【Pm4py第八讲】关于Statistics
本节用于介绍pm4py中的统计函数,包括统计轨迹变体、案例持续时间、案例到达时间等。

1.函数概述
本次主要介绍Pm4py中一些常见的统计函数,总览如下表:
| 函数名 | 说明 |
| pm4py.stats.get_start_activities() | 从事件日志中获取开始活动。 |
| pm4py.stats.get_end_activities() | 从事件日志中获取结束活动。 |
| pm4py.stats.get_event_attributes() | 获取事件的事件级的属性 |
| pm4py.stats.get_trace_attributes() | 获取事件轨迹级别的属性 |
| pm4py.stats.get_event_attribute_values() | 获取事件中某个属性的值 |
| pm4py.stats.get_trace_attribute_values() | 获取轨迹中的属性值 |
| pm4py.stats.get_case_arrival_average() | 获取事件的案件到达时间列表 |
| pm4py.stats.get_cycle_time() | 获取事件的周期时间 |
| pm4py.stats.get_all_case_durations() | 获取事件的案件持续时间列表 |
| pm4py.stats.get_case_duration() | 获取日志中特定案例的案例持续时间。 |
| pm4py.stats.get_stochastic_language() | 获取事件日志的随机语言 |
2.函数方法介绍
2.1 统计开始活动
pm4py.stats.get_start_activities(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[str, int]
说明:返回日志对象的开始活动输入参数:
log–log对象
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性输出参数:
Dict[str, int]
示例代码:
import pm4pystart_activities = pm4py.get_start_activities(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.2 统计日志对象的结束活动
pm4py.stats.get_end_activities(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[str, int]
说明:返回日志对象的结束活动
输入参数:
log–log对象
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性输出参数:
Dict[str, int]
示例代码:
import pm4pyend_activities = pm4py.get_end_activities(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.3 统计事件属性
pm4py.stats.get_event_attributes(log: EventLog | DataFrame) → List[str]
说明:统计事件属性输入参数:
log–log对象现可视化效果)
输出参数:List[str]
示例代码:
import pm4pyevent_attributes = pm4py.get_event_attributes(dataframe)2.4 统计轨迹属性
pm4py.stats.get_trace_attributes(log: EventLog | DataFrame) → List[str]
说明:统计轨迹属性输入参数:
log–log对象现可视化效果)
输出参数:List[str]
示例代码:
import pm4pytrace_attributes = pm4py.get_trace_attributes(dataframe)2.5 统计事件属性值
pm4py.stats.get_event_attribute_values(log: EventLog | DataFrame, attribute: str, count_once_per_case=False, case_id_key: str = 'case:concept:name') → Dict[str, int]
说明:统计事件属性值输入参数:
log–log对象
attribute(str)–attribute
count_once_per_case(bool)–如果为True,则只考虑案例中给定属性值的一次出现(如果有多个事件共享同一属性值,则只计算一次出现)
case_id_key(str)–要用作案例标识符的属性
输出类型:
Dict[str,int]
示例代码:
import pm4pyactivities = pm4py.get_event_attribute_values(dataframe, 'concept:name', case_id_key='case:concept:name')2.6 统计指定轨迹属性的值
pm4py.stats.get_trace_attribute_values(log: EventLog | DataFrame, attribute: str, case_id_key: str = 'case:concept:name') → Dict[str, int]
说明:返回指定跟踪属性的值
输入参数:
log–log对象
attribute(str)–属性
case_id_key(str)–要用作案例标识符的属性
输出类型:
Dict[str,int]
示例代码:
import pm4pytr_attr_values = pm4py.get_trace_attribute_values(dataframe, 'case:attribute', case_id_key='case:concept:name')2.7 统计日志变体
pm4py.stats.get_variants(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[Tuple[str], List[Trace]]
说明:从日志中获取变体
输入参数:
log–事件日志
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
输出类型:
Dict[Tuple[str],List[Trace]]
示例代码:
import pm4pyvariants = pm4py.get_variants(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.8 统计日志变体2
