使用Java Spring Boot构建高效的爬虫应用
本文将介绍如何使用Java Spring Boot框架来构建高效的爬虫应用程序。通过使用Spring Boot和相关的依赖库,我们可以轻松地编写爬虫代码,并实现对指定网站的数据抓取和处理。本文将详细介绍使用Spring Boot和Jsoup库进行爬虫开发的步骤,并提供一些实用的技巧和最佳实践。
一、介绍
爬虫是一种自动化程序,用于从互联网上获取数据。它可以访问并解析网页内容,提取感兴趣的信息,并将其存储或进一步处理。使用爬虫可以实现很多有用的功能,比如数据采集、信息监测、搜索引擎索引等。
Java是一种强大的编程语言,而Spring Boot是一个流行的Java开发框架,可以帮助我们快速构建可扩展的、高效的应用程序。结合Spring Boot和相关的库,我们可以编写出高效、可维护的爬虫应用程序。
二、准备工作
在开始编写爬虫代码之前,我们需要进行一些准备工作。首先,我们需要创建一个Spring Boot项目。可以使用Maven或Gradle构建工具来创建一个新的Spring Boot项目,然后将所需的依赖库添加到项目的配置文件中。
本文使用的依赖库是Jsoup,它是一个非常常用的Java HTML解析库,用于处理爬取到的网页内容。在项目的pom.xml文件中添加以下依赖:
<dependency><groupId>org.jsoup</groupId><artifactId>jsoup</artifactId><version>1.13.1</version>
</dependency>
三、编写爬虫代码
- 创建一个Spring Boot应用程序,并在其中创建一个Controller类,用于处理用户的请求和响应。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/crawler")
public class CrawlerController {@GetMapping("/page")public String getPageContent() {try {String url = "http://example.com"; // 要爬取的网页URLDocument document = Jsoup.connect(url).get();String pageContent = document.html();return pageContent;} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在上述代码中,我们使用了Jsoup库来连接到指定的URL,并使用
get()方法获取页面内容。然后,我们可以将获取到的页面内容返回给用户。 -
在应用程序的主类中,使用
@SpringBootApplication注解来启动Spring Boot应用程序。
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;@SpringBootApplication
public class CrawlerApplication {public static void main(String[] args) {SpringApplication.run(CrawlerApplication.class, args);}
}
四、运行爬虫应用
现在,我们已经完成了爬虫应用的代码编写,可以通过运行Spring Boot应用来启动爬虫。
使用命令行工具进入项目的根目录,然后执行以下命令:
mvn spring-boot:run
或者,可以使用IDE来运行Spring Boot应用。
应用启动后,可以使用浏览器或其他工具发送GET请求到http://localhost:8080/crawler/page,即可获取到爬取到的网页内容。
五、案例
案例一:爬取天气数据
在这个案例中,我们将使用Java Spring Boot框架和Jsoup库来爬取天气数据。我们可以从指定的天气网站中获取实时的天气信息,并将其显示在我们的应用程序中。
-
创建一个新的Spring Boot应用程序,并添加所需的依赖库。
-
创建一个Controller类,在其中编写一个方法用于爬取天气数据。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/weather")
public class WeatherController {@GetMapping("/forecast")public String getWeatherForecast() {try {String url = "http://example.com/weather"; // 要爬取的天气网站URLDocument document = Jsoup.connect(url).get();Elements forecasts = document.select(".forecast-item"); // 获取天气预报的元素StringBuilder result = new StringBuilder();for (Element forecast : forecasts) {String date = forecast.select(".date").text(); // 获取日期String weather = forecast.select(".weather").text(); // 获取天气情况String temperature = forecast.select(".temperature").text(); // 获取温度result.append(date).append(": ").append(weather).append(", ").append(temperature).append("\n");}return result.toString();} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在应用程序的主类中启动Spring Boot应用程序。
