2023年10月6日的描述:今天交学费 2023年10月7日的描述:今天周末 2023年10月8日的描述:今天给家里…...

CSS基础语法第一天
目录 一、CSS 简介 1.1 CSS简介 1.2 CSS语法 1.3 CSS 语法规范 1.4 CSS 代码风格 1.4.1 样式格式书写 1.4.2 样式大小写 1.4.3 空格规范 二、CSS 基础选择器 2.1选择器分类 2.2标签选择器 2.3 类选择器 2.4 id选择器 2.5 通配符选择器 三、盒子尺寸和背景色 …...

Leetcode 1492.n的第k个因子
给你两个正整数 n 和 k 。 如果正整数 i 满足 n % i 0 ,那么我们就说正整数 i 是整数 n 的因子。 考虑整数 n 的所有因子,将它们 升序排列 。请你返回第 k 个因子。如果 n 的因子数少于 k ,请你返回 -1 。 示例 1: 输入&#…...
十一工具箱流量主小程序源码
无授权,去过滤机制版本 看到网上发布的都是要授权的 朋友叫我把他去授权,能用就行 就把过滤去了 这样就不用授权 可以免费使用 白嫖党专属 一切接口可用,无需担心不能用 授权者不关站一直可以用 源码下载:https://download.csdn.…...
10.5汇编语言整理
【汇编语言相关语法】 1.汇编语言的组成部分 1.伪操作:不参与程序的执行,但是用于告诉编译器程序该怎么编译 .text .global .end .if .else .endif .data 2.汇编指令 编译器将一条汇编指令编译成一条机器码,在内存里一条指令占4字节内存&…...

Connect to 127.0.0.1:1080 [/127.0.0.1] failed: Connection refused: connect
报错信息 A problem occurred configuring root project CourseSelection. > Could not resolve all artifacts for configuration :classpath.> Could not resolve com.android.tools.build:gradle:3.6.1.Required by:project :> Could not resolve com.android.tool…...
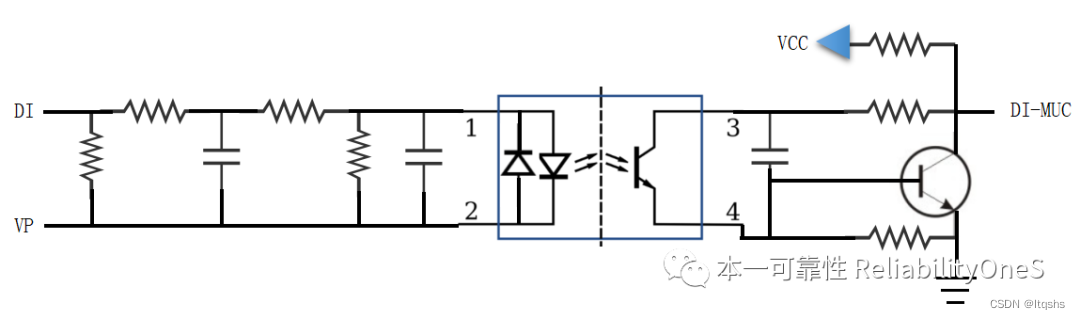
驱动器类产品的接口EMC拓扑方案
驱动器类产品的接口EMC拓扑方案 1. 概述 本文以高压伺服驱动器和变频器类产品为例,对常用端口滤波拓扑方案进行总结,后续根据不同的应用场景可进行适当删减,希望对大家有帮助。 2. 驱动器验证等级 本文推荐拓扑的实验结果,满足…...
2023最新ICP备案查询系统源码 附教程 Thinkphp框架
2023最新ICP备案查询系统源码 附教程 thinkphp框架 本系统支持网址备案,小程序备案,APP备案查询,快应用备案查询 优势: 响应速度快,没有延迟,没有缓存,数据与官方同步 源码下载:ht…...