pm4py.stats.get_variants_as_tuples(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[Tuple[str], List[Trace]]
说明:从日志中获取变体(其中键是元组而不是字符串)
输入参数:
log–事件日志
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
输出类型:
Dict[Tuple[str],List[Trace]]
示例代码:
import pm4pyvariants = pm4py.get_variants_as_tuples(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.9 统计活动的自距离
pm4py.stats.get_minimum_self_distances(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[str, int]
说明:该算法计算在事件日志中观察到的每个活动的最小自身距离。a在<a>中的自距离为无穷大,a在<a、a>中为0,在<a,b、a>为1,等等。最小自距离是事件日志中观察到的最小自距离值。
输入参数:
log–事件日志(pandas.DataFrame、EventLog或EventStream)
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
输出类型:
Dict[str,int]
示例代码:
import pm4pymsd = pm4py.get_minimum_self_distances(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')timestamp')2.10 统计活动自距离见证人
pm4py.stats.get_minimum_self_distance_witnesses(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[str, Set[str]]
说明:此函数导出最小自距离见证人。a在<a>中的自距离为无穷大,a在<a、a>中为0,在<a,b、a>为1,等等。最小自距离是事件日志中观察到的最小自距离值。“见证人”是见证自我距离最小的活动。例如,如果某个日志L中活动a的最小自距离是2,那么,如果轨迹<a,b,c,a>在日志L中,b和c是a的见证。
输入参数:
log–要使用的事件日志
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
输出类型:
Dict[str,Set[str]]
示例代码:
import pm4pymsd_wit = pm4py.get_minimum_self_distance_witnesses(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.11 统计案例到达时间
pm4py.stats.get_case_arrival_average(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → float
说明:获取两个连续事例的开始时间之间的平均差值
输入参数:
log–log对象
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
返回类型:
float
示例代码:
import pm4pycase_arr_avg = pm4py.get_case_arrival_average(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.12 统计返工活动
pm4py.stats.get_rework_cases_per_activity(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[str, int]
说明:找出日志中哪些活动发生了返工(该活动的轨迹中出现了多个)。输出是一个字典,将发生返工的案例数量与上述每个活动相关联。
输入参数:
log–log对象
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
返回类型:
Dict[str,int]
示例代码:
import pm4pyrework = pm4py.get_rework_cases_per_activity(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.13 统计日志的周期时间
pm4py.stats.get_cycle_time(log: EventLog | DataFrame, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → float
说明:计算事件日志的周期时间。
所遵循的定义是在中提出的定义:https://www.presentationeze.com/presentations/lean-manufacturing-just-in-time/lean-manufacturing-just-in-time-full-details/process-cycle-time-analysis/calculate-cycle-time/#:~:text=Cycle%20time%20%3D%20Average%20time%20between,is%2024%20minutes%20on%20average。
因此:周期时间=单位完成之间的平均时间。
网站上的例子:考虑一个制造厂,它每40小时生产100个产品。平均吞吐率为每0.4小时1台,即每24分钟1台。因此,周期时间平均为24分钟。
输入参数:
log–log对象
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
返回类型:
float
示例代码:
import pm4pycycle_time = pm4py.get_cycle_time(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')
2.14 统计案例的持续时间
pm4py.stats.get_all_case_durations(log: EventLog | DataFrame, business_hours: bool = False, business_hour_slots=[(25200, 61200), (111600, 147600), (198000, 234000), (284400, 320400), (370800, 406800)], activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → List[float]