-
运行应用程序,并在浏览器中访问
http://localhost:8080/weather/forecast,即可获取到天气预报信息。
案例二:爬取新闻头条
在这个案例中,我们将使用Java Spring Boot框架和Jsoup库来爬取新闻头条。我们可以从指定的新闻网站中获取最新的新闻标题和链接,并将其显示在我们的应用程序中。
-
创建一个新的Spring Boot应用程序,并添加所需的依赖库。
-
创建一个Controller类,在其中编写一个方法用于爬取新闻头条。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/news")
public class NewsController {@GetMapping("/headlines")public String getNewsHeadlines() {try {String url = "http://example.com/news"; // 要爬取的新闻网站URLDocument document = Jsoup.connect(url).get();Elements headlines = document.select(".headline"); // 获取新闻标题的元素StringBuilder result = new StringBuilder();for (Element headline : headlines) {String title = headline.text(); // 获取新闻标题String link = headline.attr("href"); // 获取新闻链接result.append(title).append(": ").append(link).append("\n");}return result.toString();} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在应用程序的主类中启动Spring Boot应用程序。
-
运行应用程序,并在浏览器中访问
http://localhost:8080/news/headlines,即可获取到新闻头条信息。
案例三:爬取电影排行榜
在这个案例中,我们将使用Java Spring Boot框架和Jsoup库来爬取电影排行榜。我们可以从指定的电影网站中获取最新的电影排名、评分和简介,并将其显示在我们的应用程序中。
-
创建一个新的Spring Boot应用程序,并添加所需的依赖库。
-
创建一个Controller类,在其中编写一个方法用于爬取电影排行榜。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/movies")
public class MovieController {@GetMapping("/top")public String getTopMovies() {try {String url = "http://example.com/movies"; // 要爬取的电影网站URLDocument document = Jsoup.connect(url).get();Elements movies = document.select(".movie"); // 获取电影排行榜的元素StringBuilder result = new StringBuilder();for (Element movie : movies) {String rank = movie.select(".rank").text(); // 获取排名String title = movie.select(".title").text(); // 获取电影标题String rating = movie.select(".rating").text(); // 获取评分String description = movie.select(".description").text(); // 获取简介result.append(rank).append(". ").append(title).append(", Rating: ").append(rating).append("\n").append("Description: ").append(description).append("\n\n");}return result.toString();} catch (Exception e) {return "Error: " + e.getMessage();}}
}
-
在应用程序的主类中启动Spring Boot应用程序。
-
运行应用程序,并在浏览器中访问
http://localhost:8080/movies/top,即可获取到电影排行榜信息。
这些案例只是展示了使用Java Spring Boot和Jsoup库进行爬虫开发的基本原理和方法。根据实际需求,我们可以根据网站的HTML结构和数据格式进行进一步的解析和处理。
六、注意事项
在编写和使用爬虫代码时,我们需要遵守网站的服务条款和法律规定。尊重网站的隐私权和使用规则是非常重要的。另外,为了避免给网站带来过多的负担,我们应该设置合理的爬取频率,并避免过于频繁的请求。
七、总结
本文介绍了如何使用Java Spring Boot框架来构建高效的爬虫应用程序。通过结合Spring Boot和Jsoup库,我们可以轻松地编写爬虫代码,并实现对指定网站的数据抓取和处理。同时,我们也提到了一些注意事项,以确保合法性和避免给网站带来过多的负担。
爬虫是一个非常有用的工具,可以帮助我们自动化获取互联网上的数据。当然,在使用爬虫时,我们也要遵守相关的法律和道德规范,确保使用爬虫的合法性和合理性。希望本文对于想要使用Java Spring Boot构建爬虫应用的开发者有所帮助。
相关文章:

