【论文笔记】SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
原文链接:https://arxiv.org/abs/2307.02270
1. 引言
目前的从单目相机生成伪传感器表达的方法依赖预训练的深度估计网络。这些方法需要深度标签来训练深度估计网络,且伪立体方法通过图像正向变形合成立体图像,会导致遮挡区域的像素伪影、扭曲、孔洞。此外,特征级别的伪立体图生成很难直接应用,且适应度有限。
那么如何绕过深度估计,在图像层面设计透视图生成器呢?和GAN相比,扩散模型有更简单的结构、更少的超参数和更简单的训练步骤,但目前没有关于3D目标检测伪视图生成的研究。
本文设计单一视图扩散模型(SVDM)进行伪视图合成。SVDM假设已知左视图图像,将高斯噪声替换为左图像素,并逐渐扩散右图像素到全图。由于立体图像细微的视差,仅使用很少的步骤就能产生不错的结果。SVDM不使用深度真值,且能端到端训练。
3. 方法
3.1 准备知识
3.1.a 立体3D检测器
可分为3类:只需要立体图像训练的模型(如Stereo R-CNN)、需要额外深度真值训练的模型(YOLOStereo3D)和基于体积网格的模型(如LIGA-Stereo)。
3.1.b 去噪扩散概率模型(DDPM)
详见扩散模型(Diffusion Model)简介。DDPM的目标是最优化置信下限(ELBO)。多数条件扩散模型保留了扩散过程,并将条件 y y y插入训练目标中: E t , x 0 , ϵ [ ∥ ϵ − ϵ θ ( x t , y , t ) ∥ 2 2 ] \mathbb{E}_{t,x_0,\epsilon}[\|\epsilon-\epsilon_\theta(x_t,y,t)\|_2^2] Et,x0,ϵ[∥ϵ−ϵθ(xt,y,t)∥22] 但由于 p ( x t ∣ y ) p(x_t|y) p(xt∣y)没有显式地出现在训练目标中,要保证扩散模型能学到期望的条件分布是很困难的。
3.2 单一视图扩散模型
本模型将新视图生成任务视为基于扩散模型的、图像到图像(I2I)的转换任务。本文的方法如下图所示,包含3种扩散模型方法:高斯噪声操作器、视图图像操作器和一步生成。
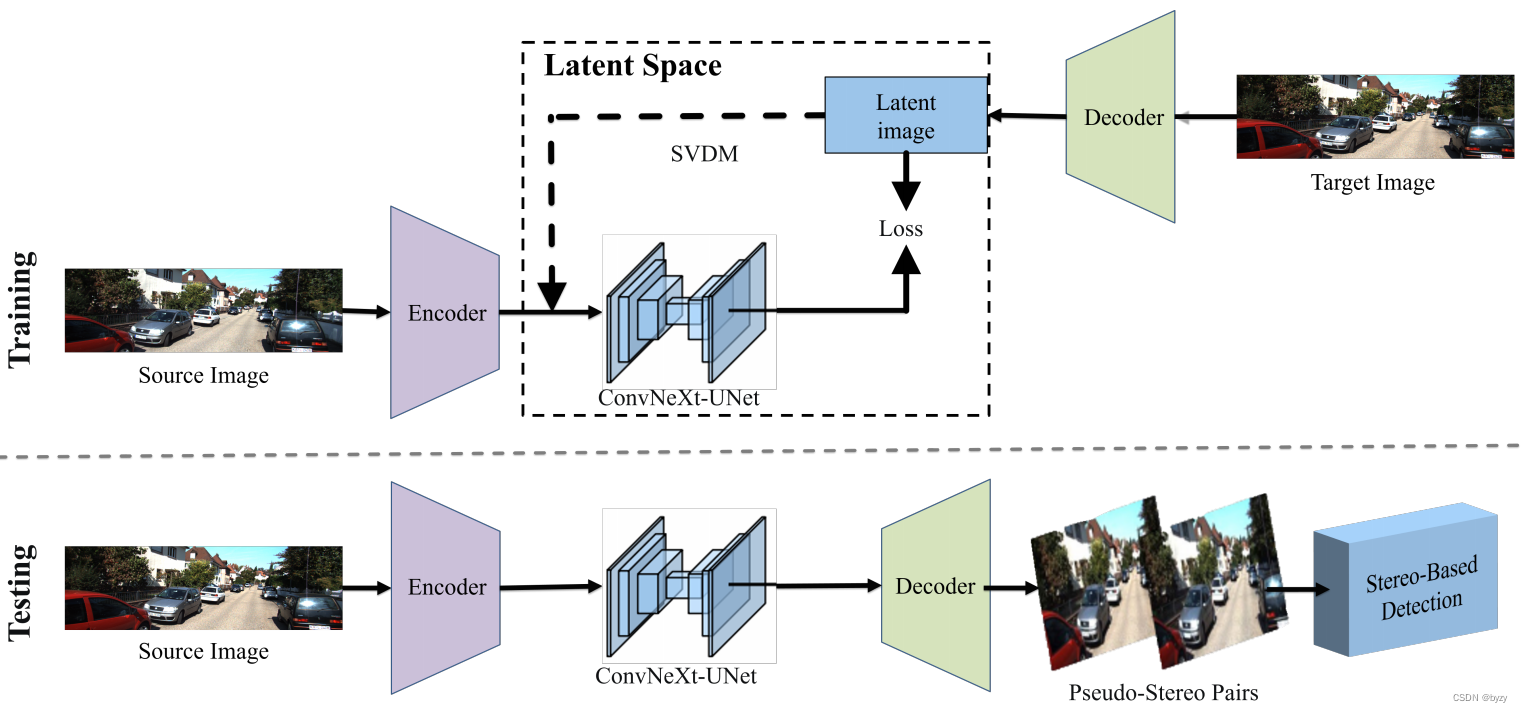
3.2.a 高斯噪声操作器
为了学习两个视图域之间的变换,根据BBDM,本文使用布朗桥扩散过程而非DDPM方法。
布朗桥过程是连续时间随机模型,其中扩散过程中的概率分布是以起始状态和终止状态为条件的。记起始状态为 x 0 ∼ q d a t a ( x 0 ) x_0\sim q_{data}(x_0) x0∼qdata(x0),终止状态为 x T x_T xT,则布朗桥扩散过程的状态分布为 q B B ( x t ∣ x 0 , y ) = N ( x t ; ( 1 − m t ) x 0 + m t y , δ t I ) q_{BB}(x_t|x_0,y)=\mathcal{N}(x_t;(1-m_t)x_0+m_ty,\delta_tI) qBB(xt∣x0,y)=N(xt;(1−mt)x0+mty,δtI)其中 m t = t / T m_t=t/T mt=t/T, δ t \delta_t δt为方差。为避免方差过大导致无法训练,使用下列方差调度: δ t = s [ 1 − ( ( 1 − m t ) 2 + m t 2 ) ] = 2 s ( m t − m t 2 ) \delta_t=s[1-((1-m_t)^2+m_t^2)]=2s(m_t-m_t^2) δt=s[1−((1−mt)2+mt2)]=2s(mt−mt2)其中 s s s控制样本的多样性,默认为1。
正向过程如下:当 t = 0 t=0 t=0时, m t = 0 m_t=0 mt=0,此时均值为 x 0 x_0 x0,方差为0;当 t = T t=T t=T时, m t = 1 m_t=1 mt=1,此时均值为 y y y,方差为0。中间过程按下式计算: x t = ( 1 − m t ) x 0 + m t y + δ t ϵ x_t=(1-m_t)x_0+m_ty+\sqrt{\delta_t}\epsilon xt=(1−mt)x0+mty+δtϵ其中 ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I) ϵ∼N(0,I)。