说明:获取事件日志中事例的持续时间
输入参数:
log–事件日志
business_hours(bool)–启用/禁用基于营业时间的计算(默认值:False)
business_hour_slots–公司的工作时间表,以元组列表的形式提供,其中每个元组表示一个工作时间段。一个槽,即一个元组,由一个开始时间和一个结束时间组成,以秒为单位,从周开始,例如[(7*60*60,17*60*60],((24+7)*60*60%,(24+12)*60=60),((24/13)*60*60,(24+17)*60*50],这意味着营业时间为周一07:00-17:00,周二07:00-12:00和13:00-17:00
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
返回类型:List[float]
示例代码:
import pm4pycase_durations = pm4py.get_all_case_durations(dataframe, activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.15 统计特定案例的持续时间
pm4py.stats.get_case_duration(log: EventLog | DataFrame, case_id: str, business_hours: bool = False, business_hour_slots=[(25200, 61200), (111600, 147600), (198000, 234000), (284400, 320400), (370800, 406800)], activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str | None = None) → float
说明:获取事件日志中特定事例的持续时间
输入参数:
log–事件日志
business_hours(bool)–启用/禁用基于营业时间的计算(默认值:False)
business_hour_slots–公司的工作时间表,以元组列表的形式提供,其中每个元组表示一个工作时间段。一个槽,即一个元组,由一个开始时间和一个结束时间组成,以秒为单位,从周开始,例如[(7*60*60,17*60*60],((24+7)*60*60%,(24+12)*60=60),((24/13)*60*60,(24+17)*60*50],这意味着营业时间为周一07:00-17:00,周二07:00-12:00和13:00-17:00
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
返回类型:List[float]
示例代码:
import pm4pyduration = pm4py.get_case_duration(dataframe, 'case 1', activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.16 统计活动位置次数
pm4py.stats.get_activity_position_summary(log: EventLog | DataFrame, activity: str, activity_key: str = 'concept:name', timestamp_key: str = 'time:timestamp', case_id_key: str = 'case:concept:name') → Dict[int, int]
说明:给定一个事件日志,返回一个字典,其中总结了活动在事件日志的不同情况下的位置。例如,如果一个活动在位置1发生1000次(案例的第二个事件),在位置2发生500次(案件的第三个事件)时,则返回的字典为:{1/1000,2:500}
输入参数:
log–事件日志对象/Pandas数据帧
activity(str)–要考虑的活动
activity_key(str)–要用于活动的属性
timestamp_key(str)–用于时间戳的属性
case_id_key(str)–要用作案例标识符的属性
返回类型:Dict[int, int]
示例代码:
import pm4pyact_pos = pm4py.get_activity_position_summary(dataframe, 'Act. A', activity_key='concept:name', case_id_key='case:concept:name', timestamp_key='time:timestamp')2.17 获取随机语言
pm4py.stats.get_stochastic_language(*args, **kwargs) → Dict[List[str], float]
说明:从提供的日志对象中获取随机语言
输入参数:
args–Pandas数据帧/事件日志/接受Petri网/过程树
kwargs–关键字参数返回类型:
Dict[List[str], float]
示例代码:
import pm4pylog = pm4py.read_xes('tests/input_data/running-example.xes')
language_log = pm4py.get_stochastic_language(log)
print(language_log)
net, im, fm = pm4py.read_pnml('tests/input_data/running-example.pnml')
language_model = pm4py.get_stochastic_language(net, im, fm)
print(language_model)如需了解更多,欢迎加入流程挖掘交流群QQ:671290481.
相关文章:
【Pm4py第八讲】关于Statistics
本节用于介绍pm4py中的统计函数,包括统计轨迹变体、案例持续时间、案例到达时间等。 1.函数概述 本次主要介绍Pm4py中一些常见的统计函数,总览如下表: 函数名说明pm4py.stats.get_start_activities()从事件日志中获取开始活动。pm4py.stats.…...
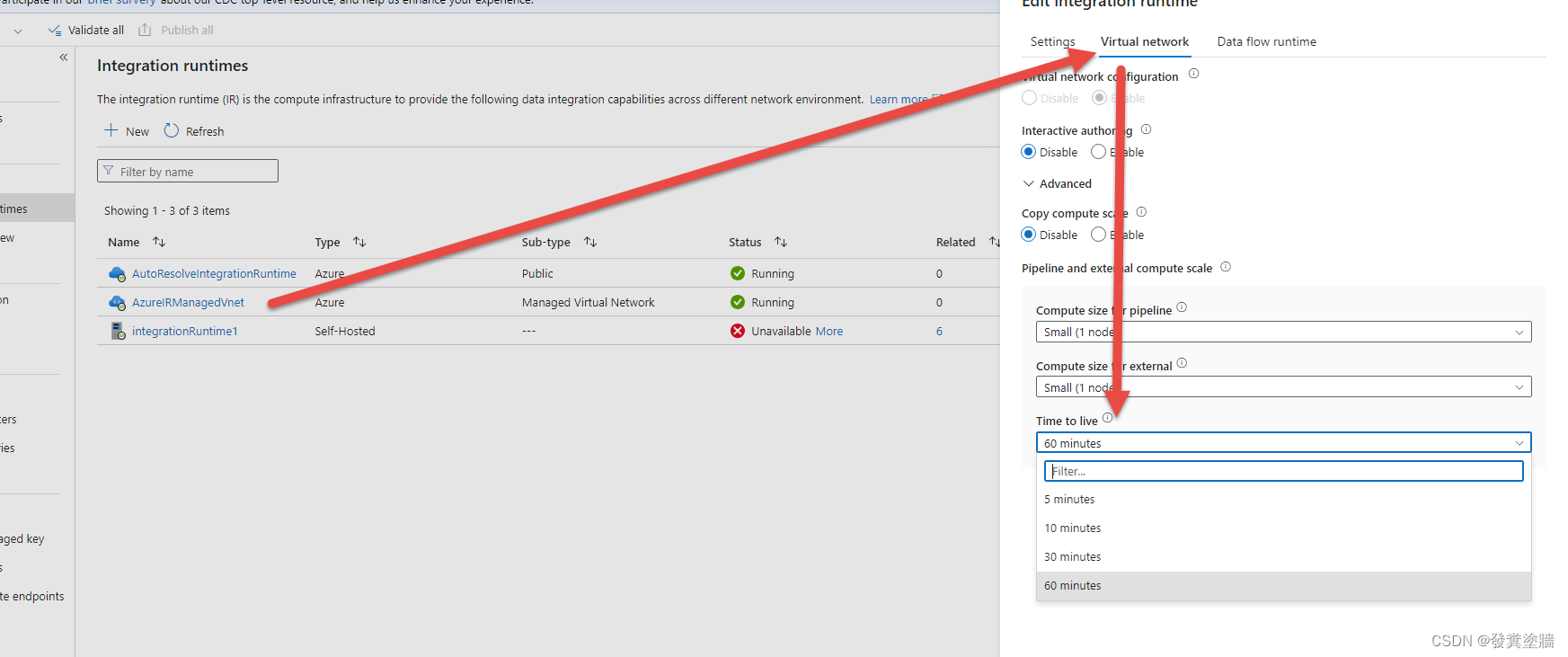
【Azure 架构师学习笔记】-Azure Data Factory (5) --Data Flow
本文属于【Azure 架构师学习笔记】系列。 本文属于【Azure Data Factory】系列。 接上文【Azure 架构师学习笔记】-Azure Data Factory (4)-触发器详解-事件触发器 前言 Azure Data Factory, ADF 是微软Azure 的ETL 首选服务之一, 是Azure data platfor…...