使用Java Spring Boot构建高效的爬虫应用
本文将介绍如何使用Java Spring Boot框架来构建高效的爬虫应用程序。通过使用Spring Boot和相关的依赖库,我们可以轻松地编写爬虫代码,并实现对指定网站的数据抓取和处理。本文将详细介绍使用Spring Boot和Jsoup库进行爬虫开发的步骤,并提供一…...
归并排序与非比较排序详解
W...Y的主页 😊 代码仓库分享 💕 🍔前言: 上篇博客我们讲解了非常重要的快速排序,相信大家已经学会了。最后我们再学习一种特殊的排序手法——归并排序。话不多说我们直接上菜。 目录 归并排序 基本思想 递归思路…...
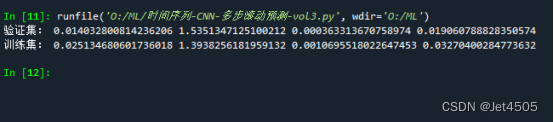
第85步 时间序列建模实战:CNN回归建模
基于WIN10的64位系统演示 一、写在前面 这一期,我们介绍CNN回归。 同样,这里使用这个数据: 《PLoS One》2015年一篇题目为《Comparison of Two Hybrid Models for Forecasting the Incidence of Hemorrhagic Fever with Renal Syndrome i…...
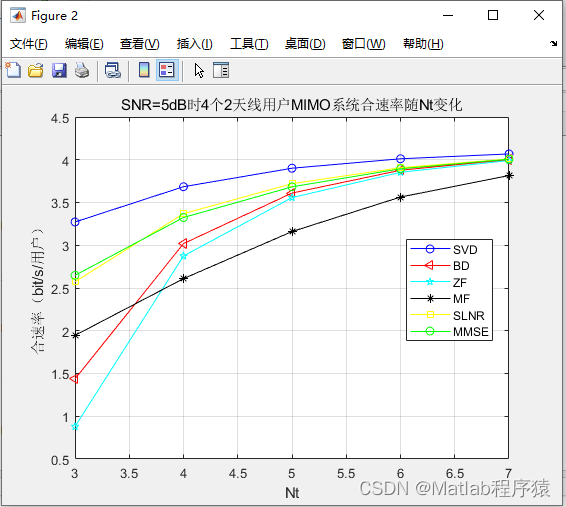
【MATLAB源码-第36期】matlab基于BD,SVD,ZF,MMSE,MF,SLNR预编码的MIMO系统误码率分析。
1、算法描述 1. MIMO (多输入多输出):这是一个无线通信系统中使用的技术,其中有多个发送和接收天线。通过同时发送和接收多个数据流,MIMO可以增加数据速率和系统容量,同时提高信号的可靠性。 2. BD (块对角化):这是一…...