大数据Doris(六):编译 Doris遇到的问题
文章目录 编译 Doris遇到的问题 一、js_generator.cc:(.text+0xfc3c): undefined reference to `well_known_types_js’...
管理)
表空间(Tablespace)管理
1.1、表空间类型类型用途说明永久表空间存储用户数据SYSTEM, SYSAUX, USERS, 自定义UNDO表空间事务回滚和读一致性自动管理,12c支持多UNDO临时表空间排序、哈希等临时操作TEMP,不产生redo大文件表空间单个数据文件可达128TBBigfile Tablespace加密表空间…...

Source Han Serif CN:7款免费开源字体如何重塑你的中文排版体验
Source Han Serif CN:7款免费开源字体如何重塑你的中文排版体验 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在数字内容爆炸的时代,选择一款优秀的中文字体往…...

IDEA里配置Druid连接池,别再手动导Jar包了!试试Maven/Gradle一键搞定
IDEA中配置Druid连接池:Maven/Gradle现代化依赖管理实战 在Java开发领域,依赖管理一直是项目构建的重要环节。记得刚入行时,我也曾手动下载各种Jar包,然后在IDE中逐个添加依赖。直到有一天,项目引用的Jar包版本冲突导致…...
实时监测设备健康状态,结合TSN网络实现毫秒级数据传输)
AI驱动的工业预测性维护技术实践:AI驱动的预测性维护系统通过多传感器融合(振动、温度、电流等)实时监测设备健康状态,结合TSN网络实现毫秒级数据传输
标签:预测性维护 PHM 工业AI 振动分析 TSN 设备管理 引言:设备算命先生的时代来了 “老张,你这台风机轴承怕是撑不过两周了。” 如果有个"设备算命先生"能掐指一算就说出这句话,工厂的设备经理们大概会把他供起来。但在2024年,这个"算命先生"真的出…...
)
NotebookLM生物学研究辅助落地手册(实验室已验证的7个不可公开的Prompt工程模板)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM生物学研究辅助落地手册(实验室已验证的7个不可公开的Prompt工程模板) NotebookLM 作为 Google 推出的文档感知型 AI 助手,在分子生物学、结构生物学与高通…...
增强代码的层级结构注意事项)
不使用void HAL_TIM_Encoder_MspInit(TIM_HandleTypeDef* tim_encoderHandle)增强代码的层级结构注意事项
这是正常用cube Max生成的代码,这里以设置编码器为例。 GPIO初始化函数放在HAL_TIM_Encoder_MspInit这个回调函数中。代码正常运行/* TIM3 init function */ void MX_TIM3_Init(void) {TIM_Encoder_InitTypeDef sConfig {0};TIM_MasterConfigTypeDef sMasterConfig…...

网络安全新态势与应对策略
网络安全新态势与应对策略 在数字化浪潮席卷全球的今天,网络空间已成为国家竞争的新战场、经济发展的新引擎和社会生活的新空间。然而,伴随技术飞速发展的,是日益严峻和复杂的网络安全挑战。传统的边界防御模式在AI驱动的自动化攻击、无孔不…...

CPU Cache初始化:从硬件复位到软件使能的底层原理与工程实践
1. 项目概述:从开机到高速缓存就绪当按下电脑的电源键,屏幕上开始跑起一行行代码时,我们看到的通常是BIOS自检、操作系统加载的宏大叙事。但在这背后,有一个对性能影响巨大却又极其低调的“幕后英雄”正在悄然启动,它就…...

手把手教你用YOLOv5训练VisDrone2019数据集:搞定无人机航拍小目标检测
无人机视角下的目标检测实战:YOLOv5与VisDrone2019数据集深度适配指南 无人机航拍图像的目标检测一直是计算机视觉领域的难点与热点。VisDrone2019作为当前最权威的无人机视角数据集之一,包含了丰富的场景变化和极具挑战性的小目标检测任务。本文将带您从…...

基于语义检索的LLM工具发现框架:从原理到工程实践
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想把手头的几个大语言模型(LLM)能力整合到自己的工具链里,发现一个挺头疼的问题:模型本身很强大,但让它去精准调用外部工具(比如查数据库、发…...