uniapp之ios开发及支付整体流程爬坑记录
前言 在写这篇记录的时候,关于ios的支付已经对接的差不多了,下一步就是测试好了直接发版,总共花了好几周的时间,从0到1对于首次做ios支付来说,确实很多坑。 其实业务层面很简单,甚至比安卓支付还简单&…...

AutoDL百川大模型体验
文章目录 镜像克隆模型下载测试效果AutoDL自定义服务 感谢AutoDL和CodeWithGPU这两个平台,让我们能低成本,低门槛地部署体验这些大模型 镜像克隆 我是在CodeWithGPU上克隆的这个镜像 模型下载 codewithgpu有介绍 注意这三个文件都需要下载 把那个&quo…...
蓝桥杯每日一题2023.10.8
题目描述 七段码 - 蓝桥云课 (lanqiao.cn) 题目分析 所有的情况我们可以分析出来一共有2的7次方-1种,因为每一个二极管都有选择和不选择两种情况,有7个二极管,但是还有一种都不选的情况需要排除,故-1 枚举每个方案看是否符合要…...
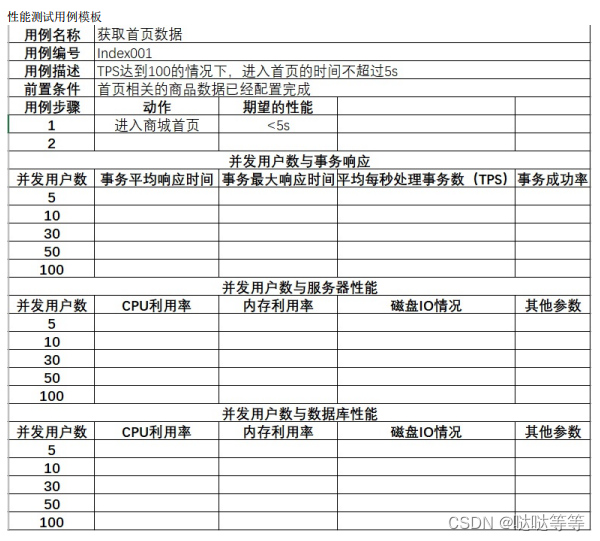
jmeter,性能测试,Locust