Uniapp 新手专用 抖音登录 获取用户头像、名称、openid、unionid、anonymous_openid、session_key
TC-dylogin 一定请选择 源码授权版 教程 第一步 将代码拷贝至您所需要的页面 该代码位置:pages/index.vue 第二步 修改appid和secret 第三步 获取appid和secret 获取appid和secret链接 注意事项 为了安全,我将默认的自己的appid和secret在云函数中删…...

openssl引擎开发踩坑小记
前言 在开发openssl引擎过程中,引擎莫名其妙的加载不上,错误如下图: 大概意思就是加载引擎动态库时失败了。 在网上一顿搜索后,也没找到想要的答案。 原因 许多引擎都是基于第三方动态库开发的,引擎本身在开发时&a…...
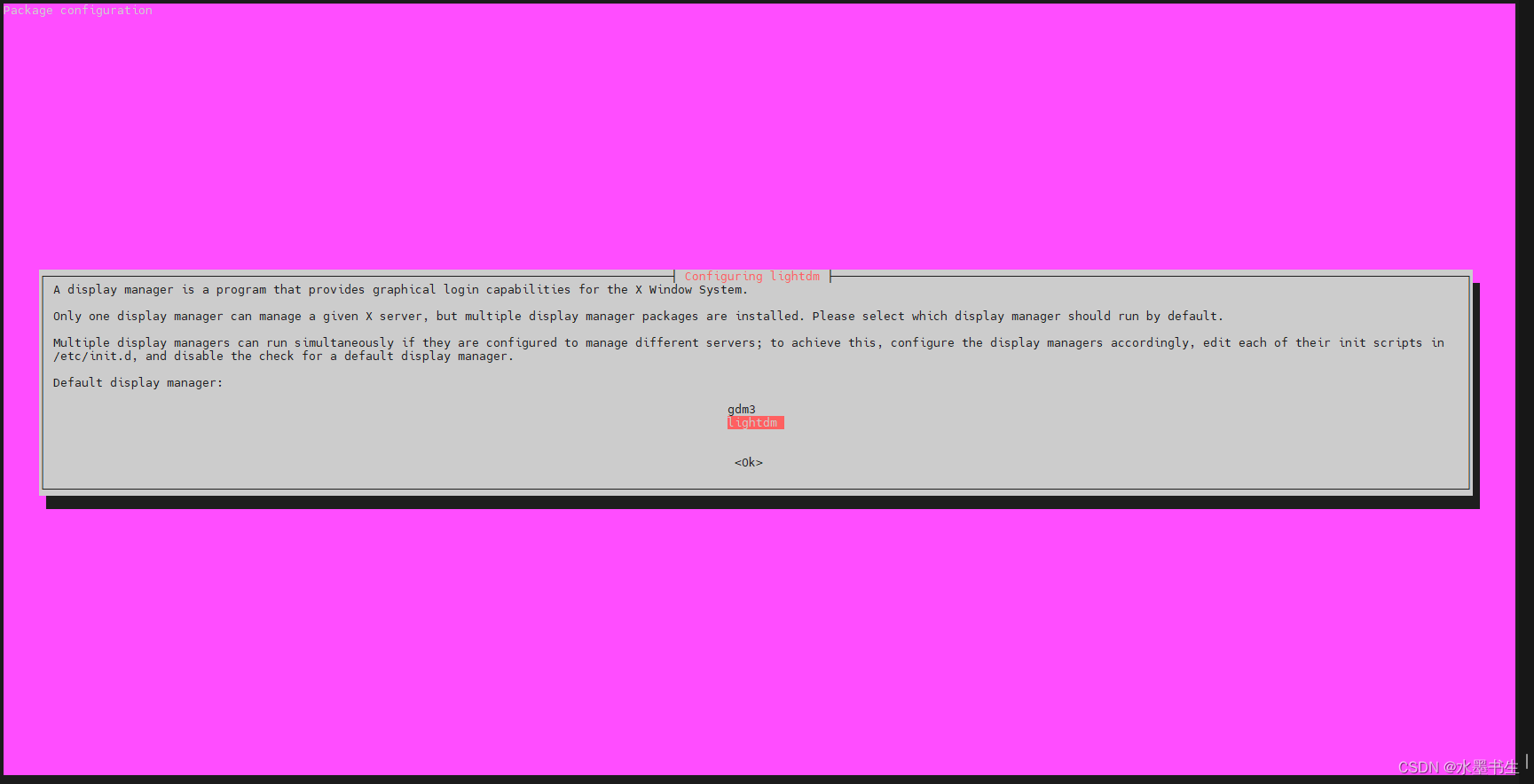
ubuntu 设置x11vnc服务
Ubuntu 18.04 设置x11vnc服务 自带的vino-server也可以用但是不好用,在ubuntu论坛上看见推荐的x11vnc(ubuntu关于vnc的帮助页面),使用设置一下,结果发现有一些坑需要填,所以写下来方便下次使用 转载请说明…...