用 t − 1 t-1 t−1替换上式中的 t t t,两式相减得到转移概率: q B B ( x t ∣ x t − 1 , y ) = N ( x t ; 1 − m t 1 − m t − 1 x t − 1 + ( m t − 1 − m t 1 − m t − 1 m t − 1 ) y , δ t ∣ t − 1 I ) q_{BB}(x_t|x_{t-1},y)=\mathcal{N}(x_t;\frac{1-m_t}{1-m_{t-1}}x_{t-1}+(m_t-\frac{1-m_t}{1-m_{t-1}}m_{t-1})y,\delta_{t|t-1}I) qBB(xt∣xt−1,y)=N(xt;1−mt−11−mtxt−1+(mt−1−mt−11−mtmt−1)y,δt∣t−1I)其中 δ t ∣ t − 1 = δ t − δ t − 1 ( 1 − m t ) 2 ( 1 − m t − 1 ) 2 \delta_{t|t-1}=\delta_t-\delta_{t-1}\frac{(1-m_t)^2}{(1-m_{t-1})^2} δt∣t−1=δt−δt−1(1−mt−1)2(1−mt)2 逆过程从已知视图出发,逐步得到目标视图的分布。即基于 x t x_t xt预测 x t − 1 x_{t-1} xt−1: p θ ( x t − 1 ∣ x t , y ) = N ( x t − 1 ; μ θ ( x t , t ) , δ ~ t I ) p_\theta(x_{t-1}|x_t,y)=\mathcal{N}(x_{t-1};\mu_\theta(x_t,t),\tilde{\delta}_tI) pθ(xt−1∣xt,y)=N(xt−1;μθ(xt,t),δ~tI)其中 μ θ ( x t , t ) \mu_\theta(x_t,t) μθ(xt,t)是预测噪声的均值,由神经网络基于极大似然准则估计。 δ ~ t \tilde{\delta}_t δ~t为每步噪声的方差,解析形式为 δ ~ t = δ t ∣ t − 1 δ t − 1 δ t \tilde{\delta}_t=\frac{\delta_{t|t-1}\delta_{t-1}}{\delta_t} δ~t=δtδt∣t−1δt−1。
完整的训练和推断过程如下:
BBDM的训练算法
- 采样数据对 x 0 ∼ q ( x 0 ) , y ∼ q ( y ) x_0\sim q(x_0),y\sim q(y) x0∼q(x0),y∼q(y);
- 均匀采样时间 t ∈ { 1 , 2 , ⋯ , T } t\in\{1,2,\cdots,T\} t∈{1,2,⋯,T};
- 采样高斯噪声 ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I) ϵ∼N(0,I);
- 正向扩散: x t = ( 1 − m t ) x 0 + m t y + δ t ϵ x_t=(1-m_t)x_0+m_ty+\sqrt{\delta_t}\epsilon xt=(1−mt)x0+mty+δtϵ;
- 计算 ∥ m t ( y − x 0 ) + δ t ϵ − ϵ θ ( x t , t ) ∥ 2 \|m_t(y-x_0)+\sqrt{\delta_t}\epsilon-\epsilon_\theta(x_t,t)\|^2 ∥mt(y−x0)+δtϵ−ϵθ(xt,t)∥2的梯度。
BBDM的采样算法:
- 采样条件输入 x T = y ∼ q ( y ) x_T=y\sim q(y) xT=y∼q(y);
- 从 t = T t=T t=T开始,进行下面的过程直到 t = 1 t=1 t=1:
采样 z ∼ N ( 0 , I ) z\sim\mathcal{N}(0,I) z∼N(0,I)
计算 x t − 1 = c x t x t + c y t y − c ϵ t ϵ θ ( x t , t ) + δ ~ t z x_{t-1}=c_{xt}x_t+c_{yt}y-c_{\epsilon t}\epsilon_\theta(x_t,t)+\sqrt{\tilde{\delta}_t}z xt−1=cxtxt+cyty−cϵtϵθ(xt,t)+δ~tz;- t = 1 t=1 t=1时,计算 x 0 = c x 1 x 1 + c y 1 y − c ϵ 1 ϵ θ ( x 1 , 1 ) x_0=c_{x1}x_1+c_{y1}y-c_{\epsilon1}\epsilon_\theta(x_1,1) x0=cx1x1+cy1y−cϵ1ϵθ(x1,1)。