一。性能测试的概念 1.性能:就是软件质量属性中的 “ 效率 ” 特性 2.效率特性: 时间特性:指系统处理用户请求的响应时间 资源特性:指系统在运行过程中,系统资源的消耗情况 CPU 内存 磁盘IO(磁盘的写…...
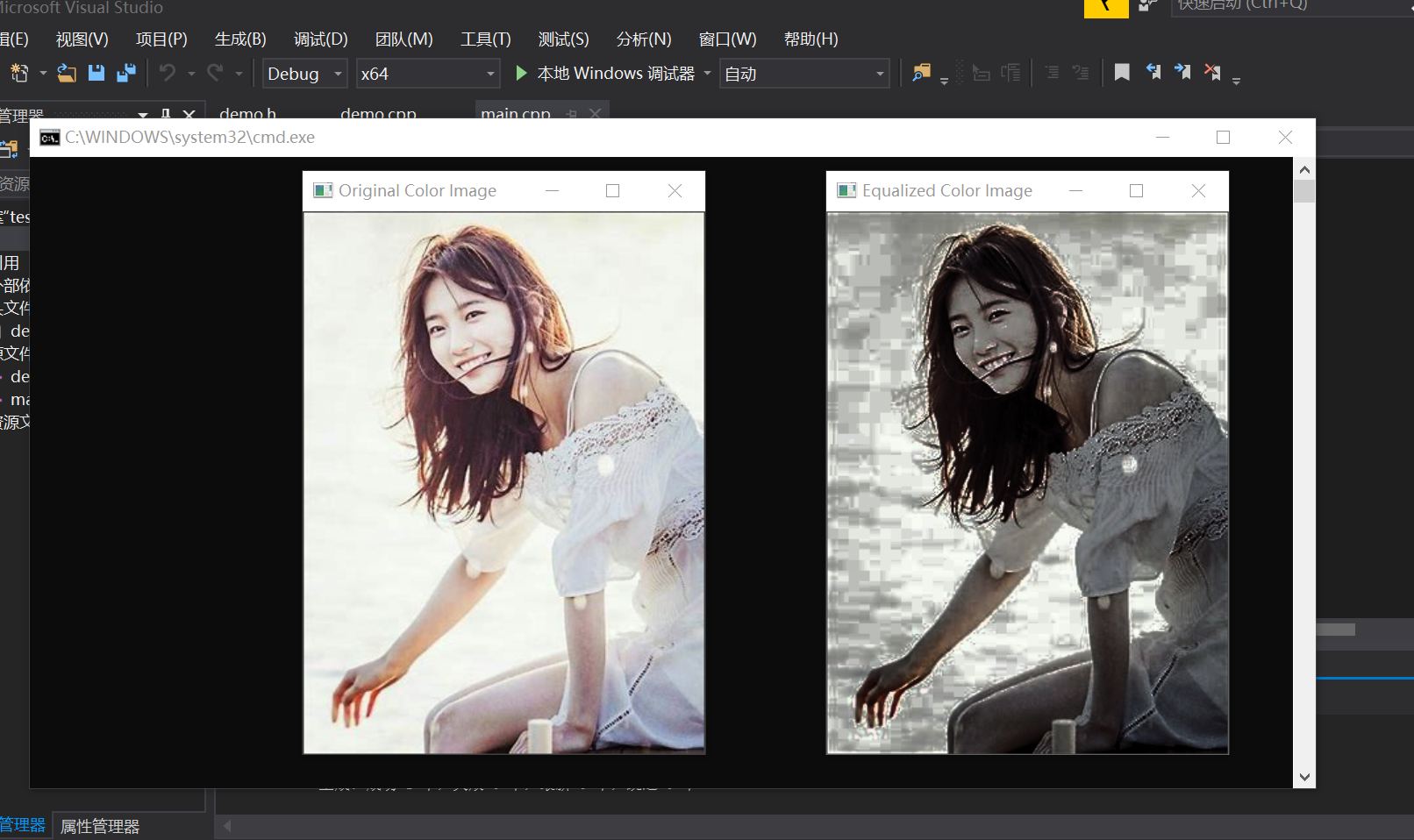
opencv图像的直方图,二维直方图,直方图均衡化
文章目录 opencv图像的直方图,二维直方图,直方图均衡化一、图像的直方图1、什么是图像的直方图:2、直方图的作用:3、如何绘制图像的直方图:(1)cv::calcHist()函数原型:英文单词 calc…...
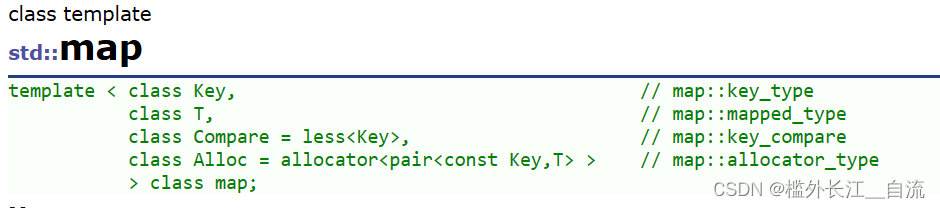
c++中的map和set
文章目录 1. 关联式容器2. 键值对3. 树形结构的关联式容器3.1 set3.1.1 set的介绍3.1.2 set的使用 3.2 map3.2.1 map的介绍3.2.2 map的使用 3.3 multiset3.3.1 multiset的介绍3.3.2 multiset的使用 3.4 multimap3.4.1 multimap的介绍3.4.2 multimap的使用 1. 关联式容器 在初阶…...