物理备份xtrabackup
物理备份: 直接复制数据库文件,适用于大型数据库环境,不受存储引擎的限制,但不能恢复到不同的MySQL版本。 1.完全备份-----完整备份: 每次都将所有数据(不管自第一次备份以来有没有修改过)&am…...
1.springcloudalibaba nacos2.2.3部署
前言 nacos是springcloudalibaba体系的注册中心,演示如何搭建最新稳定版本的linux搭建。 前置条件,安装好jdk1.8 一、二进制压缩包下载 1.1 下载压缩包 nacos下载 点击下载下载后得到二进制包如下 nacos-2.2.3.tar.gz二、安装步骤 2.1.解压二进制…...
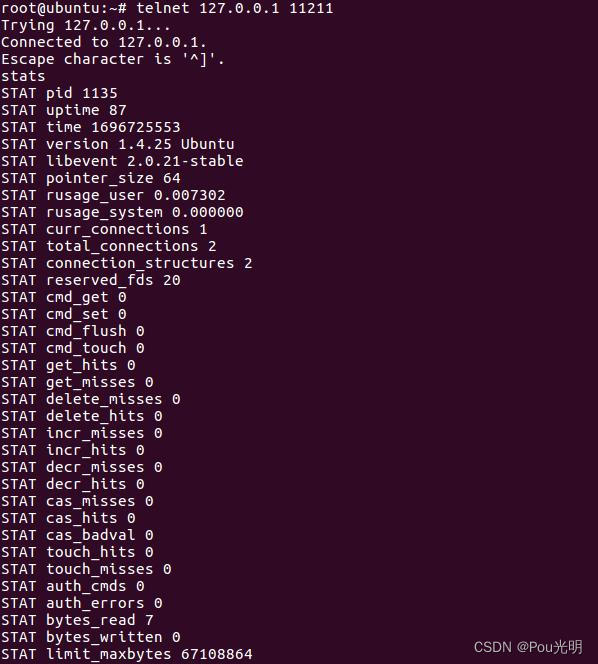
Linux 查看是否安装memcached
telnet 127.0.0.1 11211这样的命令连接上memcache,然后直接输入stats就可以得到memcache服务器的版本 安装memcached : sudo apt-get install memcached...
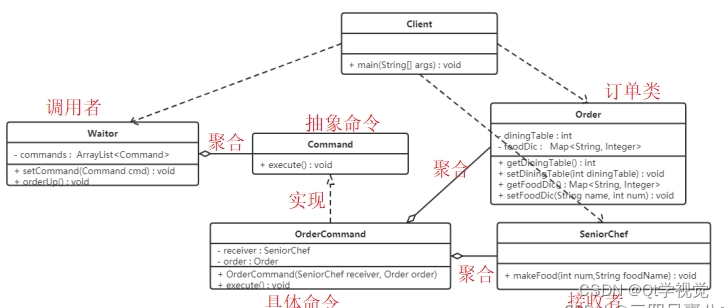
设计模式14、命令模式 Command
解释说明:命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传递给调用对象。调用对象寻找可以处理该命令的合适对象,并把该命令传给相应的对象&…...

【Go】excelize库实现excel导入导出封装(一),自定义导出样式、隔行背景色、自适应行高、动态导出指定列、动态更改表头
前言 最近在学go操作excel,毕竟在web开发里,操作excel是非常非常常见的。这里我选择用 excelize 库来实现操作excel。 为了方便和通用,我们需要把导入导出进行封装,这样以后就可以很方便的拿来用,或者进行扩展。 我参…...
【开发篇】二十、SpringBoot整合RocketMQ
文章目录 1、整合2、消息的生产3、消费4、发送异步消息5、补充:安装RocketMQ 1、整合 首先导入起步依赖,RocketMQ的starter不是Spring维护的,这一点从starter的命名可以看出来(不是spring-boot-starter-xxx,而是xxx-s…...

OpenCV实现求解单目相机位姿
单目相机通过对极约束来求解相机运动的位姿。参考了ORBSLAM中单目实现的代码,这里用opencv来实现最简单的位姿估计. mLeftImg cv::imread(lImg, cv::IMREAD_GRAYSCALE); mRightImg cv::imread(rImg, cv::IMREAD_GRAYSCALE); cv::Ptr<ORB> OrbLeftExtractor …...

深入解析PostgreSQL:命令和语法详解及使用指南
文章目录 摘要引言基本操作安装与配置连接和退出 数据库操作创建数据库删除数据库切换数据库 表操作创建表删除表插入数据查询数据更新数据删除数据 索引和约束创建索引创建约束 用户管理创建用户授权用户修改用户密码 备份和恢复备份数据库恢复数据库 高级特性结语参考文献 摘…...

