深度学习——深度学习计算二
深度学习——深度学习计算二
文章目录
- 前言
- 三、延后初始化
- 四、自定义层
- 4.1. 不带参数的层
- 4.2. 带参数的层
- 五、读写文件
- 5.1. 加载和保存张量
- 5.2. 加载和保存模型参数
- 六、GPU
- 6.1. 计算设备
- 6.2. 张量与GPU
- 6.3. 神经网络与GPU
- 总结
前言
延续上一章的学习,本章继续记录深度学习计算的知识点。
参考书:
《动手学深度学习》
三、延后初始化
框架的延后初始化(defers initialization), 即直到数据第一次通过模型传递时,框架才会动态地推断出每个层的大小
在以后,当使用卷积神经网络时, 由于输入维度(即图像的分辨率)将影响每个后续层的维数, 有了该技术将更加方便。
延后初始化使框架能够自动推断参数形状,使修改模型架构变得容易,避免了一些常见的错误。 我们可以通过模型传递数据,使框架最终初始化参数。
当我们实例化一个多层感知机时:
一旦我们知道输入维数是20,框架可以通过代入值20来识别第一层权重矩阵的形状。 识别出第一层的形状后,框架处理第二层,依此类推,直到所有形状都已知为止。
注意,在这种情况下,只有第一层需要延迟初始化,但是框架仍是按顺序初始化的。 等到知道了所有的参数形状,框架就可以初始化参数。
四、自定义层
深度学习成功背后的一个因素是神经网络的灵活性: 我们可以用创造性的方式组合不同的层,从而设计出适用于各种任务的架构。
有时我们会遇到或要自己发明一个现在在深度学习框架中还不存在的层。 在这些情况下,必须构建自定义层。
4.1. 不带参数的层
首先,我们构造一个没有任何参数的自定义层。
要构建它,我们只需继承基础层类并实现前向传播功能。
#下面的CenteredLayer类要从其输入中减去均值。 要构建它,我们只需继承基础层类并实现前向传播功能。
import torch
from torch import nn
import torch.nn.functional as Fclass Centerdlayer(nn.Module):def __init__(self):super().__init__()def forward(self,x):return x-x.mean()layer = Centerdlayer()
print(layer(torch.FloatTensor([1,2,3,4,5])))#现在,我们可以将层作为组件合并到更复杂的模型中
net = nn.Sequential(nn.Linear(8,128),Centerdlayer())#作为额外的健全性检查,我们可以在向该网络发送随机数据后,检查均值是否为0。
#由于我们处理的是浮点数,因为存储精度的原因,我们仍然可能会看到一个非常小的非零数。
y = net(torch.rand(4,8))
print(y.mean())#结果:
tensor([-2., -1., 0., 1., 2.])
tensor(-5.1223e-09, grad_fn=<MeanBackward0>)4.2. 带参数的层
让我们实现自定义版本的全连接层。该层需要两个参数,一个用于表示权重,另一个用于表示偏置项。
在此实现中,我们使用修正线性单元作为激活函数。 该层需要输入参数:in_units和units,分别表示输入数和输出数。
class Mylinear(nn.Module):def __init__(self,in_units,units):super().__init__()self.weight = nn.Parameter(torch.randn(in_units,units))self.bias = nn.Parameter(torch.randn(units,))def forward(self,x):linear = torch.matmul(x,self.weight.data) +self.bias.datareturn F.relu(linear)linear = Mylinear(5,3)
print(linear.weight)#我们可以[使用自定义层直接执行前向传播计算]。
print(linear(torch.rand(2,5)))#我们还可以(使用自定义层构建模型),就像使用内置的全连接层一样使用自定义层
net = nn.Sequential(Mylinear(64,8),Mylinear(8,1))
print(net(torch.rand(2,64)))#结果:
Parameter containing:
tensor([[ 0.6645, -1.0066, -0.3903],[ 1.7685, 1.4849, 0.2311],[-0.1649, -0.9360, -0.5300],[ 1.1137, 1.1452, -1.5475],[ 0.4353, -0.8462, 0.3522]], requires_grad=True)
tensor([[2.6093, 0.0000, 0.3777],[2.6460, 0.0000, 0.0000]])
tensor([[0.0000],[0.4022]])五、读写文件
5.1. 加载和保存张量
对于单个张量,我们可以直接调用load和save函数分别读写它们。
这两个函数都要求我们提供一个名称,save要求将要保存的变量作为输入。
#加载和保存张量x = torch.arange(1,4)
print(x)
torch.save(x,"x-file")
#将存储在文件中的数据读回内存
x2 = torch.load("x-file")
print(x2)
#可以存储一个张量列表,再读回内存
y = torch.zeros_like(x)