Swagger使用详解
目录 一、简介 二、SwaggerTest项目搭建 1. pom.xml 2. entity类 3. controller层 三、基本使用 1. 导入相关依赖 2. 编写配置文件 2.1 配置基本信息 2.2 配置接口信息 2.3 配置分组信息 2.3.1 分组名修改 2.3.2 设置多个分组 四、常用注解使用 1. ApiModel 2.A…...

ToBeWritten之车联网安全中常见的TOP 10漏洞
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

软考-密码学概述
本文为作者学习文章,按作者习惯写成,如有错误或需要追加内容请留言(不喜勿喷) 本文为追加文章,后期慢慢追加 by 2023年10月 密码学基本概念 密码学的主要目的是保持明文的秘密以防止攻击者获知,而密码分…...
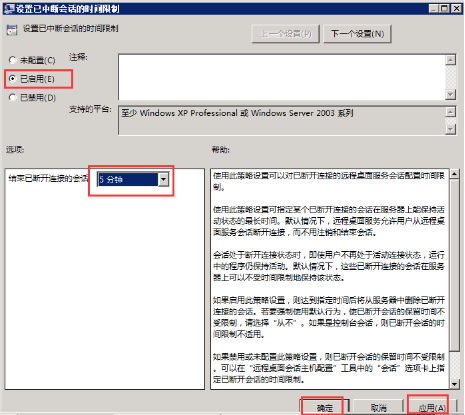
windows 2003、2008远程直接关闭远程后设置自动注销会话
1、2003系统: 按开始—运行—输入“tscc.msc”,打开“终端服务配置”。 单击左边窗口的“连接”项,右边窗口中右击“RDP-TCP”,选择“属性”。 单击“会话”项,勾选“替代用户设置”,在“结束已断开的会话”…...

iOS BUG UIView转UIImage模糊失真
iOS BUG UIView转UIImage模糊失真 ##UIView转成Image - (UIImage *)capture {UIGraphicsBeginImageContextWithOptions(self.bounds.size, YES, 0.0);[self.layer renderInContext:UIGraphicsGetCurrentContext()];UIImage *img UIGraphicsGetImageFromCurrentImageContext(…...

如何在10分钟内让Android应用大小减少 60%?
一个APP的包之所以大,主要包括一下文件 代码libso本地库资源文件(图片,音频,字体等) 瘦身就主要瘦这些。 一、打包的時候刪除不用的代码 buildTypes {debug {...shrinkResources true // 是否去除无效的资源文件(如…...