3.2.b 视图图像操作器
布朗桥扩散模型引入了额外的超参数。本文提出基于视图图像操作器的方法,将目标图像视为特殊噪声,迭代地将目标图像转换为源图像。给定初始状态 x 0 x_0 x0和目标状态 y y y,中间状态 x t x_t xt可写为: x t = α t x 0 + 1 − α t y x_t=\sqrt{\alpha_t}x_0+\sqrt{1-\alpha_t}y xt=αtx0+1−αty与常规的添加噪声过程不同,此处添加的为逐步增加权重的新视图图像。采样过程如下所示:
- 输入源图像 x T x_T xT;
- 从 t = T t=T t=T开始,进行下面的过程直到 t = 0 t=0 t=0:
x 0 ≤ f ( x t , t ) x_0\leq f(x_t,t) x0≤f(xt,t)
x t − 1 = x t − D ( x 0 , t ) + D ( x 0 , t − 1 ) x_{t-1}=x_t-D(x_0,t)+D(x_0,t-1) xt−1=xt−D(x0,t)+D(x0,t−1)(关于该方法的采样算法,原文中用到的符号应该是有问题且欠缺解释的,这里仅能猜测原文的 s s s以及 i i i实际均应为 t t t)
α t \alpha_t αt的调度如下: α t = f ( t ) f ( 0 ) , f ( t ) = cos ( t / T + s 1 + s ⋅ π 2 ) 2 \alpha_t=\frac{f(t)}{f(0)},f(t)=\cos(\frac{t/T+s}{1+s}\cdot\frac{\pi}{2})^2 αt=f(0)f(t),f(t)=cos(1+st/T+s⋅2π)2与线性调度相比,余弦调度添加目标视图更慢。
3.2.c 加速采样和一步生成
由于扩散概率模型通常会需要大量步数采样,为加速推断过程,本文提出两种方法:一是添加高阶求解器引导DPM采样,二是引入一步生成方法。
加速采样:与DDIM的基本思想相似,BBDM也可以在使用非马尔科夫过程的同时,保持和马尔科夫推断过程有相同的边沿分布。
给定 { 1 , 2 , ⋯ , T } \{1,2,\cdots,T\} {1,2,⋯,T}的长为 S S S的子序列 { T 1 , T 2 , ⋯ , T S } \{T_1,T_2,\cdots,T_S\} {T1,T2,⋯,TS},推断过程可由隐变量的子集 { x T 1 , x T 2 , ⋯ , x T S } \{x_{T_1},x_{T_2},\cdots,x_{T_S}\} {xT1,xT2,⋯,xTS}定义: q B B ( x T s − 1 ∣ x T s , x 0 , y ) = N ( ( 1 − m T s − 1 ) x 0 + m T s − 1 + δ T s − 1 − σ T s 2 δ T s ( x T s − ( 1 − m T s ) x 0 − m T s y ) , σ T s 2 I ) q_{BB}(x_{T_{s-1}}|x_{T_s},x_0,y)=\mathcal{N}((1-m_{T_{s-1}})x_0+m_{T_{s-1}}+\frac{\sqrt{\delta_{T_{s-1}}-\sigma_{T_s}^2}}{\sqrt{\delta_{T_s}}}(x_{T_s}-(1-m_{T_s})x_0-m_{T_s}y),\sigma_{T_s}^2I) qBB(xTs−1∣xTs,x0,y)=N((1−mTs−1)x0+mTs−1+δTsδTs−1−σTs2(xTs−(1−mTs)x0−mTsy),σTs2I)
一步生成:目标是不牺牲迭代细化优势的情况下进行一步生成。这些优势包括能平衡计算和质量,以及零样本数据编辑的能力。该方法建立在连续时间扩散模型概率流常微分方程(ODE)的基础上,其轨迹平滑地从数据分布转变为可处理的噪声分布。使用一个模型学习将任意步骤上的点映射到轨迹的起点,这样模型有自我一致性(即同一条轨迹上的点会被映射到相同的起点)。
一致性模型能在一次网络评估中将随机噪声向量(ODE轨迹的终点, x T x_T xT)转变为数据样本(ODE轨迹的起点, x 0 x_0 x0)。通过多步连接一致性模型的输出,能用更多的计算提高样本质量并进行零样本数据编辑,从而保持迭代细化的优势。
3.3 网络结构
根据隐式扩散模型(LDM),SVDM在隐空间而非原始像素空间内进行生成学习以减小计算。