torch.save([x,y],"x-files")
x2,y2 = torch.load("x-files")
print(x2,y2)#也可以读取或写入从字符串映射到张量的字典
mydict = {"x":x,"y":y}
torch.save(mydict,"mydict")
mydict2 = torch.load("mydict")
print(mydict2)
print(mydict2["x"])#结果:
tensor([1, 2, 3])
tensor([1, 2, 3])
tensor([1, 2, 3]) tensor([0, 0, 0])
{'x': tensor([1, 2, 3]), 'y': tensor([0, 0, 0])}
tensor([1, 2, 3])5.2. 加载和保存模型参数
需要注意的一个重要细节是,这将保存模型的参数而不是保存整个模型。
例如,如果我们有一个3层多层感知机,我们需要单独指定架构。 因为模型本身可以包含任意代码,所以模型本身难以序列化。
因此,为了恢复模型,我们需要用代码生成架构, 然后从磁盘加载参数。
class MLP(nn.Module):def __init__(self):super().__init__()self.hidden = nn.Linear(20,256)self.output = nn.Linear(256,10)def forward(self,x):return self.output(F.relu(self.hidden(x)))net = MLP()
x = torch.randn(size= (2,20))
y = net(x)
#将模型的参数存储在文件中
torch.save(net.state_dict(),"mlp.params")
#实例化了原始多层感知机模型的一个备份
clone = MLP()
clone.load_state_dict(torch.load("mlp.params"))
print(clone.eval()) # eval()的主要作用是将字符串作为Python代码进行解析和执行#由于两个实例具有相同的模型参数,在输入相同的X时, 两个实例的计算结果应该相同。 让我们来验证一下。
y_clone = clone(x)
print(y_clone == y)#结果:
MLP((hidden): Linear(in_features=20, out_features=256, bias=True)(output): Linear(in_features=256, out_features=10, bias=True)
)
tensor([[True, True, True, True, True, True, True, True, True, True],[True, True, True, True, True, True, True, True, True, True]])六、GPU
6.1. 计算设备
在PyTorch中,CPU和GPU可以用torch.device(‘cpu’) 和torch.device(‘cuda’)表示。
如果有多个GPU,我们使用torch.device(f’cuda:{i}') 来表示第 𝑖 块GPU( 𝑖 从0开始)。 另外,cuda:0和cuda是等价的。
import torch
from torch import nnprint(torch.device('cpu'), torch.device('cuda'), torch.device('cuda:1'))#查询可用gpu的数量
print(torch.cuda.device_count())#这两个函数允许我们在不存在所需所有GPU的情况下运行代码
def try_gpu(i=0): #@save"""如果存在,则返回gpu(i),否则返回cpu()"""if torch.cuda.device_count() >= i + 1:return torch.device(f'cuda:{i}')return torch.device('cpu')def try_all_gpus(): #@save"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""devices = [torch.device(f'cuda:{i}')for i in range(torch.cuda.device_count())]return devices if devices else [torch.device('cpu')]6.2. 张量与GPU
查询张量所在的设备。默认情况下,张量是在CPU上创建的。
x = torch.tensor([1, 2, 3])
print(x.device)
我们可以在创建张量时指定存储设备,一般来说,我们需要确保不创建超过GPU显存限制的数据
X = torch.ones(2, 3, device=try_gpu())
print(X)
深度学习框架要求计算的所有输入数据都在同一设备上,无论是CPU还是GPU
6.3. 神经网络与GPU
类似地,神经网络模型可以指定设备。 下面的代码将模型参数放在GPU上
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())#当输入为GPU上的张量时,模型将在同一GPU上计算结果
print(net(X))
print(net[0].weight.data.device)总结
本章简单记录了一下深度学习计算中要注意的一些问题,延后初始化概念,对层的自定义,对模型或参数的加载和保存,利用GPU进行计算等。
果而勿矜,果而勿伐,果而勿骄,果而不得已,果而勿强。
–2023-10-6 进阶篇
相关文章:

深度学习——深度学习计算二
深度学习——深度学习计算二 文章目录 前言三、延后初始化四、自定义层4.1. 不带参数的层4.2. 带参数的层 五、读写文件5.1. 加载和保存张量5.2. 加载和保存模型参数 六、GPU6.1. 计算设备6.2. 张量与GPU6.3. 神经网络与GPU 总结 前言 延续上一章的学习,本章继续记…...
HarmonyOS/OpenHarmony原生应用-ArkTS万能卡片组件Badge
可以附加在单个组件上用于信息标记的容器组件。该组件从API Version 7开始支持。 支持单个子组件。子组件类型:系统组件和自定义组件,支持渲染控制类型(if/else、ForEach和LazyForEach)。 一、接口 方法1: Badge(value…...

在Flink中集成和使用Hudi
本文介绍在Flink 中集成和使用Hudi。介绍Flink如何将Streaming引入Hudi。在Hudi上使用Flink,并学习Flink读写Hudi的不同模式: Flink SQL客户端写入:Flink SQL客户端写入(读取)Hudi。 配置:对于全局配置,通过$FLINK_HOME/conf/FLINK-conf.yaml进行设置。对于每个作业配置…...
docker搭建Jenkins及基本使用
1. 搭建 查询镜像 docker search jenkins下载镜像 docker pull jenkins/jenkins启动容器 #创建文件夹 mkdir -p /home/jenkins_home #权限 chmod 777 /home/jenkins_home #启动Jenkins docker run -d -uroot -p 9095:8080 -p 50000:50000 --name jenkins -v /home/jenkins_home…...

CSS初体验
目录 一、CSS初体验 二、CSS引入方式 三、选择器 3.1 标签选择器 3.2 类选择器 3.3 id选择器 3.4 通配符选择器 四、盒子尺寸和背景色 五、文字控制属性 5.1 字体大小 5.2 字体样式(是否倾斜) 5.3 行高 5.3.1 单行文字垂直居中 5.4 字体族 5.5 font复合属性 5.…...

python性能分析
基于cProfile统计函数级的时延,生成排序列表、火焰图,可以快速定位python代码的耗时瓶颈。参考如下博文结合实操,总结为三步: 使用 cProfile 和火焰图调优 Python 程序性能 - 知乎本来想坐下来写篇 2018 年的总结,仔细…...
苹果手机怎么备份所有数据?2023年iPhone 15数据备份常用的3种方法!
当苹果手机需要进行刷机、恢复出厂设置、降级iOS系统等操作时,我们需要将自己的iPhone数据提前进行备份。 特别是在苹果发布新iOS系统时,总有一些小伙伴因为升降级系统,而导致了重要数据的丢失。 iPhone中储存着重要的照片、通讯录、文件等数…...

【RV1103】如何新增一个新板级配置
文章目录 新建一个板级配置文件 新建一个板级配置文件 我的目标 通过./build.sh lunch 来选择我的板子配置。 在目录sdk/project/cfg目录下新建一个xxxx.mk文件,文件名字格式如下: BoardConfig-"启动介质"-"电源方案"-"硬件…...