网络代理技术:保障隐私与增强安全
在当今数字化的世界中,网络代理技术的重要性日益凸显。无论您是普通用户还是网络工程师,了解如何使用代理技术来保护隐私和增强网络安全都是至关重要的。本文将深入探讨Socks5代理、IP代理以及它们在网络安全和隐私保护中的关键作用。 1. Socks5代理&am…...
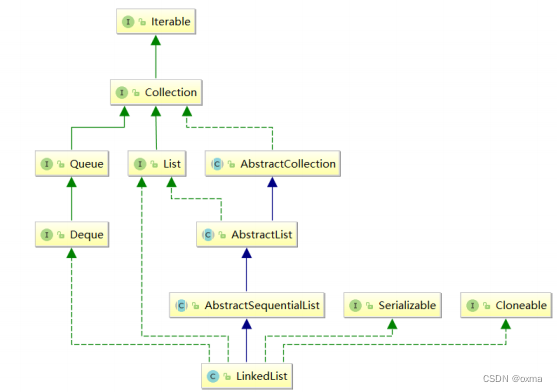
数据结构 | (二) List
什么是 List 在集合框架中, List 是一个接口,继承自 Collection 。 Collection 也是一个接口 ,该接口中规范了后序容器中常用的一些方法,具体如下所示: Iterable 也是一个接口,表示实现该接口的类是可以逐个…...

[NewStarCTF 2023 公开赛道] week1 Crypto
brainfuck 题目描述: [>>>>>>>>>>>>>>>><<<<<<<<<<<<<<<<-]>>>>>>>.>----.<-----.>-----.>-----.<<<-.>>..…...

C语言中文网 - Shell脚本 - 0
教程目录如下: 第1章 Shell基础(开胃菜) 1. Shell是什么?1分钟理解Shell的概念! 2. Shell是运维人员必须掌握的技能 3. 常用的Shell有哪些? 4. 进入Shell的两种方式 5. Linux Shell命令的基本格式 6.…...
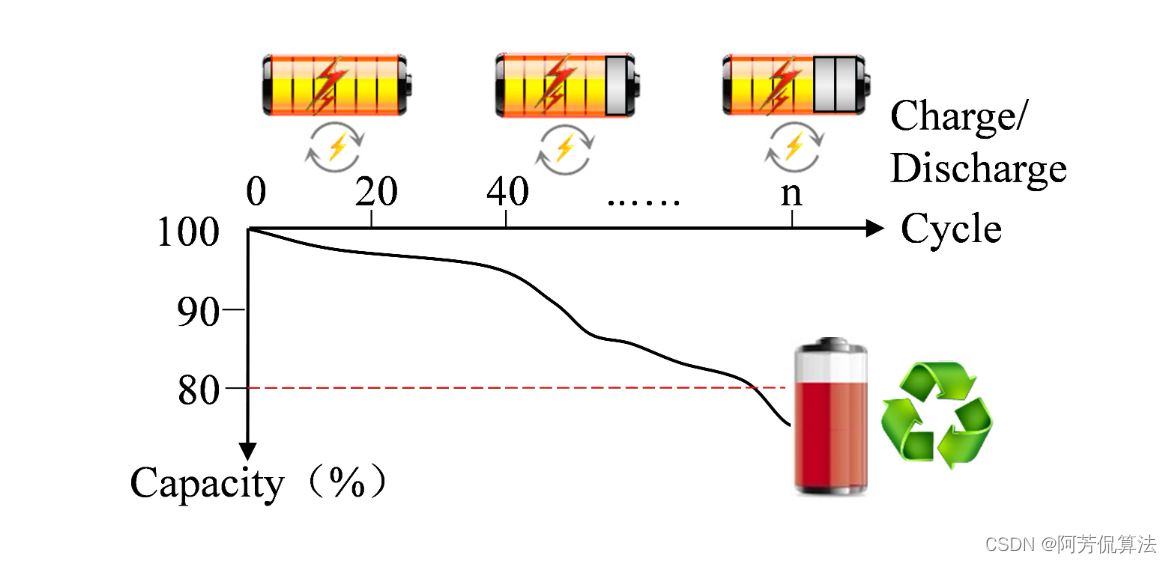
Transformer预测 | Pytorch实现基于Transformer 的锂电池寿命预测(CALCE数据集)
文章目录 效果一览文章概述模型描述程序设计参考资料效果一览 文章概述 Pytorch实现基于Transformer 的锂电池寿命预测,环境为pytorch 1.8.0,pandas 0.24.2 随着充放电次数的增加,锂电池的性能逐渐下降。电池的性能可以用容量来表示,故寿命预测 (RUL) 可以定义如下: SOH(t…...
2023年【通信安全员ABC证】找解析及通信安全员ABC证考试总结
题库来源:安全生产模拟考试一点通公众号小程序 通信安全员ABC证找解析参考答案及通信安全员ABC证考试试题解析是安全生产模拟考试一点通题库老师及通信安全员ABC证操作证已考过的学员汇总,相对有效帮助通信安全员ABC证考试总结学员顺利通过考试。 1、【…...