LDM使用预训练的VAE编码器 E E E将图像 v ∈ R 3 × H × W v\in\mathbb{R}^{3\times H\times W} v∈R3×H×W编码为隐式嵌入 z = E ( v ) ∈ R c × h × w z=E(v)\in\mathbb{R}^{c\times h\times w} z=E(v)∈Rc×h×w。其前向过程逐渐向 z z z加入噪声,逆过程去噪以预测 z z z。最后,LDM使用预训练的VAE解码器 D D D解码 z z z,得到高分辨率图像 v = D ( z ) v=D(z) v=D(z)。VAE的编码器和解码器在训练和推断时均保持固定,而由于 h < H , w < W h<H,w<W h<H,w<W,在低分辨率隐空间内扩散比在像素空间扩散更高效。本文的方法类似,给定从域 A A A中采样的图像 I A I_A IA,首先提取隐特征 L A L_A LA,然后进行SVDM过程,将 L A L_A LA映射到相应的、域 B B B内的隐式表达 L A → B L_{A\rightarrow B} LA→B。最后使用预训练的VQGAN的解码器生成图像 I A → B I_{A\rightarrow B} IA→B。
SVDM模型沿通道维度连接两张图像,并使用标准的U-Net结构和Conv-NeXt残差块进行上下采样,以达到大感受野获取上下文信息。此外,还在不同分辨率下引入注意力块,因为全局交互能大幅提高重建质量。
3.4 损失函数
损失函数包含3项:RGB L1损失,RGB SSIM损失与感知损失。
3.4.a RGB L1损失与SSIM损失
L1损失与SSIM损失如下: L L 1 = 1 3 H W ∑ ∣ I ^ t g t − I t g t ∣ L s s i m = 1 − S S I M ( I ^ t g t , I t g t ) \mathcal{L}_{L1}=\frac{1}{3HW}\sum|\hat{I}_{tgt}-I_{tgt}|\\\mathcal{L}_{ssim}=1-SSIM(\hat{I}_{tgt},I_{tgt}) LL1=3HW1∑∣I^tgt−Itgt∣Lssim=1−SSIM(I^tgt,Itgt)其中 I ^ t g t \hat{I}_{tgt} I^tgt与 I t g t I_{tgt} Itgt分别为像素通道的预测值和真实值。
3.4.b 感知损失
基于过去的工作,感知损失通过强制局部真实性确保重建约束于图像流形,且避免了仅依赖RGB损失引入的模糊。 L l a t e n t = 1 2 ∑ j = 1 J [ ( u j 2 + σ j 2 ) − 1 − log σ j 2 ] \mathcal{L}_{latent}=\frac{1}{2}\sum_{j=1}^J[(u_j^2+\sigma_j^2)-1-\log\sigma_j^2] Llatent=21j=1∑J[(uj2+σj2)−1−logσj2]
4. 实验
4.4 基于单一图像的视图合成结果
定量结果:本文的方法在PSNR指标上能超过SotA,但SSIM和LPIPS指标略低于SotA。
定性结果:可视化表明,本文的方法能生成更真实的图像,有更小的扭曲和伪影。这表明本文的方法有能力建模复杂场景的几何和纹理。
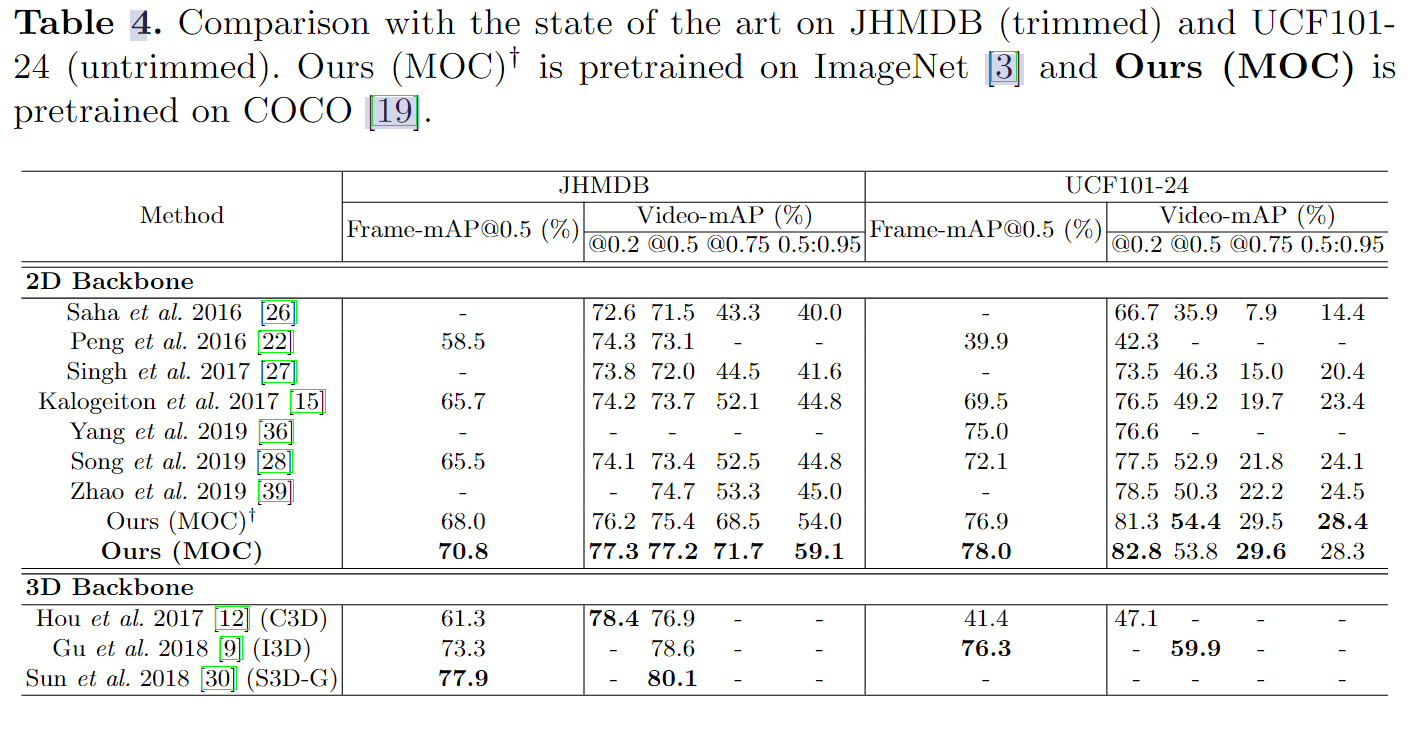
4.5 3D目标检测结果
定量结果:实验表明,SVDM在使用BBDM的情况下,能超过大多数先进方法。使用视图扩散方法能进一步提升性能,这表明视图结构在3D目标检测上有更好的泛化能力。
此外,虽然不能完全超过SotA,SVDM在困难物体的检测上有更好的性能。简单物体性能较差的原因可能是有限的约束。背景和障碍物都不可避免地干扰了新视图生成。ConvNeXt-UNet结构能在一定程度上减轻此问题,但并不完美。
4.3 消融研究
行人和自行车的3D检测结果:由于样本数量少,行人和自行车的检测比汽车的检测更加困难。但本文的方法能在几乎所有难度上超过SotA。
5. 结论和未来展望
目前,SVDM的一个缺点是不能端到端训练。
相关文章:
【论文笔记】SVDM: Single-View Diffusion Model for Pseudo-Stereo 3D Object Detection
原文链接:https://arxiv.org/abs/2307.02270 1. 引言 目前的从单目相机生成伪传感器表达的方法依赖预训练的深度估计网络。这些方法需要深度标签来训练深度估计网络,且伪立体方法通过图像正向变形合成立体图像,会导致遮挡区域的像素伪影、扭…...