ThreeJS-3D教学五-材质
我们在ThreeJS-3D教学二:基础形状展示中有简单介绍过一些常用的材质,这次我们举例来具体看下效果: 代码是这样的: <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8">&…...
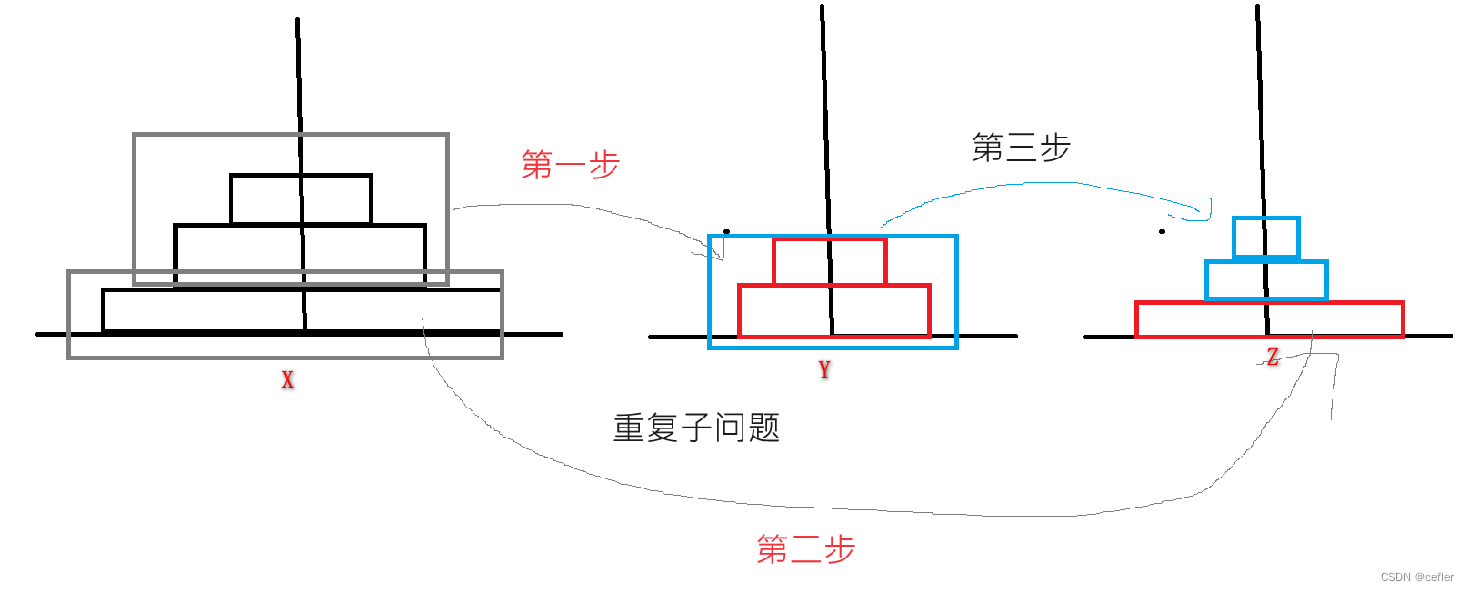
递归
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析(3) 目录 👉🏻汉诺塔 👉&…...
Vercel部署个人静态之DNS污染劫持问题
vercel是我第一次接触静态网站托管所使用的服务,类似的还有github以及Netfily。但是Vercel的自动化构建远比github page方便的多。通过github授权给Vercel就实现了自动拉取构建及发布的一系列流程。在本地推送代码可以使用小乌龟工具,线上代码发布使用Ve…...

Microsoft Defender Vulnerability部署方案
目录 前言 Microsoft Defender Vulnerability 的主要功能 Microsoft Defender Vulnerability部署方案 前言 Microsoft Defender Vulnerability 是微软公司提供的一种安全工具,用于检测和修复系统中的漏洞和弱点。它可以帮助用户保护他们的计算机免受潜在的威胁和攻击,提高…...