电能质量治理三相光伏逆变器设计【附程序】
✨ 长期致力于MPPT、电能质量治理、改进哈里斯鹰、重复控制、预置补偿角、模糊PI研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)基于混沌哈里斯鹰算法…...

深入解析epoll ET模式与守护进程
引言在前面的文章中,我们学习了 epoll 的基础用法和 LT 模式。本文将深入讲解两个重要主题:epoll 的 ET 模式:边缘触发模式的编程要点与完整实现守护进程:Linux 后台服务进程的原理与编写规范ET 模式是 epoll 高性能的关键&#x…...

Steam Cron Studio:可视化配置生成器,为AI代理打造Steam自动化任务
1. Steam Cron Studio:一个为AI代理量身定制的Steam自动化配置生成器如果你是一个Steam重度用户,同时又对AI代理(AI Agent)和自动化工具感兴趣,那么你很可能和我一样,曾经被一个看似简单实则繁琐的问题困扰…...

告别混乱XML:Notepad++插件一键美化与智能纠错实战
1. 为什么我们需要XML格式化工具? 作为一个常年和XML打交道的开发者,我太清楚那种打开一个几千行XML文件时的绝望了——所有标签挤在一起,缩进混乱得像被猫抓过的毛线球,想找个节点得用CtrlF来回搜三遍。更可怕的是,有…...

Memor:为LLM对话构建结构化记忆引擎,实现可重现、可移植的AI交互管理
1. 项目概述:Memor,为LLM对话赋予结构化记忆如果你和我一样,长期和各类大语言模型打交道,从早期的GPT-3到现在的Claude、Gemini,一个绕不开的痛点就是:对话历史的管理。默认的聊天界面里,历史记…...

从‘咖啡环’到‘热点’富集:超疏水表面如何将SERS检测灵敏度提升几个数量级?
从“咖啡环效应”到分子富集革命:超疏水表面如何重塑痕量检测极限 清晨的咖啡杯边缘总留下一圈深色痕迹,这个看似普通的日常现象背后,隐藏着改变分子检测游戏规则的物理机制。当科研人员将这种被称为"咖啡环效应"的液滴蒸发现象与表…...

从CANdb++到Matlab:手把手教你读懂DBC文件里的信号映射与物理值转换
从CANdb到Matlab:手把手教你读懂DBC文件里的信号映射与物理值转换 在汽车电子和嵌入式系统开发中,DBC文件作为CAN总线通信的"字典",承载着整车网络通信的核心协议。对于刚接触汽车网络通信的工程师来说,面对DBC文件中密…...

APK Installer完整指南:在Windows上快速安装Android应用的终极方案
APK Installer完整指南:在Windows上快速安装Android应用的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经想在Windows电脑上轻松安装An…...

深度解构:指纹浏览器底层隔离与Python高并发RPA,如何重塑电商矩阵自动化架构?
大家好,我是林焱,一名专注电商底层业务逻辑与 RPA 自动化架构定制的独立开发者。 在 CSDN 的各个技术板块中,关于爬虫与反爬虫、并发调度、以及客户端架构的讨论一直是热点。而将这些技术综合应用到极致的领域之一,就是当下极度内…...

犬种识别实战:细粒度CNN模型从训练到ONNX部署
1. 项目概述:用一张照片,让模型告诉你这是什么狗 “Deep Learning (CNN) — Discover the Breed of a Dog in an Image”这个标题看起来像一句教科书里的课后习题,但实际落地时,它是一条从数据噪声里硬生生凿出来的技术路径——不…...