C++之sqlite数据库读写
C之sqlite数据库读写 常用函数应用例程 常用函数 1、sqlite3_open() 用于打开SQLite数据库。该函数接受两个参数:数据库文件名和打开模式。成功打开数据库后,将返回一个sqlite3*对象。 2、sqlite3_close() 用于关闭SQLite数据库。该函数接受一个sqlite…...

大模型应用疯狂加速,洗牌却在静悄悄进行了
配图来自Canva可画 在被誉为“科技企业营销圣经”的《跨越鸿沟》一书中,杰弗里摩尔写道:“高科技产品面世过程中,最危险、最关键的一点,就是由少数有远见者所主宰的早期市场,向实用主义者占支配地位的主流市场过渡。”…...

oracle后台进程详解#进程结构
一、oracle进程结构 oracle体系结构主要有实例数据库; 实例由内存结构(SGAPGA..)和进程结构(服务器进程后台进程..)组成;本文主要介绍进程结构 二、服务器进程 Oracle数据库创建服务器进程来处理连接到该实…...

解决DDP的参数未参与梯度计算
将find_unused_parameters改成False之后,如果出现模型有些参数未参与loss计算等错误。 可以用环境变量来debug查看log。 export TORCH_DISTRIBUTED_DEBUGDETAIL 代码上可以用以下方法查看。 # check parameters with no grad for n, p in model.named_parameters(…...