Elasticsearch数据搜索原理
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个…...
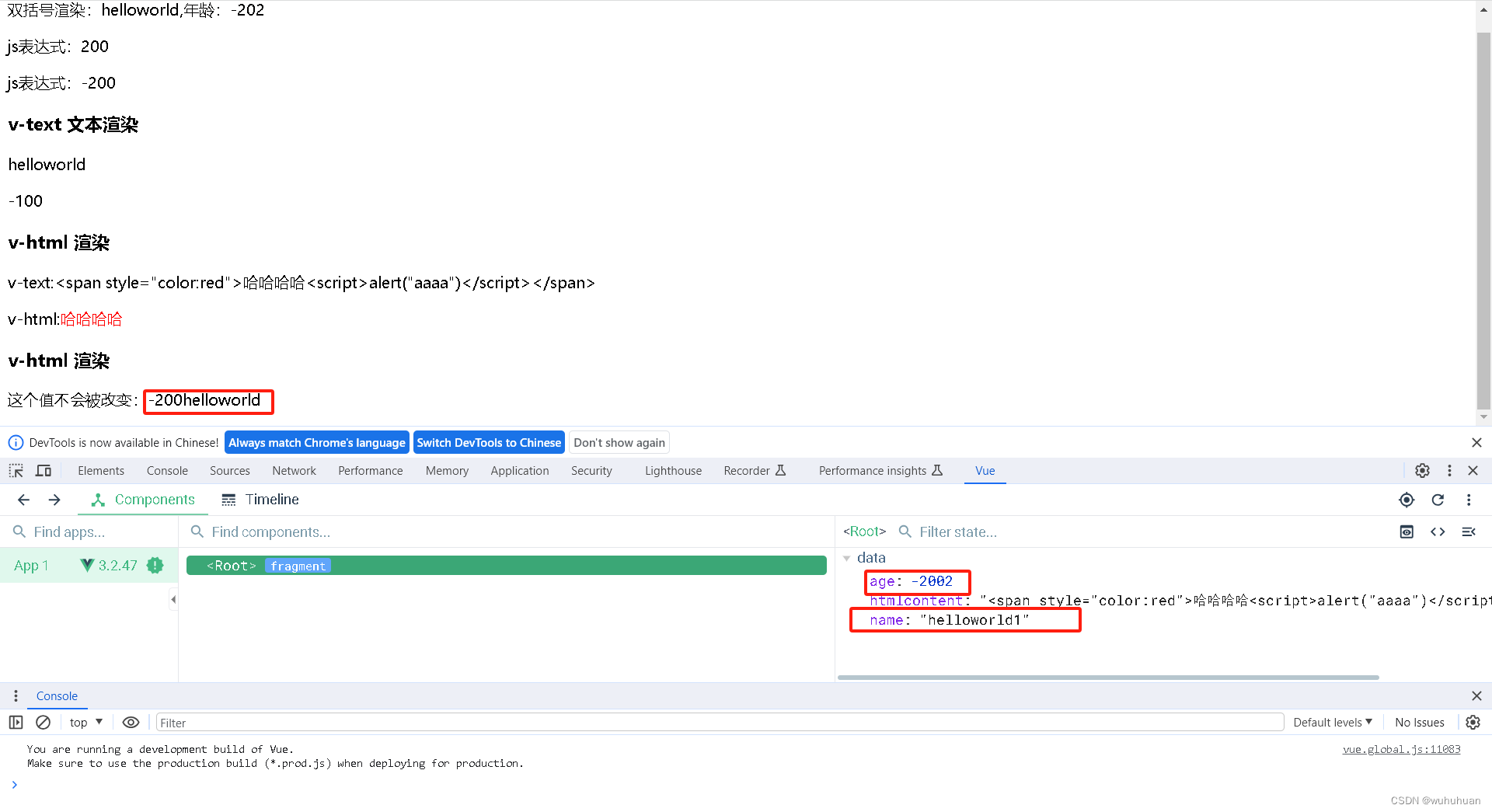
vue模版语法-{{}}/v-text/v-html/v-once
一、{{}}双括号:用于文本渲染 1、 {{变量名}}:data中返回对象的变量名 2、{{js表达式}}:可以直接进行js表达式处理 3、注意:双大括号中不要写等式书写 二、v-text 指令,用于文本渲染 1、为了解决双大括号渲染数据出现闪烁问题 三、v-cloak …...

前端埋点上传
没事看看: 从用户行为到数据:数据采集全景解析 | 人人都是产品经理 搭建前端监控,采集用户行为的 N 种姿势-前端监控设备 创业公司做数据分析(三)用户行为数据采集系统-CSDN博客...
)
第11章 Redis(一)
11.1 谈谈你对Redis的理解 难度:★★★ 重点:★★ 白话解析 对Redis的理解无非从三个方面去说一说:背景,是什么,特性。 背景:数据直接存磁盘太慢了,虽然MySQL用到了BufferPool等缓存,但是为了保证数据不丢失,MySQL采用的RedoLog依然要直接写磁盘。所以,数据的存储就…...

freertos信号量之二值信号量
freertos信号量之二值信号量 简介例程 简介 FreeRTOS的二值信号量(Binary Semaphore)是用于实现进程间同步和临界资源保护的重要工具。以下是一些二值信号量的常用函数及其说明: 1)xSemaphoreCreateBinary() 创建一个二值信号量…...