云服务器CVM_云主机_云计算服务器_弹性云服务器-腾讯云
腾讯云服务器CVM提供安全可靠的弹性计算服务,腾讯云明星级云服务器,弹性计算实时扩展或缩减计算资源,支持包年包月、按量计费和竞价实例计费模式,CVM提供多种CPU、内存、硬盘和带宽可以灵活调整的实例规格,提供9个9的数…...
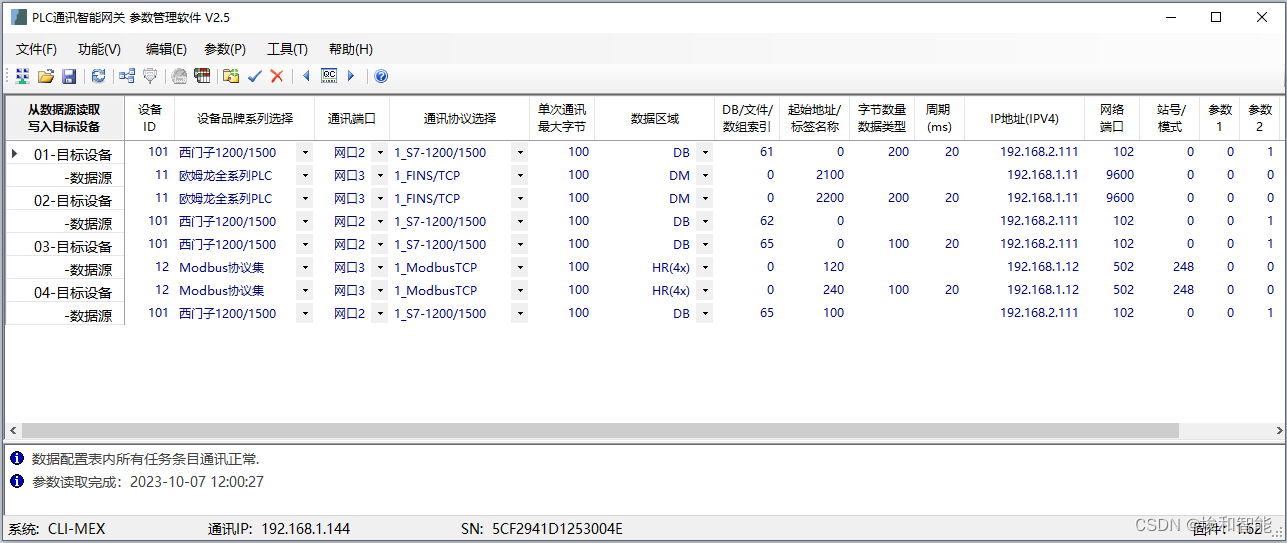
PLC之间无线通信-不用编程实现多品牌PLC无线通讯的解决方案
本文是PLC设备之间基于IGT-DSER系列智能网关实现WIFI无线通讯的案例。采用西门子S7-1500系列的PLC作为主站,与其它品牌的PLC之间进行网络通讯。案例包括智能网关AP方式、现场WIFI信号两种方式。有线以太网方式实现PLC之间通讯的案例 一、智能网关AP方式 将网络中的其…...

第二证券:A股反弹已至?9月最牛金股涨超41%
进入10月,作为券商月度战略精华的新一期金股也连续宣布。 从各券商关于十月份的大势研判来看,一些券商达观地认为反弹行情正在打开,也有一些券商认为仍是轰动市。具体配备上,AI、科创相关的标的仍然遭到喜欢,一起不少…...

机器人革命:你一定没见过这些全新的机器人技术!
原创 | 文 BFT机器人 01 通过机器人协作推进危险测绘 在危险测绘领域,研究人员开发了一种合作方案,利用地面和空中机器人对污染区域进行危险测绘。该团队通过使用异构覆盖控制技术提高了密度图的质量并降低了误差。与同质替代方案相比,该策…...
vue前端项目中添加独立的静态资源
如果想要在vue项目中放一些独立的静态资源,比如html文件或者用于下载的业务模板或其他文件等,需要在vue打包的时候指定一下静态资源的位置和打包后的目标位置。 使用的是 copy-webpack-plugin 插件,如果没有安装则需要先安装一下,…...

外汇天眼:业务员离职,也不给出金!Sky Alliance Markets摆烂不玩了?
近段时间,外汇天眼收到Sky Alliance Markets的客诉激增已达10条,目前该平台的官网还能打开。但最近关于Sky Alliance Markets是否跑路的争议也越来越多,据来外汇天眼投诉的用户透露,Sky Alliance Markets的员工大部分已经离职&…...

chrome浏览器如何多开
在网上寻找关于Chrome浏览器多开的教程时,你可能会发现操作相对复杂。然而,最近我发现了一个名为EasyBR浏览器的工具,作者使用程序将繁琐的步骤简化了。 主要功能 EasyBR浏览器具有以下主要功能: 批量账号管理:可以…...