cpp primer笔记100-拷贝控制
如果拷贝构造函数如果传递的参数不是引用类型,则调用拷贝永远不成功,因为如果调用了拷贝构造函数,则必须拷贝它的实参,但是为了拷贝实参,我们又需要调用拷贝构造函数,如此循环。 如果想要删除默认构造函数…...
【数据库——MySQL】(16)游标和触发器习题及讲解
目录 1. 题目1.1 游标1.2 触发器 2. 解答2.1 游标2.2 触发器 1. 题目 1.1 游标 创建存储过程,利用游标依次显示某部门的所有员工的实际收入。(分别用使用 计数器 来循环和使用 标志变量 来控制循环两种方法实现) 创建存储过程,将某部门的员工工资按工作…...
toString的用法)
javascript二维数组(9)toString的用法
在JavaScript中,toString() 是一个内置方法,用于将特定的对象转化为字符串表示形式。 基本使用示例 以下是一些 toString() 方法的基本使用示例: 数字的 toString(): let num 123; console.log(num.toString()); // 输出: &…...

OpenAI重大更新!为ChatGPT推出语音和图像交互功能
原创 | 文 BFT机器人 OpenAI旗下的ChatGPT正在迎来一次重大更新,这个聊天机器人现在能够与用户进行语音对话,并且可以通过图像进行交互,将其功能推向与苹果的Siri等受欢迎的人工智能助手更接近的水平。这标志着生成式人工智能运动的一个显著…...

【开发篇】十六、SpringBoot整合JavaMail实现发邮件
文章目录 0、相关协议1、SpringBoot整合JavaMail2、发送简单邮件3、发送复杂邮件 0、相关协议 SMTP(Simple Mail Transfer Protocol):简单邮件传输协议,用于发送电子邮件的传输协议POP3(Post Office Protocol - Versi…...