打造极致氛围感编码环境:从视觉、听觉到工作流的全栈实践指南
1. 项目概述:当“氛围感”遇上“编码”,一个宝藏仓库的诞生如果你和我一样,是个对开发环境、工具流和“仪式感”有执念的程序员,那你肯定不止一次地折腾过自己的IDE主题、终端配色、字体,甚至桌面的壁纸和音乐。我们内…...

S7-1500 PLC做高速数据采集?一个32位微秒时间戳的完整实现与避坑指南
S7-1500 PLC微秒级时间戳工程实践:从硬件同步到数据拼接的完整方案 在工业自动化领域,毫秒级响应已是基础要求,而微秒级精度正成为高端装备的标配。当一台数控机床以8000转/分钟的速度运行时,每个刀具接触工件的瞬间都需被精确记录…...

智能语义分块:chunkhound如何解决RAG应用中的文档处理难题
1. 项目概述:从“分块”到“猎犬”的智能进化如果你在数据处理的深海里游过泳,尤其是处理过那些动辄几十上百GB的文本、代码或日志文件,那你一定对“分块”(Chunking)这个概念又爱又恨。爱的是,它是我们处理…...

LLM赋能网页抓取:基于ChatGPT的智能数据提取实战指南
1. 项目概述与核心价值最近在数据采集和自动化领域,一个名为“oxylabs/chatgpt-web-scraping”的项目引起了我的注意。乍一看,这像是把两个热门概念——大型语言模型(LLM)和网页抓取(Web Scraping)——强行…...

从 Palantir Ontology 到企业 AI 决策系统
这几年,大模型把企业 AI 的想象空间一下子拉高了。很多公司都已经能做聊天、做问答、做检索、做 Copilot,甚至做一些初步的 Agent。但真正往生产里推,很快就会撞到几个老问题:模型能说,却未必真懂业务;能总…...
)
Lindy AI Agent工作流安全合规红线(GDPR+等保3.0双认证实操清单)
更多请点击: https://intelliparadigm.com 第一章:Lindy AI Agent工作流安全合规红线总览 Lindy AI Agent 作为面向企业级场景的智能体编排平台,其工作流在设计、部署与运行全生命周期中必须严格遵循数据安全、模型可解释性、访问控制及监管…...

好的、坏的、丑陋的:神经网络的记忆
原文:towardsdatascience.com/the-good-the-bad-an-ugly-memory-for-a-neural-network-bac1f79e8dfd |人工智能|记忆|神经网络|学习| https://github.com/OpenDocCN/towardsdatascience-blog-zh-2024/raw/master/docs/img/1e1ee7fbb30819e6f820f4d17dcd3b74.png 由…...

STM32F4用HAL库驱动MPU6050,从引脚重映射到数据读取的保姆级避坑指南
STM32F4 HAL库驱动MPU6050全流程实战:从引脚重映射到数据解析的深度避坑指南 第一次接触STM32F4和MPU6050的组合时,我花了整整三天时间才让传感器吐出第一个有效数据。不是I2C通信失败,就是数据全为零,最崩溃的是明明按照教程操作…...

Rust Trait实现:引用类型自动继承与泛型解决方案
1. 项目概述:Rust Trait实现的“引用陷阱”与泛型解决方案在Rust开发中,我们经常需要为自定义类型实现各种Trait来定义其行为。一个看似理所当然的直觉是:如果类型T实现了TraitSpeaker,那么它的引用&T也应该自动实现Speaker。…...

Go语言系统编程与命令行工具
Go语言系统编程与命令行工具 一、命令行参数解析 Go语言提供了多个标准库来处理命令行参数,包括flag包和os包。 使用flag包 package mainimport ("flag""fmt" )func main() {// 定义命令行参数name : flag.String("name", "Gues…...