学习笔记|串口通信的基础知识|同步/异步|常见的串口软件的参数|STC32G单片机视频开发教程(冲哥)|第二十集:串口通信基础
目录 1.串口通信的基础知识串口通信(Serial Communication)同步/异步?全双工?常见的串口软件的参数 2.STC32的串口通信实现原理引脚选择模式选择 3.串口通信代码实现编写串口1通信程序测试 总结 1.串口通信的基础知识 百度百科:串口通信的概…...
)
毫米波雷达ADAS实战:TI AWR1843芯片上的信号处理链优化心得(附FFT与CFAR配置要点)
毫米波雷达ADAS实战:TI AWR1843芯片上的信号处理链优化心得 在智能驾驶领域,毫米波雷达因其全天候工作能力和稳定的测距测速性能,成为ADAS系统的核心传感器之一。德州仪器(TI)的AWR1843作为一款高度集成的毫米波雷达So…...

ChatGPT开发者实战指南:从API集成到应用部署的完整资源导航
1. 项目概述:一份面向开发者的ChatGPT资源导航 如果你是一名开发者、产品经理,或者任何对AI应用构建感兴趣的技术爱好者,最近几个月肯定被ChatGPT和GPT-3相关的新闻、工具和项目刷屏了。信息爆炸带来的一个直接问题是:好东西太多…...

ue5 血条 渲染方形的分辨率 血条缩放的问题
项目设置中将Resize PIE Window to Output Resolution直接搜索Resize PIE Window to Output Resolution勾选即可...

CANoe各版本软件包怎么找?从Demo到Full Installer的下载指南与版本选择建议
CANoe版本管理与资源获取全攻略:从Demo到Full Installer的深度实践指南 在汽车电子开发与测试领域,Vector公司的CANoe软件堪称行业标准工具。但许多工程师在实际工作中常遇到这样的困境:项目需要特定历史版本进行兼容性测试,而官网…...

AnyFlip下载器终极指南:3分钟快速将在线翻页书转为PDF
AnyFlip下载器终极指南:3分钟快速将在线翻页书转为PDF 【免费下载链接】anyflip-downloader Download anyflip books as PDF 项目地址: https://gitcode.com/gh_mirrors/an/anyflip-downloader 你是否在AnyFlip上发现了心仪的电子书,却苦于无法下…...

Gemini应用商店曝光量暴跌?3步诊断+5个隐藏算法漏洞修复指南
更多请点击: https://intelliparadigm.com 第一章:Gemini应用商店曝光量暴跌?3步诊断5个隐藏算法漏洞修复指南 近期大量开发者反馈 Gemini 应用商店自然曝光量断崖式下跌,部分应用 7 日内曝光下降超 68%,但后台数据未…...
)
简化环境配置:OpenClaw v2.7.1 部署与实操教学(新手适用)
🚀 Windows 极速部署 OpenClaw v2.7.1 教程|5 分钟搭建本地 AI 智能体 在开源 AI 智能体快速普及的当下,OpenClaw(小龙虾)凭借本地运行、零代码操控、全场景自动化能力,成为办公与技术人群的效率工具&…...

FPGA实战:基于Verilog的正交调制解调系统设计与仿真验证
1. 正交调制解调系统基础认知 第一次接触正交调制解调时,我也被那些数学公式绕得头晕。后来发现,用日常生活中的例子理解会简单很多——就像两个人同时往同一个方向扔球(I路和Q路信号),接收端需要准确接住这两个球并还…...

终极图片去重神器:AntiDupl.NET帮你一键清理重复图片释放磁盘空间
终极图片去重神器:AntiDupl.NET帮你一键清理重复图片释放磁盘空间 【免费下载链接】AntiDupl A program to search similar and defect pictures on the disk 项目地址: https://gitcode.com/gh_mirrors/an/AntiDupl 你是否曾因电脑里堆积如山的重复照片而烦…...
)
生物 -- 神经系统(三)
1、髓鞘髓鞘是包裹在神经细胞轴突外层的绝缘膜,主要由脂质和蛋白质构成,起到加速神经信号传导、绝缘防漏电以及保护和修复神经的作用。你可以把它想象成电线外的绝缘皮,确保电流(即神经信号)高效、准确地传输。核心功…...