如何在Ubuntu系统部署RabbitMQ服务器并公网访问【内网穿透】
文章目录 前言1.安装erlang 语言2.安装rabbitMQ3. 内网穿透3.1 安装cpolar内网穿透(支持一键自动安装脚本)3.2 创建HTTP隧道 4. 公网远程连接5.固定公网TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 RabbitMQ是一个在 AMQP(高级消息队列协议)基…...
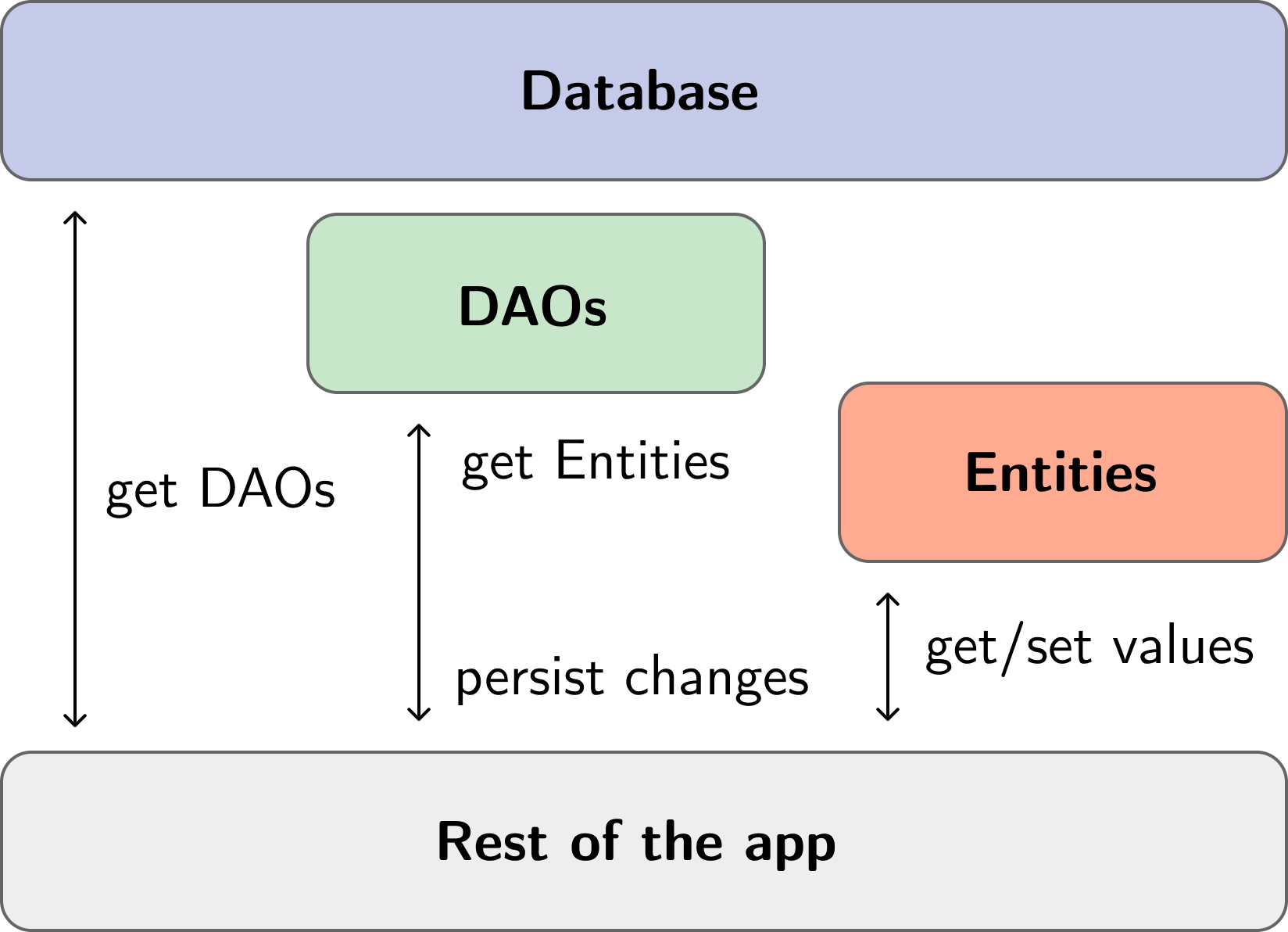
Flutter笔记:用于ORM的Floor框架简记
Flutter笔记 用于ORM的Floor框架简记 本文地址:https://blog.csdn.net/qq_28550263/article/details/133377191 floor 模块地址:https://pub.dev/packages/floor 【介绍】:最近想找用于Dart和Flutter的ORM框架,偶然间发现了Floor…...
Zabbix自定义脚本监控MySQL数据库
一、MySQL数据库配置 1.1 创建Mysql数据库用户 [rootmysql ~]# mysql -uroot -p create user zabbix127.0.0.1 identified by 123456; flush privileges; 1.2 添加用户密码到mysql client的配置文件中 [rootmysql ~]# vim /etc/my.cnf.d/client.cnf [client] host127.0.0.1 u…...
【Spatial-Temporal Action Localization(五)】论文阅读2020年
文章目录 1. Actions as Moving Points摘要和结论引言:针对痛点和贡献模型框架实验 1. Actions as Moving Points Actions as Moving Points (ECCV 2020) 摘要和结论 MovingCenter Detector (MOCdetector) 通过将动作实例视为移动点的轨迹。通过三个分支生成 tub…...

Linux基本指令(中)——“Linux”
各位CSDN的uu们好呀,今天,小雅兰的内容是Linux基本指令呀!!!下面,让我们进入Linux的世界吧!!! cp指令(重要) mv指令(重要)…...

OWASP Top 10漏洞解析(3)- A3:Injection 注入攻击
作者:gentle_zhou 原文链接:OWASP Top 10漏洞解析(3)- A3:Injection 注入攻击-云社区-华为云 Web应用程序安全一直是一个重要的话题,它不但关系到网络用户的隐私,财产,而且关系着用户对程序的新…...

Java自定义类加载器的详解与步骤
自定义类加载器的步骤 继承ClassLoader类:首先创建一个新的类,该类需要继承ClassLoader类。可以通过直接继承ClassLoader或是间接继承URLClassLoader等子类来实现。重写findClass()方法:在自定义类加载器中,最重要的是重写findCl…...
完美清晰,炫酷畅享——Perfectly Clear Video为你带来卓越的AI视频增强体验
在我们日常生活中,我们经常会拍摄和观看各种视频内容,无论是旅行记录、家庭聚会还是商务演示,我们都希望能够呈现出最清晰、最精彩的画面效果。而现在,有一个强大的工具可以帮助我们实现这一目标,那就是Perfectly Clea…...

如何让FileBeat支持http的output插件
目录 1 缘由2 编译filebeat3 配置虚拟机访问外网4 编译beats-output-http4.1 使用本地包4.2 发布在线包 5 测试6 beats-output-http的部分解释 1 缘由 官网的filebeat只有以下几种output插件: Elasticsearch ServiceElasticsearchLogstashKafkaRedisFileConsole …...

解密人工智能:决策树 | 随机森林 | 朴素贝叶斯
文章目录 一、机器学习算法简介1.1 机器学习算法包含的两个步骤1.2 机器学习算法的分类 二、决策树2.1 优点2.2 缺点 三、随机森林四、Naive Bayes(朴素贝叶斯)五、结语 一、机器学习算法简介 机器学习算法是一种基于数据和经验的算法,通过对…...

Claude Code出质量事故了?Anthropic发了一篇有诚意的复盘|AI新岗位FDE爆火
每天更新,带你读懂科技圈。 今日看点: Anthropic 正式回应 Claude Code 质量下降的社区讨论,披露三条幕后原因;FDE(Forward Deployed Engineer)正在成为 AI 公司争抢的新岗位;Figma 自研 Redis …...

GitHub中文界面极速解锁指南:5分钟告别英文困扰的终极方案
GitHub中文界面极速解锁指南:5分钟告别英文困扰的终极方案 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 你是否曾经面对…...

使用Taotoken的Token Plan套餐实现更具成本优势的持续调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken的Token Plan套餐实现更具成本优势的持续调用 对于有稳定大模型调用需求的开发者或团队而言,成本的可预测…...

5步掌握Mac视频预览革命:QLVideo让你的Finder变身全能播放器
5步掌握Mac视频预览革命:QLVideo让你的Finder变身全能播放器 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://…...

2026届最火的十大降AI率神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 人工智能生成内容也就是 AIGC 技术迅猛发展着,其在学术领域的应用引发着深刻变革…...

ITK-SNAP医学图像分割:精准医疗影像分析的利器
ITK-SNAP医学图像分割:精准医疗影像分析的利器 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 面对复杂的医学影像数据,如何快速准确地进行三维解剖结构分割ÿ…...

LeaderKey.app开发者指南:深入源码解析架构设计
LeaderKey.app开发者指南:深入源码解析架构设计 【免费下载链接】LeaderKey The *faster than your launcher* launcher 项目地址: https://gitcode.com/gh_mirrors/le/LeaderKey LeaderKey.app是一款轻量级启动器应用,以"比你的启动器更快&…...

2025最权威的降AI率方案实际效果
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 随着人工智能技术迅猛地发展,它在学术研究领域的应用越发深入,对高等…...

智能家电语音交互核心技术:从麦克风阵列到语义理解的易用性设计
1. 项目概述:从“鸡肋”到“刚需”的智能语音交互几年前,当智能家电刚开始搭载语音模块时,很多用户的第一反应是“新鲜”,第二反应可能就是“鸡肋”。唤醒词不灵敏、指令识别率低、稍微带点口音就听不懂,更别提在嘈杂环…...

【YOLO目标检测全栈实战】36 TensorRT部署实战:YOLOv8n在Jetson Orin上实现5ms推理
上周,我帮一家做无人机巡检的客户部署模型。他们的算法工程师在PC上用ONNX Runtime跑YOLOv8n,推理速度30ms,觉得“挺快”。 结果一上Jetson Orin NX,直接崩到120ms——无人机飞一圈,画面卡得像幻灯片。客户急了:“同样的模型,怎么差这么多?”我看了眼代码,发现他们还…...